










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkSemestre Económico
versão impressa ISSN 0120-6346
Semest. Econ. vol.18 no.37 Medellín jan./jun. 2015
ARTÍCULOS
APLICACIÓN DE LA ECONOMETRÍA ESPACIAL PARA EL ANÁLISIS DE LA MISERIA EN LOS MUNICIPIOS DEL DEPARTAMENTO DE ANTIOQUIA*
A SPATIAL ECONOMETRICS APPLICATION FOR ANALYZING EXTREME POVERTY IN THE MUNICIPALITIES OF ANTIOQUIA DEPARTMENT
MA APLICAÇÃO DA ECONOMETRIA ESPACIAL PARA A ANÁLISES DA MISÉRIA NOS MUNICÍPIOS DO DEPRTAMENTO DE ANTIOQUIA
Gabriel Agudelo Torres**; Luis E. Franco Ceballos***; Luis C. Franco Arbeláez****
** Ingeniero Financiero, Universidad de Medellín, Medellín, Colombia. Magíster en Matemáticas Aplicadas. Universidad EAFIT, Medellín. Colombia. Docente-investigador, Ingeniería Financiera y Negocios, Instituto Tecnológico Metropolitano, Medellín, Colombia. Grupo de Investigación Ciencias Administrativas, Instituto Tecnológico Metropolitano, Medellín, Colombia. Calle 54A No. 1-30, 4405100. Correo electrónico: albertoagudelo@itm.edu.co.
*** Ingeniero Financiero, Universidad de Medellín, Medellín, Colombia. Magíster en Finanzas, Universidad EAFIT, Medellín, Colombia. Docente-investigador, Ingeniería Financiera y Negocios, Instituto Tecnológico Metropolitano, Medellín, Colombia. Grupo de Investigación Ciencias Administrativas, Instituto Tecnológico Metropolitano, Medellín, Colombia. Calle 54A N.° 1-30, 4405100. Correo electrónico: luisefranco@itm.edu.co.
**** Matemático. Universidad Nacional de Colombia, Medellín, Colombia. Especialista en Finanzas y Mercado de Capitales. Universidad de Medellín., Medellín, Colombia. Magister en Matemáticas Aplicadas, Universidad EAFIT, Medellín, Colombia. Docente-investigador, Ingeniería Financiera y Negocios, Instituto Tecnológico Metropolitano, Medellín, Colombia. Grupo de Investigación Ciencias Administrativas, Instituto Tecnológico Metropolitano, Medellín, Colombia. Calle 54A N.° 1-30, 4405100. Correo electrónico: luisfranco@itm.edu.co.
Recibido: 27 de enero de 2014
Aceptado: 20 de agosto 2015
RESUMEN
Este artículo comprueba la existencia de autocorrelación espacial al considerar la proporción de personas que viven en situación de miseria en los municipios del departamento de Antioquia, Colombia. Para ello se utiliza el test I de Moran y se propone un algoritmo para descartar la posibilidad de que la dependencia espacial sea espuria. Los resultados demuestran la necesidad de tener en cuenta la econometría espacial para determinar la asignación óptima del gasto social, destinado a intervenir en forma efectiva la situación de miseria en los municipios del departamento de Antioquia.
PALABRAS CLAVE
Econometría, desigualdad, pobreza, modelos espaciales.
CLASIFICACIÓN JEL
C18, C31, J19, R12, I32
CONTENIDO
Introducción; 1. Metodología; 2. Resultados; 3. Conclusiones; Bibliografía.
ABSTRACT
This article proves the existence of a spatial correlation when considering the percentage of people living in extreme poverty in the municipalities of the Antioquia department. For thisp urpose, a Moran I test is used and an algorithm is proposed in order to discard the possibility of a spurious spatial dependency. Results prove that spatial econometrics must be bared in mind for an optima allocation of social expenditure, destined to effectively intervene extreme poverty in the Antioquia department.
KEY WORDS
Econometrics, inequality, poverty, spatial models
JEL CLASSIFICATION
C18, C31, J19, R12, I32
CONTENT
Introduction, 1. Methodology; 2. Results; 3. Conclusions; Bibliography.
RESUMO
Neste artigo se comprova a existencia de auto correlação espacial ao considerar a proporção de pessoas que vivem em situação de miséria nos municípios do departamento de Antioquia, Colombia. Para isso se utiliza o test I de Moran e se propõe um algoritmo para descartar a possibilidade de que a dependencia espacial seja espúria. Os resultados demostram a necessidade de ter em conta a econometria espacial para determina a designação ótima do gasto social, destinado a intervir em forma efetiva a situação de miséria nos municípios do departamento de Antioquia
PALAVRAS CHAVE
Econometria, desigualdade, pobreza, modelos espaciais.
CLASIFICAÇÃO JEL
C18, C31, J19, R12, I32
CONTEÚDO
Introdução; 1. Metodologia; 2. Resultados; 3. Conclusões; Bibliografia.
INTRODUCCIÓN
En el ámbito socio-político, la reducción del porcentaje de personas que viven en situación de miseria en el país es uno de los temas más sensibles, y de máximo impacto en la toma de decisiones frente al gasto social del Gobierno Central. Así lo consideran autores como Galvis y Meisel (2010). Uno de los enfoques más utilizados en estas investigaciones es el econométrico tradicional, que ignora la posible dependencia espacial en el comportamiento de la variable, objeto de estudio.
Según Moran (1948) Geary (1954), y Paelinck y Klaasen (1979), la econometría espacial permite analizar los efectos espaciales en la modelación de variables y, por lo tanto, se convierte en un complemento fundamental a la econometría tradicional, cuando se trata de determinar el impacto del espacio físico sobre el comportamiento de una variable de interés. Es una rama de la econometría en cuyas especificaciones se consideran elementos relacionados con el espacio físico en el cual se ubican las observaciones. Incorpora las herramientas necesarias para allegar los efectos espaciales existentes en determinada estructura económica. Esta relación constituye el primer y más importante efecto espacial entre variables, y se denomina dependencia espacial; su presencia, traducida en auto-correlación espacial, puede invalidar modelos econométricos tradicionales, tal como la auto-correlación temporal lo hace en este tipo de especificaciones.
Moreno y Vayá (2000) plantean que la posibilidad de que la econometría espacial sea utilizada en el tratamiento de un problema ésta supeditado a la existencia del fenómeno llamado dependencia espacial. Según Moreno y Vayá (2000, p. 21) la dependencia espacial es entendida como ''la existencia de una relación funcional entre lo que ocurre en un punto determinado del espacio y lo que ocurre en otro lugar''. Es decir, la variable endógena presentará altos niveles de auto-correlación espacial cuando los valores de ella dependen no solo de variables exógenas sino también de la localización geográfica de estos valores (tanto de la variable endógena como de una o más exógenas). Para la presencia de auto-correlación espacial se pueden utilizar diversos estadísticos, entre los cuales el más aplicado es el de Moran (1948).
Los test para la detección de la auto-correlación espacial pueden dar como resultado la existencia de una falsa dependencia espacial, llamada dependencia espacial espuria. Este resultado podría presentarse cuando una región con unas características bien definidas (como cultura, alimentación, estilo de vida, preferencias, etc.) aparece dividida en varias subregiones por cuestiones políticas, administrativas, etc., y podría llevar a los responsables de la asignación del gasto público a cometer errores en la distribución de recursos destinados a intervenir este problema. Diversos autores como Fingleton (1999), Lauridsen y Kosfeld (2006) y Beenstock, Feldman y Felsenstein (2012) han estudiado los efectos y posible tratamiento de este fenómeno.
Desde 1987 con la ayuda del Programa de las Naciones Unidas para el Desarrollo (PNUD), y el Departamento Nacional de Planeación de Colombia (DNP), se creó el Departamento Administrativo Nacional de Estadística (DANE), que realiza periódicamente una investigación con alcance nacional, llamada Indicadores de Necesidades Básicas Insatisfechas (NBI). El objetivo general de la investigación de NBI es determinar, con la ayuda de algunos indicadores, si las necesidades básicas de la población se encuentran cubiertas; los grupos que no alcancen un umbral mínimo fijado son clasificados como pobres. En particular, dicha investigación determina indicadores de pobreza y de miseria, que sirven a los entes públicos y privados para la toma de decisiones, apoyando planes relacionados con servicios públicos, vivienda y educación.
La investigación de NBI utiliza cinco indicadores básicos que son: vivienda inadecuada, viviendas con hacinamiento crítico, viviendas con servicios inadecuados, viviendas con alta dependencia económica y viviendas con niños en edad escolar que no asisten a la escuela. A partir de estas variables se construye un indicador que clasifica como pobres a aquellos hogares que estén, al menos, en una de las situaciones de carencia expresada por los indicadores, y en situación de miseria a los hogares que tengan dos o más de los indicadores básicos de necesidades básicas insatisfechas. La investigación de NBI, que se realiza por medio de entrevista directa en los hogares, considera que las personas que habitan en viviendas pobres o en miseria se encuentran en las mismas condiciones de su respectiva vivienda. En la investigación de NBI se obtiene para cada municipio de Colombia la proporción de personas en situación de miseria. A partir de esos datos se obtiene la información para desarrollar la metodología que permite detectar la presencia potencial de dependencia espacial en los datos correspondientes al porcentaje de personas en situación de miseria en los municipios del departamento de Antioquia.
En el ámbito internacional, muchos estudios que analizan la pobreza y la miseria se enfocan en el estudio de modelos econométricos tradicionales. Por ejemplo, De la Fuente y Cartagena (2007) estiman, para Chile, modelos econométricos del tipo Logit y Probit, e identifican algunas de las variables de mayor incidencia que impactan la dinámica de la probabilidad de un hogar de encontrarse en situación de pobreza. Otros estudios en ese sentido han sido los desarrollados por autores como Grootaert y Kanbur (1995) para el caso de África occidental, y por López y Della Maggiora (2000) y Herrera (1999) para el caso de Perú, Wodon y Cruzes (2003) en Argentina, y Slon y Zúñiga (2006) para el caso de Costa Rica.
Bayudan y Lim (2013), usando modelos econométricos de datos de panel e indicadores de bienestar, estudian los indicadores de pobreza en Filipinas. Nisar y otros (2013) utilizan un modelo logit multinomial para analizar la compleja situación de pobreza en Pakistán. Osowole, Nwoke y Uba (2012), utilizando un modelo lineal generalizado analizan el comportamiento de la pobreza en Nigeria. Una característica común en estos estudios es el énfasis que hacen en las variables temporales, y la carencia de análisis de los efectos espaciales en la medición de la pobreza, como aspecto determinante de su dinámica.
Cotte y Pardo (2011) miden y clasifican los departamentos colombianos entre 1993 y 2007 usando el análisis envolvente de datos (DEA) como una medida que determina la eficiencia en las tendencias de la pobreza y la desigualdad, y realizan un sistema de clasificación donde Valle, Caquetá, Santander y Boyacá obtuvieron los mejores resultados, y Chocó, Córdoba, Cauca y Sucre los peores. Además, identifican que los de mayor cobertura en salud, educación, e inversión pública tienen mejores resultados en su eficiencia y los que tienen mayor densidad poblacional, tasa de desempleo, tasa de homicidios y mayor concentración de la propiedad tienen un menor puntaje.
Por otro lado, existen algunos estudios que sí tienen en cuenta algunos efectos espaciales. Rodríguez (2010) revisa y aplica los modelos clásicos de regresión espacial con varianza homocedástica (Anselin, 1988; Moreno y Vaya, 2000; Arbia y Blagati, 2009) para modelar y estimar la concentración de tierra, y encuentra que para Colombia la variable concentración de tierra se auto-correlaciona espacialmente, e indica que si un departamento tiene concentración alta de tierra los vecinos se comportan de igual forma; además, el autor analiza relaciones entre la concentración de la tierra y la violencia.
Kaztman (2003, p. 22) analiza el distanciamiento físico entre pobres y no pobres y afirma que:
[...] sin duda la proximidad física aumenta las oportunidades de interacción entre ambos segmentos de la población, lo que, a su vez, favorece el desarrollo de empatías e identificaciones mínimas que hacen posible que los más pobres adopten hábitos, actitudes y expectativas de los no pobres. Que la proximidad física no es suficiente para producir este efecto se desprende con claridad de la experiencia de las sociedades de casta, en las que la cercanía espacial no parece alterar distancias sociales profundamente enraizadas en la cultura.
El efecto espacial referente a la situaciones de pobreza o miseria entre municipios contiguos no se puede suponer como existente o no, previa elaboración de modelos y políticas de intervención, y se debe, por lo tanto, realizar validaciones que permitan verificar las relaciones en la zona geográfica analizada.
Galvis y Meisel (2010, 2012) estudian la pobreza en los municipios de Colombia desde una perspectiva temporal y espacial, y a partir de los datos de los cuatro censos de NBI realizados en Colombia entre 1973 y 2005, analizan la incidencia, la persistencia, y la resiliencia de la información de las regiones y los municipios, y encuentran existencia de círculos viciosos de pobreza, concentrados en mayor medida en la periferia del país, lo cual desencadena equilibrios perversos como lo plantea Azariadis (2006).
En el mismo sentido, Pérez (2005) utiliza un planteamiento similar al de esta investigación, y toma como fuente de datos los censos de población hechos por el DANE en 1985 y 1993, para efectuar un análisis espacial de la pobreza en Colombia, y encuentra evidencia de dependencia espacial entre los municipios y departamentos de Colombia. Algo similar ocurre con Vargas (2011) quien utiliza información del Índice de Calidad de Vida (ICV) y Necesidades Básicas Insatisfechas (NBI) para el año 2005 e identifica factores de dependencia espacial en dichas medidas de pobreza, y para caracterizar el efecto espacial utiliza el análisis LISA (Local Indicators of Spatial Analysis). Pero en ningún caso se valida si esa dependencia espacial es espuria o no; y esa validación constituye un valor agregado esencial del presente artículo.
A diferencia de las investigaciones citadas referentes al análisis de econometría espacial, en este artículo el análisis se centra en los municipios del departamento de Antioquia, y se da un paso adicional, al presentar un algoritmo matemático, que permite verificar si la autocorrelación espacial encontrada es espuria o no. El algoritmo es aplicado para el análisis de la proporción de personas en situación de miseria en los municipios del departamento de Antioquia. Es importante aclarar que los estudios previos se quedan cortos en ese aspecto. La fuente de los datos para el indicador de proporción de personas en situación de miseria en cada municipio fue el censo de población llevado a cabo por el DANE sobre Necesidades Básicas Insatisfechas (NBI), por total, cabecera y resto, según municipio y nacional, a 30 de julio de 2010.
Según Agudelo-Torres (2010), la auto-correlación espacial espuria puede ser definida como el fenómeno en el cual existe una aparente dependencia espacial entre las regiones, pero que en realidad es producida por la consideración de lo que en la práctica es una sola región, como dos o más regiones independientes. Este fenómeno no ha recibido un tratamiento especial por parte de la comunidad científica. El fenómeno de auto-correlación espacial espuria es factible que se presente en aquellos espacios en los cuales se tenga una alta densidad de regiones y las cuales, en la práctica, no representan, cada una, a una región claramente diferenciada de las demás, sino que, por el contrario, la unión de algunas de ellas conforma en realidad una sola región.
Luego de esta introducción, este artículo está organizado como sigue: en la siguiente sección se describe la metodología de econometría espacial utilizada y el algoritmo para la detección de la potencial correlación espacial espuria. Luego, en la sección 2 se aplica esta metodología para el análisis de la proporción de personas en situación de miseria en los municipios del departamento de Antioquia, y al final se presentan las conclusiones.
1. METODOLOGÍA
1.1 Modelación con datos espaciales
La dependencia espacial es el fenómeno que se presenta cuando los valores observados de una variable en una región dependen de los valores observados de la misma variable en las regiones vecinas. Más adelante se expondrá una situación en la cual el valor tomado por una variable en una región no solo depende del valor de la misma variable en las regiones vecinas, sino también de los valores de otras variables en estas mismas regiones.
El proceso generador de datos del primer caso para dos regiones puede tomar la siguiente forma:
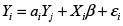
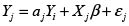
Con 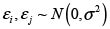 . Por simplicidad se asumen términos de error con media cero y varianza σ2.
. Por simplicidad se asumen términos de error con media cero y varianza σ2.
Para el caso de tres regiones sería entonces:
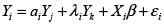
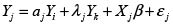
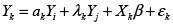
Con 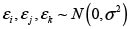
En esta situación ya se observa que este esquema no es práctico, pues supondría hallar estimaciones para un número de parámetros superior al número de observaciones disponibles.
Ord (1975) propuso una especificación diferente para modelar la dependencia espacial, la cual se caracteriza por incluir un solo parámetro que recoge la relación existente entre agregaciones de regiones vecinas y las propias regiones.
Para desarrollar esta especificación, Ord (1975) utilizó la primera Ley de la geografía formulada por Tobler (1979), la cual indica que todo tiene que ver con todo, pero las cosas cercanas están más relacionadas entre sí que las cosas lejanas. Ord (1975) materializó este principio mediante la inclusión en sus modelos econométricos de una matriz de retardos espaciales o matriz de contigüidades W, cuya forma y utilidad se exponen a continuación.
Matriz de contigüidades (W)
La matriz de contigüidades representa la materialización de la primera Ley de Tobler (1979) en términos de proximidad o lejanía. La matriz resultante es entonces del tipo binario, donde 1 representa la proximidad entre la región correspondiente a la fila y 0 el caso contrario, y la diagonal principal estará compuesta por ceros al no tener sentido el concepto de proximidad consigo mismo.
Al ser difícil la obtención de información más precisa que denote proximidad o lejanía entre un par de regiones, es común utilizar la vecindad como expresión de proximidad. Sin embargo, esta vecindad debe ser definida con mayor detalle para lograr una correcta especificación del modelo a utilizar.
Acevedo y Velásquez (2008) recopilan algunas de las formas para definir la presencia o ausencia de contigüidad. Algunas de ellas son:
• Contigüidad tipo torre: en esta definición de contigüidad se tienen en cuenta como vecinas regiones que tienen una frontera común con una longitud positiva.
• Contigüidad tipo alfil: en el esquema de contigüidad tipo alfil, se consideran vecinas las regiones con las cuales existe una frontera determinada solo por un punto.
• Contigüidad tipo reina: la contigüidad tipo reina se caracteriza por no dar relevancia al tamaño de la frontera entre las regiones; basta con que esta sea positiva o cercana a cero para que la región sea considerada contigua.
Matriz W como operador de retardo espacial
En contraste con los datos espaciales las series de tiempo tienen una característica fundamental y es su unidimensionalidad (el tiempo). Chasco (2003) establece tres características básicas que tienen los datos espaciales: la primera es su naturaleza georreferenciada, es decir, que su posición en el espacio contiene información valiosa para el investigador; la segunda característica es la multidireccionalidad de las relaciones que se establecen en el espacio; y la tercera es la multidimensionalidad, puesto que no nos movemos en una sola dimensión sino a través de un espacio geográfico compuesto por tantas dimensiones como regiones existan.
En este sentido, la matriz de contigüidades W es también conocida como matriz de retardos espaciales, pues se asemeja al operador de retardos utilizado en series temporales. En el contexto temporal, el operador de retardos provoca un desplazamiento en el eje del tiempo equivalente a la potencia j. De forma análoga, la matriz de contigüidades provoca desplazamientos en el espacio hacia el nivel de contigüidad asociado con la matriz.
Para ilustrar la naturaleza unidimensional de la serie de tiempo y multidireccional de la serie espacial y el efecto causado por los retardos temporales y espaciales pueden utilizarse los siguientes diagramas:
1) Efecto del operador de retardo en una serie temporal:
Este operador de retardo al ser aplicado a una variable, la desplaza en la dimensión temporal tantos períodos como lo indique su potencia.
2) Efecto del operador de retardo en una serie espacial:

El operador de retardo espacial desplaza y agrega las masas de las regiones contiguas a la región analizada.
Este resultado crea un problema de interpretación con la dimensión de la variable resultado. Si se desea preservar la dimensión, basta con imponer la condición de que la suma de los elementos de cada fila sea 1. Se puede entonces tomar cada fila de W y dividir cada componente entre la suma de todas las componentes de la fila respectiva; este proceso genera la matriz de contactos estandarizada y supone, no la agregación de masas en el espacio, sino hallar el promedio de estas.

Detección de efectos espaciales
I de Moran
Para la detección de efectos espaciales es usual utilizar la I de Moran, la cual se define como:
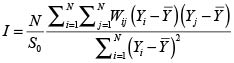
Donde:
Wij: elemento correspondiente a la posición (i,j) de la matriz de contigüidades.
S0: suma de los pesos espaciales. 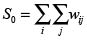 .
.
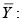 valor esperado de la variable Y.
valor esperado de la variable Y.
N: número de regiones.
Cuando se utiliza la matriz de contigüidades estandarizada, la especificación de la I de Moran se convierte en:
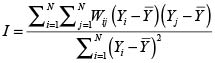
Pues la suma de los elementos de cada fila dará como resultado la unidad, por tanto, el resultado de 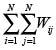 será N.
será N.
La I de Moran se basa en el coeficiente de autocorrelación temporal ρ(τ), donde se tiene que 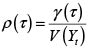 ; donde γ(τ) es la función de autocovarianza evaluada en el rezago temporal τ de la variable Yt. La I de Moran utiliza de forma similar este concepto, pero ponderando las autocovarianzas espaciales por el término correspondiente en la matriz de contigüidades estandarizada, para luego dividir el resultado por la varianza de Y.
; donde γ(τ) es la función de autocovarianza evaluada en el rezago temporal τ de la variable Yt. La I de Moran utiliza de forma similar este concepto, pero ponderando las autocovarianzas espaciales por el término correspondiente en la matriz de contigüidades estandarizada, para luego dividir el resultado por la varianza de Y.
La interpretación de los valores estadísticamente significativos de la I de Moran tipificada sería la siguiente:
1) Valores no significativos del test I estandarizado conducirán a aceptar la hipótesis nula de no autocorrelación espacial.
2) Valores significativos del test I estandarizado y mayores que cero son indicativos de autocorrelación espacial positiva.
3) Valores significativos del test I estandarizado y menores que cero son indicativos de autocorrelación espacial negativa.
Con la colección de valores del estadístico I puede construirse el correlograma espacial.
Para comprobar la presencia de dependencia espacial en una población a través de la I de Moran, se valida la significancia del parámetro ρ en un modelo SAR(1), el cual será analizado más adelante.
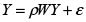
Las hipótesis planteadas son:
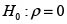
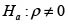
Y el estadístico de prueba es: 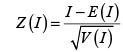
Dependencia espacial en un modelo de regresión
Para determinar el modelo a utilizar debe analizarse el tipo de dependencia espacial existente en los datos. En caso de omitir por error un retardo espacial en la variable endógena y/o en las exógenas, la dependencia espacial se trasladará de manera directa al término de perturbación, el cual pasaría a estar correlacionado espacialmente. En este caso la auto-correlación resultante es llamada auto-correlación espacial sustantiva y su solución es incluir en el modelo un retardo espacial de la variable sistemática correlacionada espacialmente.
Cuando la dependencia espacial en los residuos no es ocasionada por una omisión errónea del retardo en las variables endógena y/o exógena se considera que existe auto-correlación espacial residual.
1.2 Modelo auto-regresivo de regresión espacial de orden 1, SAR(1)
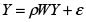
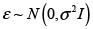
Es la especificación de dependencia espacial más sencilla y hace referencia a una situación en la cual los valores que adopta una variable están determinados por la localización geográfica de la misma. Esta especificación es determinante para desarrollar el algoritmo de agregación espacial presentado en este artículo y para hacer inferencia sobre el porcentaje de personas en situación de miseria en el departamento de Antioquia.
Auto-correlación espacial espuria
Uno de los aspectos relevantes en la econometría de series de tiempo está relacionado con las regresiones espurias, fenómeno que se puede originar cuando se consideran regresiones entre series de tiempo no estacionarias, y cuyo procedimiento formal ha sido desarrollado y divulgado ampliamente.
La auto-correlación espacial espuria puede ser definida como el fenómeno en el cual existe una aparente dependencia espacial entre las regiones, pero que en realidad es producida por la consideración de lo que en la práctica es una sola región como dos o más regiones independientes. Este fenómeno no ha recibido un tratamiento especial por parte de la comunidad científica.
El fenómeno de auto-correlación espacial espuria es factible que se presente en aquellos espacios en los cuales se tenga una alta densidad de regiones y las cuales, en la práctica, no representan cada una a una región que se diferencie en forma clara de las demás, sino que, por el contrario, la unión de algunas de ellas conforman en realidad una sola región.
Para ilustrar el problema bajo consideración, se construyó un espacio dividido en dos regiones con procesos generadores de datos muy diferentes: Yi1 con
i = 1,2,3,7,8,9,13,14,15, y Y12 con i = 4,5,6,10,11,12,16,17,18
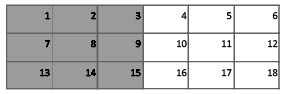
El hecho de tener 9 regiones representando las mismas características hace que los test, desde los más complejos hasta el más sencillo, indiquen la presencia de dependencia espacial, aunque, en la práctica, la auto-correlación espacial sea espuria al no depender el comportamiento de una región de sus vecinas, sino al ser ella y sus vecinas, en realidad, una sola región con un mismo proceso generador de datos.
Para detectar y corregir la presencia de auto-correlación espacial espuria se desarrolló un algoritmo que permite identificar la mejor forma de realizar un número de agregaciones dado, con el fin de atacar la hipótesis alternativa de presencia de este fenómeno. En este contexto el término agregación significa la suma de dos o más valores de la variable aleatoria objeto de estudio.
Como se planteó, el algoritmo que se propone surge de la especificación del modelo :
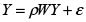
Cuya prueba de hipótesis para el parámetro ρ es:
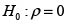

Al ser el parámetro ρ la pendiente de la recta, puede inferirse que indicará la ausencia de dependencia espacial. Este principio se utilizará como la medida de efectividad de la agregación, pues el objetivo de descartar la dependencia espacial se traduce en reducir tanto como sea posible la pendiente de la recta.
La agregación espacial debe contar con dos reglas básicas:
1) Las regiones a agregar deben ser contiguas: esta restricción se impone, pues no tiene sentido plantear que las regiones a agregar pertenezcan, en la práctica, a una sola región, mientras estas estén separadas por dos o más fronteras.
2) Deben tener la misma medida de posición: las regiones a agregar deben pertenecer al mismo cuartil, decil u otra medida de posición. Esta restricción permite que se conserve al máximo la información de la población y por consiguiente la verdadera dependencia espacial que pueda llegar a existir, pues impide la agregación de regiones con características muy diferentes.
1.3 Desarrollo teórico del algoritmo
El proceso de detectar y eliminar la posible auto-correlación espacial espuria implica agregar una cantidad dada de regiones, con las restricciones asociadas, tal que la pendiente de la recta definida por Y = ρWY sea lo más cercana a cero posible pero rotando la recta de regresión en sentido dextrógiro; esto para lograr que el algoritmo ataque con más fuerza la hipótesis alternativa de 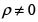 al requerir menos esfuerzo para llevar la pendiente de la recta a un valor cercano a cero.
al requerir menos esfuerzo para llevar la pendiente de la recta a un valor cercano a cero.
Ya se ha establecido el efecto que produce en la variable endógena el operador de retardo espacial. Este efecto es importante porque permite inferir las características que deberán tener las regiones a agregar en cuanto a la calidad de la agregación espacial. Una disminución en la pendiente de la recta se dará con una mayor probabilidad de ocurrencia cuando los vecinos agregados espacialmente sean tan diferentes que produzcan un valor de la variable retardada cercano a cero.
El nuevo punto en el scatter plot producido por la agregación espacial será entonces
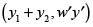 , con
, con  .
.
Donde wiyi es el retardo espacial de la región yi. El punto w'y' se define de esta forma pues luego de realizar la agregación espacial de las regiones vecinas w1y1 + w2y2 debe restarse las propias regiones y1 y y2 pues son vecinas entre sí.
Las regiones que al momento de agregarse espacialmente producirán puntos más cercanos al eje de las abscisas serán aquellas que teniendo la misma medida de posición estén rodeadas de regiones tan diferentes entre sí, que produzcan un valor cercano a cero en la suma de sus retardos espaciales, es decir que w1y1 + w2y2 --> 01.
De lo anterior es lógico suponer que las regiones a agregar se ubicarán en las fronteras de las pseudo-regiones que agrupan regiones contiguas con la misma medida de posición, pero que cuentan con un grupo de regiones tan diferentes de ellas como sea posible, al otro lado de la frontera.
Para ilustrar el proceso de construcción se consideran 100 regiones y se dividieron en deciles. Las regiones que se analizarán en este ejemplo serán entonces las que se encuentran a lado y lado de la frontera que separa los deciles 1 y 10, ya que no existen regiones contiguas con una mayor diferencia en sus medidas de posición, lo que indica que el retardo espacial de las regiones agregadas sería lo más cercano a cero que se podría encontrar en este espacio con subdivisiones del mismo por deciles.
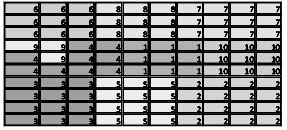
El primer paso del algoritmo será entonces hallar las regiones a analizar, es decir determinar cuáles regiones se encuentran a lado y lado de una frontera que divida dos grupos de regiones tan diferentes entre sí como sea posible.
Para determinar cuáles regiones pertenecen a las grandes regiones a analizar se toma la matriz de contigüidades W, y se remplazan los unos (1) por la expresión 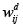 , como se especifica enseguida; esta conversión dará lugar a una matriz de diferencias Wd. En adelante, por facilidad en la exposición del algoritmo, se asumirá como medida de posición el decil y se denotará como d(.).
, como se especifica enseguida; esta conversión dará lugar a una matriz de diferencias Wd. En adelante, por facilidad en la exposición del algoritmo, se asumirá como medida de posición el decil y se denotará como d(.).
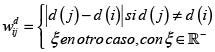
ξ deberá ser cualquier número real negativo, pues de lo contrario podría confundirse en la siguiente fase del algoritmo con los generados por |d(j)–d(i) cuando 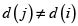
Esta expresión 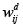 garantizará la identificación de los vecinos con la máxima diferencia entre sus deciles sin perder la funcionalidad como matriz de contigüidades, pues las entradas iguales a cero (0) continuarán representando regiones sin frontera común.
garantizará la identificación de los vecinos con la máxima diferencia entre sus deciles sin perder la funcionalidad como matriz de contigüidades, pues las entradas iguales a cero (0) continuarán representando regiones sin frontera común.
La máxima diferencia entre deciles será entonces:

Y las grandes regiones a analizar serán las correspondientes a las filas (o columnas, por simetría de esta matriz) que tengan por lo menos una entrada igual a Md y sus respectivos vecinos.
Por ejemplo, una matriz

dará como resultado una diferencia máxima entre deciles de Md = 9.
Por lo que las grandes regiones a analizar serán las representadas por las filas que contengan por lo menos una entrada igual a 9; es decir, las regiones {1,2,4,8} serán consideradas como regiones con diferencia máxima y {1,2,3,4,6,7,8,9} como vecinas de estas regiones de acuerdo con la forma de construcción de la matriz de contigüidades.
El análisis se centrará entonces en determinar el valor del retardo espacial de las nuevas regiones, las cuales serán todas las combinaciones de pares de regiones que se puedan producir entre las regiones a analizar.
Como se planteó, este retardo espacial estará determinado por la siguiente expresión:
w'y' = w1y1 + w2y2 – y1 - y2 donde wiyi es el retardo espacial de la región yi. Los valores de los retardos espaciales y los correspondientes a las regiones pueden ser obtenidos de los vectores WY y Y respectivamente, por lo que se puede construir una matriz cuadrada compuesta por los retardos espaciales de las nuevas regiones, conformadas a partir de la agregación de dos regiones originales: la correspondiente a la fila y la correspondiente a la columna.
Se puede entonces conformar una matriz de contigüidades especial (Wε) que incluya, solo para las regiones a analizar, el valor del retardo espacial para cada par de regiones (fila-columna) bajo el supuesto de ser agregadas.
Cada uno de estos puntos se graficaron en un scatter plot que incluye el nuevo punto, producto de la agregación de dos regiones, y los puntos correspondientes a las regiones no agregadas. Este nuevo punto es el que produce una modificación en la pendiente de la recta de regresión y para escoger el mejor par de puntos a agregar se deben analizar cuál es el que produce el mayor efecto sobre esta.
Un indicador que puede establecerse como regla de decisión es el valor absoluto de la diferencia entre la componente vertical del punto agregado y el valor de la variable endógena WY, es decir, 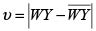 , obtenida reemplazando en la ecuación de la recta la variable exógena Y por el valor de la componente horizontal del punto agregado. Sin embargo, esta medida no tiene en cuenta otra variable a considerar y es la cercanía o lejanía del punto con respecto al eje de las ordenadas; tener en cuenta estos dos aspectos se traduce en un impacto fuerte sobre la pendiente de la recta de regresión.
, obtenida reemplazando en la ecuación de la recta la variable exógena Y por el valor de la componente horizontal del punto agregado. Sin embargo, esta medida no tiene en cuenta otra variable a considerar y es la cercanía o lejanía del punto con respecto al eje de las ordenadas; tener en cuenta estos dos aspectos se traduce en un impacto fuerte sobre la pendiente de la recta de regresión.
En la gráfica 1 se observa cómo la mayor distancia del punto A a la recta de regresión original no implica una mayor reducción en la pendiente de esta, pues el punto B contando con una menor distancia la impacta con mayor fuerza al estar su componente horizontal más cerca del origen.

Esta deducción nos lleva a otro indicador que será adoptado como regla de decisión:
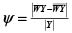
Ψ relaciona la distancia vertical del punto agregado y la recta de regresión original con la componente horizontal del primero, para producir una medida de distancia relativa que penalizará la lejanía del nuevo punto con respecto al eje de las ordenadas. Así, entre más lejano, más distancia vertical necesitará el punto para establecerse como agregación óptima.
2. RESULTADOS
Para validar la existencia de dependencia espacial en la variable porcentaje de personas en situación de miseria en los municipios del departamento de Antioquia se obtuvieron las observaciones para cada municipio utilizando como fuente el DANE.
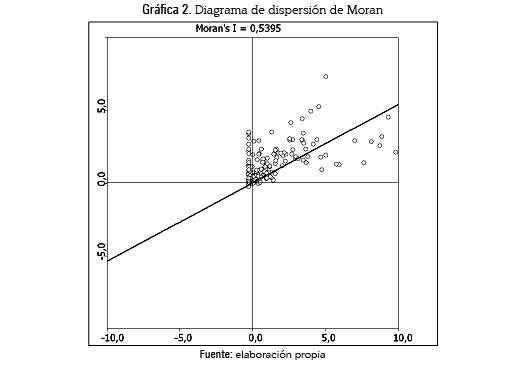
Luego se construyó la matriz de contigüidades utilizando contigüidad tipo reina y se estandarizó mediante el método explicado. Con base en estos dos insumos (vector de datos observados y matriz de contigüidades) se verificó la existencia de dependencia espacial, descartando el carácter espurio de la misma. Para el análisis, primero se obtuvo el diagrama de dispersión de Moran presentado en la gráfica 2.
Resultados del algoritmo
Como se especificó, la prueba de hipótesis con la cual se validará la existencia de dependencia espacial es la siguiente:

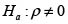
Con un nivel de confianza de 0,05, el valor-p resultante, como se evidencia en la gráfica 3, indica que la hipótesis nula debe ser rechazada; por lo tanto, la pendiente de la recta Y = ρWY + ε es significativa, indicando evidencia de dependencia espacial.
Para verificar si la dependencia espacial encontrada es real o espuria, se utilizó el algoritmo desarrollado en este artículo con los siguientes resultados:
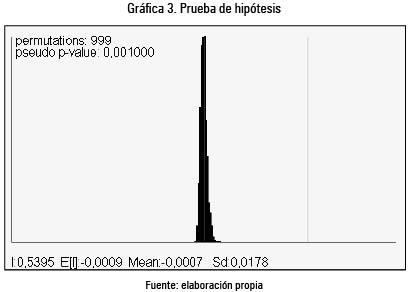
A partir de la división política del departamento de Antioquia se construyó la gráfica 4 que relaciona el porcentaje de miseria en cada municipio (Y) frente a la agregación espacial de sus vecinos inmediatos (WY) y se trazó la línea de regresión que mejor se ajusta a dichas observaciones.

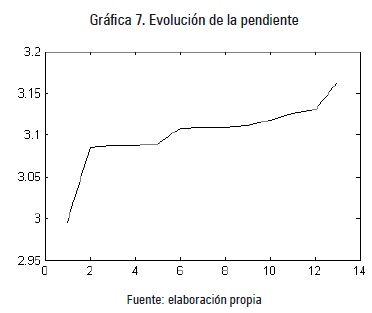
Luego de realizar 13 agregaciones espaciales (alrededor del 10 % de la muestra) la gráfica 4 se transformó hasta quedar como muestra la gráfica 5. Posteriormente la gráfica 6 presenta Situación inicial frente a gráfica, luego de 13 agregaciones espaciales.
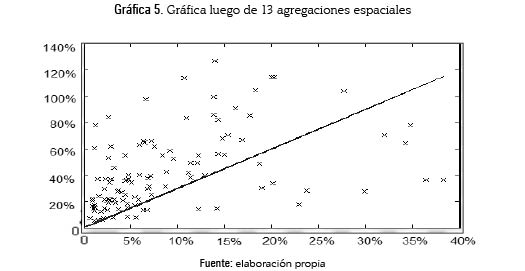
Como puede observarse la pendiente aumenta, lo que comprueba que la dependencia espacial es real. En caso contrario las regiones agregadas deberían mantenerse de esa forma y realizar nuevamente el test de Moran.
La gráfica 7 muestra la evolución de dicha pendiente a medida que se realizan las agregaciones espaciales.
3. CONCLUSIONES
Antes de los trabajos de Paelinck y Klaassen (1979) la inclusión de efectos espaciales se realizaba a través de índices que se incorporaban en los modelos econométricos tradicionales; a partir de esos estudios la econometría espacial ha tenido un lento desarrollo con respecto a la econometría financiera o de series de tiempo, aunque autores como Anselin (2003), Florax y Folmer (1992), Ord (1975) entre otros, y en las últimas décadas otros investigadores como Chasco (2003) y LeSage y Pace (2009), han profundizado en el análisis espacial y la ciencia regional. Sus valiosas contribuciones constituyen una herramienta de modelación de efectos espaciales, confiable y robusta, lo que permite a muchos investigadores alrededor del mundo, explicar con mayor precisión, el comportamiento de variables vinculadas al espacio.
Intentar modelar un efecto espacial inexistente, es decir, donde se presente auto-correlación espacial espuria puede llevar al investigador a conclusiones erradas y a tomar decisiones incorrectas. En este artículo se presenta un algoritmo que permite detectar la presencia potencial de ese tipo de auto-correlación, y su corrección, en caso de ser necesario. La aplicación de este algoritmo podría permitir el desarrollo de un test de auto-correlación espacial espuria, que pueda ser utilizado, como paso inicial, en procesos de modelación espacial.
En este artículo se verificó, a través del algoritmo para detectar auto-correlación espacial espuria presentado por Agudelo-Torres (2010), que la econometría espacial debe ser tenida en cuenta al modelar el porcentaje de personas que viven en situación de miseria en los municipios del departamento de Antioquia (Colombia). Omitir la inclusión de variables rezagadas espacialmente puede entorpecer la asignación óptima del gasto social, destinado a la reducción de dicha variable.
NOTAS:
* Artículo de investigación financiado por la Dirección de Investigaciones del Instituto Tecnológico Metropolitano y Prospección Legal S. A. S. Grupo de Investigación Ciencias Administrativas, Clasificación B Colciencias. Es uno de los productos del proyecto ''Modelo Markoviano Integral para la estimación y simulación del seguro previsional en Colombia'' ejecutado durante el período 2014-2016.
1 El término w'y' podría tender a cero con una mayor intensidad al escoger regiones cuyos valores individuales sean los suficientemente diferentes como para producir un valor cercano a cero; sin embargo, escoger este tipo de regiones violaría la segunda regla básica de agregación, eliminando no solo la dependencia espacial espuria, sino también la real.
BIBLIOGRAFÍA
Acevedo Bohórquez, I. y Velásquez Ceballos, H. (2008). Algunos conceptos de la econometría espacial y el análisis exploratorio de datos espaciales. En Ecos de Economía. Vol. 12, N.° 27, pp. 9-34. [ Links ]
Agudelo-Torres, G. (2010). Dependencia espacial: detección, validación y modelación. Medellín: Universidad EAFIT. [ Links ]
Anselin, L. (1980). Estimation methods for spatial autoregressive structures. En Regional Science Dissertation & Monograph Series, Program in Urban and Regional Studies, Cornell University, 273p. [ Links ]
Anselin, L. (1988). Spatial econometrics: methods and models. Springer: Science & Business Media, 284p. [ Links ]
Anselin, L. (2003). Spatial externalities, spatial multipliers and spatial econometrics. En International Regional Science Review. April, Vol. 26, No. 2, pp. 153-166. [ Links ]
Arbia, G. y Blagati, B. (2009). Spatial Econometrics: methods and applications: Studies in Empirical Economics. Collection Studies in Empirical Economics, Physica-Springer, 281p. [ Links ]
Azariadis, C. (2006). The Theory of Poverty Traps: What Have We Learned? Chapter 1. En: Bowles, S.; durlauf, S. y Hoff, K. (2006). Poverty Traps. New York: Princeton University Press. [ Links ]
Bayudam, C. y Lim, J. (2013). Chronic and Transient Poverty and Vulnerability to Poverty in the Philippines: Evidence Using a Simple Spells Approach. En: Social Indicators Research. Vol. 118, N.° 1, pp. 389-413. [ Links ]
Beenstock, M.; Feldman, D. y Felsenstein, D. (2012). Testing for unit roots and cointegration in spatial cross section data. En: Spatial Economic Analysis. Vol. 7, N.° 2, pp. 203-222. [ Links ]
Chasco, C. (2003). Econometría espacial aplicada a la predicción-extrapolación de datos espaciales. Universidad Autónoma de Madrid, Madrid, Consejería de Economía, Empleo y Hacienda - D. G. de Economía y Política Financiera, 339p. [ Links ]
Cotte, A. y Pardo, C. (2011). Las tendencias de la pobreza y la desigualdad: una evidencia para los departamentos de Colombia. En: Ensayos Revista de Economía. Vol. XXX, N.° 2, pp. 29-50. [ Links ]
De la Fuente, H. y Cartagena, J (2007). Caracterización de los hogares bajo la línea de pobreza en un contexto regional: Un análisis econométrico para la Séptima Región del Maule, Política Criminal: Revista Electrónica Semestral de Políticas Públicas en Materias Penales, Chile. N° 4, p. 1-20. [ Links ]
Fingleton, B. (1999). Spurious spatial regression: some Monte Carlo results with a spatial unit root and spatial cointegration. En: Journal of Regional Science, Vol. 39, No 1, pp. 1-19. [ Links ]
Florax, R. y H. Folmer (1992). Specification and estimation of spatial linear regression models: Monte Carlo evaluation of pre-test estimators. En: Regional Science and Urban Economics, Vol. 22; pp. 405-32. [ Links ]
Galvis, L. y Meisel, A (2010). Persistencia de las desigualdades regionales en Colombia: Un análisis espacial. En: Revista ESPE, N.° 120, pp. 1-35. [ Links ]
Galvis, L. y Meisel, A (2012). Convergencia y trampas espaciales de pobreza en Colombia: Evidencia Reciente. En: Documentos de Trabajo sobre Economía Regional. N.° 177, pp. 1-26. [ Links ]
Geary, R. (1954). The Contiguity Ratio and Statistical Mapping. En: Journal of the Royal Statistical Society, Vol. N° 5, p. 115-145. [ Links ]
Grootaert, C. y Kanbur, R. (1995). The Dynamics of Poverty: Why some People Escape from Poverty and others Don't: An African Case Study. En: The World Bank, Environment Department Social Policy and Resettlment Department, Policy Research Working Paper. 32p. [ Links ]
Herrera, J. (1999). Ajuste económico, desigualdad y movilidad. En: Developpement et insertion internaionale, Document de Travail, París. [ Links ]
Kaztman, R. (2003). La dimensión espacial en las políticas de superación de la pobreza urbana. En: CEPAL, Medio Ambiente y Desarrollo. Vol. 59, pp. 1-48. [ Links ]
Lauridsen, J. y Kosfeld, R. (2006). A test strategy for spurious spatial regression, spatial nonstationarity, and spatial cointegration. Papers in Regional Science. Vol. 85, N.° 3. [ Links ]
Le Sage, J. y Pace, R. (2009). Introduction to spatial econometrics. En: CRC Press Inc. [ Links ]
López, R y Della Maggiora, C. (2000). Rural poverty in Peru: stylized facts and analytics for policy. [ Links ]
Moran, P (1948). The interpretation of statistical maps. En: Journal of the Royal Statistical Society, N.° 10, pp. 243-251. [ Links ]
Moreno, R. y Vayá, E. (2000). Técnicas econométricas para el tratamiento de datos espaciales: La Econometría Espacial. Edicions Universitat de Barcelona, N.° 44. [ Links ]
Nisar, R.; Anwar, S.; Hussain, Z. y Akram, W (2013). An Investigation of Poverty, Income Inequality and Their Shifters at Household Level in Pakistan. En: Journal of Finance and Economics 1, N.° 4, pp. 90-94. [ Links ]
Ord, J. (1975). Estimation methods for models of spatial interaction. Journal of the American Statical Association, N.° 70, pp. 120-126. [ Links ]
Osowole, O.; Nwoke, F. y Uba, E. (2012). On the Level of Performance of Selected Link Functions in the Identification of Poverty Correlates in Nigeria. En: West African Journal of Industrial and Academic Research Vol. 5, N.° 1. [ Links ]
Paelinck, J. y Klaassen, L. (1979). Spatial Econometrics. Saxon House Farnborough. [ Links ]
Pérez, Gerson. (2005). Dimensión espacial de la pobreza en Colombia. En: Revista ESPE, N.° 48, pp. 234-293. [ Links ]
Rodríguez-Castillo, D. (2010). Modelar la concentración de la tierra en Colombia mediante modelos econométricos espaciales. Bogotá: Universidad Nacional de Colombia. [ Links ]
Slon, P. y Zúñiga, E. (2006). Dinámica de la pobreza en Costa Rica: datos de panel a partir de cortes transversales. En: Revista de la CEPAL, N.° 89. [ Links ]
Tobler, W. (1979), Cellular Geography. Philosophy in Geography, ed. S. Gale y G. Olsson, Dordrecht: Reidel; pp. 379 - 86. [ Links ]
Vargas, O. (2011), Aproximación al estudio de la pobreza en Colombia: Un estudio aplicado con información del año 2005. Cali: Universidad del Valle. Facultad de Ciencias Sociales y Económicas. [ Links ]
Wodon, Q. y Cruces, G. (2003). Transient and chronic poverty in turbulent times: Argentina 1995-2002. En: Economic Bulletin. STICERD? London School of Economics and Political Science, The World Bank. [ Links ]
