











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroducción
Existen muchos estudios e investigaciones sobre el desarrollo de la ortografía de niños monolingües, tanto de español como inglés, y de niños bilingües, pero no hay muchos estudios sobre el desarrollo de la ortografía en adultos (Greenberg, Ehri & Perin, 2002). En el ámbito social, la reciprocidad entre buena ortografía y buena educación constituye un marcador social (Parker, 1991). Esta habilidad ortográfica goza de la admiración del público, pues quien escribe sin faltas ortográficas se percibe con connotaciones de persona alfabetizada, inteligente y estudiosa, mientras que una persona que no domina la ortografía es vista como no muy inteligente (Gerber & Hall, 1987, p. 34). Esta actitud aún persiste, a pesar de que los estudios empíricos demuestran que no existe una correlación entre coeficiente intelectual y habilidad ortográfica (Balajthy, 1986). Entonces se podría argumentar que la ortografía se revela como un mecanismo de poder sutil que permea discriminación social.
El sistema ortográfico español es relativamente transparente en lectura, en comparación con el inglés, en el sentido de que las reglas de correspondencia grafema-fonema permiten determinar sin ambigüedad alguna el fonema que corresponde a cada grafema concreto; es decir, se rige por un conjunto de reglas consistentes (Defior, Martos & Cary, 2002). Sin embargo, en la escritura existe un cierto grado de imprevisibilidad en cuanto al grafema que se debe utilizar en algunas palabras, ya que algunos fonemas pueden representarse por dos o más grafemas (Cuetos, 1993). De acuerdo con las investigaciones de Carbonell de Grompone, Tuana, Piedra de Moratorio, Lluch de Pintos y Corbo de Mandracho (1980), existen tres fases en el desarrollo de la ortografía en los hablantes nativos del español. La primera etapa está caracterizada por el dominio de las relaciones de orden de correspondencia biunívoca de fonema-grafema; por ejemplo, las vocales a, e, o, u; excepto por la <i>, que tiene otro grafema <y>. La segunda fase involucra fonemas controlados por reglas cuya escritura varía dependiendo del contexto en el que aparece el grafema, tales como <r> <rr>. La última fase incluye el deletreo de fonemas que tienen más de una representación, pero cuya correspondencia no está sujeta a reglas contextuales, como <b> y <v>, entre otros.
Es importante tener en cuenta que el desarrollo de las habilidades de alfabetización de una lengua no se correlaciona necesariamente con la proficiencia en la otra lengua y obedecen a las limitaciones de alfabetización en esa lengua (Defior, Martos & Herrera, 2000). Por eso, en situaciones de contacto lingüístico la ortografía de una lengua parece permearse en la otra a través de reglas que se generalizan o se transfieren de una lengua a la otra. Sin embargo, sería acertado decir que no todas las producciones no canónicas obedecen a este fenómeno, sino que se deben a la carencia de alfabetización en la otra lengua. Muchas investigaciones señalan que los factores lingüísticos juegan un papel importante en el desarrollo temprano de lectura de palabras y el desarrollo ortográfico. Uno de estos factores es la conciencia fonológica (Bird, Bishop & Freeman, 1995; Ehri et al., 2001; Goswami & Bryant et al, 1990), la cual se puede definir como la conciencia de los sonidos de una lengua (Appel, 2009), que se va desarrollando progresivamente durante los primeros años de vida y le permite a los niños manipular las unidades del lenguaje hablado para posteriormente decodificarlos en el proceso de lectura y escritura. Según Mousty, Leybaert, Alegria, Content y Morais (1994), la conciencia fonológica facilita la instauración del conocimiento léxico y viceversa y, por lo tanto, la naturaleza del deletreo escrito se ajustaría a este modelo. Así, el dominio de la escritura implicaría competencias de tipo fonológico para la aplicación de las reglas de correspondencia fonema-grafema (RCFG) que son imprescindibles en el caso de las palabras no familiares o pseudopalabras1.
Algunas de las razones por las cuales muchos estudiantes de herencia2 hispana (HH) buscan cursos de español en el nivel universitario son mejorar tanto su comprensión de lectura como de escritura y poder competir en campos tanto laborales como académicos (Colombi, 2009), lo cual les permite lanzarse al mercado profesional en el que su bilingüismo los hace atractivos. Para ello es necesario dominar la ortografía. No obstante, esta tarea resulta un reto para el instructor debido a que aunque se incluyen materiales con referencia a este tema, estas actividades resultan ser aburridoras y abrumadoras para los estudiantes. Las metodologías tradicionales sugieren ejercicios repetitivos y tediosos (Beaudrie, 2012) que resultan ser frustrantes y poco motivadores para los estudiantes. La poca investigación en el área se traduce en la ausencia de instrucción adecuada para estos estudiantes, quienes no han sido expuestos lo suficientemente a la lengua, especialmente en la etapa en la que se adquiere y desarrolla la ortografía, porque han sido expuestos con mayor énfasis, o totalmente, a la otra lengua, el inglés.
El trabajo pionero de Beaudrie (2012) representa una guía para los investigadores, al igual que las recomendaciones de Llombart-Huesca (2018), quien sugiere analizar el problema desde una perspectiva lingüística cognitiva.
El presente proyecto está basado en el estudio que Beaudrie (2012) hizo con estudiantes de HH, el cual ofrece un análisis cuantitativo de un total de 21.322 palabras y 2492 errores ortográficos que detallan los patrones observados con el fin de que guíen a una intervención pedagógica específicamente diseñada para los estudiantes de herencia. Es importante replicar este estudio para confirmar el patrón que opera en la producción de errores ortográficos y así, desde una perspectiva más específica, facilitar el diseño de soluciones que optimicen el aprendizaje de la ortografía en los estudiantes de HH.
El propósito de este trabajo es identificar los errores ortográficos más comunes (frecuencia) y su tipología en 40 ensayos, clasificados en cuatro grupos de estudiantes. Las preguntas de investigación de este estudio son:
¿En qué niveles producen los estudiantes un mayor número de errores ortográficos en ensayos de escritura controlada?
¿Cuál es la tipología de errores más frecuente?
Se predice que se encontrarán menos produccciones canónicas en los niveles básicos e intermedios que en los avanzados y altos.
Metodología
El corpus analizado en este proyecto hace parte de un banco de datos de 505 composiciones que produjeron los estudiantes para ingresar a los cursos de HH en una universidad urbana en Estados Unidos durante el año 2010. Los cursos de herencia que esta universidad ofrece se dividen en cuatro niveles: básico, intermedio, avanzado y alto. Los estudiantes que han terminado estos niveles pueden inscribirse a niveles altos donde se estudian temas de lingüística, cultura y literatura de la lengua española. Se escogieron 40 ensayos, al azar, 10 por cada nivel.
Los participantes en este proyecto son los estudiantes que escribieron el ensayo como parte del proceso de aceptación al programa de herencia en esta universidad. Fueron estudiantes cuyas edades fluctuaban entre los 18 y los 28 años de edad. Las dos terceras partes de esta población eran mujeres. Algunos de estos estudiantes nacieron en los Estados Unidos y otros provenían de países de habla hispana, que llegaron a una edad temprana (antes de los cinco años). Tras leer un texto titulado "La privacidad y el internet", ellos debían componer un ensayo con un mínimo de 250 palabras, en el que daban su punto de vista y estipulaban si estaban de acuerdo o no con el autor. Se les daban treinta minutos para terminar la composición.
A diferencia del estudio de Beaudrie (2012), no se incluyeron los acentos otográficos (tildes), debido a que este tema hizo parte de otro proyecto de investigación. Se codificaron los errores ortográficos teniendo en cuenta siete categorías: 1) adición (se añade un grafema a la palabra), 2) sustitución (se intercambia un grafema por otro), 3) omisión (se suprime un grafema que pertenece a la palabra), 4) inversión (se altera el orden de las palabras), 5) fragmentación-contracción de palabras (se unen dos palabras o se fragmenta una palabra de una forma no estándar), 6) transferencia (se combinan elementos tanto del inglés como del español). Se agregó una categoría, a modo exploratorio: 7) creación léxica (se crean nuevos términos), ya que se presentó como un contínuo a lo largo de los cuatro niveles.
Con el fin de delimitar los errores visualmente, se utilizaron diferentes colores para detectar cada una de las categorías y así poder aislarlas y tipificarlas. Se clasificaron las palabras de acuerdo con su relación en cuanto a: 1) una relación de grafema-fonema compleja consistente (Tabla 2); 2) una relación compleja inconsistente entre fonema-grafema (Tabla 3); 3) una relación simple entre grafema-fonema vocal-consonante. En esta clasificación se insertó el diptongo, ya que cuando hay contacto vocálico de dos elementos parece afectar la percepción (Tabla 5); 4) errores de contracción-fragmentación de palabras, transferencia y creaciones léxicas (Tabla 6).
Tabla 1 Resultados generales
| Total de palabras | Total de errores | Errores complejos consistentes | Errores complejos inconsistentes | Errores simples | Errores de fragmentación-contracción de palabra | Errores de transferencia | Creación léxica | Errores misceláneos |
|---|---|---|---|---|---|---|---|---|
| 10.574 | 497 | 29 | 165 | 215 | 18 | 31 | 9 | 30 |
| 100 % | 4.7°% | 5.8°% | 33. 2°% | 43.3°% | 3.6% | 6.2% | 1.8% | 6.0 |
Tabla 2 Errores cuya relación grafema-fonema es compleja consistente
| Relaciones consistentes contextuales | Nivel básico | Nivel intermedio | Nivel avanzado | Nivel alto | Total |
|---|---|---|---|---|---|
| "au" | 12 (43%) | 11 (39%) | 5 (18%) | 0 | 28 |
| agu" | 1 x7(100%) | 0 | 0 | 0 | 1 |
Tabla 3 Errores cuya relación grafema-fonema es compleja inconsistente
| /s/ | <h> | /b/ | /g/ [x] | /j/[x] | AV /i/ | |
|---|---|---|---|---|---|---|
| Sustitución | 54 (32.7%) | 0% | 14 (8.5%) | 49 (29.7)% | 8 (4.8%) | 5 (3.0%) |
| Omisión | 2(1.2%) | 15 (9.1%) | 1 (0.6%) | 0 | 0 | 1(0.6%) |
| Adición | 8 (4.8) | 7 (4.2%) | 0 | 0 | 0 | 1 (0.6%) |
| Inversión | 0 | 0% | 0 | 0 | 0 | 0 |
| Total (n= 165) | 64 | 22 | 15 | 49 | 8 | 7 |
Tabla 4 Porcentajes de grafema-fonema cuya regla es inconsistente
| Nivel | Básico | Intermedio | Avanzado | Alto | Total |
|---|---|---|---|---|---|
| Sustitución | 60(36.4%) | 36(27.7%) | 22(13.3%) | 12(7.3%) | 130(78.8%) |
| Omisión | 8 (4.8%) | 5 (3%) | 3 (1.8%) | 3 (1.8%) | 19(11.5%) |
| Adición | 5(3%) | 3(1.8%) | 3 (1.8%) | 5 (13%) | 16(9.7%) |
| Inversión | 0 | 0 | 0 | 0 | 0 |
| Total | 73 (44.2%) | 44 (26.7%) | 28 (17.0%) | 20 (12.1%) | 165 (100%) |
Tabla 5 Palabras con relación simple (error vocales-vocales y entre consonante-vocal)
| Básico | Intermedio | Avanzado | Alto | Total | |
|---|---|---|---|---|---|
| Sustitución | 71 (51%) | 14 (31%) | 8 (31%) | 4 (31%) | 97 (45%) |
| Omisión | 21 (15%) | 8 (18%) | 6 (29%) | 3 (23%) | 38 (18%) |
| Adición | 12 (9%) | 9 (20%) | 0 | 2 (15%) | 20 (9%) |
| Inversión | 7 (5%) | 2 (4%) | 1 (5%) | 1 (8%) | 11 (5%) |
| Diptongo | 28 (20%) | 12 (27%) | 6 (29%) | 3 (23%) | 49 (23%) |
| Total | 139 (100%) | 45 (100%) | 21 (100% | 13 (100%) | 215 (100%) |
Tabla 6 Errores de fragmentación de palabra, transferencia y creaciones léxicas
| Nivel | Básico | Intermedio | Avanzado | Alto |
|---|---|---|---|---|
| Fragmentacion | Endonde, nomas, enves, agusto | a tra vez, aveses | Acuentas, atraves, nadamas, de el (del) | atravez, amenudo |
| Transferencia | commentos, communidad, personals, processo, programs | tecnhologia, possibilidad, necessario, credential, dommicilio, postar | cyberneticos, permision, question | author |
| Creación léxica | Furade, acomplir, motocicló, | madurezen, asuda, filteras | compartillando, permisión. | acentia |
Resultados
De un total de 10.574 palabras, hubo una cantidad de errores ortográficos de 497 (4.7 %). Ver Tabla 1. El total de errores se clasificó según las categorías presentadas en la sección anterior, con los siguientes resultados: a) errores ortográficos en palabras cuya relación grafema-fonema es compleja consistente (29 errores o 5.8 %); b) errores ortográficos en palabras cuya relación grafema-fonema es compleja inconsistente (165 errores o 33.2 %), c) errores ortográficos en palabras cuya relación grafema-fonema es simple (215 errores o 43.3 %), d) errores de fragmentación-contracción de palabras (18 errores o 3.6 %), d) transferencia (31 errores o 6.2 %); e) creación léxica (9 errores o 1.8 %) y f) misceláneos (30 errores o 6.0 %).
A diferencia del análisis de Beaudrie (2012), las reglas de correspondencias complejas se subdividieron entre consistentes e inconsistentes (ver la siguiente sección), siguiendo una de las sugerencias de Llombart-Huesca (2018). Las tildes no se incluyeron en este estudio, como se anotó anteriormente. A modo de exploración, se incluye la categoría de creación léxica, pues se observó a lo largo de las composiciones. A continuación se explica cada una de las categorías, con ejemplos, para visualizar la producción de este grupo estudiantil, bajo el marco de escritura de ensayos con instrucciones precisas.
Errores cuya relación grafema-fonema es compleja
Las reglas ortográficas que presenta el español son relativamente transparentes, pero esa relatividad es compleja en cuanto a las correspondencias entre las grafías. Las reglas complejas se subdividen en comitentes e inconsistentes. Este término de inconsistencia se refiere a los casos en donde un fonema se puede representar por varios grafemas, pero no hay ninguna pista fonológica que especifique el grafema que corresponde a la grafía correcta (Defior et al., 2009, p. 56). Las reglas de correspondencia compleja consistente se encuentran en aquellas palabras que contienen fonemas cuya escritura está informada por el contexto, el cual informa qué grafema usar. Por ejemplo, para que el grafema <c> produzca el sonido /k/ debe estar seguido de a, o, u y para que suene [ke, ki], debe usarse <que> y <qui>. En esta categoría, el fonema /k/ presentó 28 errores representado por <qu> en vez de <c> o 16.5 % y /g/ 1 error repetido siete veces para un total de 29 errores o 5.8 %. La mayoría de los errores en esta categoría fueron con los grafemas <g> y <c> los cuales tienden a disminuir a medida que se asciende de nivel. En el nivel básico hubo 12 errores con ejemplos como quidado, quando, quenta, quidamos. En este nivel también se produjo la palabra algien, repetida siete veces, se cuenta como un error. En el nivel intermedio hubo 11 errores: enquentra (encuentra), locito (loquito), sequestrados (secuestrados), qualquier (cualquier),, entre otros. En el nivel avanzado hubo cinco errores: qual (cual), consequencias (consecuencias) y qualquier por (cualquier). En el nivel alto no se presentó este tipo de error.
En cuanto a los grafemas que no están sujetos a reglas contextuales, las complejas inconsistentes, donde un fonema está asociado con más de un grafema (e.g. /b/ = <b>, <v>), se encontró un total de 165 errores (ver Tabla 2). Se divide en cuatro subtipos3: el fonema /s/ indicaba la mayoría de errores a lo largo de los cuatro niveles con un total de 64 errores (38.8 %), 26 errores en el nivel básico, 19 en el nivel intermedio, 10 en el nivel avanzado y 9 en el nivel alto. La mayoría de los casos fueron de sustitución con la /s/ por otro grafema, con un total de 54 errores (32.7 %). Ejemplos de tal caso son: desir (decir), chansa (chanza), apresiar (apreciar), ilucion (ilusión); sibernetica (cibernética); entonses (entonces), vacasiones (vacaciones), ves (vez). También se encuentran 8 casos de adición en exsister; processo, suscede; atendistes; comistes; necessario; possibilidad, posiblementes. Y dos casos de omisión: nuetros (nuestros); facinantes (fascinante); la letra h presentó un total de 22 errores o 13.3 % principalmente en casos de omisión. Por ejemplo: e (he); ay (hay); echo (hecho); estorias (historias), a (ha); ejemplos de adición son: hasustada (asustada); ha (a); hahora (ahora); haya (allá); hibamos (íbamos). El fonema /b/ presentó un total de 15 errores, (9.1 %) save (sabe), habansar (avanzar), tubieran (tuvieran), deverian (beberían), jobenes, (jóvenes), vusca (busca), rebisan (revisan), govierno (gobierno). En el fonema /x/ hubo 57 errores, (34.5 %) representados por la <g> y la <j>; ejemplos de este tipo: jente (gente), pajina (página), hente (gente), protejer (proteger), hefes (jefes); targeta (tarjeta); protejer (proteger); exijes (exiges), etc.
El fonema /λ/ /j/ presenta 7 casos. En el nivel básico <ll> fue incluido en malla (mala). Se sustituyó en: majoría (mayoría); se omitió en lendo (leyendo); en el intermedio se sustituyó en aye (allí); en el nivel avanzado con la palabra alluda (ayuda) y en el el nivel alto en haya (allá).
La siguiente tabla resume los errores presentados anteriormente entre grafemas cuya relación grafema-fonema es inconsistente.
Errores de correspondencia consistente simple entre vocales y consonantes
Las vocales en español, excepto la <i>, tienen relación uno a uno con el fonema y grafema. Es decir, corresponden a las reglas de correspondencia simple. En esta categoría se encontró un total de 215 errores y se subdividió en las mismas categorías señaladas anteriormente. Se agregó una categoría, la de diptongo, donde al parecer el contacto vocálico tiene algún efecto para que algún constituyente se pierda, se sustituya o simplemente se transforme, cambiando así de una palabra a otra; es decir, que el significado se infiere solo por el contexto. El nivel básico presentó un número alto de errores en esta categoría, seguido por el intermedio, el alto y finalmente el avanzado (ver Tabla 3).
A continuación se describen. La categoría de sustitución presenta el mayor número de errores (97) con 45.1 %. Algunos ejemplos de sustitución son: este (esta), difiendo (defiendo), emportante (importante); enportande (importante); puedomos (podemos), envolucrar (involucrar), hacir (hacer), joventud (juventud), convincieron (convencieron), etc.
La categoría que le sigue es la omisión con 38 errores o un porcentaje del 18%. Algunos ejemplos son timpo (tiempo), sempre (siempre), dario (diario), alguene (alguien), ponendo (poniendo), quen (quien), provedor (proveedor), usarios (usuarios), onde (donde), horita (ahorita), pos (pues), uste (usted), trabjo (trabajo).
La categoría de adición contó con total de 20 errores o un 9.3 %. Ejemplos de tal caso son piensamientos (pensamientos); apriopiado (apropiado); contrasienas (constraseñas) . El caso de inversión presentó 11 errores o 5 %, algunos ejemplos son: seimpre (siempre), cuidadanos (ciudadanos), us (su), ortos (otros), atriculo (artículo). Como se indicó al inicio de este proyecto, algunas palabras contienen más de un error; por lo tanto, dichas palabras se repiten bajo la codificación de determinadas categorías, las cuales se están describiendo. A continuación se dan algunos ejemplos donde se encontró el diptongo con 49 casos (23 %): meustra (muestra), pos (pues), decidiadon (decidieron),ponendo (poniendo), sentimento (sentimiento).
Errores de fragmentación de palabra, transferencia y creación léxica
Siguiendo el modelo de Beaudrie (2012), se han incluído las categorías de fragmentación-contracción de palabra. Algunos ejemplos son: agusto (a gusto), nomas (no más), almenos (almenos), endonde (en donde), encontra (en contra); a tra vez (a través); a ver (haber); aveses (a veces); deveras (de veras); de el (del); de mas (demás), lendo (leyendo), entre otros. En cuanto a transferencia, el mayor número de errores se presentó en el nivel intermedio. Algunos fenómenos que se observaron dentro de esta categoría son: 1) la duplicación de alguna consonante que se transfiere del inglés, como en communicar (comunicar), possibildad (posibilidad), attención (atención), necessario (necesario), classes (clases); 2) adición del grafema <h>, en technologia (tecnología); 3) calcos como en postar o postean. A modo exploratorio se ha incluido creación léxica, que aunque no corresponde a la ortografía, se observó como un fenómeno persistente a lo largo de los niveles. (Ver Tabla 4). Esta categoría presentó un bajo porcentaje de 9 creaciones con un 16 %. Algunos ejemplos son: compartillando, permisión, madurezen, filteras. El nivel que presenta mayor número de producciones de este tipo es el nivel básico, seguido por el intermedio. Luego aparece el nivel avanzado, seguido del nivel alto, cuyo total de errores es mínimo.
A medida que los estudiantes van adquiriendo una conciencia morfológica, los errores de segmentación de palabra van disminuyendo. La constante producción no canónica en algunas expresiones como la locución preposicional "a través de" refleja que los estudiantes aún no son conscientes de que esta expresión está compuesta por varios constituyentes, una preposición a seguida del sustantivo través más la preposición de y que, por lo tanto se separa. De igual forma ocurre con otras producciones, como las que se ilustran en la siguiente tabla que da cuenta de los porcentajes de producciones no canónicas por nivel.
Tabla 7 Porcentajes de errores de fagmentación, transferencia y creación léxica por grupo
| Nivel | Básico | Intermedio | Avanzado | Alto | Total |
|---|---|---|---|---|---|
| Contracción-fragmentación | 6 (33%) | 4 (17%) | 5 (45%) | 2 (50%) | 18 (31%) |
| Transferencia | 11 (61%) | 15 (63%) | 4 (36%) | 1 (25%) | 31 (53%) |
| Creación léxica | 1 (6%) | 5 (21%) | 2 (18%) | 1 (25%) | 9 (16%) |
| Total | 18 (100%) | 24 (100%) | 11 (100%) | 4 (100%) | 58(100%) |
Errores misceláneos
En esta categoría se incluyeron palabras que se alteran por medio de sustitución, adición e inversión, pero que no se podrían clasificar dentro de las anteriores categorías principales. Algunos ejemplos son: enportande (importante); enmpuestos (expuestos); enseniar (enseñar); numbero (número); poñendo (poniendo); manjer (manejar); bueden (pueden), esaba (usaba), ocumular (acumular); previcidad (privacidad), etc. En esta clasificación hubo un total de 30 palabras.
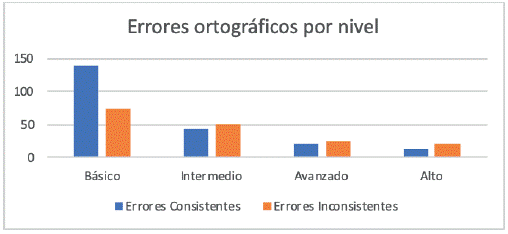
La siguiente figura muestra los errores ortográficos por nivel, en donde se ve que los porcentajes son bajos (4.7 %) y comparables con los datos que arroja el estudio de Beaudrie (2012) 3.3 %. Es necesario reiterar que los errores de acentos (tildes) no se incluyeron en este estudio, lo cual podría alterar los resultados.
Discusión
El propósito de este estudio ha sido identificar el nivel en el cual aparece el mayor número de errores ortográficos en las composiciones del examen de admisión que los estudiantes de herencia hispana presentaron en determinada universidad. El nivel en el cual aparece el mayor número de errores ortográficos es el nivel básico, posiblemente debido a la baja instrucción formal de la lengua de herencia que ha tenido este grupo de estudiantes en sus años de educación previa (primaria y secundaria) y debido también a que están a punto de iniciar el primer curso del nivel universitario de español. A continuación le sigue el nivel intermedio, luego el avanzado y finalmente el nivel alto. A mayor nivel de alfabetización, menor el número de errores ortográficos que aparecen en las composiciones.
El segundo hallazgo fue la identificación del fonema que presenta mayor número de errores. Este fue el fonema /s/. Como sabemos, este fonema tiene tres grafemas diferentes <s>, <z> y <c>, lo cual lo agrupa dentro de la categoría de reglas de correspondencia compleja inconsistente definidas por Defior et al. (2009, p. 57), pero que, a diferencia de la articulación española, el contexto no da pista del grafema que se debe usar. Estos grafemas <s>, <c>, <z>, en el español de Estados Unidos, al igual que en el resto de las Américas, no se diferencian en su forma oral en comparación con la pronunciación del norte de España, donde hay una diferencia articulatoria entre /s/ y /[]/, la primera siendo alveolar y la segunda, interdental. Tal diferenciación entre grafías se logra a través de la instrucción académica y la información visual de la palabra por medio de su exposición repetitiva, la cual se almacena como una imagen mental con información tanto semántica como fonológica (Ehri, 1980; Seymour, 1992). Esta categoría de dominio ortográfico pertenecería a la última fase, caracterizada por el desarrollo y dominio de palabras con fonemas que tienen más de una representación gráfica y que requieren de conocimiento específico de la palabra.
Algo interesante que se encontró es el dominio de la regla contextual a medida que se asciende del nivel con los grafemas "qu-" y "gu-" acompañados de los sonidos [e] o [i] donde la "u" no suena. Tal como lo indican Defior et al. (2009), estas reglas son más difíciles de dominar que las simples, ya que presuponen un proceso, "si... entonces...". Carbonel de Grompone et al. (1980) estipulan que hay un orden en el desarrollo de la ortografía en los hablantes nativos del español y ubican estas reglas en la segunda fase del desarrollo de tal ortografía. La ausencia progresiva de errores de esta categoría, a medida que se asciende de nivel, con 15 errores en el nivel básico, 11 en el intermedio, 5 en el avanzado y 0 en el alto, sugiere que el dominio ortográfico se logra por medio de la alfabetización de la lengua y la exposición a esta.
Quizás la parte que sobresale de este estudio es el alto número de errores de correspondencia simple, 215 errores, donde una gran proporción de estos errores corresponde a producción de palabras como emportante (importante), evedencia (evidencia), hacir (hacer), horita (ahorita), pos (pues), lendo (leyendo), haiga (haya), entre otras, y que son propias de la variedad de español a los que los estudiantes de herencia están expuestos. Bajo esta perspectiva, cabría poner un signo de interrogación a la palabra error cuando son producciones propias de su variedad.
Por otro lado, producciones de: nomas (no más), a tra vez (a través), a ver (haber), nadamas (nada más), amenudo (a menudo), piensamientos (pensamientos), puedemos (podemos), muestran que los estudiantes no han desarrollado aún la conciencia morfológica de las palabras. Cuando hay información tanto visual como auditiva de una palabra, a través del contacto con la lengua, esta se va almacenando paulatinamente en el lexicón mental y con la constante exposición se pueden inferir tanto la fragmentación de los constituyentes como la conjugación en caso de los verbos. Por lo tanto, este grupo estudiantil se podría beneficiar con intervenciones pedagógicas propias para este fin.
Llombart-Huesca (2018) sugiere reanalizar el estudio de Beaudrie (2012) y, en consecuencia, el presente, desde una perspectiva lingüístico-cognitiva, en la que se reclasifiquen las categorías desde el punto de vista morfológico y fonológico, pues la adquisición de la ortografía requiere de la conciencia fonológica, la cual involucra diferentes niveles: 1. Conciencia lexical (la habilidad de segmentar palabras); 2. Conciencia silábica (la habilidad de segmentar y manipular las sílabas de una palabra); 3. Conciencia intrasilábica (la habilidad de segmentar y manipula el principio y el final de la sílaba de una palabra) y 4. Conciencia fonémica (la habilidad de segmentar y manipular fonemas) (Defior & Serrano, 2011). Estas habilidades son determinantes en el desarrollo de la ortografía y de la lectura (Ball & Blachman, 1991), las cuales aparecen en las etapas previas a la instrucción escolar debido al crecimiento de vocabulario en el que se incluyen palabras de un solo fonema (Defior, Gracia, Calet & Serrano, 2015). Así, la ortografía, de manera gradual, se continúa desarrollando a través de la instrucción académica que se complementa con el aprendizaje de la escritura, que, a la vez, proporciona el conocimiento de fragmentación de palabra y discriminación fonemática (Burgess & Lonigan, 1998). La información morfológica influye en el desarrollo de la ortografía (Carlisle, 1995; Naggy et al. 2006). Carlisle (1995) la define como el conocimiento concienzudo de la estructura morfémica de las palabras y la habilidad de analizar y manipular tales estructuras4 (1994).
De esta manera, se puede observar que el desarrollo y la adquisición de la ortografía no solo involucran un nivel de conciencia, sino varios, y que ocupan un lugar primordial en el continuo del aprendizaje de la lengua. Su desarrollo depende del nivel de contacto con la lengua y la instrucción durante las estapas escolares tempranas. Como la instrucción lingüística de los estudiantes de herencia se ve interrumpida durante este periodo, estos componentes experimentan una grieta en su adelanto, el cual continúa en las etapas cuando los estudiantes regresan a la educación secundaria o universitaria.
Limitaciones
Con respecto a la composición, hay que recordar que los estudiantes usaron cierto tipo de léxico relacionado y limitado al tema que se les asignó, donde daban su opinión acerca del artículo leído: "El internet y la privacidad". En el estudio de Beaudrie (2012), los estudiantes cumplían dos tareas: 1) componían su ensayo con base en tres temas de opciones y 2) daban su opinión sobre los derechos de una persona de cargar un arma; este estudio está limitado a un solo ensayo con un tema y un léxico predeterminados. Esta limitación llevó a los estudiantes a usar determinado vocabulario, palabras con un alto grado de frecuencia en el continuo de las composiciones a través de los cuatro niveles. También, debido a la naturaleza de la tarea, un ensayo de clasificación, el tiempo que se les dio fue solo de treinta minutos, mientras que los estudiantes de Beaudrie tenían un tiempo mucho más amplio para hacer sus composiciones.
Llombart-Huesca (2018) insta a hacer más investigación en este aspecto a través de dictados tradicionales usando papel y lápiz, incluyendo pseudopalabras y bajo el marco de análisis linguístico-cognitivo.
Se observó que la mayoría de errores en las producciones de los estudiantes tendían a asociarse con sustitución, especialmente del fonema /s/ y en las palabras donde hay elementos vocálicos como: difiendo por defiendo; curriente por corriente; dicerle por decirle; necisita por necesita- donde hay elementos de percepción bueden por pueden; combierte por convierte decidiadon por decidieron; otros de omisión como enponendo por poniendo; sentimento por sentimiento, y otros asociados a su variedad: pos por pues; dicer por decir; hacir por hacer; horita por ahorita, instantanio por instantaneo; joventud por juventud, haiga por haya.
Como se observa, hay muchos factores que enmarcan estas producciones que sugieren de una forma imperativa hacer más investigación y estudios empíricos en este campo. Frente a este panorama, la sugerencia de Llombart-Huesca (2018) no es desatinada, hacer dictados que incluyan palabras con la forma estándar y que contengan palabras de esta naturaleza con el fin de observar cuál es la percepción y la producción de este tipo de palabras aisladamente. Así se tendría una mejor óptica del fenómeno que opera en tales producciones donde se podría comparar y determinar qué medidas pedagógicas interventivas son adecuadas.
Este enfoque no solo ayudaría a hallar la raíz de estas dificultades que presentan los estudiantes de herencia, sino que podría proponer soluciones pedagógicas prácticas y específicas que alivien tal dificultad.
Aunque los porcentajes de error en este estudio son bajos, se reitera que no se incluyeron los acentos ortográficos, los cuales podrían alterar considerablemente los resultados. Sin embargo, se considera que aunque los resultados reflejan tan solo una aproximación a los estudios anteriores, dicha aproximación ofrece una pista preliminar para seguir ahondando en este campo de estudio.
Conclusiones
De acuerdo con los resultados de esta investigación, se comprobó que a mayor instrucción, menor número de errores ortográficos en el continuo de los cursos de español para estudiantes de herencia hispana. Aunque el corpus usado es diferente al de Beaudrie (2012), los resultados que arroja este estudio son muy cercanos. En comparación con los estudios de Justicia et al. (1999) de 4.13 % y de Beaudrie (2012) de 3.38 %, los resultados del presente estudio (4.7 %), muestran tendencias muy similares.
Es necesario hacer más investigación de este tipo para comparar los patrones de errores ortográficos en contextos donde el mismo fonema tiene más de una representación gráfica. Desde el punto de vista de Carbonell de Grompone et al. (1980, p. 17), quienes encontraron que un factor determinante en la naturaleza de errores ortográficos en estudiantes monolingües de primaria y secundaria era la frecuencia de uso de la palabra, en vez de la dificultad de la regla que gobierna la ortografía de la misma. Si se tiene en cuenta que los estudiantes de HH no tienen niveles altos de escolaridad en dicha lengua, cabría preguntarse si los errores cuya relación grafema-fonema que presentan se debe a la baja frecuencia en su uso y no a la dificultad de la regla.
Debido a la alta correlación entre frecuencia de error y nivel de escolaridad, se hace el llamado para que se haga más investigación en este aspecto con el fin de encontrar un método eficaz de instrucción en el que los estudiantes se beneficien, debido a que la ortografía es el pilar para la buena comprensión de lectura y escritura.

