Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Introducción
Los conceptos de género, modo y secuencia textual resultan problemáticos, pues en ocasiones se asemejan entre sí y en otras se usan para clasificar textos sin el adecuado rigor académico. En esta investigación se empleará el concepto de secuencia textual, tal como ha sido definido por Adam (1992). Según este investigador, una secuencia es una estructura que tiene un propósito comunicativo determinado. A partir de esta consideración, Adam (1992) identifica cinco secuencias: narrativa, descriptiva, argumentativa, explicativa y dialogal.
Dentro de un texto es posible encontrar diversas secuencias con funciones comunicativas distintas, pero a la vez es posible identificar una secuencia textual dominante y otras secundarias. Con base en la secuencia textual predominante se puede hablar de textos narrativos, descriptivos, argumentativos, expositivos o dialogales. Un texto donde predomine la secuencia narrativa, como la autobiografía, puede considerarse un texto narrativo. Este fue el principio asumido en esta investigación.
Para Adam (1992), los textos narrativos son aquellos que informan sobre acciones y responden a la pregunta ¿qué pasó? En este tipo de textos abunda la predicación y los verbos de acción, y se destaca la estructura temporal. Esta secuencia discursiva se encuentra en cuentos, novelas, noticias, reportajes. Según Werlich (1975), las secuencias narrativas se evidencian en formas objetivas como el informe y en formas subjetivas como la narración oral.
Narrar es una de las secuencias más usadas por el ser humano. Se narran los sucesos que ocurren a diario, aquellos acaecidos en épocas pasadas y los que pueden venir en el futuro. Se narran tanto hechos reales como ficticios, y en estos últimos se crean universos de sentido alternos. En el ámbito educativo, los textos donde predominan las secuencias narrativas se leen y escriben a lo largo de todos los grados del periodo de escolaridad. Si bien puede afirmarse que es la secuencia textual más usada en el ámbito escolar, no se dispone de estudios consistentes que permitan medir la complejidad de los textos donde predomina dicha secuencia.
La necesidad de analizar la complejidad en secuencias discursivas particulares ha sido señalada en diversos trabajos, en cuanto distintas tipologías suponen medidas de complejidad diferentes (Frantz et al., 2015; Ortega, 2015; Ochoa, 2016); así, por ejemplo, criterios como la "conectividad" y la "subordinación", entre otros, parecen variar entre secuencias (Aravena & Hugo, 2016).
En la revisión bibliográfica para el presente trabajo se encontraron algunas investigaciones que, al centrar su atención en textos discursivos particulares, dieron cuenta de la complejidad de los textos narrativos en comparación con textos donde prevalecen otras secuencias. Así, la argumentación (Yang et al., 2015; Polio & Yoon, 2018) y el discurso académico aparecen como los tipos textuales más complejos, en tanto que, en el polo opuesto, se ubica el discurso cotidiano; el texto narrativo se hallaría en un punto de complejidad media (Nini, 2015). Según Meneses et al. (2012), a partir de un estudio longitudinal con estudiantes chilenos, los textos narrativos orales se oponen a los expositivos escritos en términos de longitud, diversidad léxica y relaciones intraclausales. Por su parte, Nippold et al. (2017) compararon textos narrativos y textos de pensamiento crítico que involucraban preguntas y respuestas con conversaciones y textos de pensamiento crítico producidos por adultos jóvenes, y concluyeron que los dos primeros textos tenían una complejidad sintáctica mayor que la tarea conversacional y que el primer texto era más complejo sintácticamente que el texto de pensamiento crítico.
Por otra parte, se han investigado, aunque en menor medida, los niveles de complejidad de distintos textos. Por ejemplo, Sheehan et al. (2015) indagaron si los libros de texto pensados para niños estadounidenses de primer grado y producidos por una editorial específica entre los años 1962 y 2013, se han hecho más complejos o no. La medición se hizo con el software Text Evaluator®. Los resultados muestran que la complejidad ha aumentado o se mantiene constante, debido a que tales textos han incluido una proporción creciente de pasajes informativos. Fundamentalmente, las modificaciones son las siguientes: 1) aumento en la proporción de palabras que tienden a aparecer con menos frecuencia en el texto impreso; 2) aumento en la proporción de palabras que es más característico del texto académico como opuesto a la ficción o la conversación; 3) niveles más bajos de cohesión referencial; 4) niveles más bajos de narratividad, y 5) menos instancias de un estilo interactivo/ conversacional.
Ochoa (2021), por su parte, mediante un análisis factorial examinó textos descriptivos publicados en manuales escolares de distintos grados y los clasificó en los niveles: muy bajo, bajo, medio y alto. Esta investigadora encontró que, en ocasiones, el nivel de complejidad de los textos no aumenta a lo largo de la escolaridad y que un número importante de textos se ubica en los niveles muy bajo y bajo.
Como se ve, no hay investigaciones relacionadas con la complejidad de textos narrativos en sí mismos.
Ahora bien, la complejidad es definida por Rescher (1998) como una cuestión de cantidad y variedad de elementos, y de sus interrelaciones. Por su parte, Pallotti (2015) considera que el concepto de complejidad no tiene límites claros, pues hace referencia al menos a tres aspectos: 1) complejidad estructural (propiedad de los textos y de los sistemas lingüísticos); 2) complejidad cognitiva, relativa al costo de procesamiento de las estructuras lingüísticas; y 3) desarrollo de la complejidad de distintas estructuras. En un sentido similar, Miestamo (2017) distingue entre complejidad absoluta y complejidad relativa. La primera tiene un carácter inherente al sistema lingüístico o al texto y la segunda está relacionada con la dificultad de una determinada estructura para diversos usuarios.
A efectos de esta investigación se estudió la complejidad absoluta o estructural propia o inherente a los textos, definida por Pallotti (2015) como la característica de los textos que tiene que ver con el número de constituyentes lingüísticos y sus esquemas relacionales. Este concepto se distancia del de lecturabilidad, la cual es entendida como el grado de facilidad o claridad que presenta un texto para ser comprendido por los lectores a los que está destinado. Tal facilidad se relaciona no solo con las características del texto, sino también con las competencias del lector y las características de la tarea asignada.
Respecto a las variables que determinan la complejidad, se consideran importantes las de "cantidad de elementos" (Kusters, 2008; Bulté & Housen, 2012; Lahuerta, 2017) y "variedad" (Rescher, 1998; Dahl, 2008; Miestamo, 2017). De acuerdo con estas variables, los criterios para determinar la complejidad se han centrado principalmente en indicadores sintácticos y léxicos (Vyatkina, 2013; Corriveau et al., 2016; Schilk & Schaub, 2016) relativos a la oración y la palabra. Hay algunos autores que han trabajado criterios morfológicos (Pallotti, 2015), semánticos (Plakans & Bilki, 2016; Maton & Doran, 2017) y pragmáticos, con unidades mayores que la oración (Yang et al., 2015).
Son criterios morfológicos la estructura interna (lexema y morfemas) y la categoría de las palabras (De Clercq & Housen, 2016). Entre los criterios sintácticos aparecen con alta frecuencia aquellos relacionados con la estructura del sintagma nominal y de la oración (Mancilla et al., 2017), así como los tipos y clases de oraciones (Peñaloza et al., 2017); entre ellas, la "subordinación". En el nivel léxico se analiza la "cantidad de palabras", la "diversidad léxica" (TTR) -entendida como la relación entre palabras diferentes versus palabras no repetidas-, y el grado de dificultad de las palabras. En términos semánticos y pragmáticos, se tienen en cuenta criterios como "cantidad de información", "temas" y "subtemas" (progresión temática), "cohesión", "marcadores discursivos" o "conectores". En el nivel pragmático se estudia la "presuposición" y los "enunciadores" (Solnyshkina et al., 2017).
Algunos de los rasgos anteriores han sido cuestionados como rasgos de complejidad; tal es el caso del subjuntivo -relativizado por Norris y Ortega (2009), quienes señalan que su uso disminuye con la edad y que no es una constante en textos académicos-, y de los marcadores discursivos -Van Silfhout et al. (2015) afirman que la presencia de los marcadores conduce a un procesamiento más rápido-.
Teniendo en cuenta las consideraciones anteriores, en la presente investigación se planteó como objeto de estudio la complejidad lingüística en textos narrativos, y se centró la atención en la complejidad estructural inherente a los mismos textos (Pallotti, 2015); específicamente, como problema de investigación se indagó qué criterios sintácticos, semánticos y pragmáticos permiten predecir la complejidad de un texto narrativo.
Metodología
La presente investigación es un estudio descriptivo- interpretativo con un diseño cuantitativo no experimental.
El corpus
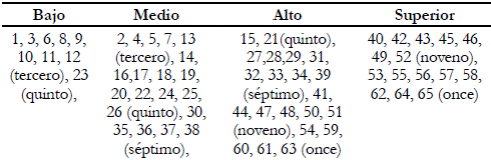
Para el corpus se seleccionaron textos narrativos escolares de dos editoriales colombianas de amplio uso en el medio educativo. La mayoría de los textos son del área de ciencias sociales, los otros textos pertenecen a las ciencias naturales, lenguaje y alguno de matemáticas. Se analizaron en total 65 textos escolares discriminados en cuatro grados: tercero, quinto, séptimo, noveno y once.
Análisis cuantitativo
En términos estadísticos, el propósito de la investigación consistió en hallar los factores que determinan el nivel de complejidad lingüística en una muestra de 65 textos. Teniendo en cuenta el estado de la cuestión, la definición adoptada de complejidad y un análisis previo del corpus, se usaron las siguientes variables para analizar el corpus: "palabras totales (número total de palabras en el texto)", "palabras repetidas", "palabras diferentes" (no repetidas), "léxico especializado" (propio de la disciplina a la que pertenece el texto, es decir, de un ámbito específico), "presuposición" (información que no aparece explícita, sino que el lector debe construir), "complementos nominales" (todas aquellas estructuras que modifican al sustantivo, tales como adjetivos, apósitos, oraciones relativas, sintagmas preposicionales, deverbales ), "sustantivos sin modificadores", "complementos circunstanciales" (tales como complementos de tiempo, espacio, modo, instrumento, compañía, etc.), "oraciones subordinadas" (dependientes de un verbo principal), "total de oraciones" (número de oraciones que componen el texto), "variación de modo: indicativo, subjuntivo", "variación de tiempo: pasado, presente, futuro", "variación de voz: voz activa, voz pasiva", "marcas de cohesión" (conectores y marcadores discursivos), "anticipaciones" (hipérbaton) y "progresión temática" (relación entre temas y remas). En estas variables se tuvieron en cuenta los factores "cantidad de elementos" y "variedad". En relación con este último factor se contó la cantidad de modos, tiempos, el tipo de progresión temática, para verificar cuáles variables resultaban productivas y si había o no variedad al usar varias de ellas. También se contó la ocurrencia de cada variable para aplicar el análisis estadístico. La mayoría de las variables se interpretaron de manera ascendente, es decir, si había una mayor entre ellas, más complejo era el texto. Solo las variables "palabras repetidas" y "sustantivos sin modificadores" se contaron en sentido inverso, esto es, cuanto más ocurrencias, menos complejidad. Con estas variables se invitó a un grupo de lingüistas expertos en evaluación de textos a establecer unos niveles que permitieran la clasificación de los textos. Estos establecieron cuatro niveles: 1. Bajo, 2. Medio, 3. Alto y 4. Superior, y generalizaron los rasgos de la siguiente manera:
Bajo: textos cortos, esquemas oracionales y nominales simples. Poca variación modal y temporal. Se manejan conceptos muy concretos y familiares. El léxico no requiere de aclaraciones ni de diccionarios. Nula presuposición.
Medio: sintagmas nominales con alguna complementación, oraciones simples y oraciones subordinadas. También pueden aparecer incisos entre los componentes de las oraciones. La longitud de los textos puede ser mayor. Se maneja ya cierto nivel de abstracción, aparece alguna que otra generalización. Baja presuposición.
Alto: predominio de oraciones subordinadas y sintagmas nominales complejos, textos con mayor número de palabras diferentes, el volumen de información es considerable. Aparecen conceptos abstractos y generales. Mediana presuposición.
Superior: estructuras complejas sintáctica y semánticamente (nominalizaciones, deverbales), términos abstractos y especializados, variedad temática, alta presuposición.
Una vez hecha esta jerarquización, los expertos clasificaron los textos de manera individual. Debido a que frente a algunos textos había discrepancia, se invitó a los expertos a un análisis en grupo sobre los textos donde la clasificación no era unívoca. Hecha la discusión, se llenó a una nueva clasificación por consenso (anexo 1).
Posteriormente se aplicó el modelo de odds proporcionales, que asume pendientes /3's diferentes para todas las viables explicativa, lo que requiere una gran cantidad de datos para estimar un coeficiente para cada predictor en cada logit acumulativo. Una forma de simplificar el modelo consiste son suponer que los coeficientes para c0da predictor son idénticos piara todas las categorías de respuesta de la variable dependiente; este supuesto de pendientes iguales se conoce como supuesto de odds proporcionales o también supuesto de líneas paralelas. En este caso, el modelo llega. a ser
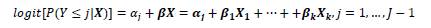
donde la probabilidad de que la variable dependiente se encentre debajo o en la categoría j es
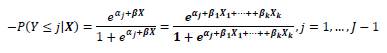
y el odds de la variable dependiente por debajo o en la categoría j
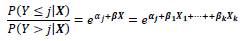
Resultados
Un total de 20 variables predictoras se midieron para los 65 textos que componen la muestra, lo que implica un total de 190 coeficientes de correlación (Tabla 1). Ahora bien, a excepción del número de verbos en tiempo futuro, que presenta muy bajos coeficientes de correlación, con el resto de las variables se observa, en general, una alta asociación lineal entro las variables: et 777.99 % de los coeficientes se encuentra por encima de 0.4 y aproximadamente el 55 % es como mínimo 0.6. Tanto el gran número de variables como los altos coeficientes de correlación presuponen un inconveniente al momento de modelar el nivel de complejidad, como consecuencia del tamaño de la muestra y de la posibilidad de que el modelo estimado presente problemas de multicolinealidad.
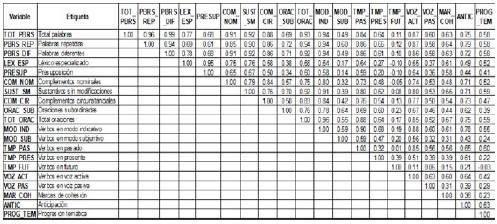
Este método consistió en reducir el número de variables mediante el análisis de componentes principales (ACP) y en usar las componentes extraídas como variables explicativas en la estimación del modelo de regresión logit acumulativo de odds proporcionales. Este camino tiene dos ventajas: reduce el número de variables y, dado que las componentes son no correlacionadas por construcción, el modelo ajustado no presenta problemas de colinealidad.
Extracción de componentes principales
Se retuvieron tres componentes de acuerdo con el criterio del número valores propios mayores que 1, las cuales explican un 78.7 % de la variabilidad total en los datos. Con el fin de encontrar una estructura simple se aplicó un método de rotación oblicuo (el modelo factorial de rotación se presenta en la Tabla 2). Como se observa, del total de variables, 16 presentan cargas significativas sobre la primera componente, 3 sobre la segunda y solamente una (verbos en tiempo futuro) sobre la tercera componente; lo que era de esperarse, dadas las muy bajas correlaciones entre esta variable y las restantes. Es necesario anotar que todas las cargas son positivas.
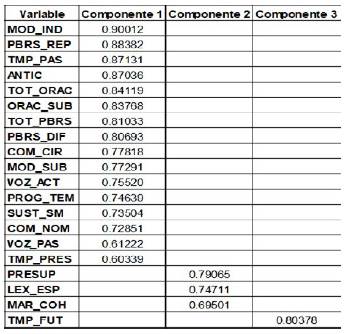
Una lectura de la componente 1 muestra que, en general, las cargas son muy altas; salvo verbos en voz pasiva y verbos en tiempo presente con cargas de 0.61 y 0.60, respectivamente, las restantes variables tienen cargas entre 0.73 y 0.90; por tanto, esta componente puede interpretarse como un factor de tamaño, que incluye atributos que aumentan el nivel de complejidad de un texto, así como algunos que lo reducen. Por otra parte, dadas las variables que cargan en la componente 2 (presuposición, léxico especializado y marcas de cohesión), esta componente puede interpretarse como un factor de calidad de la comunicación; el emisor espera que lo no explícito sea entendido, que las relaciones expuestas tengan validez lógica y que el léxico empleado sea accesible; del lector, por su parte, se espera capacidad de deducción, comprensión y análisis.
Estimación del modelo
Se puede concluir que el modelo con intercepto y covariables se ajusta mejor que el modelo base (solo intercepto), dado que el valor de la estadística para cualquiera de los criterios tenidos en cuenta es mucho menor; lo que reafirma el rechazo de la hipótesis global de no regresión (H0: P1 = P2 = P3 = P4=0) a los niveles usuales de significancia y demuestra que el modelo adaptado presenta un buen ajuste. Las tres componentes resultan significativas, con coeficiente estimado positivo para las dos primeras y negativo para verbos en tiempo futuro. En lo que se refiere al desempeño predictivo, la estadística de D de Somer es, aproximadamente, 0.86 significativamente menor que para el modelo seleccionado con el método 1 (0.93).
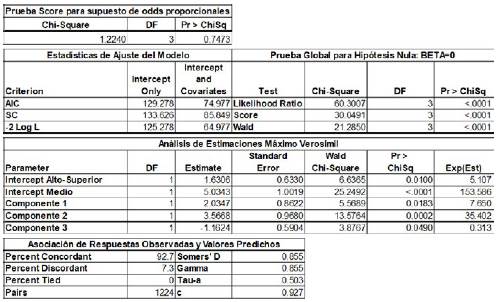
Modelo seleccionado
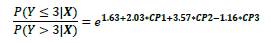
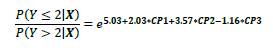
Con CP1, CP2 y CP3 cada una de las componentes principales.
1.63+2.03«CP1+3.57«CP2-1.16«CP3
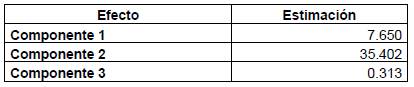
De la tabla puede concluirse que:
El odds (posibilidad ponderada) de un texto de tener mayor nivel de complejidad es 7.65 veces mayor al aumentar en una unidad la componente principal 1.
La posibilidad ponderada de un texto de tener mayor nivel de complejidad es 35.4 veces mayor si se aumenta la componente principal 2 en una unidad.
La posibilidad ponderada de un texto de tener mayor nivel de complejidad se reduce en un 68.7 % al aumentar en una unidad el número de verbos en tiempo futuro.
Discusión y conclusiones
El hecho de que la mayoría de los criterios se ubiquen en un solo factor presenta inconvenientes a la hora de explicarlos teóricamente. No obstante, es claro que en el primer componente se agrupan criterios morfosintácticos y semánticos relacionados con la variable "cantidad", lo cual concuerda con trabajos como los de Kusters (2008), Bulté y Housen (2012), y Lahuerta (2017). En el segundo componente los criterios son claramente semántico-pragmáticos, en cuanto el léxico especializado y la presuposición exigen un conocimiento que se ha de construir con la lectura o un conocimiento previo por parte del lector. Igualmente, las marcas de cohesión guían la interpretación del lector, ya que muestran el tipo de relación semántica que se establece entre las proposiciones del texto.
Es interesante que el factor que mayor incrementa la complejidad es el que está en el componente 2 que, como se ha señalado, tiene una estrecha conexión con los niveles semántico y pragmático. Este hallazgo muestra que los criterios sintácticos, tal como los empleados por Vyatkina (2013), Corriveau et al. (2016), y Schilk y Schaub (2016), no son suficientes para dar cuenta de la complejidad estructural. Por el contrario, la conclusión es coherente con los pocos estudios reportados en la bibliografía en los que la semántica ocupa un lugar principal (Plakans & Bilki, 2016) al igual que la pragmática (Solnyshkina et al., 2017).
Los resultados coinciden también con la primera revisión del corpus y con la intuición de los expertos: mayor presuposición, más y variadas marcas de cohesión y mayor presencia de léxico especializado tornan más complejo un texto.
Otras variables asociadas al factor "cantidad" como "palabras totales", "total de oraciones", "marcas de cohesión", "complementos circunstanciales" resultaron significativas, pero en menor medida. Esto nos lleva a inferir que la longitud de un texto no implica necesariamente mayor complejidad, por cuanto un texto puede tener gran longitud, pero no ser complejo y viceversa: textos cortos pueden tener un alto grado de complejidad. De igual manera, criterios morfológicos y sintácticos relacionados con tiempos y modos verbales, voz, complementación nominal, tipos de oraciones, inciden, pero en una proporción menor. Llama la atención que el léxico diferente no aparezca en el componente dos, sino en el uno. Puede hipotetizarse que la cantidad y no la calidad (variedad) fue decisiva para su ubicación. Así mismo puede suceder que las palabras sean diferentes pero que sean de uso frecuente, que el término no entorpezca la comprensión global o que su significado pueda ser inferido del contexto intratextual.
El tiempo futuro aparece con el signo negativo, posiblemente para señalar el alejamiento en la escala de la prototipicidad del tiempo privilegiado en las narraciones: el pasado. No obstante, es curioso que aparezca él solo en un componente independiente.
Los resultados generales de esta investigación muestran que, contrario a lo señalado por Frantz et al. (2015), Ortega (2015), y Aravena y Hugo (2016), los criterios que miden la complejidad no dependen de un tipo o género textual específico, ya que es evidente que las tres variables principales que explican la mayor complejidad, a saber, presuposición, conectores y léxico especializado, se presentan en cualquier tipo discursivo. Sin embargo, se puede afirmar que prototípicamente los textos narrativos escolares cuentan un suceso de forma cronológica, muestran acciones que se desarrollan principalmente en tiempo pasado, se construyen en voz activa, modo indicativo. Una mayor variación de estos indicadores podría aumentar la complejidad y con ello retar cognitivamente a los estudiantes.
Como se señaló, los rasgos semánticos son decisivos a la hora de evaluar la complejidad textual. Esta información es importante para profesores, coordinadores académicos, editores y programadores del currículum: contar con un conjunto de criterios lingüísticos apoya la tarea que tienen educadores y coordinadores escolares de seleccionar adecuadamente los textos para cada grado escolar, desarrollar la competencia comunicativa en forma progresiva y continua, y evaluar la comprensión lectora.
También puede ser útil para personas y organismos encargados de la evaluación de la comprensión lectora, pues ofrece unos indicadores acerca de qué evaluar y cuándo. La atención debe centrarse entonces en qué tanta información ofrece un texto, qué tan variada es, de qué calidad, qué tan novedosa es para los estudiantes, qué información presupone o está implícita y qué tipo de conexiones o inferencias implica.
Para terminar, es importante señalar que esta es una investigación exploratoria tanto en relación con los factores y variables que dan cuenta de la complejidad como con el tipo de texto estudiado. En este sentido, los resultados son preliminares. Es preciso indagar con un corpus más amplio, donde se incluyan textos narrativos no escolares y con textos donde primen otras secuencias textuales para validar los resultados obtenidos. Así mismo es importante contrastar el análisis con procesos de comprensión de textos en poblaciones estudiantiles de diversos grados y ciclos escolares (complejidad relativa). También es conveniente llevar a cabo análisis cualitativos que posibiliten un estudio más profundo de las variables y los componentes que permiten describir la complejidad textual.