











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Introducción
Con la llegada de las redes sociales, el debate público ha ampliado sus espacios de interacción. Cada día más personas se conectan con el acontecer nacional e internacional a través de Internet y, particularmente, de las redes sociales. Específicamente, la red social Twitter se ha convertido en un espacio de información y discusión entre internautas que permite enviar y comentar mensajes, reaccionar y encontrar las tendencias de temas de interés.
Twitter ha llegado a ser, además, la red de preferencia de los políticos, donde informan sobre sus agendas y comunican sus posturas sobre determinado tema. Fue lo que sucedió inicialmente con Obama en su disruptiva campaña presidencial de 2008 (Beas, 2010) y más tarde con la predilección de Trump de reemplazar los comunicados de prensa por tuits (Kreis, 2017; Ott, 2017). También los medios de comunicación y periodistas encuentran en Twitter un espacio para masificar sus informaciones (Peirano, 2019) e interactuar con sus audiencias. De modo similar, el activismo social y político ha encontrado un asidero fecundo para manifestar sus ideas (Rovira, 2019) y conectar con otros. Este fenómeno se debe, en parte, a la arquitectura interna de esta red social -en la cual la brevedad, la inmediatez y la viralización (Ventura, 2021) son sus principales características-, así como a la atención que reciben sus contenidos en los medios de comunicación tradicionales.
En ese sentido, Twitter se ha consolidado como una red de intercambio y debate público, que amplía el espacio de participación ciudadana agregando un espacio público digital (Seixas & Nascimento, 2021). Es decir, no se trata de un reemplazo de la plaza pública por el espacio digital, sino de un ensanchamiento del lugar de discusión ciudadana. A este fenómeno se suma el acceso abierto de los datos, a diferencia de Facebook, Instagram o Tiktok, lo que ha influido en que Twitter se convierta en un objeto de estudio para las ciencias sociales en general y particularmente para las ciencias políticas y de la comunicación (Longhi, 2013; Calvo, 2015; Hürlimann et al., 2016; Pallarés & García, 2017). No obstante, muchos de los trabajos realizados desde estas disciplinas tienen un enfoque cuantitativo, por lo que hacen falta más acercamientos desde una perspectiva que incorpore herramientas también cualitativas que podrían enriquecer análisis posteriores de los datos.
En esta línea, el presente artículo se interroga sobre la forma de abordar los enunciados verbo-visuales de Twitter para ser utilizados en posteriores análisis discursivos. Se presenta una propuesta metodológica que orienta la forma de capturar los datos, filtrarlos, organizarlos y construir un corpus manejable susceptible de análisis. Esta alternativa analítica busca aportar al estudio actual del discurso digital, en particular del material extraído de Twitter, y a enriquecer el conocimiento sobre la discursividad política en esta red social.
Este trabajo se organiza del siguiente modo: en primer lugar, se caracteriza brevemente la plataforma Twitter y su importancia como objeto de estudio; en segundo lugar, se desarrolla la propuesta analítica a partir de cinco puntos: netnografía, aspectos éticos, procedimiento de recolección y procesamiento de los datos, construcción del corpus y análisis descriptivo. Esta ruta metodológica deriva de la reconstrucción del proceso llevado a cabo en una investigación en curso1, por lo cual los ejemplos de cada paso serán tomados de esta. La investigación aborda los discursos en Twitter de grupos a favor y en contra del Acuerdo de Paz en Colombia en el plebiscito del 2016.
Twitter como objeto de estudio
Twitter, la plataforma de microblogging fundada hace más de 15 años (Twitter, 2020), es en la actualidad una de las principales redes sociales. Inspirada en el auge de los blogs de principios de siglo XXI y en los mensajes de texto (SMS), Twitter irrumpe en la web 2.0 para condensar estas dos ideas y ofrecerles a los usuarios una plataforma de promoción personal (Van Dijck 2016) y, a la vez, de intercambio comunitario. Básicamente, se trata de una red social que permite enviar mensajes de texto plano de 280 caracteres (antes 140) denominados tuits (tweets en inglés) que luego se muestran en la página principal del usuario. Con el tiempo, Twitter ha evolucionado sus formatos de interacción y hoy se pueden compartir también imágenes estáticas o animadas (gifs), ideogramas (emojis), videos, insertar enlaces de otras plataformas y hasta establecer conversaciones en directo (spaces). A pesar de que otras redes como Facebook o YouTube cuenten con más usuarios (Data Reportal, 2022), Twitter, con sus más de 400 millones usuarios2, se destaca por ser la red más popular de las personalidades políticas y los medios de comunicación y por permitir a los usuarios el seguimiento de las noticias en tiempo real. Esto se debe particularmente a la arquitectura de esta red social, que antepone la información a la formación de redes (Alcántara-Plá, 2020).
Pese a este diseño de la plataforma, donde prima la jerarquía de tuiteros influyentes que generalmente son figuras del espectáculo, políticos o celebridades (Van Dijck, 2016), varios analistas también consideran que en Twitter se encuentra un espacio de participación ciudadana, una especie de "foro político, social y cultural que se mantiene abierto 24 horas al día, los 365 días del año" (Calvo, 2015, pp. 11-12.). Es así como Twitter se configura como un espacio de conversación social en torno a temas de interés y en donde los políticos y otras personalidades encuentran un lugar sin intermediarios para comunicarse con el público. En ese sentido, la plataforma permite "una mayor intervención de los ciudadanos, lo cual ayuda a los movimientos sociales y a las políticas alternativas" (Castells, 2008, p. 1). Freire (2019) sostiene que Twitter se puede entender como un territorio político digital, en cuanto que, además de un despliegue de la acción política, también reúne características distintivas de otras redes sociales, tales como "el espíritu de publicidad, el potencial interactivo de la bidireccionalidad, la masividad de la conversación pública, el sesgo positivo, la presencia de capitales simbólicos y el poder de colonización" (p. 68). De este modo, Twitter no es reconocido por el número de usuarios activos, sino por la capacidad que tienen sus mensajes (tuits) de generar tendencias e impactar así en los medios de comunicación masiva.
Desde una perspectiva discursiva, se puede decir que Twitter es un espacio público digital, entendido como "un lugar de interacción discursiva, en que es posible analizar la producción, la circulación y recepción de discursos en que los sujetos online buscan participar, de algún modo, de la vida pública, y más específicamente política"3 (Seixas & Nascimento, 2021, p. 2402). Con lo cual, esta red social permite el ensanchamiento del espacio público (Castells, 2009; Slimovich, 2016; Rovira, 2019) en el ámbito virtual, no como un reemplazo de la plaza pública o del encuentro físico, sino que se trata de un entorno ampliado, puesto que en el espacio virtual también se encuentran las personas ocupando ese lugar. Esto coincide con el carácter conversacional y colaborativo que se ha destacado en las primeras aproximaciones analíticas de Twitter (Honeycutt & Herring, 2009) y que incide en las dinámicas de la sociedad al propiciar la interacción pública de voces (Mancera Rueda & Pano Alamán, 2020) ¿. Esta característica enfatiza en el carácter dialógico que promueve la plataforma, dado que, si bien hay una primacía de la información, los usuarios participan con su opinión sobre algún tema, la comparten dando retuit a otros o manifiestan acuerdo a comentarios dando "me gusta". Esta dinámica de comunicación suscita prácticas tecnodiscursivas (Paveau, 2017) que permiten la promoción de una comunidad definida por un ambientaffiliation (Zappavigna, 2011, 2012), es decir, por medio de la vinculación a un determinado tema donde la comunidad encuentra adhesión con ciertos valores y opiniones.
En este trabajo se plantea el diseño de una investigación cualitativa que, desde la perspectiva de Vasilachis de Gialdino (2009), es de carácter interpretativa, multimetódica, reflexiva y usa diseños flexibles al contexto. Desde este enfoque, en el diseño se incluyen herramientas diversas que permiten un acercamiento al objeto de estudio. En primera instancia, se utiliza la netnografía como método de observación, la cual permite un acercamiento al tema de estudio y retratar de forma panorámica el objeto de análisis. En segunda instancia, se procede a la recolección de datos utilizando herramientas digitales de descarga, visualización y manejo de información tales como API (Application Programming Interface) de Twitter, librerías de Python y Open Refine; recursos que habilitan la exploración de tendencias y patrones en el material. Con los datos organizados, se procede a la construcción del corpus, para lo cual es necesaria la selección de perfiles de acuerdo con criterios propios de cada investigación. A continuación, se detalla cada uno de estos pasos para ahondar en esta propuesta metodológica.
Propuesta analítica
Etnografía virtual
Con el objetivo de realizar una inmersión inicial en algún tema que se discute en Twitter y explorar el material producido en esta red social, se propone un primer acercamiento a través de una netnografía (Del Fresno, 2011; Kozinets, 2015), que tiene antecedentes en la etnografía virtual (Hine, 2004), y en la ciberetnografía (Robinson & Schulz, 2014). De acuerdo con Hine (2004), la etnografía virtual se erige como un modo de conocer la realidad social que se presenta en internet. Tal como sucede en la etnografía clásica, su forma básica consiste en que el investigador se sumerja en el mundo que estudia por un tiempo determinado y tome nota de las relaciones, actividades y significaciones que encuentre en los procesos sociales en determinado espacio, y de esa forma dar una mirada comprensiva y reflexiva sobre lo que ocurre en internet. La netnografía, como forma de investigación, hace un énfasis en la recolección y el procesamiento de cantidades significativas de datos empíricos para producir conocimiento al respecto.
Del Fresno (2011) afirma que el auge de las nuevas formas de comunicación en red abre un espacio para la netnografía como "una disciplina con gran potencial en el campo de la investigación que ofrece el ciberespacio para las ciencias sociales" (p. 64). Una de las ventajas que brinda la netnografía es la posibilidad de realizar observación no participante, para describir los procesos que se estudian sin las interferencias que la inmersión del investigador puede traer en el espacio offline. En otros trabajos (Álvarez-Bornstein & Montesi, 2016; Badillo-Mendoza & Marta-Lazo 2019; Ventura, 2018) ya se ha utilizado la técnica de observación no participante y de registro etnográfico para estudiar la comunicación en Twitter.
Para la exploración etnográfica virtual se propone la elaboración de dos tipos de registros en paralelo. El primero de ellos es un relevamiento de información en periódicos digitales, el cual permite hacer un seguimiento a los eventos noticiosos más destacados durante un periodo determinado al fenómeno que se esté estudiando, por ejemplo, una campaña electoral, una protesta o algún evento. Esta información se puede extraer a través del buscador de cada portal de noticias por medio de palabras clave y así es posible reconstruir determinado contexto o situación. El segundo registro que se sugiere es el de los trending topics o tendencias que tuvieron lugar en Twitter. Se trata de las palabras o expresiones que pueden estar agrupadas con el símbolo # (hashtags) y sirven para organizar el material dentro de Twitter, pero se basan en temas o ideas, y no en usuarios (Squires, 2016). De manera que, la revisión de las tendencias de hashtags permite saber qué temas se estaban discutiendo en la plataforma en determinado periodo de tiempo. Para obtener estos datos se puede utilizar la página web libre Trendinalia4 que monitorea los temas del momento en Twitter. En este portal solo es necesario seleccionar la ubicación (continente y país), las fechas y a continuación se revela una lista con las tendencias más destacadas, acompañada de una serie de gráficos que muestran el tiempo de duración, la localidad donde tuvieron mayor relevancia y su evolución por horas. Este acercamiento brinda un primer retrato de los acontecimientos y sirve para caracterizar el panorama de la discusión en Twitter.
De este modo, con los registros de información de los periódicos digitales y los trending topics, se puede elaborar un chequeo cruzado que permite relacionar los acontecimientos que fueron noticia en la prensa escrita digital con las tendencias de Twitter. Con este procedimiento se pueden observar las hipermediaciones (Scolari, 2008), es decir, procesos de intercambio, producción y consumo simbólico desarrollado en la red. En efecto, con la revisión cruzada de los datos de las dos fuentes mencionadas se observa si aquello que fue tendencia en la red social tuvo alguna repercusión en la prensa o si, en sentido opuesto, alguna noticia fue viralizada en Twitter. En la Tabla 1 se puede ver una muestra de este procedimiento retomado de la investigación en curso5. Este registro cruzado de ambas fuentes además posibilita la generación de esquemas o diagramas que sinteticen la información para que pueda ser visualizada de una mejor forma. Por ejemplo, cuando se trata de algún acontecimiento durante un periodo de tiempo, es posible elaborar una línea de tiempo que organice la secuencia de hechos junto con los hashtags y, de esa forma, se pueda ver su evolución.
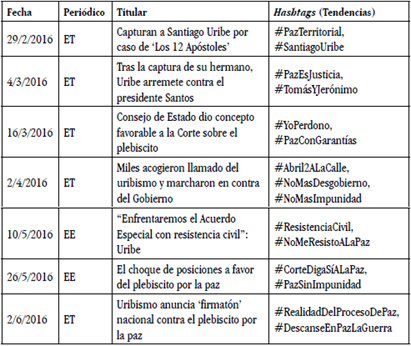
Consideraciones éticas
Antes de presentar el procedimiento de extracción y manejo de datos, es preciso referirse al aspecto ético. Un elemento clave que se tiene en cuenta en el uso de información de internet es la evaluación del grado de privacidad o apertura del entorno en línea que se pretende estudiar (Sveningsson Elm, 2009). Twitter es una plataforma de acceso público, cuyas publicaciones en los perfiles individuales o en los de otros usuarios pueden ser vistas por defecto y buscadas por cualquier persona en el mundo6. Twitter recopila los tuits de los usuarios para obtener información del contenido que ha leído, retuiteado o al que le ha dado "me gusta", el idioma y la edad, para de esa forma ofrecerles contenido personalizado (Twitter, 2020). De manera que la mayor parte de los datos que circulan en esta red social son públicos. Además, en su política de privacidad se aclara que la información compartida por los usuarios es objeto de difusión y es susceptible de ser utilizada por otros sitios web o aplicaciones para ser analizada. Tal es el caso de la API de Twitter que permite el acceso a los tuits de forma libre en ciertas cantidades con fines investigativos y de forma arancelada a gran escala para estudios de mercado.
No obstante, como afirman Page et al. (2014), el carácter público de los datos no es garantía automática de que quienes publican en determinado sitio web quieran convertirse en material de estudio. Al respecto, De Matteis (2014) arguye que los datos escritos en línea deben ser tratados con mayor precaución para proteger la identidad real de los sujetos observados, verificar si las publicaciones provienen de alguna persona o comunidad vulnerada; por lo cual es necesario detenerse y analizar si la información es sensible y puede comprometerlos, y de ser así, optar por un consentimiento informado. Por ejemplo, en el caso de perfiles de políticos, instituciones u organizaciones civiles en Twitter, se trata de información elaborada y publicada para ser difundida a la comunidad, dado que son perfiles abiertos y oficiales en muchos casos. También, cuando los usuarios emplean los hashtags en los tuits no solo se está etiquetando un tema, sino que se está conectando a la conversación con otros usuarios en lo que Zappavigna denomina searchable talk (2012, 2015) o "conversación buscable"; con lo cual el discurso puede ser encontrado, compartido, difundido y, eventualmente, estudiado.
Recolección de datos
Con las observaciones y registros producto de la etnografía virtual antes descrita se pueden reconocer las cuentas de Twitter más activas sobre los temas de interés al utilizar los hashtags que fueron tendencia y, de esa forma, no limitarse a las cuentas de los políticos más sobresalientes (a menos que el interés sea solo el de analizar esos discursos). Los datos se obtienen de modo automatizado a través de la API de Twitter, la interfaz de aplicaciones para programadores usando un script de Python. Para ello es necesario registrarse en la plataforma y obtener una autenticación en Twitter Developer, lo cual habilita la descarga de datos7. Así, se procede a la extracción y el procesamiento de los datos con Python, que cuenta con librerías abiertas especiales para el tratamiento del material de Twitter, como se puede ver en el repositorio que acompaña a este artículo8. Se extraen los datos con el paquete tweepy de Python, se lee y procesa el material principalmente con las librerías pandas, numpy y matplotlib. La API permite la descarga de aproximadamente 3200 tuits por cuenta. Los datos extraídos se presentan en texto plano y en formato de base de datos, como se muestra en la Figura 1.
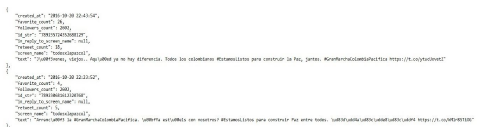
Nota: la imagen corresponde al texto sin formato que se extrae de la API. Este tipo de archivos está formado solo por caracteres legibles (excluye los símbolos alfanuméricos que dan cuenta de elementos como los emojis), pero aún carecen de formato óptimo para su comprensión.
Figura 1 Captura de pantalla de los datos como archivo de texto plano
En la exploración y el procesamiento de los datos capturados es posible encontrar de forma automática, por ejemplo, el tuit más retuiteado, el que más likes tuvo y de esa forma empezar a visualizar tópicos recurrentes y ausencias en los datos, elementos que más adelante pueden ser importantes en el análisis discursivo. Los datos obtenidos cuentan con la siguiente información: fecha de creación, número de favoritos (o likes), de seguidores, de identificación, de comentarios, de retuits, el nombre de perfil, el texto como tal y un hipervínculo si contiene algún material multimedia: imágenes o videos principalmente. A través de otra librería de Python es posible organizar los datos en tablas. No obstante, debido al gran número de datos y a que, en algunos casos, los tuits quedan cortados y con caracteres de símbolos, lo cual hace que no se puedan observar de forma integral y así se dificulta la decodificación, es necesario optar por otras herramientas de visualización, como se verá en el apartado 4.
Usando Python también es posible seguir la evolución del número de tuits durante el periodo de tiempo elegido. Así, se pueden diseñar gráficos como el del ejemplo de la Figura 2, en el cual se observa en el eje vertical el número de tuits publicados y en el eje horizontal el mes en el que fueron producidos. En este ejemplo se advierte con claridad el aumento en la producción de tuits en el segundo trimestre (desde mayo hasta julio de 2016) y luego el crecimiento exponencial en el tercer trimestre (desde agosto hasta octubre de 2016).
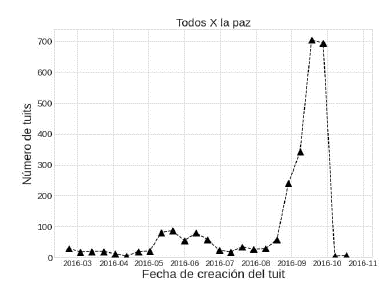
Nota: el gráfico presenta la frecuencia de los tuits durante el periodo de febrero a octubre de 2016 de una campaña plebiscitaria del perfil "Todos por la paz". En este caso se observa un número regular para los meses de febrero, marzo y abril; en mayo hay un incremento que luego vuelve a bajar y desde septiembre aumenta. El acrecentamiento final se puede entender por la cercanía a la fecha de la elección.
Figura 2 Gráfico de frecuencia de número de tuits por mes
Construcción del corpus
A continuación, y dependiendo del número de tuits extraídos, puede ser necesario hacer un proceso de muestreo, sobre todo al realizar una investigación fundamentalmente cualitativa. La selección de la muestra apunta a señalar con más detalle aquellos casos o unidades de análisis que conformarán el corpus. En primera instancia, se seleccionan las cuentas a partir de criterios inductivos relevantes para cada investigación en particular. Por ejemplo, que las cuentas hayan sido creadas en un momento determinado, que hayan tenido actividad durante ese tiempo, que sean individuales o colectivas, de perfiles oficiales o no y que tengan determinado número de seguidores (información que puede ser extraída de netnografía realizada previamente). Con la idea de no sesgar la muestra y con los perfiles seleccionados a partir de esos criterios, se propone utilizar un muestreo combinado o mixto en el cual se incluye una muestra por aleatoriedad y otra dirigida (Hernández-Sampieri & Mendoza-Torres, 2018). Por ejemplo, en Bonilla-Neira (2021) se optó por seleccionar un 20 % de los tuits al azar y los 10 tuits con más retuits (RT) de los datos. Si se tiene en cuenta que el análisis que se pretende hacer es discursivo, resulta importante conocer las voces que tuvieron más eco en los datos, es decir, aquellos tuits que más fueron compartidos. Por ese motivo, se toman en cuenta los retuits que son entendidos como heterogeneidades discursivas (Authier-Revuz, 1984; Grossmann, 2019). No obstante, el muestreo aleatorio permite mitigar el posible sesgo en los datos seleccionados. La librería pandas ejecuta la operación de muestreo de forma automática, solo se debe indicar el porcentaje de tuits que se quiere seleccionar.
En seguida, con el corpus constituido, se procede al refinamiento y a la mejora de la visualización. Como se mencionó en el apartado anterior, los datos capturados se encuentran en texto plano, es decir, sin ningún tipo de formato tipográfico ni ideogramas, de manera que para mejorar su presentación se utiliza la herramienta de visualización Open Refine. Se trata de una aplicación de código abierto (Open Refine, 2022) para limpieza y transformación de datos. Funciona como una base de datos con columnas y filas, que permite organizar y filtrar los datos, lo cual habilita su exploración en un entorno amigable, como se muestra en la Figura 3. Este software libre opera como una aplicación web local, es decir, se inicia en un servidor web y se abre en el navegador predeterminado. La herramienta permite la organización de datos al combinar, separar, agregar o eliminar columnas para mejorar su visualización. Por ejemplo, separar del texto el enlace o los hashtags incluidos y hacer otras filas para que puedan verse a simple vista. Además, las columnas tienen unas pestañas para buscar y filtrar determinada información, por ejemplo, para seleccionar palabras de interés en los tuits. Este entorno gráfico también sirve para observar los emojis y recuperar el color, con lo cual se puede apreciar mucho mejor el material. En ese sentido, Open Refine es ideal para el manejo de información como la de Twitter por el tipo de formato de texto en el que se descarga (generalmente json y cvs). En el visualizador se pueden encontrar las columnas con la enumeración de los datos, luego el texto, el número de identificación, la fecha, el nombre de la cuenta, el número de retuits, el número de favoritos y los seguidores que tenía la cuenta al momento de la descarga.

Nota: el programa toma el texto plano que se extrajo de TWitter, lo convierte y organiza en columnas con la información correspondiente. En esta captura de pantalla solo se observa la columna del texto para que se vea mejor el detalle de los tuits.
Figura 3 Captura de pantalla del entorno de Open Refine
Análisis descriptivo del corpus
Después de la construcción del corpus se da paso al análisis descriptivo, que implica hacer una revisión detallada de los tuits. Cabe recordar que los tuits son enunciados plurisemióticos complejos (Paveau, 2017) en los que es necesario apreciar las relaciones establecidas entre, al menos, los modos verbal y visual. Si bien es cierto que Twitter es una red centrada en la escritura (Squires, 2016), su algoritmo impulsa cada vez con más fuerza las publicaciones con material visual, sean imágenes estáticas o en movimiento. En la Figura 4 se puede apreciar un tuit típico de ejemplo con una radiografía básica de los elementos que lo componen. Entre sus partes se encuentran el nombre del usuario resaltado en negrilla, el identificador de usuario codificado con la @, la imagen de perfil, la fecha de producción del tuit y los modos verbal y visual que componen el tuit. El texto también puede estar acompañado por un enlace de otra plataforma, una noticia o un video.

Nota: ejemplo de un tuit compuesto por texto e imagen, en este caso un afiche. Se presentan cada uno de sus módulos: nombre de usuario, identificador, imagen de perfil, datos de producción (hora, fecha y plataforma de gestión), botones de interacción (casillas de comentario, retuit y me gusta) y tuit (con los componentes verbal y visual).
Figura 4 Radiografía de un tuit
Para este procesamiento se sugiere el apoyo de algún programa de análisis cualitativo de datos como Atlas.ti, que permite el etiquetado sistemático de forma ágil a través de códigos definidos por quien investiga. Además, es importante que en este software es posible observar los tuits junto con las imágenes si las contienen. De esta manera, se estaría considerando la forma ecológica (Paveau, 2017) del tuit, en la medida en que se atiende a más elementos del contexto en la compresión. El procedimiento de análisis que se sugiere consiste entonces en almacenar y agrupar los tuits en documentos (pueden ser Word o PDF), en este caso los tuits por perfiles, en un proyecto, también llamado unidad hermenéutica y, luego, dar paso a la codificación de estos.
En primera instancia, los tuits se pueden clasificar en cuatro categorías generales siguiendo el modelo propuesto por Gallardo-Paúls et al. (2018) de acuerdo con la estructura semiótica: texto, texto con imagen fija, texto con imagen en movimiento y texto con enlace. A su vez, dentro de la categoría "imagen fija" se utiliza la caracterización sobre el formato de Marchal et al. (2021): fotografía, que incluye las selfies, las que el usuario toma a otros; ilustración, que incorpora dibujos o caricaturas; captura de pantalla, que puede ser a la pantalla del computador o del celular, por ejemplo, de noticias o publicaciones de otras redes sociales; infografía, que consiste en la representación visual de datos, se incluyen también estadísticas, mapas o gráficas con resultados de encuestas; composición, que es una mezcla de varias categorías, por ejemplo, un collage o serie de fotos, también un meme o un video y un cartel a la vez, y afiche, que supone carteles promocionales, folletos y volantes. En la Figura 5 se observan algunos ejemplos de estas categorías y en la Figura 6 se aprecia una visualización básica en un documento de Atlas.ti. En cuanto a las imágenes en movimiento, se puede atender a categorías emergentes halladas en el corpus, tales como videos testimoniales, spots o animaciones. Sobre el texto con enlace, en algunos casos puede que se encuentre el vínculo embebido y aparezca la fotografía del portal web enlazado; en otros casos, solo se presenta la URL. Esta codificación inductiva inicial permite examinar la constitución general del corpus y reconocer las temáticas más recurrentes y los formatos en que esta se presenta.
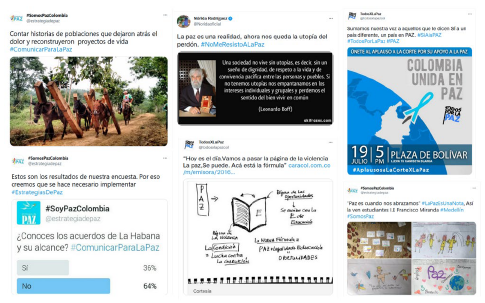
Nota: ejemplos de tipos de tuits basados en la categorización sobre el contenido visual compartido en Twitter (Marchal et al., 2021). De izquierda a derecha y de arriba a abajo, en la primera imagen se encuentra un tuit con fotografía; el segundo, cita; el tercero, afiche; el cuarto, infografía (tipo encuesta); el quinto, ilustración; sexto, composición.
Figura 5 Ejemplos de tuits con imágenes fijas
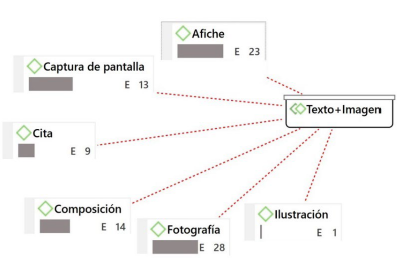
Nota: el gráfico muestra una red básica de un documento categorizado en Atlas.ti. Se observa el código: "Texto + imagen" con los subcódigos que lo componen: Afiche, captura de pantalla, cita, composición, fotografía e ilustración. La letra "E" da cuenta del enraizamiento, es decir, el número de tuits asignados con el código respectivo.
Figura 6 Ejemplo de un gráfico básico de red con Atlas.ti
En segunda instancia, debido a la naturaleza del corpus: tuits sobre un asunto público de carácter político-social, se considera importante codificarlo a partir de categorías que den cuenta de la interacción multimodal, para lo cual se utiliza la propuesta de Roque (2016, 2017). Si bien los planteamientos del autor han sido expuestos para analizar imágenes como afiches sobre la guerra o anuncios publicitarios por la evidente intención argumentativa, se tiene en cuenta que también se pueden emplear para los tuits, porque en la mayoría de los casos se presenta una interferencia entre los modos de composición. Específicamente, resulta relevante establecer una codificación balanceada de la interacción entre el encuadre verbal y el elemento visual que conforma el tuit, con el fin de comprender su funcionamiento.
Se trata entonces de distinguir cuatro tipos de interferencias verbo-icónicas, como podemos observar en los ejemplos de la Figura 7: 1) la bandera visual, visual flag (Birdsell & Groarke 2007), cuando la imagen atrae la atención hacia un argumento que se presenta verbalmente, estrategia muy utilizada en los tuits que tienen la imagen como enganche para atraer la atención de los usuarios; 2) el paralelismo, cuando tanto la imagen como el texto presentan la misma idea y se podría decir que es redundante, por ejemplo, un tuit descriptivo de una acción que se encuentra exactamente en la imagen; 3) la complementariedad o argumento conjunto, cuando los dos enunciados se complementan, aportando cada uno información importante para el sentido general del enunciado, como el caso del enunciado verbal de un tuit que indica ver lo que se encuentra en la imagen; 4) el antagonismo, cuando los dos enunciados presentan una relación opuesta, es decir, mientras el enunciado visual muestra una situación, el enunciado verbal lo niega, tal es el caso de un tuit en el que, por ejemplo, se pide que cese la violencia y la imagen es justamente una escena violenta.
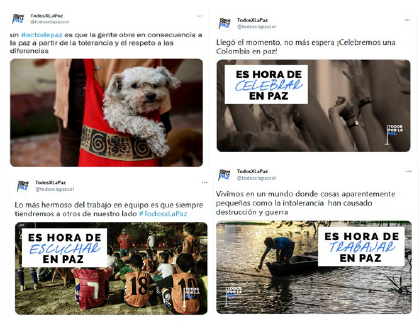
Nota: de izquierda a derecha y de arriba a abajo se encuentran ejemplos de bandera visual, paralelismo, complementariedad y antagonismo.
Figura 7 Ejemplos de funciones de la imagen en los tuits
Finalmente, se puede dar paso a un análisis discursivo exhaustivo de acuerdo con los intereses y objetivos de cada investigación. Por ejemplo, en el caso del trabajo con el que se ejemplifica este recorrido metodológico, se analiza la construcción del ethos como dimensión retórico-argumentativa, así como el registro discursivo de la violencia verbal para lo cual se emplean, entre otras, categorías de la lingüística de la enunciación y constituyentes del discurso polémico (Bonilla-Neira, 2020, 2021). Aunque con otro proceso de recolección de datos, Arrieta y Avendaño (2018), con una perspectiva sociodiscursiva y sociopragmática, analizan mensajes de Twitter de dos expresidentes de Colombia desde la metodología del análisis crítico del discurso (ACD). También, Mazucchino (2020) estudia, desde el análisis de discurso de tendencia francesa, los tuits de un expresidente y un presidente mexicanos, y describe el tuit como el sustituto actual del panfleto tradicional. En otros trabajos como el de Ventura (2021) se caracteriza la estrategia de "presentar propuestas de campaña en Twitter" en los tuits de candidatos presidenciales en Argentina, en el marco del análisis estratégico del discurso a partir del estudio de recursos gramaticales y pragmático-discursivos de los modos semióticos. De esta forma, una vez construido el corpus de análisis de tuits, se pueden hacer distintos tipos de planteamientos según sea el objetivo de la investigación.
Conclusiones
Este trabajo permitió la reconstrucción de un recorrido metodológico llevado a cabo en una investigación que integra elementos cualitativos y cuantitativos para estudiar el discurso digital en datos provenientes de Twitter. En un panorama con escasos artículos enfocados en el componente metodológico para afrontar este tipo de datos, resulta relevante facilitar esta ruta procedimental. En esa línea, este artículo detalló el tratamiento de la información, que por momentos puede ser abrumadora, razón por la cual recupera el proceso de inmersión a los datos y de construcción de un corpus manejable apto para el análisis. De esta manera, se ofreció una alternativa metodológica en la cual se presenta de forma conjunta información sobre métodos, técnicas y herramientas que pueden ser utilizadas para procesar datos de Twitter y construir el corpus.
La construcción de esta propuesta metodológica combina técnicas para la observación, como la netnografía; para la recolección, como la captura de tuits por medio de la API de Twitter, y para el procesamiento de los tuits con librerías de Python y a través de herramientas de visualización como Open Refine y análisis, como el software para el análisis cualitativo de datos Atlas.ti. La propuesta aquí desarrollada además plantea el uso de un registro cruzado de datos (noticias y tendencias) en el momento exploratorio, lo cual permite ahondar en la situación de comunicación de los acontecimientos, y propone el uso de dos clasificaciones de imágenes recuperadas de distintas propuestas, lo cual al reunirlas en una única clasificación permite catalogar los tuits en función de su relación entre imagen y texto. Asimismo, se reconoció en Twitter un espacio digital del cual se pueden tomar muestras de la discusión pública que allí se genera. Para esto se tuvieron en cuenta los aspectos éticos del carácter público del material y, al mismo tiempo, el tratamiento cuidadoso de los datos.
En síntesis, esta propuesta recupera un proceso que ha sido de idas y vueltas, y este trabajo ha permitido conectar pasos y trazar caminos para dar un esbozo del diseño metodológico que se ha estado desarrollando en una investigación doctoral que profundiza en el análisis discursivo del corpus. A partir de esa experiencia se buscó ofrecer líneas posibles para organizar un diseño de investigación con ejemplos que permiten orientar mejor el proceso en un área que aún sigue reflexionando sobre este asunto. Se espera que este procedimiento pueda servir para otro tipo de investigaciones, dado que la organización de estos recursos y su procedimiento permitió la construcción de un corpus flexible con mitigación del sesgo y preparado para su posterior análisis.
Agradecimientos especiales al Dr. Christian Sarmiento-Cano por la colaboración en el soporte computacional para el manejo de los datos y a la Lic. Noelia Stetie por el estímulo y las lecturas de los borradores que me ayudaron a mejorar la presentación del trabajo.

