











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
Permalink
Introducción
En la corriente de pensamiento emergentista (MacWhinney, 2015), la estructura lingüística emerge a partir de patrones de uso repetido en el tiempo. Los niveles del lenguaje se hallan interconexos y se adopta la visión conexionista de interrelación entre módulos permeables y emergentes. Se supone un input muy rico que permite el aprendizaje mediante mecanismos generales que abstraen propiedades estadísticas y distribucionales de dicho input. Los patrones del lenguaje surgen del uso, la generalización y la autoorganización.
En este trabajo se considera el lenguaje como un sistema dinámico, es decir, como sistema que cambia en el tiempo de procesamiento online en el momento del habla. Al aprender una lengua, el aprendiente crea variabilidad, esto es, nuevas formas ("errores") que no estaban codificadas en las condiciones iniciales del input que recibe (o en su L1). El contexto/ambiente cognitivo de producción (características de la forma seleccionada, memoria a corto plazo, motivación, similitud de rasgos con su L1, etc.) influye para que el hablante profiera formas "correctas" o "incorrectas". Por ejemplo, realizar una concordancia en un contexto de dependencia a larga distancia podría aumentar la chance de error. Cada forma constituye el resultado de un sendero continuo de activación mental que desemboca en una forma lingüística discreta proferida. Pero, a medida que pasa el tiempo, el sistema del lenguaje se adapta a los contextos y, si se producen cambios de dinámica/bifurcaciones -por ejemplo, un aumento de competencia lingüística- los errores disminuyen. Colectivamente emerge un patrón global de error. O sea que el error se constituye como un fenómeno emergente.
Las reglas que gobiernan el sistema se especifican como ecuaciones (diferenciales ordinarias no lineales). La dinámica se representa en un espacio de fase (phase space) de m dimensiones, donde se hallan todos los posibles estados del sistema, y cada estado corresponde a un único punto m-dimensional en dicho espacio. A medida que pasa el tiempo, el vector de estado cambia posición en el espacio de fase, creando así una trayectoria o flujo. Un punto fijo es aquel donde el sistema no cambia (la tasa de crecimiento es constante). En sistemas de flujos unidimensionales, un punto fijo puede ser un "atractor" (estable), un "repulsor" (inestable) o ser un "punto silla" (saddle). Un "atractor" es una región/punto del espacio de fase al cual el sistema es atraído. Por el contrario, un punto del espacio de fase del cual el flujo se aleja constituye un "repulsor". En un "punto silla", el punto fijo atrae en una dirección y repele en la otra. El conjunto de condiciones iniciales que llevan a un atractor se llama "cuenca de atracción". Una bifurcación es un cambio cualitativo en el comportamiento del sistema (Kaplan & Glass, 1995).
No existen investigaciones de modelado con sistemas dinámicos aplicados a la adquisición de lenguas segundas. Smith et al. (2018) propusieron un modelo para el fenómeno de atracción en la concordancia sujeto-verbo en L1, en inglés, focalizándose en sujetos que eran construcciones pseudopartitivas del tipo "una caja [N1] de chocolates [N2]". Utilizaron un modelo generalizado de competición de Lokta-Volterra. El sistema terminaba atraído a una configuración con el N1 (concordancia correcta) o a otra con el N2 (incorrecta). Otra vertiente de investigación son los modelos de ascenso de gradiente. Dichos modelos definen una función de "armonía" global que indica el grado de "buena formación" de los estados del sistema. Estos estados se definen en términos de configuraciones de rasgos. Los "picos" de la función se corresponden a diferentes tipos de estructuras lingüísticas simbólicas, estén bien o mal formadas. Los modelos "recorren" la función de armonía en dirección ascendente y se detienen en uno de los picos, que constituyen atractores. Debido a la acción del "ruido", el sistema puede ser empujado hacia atractores de estructuras mal formadas, o sea, ser inducido a error. En dicha dirección están los trabajos de Smith y Tabor (2018), Smith et al. (2021) y el paradigma de Gradient Symbolic Computation (Smolensky et al., 2014; Cho et al., 2017, 2018, 2020; Brehm et al., 2022). Por otra parte, se encuentran los modelos que aplican teoría de los juegos evolutiva al lenguaje. Deo (2015) utilizó dicha teoría para modelar el ciclo progresivo ("estaba comiendo") - imperfecto ("comía") en el cambio semántico diacrónico de los verbos en pasado mediante cuatro estadios/estrategias.
Aquí se propone ver las concordancias (nominales) correctas e incorrectas producidas por los aprendientes de español como lengua extranjera (ELE) como atractores de un sistema dinámico. Se intentará modelar la dinámica en las trayectorias de "activación mental" que lleven el flujo hacia alguno de los atractores. Cada punto en el estado de fase será un vector que describirá la configuración de activación "mental". Se considerará que inicialmente el aprendiente se encuentra en un estado mental "mixto" entre los posibles atractores estables; esto es, en un punto fijo inestable del cual se debe alejar para entrar en la cuenca de atracción de alguno de los atractores mencionados. Diversas características de los ítems experimentales (características del controlador nominal, si es a larga distancia, etc.) determinarán hacia cuál cuenca habrá inclinación, lo cual sesgará a su vez qué atractor resultará ganador. Esta dinámica se producirá para cada instancia de concordancia producida por el aprendiente. Los atractores serán símbolos discretos que emergen de una dinámica continua. Si en cada instancia de concordancia se aplica la dinámica, colectivamente emergerá un patrón de proporción global de error. Las variables relevantes se identificaron con ayuda de modelos estadísticos aplicados al corpus de datos. Estas formaron parte de un mecanismo de distancia a configuraciones de variables con chance de error baja, que permitió "romper" el estado mixto inicial e inclinar el flujo hacia alguno de los atractores. El error de concordancia es representado como un atractor simbólico (estado puro) que emerge de la dinámica de estados mixtos entre los diferentes atractores de estructuras correctas y erróneas. Se realizaron simulaciones para aproximar los patrones observados de error global y por series temporales a partir de datos longitudinales de cuatro aprendientes con diferente competencia en ELE.
Método
Participantes y diseño del corpus
Se utilizó un corpus de adquisición de cuatro aprendientes italianos de ELE. Se trató de cuatro alumnos adultos, de lengua nativa italiana, estudiantes del Instituto Cervantes de Milán en el año académico 2008-2009. Cada alumno poseía un nivel distinto de competencia lingüística según el Marco Común Europeo de Referencia (los nombres son ficticios para preservar la identidad de los sujetos). Se hicieron entrevistas de treinta minutos entre el alumno y el investigador (autor de este trabajo). La tarea consistió en una conversación no estructurada, sobre temas acordes al nivel de competencia del sujeto. Cada alumno realizaba simultáneamente el curso de español del nivel. Hubo entre doce y catorce entrevistas por alumno. La codificación y transcripción de los datos se hizo mediante el formato CHAT, siguiendo a MacWhinney (2021). El corpus estaba constituido por los siguientes conjuntos de transcripciones: SONIA (nivel A1/A2): 12 transcripciones; NATI (nivel B1): 14 transcripciones; JAKO (nivel B2): 14 transcripciones; MIRKA (nivel C1): 12 transcripciones.
Se extrajeron las concordancias plurales en el dominio nominal, verbal (predicativos) y en oraciones subordinadas. La concordancia se consideró asimétrica con controlador nominal. Además, siempre estaban formadas por dos términos, es decir que si hubiere más de dos, por ejemplo, las casas blancas, se codificaron dos ejemplos: las casas y casas blancas. Se clasificaron los errores del siguiente modo: (1) ausencia de error; (2) errores en el género; por ejemplo: muchos personas [Sonia, sesión 1, línea 56] (error por: muchas personas); (3) errores debidos al uso del alomorfo -es, por ejemplo: muchos trenos [Sonia, sesión 7, línea 148] (error por muchos trenes); (4) errores de plural, o sea ausencia del alomorfo -s; por ejemplo: los veneciano [Sonia, sesión 5, línea 293] (error por los venecianos); (5) errores mixtos por acumulación de los anteriores; por ejemplo: les joven [Sonia, sesión 2, línea 144] (error por los jóvenes). El conteo se hizo con el programa CLAN. Se crearon variables que caracterizaban cada instancia objetivo de concordancia en español (con independencia de que la instancia efectivamente producida contuviera o no error). Se aplicaron dos modelos estadísticos a la variable respuesta de tipos de errores: (a) un modelo multinomial bayesiano (Marafioti, 2021); (b) un modelo de riesgos competitivos utilizando el tiempo hasta que ocurre el evento "tipo de error" (Marafioti, 2022). Las siguientes variables resultaron en una disminución de la chance de los tipos de error.
Mod. Tipo de modificador del controlador. Niveles: 0 = artículo definido; 1 = artículo indefinido; 2 = determinante (adjetivos posesivos, indefinidos, demostrativos, interrogativos, exclamativos); 3 = adjetivos (calificativos, numerales, ordinales).
Fabs. La frecuencia del TYPE de concordancia. Cada TYPE especificaba el contexto de la concordancia. Por ejemplo, la instancia romanos alegres en el contexto [los romanos son muy alegres] se codificó como: [L-n-<SER>-j-os-es]. Se trata de una concordancia a larga distancia marcada por "L". Consta de un nombre ("n") luego se especifica el verbo "<SER>", seguido de un determinante "j", después vienen las terminaciones de ambos términos: "os", "es" [sin -e- epentética]. Dichas frecuencias fueron calculadas a partir del corpus de datos propios [variable Fabs_c] y de un corpus del español electrónico en línea [variable Fabs_s]. Para esto último, se apeló al corpus del español EsTenTen de Sketch Engine (Kilgarriff et al., 2014). Primero se transformaron según: Fabs_C=log(Fabs_C+1) y Fabs_s = log(Fabs_s + 1). Dado que ambas se hallaban correlacionadas, se obtuvo un índice a partir de ambas utilizando análisis de componentes principales (PCA) (Peña, 2002). Luego, dicho índice se discretizó usando clustering por mezcla de gausianas (Scrucca et al., 2016), en los niveles: 1 = frecuencia alta, 0 = frecuencia baja.
Epen. Se especificó si en el controlador, en el objetivo, o en ambos, había una desinencia que requería la inserción de "e" epentética [-(e)s]; según [ES]: 0 = sin "e" epentética; 1 = con "e" epentética en un término; 2 = con "e" epentética en ambos términos.
FamLex. Índice a partir de PCA combinando los siguientes rasgos del controlador nominal extraídos de la base de datos "BuscaPalabras" (Davis & Perea, 2005): (i) Familiaridad (FAM): índice subjetivo en escala de 1 a 7, que indica cuán frecuentemente una palabra es oída, leída o producida diariamente; (ii) Frecuencia (LEXESP): frecuencia de la palabra en el corpus "BuscaPalabras", en escala por mil; y transformada como: LEXESP = log(LEXESP + 1). Se discretizó el índice PCA mediante clustering por mezcla de gausianas, en los niveles: 1 = alto, 0 = bajo.
Morf. Se usó la distancia de Levenstein (Nerbonne et al., 2013) con el objetivo de medir la similitud entre los alomorfos de género y número plural. El algoritmo de Levenstein calcula la distancia entre dos secuencias de caracteres como el número mínimo de operaciones necesarias para transformar una secuencia en la otra. Se las discretizó mediante clustering por mezcla de gausianas, según: 0 = distancia baja, 1 = distancia media, 2 = distancia alta.
Estrategias. Se crearon atributos binarios de "estrategia" para la formación del plural: cada atributo registraba "1" en aquella instancia donde la estrategia de plural podía ser aplicada en alguno de los dos términos de concordancia (o en ambos). Dichas estrategias buscaron identificar casos que facilitaran o dificultaran la producción de concordancias. Entre estas: (a) EST1: si la palabra plural del italiano termina en -i poner en español plural en -os; (b) EST2: si la palabra plural del italiano termina en -e poner en español plural en -as; (c) EST5: si la palabra singular del italiano termina en -e, poner en español el plural en -es. Por ejemplo, la palabra sole [sol] podría ser la base para formar el plural español agregando "s": sole > soles; y el singular también, sacando "s": sole > sol; istituzione > instituciones. Se trata de casos en los cuales el español coincide con la aplicación del plural con -e- epentética.
Se recolectaron 1857 casos de concordancia en total. Sin embargo, los atributos relacionados con el controlador a veces no tenían datos registrados en la base de datos de "BuscaPalabras". Debido a ello, hubo 161 casos en los que faltaban datos en una o más de estas variables. Los casos faltantes representaron el 8.6 % de la base de datos. Se utilizó el paquete mice (Multivariate Imputation by Chained Equations) de R (Van Buuren & Groothuis-Oudshoorn, 2011), que realiza imputación múltiple. Por ejemplo, en la instancia "los alemanos" (error por "los alemanes") [SONIA, sesión 3, línea 178] el modificador es un artículo definido [Mod = 0]; se trata de una concordancia de frecuencia alta [Fabs = 1]; el plural de "alemán" requiere insertar una "e" epentética [Epen = 1], "alemán" conlleva una familiaridad / frecuencia léxica baja [FamLex = 0], la distancia con las desinencias del italiano ("i tedeschi") es alta [Morf = 2]; no es aplicable ninguna estrategia [Est1 = Est2 = Est5 = 0].
Los siguientes son los niveles de las variables asociadas a disminución de chance de error de concordancia plural, según tipo de error; halladas en Marafioti (2021, 2022): (i) adjetivos [Mod = "3"] (en errores de género); (ii) frecuencia alta de TYPE de concordancia [Fabs = "1"] (en errores de género, plural y mixto); (iii) concordancias cuyas terminaciones tienen similitud media [Morf = "1"] (error de "e" epentética y plural) y alta con el italiano [Morf = "2"] (error de plural); (iv) concordancias cuyo controlador tiene alta familiaridad y/o frecuencia léxica (errores de "e" epentética, plural y mixto); (v) concordancias en las que ambas terminaciones llevan "e" epentética [Epen = "2"] (error de plural); (vi) las concordancias en donde es posible aplicar las estrategias EST1 (error de género y mixto), EST2 (error de "e" epentética), EST5 (error de "e" epentética, mixto).
También se tuvo en cuenta, para cada instancia, la proporción de errores cometidos hasta la instancia anterior, contando desde el inicio de cada sesión. Por ejemplo, en SONIA, la primera sesión consta de las siguientes instancias: ["muchos personas" (error), "muchos pueblos" (correcto), "mucho pensatores" (error), "otros autores" (correcto)] y tiene las siguientes proporciones de errores anteriores a una instancia en cuestión: [0; 1; .5; .66]. Es decir que en "otros autores" hubo dos errores sobre tres instancias producidas antes, contando desde el inicio de la sesión.
Modelado
Las simulaciones que siguen tienen siempre dos atractores estables: "correcto" y "error". Para cada instancia se intenta recrear un sendero de "activación" en el "paisaje de eventos mentales" hasta que el sistema se acerque a uno de los atractores. Las variables especificadas en cada tipo de error se toman como un "contexto" que sesga el flujo de activación hacia uno de los atractores. Para lograr esto, se plantean diferentes mecanismos de similitud entre las variables de la instancia que se procesa y cada uno de los contextos que disminuyen el error. O sea, la idea fue combinar la lejanía a los contextos que favorecen el buen desempeño junto con los errores cometidos anteriormente, para sesgar el flujo de activación hacia uno de los dos atractores. A continuación, se detallan los modelos. El material complementario con el detalle técnico y el código de R empleado puede consultarse en github (https://github.com/pablomarafioti/PabloMarafioti/tree/master/Simulacion).
Modelo competitivo de Lokta-Volterra
Los modelos de competición de Lokta-Volterra intentan captar la interacción entre (dos) especies. Dichas especies se interfieren entre sí, disminuyendo (las unas a las otras) las tasas de crecimiento de abundancias poblacionales (Kot, 2001 ; Murray 2002). Se trata de una extensión a varias especies del modelo logístico de una especie. Sean entonces dos especies, cada una con abundancias N i, i = 1; 2. En ausencia de la otra, la abundancia de cada especie sigue un crecimiento logístico cuya tasa decrece linealmente con el tamaño poblacional. Cada especie tiene su propia tasa constante de crecimiento r 1 y su propia capacidad de carga ambtental K ¡ ("carring capacity", la máxima caracidad de "carga" del ambientefa respecto de cada especie). El modelo logístiao prescribe un sistema dinámico de dos dimensiones, mediante las siguientes ecuacionts diferenciales ordinarias:
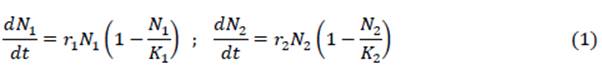
El término cuadrático representa la competencia intraespecífica, o sra, entre miembro de la misma especie. A medida que t →∞ œ, N i →K i , para Soda fabundanda inicial N 0i >0. Ahora introdúzcase un efecto de competición interespecífica, en el que ceda especie causa un decrecimiento an la abundancia de la otra especie. Ya que las especia soon diferentes, el efecto de disminución puede- ser más fuerte o más débil. Dicho efecto se represrata en dos parámetros de competencia con α ij : la "fuerza" del efecto de competencia de la especie j respecto de la especie i; α 12 y α 21, E l modelo queda:
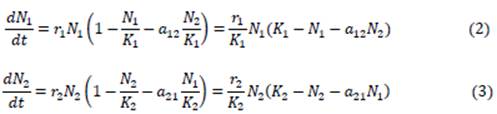
En el ámbito de la adquisición, las abundancias de las dos especies serán: (i) N
1
: la abundancia de especie " correcto "; (ii) N
2
: la abundancia de la ;a especie "error". Las nulclinas del sistema son los puntos (N
1, N
2) en los que el flujo del campo vector apunta en una determinada dirección; allí la ecuación diferencial de una determinada variable se anula:
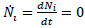 . Las nulclinas correspondientes a N
1
=0 son: (a) N
1
=0 y (b) N
1
= k
1
-a
12
N
2
Por otra partr, las nulclinas correapondientes a N
2=0 son: (c) = N
2=0 y (d) N
2=0 y (d) N
2
= K
2
-a
21
N
1
, Lo; puntos fijos(p.f.)del sistema son aquellos puntos en donde las nulclinas se intersectan entre sí o intersectan los ejes del plano de fase: p.f.e={P
1
=(0,0); P
2
=(K
1,0);P
a
=(0,K
2); P
4
=
. Las nulclinas correspondientes a N
1
=0 son: (a) N
1
=0 y (b) N
1
= k
1
-a
12
N
2
Por otra partr, las nulclinas correapondientes a N
2=0 son: (c) = N
2=0 y (d) N
2=0 y (d) N
2
= K
2
-a
21
N
1
, Lo; puntos fijos(p.f.)del sistema son aquellos puntos en donde las nulclinas se intersectan entre sí o intersectan los ejes del plano de fase: p.f.e={P
1
=(0,0); P
2
=(K
1,0);P
a
=(0,K
2); P
4
=
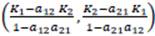 }
}
El sistema permite cuatro tipos de dinámicas posibles. Sin embargo, nos interesa el caso con dos atractores, ya que la hipótesis de este trabajo es que "correcto" y "error" atraen el flujo de la dinámica. Para dicho caso debe suceder que:
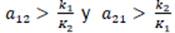 y El punto fijo interior P
4. es un nodo "silla" (inestable). El punto P
1
es un nodo repulsor (inestable) y los puntos P
2
y P
3
son nodos atractores (estables). Hay una separatrix que delimita el comportamiento de la dinámica: arriba de esta las órbitas son atraídas hacia P
2
y debajo son atraídas hacia P
3 . Las órbitas que comienzan en la separatrix (excepto el origen) convergen hacia P
4
. La competencia interespecífica es fuerte y eventualmente una de las especies gana" la otra se extingue, dependiendo de las condiciones iniciales. Se tomaron cos siguientes parámetros: r
1 = r
2= .5; α12 = α21 = 1.5; K
1
= K2 = 1. Con lo cual el punto interior "silla" fue
y El punto fijo interior P
4. es un nodo "silla" (inestable). El punto P
1
es un nodo repulsor (inestable) y los puntos P
2
y P
3
son nodos atractores (estables). Hay una separatrix que delimita el comportamiento de la dinámica: arriba de esta las órbitas son atraídas hacia P
2
y debajo son atraídas hacia P
3 . Las órbitas que comienzan en la separatrix (excepto el origen) convergen hacia P
4
. La competencia interespecífica es fuerte y eventualmente una de las especies gana" la otra se extingue, dependiendo de las condiciones iniciales. Se tomaron cos siguientes parámetros: r
1 = r
2= .5; α12 = α21 = 1.5; K
1
= K2 = 1. Con lo cual el punto interior "silla" fue
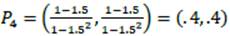 y los atractores son: P
3
= (00.1) =" error" y P2 = (1.0) = "correcto". La condición inicial del séstema se establece por un mecanismo que involucra distancias de los valores de las variables asociadas a la instancia en cuestión y loa contextos descritos. Además, se tiene en cuenta la cantidad de errores producidos hasta d momdnto de proferir la concordancia plural en cuestión (ver material complementario). La Figura 1 ilustra el espacio de faase del sistema con la recorrida del flujo para dos instancias "muchos pueblos" [SONIA, sesión 1, línea 94] y "les «difamas" -SONIA, sesión 2, línea 111]. Cada punto (N
2,
N
1
) indica un estado del sistema con las abundancias mixtas de "correcto" (Ai
1) y "error" (N
2
). Es decir que se trata de estados que indican "incertidumbre" respecto de la producción de una determinada concordancia plura". Las flecha" indican la dirección del flujo. Las rectas negras son las nulclinas y su intersección indica los puntos fijos. El círculo indica la condición inicial del sistema, determinado por el mecanismo de distancia a los contextos. Para "les idiomas" (línea punteada) la condición inicial está arriba de la separatrix, con lo cual el flujo llevará el sistema al atractor "error" (0,1). En el caso de "muchos pueblos" (línea discontinua) la condición inicial se halla debajo de la separatrix; por ende, el flujo el flujo conducirá hacia el atractor "correcto" (1,0). La Figura 2 indica las abundancias de "correcto" y "error" a medida que pasa el tiempo. Mientras que las abundancias de una especie aumentan, las otras caen a cero. Eventualmente, una especie alcanza el atractor ("correcto" o "error") y la otra "se extingue".
y los atractores son: P
3
= (00.1) =" error" y P2 = (1.0) = "correcto". La condición inicial del séstema se establece por un mecanismo que involucra distancias de los valores de las variables asociadas a la instancia en cuestión y loa contextos descritos. Además, se tiene en cuenta la cantidad de errores producidos hasta d momdnto de proferir la concordancia plural en cuestión (ver material complementario). La Figura 1 ilustra el espacio de faase del sistema con la recorrida del flujo para dos instancias "muchos pueblos" [SONIA, sesión 1, línea 94] y "les «difamas" -SONIA, sesión 2, línea 111]. Cada punto (N
2,
N
1
) indica un estado del sistema con las abundancias mixtas de "correcto" (Ai
1) y "error" (N
2
). Es decir que se trata de estados que indican "incertidumbre" respecto de la producción de una determinada concordancia plura". Las flecha" indican la dirección del flujo. Las rectas negras son las nulclinas y su intersección indica los puntos fijos. El círculo indica la condición inicial del sistema, determinado por el mecanismo de distancia a los contextos. Para "les idiomas" (línea punteada) la condición inicial está arriba de la separatrix, con lo cual el flujo llevará el sistema al atractor "error" (0,1). En el caso de "muchos pueblos" (línea discontinua) la condición inicial se halla debajo de la separatrix; por ende, el flujo el flujo conducirá hacia el atractor "correcto" (1,0). La Figura 2 indica las abundancias de "correcto" y "error" a medida que pasa el tiempo. Mientras que las abundancias de una especie aumentan, las otras caen a cero. Eventualmente, una especie alcanza el atractor ("correcto" o "error") y la otra "se extingue".
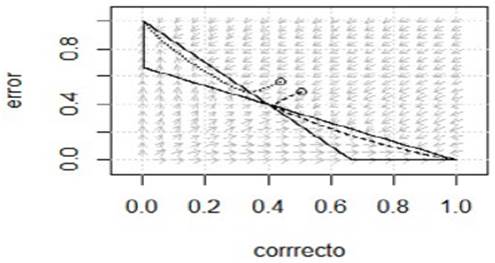
Figura 1 Espacio de fase del modelo competitivo de Lokta-Volterra. Línea punteada: flujo de "les idiomas"; línea discontinua: flujo de "muchos pueblos".
Modelo basado en la teoría de los Juegos evolutiva
Se considera un "juego de coordinación" con dos jugadores (i=1,2), cada uno "de ellos con dos esrategias puras y unti mbrta (Weibull, 1997)- El conjunto-de estrategias puras de cada uno es s
1
≠ s
2
={e
1,
e
2} donde la primea estrategia es "error" y la segunda, "correcto". La estrategía mixta -
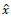 es una distribución de probabilidad sobre el conjunto de estrategias puras. Aquí
es una distribución de probabilidad sobre el conjunto de estrategias puras. Aquí
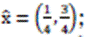 osea que los jugadores usan la primera estrategía ("error") un 25 % de la- veces (en coincidencia con el error total de los datos) y la segunda, un 75%. Hay una función de utilidad que asocia un pago a cada estrategia. Aquí, la matriz de pagos será doblemente simétrica, dada por A=
osea que los jugadores usan la primera estrategía ("error") un 25 % de la- veces (en coincidencia con el error total de los datos) y la segunda, un 75%. Hay una función de utilidad que asocia un pago a cada estrategia. Aquí, la matriz de pagos será doblemente simétrica, dada por A=
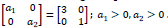 .
.
Por ejemplo, supóngase que el primer jugador corresponde a las filas y el segundo, a las columnas. Si ambos juegan la estrategia (primera fila / columna), obtienen un pago de 3. Notar que para la estrategía mixta ocurre que
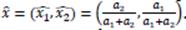 Ahora biens, existe equilibrio de Nash [EN] si un juiador supone que el otro se queda con una "determinada esrategía de una fila/columna, al otro no le ronviene pasarse de fila/columna. En A, EN =
Ahora biens, existe equilibrio de Nash [EN] si un juiador supone que el otro se queda con una "determinada esrategía de una fila/columna, al otro no le ronviene pasarse de fila/columna. En A, EN =
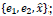 es decir que ambos deberían lugar la estrategía "correcto", "error" o la mixta. Supóngase ahora una población grande de individuos que son seleccionados aleatoriamente para jugar un juego simétrico de a dos. Cada individuo está programado para jugar las mismas estrategias mencionadas. Cada estrategía es jugada por una fracción de individuos de la población. Una estrategia se dice "evolutivamente estable" si es resistente a las perturbaciones. Osea, si otras estrategias mutantes que se introducen en la población eventualmente se entinguen porque nadie las juega. En el juego que nos ocupa las estrategia puras son estables y la mixta es inestable; Notar que si una estrategia es evolutivamente estable, entonces es un equilibrio dee Nash. Ambos conceptos suponen equilibrios estáticos. Pero supongamos ahora que cada individuo está programado para usar una estrategia pura, la cual replica a su descendencia. La dinámica del replicador muestra cómo la distribución de estrategias puras de la población cambia con el tiempo siguiendo un proceso de selección, y que dicha distribución converge a una estrategía evolutivamente estable ( punto fijo). Denótase x
1 (t) a la fracción de individuos que juega la estrategia pura "error" en el tiempo t. En consecuencia, x2(t)= 1-x1(t) será la fracción de individuos que juega la estrategia pura "correcto" en el tiempo t. Por ende, el estado de la población en t estará dado por x(t) =(x1(t),1-x1(t)). El pago promedio ("fitness") de un individuo que usa la estrategia "error" es u(e
1,x) el pago promedio de un individuo contra cualquier otro (promedio o "fitness" poblacional) es u (x,x). Las ecuaciones diferenciales para la dinámca del replicador para la matriz A son
es decir que ambos deberían lugar la estrategía "correcto", "error" o la mixta. Supóngase ahora una población grande de individuos que son seleccionados aleatoriamente para jugar un juego simétrico de a dos. Cada individuo está programado para jugar las mismas estrategias mencionadas. Cada estrategía es jugada por una fracción de individuos de la población. Una estrategia se dice "evolutivamente estable" si es resistente a las perturbaciones. Osea, si otras estrategias mutantes que se introducen en la población eventualmente se entinguen porque nadie las juega. En el juego que nos ocupa las estrategia puras son estables y la mixta es inestable; Notar que si una estrategia es evolutivamente estable, entonces es un equilibrio dee Nash. Ambos conceptos suponen equilibrios estáticos. Pero supongamos ahora que cada individuo está programado para usar una estrategia pura, la cual replica a su descendencia. La dinámica del replicador muestra cómo la distribución de estrategias puras de la población cambia con el tiempo siguiendo un proceso de selección, y que dicha distribución converge a una estrategía evolutivamente estable ( punto fijo). Denótase x
1 (t) a la fracción de individuos que juega la estrategia pura "error" en el tiempo t. En consecuencia, x2(t)= 1-x1(t) será la fracción de individuos que juega la estrategia pura "correcto" en el tiempo t. Por ende, el estado de la población en t estará dado por x(t) =(x1(t),1-x1(t)). El pago promedio ("fitness") de un individuo que usa la estrategia "error" es u(e
1,x) el pago promedio de un individuo contra cualquier otro (promedio o "fitness" poblacional) es u (x,x). Las ecuaciones diferenciales para la dinámca del replicador para la matriz A son
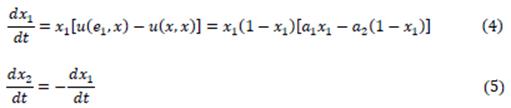
La tasa de crecimiento de la fracción poblacional de la estrategia "error" es proporcional a la diferencia entre su "fitness" y el "fitness" poblacional. Si esta diferencia es positiva, la tasa de crecimiento aumentará y habrá más individuos jugando dicha estrategia en la próxima generación, en t + dt. Ya que x
2 = x
1, se trata de un sistema unidimensional. Por lo tanto se concentrará el análisis en la primera ecuación. Sus puntos fijos serán los que hagan que x
1 = 0, lo cual sucede cuando:
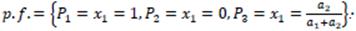
Con la condición α1>0, α2> 0, existe un nodo interior repulsor P
3, que coincide con la probabilidad de la estrategia "error" del equilibrio de Nash mixto
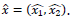 Recuérdese que en el juego de coordinación la estrategia mixta
Recuérdese que en el juego de coordinación la estrategia mixta
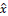 no es evolutivamente estable (es un euilibrio inestable ). Si la condición inicial
no es evolutivamente estable (es un euilibrio inestable ). Si la condición inicial
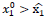 , el flujo es atraído al punto fijo estable P
1= 1 (gana la estrategia "error": e
1) Por otra parte, si la condición inicial
, el flujo es atraído al punto fijo estable P
1= 1 (gana la estrategia "error": e
1) Por otra parte, si la condición inicial
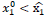 el flujo es atraído al punto fijo estable P
2= 0 ( gana la estrategia "correcto" : e
2 ). Por lo tanto, las cuencas de atracción (CA) (basin of "attraction") de ambos atractores son CA (P
1) = (
el flujo es atraído al punto fijo estable P
2= 0 ( gana la estrategia "correcto" : e
2 ). Por lo tanto, las cuencas de atracción (CA) (basin of "attraction") de ambos atractores son CA (P
1) = (
 , 1) y CA (P
2) = (0,
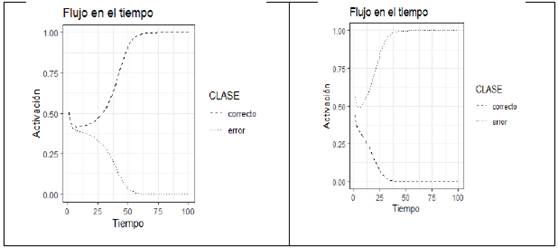
): La figura 3 ilustra, a la izquierda, el flujo en el tiempo para el ejemplo lo "estudios" [SONIA, sesión 4, línea 179]. A la derecha se muestra el espacio de fase del modelo. Ya que
, 1) y CA (P
2) = (0,
): La figura 3 ilustra, a la izquierda, el flujo en el tiempo para el ejemplo lo "estudios" [SONIA, sesión 4, línea 179]. A la derecha se muestra el espacio de fase del modelo. Ya que
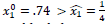 , el flujo escapa del punto inestable interno y se dirige al punto fijo estable de la estrategia pura de "error".
, el flujo escapa del punto inestable interno y se dirige al punto fijo estable de la estrategia pura de "error".
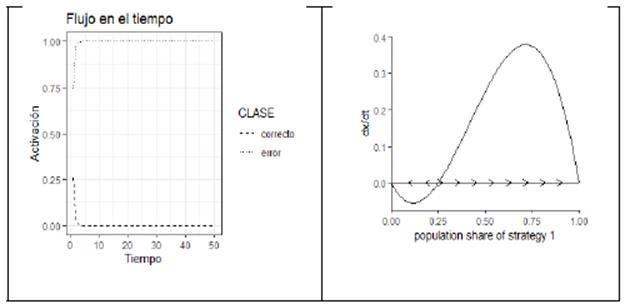
Figura 3 Flujo en el tiempo para la instancia "los estudio" (izquierda) y espacio de fase del modelo (derecha).
2.2.3 Modelo de ascenso de gradiente de armonía
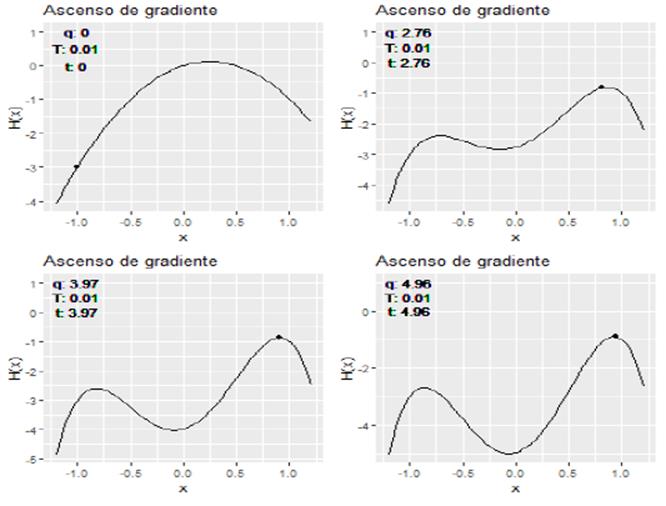
En el paradigma de Gradimt Symbolic Computation se postulan sistemas dinámicos estocásticos para tiempo y estados continuos. Se construyen gradualmente estructuras simbólicas discretas (atractores) a partir de un espacio de estados continuo. Considérese un modelo para una dimensión donde la variable "x" constituye un continuo Oe activación entre [-1,1].En los extremos "x" representa dos estados "puros" o atractores discretos: x= -1 es el símbolo "correcto" y x = 1 representa el símbolo "error". Los valores de x Є (-1,1 ) son estados "mezcla" entre ambos símbolos. Se desea que el sistema comience en un estado arbitrario y la activación vaya, hacia alguno de los estados "puros". Al inicio, la función de armonía H (x,q,e) tiene un único atractor que representa dicho estado "mezcla", intermedio entre "error" y "correcto". A medida que el parámetro q Є [0, 5] cambia, se produce una bifurcación y aparecen dos atractores estables. Por otro lado, el produce e Є [-1, 1] es el valor que sesga el flujo hacia alguno de los atractores. Se lo calcula mediante un mecanismo de similitud a los contextos ya especificados (ver material complementario). A medida que pasa el tiempo, el sistema escala el gradiente de la función de armonía 𝛻 x H(x,q,e) para terminar cerca del pico de alguno de los dos atractores. sin embargo, si el ruido es grande, el sistema podría, por ejemplo, terminar en el atraOtor "error" aunque estuviera sesgado hacia el atractor "correcto". El modelo estocástico se muestra en (6); la función de armonía, en (7) y su gradiente, en (8). En (6) W es el proceso de Wiener, T es d nivel de ruido (que puede ser constante o decrecer con el tiempo de modo exponencial) y 𝛻 x es el gradiente de la armonía total evaluada en valor de activación "x". tl primer término es el determinístico (drift) y el segundo es la parte estocástico.
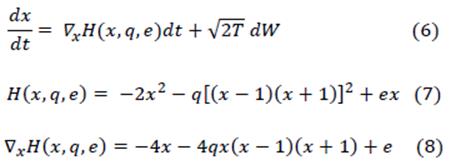
Ahora bien, supóngase e = 1; es decir que el sistema está sesgado hacia el atractor "error" (si e = 0 no h=y sesgo). La Figura 4 ilustra el comportamiento del sistema a medida que cambia el parámetro dinámico "q". Si q = 0 la "superficie" de armonía tiene la forma de una parábola con máximo global en x = ¼. Por lo tanto, dicho máximo es el único atractor y representa un estado "mezcla", intermedie" entre "error" y "correcto", con un poco de sesgo hacia el "error". Si se aumenta el valor de "q", se observará que aparecen dos máximos locales. Ha sucedido una bifurcación y se ha pasado de un atractor a sos atractores. A medida que "q" sigue aumentanto, el "valle" entre ambos máximos locales se hace más "profundo'. El sistema "escalará" el gradiente de armonía y eventualmente se aproximará x = ", el atractor del ""error". Si la cantidad de ruido T que se agrega a la parte determinística de la ecuación es pequeño, será difícil que haya valores que estén atraídos hacia el atractor "correcto" y superar "hacia atrás" el valle entre los máximos locales.
Resultados
Globalmente, el patrón de error fue: JAKO < SONIA < MIRKA < NATI. El porcentaje dd error en todo el corpus fue del 24.7 %. En primera instancia se presentan los resaltados de la simulación con el modelo competitivo de Lokta-Volterra. La Tabla 1 muestra: (i) las proporciones globales de "error" entre la simulación y los dados; (ii) los p-valores de un test asintótico de diferencia entre proporciones entre los errores simulados y los errores de los datos (se debería observar que p > .05); (iii) los valores de la distancia de Minkowski D =
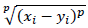 (p = 3), ente los errores simulados y reales para la serie temporal de errores por sesiones ((a menor distancia, mejor).
(p = 3), ente los errores simulados y reales para la serie temporal de errores por sesiones ((a menor distancia, mejor).
Se observa que SONIA y MIRKA subestiman el error global y JAKO lo sobreestima. Sin embargo, las diferencias entre las proporciones de errores no resultan significativas. En cuanto al patrón por sesiones, SONIA retiene el mejor desempeño; MIRKA, el peor; y NATI y JAKO se aproximan de igual modo a las series de tiempode los datos. El error se simulación total promedio es
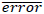 = .245, muy cercano al real. Por otro lado, la distancia promedio arrojada
= .245, muy cercano al real. Por otro lado, la distancia promedio arrojada
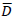 = 11.301.
= 11.301.
En lo que atañe al modelo basado en dinámica del replicador, en la Tabla 2 se observa que SONIA y MIRKA subestimen al error y que JAKO lo sobreestima. No obstante, las diferencias entre las proporciones de error no arrojan significatividad. En lo que respecta al patrón por sesiones, la distancia D aumenta con el nivel. SONIA resulta ser la mejor desempeño; MIRKA obtiene el peor; y NATI/JAKO aproximan las proporciones de error por sesiones de manera similar. El error de simulación total promedio
= .241, muy cercano ala real. Por otro lado, la distancia promedio arroja
= 12.961.
En lo concerniente al modelo basado en ascenso de gradiente de armonía, la Tabla 3 muestra: (i) la media de las proporciones de error extraídas de n = 50 simulaciones; (ii) su error estándar (ee = s/√𝑛 () ; (iii) la proporción de error en los datos; (iv) la frecuencia relativa de veces (en 50 simulaciones) en las que los p-valores de un test asintótico de diferencia entre proporciones entre los errores simulados y los errores de los datos son menores a .05 (o sea que habría diferencia significativa entre el patrón global simulado y el de los datos); (v) la distancia media D para medir la distancia entre el patrón por sesiones simulado y real. En el patrón global, las simulaciones que más se acercan, en media, son las de JAKO y MIRKA. Se observa que las proporciones simuladas varían muy poco. En general, no hay diferencias significativas entre las proporciones simuladas y las reales. En el patrón por sesiones, SONIA es la que mejor aproxima el patrón real. Los otros tres aprendientes evidencian un desempeño similar. Notar que este modelo es el que mejor aproxima el patrón por sesiones para MIRKA.
Conclusiones
Si cada concordancia fuera un "individuo" que toma decisiones de acuerdo con la dinámica de los modelos especificados; entonces, a partir del conjunto de dichas decisiones emerge un patrón global de error y otro por serie de tiempo. Es decir que los patrones de aprendizaje se autoorganizan y emergen de la dinámica ejercida por los individuos. En general, los modelos aproximan bien los datos globales de error reales. En cuanto a la aproximación a las series de sesiones reales, SONIA, NATI y JAKO obtienen un mejor desempeño con el de Lokta-Volterra, y MIRKA alcanza un resultado de menor distancia media (D) con el modelo de ascenso de gradiente. Comparativamente, MIRKA resultó la de peor desempeño en todos los modelos. Todos los modelos dinámicos analizados consideraban al error como atractor que se alcanzaba (o no) en el último paso temporal. Es decir que el error se trató como una representación continua y solamente al final, en el atractor (o cerca de este), como una representación discreta. Por lo tanto, «Error» o «Correcto» son propiedades emergentes de los sistemas dinámicos, al igual que los patrones globales de error agregados y por series temporales. Asimismo, la cognición no es vista como una maquinaria representacional que procesa información y está guiada por una sintaxis computacional. En cambio, se adscribe a una concepción en términos de un flujo continuo de procesos. La mayoría de los formalismos de la teoría lingüística (minimalismo, gramáticas a unificación, etc.) están pensados para la sincronía, donde las distribuciones de probabilidad de los patrones se han estabilizado. No parece útil aplicarlos a la adquisición, donde la lengua se encuentra en flujo constante. Las ciencias de la complejidad iluminan otro camino: pasar de teorías que manipulan símbolos discretos a otra donde lo importante es un flujo de estados "mezcla" con patrones/configuraciones que modifican sus distribuciones de probabilidad hasta alcanzar atractores discretos estables. Si se considera el lenguaje como un flujo no lineal, continuo, fractal y adaptativo, entonces las técnicas de análisis deben pasar por las series de tiempo (no lineales), el análisis de la variabilidad y cambios de régimen, los estudios longitudinales y las simulaciones.

