











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Introducción
En los últimos años, los sistemas de traducción automática (en adelante, TA) han transformado profundamente el mundo de la traducción y se han incorporado cada vez más a la vida cotidiana de las personas, que los utilizan con distintos fines. La TA, tanto de tipo estadístico como neuronal, lejos de amenazar el trabajo de los traductores, se ha convertido en una ayuda que en muchos casos simplifica el trabajo de estos profesionales, ya que permite traducir una gran cantidad de textos en muy poco tiempo. Los traductores suelen utilizarla profesional y académicamente, y se emplea cada vez más en el contexto de la enseñanza/aprendizaje de las lenguas extranjeras. En este último ámbito suele aprovecharse sobre todo en los niveles altos, para desarrollar actividades de traducción, de análisis de las traducciones y de posedición; se trata de actividades muy útiles que estimulan la reflexión y amplían el conocimiento tanto sobre la lengua que se está aprendiendo como sobre la lengua materna de los estudiantes (Loock et al., 2022; Zhang & Torres-Hostench, 2019; Niño, 2009; Conde, 2018).
A pesar de las muchas ventajas que ofrecen estos sistemas (entre ellos, acortar considerablemente los tiempos de traducción, reducir los costes, disponer de cierta autonomía en el proceso de traducción), no hay que infravalorar algunos problemas relacionados con la calidad del producto final, que presenta a veces falta de coherencia y algunas imprecisiones. En especial cuando se trata de determinadas combinaciones lingüísticas, estos sistemas están menos entrenados, y el producto final puede presentar desaciertos, por lo que se hace necesario un proceso de evaluación de aspectos teóricos y prácticos. Puede ocurrir, de hecho, que estos sistemas no consideren ni el contexto cultural ni el destinatario del texto meta, lo que conlleva la pérdida de algunos matices culturales y la falta de adecuación a los códigos culturales del país de destino, además de posibles incorrecciones gramaticales. En el campo teórico, las investigaciones se han focalizado sobre todo hacia lenguas como el inglés, mientras que el análisis de las traducciones entre lenguas romances, como las que nos ocupan aquí, presenta estudios aún exiguos, por lo que es preciso seguir investigando en este ámbito (Valdez & Lomeña, 2021; Oliver, 2020; Vergés & Costa-jussà, 2020). De ahí nuestro interés por estudiar la traducción entre dos lenguas próximas, en el contexto del turismo temático, concretamente en el gastronómico y el enológico.
Nuestro objetivo es analizar el tipo de traducciones propuestas por el motor DeepL centrándonos en los realia o culturemas para observar cómo se trasladan de una lengua/cultura origen a una lengua/cultura meta.
Después de una breve descripción de las investigaciones sobre la TA y el proceso de evaluación, se trazan las principales características del lenguaje turístico abordando el tema de la traducción de los culturemas. En el análisis se observan las propuestas del motor DeepL y se comparan con la traducción publicada en la página web de la que se ha extraído el corpus. Se analizan los errores que intervienen en la traducción automática neuronal del español al italiano con el fin de descubrir si existe una tipicidad de errores en el ámbito específico que nos ocupa y, de este modo, contribuir a los estudios que se dedican a la TA entre lenguas próximas.
Nuestro objetivo es contestar a las preguntas de investigación siguientes: el motor de traducción DeepL, en su versión de libre acceso en línea, ¿alcanza un nivel de correspondencia que mantiene el contenido informativo y comunicativo del texto de salida?; en caso de errores, ¿cuál es su tipología?; ¿qué tipo de traducciones ofrece en el par de lenguas y en el campo de nuestro interés? Para formar nuestro corpus hemos acudido al portal oficial de turismo de España (https://www.spain.info/es/) y para traducir los fragmentos seleccionados se ha empleado la versión en línea gratuita de DeepL.
Marco teórico
A continuación, se presentan algunos conceptos básicos sobre la TA y sobre los métodos de evaluación más empleados; después, se describe el motor DeepL y, finalmente, se esbozan las principales dificultades que entraña la traducción del turismo.
La TA y su evaluación: conceptos básicos
Sánchez y Rico (2020, p. 1) definen la TA "como la aplicación de la tecnología informática a la traducción de textos de una lengua a otra sin intervención humana". Desde su comienzo hasta los años noventa del siglo pasado el sistema utilizado era el basado en reglas, que usaba gramáticas y diccionarios para analizar el texto de origen y generar el correspondiente texto meta (Monti, 2019). Se trata de sistemas que sustituyen las palabras de la lengua de partida por equivalentes de la lengua meta (Díaz, 2012) y en este patrón entran los sistemas directos, los indirectos y la interlingua. Como se usan listas/grupos de palabras, la traducción es literal, lo que causa muchos errores; además, no se lleva a cabo un análisis sintáctico y tampoco se selecciona siempre el sentido correcto de las palabras que tienen más acepciones (Díaz, 2012).
Los sistemas indirectos nacen para intentar solucionar este tipo de problemas: a la hora de analizar el texto de salida integran reglas lingüísticas (morfológicas, sintácticas, semánticas) y lo examinan en módulos diferentes antes de producir el texto meta, creando un pasaje intermedio. Hay dos tipos de estrategias indirectas: la transferencia y la interlingua. Los sistemas basados en la transferencia analizan el texto de partida, crean una representación abstracta de él y después hacen una representación abstracta del texto de llegada, que permite establecer equivalencias de tipo sintáctico, léxico, semántico; gracias a esta información, finalmente generan el texto final (Tertoolen, 2012). Este sistema, por tanto, crea una representación intermedia de las dos lenguas y necesita glosarios monolingües (para los aspectos gramatical, morfológico y semántico) y bilingües (para la equivalencia léxica entre lenguas). También el sistema de la interlingua se basa en reglas lingüísticas, pero aquí el texto se convierte a un lenguaje intermedio, independiente de la lengua de partida y de la lengua de llegada. De esta forma, se pueden añadir módulos de distintas lenguas y se puede traducir de la lengua origen a la lengua meta y viceversa.
Gracias al avance de Internet, a partir de los años ochenta del siglo pasado aparecieron otros sistemas con planteamientos muy empíricos acerca del problema de la traducción: el basado en ejemplos, el estadístico y, finalmente, el neuronal.
El primer tipo, basado en ejemplos, utiliza corpus de textos bilingües alineados al nivel de la frase. El sistema busca equivalencias y relaciona la frase del texto origen con los ejemplos/segmentos que aparecen en el corpus para luego traducirlos. Recupera de una base de datos bilingüe traducciones realizadas anteriormente, pero el traductor (humano) no puede intervenir en el proceso de traducción, de modo que no puede elegir entre diferentes traducciones. El segundo tipo de sistema, el estadístico, que durante muchos años ha sido el modelo dominante en TA (Bing, Google Traductor o Moses), emplea corpus de textos que ya han sido traducidos y que están disponibles en Internet; las frases o los grupos de palabras de los textos en la lengua de salida se alinean con sus equivalencias traducidas, para después calcular la probabilidad de que una palabra determinada sea la equivalente de otra en el texto original. Se trata de un enfoque basado en datos (data-driven) y técnicas de aprendizaje (machine learning), y en el principio de la probabilidad de distribución cp(e |f), donde e en la lengua meta es la traducción estadísticamente más frecuente de un segmento textual fen la lengua origen (Monti, 2019). Hay que adiestrar estos sistemas con datos voluminosos, como corpus paralelos y monolingües, que operan como modelo traductivo y se utilizan para computar en la lengua de llegada las traducciones más frecuentes de términos o secuencias de términos en la lengua origen.
Tras la aparición de la traducción automática neuronal (TAN) en el mercado, el panorama de la traducción ha cambiado profundamente. Estos sistemas se basan en modelos matemáticos que, con neuronas artificiales, reproducen una red neural biológica (Monti, 2019). Varias investigaciones (Hasler et al., 2018; Michon et al., 2020) demuestran que los sistemas de traducción neuronal suelen producir mejores traducciones que los basados en la estadística. No obstante, sin querer subestimar la gran calidad alcanzada por la TAN en la actualidad, sus resultados aún no cubren algunos dominios específicos que se utilizan a menudo en el sector de la traducción. Por ejemplo, algunos estudios (Macketanz et al., 2017; Haque et al., 2019) sugieren que la TAN presenta menor eficacia en la traducción de los términos específicos de un dominio en comparación con la traducción automática estadística (TAE). Como la TAE, también la TAN emplea corpus paralelos o monolingües específicos del dominio para aprender términos específicos de este (Farajian et al., 2018); sin embargo, a menudo un dominio puede ser demasiado restringido y carecer de datos necesarios para entrenar un motor neuronal. Otro aspecto es que las memorias de traducción representan datos de entrenamiento preparados para usarlos en la adaptación del sistema neuronal a un dominio determinado, mientras que las bases de datos terminológicas son más complicadas de manejar, situación que ha dado lugar a la creación de varias propuestas de métodos con el objetivo de integrar la terminología perteneciente a un dominio específico en la TAN en tiempo de ejecución (Dinu et al., 2019; Hasler et al., 2018; Michon et al., 2020).
Hoy en día conviven la TA basada en reglas, la TAE y la TAN, e incluso han originado sistemas híbridos, que emplean enfoques del sistema estadístico y del sistema basado en reglas (Monti, 2019). A pesar de algunas limitaciones, la TAN ha transformado el mundo de la traducción, simplificando en muchos casos la tarea de los traductores ya que ha ido tanto ampliando -gracias incluso a los estudios teóricos-el nivel de calidad como reduciendo el tiempo de posedición.
Como se ha mencionado, un aspecto estrechamente relacionado con la TA es el que atañe a la calidad de las traducciones. Como señalan Sánchez y Rico (2020), el de la evaluación de la TA es un tema complejo, ya que el concepto de calidad puede variar de acuerdo con el encargo, con el tipo de traducción, con la situación comunicativa a la que el texto está enfocado, etc.
Sintetizando, podemos afirmar que en la actualidad se dispone de dos procedimientos para medir la calidad de la TA, los sistemas o métodos automatizados, de tipo cuantitativo, y la evaluación realizada por traductores humanos, de tipo cualitativo; la elección de un método u otro suele depender del tipo de texto que se necesita evaluar y de su función. La evaluación humana ha empleado criterios de adecuación, comprensión y fluidez. Luego, se han incorporado métricas que evaluaban los errores de traducción (Monti, 2019). Entre las técnicas de evaluación humana, las más empleadas son la clasificación de errores (que a menudo va asociada a explicaciones o comentarios), la clasificación de frases, la ordenación de oraciones y la evaluación con posedición. Sin embargo, este tipo de evaluación presenta algunos aspectos negativos como el tiempo requerido, el aumento de los costes y la subjetividad de estos. Los métodos de evaluación automatizados permiten una evaluación muy rápida y objetiva, pero que se limita a las formas superficiales de las palabras. Entre las principales medidas automáticas Zhang (2019) señala BLEU, NIST, METEOR, WER, TER y PER; a pesar de que se hayan desarrollado varios sistemas de métricas para evaluar la TA, no siempre se han considerado suficientes y se ha recurrido a la evaluación humana. La elección de uno u otro tipo de evaluación dependerá de distintos factores como, por ejemplo, el funcional: si la evaluación automatizada de la traducción automática puede utilizarse para las traducciones informativas, sin que intervenga el traductor, lo mismo no puede decirse para los textos que se necesitan publicar, ya que a menudo requieren la intervención del traductor después del proceso automático.
DeepL
Se trata de uno de los sistemas de traducción automática neuronal más conocidos, con una interfaz simple e intuitiva, lanzado en su versión gratuita en agosto de 2017 por la empresa alemana DeepL GmbH. La plataforma, que nació como sistema de base estadística y luego se reconvirtió en neuronal, apareció en Internet varios años después de Google Translate, que se lanzó en 2006. Desde marzo de 2018 la plataforma cuenta con una versión de pago de mayor rendimiento, DeepL Pro, que les permite a los usuarios usar un traductor web optimizado (traduce textos que superan las 5000 palabras, guarda las traducciones para retomarlas en otro momento, ofrece la función de tono formal o informal), y admite integrar los algoritmos en su software de traducción o desarrollar nuevas aplicaciones y servicios con la API de DeepL. Por lo que a la versión gratuita se refiere, uno de los límites del sistema es que, una vez efectuadas unas cuantas traducciones, deja de funcionar y es necesario abonarse. Además, solo gestiona los formatos .docx, .pptx,.txt y .html. El documento traducido puede descargarse en el ordenador y haciendo clic sobre una palabra aparece un glosario con otras posibles traducciones, lo que le permite al traductor intervenir en el proceso traductivo y, dependiendo del contexto y cotexto, elegir la que considere más apropiada entre las opciones propuestas. En la actualidad, el sistema puede traducir 31 lenguas, basándose en la experiencia de Linguee -diccionario en línea que emplea corpus paralelos multilingües integrados por traducciones hechas a partir de textos alineados en la web- y en los algoritmos de la inteligencia artificial y el aprendizaje automático ya utilizados. Al sistema de inteligencia artificial, también llamado aprendizaje profundo -deep learning- que dio el nombre al sistema, se añaden nuevos algoritmos de traducción y un sistema de redes neuronales que guarda los datos y sigue aprendiendo, de forma que los mismos errores aumentan las redes neuronales artificiales y mejoran las traducciones. Por consiguiente, las traducciones en línea de DeepL son fruto de una combinación de algoritmos de aprendizaje automático altamente especializados y de redes neuronales convolucionales, así como de una exorbitante base de datos de traducciones antiguas y de búsquedas en línea que entrenan el motor de traducción e incrementan incesantemente su rendimiento. A esto se añade un equipo de especialistas que controlan y corrigen los errores en el código, lo que también permite mejorar las traducciones.
La traducción del turismo gastronómico y enológico
El sector del turismo es clave para los dos países que interesan este estudio, España e Italia, ya que mueve una economía importante. Por lo que se refiere al turismo que de Italia se mueve hacia España, los datos dicen que en 2022 visitaron este país algo más de 4 millones de italianos y que el gasto total de Italia fue de 3533 millones (Ministerio de Industria, Comercio y Turismo, 2023). El sector del turismo genera empleo y riqueza en distintos ámbitos, incluido el de la traducción, fundamental para que se produzca una buena comunicación entre los turistas y la parte que ofrece los servicios. Traducir y localizar a distintos idiomas los productos turísticos con calidad es esencial para proporcionar una imagen positiva del país y así atraer al turista y ayudarlo a crear una experiencia positiva. En los últimos años, además, ha ganado terreno un tipo de turismo específico, el gastronómico y enológico, que busca conocer la cultura y los alimentos típicos de una zona determinada. Por ello, cada vez es más frecuente encontrar guías y páginas web que se dedican a esta forma de turismo, como también ocurre en el portal del que hemos obtenido nuestro corpus. Se trata de textos de distinto tipo: portales de Internet, guías, videos de presentación, folletos, descripción de cursos, etc., que necesitan una traducción precisa, que sea coherente con los usuarios del texto meta. El turismo en general representa una realidad muy heterogénea y amplia en el ámbito textual (Calvi, 2019); de ahí que su traducción se haya abordado en muchos estudios de investigación y desde múltiples perspectivas (Calvi, 2006, 2010; Marangon, 2014-2015). Según Calvi (2019), esta diversidad lingüística y cultural conlleva el empleo de distintas modalidades de traducción (...): 1) la traducción intralingüística, 2) la mediación intercultural, aplicada, en particular, al léxico y 3) la traducción interlingüística propiamente dicha, con especial referencia a la difusión de la información en diferentes lenguas. (p. 74)
En el ámbito que nos ocupa, cabe esperar la aparición de muchos realia o culturemas, es decir, palabras que denotan objetos, aspectos y conceptos típicos de una cultura. Según Nord (1997, p. 34) un culturema es "un fenómeno social de una cultura X que es entendido como relevante por los miembros de esa cultura y que, comparado con un fenómeno correspondiente de una cultura Y, es percibido como específico de la cultura X". Se trata de elementos de distinto tipo que pueden aparecer en el texto y que se relacionan con ámbitos heterogéneos. Según la clasificación de Newmark (1992), pueden relacionarse con la ecología (flora, fauna); con la cultura material (objectos, productos, artefactos), que incluye comida y bebida, ropa, casas y ciudades y transporte; con la cultura social (trabajo, recreo); con las organizaciones, costumbres, actividades, procedimientos y conceptos de tipo políticos y administrativos, religiosos y artísticos; y con gestos y hábitos.
La traslación de estos elementos de una lengua y una cultura de origen a otra meta supone cierto nivel de dificultad, y para traducir un culturema no existen "soluciones unívocas ni técnicas características (...) sino una multiplicidad de soluciones y de técnicas" (Hurtado, 2001, pp. 614-615), en función del contacto entre las dos culturas, del género textual en el que se inserta, de la función del culturema en el texto original, de la naturaleza del culturema y de la finalidad de la traducción. Newmark (1992) propone una serie de procedimientos de traducción para trasponer estos elementos (transferencia, equivalente cultural, traducción literal, neutralización, o sea, equivalente cultural o descriptivo, etc.). Durán (2012), retomando la distinción de Hurtado (2001) entre problemas y dificultades de traducción, señala los principales problemas y dificultades de la traducción de textos turísticos. Entre los problemas destaca la subordinación de la traducción turística y la falta de información para el traductor, la presencia de frases ambiguas o de doble sentido, la aparición de culturemas, el lenguaje positivo y poético constante y el lenguaje confuso del texto de origen. Entre las dificultades de traducción de los textos turísticos engloba los nombres propios de personas, museos, instituciones, etc., los topónimos, la traducción inversa, los neologismos, la escasez de fuentes de referencia (Durán, 2012). Como puede verse, al ser la lengua del turismo un lenguaje de especialidad (Calvi & Mapelli, 2011), requiere una traducción especializada que implica varios retos.
La metodología
Para crear nuestro corpus hemos extraído los textos de un portal de una institución pública, https://www.spain.info/es/, que promueve el turismo en España y proporciona información detallada sobre los diferentes tipos de turismo que es posible hacer en este país. Las páginas webs son un macrogénero textual, caracterizado por una hibridación de géneros, tipologías textuales, estilos, etc. (Calvi, 2010). En nuestro caso, se trata de una página muy dinámica y articulada; en ella aparece una sección llamada qué hacer, que incluye varias posibilidades: arte y cultura, costas y playas, turismo urbano, naturaleza, gastronomía y enología, deporte y aventura, compras y rutas. Los textos se han extraído de la sección gastronomía y enología, y promocionan los distintos lugares de España a través de su gastronomía. Se trata de textos de tipo persuasivo, en los que conviven la función apelativa y la informativa. En ellos hay una copiosa adjetivación y un léxico relativo a la percepción (saborea, prueba, etc.). Además, como ha señalado Durán (2012, p. 108), aparece un "lenguaje lleno de connotaciones y valoraciones positivas" para que el potencial turista se sienta atraído; también se han localizado elementos poéticos, los culturemas, los topónimos, los nombres de museos, calles, monumentos, etc.
En total, se han extraído 25 textos por un total de 14 902 palabras de la versión española. En primer lugar, para facilitar su procesamiento, a medida que se iban extrayendo los textos de la web, se iban insertando en un archivo Word, y se eliminaban los elementos que pudiesen dificultar la traducción, como símbolos, hipervínculos, imágenes, etc. Sucesivamente se han extrapolado de la página web las traducciones en italiano de los mismos textos, para la posterior comparación con el texto procesado en DeepL. En segundo lugar, se han introducido los textos en DeepL para su traducción al italiano. Este motor, en su versión gratuita, permite traducir como mucho 5000 palabras a la vez, motivo por el cual en algunos casos los textos se han dividido y se han cargado en el motor en dos o más partes. La traducción que se considera para nuestro análisis es la primera que proporciona el motor de traducción, a pesar de que DeepL ofrece la posibilidad de elegir entre traducciones alternativas. La traducción se ha guardado en un archivo Word y luego los textos en español y las respectivas traducciones al italiano se han alineado con LF Aligner1 y exportados a un archivo XLS para poder analizar y evaluar la traducción. Por último, se ha llevado a cabo el análisis de tipo comparativo entre las dos traducciones a través de una evaluación humana de los textos traducidos automáticamente. Para evaluar la calidad de la traducción automática, nos hemos ceñido a algunos aspectos; además de los criterios de la adecuación pragmática y funcional, hemos observado elementos que consideramos fundamentales, "como son la legibilidad del texto meta, es decir, la claridad y la comprensibilidad, coherencia y cohesión que muestra el texto de llegada en su totalidad; la corrección gramatical en cuanto a las normas gramaticales, ortográficas y ortotipográficas de la lengua de llegada (...)" (Durán, 2012, p. 105). Una vez analizados los errores y su tipología, se ha podido cotejar la traducción con la publicada en la página web y se ha podido evaluar su calidad.
Resultados y discusión
Una vez finalizado el proceso de traducción y de análisis se han establecido seis categorías de errores: calcos o traducciones literales, errores morfosintácticos, errores terminológicos, omisiones; traducciones erróneas y términos sin traducir. Los porcentajes de estos se presentan en la Figura 1:
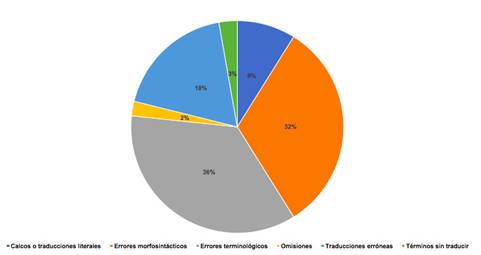
Establecer estas categorías no ha sido una tarea fácil, debido al hecho de que a veces una tipología de error puede interesar a categorías diferentes, ya que un mismo error puede considerarse terminológico y, al mismo tiempo, de traducción. En la categoría errores morfosintácticos se han englobado diferentes tipos de errores, como los relacionados con el uso de las clases de palabras, el orden de los elementos oracionales, la falta de concordancia, además de puntuación. No obstante, a la hora de evaluar la traducción con DeepL, se ha observado que se mantiene la adecuación pragmática y funcional, y casi siempre la legibilidad así como la coherencia y cohesión.
La primera desigualdad entre las dos versiones de la traducción se ha encontrado en la elección del pronombre personal sujeto; el texto origen español emplea la segunda persona singular, que se mantiene en la versión italiana publicada en la web, mientras que en DeepL se emplea el pronombre de segunda persona plural2:
En Barcelona hallarás restaurantes de renombre internacional y podrás saborear platos con sello personal (...). / A Barcellona troverai ristoranti di fama internazionale e potrai assaggiare piatti unici (.). / A Barcellona troverete ristoranti di fama internazionale e potrete assaporare piatti dal tocco personale (.).
En los textos aparecen varios calcos o traducciones literales; en general, se trata de términos que han sido traducidos de forma literal sin adecuarlos al contexto o sin emplear el término adecuado en italiano, "calcando" el español, como en el caso de terraza, capital, reloj, repetir, que en DeepL se traducen tal cual:
Sin embargo, lo mejor es preguntar por la especialidad de cada lugar y sentarse en una terraza al sol para probarlas. / Tuttavia il miglior consiglio che possiamo darti è quello di chiedere la specialità del luogo e accomodarti in uno dei dehors riscaldati dal sole. / Tuttavia, è meglio informarsi sulle specialità di ogni locale e sedersi su una terrazza al sole per provarle.
Logroño es la capital de La Rioja. / Logroño è il capoluogo di La Rioja. / Logroño è la capitale de La Rioja.
Es una zona espectacular de lagunas glaciares y aldeas de casas de piedra en las que el reloj parece detenerse. / Si tratta di una zona spettacolare fatta di lagune glaciali e villaggi di case in pietra dove il tempo sembra essersi fermato. / Si tratta di una zona spettacolare di laghi glaciali e villaggi di case in pietra dove l'orologio sembra essersi fermato.
Los platos vegetarianos de la gastronomía española que desearás repetir / I piatti vegetariani della cucina spagnola che ti faranno fare il bis / Piatti vegetariani della gastronomia spagnola che vorrete ripetere.
En lo que se refiere a los errores morfosintácticos, estos representan la segunda tipología de errores más frecuente; entre ellos, el orden equivocado de los elementos que dificultan la comprensión, las repeticiones que limitan la fluidez, la elección incorrecta de las preposiciones, la falta de concordancia y el empleo desacertado de la puntuación:
Y es que, dotada de un clima privilegiado y agradable todo el año, La Palma tiene en la agricultura no sólo una de sus principales fuentes de ingresos sino, además, todo un valor tradicional marcadamente palmero. / Benedetta da un clima eccezionale, con temperature gradevoli durante tutto l'anno, La Palma trova nell'agricoltura non solo una delle principali fonti di reddito, ma anche un autentico valore tradizionale con fisionomia propria. / Grazie al suo clima privilegiato e piacevole tutto l'anno, l'agricoltura di La Palma non è solo una delle principali fonti di reddito, ma anche un valore tradizionale di La Palma.
Por supuesto, todo acompañado de papas arrugadas con mojo (rojo para la carne, verde para el pescado). / Naturalmente, con guarnizione di papas arrugadas (patate novelle bollite) con salsa mojo rossa, nel caso della carne o verde nel caso del pesce. / Naturalmente, tutto accompagnato da papas arrugadas con mojo (rosse per la carne, verdi per il pesce).
Es el producto estrella de la pastelería mallorquina, a base de harina, agua, huevos, azúcar, masa madre y grasa de cerdo, en mallorquín saïm, ingrediente que le da su nombre. / Questo prodotto di punta della pasticceria di Maiorca è a base di farina, acqua, uova, zucchero, lievito madre e strutto, saïm nel dialetto locale, ingrediente da cui deriva il nome. / È il prodotto di punta della pasticceria maiorchina, a base di farina, acqua, uova, zucchero, lievito madre e grasso di maiale, in saïm maiorchino, l'ingrediente che gli dà il nome.
En estos últimos ejemplos se evidencia la repetición del nombre que no se da en la traducción publicada en la página web (fisionomia propria), la concordancia errónea con el término "papas" en lugar de "mojo" (rosse per la carne, verdi per il pesce) y, en el último ejemplo, la traducción literal de "grasa de cerdo" por grasso di maiale en vez de strutto, además del posicionamiento incorrecto de la preposición in.
En cuanto a los errores terminológicos, se ha evidenciado que estos son los más frecuentes, y en su mayoría atañen a los culturemas, como en los ejemplos que siguen, en los que alimentos típicos se han traducido con términos equivocados (cotoletta, vini da tè) así como una profesión típica de Galicia, la de recolector de percebes (barbagianni):
Algunos de sus platos insignia son el bacalao a la riojana, las patatas a la riojana o las chuletillas al sarmiento. / Alcuni dei piatti principali sono il baccalà alla riojana, le patate alla riojana e le costolette arrostite su tralci di vite. / Alcuni dei suoi piatti tipici sono il baccalà alla Rioja, le patate alla Rioja e le cotolette alla vigna.
Mención especial merecen los vinos de tea (denominados así porque se crían en barricas de madera de tea extraída del pino canario), y los vinos de malvasía (...) / Meritano un'attenzione particolare i vini detti di tea (nome che deriva dalla fermentazioni in botti di legno di pino delle Canarie) e i vini di malvasia [...] / Una menzione particolare meritano i vini da tè (cosí chiamati perché invecchiati in botti di legno di tè estratto dal pino delle Canarie) e i vini da malvasia (.)
En Galicia no solo resulta fácil comer muy bien, sino que se pueden vivir algunas experiencias culinarias propias de la zona como, por ejemplo, (.) conocer cómo trabajan los percebeiros. / In Galizia non solo si mangia bene, ma esiste una serie di esperienze culinarie locali tutte da scoprire come, ad esempio, (.) la possibilità di osservare i percebeiros, ovvero i pescatori di lepadi, al lavoro. / In Galizia non solo è facile mangiare molto bene, ma è anche possibile vivere alcune esperienze culinarie tipiche della zona, come, ad esempio, (.) conoscere il lavoro dei barbagianni.
Cabe destacar que las omisiones son muy poco frecuentes; se ha notado que DeepL no traduce una frase, falta el verbo en dos ocasiones y una vez el adjetivo:
Muy recomendable la ternera de la zona y vinos como el Denominación de Origen Valdeorras. / Ti consigliamo di provare il vitello della zona e vini come la Denominazione d'Origine Valdeorras. / 0
Avisamos: una buena mariscada de centollas o bogavantes gallegos no se olvida fácilmente. / Attenzione: un buon piatto di frutti di mare a base di granseole o astici della Galizia non si dimentica facilmente. / Un buon piatto di frutti di mare a base di granseole o aragoste galiziane non si dimentica facilmente.
En el ejemplo anterior, además, se observa la traducción incorrecta del término bogavantes, que DeepL traduce por aragosta.
En lo que respecta a las traducciones erróneas, estas aparecen de varios tipos, como la traducción del nombre de los espacios culturales (Matadero), de las calles, de los edificios o de los museos, que en la traducción italiana publicada, a excepción del nombre del museo, no se traducen:
Matadero. / Matadero / Mattatoio
La calle Laurel de Logroño / Calle Laurel di Logroño / Via dell'Alloro a Logroño
Y si vas en verano, todavía mejor, porque en julio y agosto en el ático encontrarás abierto el Mirador del Thyssen, con increíbles vistas a los Jeróminos y un restaurante que ofrece una cocina mediterránea de lujo. / Se vieni in estate ancora meglio. A luglio e agosto, nell'attico del museo, potrai visitare il balcone panoramico del Thyssen, con una vista incredibile sulla chiesa di San Jerónimo, e un ristorante con cucina mediterranea pregiata. / E se ci andate in estate, ancora meglio, perché in luglio e agosto troverete il Mirador Thyssen aperto sull'attico, con una vista incredibile sui Monti Geronimi e un ristorante che offre una cucina mediterranea di lusso.
En Guijuelo, se encuentra el Museo de la Industria Chacinera, un buen lugar para conocer en profundidad la tradición jamonera de la zona. / A Guijuelo, si trova il Museo dell'Industria Salumiera, il luogo ideale per conoscere a fondo la tradizione del prosciutto locale. / A Guijuelo si trova il Museo dell'Industria della Salsiccia, un luogo ideale per conoscere la tradizione prosciuttifera della zona.
En algunos casos, la traducción errónea afecta el significado mismo de la frase y en ocasiones lo cambia completamente, como puede verse en los ejemplos siguientes:
También encontrarás alojamientos rurales de diseño donde poder disfrutar de una estancia de lo más especial y la opción de recolectar un olivo con tus propias manos, sin duda una experiencia única. / Esistono anche alloggi rurali di design dove potrai goderti un soggiorno davvero speciale e raccogliere olive con le tue stesse mani, sicuramente un'esperienza unica. / Troverete anche alloggi rurali di design dove potrete godere di un soggiorno davvero speciale e la possibilità di raccogliere un ulivo con le vostre mani, un'esperienza unica.
¡Buen provecho! / Buon appetito! / Godetevela!
Por lo que se refiere a los términos sin traducir, se advierte que en su mayoría pertenecen al ámbito gastronómico; se destacan porque aparecen en la frase junto a otros términos que el motor traduce:
Las partes más sabrosas del atún rojo son la ventresca, el morrillo y sus huevas. / Le parti più gustose del tonno rosso sono la ventresca, il capocollo e le uova. / Le parti più gustose del tonno rosso sono la ventresca, il morrillo e la bottarga.
Son típicos el pescaíto frito, los pinchos morunos, los montaditos de embutidos y las patatas bravas o alioli. / Le più tipiche sono la frittura di pesce, gli spiedini di carne, i "montaditos" (paninetti) farciti di salumi e le "patatas bravas" o con "alioli". / Le tapas tipiche includono il pescaíto frito (pesce fritto), i pinchos morunos, i montaditos de embutidos (panini con salsiccia) e le patatas bravas o alioli.
También es posible participar en una jornada de pesca de la almadraba (popularmente conocida como "levantá") entre los meses de abril y junio. / È anche possibile partecipare a una giornata di pesca nella tonnara (popolarmente conosciuta come "levantá") tra i mesi di aprile e giugno. / È anche possibile partecipare a una giornata di pesca dell'almadraba (popolarmente nota come «levantá») tra aprile e giugno.
Como puede observarse, los términos de las comidas a veces se traducen otras no incluso en la traducción publicada donde se emplean las comillas, mientras que en DeepL se insertan en una enumeración de términos que sí han sido traducidos (la ventresca, il morrillo e la bottarga).
En definitiva, se puede afirmar que son precisamente los aspectos terminológicos, y específicamente los culturemas, los que producen más errores, debido a su complejidad, así como han sugerido los estudios teóricos que se ocupan de la traducción del turismo (Rodríguez, 2010). Trovato (2019), de hecho, al abordar las dificultades que entraña la traducción de los textos turísticos entre lenguas afines, señala que es precisamente la traducción de la gastronomía -y, en especial, de los culturemas-, junto con las siglas y acrónimos y los topónimos, lo que genera varias dificultades de traducción.
Conclusiones
Nuestro estudio ha presentado una evaluación cualitativa de la traducción realizada por DeepL empleando textos sobre turismo gastronómico y enológico. El objetivo era estimar la validez de este motor a la hora de traducir este tipo de textos en la combinación lingüística español-italiano. Después de un proceso de evaluación humana, se puede afirmar que la traducción llevada a cabo con DeepL en la combinación lingüística de nuestro interés alcanza un nivel de correspondencia que mantiene el contenido informativo y comunicativo del texto de salida. Aunque se hayan detectados errores, estos no afectan la comprensibilidad del texto en la combinación lingüística de nuestro interés; sin embargo, la falta de estrategias traductivas (como, por ejemplo, la descripción, la adaptación, la ampliación lingüística, etc.), la falta de coherencia y las imprecisiones que se observan en algunos casos limitan la legibilidad del texto meta y demuestran que para las traducciones del sector del turismo llevadas a cabo con este motor neuronal sigue siendo necesario el trabajo de evaluación y posedición. Lo mismo puede decirse en relación con la corrección gramatical entendida como corrección de las normas gramaticales, ortográficas y ortotipográficas de la lengua de llegada (Durán, 2012). De hecho, si es verdad que se han detectado errores menores que no han afectado la adecuación pragmática y la funcional del texto meta, también es cierto que se han localizado errores que justifican la necesidad del proceso de revisión. Como se muestra en la Figura 2, la cantidad de errores detectados varía según la tipología:
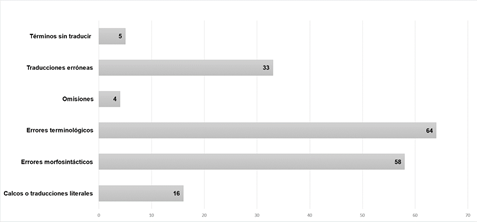
En conclusión, hemos notado que los errores principales se relacionan con la terminología, y son los culturemas los elementos que entrañan más problemas a la hora de ser traducidos. El análisis ha demostrado que la traducción publicada en la web, a pesar de no estar exenta de algún error menor, resulta ser mucho más precisa desde un punto de vista pragmático y gramatical, lo cual sugiere que para que un texto turístico pueda ser publicado una vez traducido con DeepL, necesita de un minucioso proceso de posedición

