











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
PermalinkINTRODUCCIÓN
El futuro ha fascinado al hombre y predecirlo concede un poder que condiciona el presente y direcciona las decisiones que se toman. Desde Hipócrates1, en el acto médico se toman decisiones basadas en posibilidades futuras, pero la diversidad de métodos diagnósticos y terapéuticos demanda conocimientos específicos sobre el efecto de cada decisión diagnóstica y terapéutica en la condición de salud futura del paciente. En consecuencia, se debe avanzar en la investigación del pronóstico de tal forma que sus resultados y conclusiones permitan avanzar en la toma de decisiones clínicas, generar políticas de salud pública, mejorar los servicios y tecnologías de salud, innovar en los mecanismos fisiopatogénicos y blancos terapéuticos, superar limitaciones diagnósticas e incluso para descubrir perfiles de nuevas enfermedades2.
1. GENERALIDADES
1.1. Definiciones
1.1.1. Pronóstico: es la predicción del riesgo de un evento futuro en pacientes o grupos de individuos con enfermedades o determinadas condiciones de salud, y la clasificación de esos individuos según su riesgo1)(3.
1.1.2. Factor pronóstico: es una característica individual biológica, molecular, patológica, anatómica, fisiológica, imaginológica o clínica que se asocia con un resultado de salud o enfermedad determinado4. Se puede considerar sinónimo de variable predictora o marcador3.
1.1.3. Modelo de predicción: es una combinación formal de múltiples predictores que permite generar una estimación del riesgo o de la probabilidad de ocurrencia de la condición de enfermedad de un individuo. Son sinónimos los términos índice o regla pronóstica, índice o regla predictiva, modelo de predicción clínica o modelo predictivo de riesgo3, y en el caso del diagnóstico es índice, regla o modelo diagnóstico5)(6. Según el Diccionario de epidemiología de Last “es la representación abstracta de la relación entre los componentes lógicos analíticos o empíricos de un sistema”, y su uso inició con el esfuerzo de predecir el inicio y curso de las epidemias7.
1.2. Proceso de investigación en pronóstico (Figura 1)
1.2.1. Investigación fundamental: identifica diferencias en la condición de salud o enfermedad de las personas, o en aspectos relacionados con la atención, en diferentes contextos naturales clínicos y demográficos. Un ejemplo es el estudio de Bravo y colaboradores en Cali, en el que evaluaron la supervivencia de personas en diferentes contextos socioeconómicos con base en información obtenida del registro poblacional de cáncer de Cali entre 1995 y 20048. Encontraron que en personas de estrato socioeconómico bajo, la probabilidad de morir por cáncer de cérvix, mama o próstata, era de 1,2; 2,8 y 3,6 veces, respectivamente, la probabilidad de morir por estos mismos tipos de cáncer entre personas del estrato socioeconómico alto.
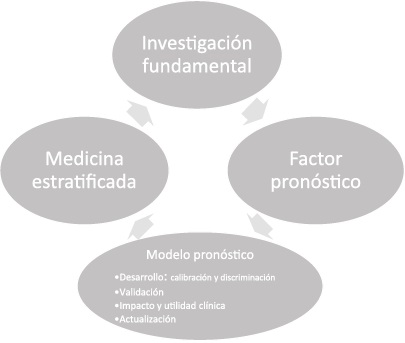
1.2.2. Investigación en factor (es) de pronóstico: identifica factores específicos que se asocian con determinada condición de salud o enfermedad. Un ejemplo es un estudio en 684 pacientes que ingresaron a urgencias con sospecha de infección y sepsis, en ellos se observó que valores de dímero D superiores a 1180 ng/mL se asociaban con mayor mortalidad al día 289.
1.2.3. Investigación en modelos de pronóstico: identifica la forma en que se relacionan diferentes factores con un efecto sobre la salud o la enfermedad, generando una herramienta que permite predecir el riesgo para un individuo o grupo de individuos con el fin de informar, guiar las decisiones de médico y paciente o comparar diferencias en el desempeño de instituciones de salud, entre otros1)(10. Un ejemplo es un modelo predictivo de positividad de hemocultivos, que se desarrolló en una cohorte de 719 pacientes y se validó en una cohorte de 467 pacientes con sospecha o confirmación de infección. El modelo predictor final mostró mayor asociación de las variables temperatura mayor de 38 °C, recuento de plaquetas menor de 150 000 µL y escala de Glasgow menor de 15 con la probabilidad de un hemocultivo positivo. La calibración, determinada con la prueba de bondad de ajuste de Hosmer Lemeshow, fue adecuada en la cohorte de desarrollo y en la de validación; y la discriminación del modelo fue apenas aceptable en ambas cohortes (AUC-ROC = 0,68; IC95 % = 0,67-0,72 en la de desarrollo y AUC-ROC = 0,65; IC95 % = 0,61-0,70 en la de validación)11.
1.2.4 Investigación de medicina estratificada: clasifica los individuos según la presencia o no de ciertos factores que determinan la toma de decisiones diagnósticas o terapéuticas. La medicina estratificada se inicia al identificar las diferencias entre los individuos, sigue con descubrir uno o varios factores asociados con determinada respuesta terapéutica para establecer subgrupos de riesgo, y finalmente permite examinar el impacto de las decisiones en salud para estos subgrupos por medio de experimentos clínicos, estudios de costo-efectividad, evaluación de tecnologías o de políticas12.
2. Modelo pronóstico
2.1. Desarrollo de un modelo
El modelo estadístico depende del nivel de medición del desenlace. En el caso de desenlaces continuos, se pueden generar modelos de regresión lineal múltiple o modelos más flexibles como los aditivos generalizados que transforman automáticamente los predictores que no tienen una relación lineal con el desenlace10. En el caso de desenlaces dicotómicos, se generan modelos de regresión logística o extensiones como la regresión logística bayesiana naive o modelos aditivos generalizados10. Otra forma de analizar este tipo de desenlaces son las particiones recursivas como el árbol de regresión y clasificación y diversos modelos de inteligencia artificial como las redes neuronales y las máquinas de soporte vectorial10. Para desenlaces que modelan el tiempo hasta el evento se usa el método de riesgos proporcionales de Cox o métodos paramétricos que modelan en relación con las distribuciones exponencial, Weibul o de Poisson, entre otras10.
2.1.1. Selección y manejo de predictores: se definen las variables predictoras en los pacientes antes de que presenten el desenlace que se va a predecir o la enfermedad por diagnosticar3. Esto, no obstante, es uno de los elementos más complejos y difíciles de decidir en el desarrollo de un modelo de pronóstico, porque se deben balancear muy cuidadosamente la disponibilidad de información, el uso de recursos y sus costos, la aplicabilidad para la práctica clínica y la exactitud en la predicción. Usualmente se recoge información de más predictores de los necesarios, con base en los reportados en la literatura o los que son de conocimiento del experto, dado que se asume que con más fuentes disponibles hay menor riesgo de sesgo al seleccionarlos10. Igualmente, se desaconseja excluir predictores simplemente por no tener asociación significativa con el desenlace en el análisis univariado13. Considerando el principio de parsimonia (Ockham’s Razor), el modelo que tenga menos predictores es más viable para su uso en la clínica7)(10. En este sentido, se podrían excluir predictores según el número de datos perdidos y la asimetría de la distribución, y también es posible que aquellos predictores relacionados entre sí se combinen en una sola variable10. Aunque aumentar el número de predictores puede disminuir el error aleatorio, este cambio no es sustancial luego de cinco predictores. Aumentar el número de predictores más allá de cinco, por otra parte, puede causar sobreajuste al aumentar la diferencia entre el rendimiento del modelo en los datos que lo originaron y el rendimiento en un nuevo conjunto de datos10.
Por otra parte, el modelo tiene mayor poder y menor sesgo si las variables conservan su medición original, especialmente en las continuas, aunque el clínico usa más fácilmente las dicotómicas12. Para incluir los predictores continuos se debe verificar que tengan una relación lineal con el desenlace, de lo contrario se desarrollará un modelo inexacto13. En situaciones especiales, con mucha atención a la comprensión y aplicabilidad clínica, se puede transformar el predictor con funciones como la cuadrática, cúbica o logarítmica, para que su relación sea lineal; o se pueden modelar las relaciones no lineales con técnicas avanzadas como polinomios fraccionales multivariables o con splines cúbicos restringidos13. Estas transformaciones, sin embargo, obligan a una validación mucho más exhaustiva del modelo pues pueden incurrir en sobreajuste a los datos10.
2.1.2. Tamaño de la muestra: a diferencia de las pruebas de hipótesis convencionales para experimentos clínicos u otros estudios de asociación, no existe en los modelos predictivos una formulación estándar que permita estimar el número de individuos necesario para detectar la “diferencia que se espera encontrar”13. Es claro que un criterio fundamental es el número absoluto de sujetos que presentan el desenlace de interés, más que el total de individuos en riesgo que componen la muestra, y que el modelo es más confiable si se desarrolla con bases de datos grandes y de calidad, aunque no exista una definición única para ese “grande”3)(10. En términos generales, de acuerdo con consideraciones como el tipo de predictores, su distribución y variabilidad, la necesidad de transformaciones o la presencia de interacciones, podría considerarse necesario tener de 10 a 50 desenlaces por cada variable independiente predictora en el modelo10.
2.1.3. Elaboración del modelo: siguiendo la recomendación del grupo PROGRESS (Prognosis Research Strategy Partnership), se deben tener en cuenta las siguientes consideraciones desde el protocolo de investigación3:
Las definiciones de las predictoras y su medición completamente estandarizadas. Es necesario excluir un predictor con un error de medición significativo por sus consecuencias en la calidad del modelo3)(13.
La codificación de las variables categóricas y continuas se puede basar en estudios previos o en el mismo comportamiento de los datos, con prelación a la lógica de la interpretación clínica.
El manejo que se les dará a los datos perdidos. La mejor forma de manejar la pérdida de datos es prevenirla, lo que no es posible en los diseños retrospectivos en los que se obtiene información de fuentes secundarias como historias clínicas o bases de datos administrativas. En general, no se deberían considerar las variables predictoras con altos porcentajes de datos perdidos porque pueden igualmente ser casi inexistentes en la práctica real. Por otra parte, analizar únicamente los pacientes con toda la información, los denominados casos completos, es ineficiente y puede generar un sesgo de selección, a menos que las pérdidas sean inferiores al 5 %3)(13. Cuando la pérdida de datos en la variable predictora ocurre por azar y no supera un 20 % a 30 % del total, se considera adecuada la realización de la denominada imputación múltiple10. Con esta técnica, la generación de los datos perdidos se hace con un modelo cuyo desenlace es la variable con dichos datos y los predictores son los mismos que harán parte del modelo, además del desenlace y otras variables auxiliares que pudieran explicar las pérdidas. Si se decide imputar, se deben presentar los resultados con y sin imputación10.
La interacción de las variables predictores que se va a considerar13. La decisión de incluir un término de interacción se debe basar en el conocimiento clínico, las publicaciones previas y ocasionalmente en el comportamiento de los datos. Si un término de interacción no mejora el rendimiento del modelo debe eliminarse.
Los supuestos que debe cumplir el modelo3 deben estar claros. Sin embargo, la mejor predicción no necesariamente ocurre cuando se cumplen estrictamente todos los supuestos10. El intentar un modelo perfecto en cumplimiento del supuesto de linealidad o de la inclusión de todas las interacciones puede disminuir su utilidad y llevarlo a un sobreajuste.
El método de entrada de las variables predictoras en el modelo final. Aunque no hay consenso en el mejor método, hay acuerdo en tener cuidado con el sobreajuste y el sesgo de selección13. Un criterio de inclusión puede ser un valor de p de 0,1 o 0,15 en análisis univariado. Una opción puede ser el método de eliminación hacia atrás, que comienza con todas las variables en el modelo y las elimina paso a paso según los valores de p, teniendo en mente que puede llevar a sesgo de selección y sobreajuste.
Debe primar la aplicabilidad clínica que se da cuando los modelos son simples y se expresan en puntajes fáciles de interpretar13.
La presentación del modelo predictivo como regla de predicción o decisión. La regla de predicción genera una probabilidad diagnóstica o pronóstica y puede presentarse con la fórmula de regresión, un puntaje, una tabla con predicciones o un nomograma. La regla de decisión genera recomendaciones para tomar decisiones, presentadas en un árbol o puntaje, entre otros10.
2.1.4. Valoración del modelo: en esta se determinan las medidas de rendimiento o exactitud predictiva y además deben especificarse la estabilidad y reproducibilidad del modelo13. Para regresión logística una medida de exactitud es la calibración, que determina la concordancia entre los desenlaces que predice el modelo y los que realmente se observan con el seguimiento. Puede medirse con una gráfica de valores observados en el eje “X” y de predichos en el “Y”, que al formar una línea de 45º o pendiente de 1 define una excelente calibración. Adicionalmente, una prueba de bondad de ajuste de Hosmer-Lemeshow con un valor de p superior a 0,05 está en consonancia con lo anterior, aunque tiene poder limitado para detectar una mala calibración10)(13. Una medida adicional de exactitud es la discriminación, o habilidad del modelo para separar a los individuos con el desenlace de aquellos que no lo presentan. La discriminación para modelos de regresión logística se puede medir con el estadístico C del área bajo la curva de características operativas del receptor (AUC-ROC), en el que los valores cercanos a uno representan la discriminación perfecta10. En el caso de modelos de regresión lineal múltiple o modelos aditivos generalizados, el R2 mide la discriminación del modelo. No es claro cómo valorar la discriminación de los modelos de tiempo hasta el evento, pero se describe el uso del estadístico C de Harell con una interpretación similar al área bajo la curva ROC10. Recientemente se ha sugerido que el rendimiento de un modelo debe ir más allá de la discriminación y la calibración, especialmente hacia la habilidad y utilidad de clasificar mejor a los pacientes con el modelo que sin él. Para identificar la utilidad se debería hacer una curva de decisión que permita identificar, con diferentes umbrales ponderados de falsos positivos o falsos negativos, cuántos pacientes se tratan correctamente comparado con no tratar a los que no necesitan tratamiento10.
2.2. Validación
Se debe hacer en un conjunto de datos diferente al que se desarrolló. Es común la validación en una muestra aleatoria de la población en que se desarrolló el modelo, pero esto usualmente es ineficiente desde el punto de vista estadístico y débil metodológicamente3. Ocasionalmente, puede ser útil para valorar mejor la variabilidad y probablemente anticipar el optimismo de un modelo, una forma de validación interna denominada bootstrap en la que se hace un remuestreo con reemplazo de los datos, creando muestras con diferentes observaciones y luego de determinadas repeticiones (50 a 500), obtener estimadores más estables10. Un modelo es válido si la predicción del desenlace es igual en los datos en que se desarrolló y en los datos nuevos14. Los problemas en la validez de la predicción pueden ocurrir por deficiencias en el diseño, sobreajuste a los datos de la cohorte inicial, deficiencias o diferencias en el sistema de salud, diferencias en los métodos de medición y en las características de los pacientes14. Las diferencias mencionadas pueden llevar a cambios en el rendimiento del modelo, por ejemplo, si se incluye mayor proporción de casos graves se reducen el estadístico C y el beneficio neto. La transportabilidad del modelo temporal, geográfica, metodológica e independientemente de los investigadores y lugares, se refiere a la capacidad del modelo para predecir el desenlace a un individuo diferente del grupo de personas en quienes se desarrolló el modelo10. Tanto la transportabilidad como la validación del modelo implican evaluarlo en un grupo de datos diferente al que fue desarrollado13)(14.
2.3. Evaluación del impacto y la aplicabilidad clínica del modelo
Busca estimar el efecto en la toma de decisiones y en los desenlaces del paciente, así como en los costos. Los estudios de impacto permiten definir la aplicabilidad del modelo y los factores que pueden afectar su implementación en la atención. Podrían ser ensayos clínicos controlados, estudios de cohorte, series de tiempo interrumpidas de antes y después o diseños de corte transversal3. La aplicabilidad clínica ocurre cuando se prueba un impacto positivo en la toma de decisiones. La implementación de un modelo puede limitarse cuando la medición de los predictores no está disponible en el cuidado de rutina o si dicha medición es costosa. Un modelo complejo o que dificulta la toma de decisiones es difícil de usar en el contexto clínico3)(15. Para su aplicabilidad clínica, un puntaje de riesgo debe ser creíble, bien calibrado, con buena habilidad discriminativa, generalizable, y proveer a los clínicos información para mejorar la toma de decisiones terapéuticas14. Otras limitaciones en la aplicabilidad que afectan el rendimiento predictivo ocurren debido a los siguientes factores15:
La circunstancia que se va a predecir es infrecuente.
La definición del predictor y/o del desenlace es ambigua.
Los cambios que puede sufrir el pronóstico, tratamiento o diagnóstico de la condición desde el momento en que se desarrolló el modelo.
La tendencia a crear nuevos modelos en lugar de actualizar los modelos previos que ahora tienen un menor rendimiento.
La validación con una muestra menor que la usada para desarrollar el modelo.
2.4. Actualización
Se lleva a cabo cuando hay cambios en el diagnóstico o en el tratamiento de la enfermedad o cuando se considera que hay nuevos factores relacionados biológicamente con la misma. El modelo se evalúa nuevamente para ver cambios en la predicción y si es posible identificar diferentes grupos de riesgo3. Dado que el rendimiento del modelo puede cambiar con el tiempo, la actualización luego de algunos años se relaciona con resultados exitosos en la validación y evaluación del impacto tiempo después de su desarrollo14.
El reporte de estudios de modelos pronósticos está especificado en la guía TRIPOD (por la sigla en inglés de transparent reporting of a multivariable prediction model for individual prognosis or diagnosis), en la cual se listan y aclaran algunos de los aspectos de este tipo de investigación16.

