Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Introducción
Los estudios observacionales de alta calidad tienen un papel importante en la literatura científica al ser generadores de hipótesis, aportar evidencia preliminar para futuros ensayos, proporcionar estimaciones del efecto del tratamiento consistentes con las de ensayos controlados aleatorios y son un componente crítico de la investigación de efectividad comparativa1. Hacen parte crucial del equipamiento de la investigación biomédica, especialmente al estudiar condiciones complejas o problemas relacionados con la comprensión de los resultados de intervenciones en poblaciones heterogéneas2.
En este sentido, los estudios de cohorte constituyen un método privilegiado para obtener información clínica y epidemiológica que impacta la salud humana, al establecer una clara secuencia temporal entre exposición y desenlace con el respectivo aporte en inferencia causal en estudios etiológicos. Permiten evaluar exposiciones poco frecuentes, estudiar dosis respuesta, evalúan múltiples desenlaces que puedan estar relacionados con la exposición, incluso exposiciones probablemente nocivas3, sin dejar de mencionar su importancia por reflejar condiciones de la vida real.
Existen directrices publicadas y ampliamente aceptadas por la comunidad científica sobre la forma de reportar los estudios observacionales, pero ellas, más que hacer énfasis en la calidad del dato pues se da por sentada, solicitan explicitar los esfuerzos para controlar las potenciales fuentes de sesgos4. El grado de fiabilidad de los estudios observacionales varía mucho, en particular según el diseño del registro, los métodos utilizados para el análisis y, sobre todo, la calidad de los datos registrados5. La preocupación por esta calidad se amplía en el caso de los estudios que utilizan datos observacionales recogidos de forma rutinaria6, por lo tanto, se deben hacer esfuerzos para prevenir, detectar y corregir a tiempo los errores que se puedan presentar durante ese proceso.
Esta preocupación no solo es teórica. Un estudio encontró que la prevalencia de eventos definitorios de VIH, después de realizar auditoría a los datos, era 17,5 %, diferente al 12,9 % que arrojaban los datos originales, es decir, un incremento erróneo en 36 % de esa prevalencia e identificó subvaloraciones en la magnitud del riesgo de los factores estudiados, lo cual afectaba negativamente las inferencias6. Otro estudio en VIH encontró errores en 10 % de los registros de esquemas terapéuticos7. La toma de decisiones con base en esta información errada por la mala calidad de la obtención del dato puede tener consecuencias negativas sobre las personas y comunidades afectadas.
El aseguramiento y el control de la calidad de los datos (ACCD) son estrategias que aumentan la confianza en los resultados de un estudio, complementarios con los esfuerzos previos desde la formulación del protocolo de investigación encaminados al control de los propios sesgos8. El aseguramiento está orientado a garantizar la calidad antes de la recolección y el control una vez obtenidos los datos. Gran parte de la literatura sobre la ACCD ha surgido en el contexto de los ensayos clínicos, centrándose en la maximización de la calidad de los datos mediante protocolos estandarizados para todo el estudio y protocolos locales específicos, la formación del personal del estudio y los sistemas de gestión de datos, pero esta literatura no suele ser relevante para los estudios de cohortes9.
La mayoría de los estudios publicados no enseñan de manera detallada el manejo que se le hace a los datos10-12y a pesar de la bibliografía médica y bioestadística sobre los fundamentos teóricos que rigen el ACCD13-19, poco se ha mostrado sobre la aplicación de herramientas para garantizar su calidad en estudios reales20-23. El objetivo de este artículo es presentar la experiencia en el manejo de datos implementada con el fin de para mantener la fiabilidad y la validez en un estudio con seguimiento, durante varios años, a una de las cohortes de pacientes con Enfermedad Renal Crónica (ERC) más grande de Latinoamérica.
Metodología
Estudio original
La investigación tuvo un diseño analítico de cohorte, con un seguimiento durante 49 meses a dos cohortes dinámicas de pacientes mayores de 16 años diagnosticados con ERC pertenecientes a dos Entidades Promotoras de Salud (EPS) colombianas, 4202 del grupo de expuestos al Programa de Protección Renal (PPR) y 1461 como grupo de control con Terapia Convencional (TC)24. Como fecha de inicio de ambos grupos se consideró la correspondiente al diagnóstico de ERC según guías KDOQI, además de la fecha del ingreso al programa en el grupo expuesto al PPR. Se recogió información retrospectiva de historias clínicas sistematizadas de 36 meses y en forma prospectiva de 13 meses más, para evaluar progreso de estadio, requerimiento de diálisis y muerte.
El PPR es un plan de prevención secundario con estrategias como citas educativas y asistenciales periódicas, exámenes clínicos y de laboratorio, y la búsqueda activa de pacientes en riesgo que se organizan en dos niveles de atención. El primer nivel hace seguimiento a pacientes en estadios tempranos de ERC con medicina general y enfermería, además de dos citas por año con medicina interna y nutrición. El segundo nivel atiende pacientes del estadio tres en adelante con citas con medicina interna, nefrología y nutrición de forma bimestral o seis veces al año.
La TC se aplica en el primer nivel de atención a las personas con riesgo y a los pacientes con enfermedad y no se hace búsqueda activa de ellos. La remisión a especialista se realiza según el criterio del médico tratante y no se ejecutan protocolos o esquemas definidos de atención especial.
Estudiantes de los dos últimos años de medicina con conocimiento sobre ERC y capacitados en el diligenciamiento de los formularios y el manejo de los sistemas de información de las EPS, coordinados por el investigador principal, revisaron las historias clínicas.
Decisiones y comunicación entre el equipo
Se establecieron canales de comunicación eficaces entre los niveles de decisión del proyecto. El primer nivel estuvo conformado por el investigador principal, un nefrólogo y un estadístico. Un segundo nivel, conformado por una gerente en sistemas de información, una médica coordinadora técnica del trabajo en terreno y una administradora interna del proyecto, quienes semanalmente programaron y evaluaron el proceso haciendo los ajustes requeridos, por último, un tercer nivel conformado por el personal que realizó la recolección de los datos, con quienes se mantuvo permanente comunicación mediante la coordinación del trabajo de campo. Se generaron y divulgaron informes internamente con el fin de mejorar tanto el proceso mismo como las herramientas y la tecnología que lo soportaban. Se hicieron reuniones periódicas para realimentar los procesos de captura y para actualizar los instructivos.
Captura de los datos
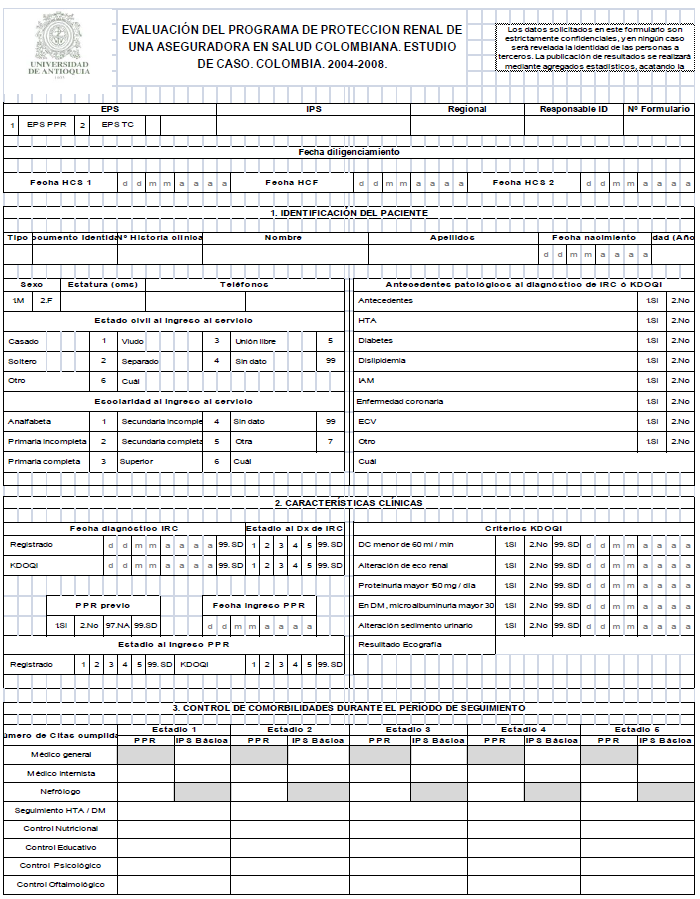
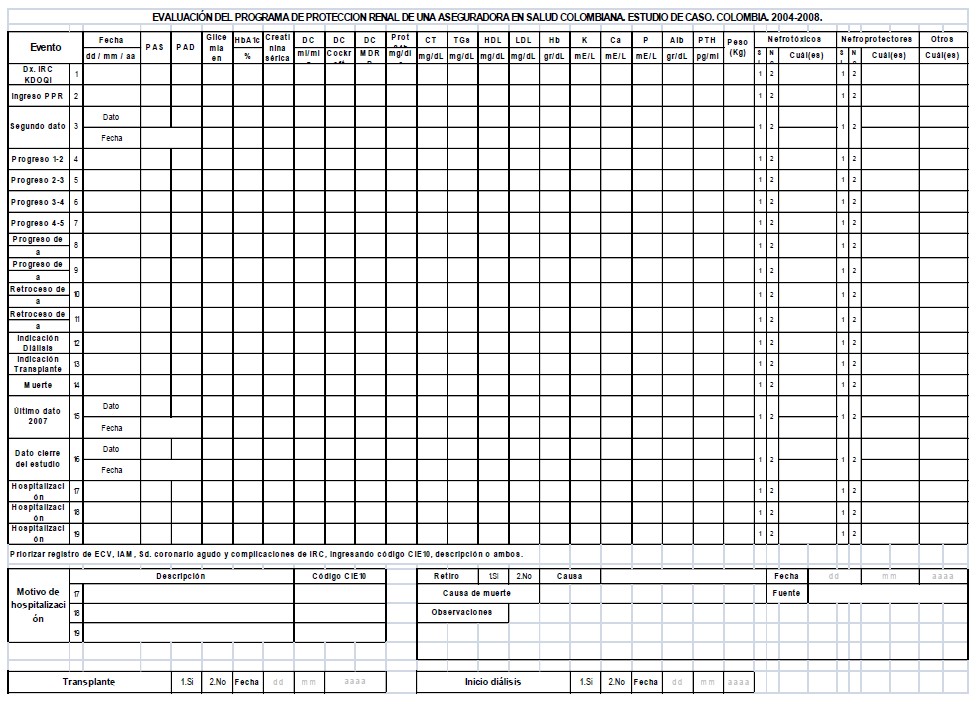
Cada una de las historias clínicas de los participantes fue revisada al menos en dos ocasiones durante el seguimiento aportando al mejoramiento en la calidad y los datos se consignaron en un formulario en físico con cuatro componentes: características generales del paciente, características clínicas, control de comorbilidades, y seguimiento de desenlaces (Anexo 1). Posteriormente los datos se transcribieron a un formulario electrónico desarrollado en Visual Fox Pro-8.0 con un diseño lo más coincidente posible con el instrumento físico. Con esta estrategia se buscó contribuir a la agilidad de la digitación y a disminuir el riesgo de error en la transcripción.
Al instrumento físico y las variables contenidas se le realizaron inicialmente pruebas de contenido por los investigadores con expertos en nefrología y estadística para lograr que su contenido fuera suficiente, pertinente, exhaustivo y breve. Se definieron las variables para que los datos fueran recolectados en su expresión básica, y en los casos en que no se encontró el dato de la depuración de creatinina, los recolectores del dato la calcularon con las fórmulas estandarizadas de Cockcroft-Gault y MDRD respectivas, cuyo resultado fue verificado por otra persona.
Debido a que en las historias clínicas se encuentran datos faltantes, se realizó una búsqueda exhaustiva en diferentes secciones de las historias para que la base de datos creada se afectara lo menos posible, aun así la mayoría de las variables de interés presentaron una proporción de datos faltantes entre el 7 y el 11 %, ante lo cual se decidió no hacer imputación, la cual es una de las alternativas en el manejo de los datos perdidos. En relación con los datos atípicos e inverosímiles registrados, una persona diferente a quien captó el dato inicial, verificó la fidelidad de la fuente en la historia clínica y se corrigió. Se codificaron los posibles valores permitidos para cada variable y se incluyeron las opciones de "otros" y "sin dato", para aquellos casos en que se consideró necesario tal diferenciación.
Estandarización
Para estandarizar la captura de los datos se implementaron unos pasos claramente definidos. Se seleccionaron estudiantes de medicina del último año con conocimiento de ERC, se les capacitó para diligenciar los formularios y en el manejo de los sistemas de información de las EPS. Se elaboraron manuales instructivos aclarando cada campo del formulario para facilitar la recolección y captura del dato, los cuales estuvieron siempre disponibles para los responsables, además del refuerzo realizado en las reuniones periódicas con ellos.
La coordinación capacitó a los recolectores su ingreso a la investigación en el contenido de las guías KDOQI, en los protocolos para diligenciar los instrumentos (HCS1 y HCS2: historia clínica sistematizada para la primera y la segunda captación) y estandarizó y verificó en terreno la adecuada captación de los datos de las historias clínicas. Se estableció un proceso de asignación y recepción de formularios de tal manera que cada estudiante era responsable por un número de historias clínicas a revisar y al momento de recepción del formulario diligenciado se verificó que se hubiera realizado de manera correcta, mediante la aplicación de un instrumento de control de calidad. De esta manera se garantizó que las correcciones necesarias se hicieron de manera oportuna en terreno.
Se hicieron varias pruebas piloto para probar y ajustar los instrumentos, y para garantizar el adecuado adiestramiento de los captadores de datos. Estas pruebas se demoraron más tiempo del planeado inicialmente debido a los múltiples ajustes realizados.
Almacenamiento de los datos
Al confirmar que un paciente cumplía con los criterios de la investigación y que el instrumento estaba diligenciado correctamente, se le asignaba el número de archivo y se pasaba a digitación. Si el paciente cumplía con los criterios, pero se detectaban errores en el diligenciamiento del formulario, se devolvía al responsable para hacer las correcciones del caso. Los formularios repetidos y los que no cumplían con los criterios de inclusión se archivaron en forma separada, de acuerdo con la EPS y en orden cronológico.
Todos los formularios fueron ingresados en dos bases de datos por dos digitadores diferentes, para luego ser confrontadas identificando discrepancias que fueron resueltas tras verificar por un tercero el registro correcto en Excel. La información se almacenó en medios físico y magnético, identificando cada formulario recibido con un número que lo ubicaba en una posición específica en el archivo coincidente con el digitado en la base de datos, con el fin de poder ubicarlos posteriormente cuando fuese necesario.
Para el almacenamiento magnético se diseñó una base de datos relacional en SQL Server con las variables de los cinco componentes del instrumento físico y con la adición de variables calculadas de manera automática a partir de datos primarios recolectados, por ejemplo, la edad a partir de la fecha de nacimiento, los criterios KDOQI a partir de las especificaciones de la National Kidney Foundation o diferentes tiempos a partir de las fechas pertinentes consignadas.
Se realizaron copias de seguridad de la base de datos tanto de forma electrónica como automática con actualización diaria por cada digitadora, lo que aseguró la integridad de la base y la consistencia de los datos en caso de una falla en el sistema.
Control de sesgos
Desde el diseño del estudio se identificaron unos posibles sesgos, que suelen ser comunes a este tipo de estudios, y se establecieron estrategias para su control. Un sesgo pudo darse al conformar la cohorte cuando las personas que ingresaron al estudio hubiesen diferido en factores relacionados con la probabilidad de ocurrencia de los eventos a medir, como con los diferentes estadios de ERC al ingreso, lo que llevó a su control al ajustar (por estratos) en el análisis por estadio al ingreso. Para el control de sesgos de selección se tuvo en cuenta que los sujetos de la investigación se ajustaran a los criterios de inclusión y exclusión, además se captó la información de la totalidad de los pacientes del PPR y del TC.
Para evitar los sesgos de medición, se realizó prueba piloto de los instrumentos con los que se captaron los datos, y se evitaron los sesgos del observador, al capacitar a quienes recogieron los datos y se hizo estandarización del proceso de aplicación de los instrumentos.
Otro sesgo potencial de información provino de la posible falta de estandarización en los valores de referencia para los resultados de laboratorio. Para cada resultado, se tuvo en cuenta el valor de referencia reportado por el laboratorio que procesó la muestra, y se relacionó con el estándar internacional aceptado y reportado en la literatura científica
Verificación del aseguramiento y control de la calidad del dato
Todos los errores identificados en los primeros 50 instrumentos diligenciados se codificaron y cuantificaron, y se comparó esa frecuencia de ocurrencia con los siguientes 50 formularios, a la vez que se seguía implementando el plan de ACCD. Se siguió cuantificando y comparando la frecuencia de los errores en bloques de 50 formularios hasta llegar al número 700. Desde el formulario 701 hasta el 3000, se hizo control de calidad a las variables que tuvieron mayor frecuencia e importancia clínica en los primeros 700 formularios. Una vez fueron identificados estos errores, se corrigieron en la base de datos previa verificación en la fuente primaria y se reforzó la instrucción al personal recolector.
Entre el formulario número 3000 y el 9887, número total de historias clínicas revisadas, se continuó con la revisión de una muestra aleatoria de 150 formularios. Esta evaluación la realizó una persona diferente a quien hubiese captado los datos iniciales, seleccionada al azar del grupo recolector, con lo cual, adicional a la evaluación de la calidad del dato, se valoró la concordancia inter-evaluador.
La selección de las variables para valorar la concordancia fue por consenso del equipo investigador, privilegiando las que se consideraron más importantes (criterios diagnósticos de ERC y estadio al ingreso), y las que los recolectores consideraron menos relevantes (antecedentes patológicos, presión arterial sistólica y segunda medición de presión diastólica después del diagnóstico, y creatinina sérica al momento del diagnóstico). Para cuantificar esta concordancia, se aplicó el índice de Kappa a las variables cualitativas y el coeficiente de correlación intraclase (CCI) para las cuantitativas25. En cuanto a los aspectos éticos, la investigación original contó con aprobación del Comité de Bioética de la Facultad de Medicina de la Universidad de Antioquia y de las EPS. Este uso secundario de datos no requiere evaluación por Comité de Ética, dado que toma datos administrativos y consolidados previamente en la investigación original, no se toma información de personas ni se tuvo nuevo contacto con ellos o con sus registros.
Resultados
La proporción de errores encontrados en los primeros 700 formularios verificados se relacionaron por tipo de error, así: identificación del paciente 13 %, diagnóstico ERC 13 %, ingreso al PPR y estadios 13 %, PPR previo 2 %, criterios KDOQI 40 %, registro de cambio de estadio 21 % y otros 8 %. Cinco de los 50 (10 %) primeros formularios y diez (20 %) de los siguientes 50 no presentaron ningún error. La Tabla 1 muestra el número de errores dentro de cada formulario, para cada uno de los tipos de errores más frecuentes e importantes, en general pasó a ser menor en el segundo grupo.
Tabla 1 Reporte del tipo de errores de los formularios 1 al 100.
| Tipo de errores más frecuentes | Consecutivo de Formularios | ||
|---|---|---|---|
| 0-50 | 51-100 | ||
| Error cometido | Código error | Número de formularios con el error | Número de formularios con el error |
| Elegir "Sin Dato" en sedimento urinario cuando es "No" | 073 | 19 | 7 |
| Fecha de criterio de Depuración de Creatinina equivocada | 040 | 15 | 3 |
| Falta de registro de citas a nutrición PPR | 080 | 13 | 7 |
| No hay resultado de ecografía renal, con respuestas "Si" y "No" en el criterio | 078 | 12 | 4 |
| Fecha de criterio de proteinuria 24 horas equivocada | 042 | 8 | 2 |
| Falta de registros de "último dato" | 095 | 8 | 0 |
| Fecha de diagnóstico KDOQI errada, secundario a fecha de depuración de creatinina equivocada | 008 | 4 | 7 |
| Más retrocesos de los que realmente son | 088 | 4 | 5 |
KDOQI, Kidney Disease Outcomes Quality Initiative.
Fuente: El estudio.
Los índices de Kappa obtenidos para las variables de mayor importancia, como son los criterios diagnósticos de ERC, depuración de creatinina, alteración de la ecografía renal, la proteinuria, y el estadio al ingreso fueron mayores a 0,8 y fue de 0,73 para la alteración del sedimento urinario. Los CCI para la presión arterial sistólica y segunda medición de presión diastólica después del diagnóstico y la creatinina sérica al momento del diagnóstico igualmente indican buena correlación. La Tabla 2 muestra que todos estos valores fueron significativamente distintos de los esperados por el azar.
Tabla 2 Análisis de concordancia inter-evaluador de variables clínicas seleccionadas
| Variable | Valor del coeficiente de reproducibilidad | Error | Valor p |
|---|---|---|---|
| Antecedente de Hipertensión arterial | 0,8521 | 0,072 | <0,001 |
| Antecedente de Diabetes | 0,5041 | 0,052 | <0,001 |
| Antecedente de Dislipidemia | 0,5391 | 0,065 | <0,001 |
| Antecedente de Infarto Agudo de Miocardio | 0,4131 | 0,149 | <0,001 |
| Antecedente de Enfermedad coronaria | 0,6001 | 0,101 | <0,001 |
| Antecedente de Enfermedad cerebro-vascular | 0,4031 | 0,169 | <0,001 |
| Estadio al ingreso PPR registrado | 0,9561 | 0,044 | <0,001 |
| Depuración de creatinina < 60 mL/min | 0,9601 | 0,028 | <0,001 |
| Alteración ecografía renal | 0,9421 | 0,029 | <0,001 |
| Proteinuria > 150mg/dL | 0,8711 | 0,042 | <0,001 |
| Alteración sedimento urinario | 0,7301 | 0,104 | <0,001 |
| Presión arterial sistólica | 0,9962 | 0,994-0,9953 | <0,001 |
| Presión arterial diastólica | 0,9932 | 0,959-0,9963 | <0,001 |
| Creatinina | 0,9952 | 0,993-0,9973 | <0,001 |
1 Kappa. 2 Coeficiente de correlación intraclase. 3 Intervalo de confianza del 95 %. PPR, programa de protección renal.
Discusión
Este trabajo evidenció que hubo mejoría en la captación de los datos de la investigación luego de que los recolectores asistieran a las reuniones de retroalimentación y los formularios e instructivos fueran ajustados según las evaluaciones realizadas, evidenciando una reducción en el número de errores y en el tipo de error más frecuentemente cometido. Hacer uso de personal del área de la salud para el proceso de captura como fue en este caso, corroboró los beneficios que han demostrado estudios previos, al valorar la concordancia inter-evaluador de los datos extraídos por especialistas vs. personal no médico entrenado20.
Lo anterior se hizo evidente en los resultados del valor de Kappa y del CCI con excelentes niveles de concordancia en la mayoría de las variables, donde las cifras que aportaban información relacionada directamente con los desenlaces tuvieron índices de reproducibilidad cercanos a 0,9. Los coeficientes menores se podrían atribuir a que corresponden a variables de menor importancia para el estudio y que por tanto llevan menos cuidado por parte de los recolectores a la hora de procesarlas, dado su conocimiento del tema. Estudios previos muestran que las variables de menor importancia suelen tener índices de reproducibilidad bajos, comparado con variables consideradas como importantes26.
La doble entrada de datos a la base electrónica también contribuyó al control de sesgos y a aumentar la calidad del dato. Esta estrategia es implementada en gran cantidad de estudios actualmente y su utilidad ha sido probada. En estudios basados en registros médicos, los investigadores obtienen los datos de documentos que no han sido creados para responder con los objetivos del estudio. Esto implica mayor dificultad a la hora de obtenerlos e implica la necesidad de aplicar metodologías precisas para garantizar su calidad.
Se rescata la importancia de ciertos elementos metodológicos para tener en cuenta a la hora de hacer estudios retrospectivos basados en registros médicos, entre los que se encuentra el desarrollo de criterios explícitos de inclusión y exclusión, la adecuada operacionalización de las variables incluidas en la revisión retrospectiva, el entrenamiento y la supervisión de los extractores de datos, el desarrollo y la utilización de formularios de abstracción de datos estandarizados, la creación de un manual de procedimientos para explicar la abstracción de datos, la evaluación de la fiabilidad interobservador e intraobservador y la realización de una prueba piloto, estrategias implementadas en este estudio16.
En reconocidas publicaciones se evaluó la metodología aplicada a estudios retrospectivos en medicina de urgencias y en psiquiatría, y encontraron importante hacer énfasis en la construcción meticulosa de los formularios de recolección y de los instructivos para su diligenciamiento, así como la identificación de errores en estos a medida que el estudio es conducido21,27. Además, son fundamentales el entrenamiento del personal de recolección y el proceso de retroalimentación. Como en el presente trabajo, otros estudios trataron de garantizar que cada recolector estuviera permanentemente entrenado, mediante la asignación constante de historias clínicas a revisar para mantener las habilidades y los criterios de recolección en el mejor nivel.
Así mismo, se reconoce en la literatura especializada, que esforzarse por mejorar la calidad de los datos es una expresión de respeto hacia los participantes por su contribución con la información. En ese sentido, la calidad de los datos comienza con el reconocimiento de los retos y dificultades que implica su responsable captación, de ahí el aporte de la estandarización de los procesos y el personal que los lleve a cabo en forma idónea. Estudios evidencian que muchos procesos de mejora surgen en el desarrollo de la investigación sin protocolos preestablecidos, y requieren importantes inversiones económicas28.
A la par con la necesidad de publicar artículos científicos rigurosos, se hace necesario explicitar métodos que garanticen en forma real, la calidad de los datos recopilados y analizados para soportar las conclusiones de las investigaciones realizadas. Dar cuenta en forma detallada de estrategias para mantener el ACCD no es frecuente en los artículos, pues suele resumirse sin mayor detalle en la sección de los métodos29.
Si bien el ACCD son conceptos separados y que pertenecen a dos momentos diferentes en la ejecución del estudio, en la práctica suelen ser elementos codependientes y de permanente aparición, hasta tal punto que hay estrategias que pueden ser consideradas dentro de ambos conceptos. Existen publicaciones que proporcionan una serie de elementos sucesivos de aplicación sistemática para garantizar cierto nivel en la calidad del dato16,21. En el caso de los estudios prospectivos, la depuración posterior puede mejorar la utilidad de los datos, pero la corrección retrospectiva de los problemas que surgen durante el periodo de recopilación es, en el mejor de los casos, una tarea que requiere mucho tiempo y puede ser imposible. Por lo tanto, los esfuerzos de calidad de los datos deben comenzar en la fase de diseño del estudio30.
Como debilidad de este trabajo, se reconoce que no hubo un protocolo previo para medir el efecto del control de la calidad del dato en el estudio de cohorte referenciado24, diferente a los instrumentos mencionados. Otra debilidad es la baja posibilidad de comparar estos resultados con otros estudios, debido no sólo a la baja frecuencia de publicaciones de este tipo, sino por la especificidad de cada aplicación realizada. Dado que se diseñó y utilizó un instrumento de recolección de datos, sin pretensiones de validación como escala, no se realizó análisis de consistencia interna de los datos con índices como el Alpha de Cronbach. Se rescata como positivo el ofrecer este tipo de reporte como insumo de aprendizaje, a quienes emprendan un gran estudio de cohorte como el realizado.
Se concluye que la estrategia usada en este estudio de cohorte con pacientes con ERC aportó en la calidad de los datos desde la captación, en la medida que se redujeron la proporción y los tipos de errores más frecuentes, gracias a su identificación y corrección temprana, además del subsecuente ajuste a los instructivos y a la capacitación continua del personal. El análisis mostró una buena concordancia inter-evaluador.
La calidad de los datos recogidos durante un estudio longitudinal repercute en la fiabilidad y validez de las mediciones. Mantener la integridad de los datos a lo largo del tiempo plantea retos, especialmente con los cambios de personal, los errores de transcripción y los acontecimientos históricos.