











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
Permalink
I. INTRODUCTION
Cocoa, which is a tropical agricultural product in worldwide demand by different industries, represents an important source of economic sustenance for small farmers. In 2017, Colombia registered an increase of 3.750 tons in production compared to the previous year, which marks a milestone for the country consistent with the efforts of farmers, guilds, and the national government. In addition, cocoa has was nominated for "crop for peace", which allows the substitution of illicit crops and the generation of job opportunities. However, the causes of the production increase lie in the expansion of the harvested area and not in the improvement of productivity and agricultural practices, crop renewal or use of new technologies.
Machine learning has become an alternative for studying agricultural yields and identifying the factors that explain their variability, including climatic and soil conditions. This alternative considers each crop as a different experiment and their associated data is adjusted to a certain function to make predictions [1 - 3]. Drummon et al. [4] proposed the use of neural networks, stepwise linear regression, and projection pursuit regression to predict the yield of corn and soybean in Missouri, United States, by considering physical and chemical characteristics of the soil, as well as climatic conditions. Similarly, De Paepe et al. [5] analyzed the effects of soil characteristics and climatic conditions on wheat yields in the Argentine pampas using neural networks. On the other hand, several authors have modelled crop yields according to the phenotype of the plants [6 - 8]. Romero et al. [8] suggested OneR, IBK, C4.5, and Apriori classification algorithms to provide association rules in order to predict the level of wheat production, according to spikelet number, plant height, peduncle length, and spike fertility. Other authors have evaluated variables such as quantity of fertilizer, fertilizer source, pest and disease management, and seed variety [7, 9-10].
Regarding cocoa crops, the yield prediction has been approached from different perspectives. Corrales et al. [11] predicted the cocoa yield level in Santander. The authors evaluated the daily average temperature, daily relative humidity, and total daily precipitations rate, using ten different algorithms implemented in WEKA software. For them, Random Forest was the algorithm that generates the best model in order to classify cocoa yield levels. Other studies [12-13] evaluate the yield using linear regression models, ANOVA and mechanistic models like SUCROS, finding that climatic conditions (such as temperature, radiation and rainfall) are the most critical in the cocoa productivity.
According to the literature, machine learning algorithms have had satisfactory results in different traditional crops, such as wheat, corn, soybean, and rice. However, few studies have assessed the factors that affect the cocoa yield using this approach and, particularly, evaluating the influence of shadow on agroforestry systems. Therefore, the present research study evaluates some of the most powerful and popular algorithms: Support Vector Machines, Random Forest, Gradient Boosting, and LASSO regression, to predict cocoa yields and identify the factors that influence them. Similarly, from a marginal influence analysis, these algorithms are used to determine the factors that affect cocoa yield depending on the kind of sun exposure (shade-grown or sun-grown), which is key to differentiated agricultural management and productivity maximization.
II. MATERIALS AND METHODS
Data is the most important input for predictive model construction based on machine learning. This section describes the experimental design used to obtain the data, and the secondary sources consulted. Furthermore, it shows the algorithms implemented and the metrics used to compare their different performances.
A. Data Acquisition
The data analyzed in this research study was obtained from an experimental crop during the period 2015-2017. This crop was stablished in 2008 in the research center "La Suiza" of the Colombian Corporation for Agricultural Research – Agrosavia - in the municipality of Rionegro (Santander, Colombia), at an altitude of 550 meters above sea level. The experimental design was completely randomized in a block design, with three replicates, ten cocoa varieties (5 universal and 5 regional) [14], three levels of fertilization, and two kinds of sun exposure (Table 1).
Table 1 Factors and experimental design levels
| Clones | Fertilization | Exposition |
| Regionals clones: SCC-19, SCC-52, SCC-61, SCC-64, SCC-83 Universal clones: CNN-51, EET-8, ICS-1, ICS-95, TSH-565 | 50%, 100%, 50% | Sun / Shade |
Fertilization is related to the percentage of basic criteria which includes urea, Diammonium phosphate (DAP), KCl, organic matter, sulfur (S), magnesium sulfate (MgSO4) and borate.
The treatments were applied to five plants per replication, for a total of 900 plants per hectare (450 sun-grown and 450 shade-grown). The shade is supplied by Cariniana pyriformis Miers and Tectona grandis L.f, with an average height of 12 [m] and a density of 340 [trees/ha].
Also, the models consider the physical characteristics of the soil and the climatic conditions of the area (Table 2), which were measured daily by meteorological stations located in the region (Watchdog 2000, Spectrum Technologies Inc, Aurora, IL, USA) and data from the “Instituto de Hidrología, Meteorología y Estudios Ambientales” (Ideam).
Table 2 Inputs for development of cocoa yield model
| Variable name | Meaning | Type | Variable name | Meaning | Type |
| Cocoa_v | Cocoa variety | Cata | P_accu_prev | Accumulated rainfall one month before harvest | Conb |
| Exp | Exposition | Cata | T_avg | Temperature average on harvest month | Conb |
| F_level | Fertilization level | Cata | T_avg _prev | Temperature average one month before harvest | Conb |
| EC_avg | Electrical conductivity on harvest month | Conb | Rad_accu | Accumulated photosynthetic active radiation (PAR) | Conb |
| Hum_avg | Soil humidity average on harvest month | Conb | Rad_accu_prev1 | Accumulated photosynthetic active radiation (PAR) one month before harvest | Conb |
| P_accu | Accumulated rainfall on harvest month | Conb | Rad_accu_prev2 | Accumulated photosynthetic active radiation (PAR) two months before harvest | Conb |
B. Linear Regression Models
The linear regression LASSO (Least Absolute Shrinkage and Selection Operator) is a statistical model that relates a set of independent variables (predictors) to one dependent variable (response variable). Unlike the classical linear regression model, LASSO includes a regularization factor (α) in the regression coefficients, using the L1 norm (absolute value) equation (1).
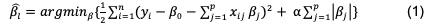
Where y is a vector of observations (yield), xij are vectors of independent variables (independent variables), β are the regression coefficients, and . is the penalty. A high value of α implies low or almost zero coefficients, while a low value, a classical linear regression. Therefore, the value of α is determined by cross-validation.
C. Support Vector Machines (SVM)
SVM is a non-parametric algorithm based on statistical learning theory that seeks to identify a decision hyperplane where the margin of separation between positive and negative observations is maximum. Initially, Vapnik [15] proposed this algorithm for classification problems, however, it has been extended to regression problems [16]. The objective is to minimize the error between observed data (dependent variable – cocoa yield) and a family of functions F(x,w) parameterized by w, and x, which is the input space (independent variables).
D. Ensemble Learning Models
Ensemble methods are based on the premise that multiple algorithms are better than one, since they improve predictive performance by aggregating multiple and independent learning algorithms [17]. Base and aggregation algorithms are used to build an ensemble. The first ones are used to generate multiple predictions that are adding. The algorithm is usually a regression tree. On the other hand, the latter manipulates the inputs of the base algorithms to generate independent models. In the development of the present research study, the following aggregation algorithms are considered:
1) Boosting: iterative procedure to adaptively change the distribution of training samples, so that the basic algorithm focuses on samples that are difficult to predict. In each iteration, weights are assigned to each training-observation, which are updated according to the error with respect to the observed values. Two of the most popular boosting algorithms are AdaBoost and Gradient Boosting, the latter does the training of the base algorithms with the errors of the previous iteration, and maximizes the predictive accuracy by means of gradient descent [18].
2) Random Forest: it was proposed by professor Leo Breiman [19]. This algorithm is a combination of predictions of multiple regression trees, where each one depends on a set of independent random vectors and has the same probability distribution.
E. Evaluation Metrics
These metrics evaluate the model performance and compare it with other proposals. Some of these metrics include the Root Mean Square Error (RMSE), the Mean Absolute Error (MAE), and the coefficient of determination (R2), as shown in equations (2), (3) and (4).
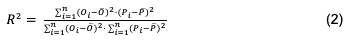
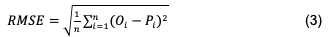


Where: Oi and Pi are the observed and predicted values for the ith observation, respectively; O ̅ and P ̅ are the average values of the observed and predicted yield; and n is the number of observations. The relative improvement of RMSE (〖RI〗_RMSE) shown in equation (5) was used to measure and compare the algorithms and establish the alternative that best fits the yields observed in the crop. 〖RMSE〗R. and 〖RMSE〗c. are the performance values of the reference and comparative algorithms, respectively.
III. RESULTS AND DISCUSSION
Initially, the predictive models are built for the complete dataset (cocoa yield and inputs described in table 1), including the kind of sun exposure as an independent variable. In a second scenario, the dataset is divided according to the kind of sun exposure: sun-grown (284 observations) and shade-grown (274 observations).
In the training phase, 80% of the data is used as the training set for each model, and the remaining 20% as the test set (hold-out validation). In the same way, a cross-validation with k=10 was performed, together with grid search, to establish the best hyper parameters for each algorithm. The module of model_selection in the sklearn package is used [20] for this process.
A. Model Evaluation
Table 3 shows the average results for performance metrics in hold-out validation. On average, the performance of Gradient Boosting is higher than the other algorithms, with the lowest values for MAE and RMSE, and the highest value for R2. Moreover, the relative improvement in RMSE is 20.99%, 8.54%, and 5.93% compared to LASSO, SVM, and Random Forest, respectively.
Table 3 Average performance of the algorithms for the complete dataset
| Model | MAE | RMSE | R2 (%) | RIrmse (%) |
| LASSO | 20.65 | 31.73 | 20.65 | 20.99 |
| SVM | 15.69 | 27.41 | 41.17 | 8.54 |
| Random Forest | 14.7 | 26.65 | 44.19 | 5.93 |
| Gradient boosting | 12.94 | 25.07 | 49.29 | - |
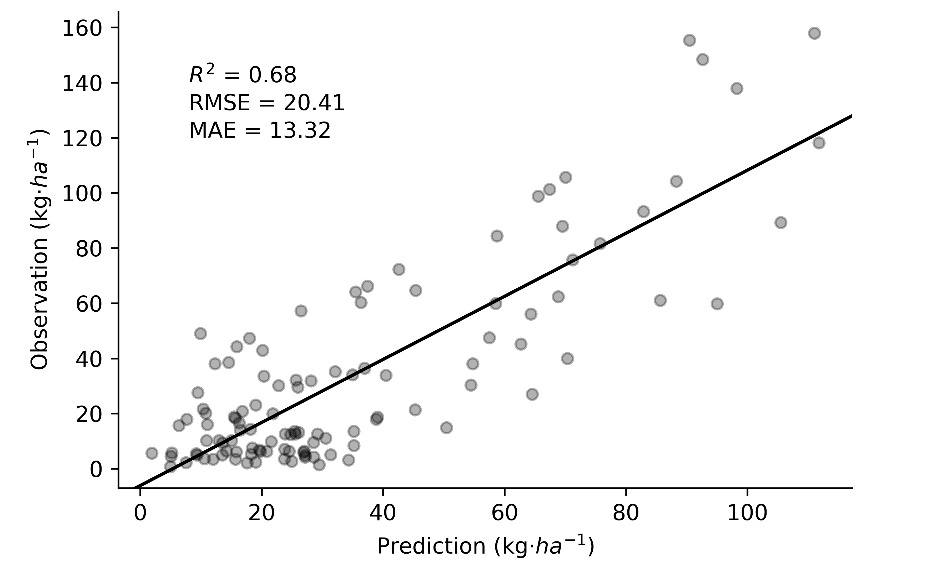
For each of the 100 repetitions in holdout validation, the algorithm is trained and tested with a random sample, where the best alternative is Gradient Boosting with 480 trees. This algorithm explained the 68% of the variability, and presented a MAE of 13.32, and a RMSE of 20.41 (Figure 1).
Once the best model alternative is identified, the next step is to evaluate the importance of the variables. For Gradient Boosting, the MSE Friedman metric allows to choose the variables which will improve the quality in a split. However, to make a comparison between the impact of each variable in the different algorithms and quantify this impact, it is necessary to use another strategy. The partial dependence plots illustrate the marginal influence when a variable change and the other variables remain constant. Logan et al. [21] proposed an alternative to measure the marginal influence with equation (6).

Table 4 shows the variables with the highest oscillation value considering the best model identified in the validation phase.
Table 4 Variables for the complete dataset considering Gradient Boosting
| Variable | Swing | Variable | Swing |
| P_accu | 0.17 | Clon_CCN51 | 0.07 |
| Rad_accu_prev1 | 0.16 | Clon_TSH565 | 0.07 |
| Rad_accu_prev2 | 0.10 | T_avg _prev | 0.06 |
These results indicate that the average temperature one month before harvest, the accumulated radiation one and two months before harvest, and the accumulated rainfall on harvest month are the factors with greatest impact on crop yields. According to [22], temperature is one of the factors that limit cocoa production, since it causes stress on the plants, increases seasonal variability, and is responsible for the reduction in photosynthetic rates. Radiation and rainfall are related to the final stage of cocoa crop growth, where rainfall is more important than radiation [13]. Concerning the sun exposure variable, the oscillation is close to 0. Thus, it can be assumed that the type of sun exposure is not representative for the predictive model.
The variable influence evaluation is performed using Gradient Boosting as well as partial dependence plots for the interaction between precipitation, temperature, and radiation one month before harvest (Figure 2).
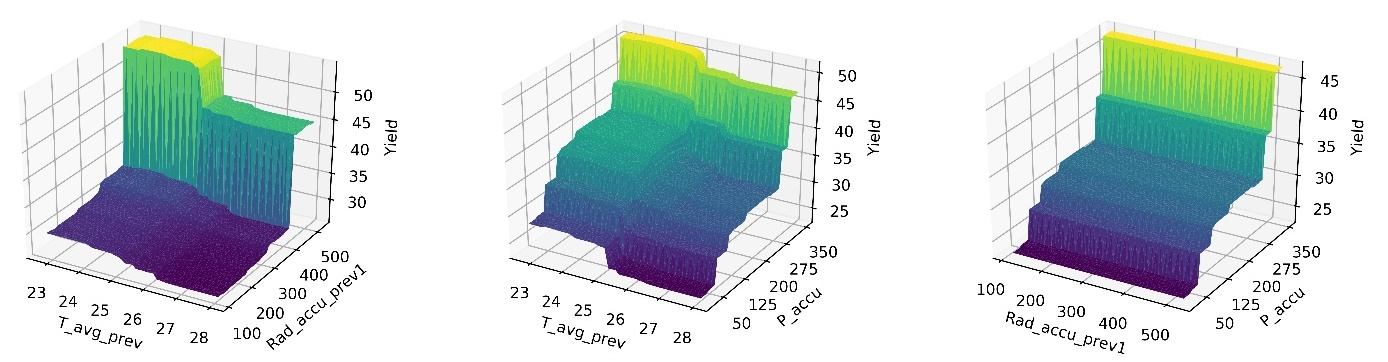
The vertical axis (crop yield) shows that the interaction between radiation and accumulated rainfall has the lowest effect, while interactions with temperature generate higher yields. These results suggest that the control of temperature, radiation and accumulated rainfall are determinant for increasing crop productivity. Likewise, the effect of radiation decreases when it interacts with rainfall, which ratifies accumulated rainfall as the most influential variable on crop yields.
B. Sunshade Exposure Models
In this second scenario, for each kind of exposition (sunshade) the best identified algorithm is ran again. Table 5 shows that variability is best explained in the shade-grown model with an average R2 of 54.27%, and lower values of MAE and RMSE, compared to the sun-grown model.
Table 5 Average performance for two different kinds of sun exposure
| Metric | R 2 | RMSE | MAE |
| Sun | 42.28% | 25.98 | 14.67 |
| Shade | 54.27% | 24.51 | 11.25 |
To evaluate the importance of the variables in the models associated with the kind of sun exposure, the procedure described in the previous section is applied once again. Table 6 suggests that the accumulated rainfall on harvest month and the average soil moisture are the most influential variables in the sun-grown predictive model. This result evidences the higher water requirements of sun grown plants. In fact, sun-grown crops have a higher leaf transpiration and soil water evaporation, which lead to lower photosynthetic activity and higher stomatal closure. The last affirmation implies shorter production cycles, higher nutrient requirements, better management of irrigation systems, and, therefore, a higher investment [23].
For the shade-grown case, radiation one month before harvest has the highest oscillation value, which indicates a strong relationship between this variable and crop yield. As stated by Zuidema et al. [13], shade must be properly managed in this kind of crops, to avoid yield reduction due to lack of radiation.
Table 6 Importance of variables for sun-grown and shade-grown models.
| SUN | SHADE | ||
| Variable | Swing | Variable | Swing |
| P_accu | 0.20 | Rad_accu_prev1 | 0.39 |
| Hum_avg | 0.13 | P_accu | 0.11 |
| Clon_CCN51 | 0.10 | Rad_accu | 0.08 |
| Clon_TSH565 | 0.07 | Clon_TSH565 | 0.06 |
Furthermore, in Table 6 some cocoa clones are identified (CNN-51 and TSH-565). As a result, the cocoa yield is evaluated and compared in the two kinds of sun exposure. A Kruskal-Wallis test is used with a significance level of 5%, stating as a null hypothesis that the medians of the samples are equal. With values of p < 0.05, the results (Table 7) suggest that CNN51 and SCC64 clones perform dissimilarly in both kinds of sun exposure. Likewise, the average yield indicates that both clones perform better under sun-grown conditions.
Table 7 KruskalWallis test
| Cocoa clone | Yield mean Sun | Yield mean Shade | Yield median Sun | Yield median Shade | P_value |
| CNN51 | 62.39 | 33.71 | 44.651 | 19.224 | 0.017 |
| EET8 | 32.42 | 36.18 | 27.641 | 13.532 | 0.145 |
| ICS1 | 30.95 | 25.18 | 17.859 | 18.760 | 0.715 |
| ICS95 | 31.75 | 37.49 | 16.900 | 21.699 | 0.481 |
| SCC19 | 34.77 | 36.92 | 20.649 | 14.953 | 0.984 |
| SCC52 | 33.23 | 29.67 | 24.966 | 18.205 | 0.742 |
| SCC61 | 57.86 | 44.90 | 37.670 | 23.521 | 0.751 |
| SCC64 | 43.53 | 30.43 | 27.615 | 16.211 | 0.012 |
| SCC83 | 28.22 | 45.16 | 21.718 | 20.673 | 0.575 |
| TSH565 | 45.58 | 41.35 | 37.930 | 24.078 | 0.269 |
In general, there is no difference between the crop yield under sun and shade-grown conditions, which is positive for the promotion of agroforestry crops. These findings are consistent with [12-13, 24], who state that shade does not affect cocoa yield, as long as it is adequately provided. In addition, [25-26] state that moderate shade-grown crops have positive implications for soil management, moisture and temperature control, and for the creation of environments to improve cocoa physiology and reduce the impact of pests and diseases.
IV. CONCLUSIONS
This research study proved the ability of machine learning algorithms to represent agricultural crop relations and predict their yields. Therefore, they are an adequate alternative to support farmers and stakeholders in the cocoa production chain. Comparative results indicated that the Gradient Boosting algorithm performs best with the highest value of R2 and the lowest of MAE and RMSE. Also, relationships between variables are identified to improve the specific management of crops and, therefore, their productivity.
Variables such as radiation one month before harvest, rainfall on the harvest month, temperature one month before harvest, and soil moisture are the most important to explain the variability of crop yields. Sun-grown crops should have adequate management in their irrigation and fertilization systems, while shade-grown crops should have careful management of their forest plants. These results provide valuable information to make decisions targeted at crop requirements, which allows the implementation of a specific agriculture management that may not only improve the productivity, but also reduce costs. For instance, if there is no significant difference between the sun and shade yield, farmers should choose agroforestry systems with positive implications over soil management and moisture and temperature control. By doing so, the crop productivity won't be compromised. It is important to mention that results must be carefully interpreted, since the models are based on data taken from a specific site, and the performance of clones may vary according to geographic and environmental conditions. However, the methodological approach can be replicated in other study sites.
Future researches can consider multiple study sites to determine changes in crop yield influential variables according to crop location. Also, it is recommendable to incorporate other predictor variables in the models, such as the age of the cocoa plants, agricultural practices, or geographical location.

