











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
I. Introducción
La biodiversidad de los países tropicales se considera un foco de atención debido a su riqueza endémica, la cual se ha visto amenazada por los problemas ambientales. En particular, el bosque seco tropical (BST) de Colombia es uno de los ecosistemas más amenazados, en razón de factores como el crecimiento de la población, las grandes extensiones de tierras ganaderas y la deforestación para la exploración agrícola desde los tiempos coloniales [1]. Para guiar las políticas de conservación del medio ambiente, es indispensable establecer el estado de perturbación de cada ecosistema.
Existen dos indicadores importantes para comprender este estado. El primero es la permanencia, que permite identificar la capacidad de los ecosistemas para persistir en su estado original, a pesar de las distintas perturbaciones [2]. El segundo es la transformación, que se asocia con el grado de transición de un ecosistema alterado. Tradicionalmente, los expertos en conservación miden estos indicadores mediante la observación directa, creando inventarios de especies. Este método tiene varias desventajas, como ineficiencia de costos, mucho tiempo para el análisis de grandes extensiones de tierra y perturbación de los sitios estudiados [3].
La bioacústica se centra en el análisis de los sonidos producidos por los animales para estudiar sus comportamientos, formas de comunicación y áreas donde viven [4]. La ecoacústica incluye el estudio de la antropofonía (sonidos generados por las actividades humanas), la geofonía (sonidos ocasionados por el viento o lluvia) y la biofonía (sonidos causados por animales diferentes al ser humano) para estimar la densidad de población, las estructuras internas, la distribución espacial y los efectos de los cambios globales [5].
Una de las técnicas que permite el estudio de los ecosistemas sin perturbarlos es el monitoreo acústico pasivo [6], el cual usa grabaciones acústicas para investigar la vida silvestre y sus entornos, a través del análisis de los sonidos biofónicos, geofónicos y antropofónicos [7]. Estos registros se realizan en los lugares de estudio durante horas, días y meses.
Dada la complejidad del paisaje sonoro y la necesidad de examinar grandes cantidades de datos, se han propuesto variables representativas para identificar automáticamente las características biológicas en las grabaciones. Entre estas, los investigadores han desarrollado los índices acústicos [8], que muestran la distribución de la energía en el sonido y ayudan a extraer información de los ecosistemas: riqueza de especies, igualdad entre comunidades y nichos acústicos, entre otros [9].
En lo que se encontró, existen pocos trabajos centrados en el análisis del paisaje sonoro para generar herramientas computacionales que contribuyan a identificar los cambios de los ecosistemas. Gómez et al. [10] demostró la posibilidad de diferenciar entre tres tipos de ecosistemas (bosque, rastrojo y pastizal) del bosque húmedo tropical (BHT), por medio de instrumentos de aprendizaje automático sobre índices acústicos. La primera aproximación para identificar las transformaciones del BST de Colombia a partir del análisis de grabaciones acústicas [12] empleó algoritmos de aprendizaje no supervisado para encontrar estados intermedios de la transformación de los lugares estudiados. Sin embargo, este planeamiento tuvo un bajo rendimiento en zonas del BST donde se contaba con bases de datos desbalanceadas. Es necesario continuar con propuestas de herramientas computacionales específicas para la identificación del nivel de transformación del BST. Este documento expone una metodología útil para definir automáticamente esta alteración, con base en el análisis de grabaciones acústicas, en las cuales se consideraron los índices más informativos y se añadió una nueva variable, usualmente aplicada en la identificación de géneros musicales.
II. Métodos
El método utilizado incluye cuatro etapas. Primero, se aplica el algoritmo presentado en Bedoya et al. [13], a fin de separar las grabaciones ruidosas. Segundo, en cada grabación, se calculan los índices acústicos seleccionados. En el tercer paso, para el estudio de cada región geográfica, se genera un Gaussian Mixture Models (GMM) en cada estado de transformación, usando el algoritmo de Expectation-Maximization (EM) para estudiar las zonas localmente.
Con el objetivo de analizar todas las regiones, se utiliza un Universal Background Model (UBM). Cuarto, para estimar el tipo de transformación con cada nueva grabación, se ingresan los índices acústicos a los modelos en cada región y se calcula el Log-Likelihood para cada GMM. Se escoge la etiqueta del nivel de transformación para cada nueva grabación, de acuerdo con el máximo valor del Log-Likelihood. Estos pasos se describen con mayor detalle en las siguientes subsecciones. Las etapas principales de la metodología propuesta se presentan en la Figura 1.
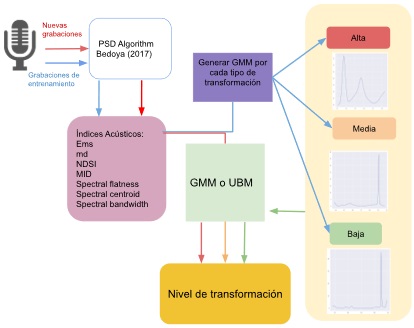
A. Lugar de estudio
Los registros acústicos fueron proporcionados por el Instituto “Alexander Von Humboldt” (IAVH). Estos se grabaron en diferentes zonas geográficas de la región caribeña colombiana en las cuencas de los ríos Cañas y Arroyo, localizados en los departamentos de La Guajira y Bolívar. Las áreas corresponden a un ecosistema de BST, en tanto que los registros pertenecen al lapso entre diciembre de 2015 y marzo de 2017 (Proyecto GEF). El BST se ubica entre 0 y 1000 metros sobre el nivel del mar, con altos niveles de endemismo, altos cambios en las precipitaciones y periodos secos de entre 3 y 6 meses.
Con el fin de desarrollar el aprendizaje de los algoritmos, los registros se etiquetaron de acuerdo con el gradiente de nivel de transformación (alto, medio, bajo). Este sistema de clasificación se asignó a través de la observación directa realizada por investigadores del IAVH especializados en vegetación y especies de ecosistemas, con base en el análisis de bosque/no bosque en la serie temporal entre 1990 y 2012 del IDEAM.
El nivel de transformación bajo corresponde a las zonas con una proporción mayor de bosques retenidos/nuevos y una proporción menor de bosques perdidos. El nivel de transformación alto se refiere a las áreas con una alta pérdida de bosques y una transformación media en las zonas restantes. En este trabajo, se analizaron tres espacios geográficos: Cesar y San Juan Nepomuceno, en el departamento de Bolívar, y Mingueo, en el departamento de La Guajira. Las grabaciones de Bolívar se registraron en el río Arroyo Medio; las de Cesar, en el río Garupal, y las de La Guajira, en el río Cañas. En ellas, se emplearon grabadoras SM2 y SM3 (wildlife acoustics), programadas para grabar 5 minutos cada 10 minutos durante 5 días continuos y dejar de grabar 5 días.
B. Algoritmo de detección de lluvias
Uno de los elementos geofónicos más relevantes en el campo de la ecología del paisaje sonoro es la lluvia, pues modifica las propiedades físicas del ambiente [14] (humedad relativa), lo que influye en los patrones de reproducción y la estructura de especies tropicales como los anuros [15] y las aves [4].
El método propuesto por Bedoya et al. [13], es un buen estimador para reconocer registros con lluvia, sonidos geofónicos fuertes y elementos antropogénicos, ya que se basa en el uso de Power Spectral Density (PSD). Con el fin de calcular la PSD, se implementó el método no paramétrico de Welch [16] (ecuación 1), donde . es el periodograma de la señal en cada ventana y . es el número de la ventana.
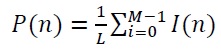 (1)
(1)
Para calcular automáticamente el umbral de la PSD en cada set de grabaciones, se eligió la mediana del cálculo de esta en todas las grabaciones de la zona analizada. Con el propósito de evitar falsos positivos, se obtuvo la relación señal-ruido (SNR). De esta manera, el valor del umbral se desprendió del menor valor de la SNR que presentan las grabaciones ruidosas.
C. Extracción de características
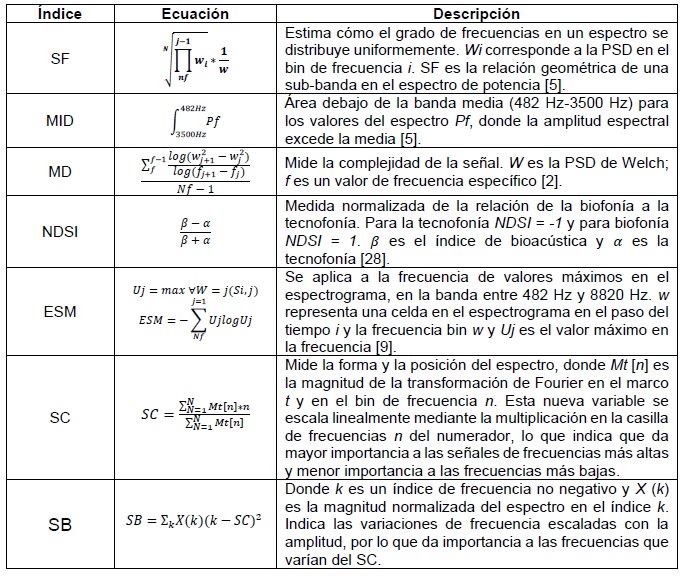
Los índices acústicos seleccionados, también utilizados en estudios de paisajes [9, 12, 17], son Entropy of Spectral Maxima (ESM), Musicality Degree (MD), Normalized Difference Soundscape Index (NDSI), Mid-Band Activity (MID) y Spectral Flatness (SF), como se detalla en la Tabla 1.
Con el objetivo de identificar los índices acústicos más relevantes, se construyeron los diagramas de cajas representados en las Figuras 2 y 3.
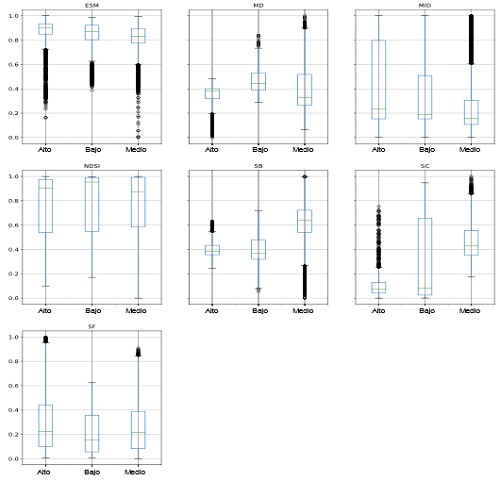
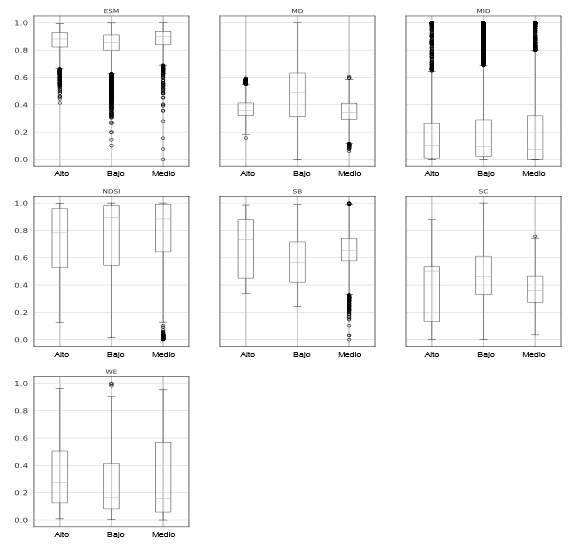
Además, los índices acústicos se implementaron en Python usando las librerías: Numpy, Math, Scipy y Librosa. Este estudio incluye dos nuevos índices SC y SB, que se han usado en el diagnóstico de la enfermedad de Alzheimer [18] y en la clasificación de los géneros musicales [19].
El índice MD presentó un comportamiento semejante entre los dos casos de estudio y mostró diferentes niveles en cada etiqueta de transformación, por lo que se estimó pertinente insertarlo en el estudio. De manera similar, los índices ESM, NDSI, SC y WE demostraron una buena discriminación entre dos niveles de transformación. Por otro lado, algunos índices no resultaron homogéneos; por ejemplo, el índice NDSI tuvo valores altos para la transformación alta y baja en Bolívar, mientras que, para La Guajira, cobró valores altos para la transformación baja y media.
D. Métodos de clasificación
Los índices acústicos ingresan a un clasificador que permite discriminar el tipo de transformación. Este estudio plantea dos modelos de clasificadores basados en GMM; ambos se implementaron en Python usando la librería Mixture [20]. El primero genera modelos GMM para cada zona geográfica, usando el máximo Log-Likelihood para definir el tipo de transformación. El segundo es una propuesta para trabajar estableciendo un UBM con todas las áreas, con el objetivo de detectar el nivel de transformación en el BST, independientemente de la región. El GMM es un híbrido entre un modelo de densidad paramétrico, puesto que tiene una estructura y unos criterios que controlan el comportamiento, y un modelo de densidad no paramétrico, ya que despliega la restricción en el tipo de distribución [21]. La distribución es una combinación lineal de . densidades gaussianas multimodales P(x).
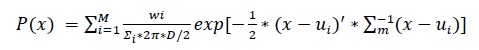 (2)
(2)
Con la restricción de los parámetros se denotan como . Estos se estiman con el algoritmo de EM que los refine iterativamente. A fin de clasificar una nueva grabación, se calcula el Log-Likelihood para cada GMM, teniendo como entrada al clasificador los índices acústicos de la nueva grabación. Finalmente, se elige el valor máximo como el estado de transformación de la grabación.
El UBM es un gran GMM entrenado para representar la distribución independiente de las características. El GMM-UBM se usa como la adaptación de un nuevo GMM al modelo entrenado UBM. Para encontrar los nuevos parámetros, en este caso, se utilizó la estimación del Máximo A Posteriori (MAP), que es una forma de adaptación bayesiana en las mezclas gaussianas.
Existen varios enfoques para entrenar un UBM. En este estudio, entrenamos UBM individuales en subpoblaciones; una por cada nivel de transformación. Este enfoque es eficaz con conjuntos de datos desbalanceados. Los parámetros de cada clase se adaptan al UBM y, finalmente, los índices acústicos de las nuevas grabaciones se ajustan mediante la estimación MAP. Con las nuevas grabaciones generadas por el GMM, el siguiente paso es encontrar la distancia a cada clase. La adecuación del GMM con la distancia de Bhattacharyya (Bha) y la clase con los modelos adaptados de distancia más corta definen la transformación estimada. Bha mide la distancia entre dos distribuciones de probabilidad [22]. Si asumimos el GMM, la distancia de Bha viene dada por esta ecuación.
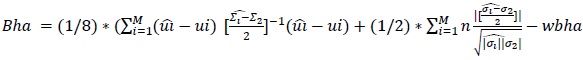 (3)
(3)
Donde 𝑢𝑖 𝑦 𝜎𝑖 son la media y la matriz de covarianza del UBM; mientras que 𝑢𝑖 y 𝛴𝑖 son el vector medio y la matriz de covarianza de las nuevas grabaciones adaptadas del GMM. Cada clase de distancia se compara y se elige la etiqueta de la mezcla gaussiana con la distancia más corta como aquella de las nuevas grabaciones.
III. Resultados
El algoritmo para identificar la lluvia y eventos ruidosos [13], se adaptó con el objeto de distinguir automáticamente las grabaciones de cada zona. Aquellas ruidosas, relativas a altos niveles de PSD y baja relación de señal a ruido, equivalieron a 9.58% de la muestra inicial; los límites de PSD utilizados variaron entre las bandas de frecuencia de 600-1200 Hz. De esta manera, se obtuvieron 9647, 14267 y 21672 grabaciones útiles para Cesar, Bolívar y La Guajira, respectivamente.
En cada registro, se estimaron los índices seleccionados, con el objetivo de extraer información para establecer el modelo de cada región. En Cesar, las grabaciones que superaron el nivel de ruido corresponden únicamente a zonas con nivel de transformación media. Para medir el desempeño del modelo GMM, los datos de Bolívar y La Guajira se dividieron en 70% para el entrenamiento, 20% para la prueba y 10% para la validación. La predicción en la prueba se realizó por medio de Log-Likelihood por muestra, eligiendo la máxima probabilidad de pertenecer a una determinada clase.
Por lo tanto, se empleó Gridsearch (búsqueda exhaustiva para optimización de hiperparámetros), con el propósito de hallar el número óptimo de componentes para cada GMM en los dos enfoques. El mejor rendimiento se encontró con el uso de matrices de covarianza diagonal. Al emplear un modelo general con el GMM, para el BST global (sin importar los lugares de estudio), resultó con una precisión menor de 75% usando un número de componentes de 21 (los valores más altos produjeron un sobreajuste), por lo que se decidió mantener el método propuesto para el análisis local. Teniendo en cuenta este enfoque, se creó un modelo para Bolívar y otro para La Guajira. La Tabla 2 presenta los resultados utilizando GMM.
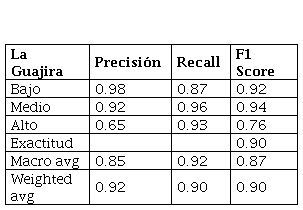
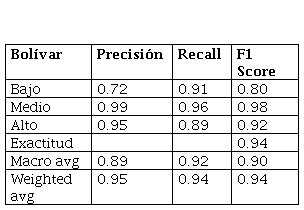
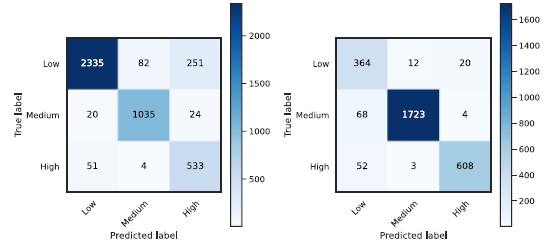
También se halló un número de componentes de 25 como la mejor configuración basada en la precisión para Bolívar. Para La Guajira, se encontró un número de componentes de 30. De hecho, la similitud entre las cifras muestra homogeneidad acústica, ya que ambas zonas son parte del mismo ecosistema. El área de Bolívar tuvo el mejor desempeño, con 93.7% de precisión, y La Guajira obtuvo 89.9% con los datos de validación. La Figura 4 especifica la matriz de confusión, que permite identificar la correspondencia del modelo resultante con las etiquetas esperadas. En ambos casos, la clase con mayor número de registros era la que mejor se adaptaba.
Esto era de esperar, pues había desbalance de datos en ambos sitios. Sin embargo, comprueba que las grabaciones de los niveles de transformación restantes fueron representativas. Se escucharon algunas grabaciones falsas positivas seleccionadas al azar, pero no se encontraron ni ruidosas ni patrones notables. Para producir un modelo general del BST (aplicado a todas las áreas), se realizó un modelo UBM con 50% de los datos en las zonas de Bolívar, La Guajira y Cesar. La adaptación para cada clase se formuló con 30% para cada tipo de transformación, obteniendo un alto GMM, un bajo GMM y un medio GMM. La prueba se desarrolló con grupos de adaptación de grabaciones con 20% restante. En contraste con el enfoque GMM, se logró 84% de precisión.
El modelo general obtenido con el GMM-UBM muestra un mejor desempeño que el enfoque general del GMM. Aunque el rendimiento para el clasificador GMM-UBM no fue tan bueno como el del GMM, el primero tiene un gran potencial respecto de la identificación de cambios en diferentes zonas de un ecosistema; en particular, por el uso de la adaptación bayesiana. Ambos enfoques discriminan entre los diversos estados de transformación del BST. El GMM ofrece buenos resultados, con la limitación de funcionar solamente para cada lugar de estudio con un número distinto de componentes. El GMM-UBM funciona en ambas zonas, con menor desempeño que si se analizan por separado.
IV. Discusión
En este documento, se propuso una metodología que permite identificar los niveles de transformación del BST mediante grabaciones acústicas. En este sentido, se usó el GMM para crear modelos de clasificación locales (regiones individuales); también se utilizó el GMM-UBM para diseñar un clasificador global (todas las zonas). Si bien se plantearon los dos enfoques, a partir de los resultados, se recomienda el análisis para cada área del BST.
Durante el análisis acústico, se estiman, como entrada al clasificador, los índices considerados más relevantes, además de la variable SC, útil para complementar la clasificación de la transformación del BST y no usada anteriormente para el análisis ecoacústico, sino para la identificación de los géneros musicales. El desempeño de los clasificadores es alto, teniendo en cuenta la construcción de modelos capaces de cumplir con el criterio de generalización, ya que el entrenamiento se realizó con un conjunto de datos diferente al de validación.
Se recomienda explorar técnicas que permitan tener grados de pertenencia a los tres niveles de transformación y no a uno solo, como se aborda en este documento. Esto contribuiría al seguimiento de los cambios tempranos del BST para las medidas de conservación de las organizaciones. A pesar de los posibles sesgos debido al desbalance de las muestras por categoría, el modelo discriminó todas las clases elegidas. Los resultados confirman que el análisis multivariado de índices acústicos posibilita la descripción del paisaje sonoro en ambientes perturbados. Sin embargo, los índices presentaron comportamientos diferentes, según las características de la región de estudio.
Esto significa que un índice no necesariamente es discriminante, en términos de la transformación para todos los ecosistemas. Es posible que alguna fuente acústica singular caracterice el comportamiento de los índices, por lo que se requieren más estudios acerca de su variación a partir de las comunidades acústicas específicas de los ecosistemas, con el propósito de identificar factores clave para clasificar los diversos tipos de transformación, independientemente de aquellos.

