











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
Permalink
I. INTRODUCTION
The growth of public documents available on the Web has made it necessary to develop methods to generate summaries quickly and automatically with the most relevant document information. The aim of automatic single document summarization is to provide a short version of the document while preserving the main idea of its content, applying it to multiple areas of study in which documents of different types are considered, such as news, blogs, events, emails, movies, scientific documents and text comprehension, among others [1].
Automatic Document Summarization can be classified according to how the summary is generated: abstractive, extractive, or hybrid. Abstractive summaries are generated using natural language processing techniques that modify the sentences to make the summary more coherent. Extractive summaries are generated with the original sentences of the document by selecting those most relevant. These are faster and more straightforward than abstractive summaries [2]. Meanwhile, hybrid summaries are generated considering the most significant amount of original information, making minor modifications. For this mapping, automatic extractive single document summarization (AESDS) was considered since most studies in the state-of-the-art are of this type.
The majority of AESDS research is based on methods that use statistical features to evaluate the sentences of the document. Among these are position, frequency of terms, number of keywords, and length, among others. Semantic features have also been used to evaluate the meaning and sentiment of a sentence or the semantic distance between them. These include coverage, redundancy, relevance, and similarity with the title, among others. Accordingly, it is essential to analyze which characteristics are most used and what relationship exists in using them.
Additionally, automatic document summarization has been approached considering the number of objectives through three approaches: single-objective, multi-objective (2 or 3), or many-objective (4 or more). The single-objective approach assesses one or a combination of several characteristics. No studies related to the many-objective approach for AESDS were found in this systematic mapping.
This systematic mapping aims to provide knowledge about the methods and techniques used in AESDS by analyzing the different approaches and characteristics evaluated, with the purpose of providing information that can be used for future research.
This article is developed as follows: Section 2 explains the research methodology for the systematic mapping; Section 3 shows the results obtained from the mapping; Section 4 presents a discussion based on the results obtained; and Section 5 presents the conclusions.
II. METHODOLOGY
Systematic mapping is a method that allows the identification and classification of studies containing knowledge related to a specific area, such as AESDS. This mapping was carried out based on the methodological guide proposed in [3] - [6] and in its three central stages Planning, Execution, and Result Analysis (Fig. 1).
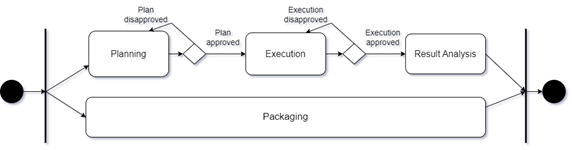
A. Planning
This stage includes the activities described below:
1) Objectives and Research Questions. The set of research questions is designed to align with the objectives posed for this mapping, as presented in Table 1.
Table 1 Research questions.
| Questions | Motivation |
|---|---|
| Q1. What types of methods have been used for AESDS recently? | Identify techniques and approaches to solve the AESDS problem. |
| Q2. Which methods in AESDS have a many-objective approach? | Determine if there are methods with a many-objective approach. |
| Q3. What characteristics are considered for AESDS? | Identify the characteristics most used to evaluate sentences. |
| Q4. What types of clustering have been applied in AESDS? | Identify the clustering techniques used in AESDS. |
These questions and motivations are used to define the search string used in the Science Direct, Springer Link, Scopus, and IEEE search engines.
2) Research Strategy. A search string was designed to find the primary studies (Table 2). This table omits studies whose titles contained the terms multi-document or abstractive.
Table 2 Search string.
| Title, Abstract or Keywords | Title |
|---|---|
| Single AND (text OR document) AND summarization AND extractive | NOT (abstractive OR multi-document) |
Then, to select the primary studies, a selection process was applied where the study title, the abstract, and the complete document were analyzed (Fig. 2).
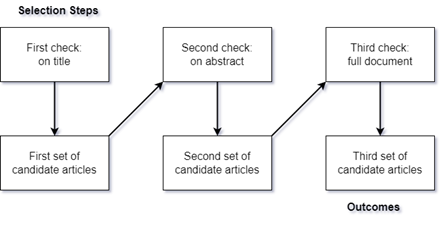
3) Inclusion/Exclusion Criteria. A filter was applied to the studies found considering as relevant those that met the following inclusion criteria: (i) published in English, (ii) contains the keywords defined in the search string, and (iii) falls within the date range between 2018 and 2022. Similarly, those that met any exclusion criteria were discarded: (i) not relevant to the AESDS problem, (ii) published in unrecognized journals, books, congresses, or conferences, (iii) without detailed information or access, and (iv) repeated studies.
4) Quality Assessment Criteria. In addition, to measure the quality of the primary studies, a questionnaire was defined using a 3-value scoring system (-1, 0, +1) according to their content. The first four questions are associated with the research questions, and the remaining questions analyze the importance of the articles (see Table 3). The total score for each item corresponds to the sum of values for each question, obtaining values between -6 and +6. The scores obtained indicate the studies that could be relevant in the future, and the results can be found at the following.
Table 3 Evaluation criteria questionnaire.
| Id | Question | Assigned score | ||
|---|---|---|---|---|
| -1 | 0 | +1 | ||
| Q1 | Is the proposed method ranked in the state-of-the-art in AESDS? | Top 7+ | Top 4 - 6 | Top 3 |
| Q2 | How many objectives are evaluated in the proposed method? | 1 | 2 or 3 | 4+ |
| Q3 | How many characteristics are considered to evaluate the sentences? | 1 to 3 | 4 to 6 | 7+ |
| Q4 | In the paper, was at least one clustering technique used? | No | Partial | Yes |
| Q5 | The impact level of the journal, book, conference, or congress | Q4 | Q2 or Q3 | Q1 |
| Q6 | Number of references in the study | 0 | 1 to 10 | 10+ |
5) Execution Stage. The selection of studies was carried out in four iterations considering the query databases as shown in this, as follows: (i) matching the search string, (ii) considering the inclusion and exclusion criteria, (iii) answering the research questions, and (iv) eliminating repeated studies. At the end of the iterations, out of the 571 studies found, 24 primary studies were obtained (Table 4).
III. RESULTS
The results obtained for each mapping research question related to the quality criteria are presented below:
Q1. What types of methods have been used for AESDS recently? A significant group of 13 studies (54%) based their proposals on machine learning (ML) [7]-[13] or hybridizing neural networks with techniques such as graphs [14], metaheuristics [15], differential evolution [16], NLP[17], [18], or genetic algorithms [19], and most of the methods present in the ranking of state of the art are among these proposals.
Q2. Which methods in AESDS have a many-objective approach? From the set of 24 studies obtained in the execution stage and from the results obtained from the evaluation questionnaire, it is evident that there are no studies where a many-objective approach is considered. Thirteen studies (54%) are multi-objective, while the remaining 11 (46%) are single-objective.
Q3. What characteristics are considered for AESDS? In the studies reviewed, one feature or the combination of several features (naive multi-objective approach) can be evaluated in a single objective. From these, the most commonly used features were: sentence position 54%, sentence length 46%, title similarity 29%, proper nouns 29%, TF-IDF measure 29%, numerical data 21%, keywords 17%, coherence 17%, antiredundancy 17%, sentiment (positive or negative) 17%, aggregate similarity 13%, diversity 8%, readability 8%, coverage 8%, date-type data 4%, centrality 4%, among others such as number of verbs, importance, number of entities, relevance, number of verbs, bigrams, and trigrams.
Q4. What types of clustering have been applied in AESDS? It was found that 16 studies (64%) included the use of some grouping or clustering technique such as K-means [13], [20], [21]; K-medoids [15], [22], [23]; neural network-based clustering, e.g., self-organizing maps (SOM) [7]-[9], [15], [16]; topic detection such as LDA [14]; clustering by keyword identification [11], [18], [24] or using non-negative factorization matrices [12], [25].
IV. DISCUSSION
This AESDS systematic mapping identified a preference for machine learning methods or hybridizing with machine learning. These methods report excellent results and are well-placed within the state-of-the-art ranking. For example, in [15], [16], self-organizing maps (SOM neural networks) combined with metaheuristics are used, and in [14], neural networks are used together with graphs, among others.
Although semantic features evaluate the meaning and sentiment of a sentence or the semantic distance between sentences, a high percentage of research found uses statistical features (sentence position, sentence length, proper names, numerical data), showing that these are still useful for the generation of extractive summaries. In addition, the best state-of-the-art methods [16], [21], [26] show the importance of considering both types of features (statistical and semantic) independently or combined.
Concerning the many-objective approach, no previous study considered four or more objectives, providing a space for future research using this approach.
Similarly, there is growing attention to the inclusion of clustering techniques in AESDS methods, also achieving an improvement in the results compared to other similar or equal methods in the state of the art that do not include these techniques.
V. CONCLUSIONS
This AESDS mapping identified specific methods that tend to obtain the best results from the state-of-the-art. These are machine learning-based or hybrids that include some clustering techniques.
It was also found that statistical features remain relevant for assessing the quality of summaries in AESDS methods, as most of the methods found in this systematic mapping use this type of feature.
In future work, we propose to address the AESDS problem with a many-objective approach because, in this research area, there are combinations of features that can be evaluated independently. In addition, we intend to continue mapping this research area because it is very active, and new articles are constantly being published. We further hope to consider mapping the automatic generation of summaries for multiple documents and abstractive methods for summarization.

