











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
Permalink
I. INTRODUCTION
Traditional search engines generally use statistical techniques that determine relevance by keyword matching without fully understanding the user's search intentions and the implicit context of the indexed information [1 - 2]. Retrieving relevant and personalized information poses a challenge for Information Retrieval Systems (IRS) that need to satisfy a user's need presented in the form of a question and specified through a set of keywords by analyzing a collection of documents with variable volume and format [3]. The Information Retrieval (IR) process has been improved by developing several models [4 - 8] focused on solving problems related to:
The difficulty to identify and understand the user's needs written in natural language when entering exact or ambiguous terms limits the retrieval of relevant documents.
The retrieval of documents by the statistical term without analyzing the context of the question and the stored information.
To solve the main shortcomings identified in the IRSs, we propose to process documents [9 - 11], queries [12 - 15], and the user profile [2,16,17] to improve the IR by using ontologies and analyzing the user's behavior.
In the IR process -even though knowing users' search intent is important to understand their need- applying relevance algorithms that combine preference profile [16 - 18], query expansion [2,14], and semantic annotations [2,9,11] enables enhancing the obtained search results.
Customization of search results plays an important role in the level of user satisfaction when interacting with an IRS [19]. Gupta et al. [20] proposed the use of web mining techniques, Natural Language Processing, and ontologies to extract behavioral patterns from users' web logs. Regarding the generation of the user preferences profile, the main proposals focus on combining explicit (selected interests in their profile related to topics, age, and gender) and implicit preferences (browsing history and user location) to model the profile according to the users' behavior [2, 16,17,21,22].
According to [23,24] in the construction of a user profile, three fundamental phases related to collecting, constructing, and using the data acquired by analyzing the user’s behavior in a CRS are identified. IRSs register the user’s actions to collect as much information as possible to identify behavioral patterns and obtain their preferences.
Nandanwar, Choudhary, and Singh [25] analyze users’ implicit and explicit preferences to generate a hybrid profile, and they weight it by a constant value α = 0.6 between a short-term and long-term profile to obtain a preference value between [0, 1]. However, the proposal does not describe the method to apply the temporality of the profiles. Queries are classified into ambiguous and unambiguous to improve their processing; the terms of the ambiguous query are expanded with WordNet and modified with the combination of the maximum similar category and the user's profile. The authors apply cosine similarity to determine the relevance between the expanded query and the document collection to display results relevant to the user and then update the profile preferences [25].
In addition, a user preference profile combining tags, annotations, and retrieved documents [18]. Two algorithms that extract the terms are designed to analyze their match with the documents and select the most relevant ones to be included in the user profile. The user's preference profile is used to expand the query.
The proposals by [23,24,25] focus on extracting information from user behavior to predict search preferences. The preferences elicitation and the temporality of the profile present shortcomings, which reduce the effectiveness of the search results customization. This paper proposes weighing the preferences profile temporality and consider the relevance of the concepts used in the query and documents retrieved and consulted by the user to fix the identified deficiencies.
Query expansion (QE) seeks to reformulate the original words written by the user and substitute them for relevant terms from different sources, weighing them to reduce ambiguities and improve the information retrieval accuracy [2,13,14]. When the user submits a query, it is expressed in natural language and sometimes uses imprecise sentences that do not allow the IRSs to provide relevant results. Some literature reports [12,14,26] propose that, to understand the context of the question asked by the user, it is necessary to expand the query through ontological repositories and preference profiles [13,14].
The main expansion techniques in [2,12,13,14] focus on processing the entered terms through a similarity measure with an ontological repository to obtain semantically similar concepts included in the query reformulation. To reduce ambiguities and personalize the results, it has been proposed to include information related to the user's preference profile in the expansion process [2,12,13,17].
The use of information annotation in QE is evidenced in [2], which suggests combining information from clinical diagnoses with word embedding to retrieve relevant biomedical information. Besides, three types of words are included (domain-specific, domain-related, and hybrid) to perform the annotations in the original query. Also, MetaMap is used to recognize and extract biomedical concepts that are candidates to be included in the query expansion. In the selection of candidate terms, the cosine similarity is used, and the original query is weighed with the expanded terms.
The method proposed by Nandanwar, Choudhary, and Singh [25] combines the entered query with the user profile and WordNet to customize the expansion. The queries are initially classified into ambiguous or unambiguous. WordNet and the most similar category in the user's profile are used for ambiguous queries. For unambiguous queries, all the terms of the query are identified in WordNet, and the most representative term in the user's profile is added to the original query.
Suma [5] proposes to expand the query with user profile information and a domain ontology by weighing semantic relations to select candidate terms for expansion. Also, Jain et al. [14] proposed a method for the construction of an ontology to identify semantic relationships in query expansion. In addition, Dahir et al. [13] employed a query expansion method based on bag-of-words distribution to select the 20 terms with the highest similarity and determine the efficient expansion terms from single or multi-valued DBpedia attributes.
Analyzing the consulted solutions allows identifying the variety of similarity measures to recognize the candidate concepts to be included in the expansion. In addition, the main shortcomings are related to the use of data sources and the amount of information to be added. Our research proposes to expand the terms using an ontological repository and to reduce ambiguity through the user's preference profile. As a novelty, concepts from the user's profile with greater similarity to the query are included.
Relevance is defined in [27,28] as the level of usefulness, quality, and value of the retrieved information to satisfy the user's needs. Relevance can be represented by a scalar and measures the degree of agreement of different criteria (match, meaning, and frequency of occurrence of the terms) between the entered query and the document collection.
Wan et al. [29] presented a method that combines similarity by matching and semantics to obtain an initial score of the documents using the BM25 algorithm. Then, they improved the definition of relevance with the linear combination of the semantic analysis by BERT and reformulated the query using the terms extracted from the N top-ranked documents to improve the search results.
A hybrid model for document ranking that combines query probability and semantic similarity between concepts using WordNet was proposed by Neji et al. [30]. This model calculates the similarity between concepts by Jiang-Conrath similarity and user preferences to extract concepts and reformulate the query. It determines the similarity between documents and the query to sort the search results.
The analysis of previous works allowed us to identify a coincidence in the use of query expansion [12 - 15], user profile processing [2,16,17], and documents [9,10,13] to retrieve relevant and customized information.
This article is organized as follows: Section 1 presents a selection of works related to the user's profile, the query expansion, and customized information retrieval; Section 2 presents the proposed model and describes the implemented algorithms; Section 3 shows the discussion based on the results obtained in this research; and Section 4 presents the conclusions.
II. MATERIALS AND METHODS
This section describes the proposed model that enables collecting, indexing, and processing the information available on the Web to obtain relevant and personalized search results. The main objective of the model is to improve the quality of the search results provided to the users when they access an IRS by integrating the preference profile, query expansion, and stored documents into a relevance algorithm (Figure 1).
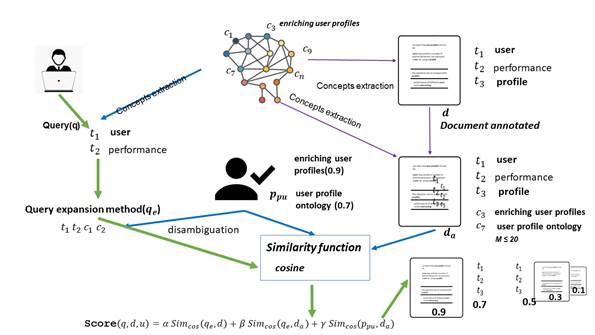
When the users register in the IRS, they create their profile, and the system analyzes their behavior and uses this information to personalize the search results. The use of an ontological repository to make semantic annotations and expand the query makes it possible to improve information processing and retrieve the most relevant documents for the user.
The model obtains the query entered by the user as inputs and, through the indexing process, the documents extracted from the Web (Figure 1). The documents are categorized and semantically annotated to enrich and reduce their semantic ambiguity by means of an ontological repository. Besides, the expansion process is applied to the entered query, and the relevance algorithm is used to retrieve the documents that best fit the user's needs. The outputs are the search results relevant to the user and the user's updated preference profile.
A. Query Expansion with Ontology and User Preference
Query expansion reformulates the original query by incorporating relevant terms from different sources, weighting them in the expansion process to understand their semantic meaning and improve the information retrieval accuracy [2]. Query processing mainly aims at disambiguating the terms entered by the user to improve the relevance of the search results.
The developed expansion algorithm (Algorithm 1) combines the original query terms, a domain ontology, and the user's preference profile. The entered terms are processed to obtain the candidates to be included in the expansion. The similarity measure between concepts, proposed by Rafa et al. [2] (Expression 1), is applied to obtain the most relevant concept to be included in the expanded query.

The query disambiguation process is performed according to the user's preferences profile to obtain concepts associated with the entered terms. As a first step of the algorithm (1), the user's search history (PCA) PCAu={pu1,pu2,pu3...pun} is obtained from the user's profile to access the relevance of the concepts stored in his preferences profile. Then, the original query terms are retrieved, and the similarity between the candidate and associated concepts is calculated to determine the relevance of the information retrieved from the user's profile. As a second step, the candidate concepts for the expansion are obtained, and the Cosine similarity is applied to select the most relevant concepts to reformulate the query. The result is an expanded query disambiguated by user profile and ontology.
B. Relevant and Customized Information Retrieval
Algorithm #2 is developed and applied to determine the similarity between the query and the stored documents, which combines query expansion and document annotation with a result weighing according to the user search preferences. For each document, there is a representation of the original document vector (term/weight) and annotated document vector (concepts/index).
Algorithm #2 uses the documents (d), the user's preference profile (ppu), and the expanded query (eq) to determine the relevance of the search results. The relevance of a document according to the query entered by the user is calculated using Expression (1), and the relevance calculation algorithm is designed and implemented:
Score
Where Score (q,d,u) is defined as the relevance for the user (u) of document (d) according to the similarity between the query (q), the document (d), and the preference profile (ppu). It is assumed that the results obtained when executing the same query by several users do not necessarily satisfy them to the same extent. In the developed algorithm, a linear combination is defined to weigh values α, β, γ, where the value of Score (q,d,u) <=1 provided that α + β+ γ=1. Also, the Cosine measure (2) was used, and it obtains values in the interval [0,1] to determine the similarity. Besides, the Cosine similarity (
In addition, it is stated that:
Cosine similarity (q,d): function to calculate the similarity between the query (qe) and the document (d).
Cosine similarity (qe,da): function to calculate the similarity between the query (qe) and the annotated document (da).
Cosine similarity (ppu,da): function to calculate the similarity between the concepts annotated in the documents (da) and the user's search concept preference profile (ppu).

III. RESULTS
To evaluate the proposed model, an experiment was designed to measure the relevance of retrieved documents by integrating user preferences, query expansion, and relevance calculation. The experiment to test the search results quality is described below.
From the collection of stored documents, 5000 documents were selected, categorized, and semantically annotated using domain ontologies and WordNet. Each document contains the original and the concepts annotated by semantic similarity with the ontology repository. Thirty user profiles were designed. The preferences of each profile were determined by recording 10 queries with 20 relevant documents and an average of 70 annotated concepts in its history. In addition, implicit data related to their preferences, search categories, location, and other data recorded by the IRS are captured. Each user was assigned 50 queries with different levels of semantic ambiguity (high, medium, and low) and executed in the 4 scenarios designed to perform the search. Each user was informed of the characteristics of the assigned profile and was asked to simulate the defined preferences to evaluate the search results.
For the selection of documents, queries, user profiles, and scenarios, the studies conducted by Hahm et al. [32], Xu et al. [33], and Malik et al. [15] -who designed similar proposals and used metrics such as Precision (P), Recall, and Mean Average Precision (MAP) for validation- were considered. Due to the importance of having a correct data source to select and collect documents, queries, and user profiles, the following criteria were considered:
Quality: documents should be high-quality and semantically annotated to ensure the relevance evaluation of the developed system. Queries should be expanded using an ontology to improve their relevance and performance. User profiles should contain detailed information about preferences and relevant concepts.
Relevance: documents should be relevant to the application domain and contain a wide variety of topics. Queries should be varied and represent different levels of complexity. User profiles should be as similar as possible to the user's preferences and needs in the application domain.
Diversity: documents, queries, and user profiles should be varied to ensure that the system performs well in different scenarios and situations.
Representativeness: the selected documents, queries, and user profiles should accurately represent the application domain and user interests.
In relation to the execution of the data, a case study composed of 4 scenarios was designed to compare the functioning of the IRS. These scenarios cover the operation of the IRS without modifications, with query expansion, with user preferences, and integrating the preferences’ relevance and query expansion.
Base proposal (without modification (PS)): measures system performance without modification and is set as execution condition for α = 1, β = 0, and γ = 0 for Expression 1.
Proposal # 2 with query expansion (Pqe): measures the performance of the system with query expansion and is set as execution condition for α = 0, β = 1 and γ = 0 for Expression 1.
Proposal #3 with query expansion and customization by user search history preferences (Pqeu): measures the performance of the system with query expansion and weighing by search history. It is set as an execution condition for α = 0, β = 0.5, and γ = 0.5 for Expression 1.
Proposal #4 with terms, query expansion, and search preferences (Pdqeu): measures system performance with keyword search, query expansion, and search history weighing. It is set as an execution condition for α = 0.3, β = 0.5, and γ = 0.2 for Expression 1.
The selection of weighing values for α, β, and γ is based on the importance of semantic annotation for information retrieval. The more relevant the semantic annotation, the more similar the query, the user profile, and the indexed documents. Query expansion increases the coverage of possible relevant terms and generates higher weighing values compared to terms and the user profile.
The expanded query has a higher probability of including relevant terms that may be present in relevant documents but were not included in the original query. Terms and user profile have more limited coverage and are less likely to be present in all relevant documents because they are more specific and limited to the keywords provided by the user in the original query and their preference profile.
Next, the queries assigned to each user profile are executed, and the results are recorded to apply the Precision (P), Recall (R), and Mean Average Precision (MAP) metrics to measure the quality of the results.
Precision: retrieved documents relevant to the user's information need, set as cut-off measure P@10 and determined by Expression 4.
Completeness: the documents relevant to a query were retrieved and determined by Expression 5.
Mean Precision is the average of the mean precision scores for each query and is determined by Expression 6.
Table 1 P, R, MAP metrics results.
| Approach | P@10 | R@10 | MAP@10 |
|---|---|---|---|
| PS | 0.29 | 0.19 | 0.17 |
| Pqe | 0.55 | 0.43 | 0.36 |
| Pqeu | 0.63 | 0.54 | 0.45 |
| Pdqeu | 0.86 | 0.83 | 0.71 |
Expression 4 was used to calculate the precision of the results, and P@10 was selected as the cut-off ranking. The use of a ranking to evaluate the first results is common in research [2,13,31].
The analysis of the results obtained after executing the case study confirmed that combining user preferences and ontologies with semantic annotation, query expansion, and relevance calculation improves the IR. The precision values obtained for P@10 (0.86) were acceptable and allowed to corroborate that query expansion improves search results by 2.3 times the system without modification and increases up to 3 times when combined with document annotation and user preferences profile. Better results are obtained when the documents are annotated, and the user profile allows them to retrieve enough information to define their preferences.
To compare the results obtained with research analyzed in the related works section, versions of the proposals of [2,13,31] were implemented according to the descriptions because they address query expansion and user profiles. A new experiment was designed with 10 users, 15 queries, and 1000 documents to compare the implemented proposals.
It is assumed that the most relevant documents have the highest degree of similarity with the expanded query when applying the cosine measure and that the concepts annotated in the document and the query have the highest similarity with the preferences defined in the user’s profile. For Experiment 2, α = 0.3, β = 0.5, and γ = 0.2 are defined as the execution condition for weighing the values in Expression 4.
Precision (P), Recall, and Mean Average Precision (MAP) metrics are used to evaluate the results, and they are shown in Table 2.
Table 2. P, R, MAP metrics results. Experiment 2.
| Approach | P@10 | R@10 | MAP@10 |
|---|---|---|---|
| Hahm et al. [32] | 0.64 | 0.61 | 0.60 |
| Xu et al. [33] | 0.73 | 0.67 | 0.46 |
| Malik et al. [15] | 0.89 | 0.65 | 0.62 |
| Proposed model | 0.87 | 0.83 | 0.70 |
The values of P@10 and R@10 were higher than those of research [13,31], similar to [2] and evidence, and had greater relevance when using information annotation, user profiles, and queries. Also, the results obtained from MAP (0.70) evidence similarity with proposals [2,13,31], which include search customization with user preference profiles and query expansion. Better results are evidenced when the user profile is well defined, thus helping to decrease the ambiguity of the terms entered in the query.
The evaluation using the Precision (P), Recall (R), and Mean Average Precision (MAP) metrics demonstrates the quality, relevance, and pertinence of information retrieval with semantic annotation. It also reveals that the integration of user preferences and semantic annotation improves query expansion and adjusts the search results to their needs by selecting the most relevant ones to increase their experience in using IRS.
IV. DISCUSSION AND CONCLUSIONS
The analysis of the information retrieval process allowed identifying the main deficiencies that affect information processing, e.g., information overload, heterogeneity of information sources, and interoperability, which greatly hinder the adequate processing of the available information. The developed query expansion algorithm combines user preferences and the concepts associated with the entered terms to help reduce ambiguity and retrieve relevant and customized documents. Also, the semantic annotation of information in the documents, the user profile, and the query expansion increase the relevance of the retrieved documents.
The application of the relevance algorithm improves the process of retrieving customized and relevant information. Applying and analyzing Precision, Recall, and Mean Average Precision (MAP) metrics to the developed proposal allows us to verify that it improves the quality of the results.

