











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
Permalink
I. INTRODUCTION
The healthcare sector generates large amounts of data on a daily basis; however, the lack of data quality has become a problem for their analysis since low-quality information can lead to erroneous conclusions and decisions; instead, the use of accurate and reliable data will allow to make informed decisions and generate value in this sector [1].
In this context, Health Service Providing Institutions (IPS by its Spanish acronym) own large amounts of data, part of which is reported to Health Service Promoting Entities (EPS by its Spanish acronym) to follow-up the services provided. However, within these reports, in particular on the delivery of prescriptions and the assignment of medical appointments, there are frequent problems such as (i) attributes that lack a coherent structure and are inconsistent in format; (ii) incomplete, non-existent, or registered unique medication code with the Anatomical Therapeutic Classification (ATC) codes, which does not allow identifying the commercial presentation of the medication delivered to the affiliate; (iii) non-existent or incomplete diagnosis codes according to the International Classification of Diseases (CIE10 by its Spanish acronym); (iv) information on members who do not exist in the database or who are affiliated with other EPS; (v) quantities prescribed, delivered, days of treatment, dates of submission and delivery with errors and inconsistencies, e.g., delivered quantities greater than those formulated, delivery dates prior to the prescription [2].
Systematic mapping allowed us to find studies related to data quality. In [3] they propose a process that standardizes the data structure to detect and correct errors in the defined variables. In [4] they compare discrepancies between source and target data using three categories: completeness, consistency, and syntactic validity. Furthermore, in [5] they propose data cleaning to evaluate data, metadata, outliers, and duplicates; then, they detect anomalies and follow up inconsistencies to standardize the data. Kahn [6] proposes three categories of quality: conformance, which evaluates whether values comply with syntactic or structural constraints; completeness, which verifies the presence or absence of data at one or more points in time; and plausibility, which describes the credibility or veracity of values. These studies [4] [5] have addressed data quality in the health sector, focusing on their structure and domain and on the standardization and detection of anomalies to correct errors in the variables. However, they do not consider the completeness and plausibility categories proposed by Kahn, which are essential to validate the data. Furthermore, these Kahn categories have been used and accepted in the health sector in other countries [7] [8] [9].
Considering the importance of addressing Kahn's data quality categories, this research proposes to adapt these categories to the specific characteristics of prescription delivery and medical appointment assignment reports, seeking a higher quality of data that will allow EPS to perform analyses.
This research used the Iterative Research Pattern methodology, which Observation stage includes a systematic mapping based on [10] [11] and the structure and guidelines established by the Ministry of Health and Social Protection (MSPS by its Spanish acronym); for these, two reports were reviewed. In the Problem Identification stage, the problems concerning data quality were related to each attribute of the reports. In the Solution Development stage, the general and specific adaptation of Kahn's data quality subcategories to these reports was carried out. Finally, in the Solution Testing stage, the proposed adaptation to each subcategory was validated by a focus group with experts in the health sector.
This article presents the methodology used to adapt the two reports, describes this adaptation in detail and its evaluation by a focus group; finally, it presents the conclusions.
II. METHODOLOGY
The research employed the Iterative Research Pattern (PII) methodology proposed by Pratt [12], which comprises four stages: observation, problem identification, solution development, and solution testing.
A. Observation
1) Systematic Review. This review was conducted based on [10] [11] to define the research questions, search terms, databases, and inclusion/exclusion criteria. The most relevant articles found in this review are presented below.
In 2016, an optimization model for ETL was proposed [3] it contemplates: (i) the Prerequisite phase, which standardizes the data structure; (ii) the Main phase, which detects outliers and inconsistencies and records them in a table of variables; (iii) the Alternative phase, which stores the error history, manages the variables, and evaluates the process using two indicators (confidence and support). In 2018, an approach was proposed to validate ETL processes through balancing tests composed of five phases [4]: (i) Defining generic properties through completeness, consistency, and syntactic validity and checking for mismatches between data; (ii) Identifying source-to-target mappings through aggregation operations to join records; (iii) Testing mappings to verify matches between source and target record counts; (iv) Approach evaluation to detect record failures; and (v) Automated mutation testing to evaluate failures in the target table.
Later in 2019, a quality assurance (QA) process was proposed [7]; it focuses on Kahn's Conformance and Completeness categories, which are applied in all ETL stages starting with the Completeness category. Here, a count of source and transformed rows is made, followed by the Relational Conformance category, which checks that foreign key values match foreign sources. Finally, the Value Conformance category quantifies the amount of mapped and unmapped data. The same year, they proposed a data quality assessment through data cleansing [9], based on Kahn's data quality categories, applied in a data retention cycle: (i) evaluates the Conformance category of the data model at the table level and leaves the Plausibility and Completeness categories for later cycles; (ii) updates the data dictionary and data characterization; (iii) reports empirical data characterization; and (iv) discusses the results of the previous cycles and creates a plan for error mitigation.
In the same year, 2019, an automated framework for data cleansing was proposed [5] using a three-module architecture: (i) Data evaluation assesses raw data, extracting metadata and calculating descriptive statistics; (ii) Data quality control detects missing values, anomalies, and duplicates; and (iii) Data standardization ensures data matching with reference models through lexical and semantic comparisons.
Finally, in 2020, a data monitoring architecture is proposed to measure the quality of data in the ETL process [8] using Kahn's categories and employing diagnostic filters to generate error events, which are stored in the fact table linked to an audit dimension for their respective analysis.
The results obtained from the systematic mapping indicate that the health sector accepts Kahn's data quality categories [7] [8] [9]. This study involved the participation of approximately 100 professionals from different disciplines from the US and international networks and projects, who contributed to the development and revision of harmonized data quality terminology. Furthermore, this study involved more than 540 million patient records thatsupport the robustness and relevance of these categories in the medical field. Also, in this systematic review, it can be identified that studies [3] [4] [5] have addressed data quality in the health sector, focusing on the structure and domain of the data, and on the standardization and detection of anomalies to correct errors in the variables. However, they do not consider the Completeness and Plausibility categories proposed by Kahn. These are important to validate the veracity of the data. In addition, it is noted that these studies were developed in the United States [7] [9], Germany [8], Italy [4], and Colombia [3]. The latter is applied in a case study of environmental data.
2) Reports on Prescription Delivery and Medical Appointments. We reviewed the consolidated reports generated by the IPS based on the structure established by the Ministry of Health and Social Protection (MSPS) through Resolution 1604 of 2013 [13] that defines the requirements for prescription delivery. Resolution 1552 of 2013 was also considered [14]; it sets the guidelines for medical appointment assignment reports. These resolutions establish the standards and procedures to be followed by IPS when generating reports intended for EPS to follow up and control prescription delivery and the assignment of medical appointments.
1. Identification of the problem
Table 1 details the problems identified for each attribute of the two reports. The nomenclature used in the columns indicates: (V) Empty, a record with no data is found; (NN) Non-standardized, the data is not presented in a standard format; (E) Erroneous, the attribute value is incorrect or inaccurate; (IN1) Incomplete, it refers to cases where information is missing or the data is incomplete; (IN2) Inconsistent, the attribute value does not match other data or is not consistent with general information; and (IN3) Inexistent, the data is not found.
Table 1 Problems identified for each attribute.
| Attribute | V | NN | E | IN1 | IN2 | IN3 |
|---|---|---|---|---|---|---|
| Pending quantity | X | X | X | |||
| Prescribed quantity | X | X | X | |||
| Delivered quantity | X | X | X | |||
| Medication CUM code | X | X | X | X | X | |
| Habilitation code | X | X | X | X | X | |
| Concentration | X | X | X | X | X | X |
| Affiliate department | X | X | X | X | X | |
| IPS department | X | X | X | X | X | |
| Main diagnosis | X | X | X | X | X | |
| Related diagnosis | X | X | X | X | X | |
| Days of treatment | X | X | X | |||
| Date of authorization | X | X | X | X | X | |
| Delivery record date | X | X | X | X | X | |
| Prescription date | X | X | X | X | X | |
| Filing date of the medical prescription by the user | X | X | X | X | X | |
| Date on which the user requests the appointment | X | X | X | X | X | |
| Date on which the user requests the appointment to be assigned | X | X | X | X | X | |
| Date of the appointment | X | X | X | X | X | |
| Pharmaceutical form | X | X | X | X | X | |
| Affiliate’s municipality | X | X | X | X | X | |
| IPS’ municipality | X | X | X | X | X | |
| Provider’s NIT (without DV) | X | X | X | X | X | |
| Name of the medication | X | X | X | X | ||
| Names and last names of affiliate | X | X | X | X | ||
| Identification number | X | X | X | X | X | |
| Total number of appointments assigned | X | X | X | |||
| Supplier's company name | X | X | X | X | ||
| Affiliated regime | X | X | X | X | X | |
| Service requested | X | X | X | X | X | X |
| Document type | X | X | X | X | X | |
| Form of administration | X | X | X | X | X | |
| Genre | X | X | X | X | X | |
| Affiliate's phone number | X | |||||
| Delivery record date | X | X | X | X | X | |
| Type of medication delivery, at home or at point of delivery? | X | X | ||||
| Satisfactory delivery number | X | X | X | X | X |
B. Solution Development
First, a general adaptation of Khan's data quality categories and subcategories was performed and evaluated by implementing two strategies: (i) Verification to check whether the data values conform to established expectations and local knowledge; and (ii) Validation to check that data values are aligned with respect to external sources.
For this purpose, we started by defining each subcategory, identifying the most relevant characteristics; then, we determined the Verification Criteria that describe the adaptation made for each subcategory and the Validation Criteria that present the adaptation considering external sources, as shown in Table 2.
Table 2 General adaptation of data quality categories and subcategories.
| Category | Subcategory | Attribute | Verification Criteria | Validation Criteria |
|---|---|---|---|---|
| Conformance | Value Conformance | Internal formatting restrictions | Data type, data format, length | NA |
| Allowable values or ranges | Data domain | NA | ||
| Relational Conformance | Complies with referential integrity restrictions | Foreign key | External databases | |
| Complies with the uniqueness constraint | Primary key | NA | ||
| Complies with the nullity restrictions | Invalidity | NA | ||
| Computational Conformance | The calculated values conform to computational or programming specifications | NA | NA | |
| Completeness | Completeness | The absence of values at a single point in time is in accordance with local or common expectations | Attributes comply with the absence of the value | NA |
| Plausibility | Uniqueness Plausibility | Data values identifying a single object are not duplicated | Attributes that meet the condition | NA |
| Atemporal Plausibility | It seeks to determine whether the values, distributions or densities of the observed data agree with local or "common" knowledge | Values and distributions | External databases | |
| Logical constraints between values | External databases | |||
| Repeated measurement values | External databases | |||
| Temporal plausibility | Observed or derived values conform to expected time properties | Observed or Derived Values | NA | |
| Sequences of values | NA | |||
| Value density measures | NA |
Once the verification and validation criteria had been identified, we proceeded to adapt each attribute of the prescription delivery and medical appointment assignment reports.
C. Solution Testing
The proposed adaptation was evaluated by a focus group composed of experts from the health sector with more than 20 years of experience (see Table 3). Before the focus group session, an invitation was sent via e-mail to the experts, attaching reading material with a description of the adaptation carried out. During the session, a presentation was made to explain the adaptation made to each subcategory of data quality in the two reports in detail. Then, the experts provided feedback and discussed the topic. At the end of the session, the experts were asked to complete a questionnaire (see Table 4) to evaluate the adaptation made for each of the reports.
Table 3 Health experts.
| Expert ID | Occupation | Studies |
|---|---|---|
| E1 | Vice president of health services, professor of postgraduate courses. | Surgeon, Specialist in Health Services Management, Specialist in Quality Management and Health Auditing. |
| E2 | Expert advisor in health product development, Vice president of health. | Surgeon, Specialist in Health Services Management, Specialist in Quality Management and Health Auditing. |
| E3 | Professional in National Health Services, General Practitioner | Physician and surgeon, Specialist in Hospital Administration, Specialist in Auditing and Quality Assurance with an emphasis in Epidemiology from EAN, Nation-wide Lecturer in the field of Health Administration, Advisor to Hospitals and E.S.E.S. in Cauca and Valle del Cauca. |
Table 4 Questions in the expert evaluation questionnaire
Nomenclature: (5) Strongly Agree, (4), Agree, (3) Neither Agree Nor Disagree, (2), Disagree, (1) Strongly Disagree
III. RESULTS
A. Adaptation of Data Quality Categories of the Medication Delivery Report
The adaptation of the Value Conformance and Relational Conformance subcategories to each attribute, along with the verification and validation assessment strategies, are shown in Table 5; the Completeness category in Table 6; the Uniqueness Plausibility subcategory in Table 7; the Atemporal Plausibility subcategory in Table 8; and the Temporal Plausibility subcategory in Table 9 .
Table 5 Adaptation of Value Conformance and Relational Conformance - Prescription Delivery.
| ID | Attribute | Value Conformance | Relational Conformance | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Verification | Validation | Verification | Validation | |||||||
| DT | LE | FO | DO | ON | PK | FK | ||||
| 1 | Document type | ST | 2 | NA | NA | NA | NN | NA | DBA | BDUA |
| 2 | Identification number | N | 16 | NA | NA | NA | NN | NA | DBA | BDUA |
| 3 | Names and last names | T | 80 | NA | NA | NA | NN | NA | NA | NA |
| 4 | Genre | ST | 9 | NA | F,M | NA | NN | NA | DBA | BDUA |
| 5 | Affiliated Regime | ST | 12 | NA | NA | NA | NN | NA | DBA | BDUA |
| 6 | Affiliate’s Department | N | 2 | NA | NA | NA | NN | NA | DBA | BDUA |
| 7 | Affiliate’s Municipality | N | 5 | NA | NA | NA | NN | NA | DBA | BDUA |
| 8 | Affiliate's phone number | N | 20 | NA | NA | NA | NU | NA | NA | NA |
| 9 | Medication CUM code | N | 11 | NA | NA | NA | NN | NA | NA | INV |
| 10 | Name of the medication | T | 200 | NA | NA | NA | NN | NA | NA | NA |
| 11 | Concentration | T | 30 | NA | E.g1 | NA | NN | NA | NA | NA |
| 12 | Pharmaceutical form | T | 180 | NA | E.g2 | NA | NN | NA | NA | NA |
| 13 | Form of administration | ST | 40 | NA | E.g3 | NA | NN | NA | NA | NA |
| 14 | Days of treatment | N | 5 | NA | NA | NA | NN | NA | NA | NA |
| 15 | Prescribed quantity | N | 5 | NA | NA | NA | NN | NA | NA | NA |
| 16 | Delivered quantity | N | 5 | NA | NA | NA | NU | NA | NA | NA |
| 17 | Pending quantity | N | 5 | NA | NA | NA | NN | NA | NA | NA |
| 18 | Main diagnosis | ST | 4 | NA | NA | NA | NN | NA | CIE | CIE |
| 19 | Related diagnosis | ST | 4 | NA | NA | NA | NU | NA | CIE | CIE |
| 20 | Prescription date | D | 10 | FD | NA | NA | NN | NA | NA | NA |
| 21 | Authorization date | D | 10 | FD | NA | NA | NN | NA | NA | NA |
| 22 | Filing date of the medical prescription by the user | D | 10 | FD | NA | NA | NN | NA | NA | NA |
| 23 | Delivery record date | D | 10 | FD | NA | NA | NU | NA | NA | NA |
| 24 | Provider’s NIT (without dv) | N | 16 | NA | NA | NA | NN | NA | DBI | REPS |
| 25 | Supplier's company name | T | 100 | NA | NA | NA | NN | NA | NA | NA |
| 26 | Type of prescription delivery, at home or at point of delivery? | I | 1 | NA | E.g4 | NA | NU | NA | NA | NA |
| 27 | Satisfactory delivery number | T | 50 | NA | NA | NA | NU | NA | NA | NA |
Nomenclature: (DT) Data Type, (LE) Length, (FO) Format, (DO) Domain, (ON) Obligatory nullability, (PK) Primary Key, (FK)Foreign Key, (ST) Short Text, (N) Numeric, (T) Text, (I) Integer, (D) Date, (NA) Not Applicable, (FD) DD-MM-YYYYY, (NU) Null, (NN) Not Null, (DBA) DB Affiliate EPS, (DBI) DB IPS Contracted EPS, (BDUA, by its Spanish acronym) DB Unique of Affiliates, (INV) DB National Institute for the Safety of Medicines and Food INVIMA, (CIE) DB Diseases CIE10, (REPS, by its Spanish acronym) DB Special Register of Health Service Providers, (E.g1) 200 mg, 300 mg,600mg/100000 i.u., (E.g. 2) Solution for injection, Tablet, (E.g. 3) Oral, Intramuscular, Infiltrative - local, (E.g. 4)1: Domiciliary, 2: Point of delivery, (M) Male, (F) Female.
Table 6 Adaptation of the Completeness category - Prescription delivery.
| Attribute | Adaptation of Verification | Adaptation of Validation |
|---|---|---|
| Delivered quantity | If Delivered quantity is null or equal to 0, the Delivery Record Date must be null. | NA |
| Delivery record date | If Delivery Record Date is null, the Delivered quantity must be null or zero. | NA |
| Related diagnosis | If Related diagnosis is null, Main diagnosis must not be null. | NA |
Table 7 Adaptation of the Uniqueness Plausibility subcategory - Prescription delivery.
| Attributes | Adaptation of Verification | Adaptation of Validation |
|---|---|---|
| Document type | There should be no duplicate records: Document type + Identification number + Medication cum code + Prescription date | NA |
| Identification number | ||
| Medication CUM code | ||
| Prescription date |
Table 8 Adaptation of the Atemporal Plausibility subcategory - Prescription delivery.
| Attributes | Adaptation of Verification | Adaptation of Validation |
|---|---|---|
| Document type | Document type + Identification number matches the Affiliates DB. | BDUA |
| Affiliated Regime | Affiliated Regime + Document type + Identification number matches the Affiliates DB. | BDUA |
| Affiliated Department and Municipality | Department of the affiliate + Municipality of the affiliate + Document type + Identification number matches the Affiliates database. | BDUA |
| Days of treatment | There should be no treatment days at 0, single dose medications are managed in one day. | NA |
| Delivered quantity | Delivered quantity + Pending quantity <= Prescribed quantity. | NA |
Table 9 Adaptation of the Temporal Plausibility subcategory - Prescription delivery.
| Attributes | Adaptation of Verification | Adaptation of Validation |
|---|---|---|
| Delivery record date | Delivery record date >= Prescription date. | NA |
| Date of authorization | Date of authorization >= Prescription date. | NA |
| Delivered quantity (t) |
For two records at time t and t-1, which have the same: Document type + Identification number + Medication CUM code + Prescription date. It reviews: Pending quantity (t-1) - Delivered quantity (t) = Pending quantity (t) |
NA |
| (Prescription Date + Days of treatment) (t-1) |
For two records at time t and t-1, which have the same: Document type + ID number + Medication cum code + Days of treatment. It reviews: Prescription Date (t) > (Prescription Date + Days of treatment) (t-1) |
NA |
B. Validation of the Adaptation of the Prescription Delivery Report
The results obtained from the expert focus group with respect to the adaptation of each subcategory are presented in Fig. 1 , according to the Likert scale. The subcategory showing the highest adaptation is Atemporal Plausibility, with 100% in the "Completely Agree" category; followed by Value Conformance, Relational Conformance, Completeness, and Temporal Plausibility with 66.7% in "Strongly Agree" and 33.3% in "Agree". In addition, the Uniqueness Plausibility subcategory scored 66.7% in "Agree", and 33.3% in "Strongly Agree".
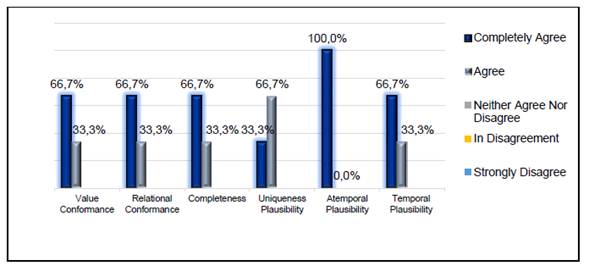
Table 10 presents one of the experts' comments on the open-ended questions (see Table 4) with its respective improvement actions.
C. Adaptation of Data Quality Categories of the Report on Assignment of Medical Appointments
The adaptation of the Value Conformance and Relational Conformance subcategories to each attribute, along with the verification and validation assessment strategies, are shown in Table 11; the Completeness category in Table 12; the Uniqueness Plausibility subcategory in Table 13; the Atemporal Plausibility subcategory in Table 14; and Temporal Plausibility in Table 15 .
Table 11 Adaptation of Value Conformance and Relational Conformance - Assignment of medical appointments.
| ID | Attribute | Value Conformance | Relational Conformance | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Verification | Validation | Verification | Validation | |||||||
| DT | LE | FO | DO | ON | PK | FK | ||||
| 1 | Document type | ST | 2 | NA | NA | NA | NN | NA | BDA | BDUA |
| 2 | Identification Number | N | 16 | NA | NA | NA | NN | NA | BDA | BDUA |
| 3 | Names and last names | T | 80 | NA | NA | NA | NN | NA | NA | NA |
| 4 | Affiliated Regime | ST | 12 | NA | NA | NA | NN | NA | BDA | BDUA |
| 5 | Affiliate Department | N | 2 | NA | NA | NA | NN | NA | BDA | BDUA |
| 6 | Municipality of affiliate | N | 5 | NA | NA | NA | NN | NA | BDA | BDUA |
| 7 | Phone | N | 30 | NA | NA | NA | NN | NA | NA | NA |
| 8 | Date on which the user requests the appointment or surgery | D | 10 | FD | NA | NA | NN | NA | NA | NA |
| 9 | Date on which the user requests the appointment or surgery to be assigned to him/her | D | 10 | FD | NA | NA | NN | NA | NA | NA |
| 10 | Date for which appointment or surgery is assigned | D | 10 | FD | NA | NA | NN | NA | NA | NA |
| 11 | IPS Department | N | 2 | NA | NA | NA | NN | NA | DBI | REPS |
| 12 | IPS Municipality | N | 5 | NA | NA | NA | NN | NA | DBI | REPS |
| 13 | Provider’s NIT (without dv) | N | 12 | NA | NA | NA | NN | NA | DBI | REPS |
| 14 | Qualification Code | N | 12 | NA | NA | NA | NN | NA | DBI | REPS |
| 15 | Supplier's company name | T | 100 | NA | NA | NA | NN | NA | NA | NA |
| 16 | Service requested | N | 4 | NA | NA | NA | NU | NA | DBI | REPS |
| 17 | Other specialty or Surgery | T | 100 | NA | NA | NA | NU | NA | NA | NA |
| 18 | Total number of appointments assigned | N | 2 | NA | NA | NA | NN | NA | NA | NA |
Nomenclature: (DT) Data Type, (LE) Length, (FO) Format, (DO) Domain, (ON) Obligatory nullability, (PK) Primary Key, (FK)Foreign Key, (ST) Short Text, (N) Numeric, (T) Text, (I) Integer, (D) Date, (NA) Not Applicable, (FD) DD-MM-YYYYY, (NU) Null, (NN) Not Null, (DBA) DB Affiliate EPS, (DBI) DB IPS Contracted EPS, (BDUA) DB Unique of Affiliates, (INV) DB National Institute for the Safety of Medicines and Food INVIMA, (CIE) DB Diseases CIE10, (REPS) DB Special Register of Health Service Providers
Table 12 Adaptation of the Completeness category - Assignment of medical appointments.
| Attribute | Adaptation of Verification | Adaptation of Validation |
|---|---|---|
| Service requested | If the Service requested is null, Other Specialty or Surgery should not be null. | NA |
| Other specialty or Surgery | If the Other Specialty or Surgery is null, the Service requested should not be null. | NA |
Table 13 Adaptation of the Uniqueness Plausibility subcategory - Assignment of medical appointments.
| Attributes | Adaptation of Verification | Adaptation of Validation |
|---|---|---|
| Document type | There should not be more than 2 duplicate records: Document type + Identification number + Date for which the appointment or surgery is assigned + Nit provider + Service Requested >=2 | NA |
| Identification number | ||
| Date for which the appointment or surgery is assigned | ||
| Provider’s NIT | ||
| Service Requested |
Table 14 Adaptation of the Atemporal Plausibility subcategory - Assignment of medical appointments.
| Attributes | Adaptation of Verification | Adaptation of Validation |
|---|---|---|
| Document type | Document type + Identification number matches the Affiliates DB. | BDUA |
| Affiliated Regime | Affiliated Regime + Document type + Identification number matches the Affiliates DB. | BDUA |
| Affiliate’s Department and Municipality | Department of the affiliate + Municipality of the affiliate + Document type + Identification number matches the Affiliates database. | BDUA |
Table 15 Adaptation of the Temporal Plausibility subcategory - Assignment of medical appointments.
| Attributes | Adaptation Verification | Adaptation Validation |
|---|---|---|
| Date for which appointment or surgery is assigned | Date for which appointment or surgery is assigned >= Date on which the user requests the appointment or surgery. | NA |
| Date on which the user requests the appointment or surgery to be assigned to him/her | Date on which the user requests the appointment >= Date on which the user requests the appointment or surgery. | NA |
D. Validation of the Adaptation of the Report on Assignment of Medical Appointments
The results obtained from the expert focus group regarding the adaptation of each subcategory are presented in according to the Likert scale. The Atemporal Plausibility subcategory shows the highest adaptation, 100% in "Completely Agree"; Relational Conformance, Completeness and Temporal Plausibility, 66.7% in "Strongly Agree", and 33.3% in "Agree". In addition, the Plausibility of Uniqueness obtained 66.7% in "Agree" and 33.3% in "Completely Agree ".
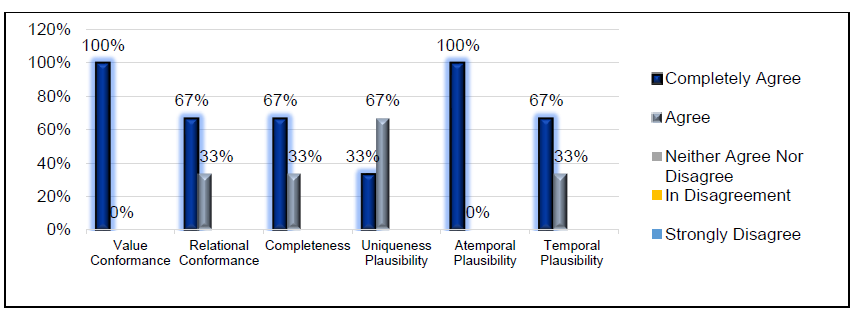
Table 16 presents one of the experts' comments on the open-ended questions (see Table 4) with their respective improvement actions.
IV. CONCLUSIONS
The adaptation of Kahn's data quality categories for the reports of the prescription delivery and assignment of medical appointments is proposed in this article improves data quality because the criteria defined in the Conformance category ensure that the types of data are correct; that the formats, lengths, and domains conform to internal restrictions; and that the relationships between specific attributes of the reports and external sources (BDUA, Invima, CIE10 and REPS) are correctly established. Regarding Completeness, it is guaranteed that the absence of data in an attribute is under MSPS regulations; and regarding Plausibility, it is ensured that the records are credible and that the quantities in the reports are logical and coherent, in addition to ensuring that each prescription delivery and medical appointment is correctly associated with the corresponding affiliate. In addition, the proposed adaptation of each attribute of the two reports could be applied by the EPS and contribute to obtaining more reliable reports and accurate indicator results, thus promoting more informed decisions in the health sector.
The results of the validation by the health sector experts’ focus group indicate that the proposed adaptation meets the needs of data quality for the reports on the prescription delivery and assignment of medical appointments, considering that in all subcategories a percentage of 100% is obtained by adding up "Completely Agree" and "Agree"; which supports the importance of applying these data quality criteria.
Considering the experts suggestions, it is proposed that this adaptation include parameters defined by the IPS for the supra-specialties, thus allowing greater control of the data quality (e.g., establishing a maximum number of appointments per supra-specialty). In addition, this adaptation should be incorporated into an ETL process to define a structured data quality flow at each stage, seeking to reduce errors and improve the overall quality of the information managed.

