










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkRevista de Ciencias
versão impressa ISSN 0121-1935
rev. cienc. vol.18 no.2 Cali jul./dez. 2014
Structured Secant Method for the Multilayer Perceptron Training
Método secante estructurado para el entrenamiento del perceptrón multicapa
Hevert Vivas
Departamento de Matemáticas, Universidad del Cauca, Popayán-Colombia
E-mail: hevivas@unicauca.edu.co
Héctor Jairo Martínez
Departamento de Matemáticas, Universidad del Valle, Cali- Colombia
E-mail: martinez@correounivalle.edu.co
Rosana Pérez
Departamento de Matemáticas, Universidad del Cauca, Popayán-Colombia
E-mail: rosana@unicauca.edu.co
Received: May 6, 2014
Accepted: August 22, 2014
Abstract
In the group of models of artificial neural networks, it is the multilayer perceptron, a unidirectional neural network consisting of three or more layers, its training is done by an algorithm called backpropagation. In this work, we introduced the structured secant method for the training of multilayer perceptron and we compare its numerical performance with other methods widely used with the same purpose. Some numerical experiments show a good performance of this algorithm.
Keywords: Multilayer perceptron, structured secant method, training neural network, nonlinear least squares.
Resumen
Dentro del grupo de modelos de redes neuronales artificiales está el perceptrón multicapa: una red neuronal unidireccional constituida por tres o más capas, cuyo entrenamiento se hace mediante un algoritmo denominado retro-propagacion de errores. En este trabajo, proponemos e implementamos por primera vez, el método secante estructurado para el entrenamiento del perceptrón multicapa y analizamos su desempeño numérico comparandolo con métodos ampliamente usados con el mismo proposito.
Palabras clave:método secante estructurado, entrenamiento de redes neuronales artificiales, perceptrón multicapa, mínimos cuadrados no lineales.
1 Introducción
Las Redes Neuronales Artificiales (RN A) son sistemas de procesamiento de información que funcionan de manera similar a las redes neuronales biológicas. Estas redes tienen en común con el cerebro humano la distribución de las operaciones a realizar en una serie de elementos básicos que, por analogía con los sistemas biológicos, se denominan neuronas artificiales; las cuales están relacionadas entre sí, mediante una serie de conexiones que se conocen como pesos sinápticos. En las RNA supervisadas, estos pesos y conexiones varían mediante un proceso, usualmente iterativo, conocido como aprendizaje o entrenamiento de la red en el cual, está inmersa una función error que depende explícitamente de los pesos sinápticos y proporciona el error que comete la red. Matemáticamente, el proceso de aprendizaje consiste en encontrar un vector (una configuración de pesos) que minimice dicha función error. Esto conduce a un problema de minimización, más exactamente, un problema de mínimos cuadrados no lineales.
El modelo de redes neuronales artificiales más empleado en aplicaciones prácticas es el del perceptrón multicapa, una red neuronal unidireccional constituida por al menos, tres capas junto con su algoritmo de entrenamiento denominado retropropagación de errores (backpropagation) (Martín del Brío y Sanz, 2007).
En este artículo, proponemos e implementamos por primera vez, el método secante estructurado para el entrenamiento del perceptrón multicapa, y analizamos su desempeño numérico comparándolo con métodos ampliamente usados con el mismo propósito, tales como: Gauss-Newton y Levenverg-Marquardt (Martín del Brío y Sanz, 2007). Pruebas numéricas preliminares muestran un buen desempeño numérico del método propuesto.
Organizamos la presentación de este documento de la siguiente forma. En la Sección 2, presentamos el problema de Mínimos Cuadrados No Lineales como un caso particular de minimización sin restricciones y describimos diferentes métodos de solución y sus propiedades de convergencia, centrándonos en el método secante estructurado. En la Sección 3, presentamos en forma descriptiva las redes neuronales artificiales, su estructura y su funcionamiento, profundizando en el perceptrón multicapa y en su algoritmo de entrenamiento denominado retropropagación de errores. En la Sección 4, proponemos e implementamos por primera vez, el método secante estructurado para el entrenamiento del perceptrón multicapa y analizamos numéricamente su desempeño para diferentes actualizaciones secantes. Finalmente, en la Sección 5, hacemos algunos comentarios finales y propuestas de trabajos futuros sobre el tema.
2. Mínimos cuadrados no líneales (MCNL)
En esta sección, abordamos un problema particular de miniminización sin restricciones que surge con frecuencia en problemas prácticos, tales como: ajuste de curvas, reconocimiento y clasificación de patrones y en redes neuronales artificiales, entre otros. Nos referimos al problema de Mínimos Cuadrados No Lineales.
2.1. Planteamiento del problema
Dada R : ℝn → ℝm, m ≥ nm R(x) = (r1 (x),...,rm(x))T, función no lineal y dos veces continuamente diferenciable, el problema de Mínimos Cuadrados No Lineales (MCNL) consiste en resolver el problema de minimización sin restricciones
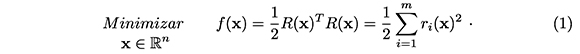
La estructura particular del problema (1), se observa claramente en las expresiones para el vector gradiente y la matriz hessiana de f,en x. En efecto,
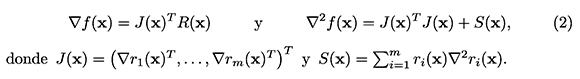
Observemos que la matriz jacobiana J(x) contiene solamente información de primer orden (primeras derivadas parciales) y S ( x) contiene información de segundo orden (es una combinación lineal de matrices hessianas). Esta estructura especial de la matriz hessiana de f, es la que se aprovecha en algunos de los métodos usados para resolver el problema (1) y es la razón por la cual no se usan métodos de propósito general para resolver el mismo. La información de primer orden es relativamente fácil de calcular, mientras que la de segundo orden es numéricamente difícil de calcular, ya que involucra el cálculo de m hessianos, lo que implica un alto costo computacional (Dennis & Schnabel, 1983; Nocedal & Wright, 2006; Fletcher, 2000) .
2.2. Métodos de solución
En esta sección, describimos algunos métodos de solución del problema MCNL. Incluimos, dada su popularidad e importancia, métodos de propósito general para resolver problemas de minimización tales como el método de Newton y los métodos secantes, los cuales debido a que no aprovechan la estructura particular del problema (1), no son muy apropiados para resolverlo. Además, describimos métodos especialmente diseñados para resolver el problema MCNL, como Gauss Newton, Levenberg-Marquardt y secante estructurado. Todos estos métodos coinciden en que una iteración básica incluye la solución de un sistema de ecuaciones lineales para posteriormente, generar la aproximación siguiente.
2.2.1. Método de Newton
La idea básica del método de Newton para resolver un problema de minimización sin restricciones consiste en, dada una aproximación a la solución del problema, resolver en cada iteración un sistema de ecuaciones lineales, cuya "solución" es usada para generar la aproximación siguiente. Es decir, su iteración básica es:
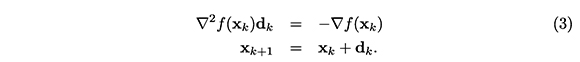
La convergencia de este método es q-cuadrática, siempre y cuando ![]() 72 fsea Lipschitz continua alrededor de Xk y
72 fsea Lipschitz continua alrededor de Xk y ![]() (xk) sea definida positiva (Dennis & Schnabel, 1983). A pesar de que las propiedades de convergencia del método de Newton son muy buenas comparadas con otros métodos, el término S(x) es, computacionalmente, costoso de calcular.
(xk) sea definida positiva (Dennis & Schnabel, 1983). A pesar de que las propiedades de convergencia del método de Newton son muy buenas comparadas con otros métodos, el término S(x) es, computacionalmente, costoso de calcular.
2.2.2. Método Gauss-Newton
El método de Gauss-Newton es una variante del método de Newton y su iteración básica es:
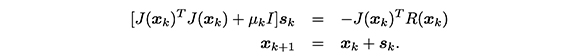
Este método surgió para evitar dificultades del método Gauss-Newton cuando, a lo largo del proceso iterativo, la matriz Jacobiana no tiene rango completo o está mal condicionada. Las propiedades de convergencia del método de Levenberg-Marquard son similares a las del método de Gauss-Newton; sin embargo, muchas implementaciones de su algoritmo superan las desventajas propias del método de Gauss-Newton (Dennis & Schnabel, 1983).
2.2.4. Métodos Secantes
En la iteración de Newton (3), es necesario calcular la matriz hessiana de f en xk y, para encontrar el paso de Newton, vía factorización de Cholesky, se requiere que la matriz ![]() (xk) sea definida positiva; por lo cual, a no ser que ella tenga una estructura particular, dicha factorización es muy costosa computacionalmente. Si a lo anterior le agregamos el hecho de que, en general, el sólo cálculo del hessiano de f en (xk) ya es muy costoso, se hace indispensable tener métodos que resuelvan el mismo problema de minimización, sin tener que realizar estos cálculos. De esta manera, surgen los denominados métodos cuasi Newton, los cuales usan una aproximación de la matriz hessiana en lugar de ella misma. Así, si Bk es una "buena" aproximación de la matriz hessiana
(xk) sea definida positiva; por lo cual, a no ser que ella tenga una estructura particular, dicha factorización es muy costosa computacionalmente. Si a lo anterior le agregamos el hecho de que, en general, el sólo cálculo del hessiano de f en (xk) ya es muy costoso, se hace indispensable tener métodos que resuelvan el mismo problema de minimización, sin tener que realizar estos cálculos. De esta manera, surgen los denominados métodos cuasi Newton, los cuales usan una aproximación de la matriz hessiana en lugar de ella misma. Así, si Bk es una "buena" aproximación de la matriz hessiana ![]() (xk), entonces la dirección cuasi newton será la solución al sistema de ecuaciones lineales
(xk), entonces la dirección cuasi newton será la solución al sistema de ecuaciones lineales
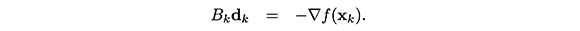
Cuando decimos una "buena" aproximación, nos referimos a que requerimos que Bk conserve las buenas propiedades del hessiano (simetría) y que permita encontrar direcciones de descenso (definida positiva). Así, al resolver un problema de minimización, usando un método cuasi Newton, ganamos estabilidad numérica, eficiencia y convergencia (Pérez y Díaz, 2010). Si además, actualizamos la aproximación Bk de tal forma que satisfaga la llamada ecuación secante1
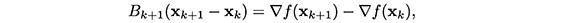
entonces surgen los denominados métodos secantes, cuya iteración básica es la siguiente:
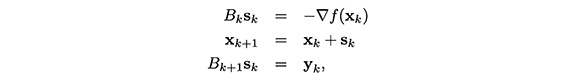
donde sk+1 - xk , yk = ∇f(Xk+1) - ∇f(xk) y Bk+1 es llamada actualizaciòn secante.
Existen varias actualizaciones secantes exitosas. Entre ellas, están la BFGS, propuesta independientemente por Broyden en (1969) y Fletcher, Goldfarb y Shano en (1970), dada por:
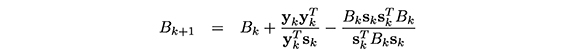
y la actualización DFP propuesta por Davidon en (1959), Fletcher y Powell en (1963) definida por
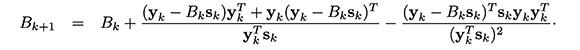
En la práctica, se recomienda la actualización BFGS, debido a que su desempeño numérico es mejor; sin embargo, la actualización DFP fue la primera actualización secante propuesta, por lo cual tiene un gran interés tanto histórico como analítico (Pérez y Díaz, 2010; Dennis & Schnabel, 1983).
2.2.5. Métodos secantes estructurados
Desafortunadamente, los métodos secantes tal y como han sido descritos hasta aquí, no aprovechan la estructura de la matriz hessiana dada en (2). Es decir, no aprovechan los cálculos del jacobiano ya realizados. Una alternativa para ello, la representan los llamados métodos secantes estructurados. Estos métodos son apropiados para problemas en los cuales la matriz hessiana, tal como sucede en el problema (1), se puede expresar en la forma:
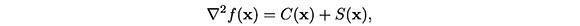
donde C(x) contiene información "fácil" de obtener y S(x) contiene información que es "difícil" o imposible de calcular. Así, en un método secante estructurado, basta hacer una aproximación secante de la parte "difícil", S(x), conservando el resto de la estructura.
En particular, para el problema MCNL (1), tenemos que ∇2 f(x) = C(x) + S(x), donde:
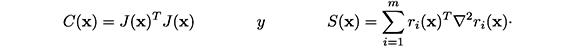
Con ello, en un método secante estructurado, para el problema de mínimos cuadrados no lineales (1), hacemos el proceso iterativo
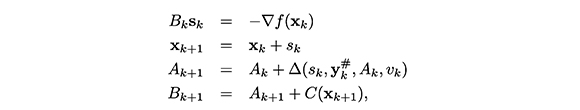
donde Ak es una aproximaciòn a 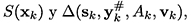 corrección de actualización secante, está definida por
corrección de actualización secante, está definida por
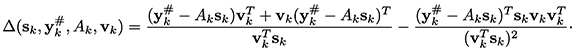
El vector vk ∈ ℝn es denominado la escala y con frecuencia es función de s, y y B Diferentes valores de la escala permiten obtener actualizaciones reconocidas y muy utilizadas (Martínez & Engels, 1991) como por ejemplo:
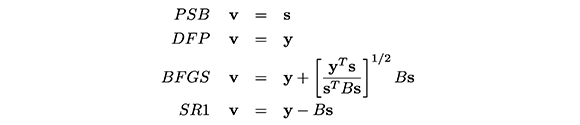

Entre las ventajas del método secante estructurado, está el hecho de que no es necesario el cálculo analítico de la matriz hessiana; basta aproximar solo la parte que contiene la información de segundo orden, la cual es costosa de obtener computacionalmente y difícil de obtener analíticamente. Además, su convergencia es q-superlineal y no depende del tamaño del residuo de la función objetivo (Dennis & Schnabel, 1983).
La teoría de convergencia para los métodos secante estructurados PSB, DFP ue desarrollada en 1981 (Dennis & Walker, 1983)mientras que la del método BFGS estructurado fue establecida en 1989 (Martínez et al., 1989). Una aplicación directa de esta teoría da la primera prueba de convergencia local y q -superlineal del método BFGS estructurado para el problema de mínimos cuadrados no lineales, el cual es usado por Dennis, Gay, y Welsh en la versión actual del código NL2SOL (Dennis et al., 1981).
3. Redes Neuronales Artificiales (RNA)
La historia de las redes neuronales artificiales está llena de creatividad individual en diferentes campos y ha sido documentada por varios autores. Desde antes de la aparición del primer computador hasta hoy, han ocurrido varios hechos que marcaron la historia de las redes neuronales artificiales. En la actualidad, son numerosos los trabajos que se realizan y publican cada año las aplicaciones nuevas que surgen (sobretodo en el área de control) y las empresas que lanzan al mercado productos nuevos, tanto en hardware como en software (sobre todo para simulación) (Martín del Brío y Sanz, 2007).
Informalmente, un sistema neuronal artificial tiene una estructura análoga al sistema neuronal biológico cuyos elementos básicos, llamadas neuronas artificiales, se conectan entre sí y se organizan en capas para formar la red neuronal.
3.1 Modelo general de neurona artificial
Al igual que una neurona biológica, una neurona artificial posee unas entradas que pueden provenir del exterior o de otras neuronas conectadas a ella y proporciona una única salida. En una red neuronal artificial, los elementos que constituyen la "neurona i" son las entradas xj (t), los pesos sinápticos, wij,la regla de propagación, hi(t) = σ(wij,Xj(t)), donde σ(·,·) proporciona el valor del potencial postsináptico; la función de activación, fi(ai (t- 1), hi( t)) , donde ai(t) proporciona el estado de activación actual; finalmente, la función de salida, Fi(ai(t)).
En general, el modelo que habitualmente se usa es aquel cuya regla de propagación es la suma ponderada de las entradas y de sus pesos respectivos, la función de activación proporciona su salida y tiene un parámetro adicional (θ)i, conocido como umbral o bias, el cual puede tener diferentes usos dependiendo del modelo (Figura 1). Así, dicho modelo se puede expresar por la igualdad
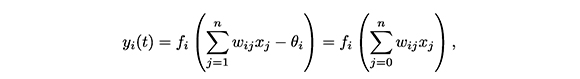
donde en la última parte hemos incluido el parámetro (θ)i como si fuera el peso wi0, con la convención de que x0 = -1
Figura 1. Principales elementos de una neurona artificial
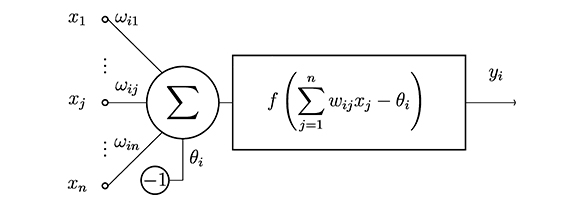
3.2. Estructura
En una red neuronal artificial, podemos distinguir tres tipos de capas. Una capa de entrada formada por las neuronas que reciben la información del medio exterior, una capa de salida formada por las neuronas que transfieren la información procesada al exterior y una capa intermedia u oculta (la cual puede o no existir), en la cual se procesa toda la información sin tener conexión con el entorno donde opera.
Dependiendo del enfoque, se pueden establecer diferentes arquitecturas de redes neuronales artificiales. De acuerdo al número de capas hablamos de redes neuronales monocapa compuestas por una única capa; o redes neuronales multicapa compuestas por varias capas. En relación a la manera como fluye la información, tenemos las redes neuronales unidireccionales (feedforward), en las cuales la información fluye en un solo sentido y las redes recurrentes o retroalimentadas (feedback), en las que la información puede fluir en cualquier sentido, incluido el de entrada-salida.
3.3. Aprendizaje
En una red neuronal artificial, podemos distinguir tres tipos de capas. Una capa de entrada formada por las neuronas que reciben la información del medio exterior, una capa de salida Una RNA no está completa si no podemos garantizar que funcione correctamente con un cierto grado de confianza; para ello, al igual que nuestro cerebro, funciona mejor en la medida que reciba un buen aprendizaje o entrenamiento, una vez definida su estructura, las redes neuronales artificiales necesitan pasar por un proceso de aprendizaje, en el cual se ajustan sus pesos sinápticos, con el fin de adaptar su desempeño al entorno donde operará. El tipo de aprendizaje es determinado de acuerdo a la manera en que dichos pesos son ajustados.
En efecto, con la estructura de la red fija, el proceso de aprendizaje consiste en modificar los pesos sinápticos siguiendo una cierta regla de aprendizaje. En este sentido, básicamente, existen dos tipos de aprendizaje: el supervisado que se caracteriza por tener un control externo a través de un supervisor o maestro, el cual conoce las salidas deseadas correspondientes a un conjunto de entradas; dichas salidas permiten definir una función error que se desea minimizar. El otro tipo de aprendizaje es el no supervisado o autoorganizado que consiste en estimar los pesos de la red, en función de la caracterización de los datos de entrada de acuerdo a un objetivo específico que permita detectar sus patrones.
3.4. Perceptrón multicapa
Dentro del grupo de redes unidireccionales que usan aprendizaje supervisado, están el perceptrón simple, la adalina y el perceptrón multicapa. El perceptrón simple y la adalina son de gran interés histórico, pues su evolución representa la historia misma de las redes neuronales artificiales (Martín del Brío y Sanz, 2007). En general, la importancia de estos modelos se debe a su carácter de dispositivos entrenables.
El perceptrón multicapa es una red neuronal unidireccional constituida por tres o más capas: una capa de entrada, otra capa de salida y el resto de capas intermedias denominadas capas ocultas. La estructura de un perceptrón multicapa, con una capa oculta3 , se representa en la Figura 2.
Figura 2. Perceptrón multicapa (MLP).
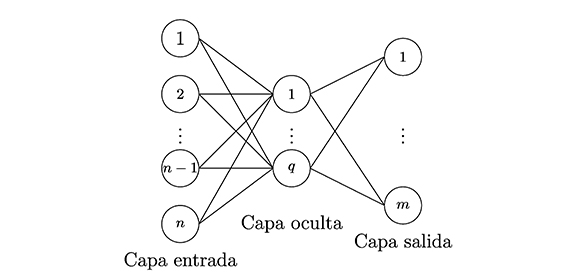
Sean xilas entradas de la red; yj, las salidas de la capa oculta; zk, las salidas de la capa final; wij, los pesos de la capa oculta y θj, sus umbrales; wtkj, los pesos de la capa de salida, y θ'k, sus umbrales, para todo i = 1, ...,n, j = 1, ... , q y para todo k = 1, ... , m. La operación de un perceptrón multicapa con estas características se expresa matemáticamente por la ecuación:
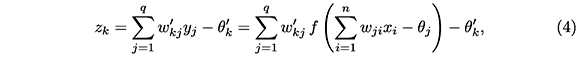
Como ya mencionamos, el aprendizaje de un perceptrón multicapa se hace a través de la minimización de una función error que mide la diferencia entre la salida z obtenida por la red y la salida deseada t. Matemáticamente, la función error es es un campo escalar E : ℝn → ℝ, en la variable w, que para nuestro caso es un vector cuyas componentes son los pesos sinápticos. Así, asociado al aprendizaje de un perceptrón multicapa, tenemos el siguiente problema de optimización:
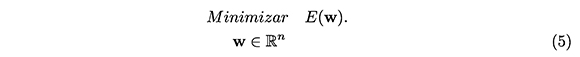
En el caso de una muestra finita formada por los patrones de entrada, x1, x2,...,xP, vectores ℝn de cada uno de los cuales tiene como componentes las entradas de la red, y de los vectores de ℝm, t1, t2,...,tP, que contienen las salidas deseadas, la función error E es la siguiente
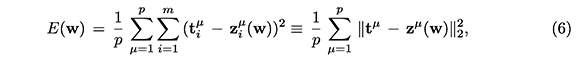
donde cada vector zµ (w) µ ∈ ℝm, con µ = 1,...,p, contiene las respuestas de la red correspondientes al patrón de entrada xµ, cuando los pesos sinápticos están dados por w. Así, la función E permite obtener el error cuadrático medio de las salidas de la red respecto de las deseadas (Martín del Brío y Sanz, 2007).
En el proceso iterativo del algoritmo de entrenamiento de una red neuronal multicapa, se lleva a cabo una fase de ejecución de la red para los patrones de entrenamiento. Existen dos maneras de hacer esta ejecución; una denominada aprendizaje por lotes, que consiste en presentar a la red todos y cada uno de los patrones de entrenamiento, calcular para cada patrón, el error en la salida y por último, proceder a hacer la actualización de los pesos sinápticos; y la otra llamada aprendizaje en serie que consiste en calcular el error en la salida y actualizar los pesos sinápticos tras la presentación de cada patrón de aprendizaje, teniendo presente que en cada iteración, el orden en la presentación de los patrones sea aleatorio (Martín del Brío y Sanz, 2007).
Para el perceptrón multicapa definido anteriormente, si xµ para µ = 1,..., p es un patrón de entrada, la ejecución de la red (4) se expresa como:
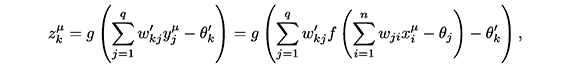
donde g es la función de activación de las neuronas de salida y f de las ocultas. En este sentido, la función error cuadrático medio es
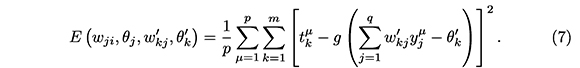
El problema (5) con E dada por (7) es un problema MCNL [2].
4. Pruebas numéricas
En esta sección, implementamos por primera vez, el método secante estructurado para el entrenamiento del perceptrón multicapa. Con el propósito de comparar su desempeño numérico, también implementamos los métodos de GaussNewton y Levenverg-Marquardt, ampliamente utilizados con el mismo propósito, en paquetes (o programas) como el Toolbox de redes neuronales de MATLAB®. Usamos las cuatro fórmulas dadas en (4) para actualizar en cada iteración la matriz Ak dada por (4), con lo cual tenemos cuatro versiones del algoritmo secante estructurado, las cuales llamaremos: método PSBE, DFPE, BFGSE y SR1E, respectivamente.
Para las pruebas numéricas, consideramos el entrenamiento de dos redes del tipo perceptrón multicapa para resolver sendos problemas: evaluar la función seno y predecir el consumo de energía eléctrica en una determinada región, en un día dado y una hora determinada usando la red propuesta por (Medicina y Complejidad, s.f.). Para escribir los códigos de los algoritmos y de las funciones objetivo de cada problema, usamos el software MATLAB® versión 2010. Realizamos las pruebas numéricas en un computador Intel (R) Core (TM) i5-CPU de 2.67 GHz. La presentación de los parámetros de entrenamiento la hicimos usando la técnica de entrenamiento por lotes descrita en la Sección 3.
4.1 Algoritmo general
Como lo mencionamos anteriormente, en el entrenamiento del perceptrón multicapa, resolvemos el problema de minimización (5) con E definida por (6). En general, para la obtención de los pesos iniciales, se recomienda iniciar con vectores aleatorios (Martín del Brío y Sanz, 2007); los algoritmos están implementados, usando una estrategia de globalización denominada búsqueda lineal, que permita iniciar desde cualquier punto [12, 2].
Los métodos globalizados, en cada iteración, determinan una dirección de descenso sk y con una estrategia de búsqueda lineal (Dennis & Schnabel, 1983)encuentran un tamaño de paso λk, con el cual se define la aproximación siguiente Wk+1·
Usamos dos criterios de parada en nuestro algoritmo: uno relacionado con el tamaño del gradiente de la función objetivo (b ∇ E(w) ) y el otro, relacionado con el número de iteraciones (n). Exactamente, declaramos convergencia si ||g||2 ≤ tol y divergencia si n > N, es el número máximo de iteraciones en el algoritmo.
A continuación, presentamos la estructura general del algoritmo para el entrenamiento de un perceptrón multicapa, en el cual se asume conocida la arquitectura de red neuronal artificial.
Algoritmo 1 Dados los patrones de entrenamiento: xµ y tµ, >µ = 1,...,p, se procede como sigue:
P. O. Inicialización
Generar los pesos iniciales w0.
Calcular la salida de la red para los p patrones de entrenamiento, y el error en la salida.
P.1. Criterios de parada
||∇E(wk||2 > Tol y k ≤ N
P.2. Búsqueda direccional
Calcule Bk y encuentre sk tal que Bksk = - ∇E(wk).
P.3. Búsqueda lineal
Calcular λk tal que E(w + λk sk = ∇E(wk).
P.4. Actualización
Definir w : wk+1 = wk + λksk
Para el paso P.3 del algoritmo, en las pruebas numéricas, usamos como valor inicial del tamaño de paso λ0 = 1 y como valores de la constante a usamos dos valores 0.0001 y 0.01.
Realizamos dos tipos de pruebas numéricas:
l. Comparar el desempeño numérico de las cuatro versiones del método secante estructurado. Haremos referencia a estas versiones como métodos PSBE, DFPE, BFGSE y SRlE, respectivamente.
2. Comparar el desempeño numérico de los métodos BFGS, LevenvergMarquard, Gauss-Newton y "el mejor" de los métodos estructurados mencionados en el numeral anterior.
Problema 1: Evaluación de la función seno
Este problema ilustra el uso del percetrón multicapa como aproximador universal de funciones. En efecto, para cualquier función de ℝn en ℝm, siempre es posible diseñar y entrenar un perceptrón multicapa, de tal manera que realice un ajuste de los datos de dicha función con un grado de precisión predefinido (Caicedo, y López, 2009). En particular, es relativamente sencillo evaluar una función de variable y valor real tal como la función seno, mediante una de estas redes.
Resolvimos el problema mediante una percetrón multicapa de tres capas (Figura 3), donde el número de neuronas en la capa oculta (neo) es definido por el usuario. Los patrones de entrenamiento fueron x = (x1,...,xp)T, p = 41 y t (t1,...,tp)T cob ti = senxi, donde las componentes de x (entradas de la red) son números reales distribuidos uniformemente en el intervalo [0,2π]. Usamos como función de activación la sigmoidal (logsig) y la identidad (purelin) en la capa oculta y de salida, respectivamente (Caicedo, y López, 2009).
Figura 3. Perceptrón multicapa que aproxima lafúnción seno.
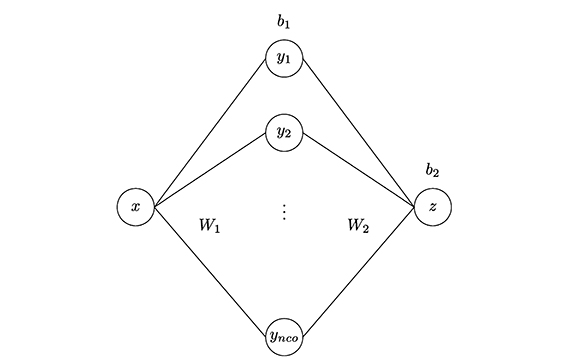
El vector de pesos iniciales para cada valor de neo, w0nco, lo generamos aleatoriamente con la función de MATLAB® randan(·,·), exactamente w0nco = randn(3neo + 1, 1) (Vivas, 2014).
Presentamos los resultados de estas pruebas en dos tablas, cuyas dos primeras columnas contienen la información sobre el número de neuronas en la capa oculta (neo) y la tolerancia usada (Tal). Las cuatro columnas siguientes contienen, para cada método, el tiempo de ejecución (t) , medido en segundos, y el número de iteraciones (n). El símbolo "-" indica que hubo divergencia del método considerado (se excedió el número máximo de iteraciones permitido (N= 500 )).
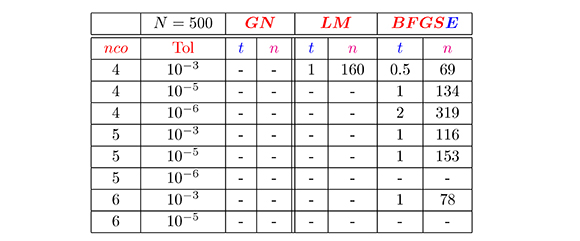
En la Tabla 1, podemos observar que en general, el método BFGSE convergió en el menor tiempo y número de iteraciones, mientras que los métodos DFPE y SR1E no convergieron en ningún de los casos. De la Tabla 2, observamos que para Tol ≤; 10-5 y neo = 4 y 5, el método BFGSE siempre converge y lo hace con un mejor desempeño numérico que los otros métodos comparados aquí. Además, el método Levenberg-Marquardt presentó mejor desempeño numérico que Gauss-Newton.
Tabla 1. Resultados de los métodos secantes estructurados para la evaluación de la función seno
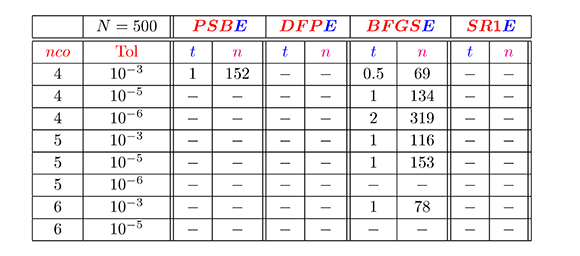
Tabla 2. Resultados de los métodos de Gauss-Newton (GN), Levenberg-Marquardt (LM) y secante estructurado (BFGSE) para la evaluación de la función seno
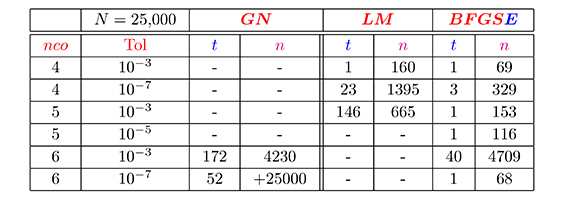
Cabe mencionar que, la divergencia en los métodos secantes estructurados PSBE, DFPE, Levenberg-Marquardt y Gauss-Newton, ilustrada en las Tablas 1 y 2, se debe a que se alcanzó el número máximo de iteraciones permitido. Sin embargo, las Tablas 3 y 4 muestran lo que sucede si el número máximo de iteraciones se aumenta suficientemente (o considerablemente).
Tabla 3. Otros resultados de los métodos secantes estructurados, N = 25 ,000, para la evaluación de la función seno.
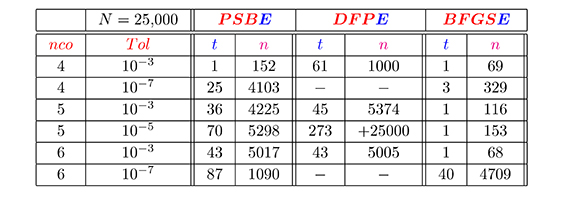
Tabla 4. Otros resultados de los métodos de Gauss-Newton (GN), Levenberg-Marquardt (LM) y secante estructurado (BFGSE), N= 25,000, para la evaluación de la función seno
Problema 2: Predicción de consumo eléctrico [8, 15].
Una empresa abastecedora de energía eléctrica, en una población, debe garantizar que el servicio siempre llegue con buena calidad y, de ser posible, a un precio justo. Para que esto ocurra, el servicio debe entregar energía a todos los puntos que lo requieran, mantener los límites de la frecuencia y la tensión con valores dentro de un rango tolerable y operar con costos mínimos, tanto económicos como ambientales. Por tal motivo, es indispensable una planeación exhaustiva del sistema que nos permita, no solo conocer su estado actual en cualquier momento sino también estados futuros, con el fin de no producir en exceso, ya que habría desperdicio del servicio y daños en el medio ambiente; ni producir tan poco, que no sea suficiente para cubrir las necesidades del servicio.
U na de las partes indispensables en esta planeación es la predicción del consumo de carga eléctrica. El interés de esta predicción radica en la necesidad de que las empresas productoras o vendedoras de energía de la región, conozcan con antelación las necesidades de su mercado para poder planear la distribución futura de la energía eléctrica, con el fin de optimizar tanto la producción como su abastecimiento. Por tal motivo, este problema consiste en predecir la demanda de consumo eléctrico en una región para una hora y un día cualquiera, en años futuros.
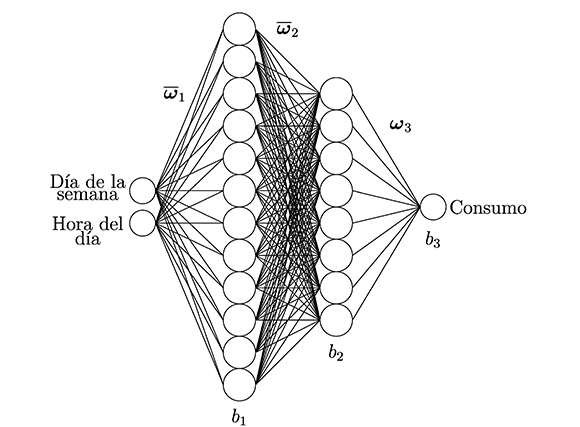
Para resolver este problema, usamos el modelo propuesto en una investigación realizada en la Universidad Tecnológica de Pereira (Medicina y Complejidad, s.f.), este modelo consiste en una red neuronal de 4 capas (Figura 4): la capa de entrada, con dos neuronas que corresponden al día y la hora; la capa de salida, con una neurona que corresponde al consumo eléctrico en kilovatios ( kw); la primera capa oculta, con doce neuronas, y la segunda capa oculta, con ocho neuronas. Como funciones de activación usaron la tangente sigmoidal (tansig), en ambas capas ocultas, y la identidad (purelin), en la capa de salida, y como algoritmo de entrenamiento, el método de Levenberg-Marquardt que aparece en el Toolbox de MATLAB®.
Figura 4. Perceptrón multicapa para el consumo eléctrico
Para generar vectores iniciales, procedimos de la siguiente forma. Inicialmente, generamos aleatoriamente dos vectores ![]() 0 = randan(149,1) y
0 = randan(149,1) y ![]() 1 = randan(149,1). Luego generamos otros vectores iniciales de la forma α
1 = randan(149,1). Luego generamos otros vectores iniciales de la forma α![]() 0 y µ
0 y µ![]() 0 +
0 + ![]() 0, para
0, para ![]() = 1, 1.2, 2, 2.5, 10, -10, 102 y µ = 1, 10, 102 , respectivamente (Vivas, 2014).
= 1, 1.2, 2, 2.5, 10, -10, 102 y µ = 1, 10, 102 , respectivamente (Vivas, 2014).
En las pruebas numencas para el Problema 2, usamos 112 datos de entrenamiento extraídos de los datos usados en (Medicina y Complejidad, s.f.) y los cuales, corresponden a los promedios históricos de consumo eléctrico, en una población de muestra a la que se le hizo un seguimiento, hora a hora, durante una semana.
Los resultados de las pruebas numéricas para el Problema 2, los presentamos en las Tablas 5 y 6. La primera tabla contiene información de los algoritmos secantes estructurados obtenida a partir de puntos iniciales de la forma ![]() w0 y µw1 + w0. Exactamente, la primer columna contiene los valores de α y de µ utilizados. Las cuatro columnas siguientes contienen, para cada método secante estructurado, la tolerancia usada (Tol), el tiempo de ejecución (t), medido en segundos y el número de iteraciones (n). La segunda tabla, contiene los resultados de la comparación de los métodos de Gauss-Newton, Levenberg-Marquardt y secante estructurado (BFGSE), a partir de estos puntos iniciales. El símbolo "-" indica que hubo divergencia del método considerado (se excedió el número máximo de iteraciones permitido, (N= 200 )).
w0 y µw1 + w0. Exactamente, la primer columna contiene los valores de α y de µ utilizados. Las cuatro columnas siguientes contienen, para cada método secante estructurado, la tolerancia usada (Tol), el tiempo de ejecución (t), medido en segundos y el número de iteraciones (n). La segunda tabla, contiene los resultados de la comparación de los métodos de Gauss-Newton, Levenberg-Marquardt y secante estructurado (BFGSE), a partir de estos puntos iniciales. El símbolo "-" indica que hubo divergencia del método considerado (se excedió el número máximo de iteraciones permitido, (N= 200 )).
En la Tabla 5, podemos observar que, en general, los 4 métodos secantes estructurados tienen un buen desempeño numérico (similar en todos los casos), en cuanto a tiempo de ejecución y número de iteraciones, excepto, cuando µ = 102, y Tol = 10-3, caso en el cual, el método PSBE empleó más tiempo y convergió en un número mayor de iteraciones que los otros métodos.
Tabla 5. Resultados de los métodos secantes estructurados para el problema del consumo eléctrico
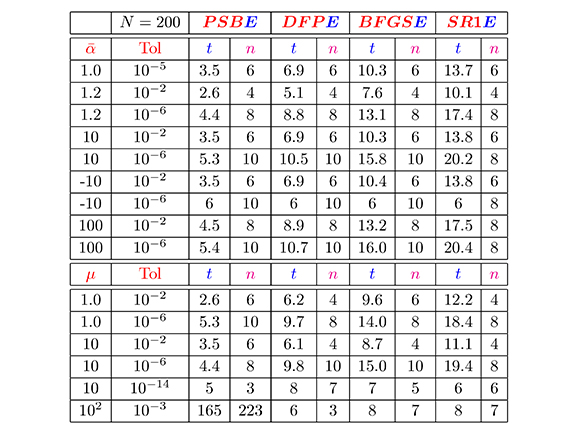
Tabla 6. Resultados de los métodos Gauss-Newton (GN), Levenberg-Marquardt (LM), BFGS y secante estructurado BFGSE para el problema del consumo eléctrico
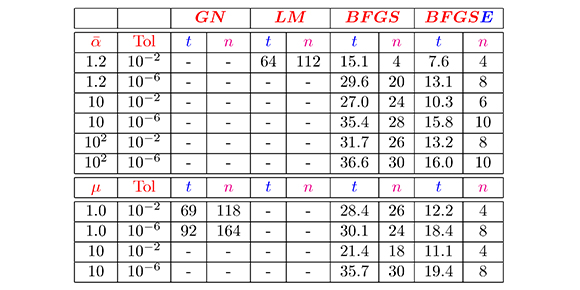
Con relación a la Tabla 6, podemos observar, como esperábamos, el buen desempeño numérico del método BFGSE en comparación con los métodos BFGS, Gauss-Newton y Levenberg-Marquardt, en todos los aspectos comparados. Ahora, si solo comparamos los métodos Gauss-Newton y Levenberg-Marquardt, vemos que en casi todos los casos hay divergencia. Esta divergencia está condicionada al número máximo de iteraciones permitido en cada algoritmo (N), tal como sucedió para el Problema l.
Por otra parte, podemos observar que los resultados obtenidos están acordes con la teoría sobre los métodos estudiados, la cual garantiza que para problemas de gran tamaño, la convergencia de los métodos secantes estructurados, en especial el método BFGSE, en general, es mejor que la de los otros métodos con los cuales hicimos las comparaciones (Dennis & Schnabel, 1983).
5. Comentarios finales
El estudio de redes neuronales artificiales constituye en la actualidad un amplio y activo campo en el que pueden interactuar investigadores de muchas y diferentes áreas, para resolver problemas prácticos y útiles tales como control de procesos industriales, reconocimiento de vehículos en los peajes de las autopistas, previsión de consumo eléctrico, entre otros. En este contexto, es quizá el perceptrón multicapa, con su algoritmo de entrenamiento de retropropagación de errores, el modelo neuronal más utilizado.
Métodos numéricos tradicionalmente usados en el entrenamiento supervisado del perceptrón multicapa como por ejemplo Newton, Gauss-Newton y LevenvergMarquardt requieren del cálculo de la matriz hessiana de la función error; es decir, requieren información de segundo orden, lo que representa, a pesar de las buenas propiedades de los métodos, una desventaja de ellos, ya que los hace inadecuados para problemas con un elevado número de neuronas. En este caso, el cálculo analítico del hessiano es muy difícil o muy costoso, computacionalmente, dado el gran número de operaciones involucradas en el proceso. Una alternativa la representa el método secante estructurado, el cual no requiere explícitamente el cálculo directo de la matriz hessiana de la función a minimizar y además, aprovecha la estructura del problema, sin contar con las buenas propiedades de convergencia que posee.
Motivados por las buenas características del método secante estructurado, en este artículo lo proponemos e implementamos, por primera vez, para el entrenamiento del perceptrón multicapa, y analizamos numéricamente su desempeño comparándolo con los métodos Gauss-Newton y Levenverg-Marquardt. Resultados de pruebas numéricas presentadas indican un buen comportamiento numérico del método propuesto, pero creemos que es necesario realizar más experimentación numérica con diversos problemas de aplicación e introducir otros métodos de globalización, con lo cual se abre la puerta a nuevas investigaciones.
Agradecimientos
Los autores agradecen a la Universidad del Cauca por el tiempo concedido para este trabajo mediante el Proyecto de investigación VRI ID 3908.
Citas de pie de página
1. El nombre de ecuación secante se utiliza porque en el caso n = 1, Bk+l representa la pendiente de la recta secante a la gráfica de la función f'que une los puntos (xk,f'(xk)) y (xk+l, f'(xk+l))·
2. NL2SOL es una biblioteca en FORTRAN90 que implementa un algoritmo para resolver problemas de mínimos cuadrados no lineales y fue creada por John Dennis, David Gay y Roy Welsch. Este es un método de implementación para el algoritmo secante estructurado que usa una estrategia de región de confianza para globalizarlo (Martínez & Engels, 1991; Dennis & Schnabel 1983).
3. Existen diversas demostraciones de que este modelo de perceptrón multicapa es un aproximador universal de funciones (Martín del Brío y Sanz, 2007).
Referencias
Caicedo, E. F., y López, J. A. (2009). Una aproximación Práctica a las Redes Neuronales Artificiales. Cali, Colombia: Programa Editorial Universidad del Valle. [ Links ]
Dennis, J. E., & Schnabel, R. B. (1983). Numerical methods for unconstrained optimization and nonlinear equations. New Jersey, USA: Prentice-Hall. [ Links ]
Dennis, J . E., & Walker, H. F. (1983). Covergence theorems for least change secant update methods. SIAM Journal Numerical Analisys, 18, 949-987. [ Links ]
Dennis Jr, J. E., Gay, D. M., & Welsch, R. E. (1981). Algorithm 573: NL2SOL-an adaptive nonlinear least-squares algorithm [E4]. ACM Transactions on Mathematical Software (TOMS), 7(3), 369-383. [ Links ]
Fletcher, R. (2000). Practica! Methods of Optimization (3 ed.). New York, USA: Wiley. [ Links ]
Gavin, P. H. (2013). The Levenberg-Marquardt method for nonlinear least squares curve-fitting problems. Durham, USA: Duke University. [ Links ]
Kandel, E. R., Schwartz, T. H., & Jessel, T. M. (1999). Principies of Neural Science (4 ed.). New York: McGraw-Hill. [ Links ]
Martín del Brío, B., y Sanz, A. (2007). Redes Neuronales y Sistemas Borrosos. Barcelona, España: Alfaomega. [ Links ]
Martínez, R.H.J., & Engels, J. (1991). Local and superlinear convergence for partially known quasi-Newton methods. Siam Journal on Optimization, 1(1), 42 - 56. [ Links ]
Martínez, R.H.J., Dennis, J., & Tapia, R. (1989). Convergence theory for the structured BFGS secant method with an application to nonlinear least squares. Journal of Optimization Theory And Applications, 61, 161 - 178. [ Links ] [ Links ]
Moré, J.J., Garbow, B. S., & Hillstrom, K. E. (1980). User guide for MINPACK-1. Argonne National Labs Report ANL-80-74. [ Links ]
Nocedal, J., & Wright, S. J. (2006). Numerical Optimization (2 ed.). London, UK: Springer. [ Links ]
Pérez, R., y Díaz, T. (2010). Minimización sin Restricciones. Popayán, Colombia: Editorial Universidad del Cauca. [ Links ]
Vivas, H. (2014). Optimización en entrenamiento del perceptrón multicapa. Tesis de Maestría. Universidad del Cauca, Popayán, Colombia. [ Links ]

Revista de Ciencias por Universidad del Valle se encuentra bajo una licencia Creative Commons Reconocimiento 4.0.

