











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1 Introducción
Los procesos más utilizados por investigadores para determinar diferencias significativas entre un parámetro poblacional y un valor hipotético se basan en procesos clásicos de inferencia estadística. A pesar de que los modelos de pruebas de hipótesis son muy usados para este fin, existen múltiples investigaciones que desaconsejan su uso, argumentando la presencia de graves deficiencias y dudosa utilidad 1 , 2, algo que parece no ocurrir cuando se usan modelos basados en intervalos de confianza, los cuales se asegura, son procedimientos que aventajan el uso del valor P como instrumento inferencial para muchos tipos de estudios observacionales y experimentales investigados principalmente en las ciencias médicas y sociales 3 - 5. El argumento presentado por estos estudios ha tenido tal impacto que algunas revistas que publican artículos sobre estas ciencias alientan a sus autores a trabajar con intervalos de confianza en lugar de pruebas de hipótesis 6.
El principal argumento por el cual se estimula el uso de intervalos de confianza en lugar del valor P es que los investigadores deben estar interesados en determinar el tamaño de la diferencia entre los parámetros comparados en lugar de una simple respuesta dicotómica que indique la existencia o no de dicha diferencia. En este sentido, con el uso del valor P nunca podremos determinar conclusiones más allá de aquella que nos permita determinar (o no) la existencia de diferencias significativas, independientemente de cuán grande sea esta, mientras que los intervalos de confianza nos mostrarán la magnitud de estas diferencias encontradas (7, 8) . A partir de este pensamiento se han escrito varias críticas sobre el uso de las pruebas de hipótesis en la valoración de la importancia de los resultados investigativos, dos muy famosas rezan de la siguiente manera “Adiós, p menor del 0.05”, equivoco y traicionero compañero de viaje. Tus efectos colaterales y toxicidad intracerebral son demasiado grandes para compensar cualquier beneficio que pudieras aportar” 9 y “Las típicas aseveraciones (p<0.05, p>0.05 o p= Nivel de significancia) dan poca información sobre los resultados de un estudio y se basan en el consenso arbitrario de utilizar el nivel de significación estadístico de 5% para definir los posibles resultados: significativo o no significativo. Esto no sirve para nada y, además, favorece la vagancia intelectual. Incluso cuando se indica el valor p en concreto, no se proporciona información alguna sobre las diferencias en los grupos estudiados” 10.
Con lo expuesto hasta ahora, concordamos en pensar que el valor P proporciona menor información de la estimación de un parámetro que los intervalos de confianza. Aún más, nos gustaría aportar a estas ideas, ciertos análisis muy interesantes sobre el mal planteamiento que parecen presentar las pruebas de hipótesis tradicionalmente usadas. Por ejemplo, hablando de test de hipótesis para probar perfecta normalidad, George Box en 1979 mencionó: “en la vida real no existe una distribución perfectamente normal, sin embargo, con modelos, que se sabe que son falsos, a menudo se pueden derivar resultados que coinciden, con una aproximación útil a los que se encuentran en el mundo real” 11.
Este pensamiento, fácilmente se puede trasladar a cualquier hipótesis nula que pretenda probar una perfecta igualdad de parámetros (medias, varianzas, proporciones, …) lo cual nos lleva a pensar que probar una hipótesis de perfecta igualdad carece de sentido, en su lugar parece ser que lo verdaderamente importante es saber si la aproximación de la prueba es lo suficientemente buena como para ser considerada útil. El criterio de Cochran establece que un test de hipótesis es considerado un buen modelo cuando la Probabilidad de cometer un error tipo I se aleja una distancia máxima del 20% de α por encima o por debajo de este nivel de significancia 12. Exactamente el mismo criterio es utilizado para definir la robustez de una prueba de hipótesis 13.
Además, cabe recalcar la dificultad lógica al concluir estos tipos de test tradicionales, en el sentido de que cuando no rechazamos una hipótesis nula no estamos concluyendo igualdad entre los parámetros comparados, en su lugar lo único que se concluye es ausencia de evidencia para determinar diferencias significativas entre los parámetros contrastados, lo cual no debe ser confundido con una significativa igualdad, o como en este mismo sentido se menciona “Ausencia de evidencia no es evidencia de ausencia” 14 o “Una diferencia no significativa no debe ser confundida con una significativa homogeneidad” 15. Si todas estas dificultades lógicas se producen al no rechazar una hipótesis nula tradicional de perfecta igualdad, por otra parte, el rechazarla solo podría estar probando una simple diferencia irrelevante entre los parámetros comparados, insuficiente como para ser considerada altamente significativa 16, lo cual nos lleva nuevamente a pensar la importancia de medir el tamaño de la diferencia entre los parámetros comparados.
A pesar de toda esta evidencia teórica en contra del uso de los test de hipótesis tradicionales, no estamos de acuerdo en afirmar que estadísticamente hablando se deba considerar que los intervalos de confianza son modelos inferenciales mejores que los test de hipótesis. A nuestro criterio, lo único que se ha demostrado con los estudios previos es que, a diferencia de las pruebas de hipótesis, el proceso de inferencia por intervalos de confianza proporciona mayor información de la magnitud de la diferencia entre el parámetro comparado y su valor hipotético, lo cual no debería ser confundido con un análisis objetivo de la comparación de la eficiencia de estos procedimientos. Si el problema es determinar la magnitud de la diferencia entre parámetros comparados, un enfoque de pruebas de hipótesis diferente al tradicional sería la solución. Este enfoque debe contener una hipótesis a probar en la que se establezca la existencia de identidad entre parámetros dentro de un intervalo de interés alrededor de la perfecta igualdad. Este tipo de pruebas de hipótesis existen, se denominan “test de hipótesis de equivalencia” y fueron planteadas por Steffan Wellek en el año 2010. El autor usa el término de equivalencia como una forma dilatada de una relación de semejanza entre los parámetros analizados y considera que esta dilatación en la hipótesis de equivalencia se induce al añadir en la hipótesis tradicional una zona de irrelevancia (que podría estar dada por la magnitud de la diferencia entre tratamientos comparados que se quieran probar) alrededor de la correspondiente región o punto en el espacio paramétrico que denota la igualdad perfecta. Esta zona de irrelevancia, cuyos límites son constantes positivas deben ser asignadas a priori y sin mayor conocimiento de la muestra. Inverso al test de hipótesis tradicional donde en la hipótesis nula, se especifica la igualdad de los parámetros comparados. Este tipo de pruebas se plantean de tal forma que la hipótesis nula establece la no equivalencia, mientras que la alternativa establece la equivalencia. Este cambio de interés en la investigación conduce a diseñar un estudio que pretende demostrar ausencia de una diferencia relevante entre los efectos de dos o más tratamientos, es decir, equivalencia 17. Además, es muy importante notar que las pruebas de equivalencia no buscan probar una perfecta igualdad de parámetros a compararse, en lugar de esto, la intención es declarar el cumplimiento de la relación de identidad incluso para desviaciones que pueden ser consideradas como irrelevantes o despreciables. Parece ser que, con estas precisiones, este enfoque supera las dificultades lógicas de los test tradicionales analizadas en los párrafos anteriores.
Aunque el problema de incluir la magnitud de la diferencia entre parámetros en un modelo de prueba de hipótesis parece estar superado con el uso de los test de equivalencia, aún nos resta comprobar (desde un punto de vista más objetivo que el planteado en investigaciones previas) si los modelos de intervalos de confianza pueden ser considerados mejores que los test estadístico tradicionales. Para ello, una medición y comparación de las probabilidades de error y/o acierto de los dos modelos nos parece un criterio estadístico no subjetivo. Por una parte, una estimación de la probabilidad de cometer un error al realizar un intervalo de confianza se puede obtener a partir de la proporción de veces que un parámetro cae afuera del intervalo cuando realmente debería estar adentro, el correspondiente estimador en una prueba de hipótesis es la proporción de veces que se rechaza la hipótesis nula de perfecta igualdad cuando esta es verdadera, lo cual se conoce como la Probabilidad de cometer un Error de tipo I. Por otra parte, una estimación de la probabilidad de cumplir un acierto en intervalos de confianza se puede ver como la proporción de veces que cierto parámetro cae fuera del intervalo cuando realmente debería hacerlo, el correspondiente estimador para pruebas de hipótesis es la proporción de veces que se rechaza la hipótesis nula de perfecta igualdad cuando esta es falsa, lo cual se conoce como la potencia de la prueba.
El presente estudio estima mediante un proceso de simulación las probabilidades de éxito y error descritas. Delimitamos estas mediciones a inferencias sobre una y dos medias cuando se asegura normalidad (Z test, t - Student test y Welch test), esto debido a que en la práctica estas pruebas suelen ser las más utilizadas.
2 Materiales y métodos
Delimitando el parámetro a estudiar y basados en la estimación de las probabilidades de éxito y error que presentan las técnicas de Intervalos de Confianza y Pruebas de Hipótesis, pretendemos determinar si existe evidencia para considerar una técnica mejor que otra, lo cual nos parece un criterio menos subjetivo que aquellos presentados en la sección de Introducción. La Tabla 1 muestra estas técnicas con sus correspondientes estadísticos 18, usados para estimar las probabilidades que deseamos comparar: las probabilidades deseadas son obtenidas a partir de funciones de simulación propias desarrolladas en el software estadístico R 19. Con el fin de que estas funciones, computacionalmente hablando sean lo menos pesadas posibles, se crearon funciones auxiliares propias (Anexo A), las cuales se usaron en lugar de las existentes en las librerías del software. Estas funciones auxiliares calculan los intervalos de confianza y los estadísticos que se encuentran en la Tabla 1 y se las puede visualizar de acuerdo al detalle especificado en la misma tabla.
Tabla 1 Modelos de inferencia estadística usados para estimar Probabilidades de acierto y Probabilidades de Error.

Las probabilidades de éxito y error para Intervalos de Confianza y Pruebas de hipótesis se obtuvieron a través de la función propia de simulación “onemean” (Anexo B) en el caso de una muestra y “twomean” (Anexo C) en el caso de dos muestras. En el caso de una muestra, el proceso de simulación implementado en la función “onemean” y sus argumentos se detallan a continuación: A través del comando rnorm del paquete base de R, se crea una variable aleatoria normal de tamaño n, con media mu y desviación estándar sigma. A partir de esta variable, se calculan los intervalos de confianza y los estadísticos correspondientes según sea el caso que indique el argumento var.known, esto es, inferencias cuando conocida (Z test) en el caso de que se indique un valor TRUE al argumento o inferencias cuando σ desconocida (t - Student) en el caso de tomar el valor FALSE. Cuando los argumentos mu y mu.hip (media hipotética o de comparación) son iguales, es decir la media hipotética coincide con la media poblacional que genera la muestra, las estimaciones obtenidas a partir de m = 1000000 (un millón) de réplicas de simulación, corresponden a las probabilidades de cometer un error, las cuales son calculadas en el caso de intervalos de confianza como la proporción de veces que la media hipotética está afuera de los intervalos generados (cuando en realidad debería estar adentro) y para pruebas de hipótesis como la proporción de veces que se rechaza la hipótesis nula de igualdad H0: μ = 0 (cuando en realidad, teóricamente la muestra sí se formó con esta media poblacional). Cuando los argumentos mu y mu.hip son diferentes, es decir la media hipotética es distinta a la media poblacional que genera la muestra, las estimaciones obtenidas a partir de m = 1000000 (un millón) de réplicas de simulación, corresponden a las probabilidades de acierto, las cuales son calculadas en el caso de intervalos de confianza como la proporción de veces que la media hipotética está afuera de los intervalos generados (siendo esto lo correcto) y para pruebas de hipótesis como la proporción de veces que se rechaza la hipótesis nula de igualdad H0: μ = 1 (cuando en realidad, teóricamente la muestra no se formó con esta media poblacional).
En el caso de dos muestras, el proceso de simulación implementado en la función “twomean” y sus argumentos se detallan a continuación: A través del comando rnorm del paquete base de R, se crean dos variables aleatorias normales de tamaño n1 y n2 respectivamente, estas variables tienen una diferencia teórica de medias dado por el argumento diffmean (este valor siempre será cero para asegurar igualdad poblacional de las medias comparadas, caso contrario denotaría diferencia) y un aseguramiento de la homocedasticidad dado por el argumento ratioSigma (un valor de 1 denota perfecta homocedasticidad y mientras más nos alejemos de 1 se representa una heterocedasticidad más fuerte). A partir de estas variables, se calculan los intervalos de confianza y los estadísticos correspondientes según sea el caso que indique el argumento var.known, esto es inferencias cuando σ 1 σ 2 son conocidas (Z - test) en el caso de que se indique un valor TRUE al argumento, o inferencias cuando σ 1 σ 2 son desconocidas en el caso de tomar el valor FALSE. Es importante recordar, que cuando estas desviaciones teóricas son desconocidas el uso del t - Student o del test de Welch dependerá del cumplimiento del supuesto de homocedasticidad.
Cuando los argumentos diffmean y dm.hip (diferencia de medias hipotética o de comparación) son iguales, es decir la diferencia hipotética de medias coincide con la diferencia de medias poblacionales que generan las muestras, las estimaciones obtenidas a partir de m = 1000000 (un millón) de réplicas de simulación, corresponden a las probabilidades de cometer un error, las cuales son calculadas en el caso de intervalos de confianza como la proporción de veces que la diferencia de medias hipotética está fuera de los intervalos generados o no contiene el cero (cuando en realidad debería estar dentro o contener el cero) y para pruebas de hipótesis como la proporción de veces que se rechaza la hipótesis nula H 0: μ 1 - μ 2 = 0 (cuando en realidad, teóricamente las muestras sí se formaron con estas dos medias poblacionales iguales).
Cuando los argumentos diffmean y dm.hip son diferentes, es decir la diferencia hipotética de medias es diferente a la diferencia de medias poblacionales que generan las muestra, las estimaciones obtenidas a partir de m = 1000000 (un millón) de réplicas de simulación, corresponden a las probabilidades de acierto, las cuales son calculadas en el caso de intervalos de confianza como la proporción de veces que la diferencia de medias hipotética está fuera de los intervalos generados (siendo esto lo correcto) y para pruebas de hipótesis como la proporción de veces que se rechaza la hipótesis nula H 0: μ 1 - μ 2 = 1 (cuando en realidad, teóricamente las muestras no se formaron con estas dos medias poblacionales distintas).
Finalmente, para ambas funciones principales, los argumentos alpha y seed indican respectivamente el nivel de confianza de las pruebas y la semilla utilizada con el fin de que todas las simulaciones sean replicables con los mismos resultados. Para las probabilidades de error, los valores de la media teórica y la media hipotética fueron ambas cero, mientras que para las probabilidades de acierto fueron de cero y uno respectivamente. Se obtuvieron los resultados para un nivel de significancia α = 0.05, usando tamaños muestrales de n = 5;10;15;20 para los casos de estimación de una sola media y n = (5,5);(10,10);(5,10);(10,5) cuando la estimación es sobre dos medias. Cabe recalcar que los estadísticos correspondientes en cada modelo de inferencia utilizado fueron calculados de acuerdo a cada premisa diferente sobre el conocimiento de la varianza teórica y sobre los criterios correspondientes de homocedasticidad o heterocedasticidad.
3 Resultados
En el Anexo D, se muestran los resultados completos de las estimaciones de las probabilidades de error y aciertos para todos los casos descritos. Además, se muestra en paralelo la precisión que tuvo el proceso de simulación al estimar estos parámetros, esto es el error estándar de la estimación de probabilidades a partir de proporciones. Para visualizarlo de mejor manera, estos resultados se resumen en los gráficos que se detallan a continuación.
La Figura 1 muestra que la probabilidad de error es exactamente la misma cuando se usan cualquiera de los dos métodos (Pruebas de Hipótesis o Intervalos de Confianza), independientemente del tamaño muestral y el estadístico utilizado (Z, t o Welch). La probabilidad de acierto también es la misma con cualquiera de los dos métodos, pero incrementa conforme el tamaño muestral es mayor, en este sentido aunque estudiar casos para tamaños muestrales más grandes puede resultar interesante, no tendría sentido hacerlo, puesto que ya se observa claramente lo que ocurriría, esto es, que las probabilidades de cometer un error se mantendrían relativamente controladas muy cerca del nivel de significancia planteado y las probabilidades de aciertos irían aumentando de manera asintótica hacia 1 (probabilidad límite).
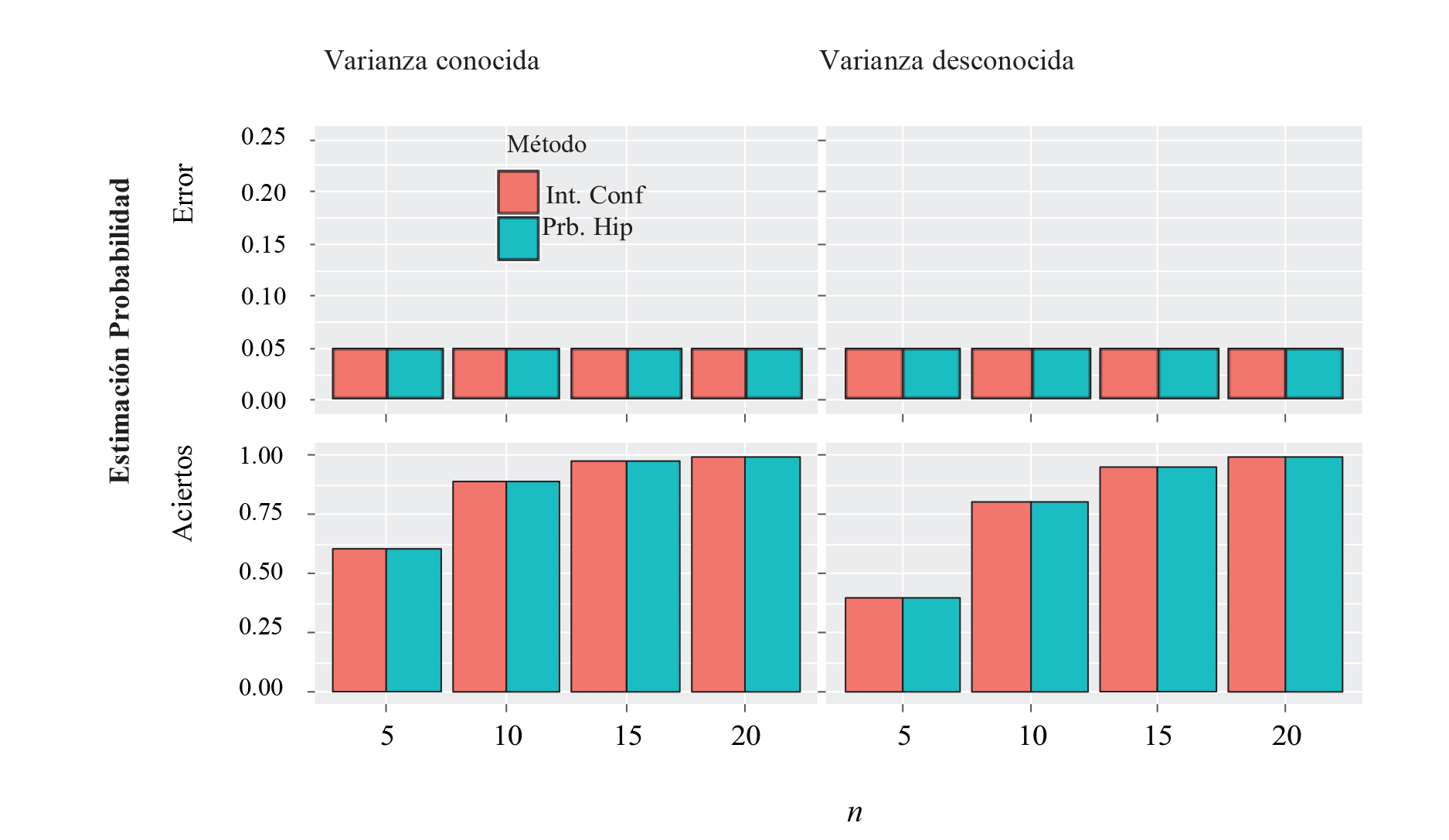
Figura 1 Estimación de Probabilidad de acierto y error para inferencias sobre una media usando α = 0.05.
La Figura 2 y la Figura 3 muestran respectivamente las probabilidades de cometer un error y un acierto cuando se estiman dos medias con la premisa de varianzas conocidas. Podemos notar que el comportamiento es similar al presentado en el caso de una media en cuanto que no se observan diferencias entre las probabilidades estimadas cuando se usan intervalos de confianza y pruebas de hipótesis. El error es siempre el mismo independientemente del tamaño muestral y el nivel de heterocedasticidad, pero la probabilidad de acertar es mayor conforme el tamaño muestral incrementa (especialmente para casos balanceados) y el nivel de heterocedasticidad es menor.
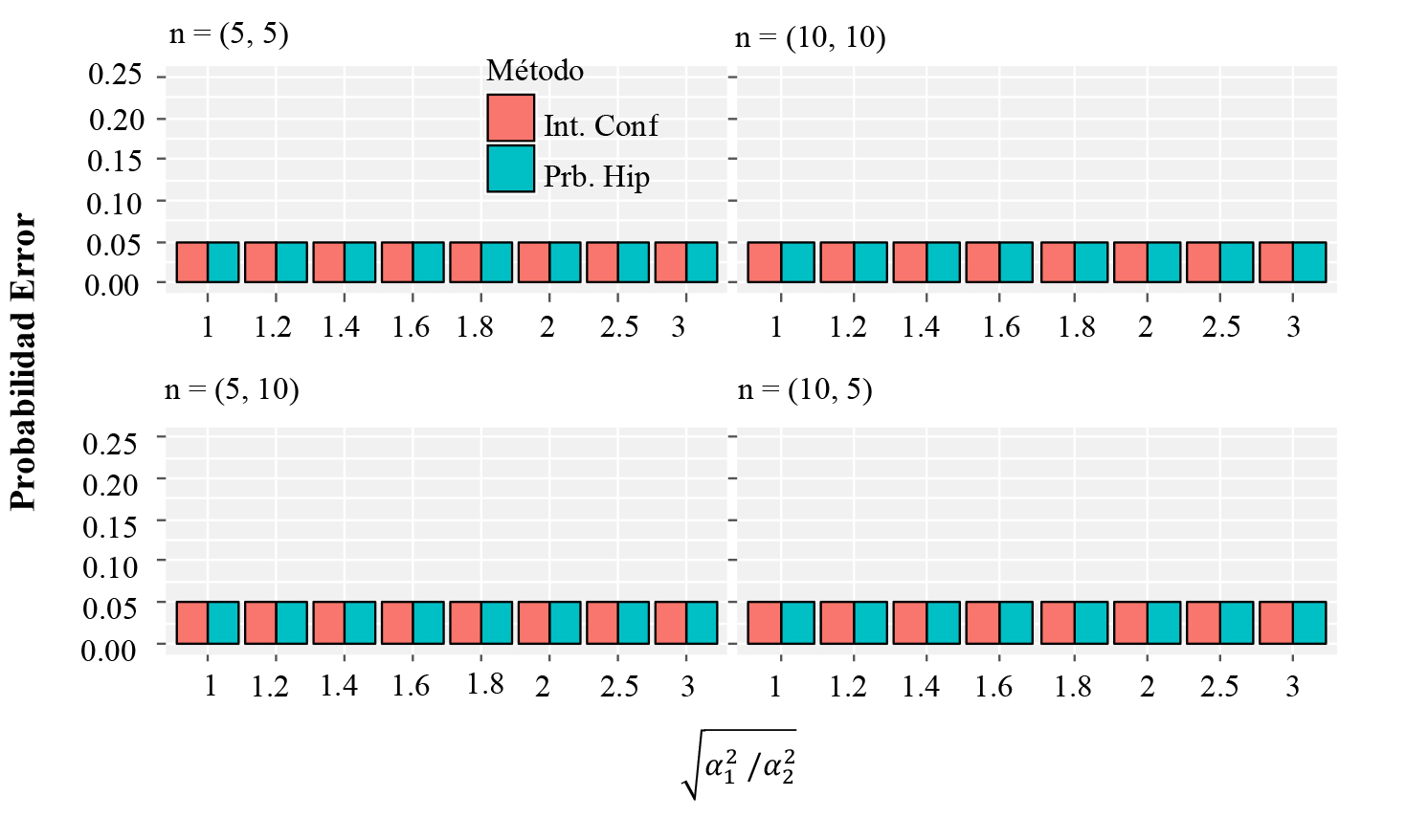
Figura 2 Estimación de Probabilidad de error para inferencias sobre dos medias cuando la varianza es conocida, usandoα=0.05.
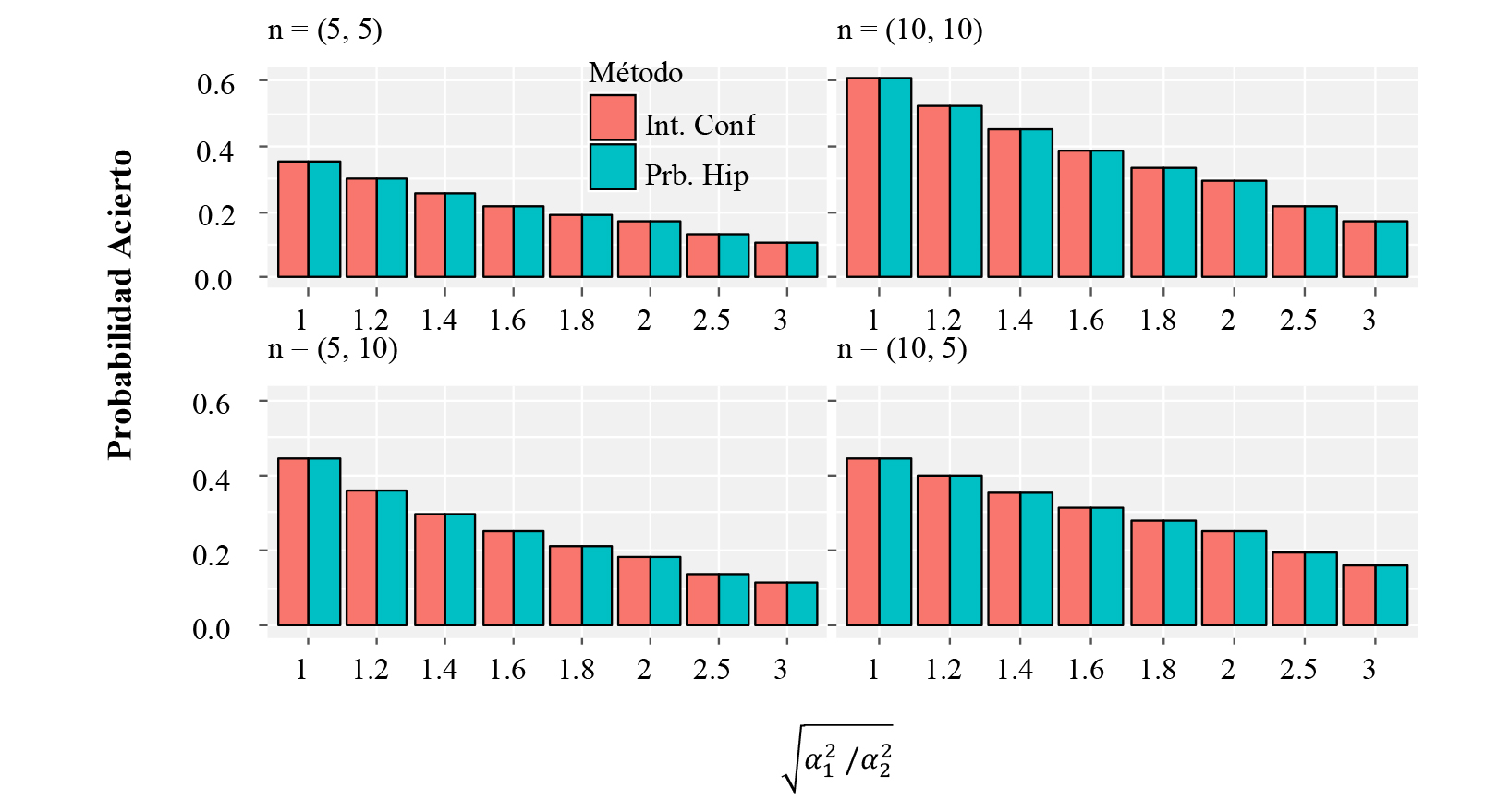
Figura 3 Estimación de Probabilidad de acierto para inferencias sobre dos medias cuando la varianza es conocida, usando α=0.05.
Conforme lo muestran la Figura 4 y la Figura 5, exactamente este mismo comportamiento se observa cuando la varianza es desconocida, aunque con una leve disminución de la probabilidad de cometer un acierto, pero con la misma dinámica que con varianzas conocidas.
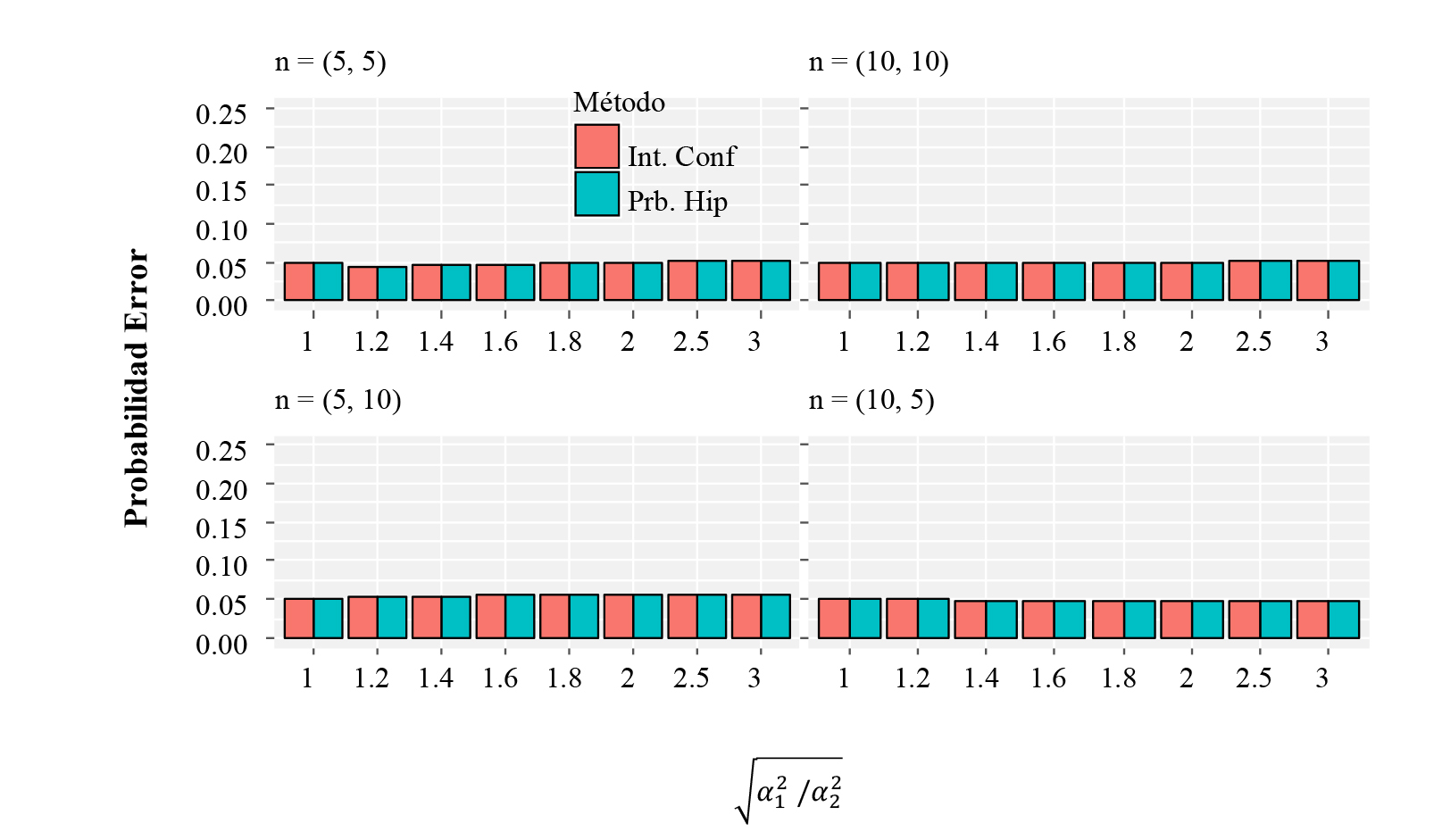
Figura 4 Estimación de Probabilidad de error para inferencias sobre dos medias cuando la varianza es desconocida, usando α = 0.05.
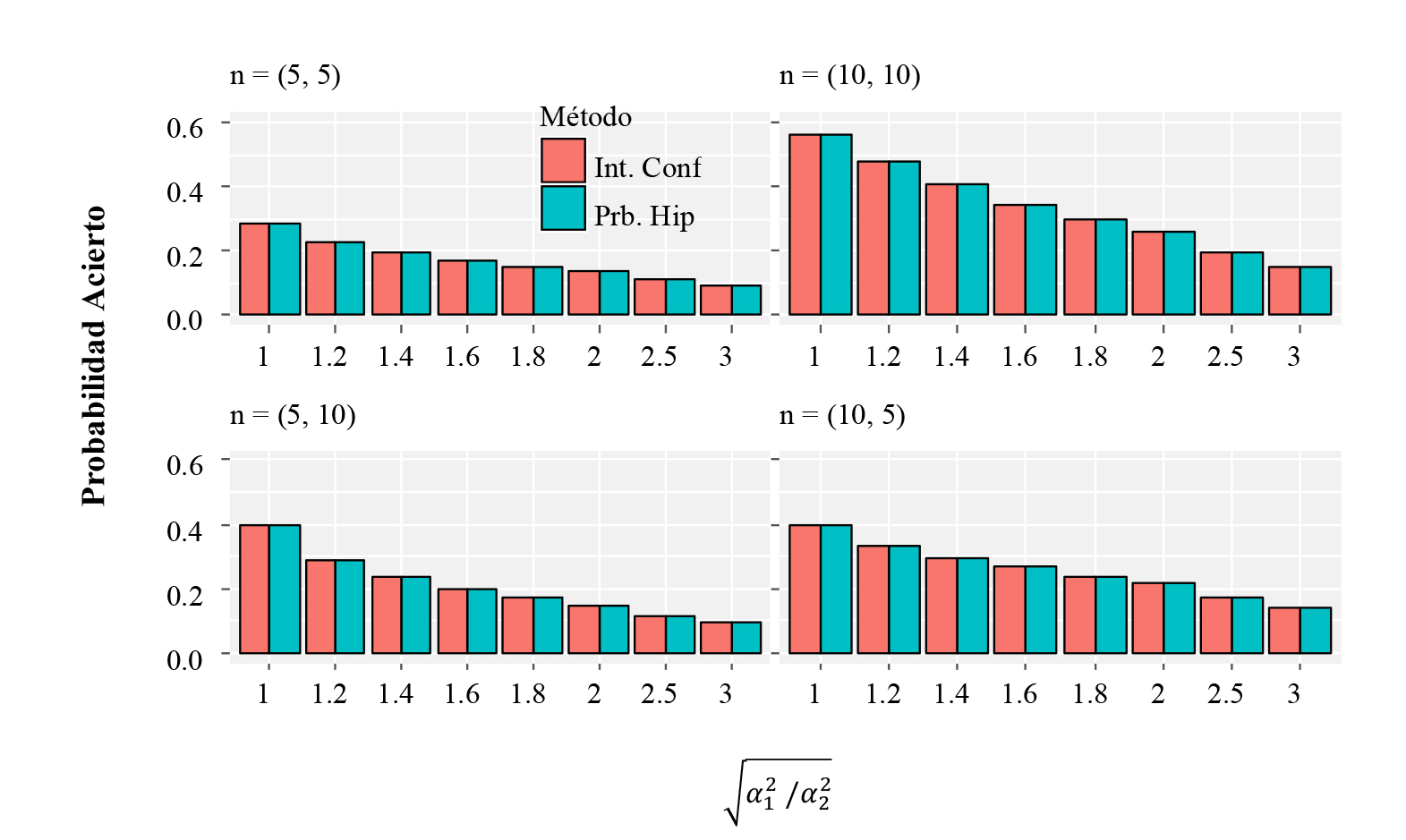
Figura 5 Estimación de Probabilidad de acierto para inferencias sobre dos medias cuando la varianza es desconocida, usando α = 0.05.
Del mismo modo que para una sola media, es un tanto predecible el comportamiento que tendrían las probabilidades estimadas cuando se usan tamaños muestrales más grandes, esto es, que en todos los casos balanceados y desbalanceados la probabilidad de error tanto para intervalos de confianza como para pruebas de hipótesis quedaría bastante controlada y cerca del nivel de significancia planteado, mientras que la probabilidad de acierto iría aumentando conforme el tamaño muestral crezca, aunque con una mayor rapidez para los casos balanceados que para los desbalanceados.
4 Conclusiones
Los resultados observados muestran claramente que sin importar el número de parámetros a compararse (uno o dos), el estadístico (Z, t o Welch), el tamaño muestral o el nivel de heterocedasticidad, no existe evidencia para concluir estadísticamente que la metodología basada en intervalos de confianza tenga una mayor probabilidad de aciertos o una menor probabilidad de cometer un error que la presentada por la metodología basada en pruebas de hipótesis. En este sentido, no podemos emitir un criterio estadístico formal que confirme que los intervalos de confianza (estadísticamente hablando) son procedimientos que superan la eficiencia de las pruebas de hipótesis en los procesos de inferencia estadística.
Si bien es cierto, como ya lo dijimos, confirmamos que los intervalos de confianza proporcionan mayor información sobre la magnitud de la diferencia estadística hallada entre tratamientos, sin embargo, los resultados de la medición de la probabilidad de acierto o error que tienen estos procedimientos muestran que ambos tienen la misma efectividad de inferencia. Concluimos que los modelos de pruebas de hipótesis no son erróneos ni menos potentes que los intervalos de confianza, lo único que ocurre es que estos tienen un incorrecto planteamiento que no permite observar la magnitud de las diferencias significativas halladas, sin embargo, creemos que un planteamiento de hipótesis basado en equivalencia proporcionará esta información requerida, la cual se puede establecer en los límites de irrelevancia que el investigador proporcione al test de hipótesis.

