










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkCuadernos de Economía
Print version ISSN 0121-4772
Cuad. Econ. vol.33 no.63 Bogotá July/Dec. 2014
https://doi.org/10.15446/cuad.econ.v33n63.45351
http://dx.doi.org/10.15446/cuad.econ.v33n63.45351
Estimación bayesiana del valor en riesgo: una aplicación para el mercado de valores colombiano
Bayesian estimation of the value of risk: an application for the colombian securities market.
Estimation bayésienne de la valeur en risque: une application pour le marché de valeurs colombien.
Estimação bayesiana do valor em risco: uma aplicação para o mercado de valores colombiano.
Charle Augusto Londoñoa
Juan Carlos Correa M.b
Mauricio Lopera C.c
a MSc, se desempeña como profesional especializado en el Departamento Administrativo de Planeación de la Alcaldía de Medellín. Medellín, Colombia. Correo electrónico: calondonoh@unal.edu.co.
b Ph.D, profesor asociado, Escuela de Estadística, Universidad Nacional de Colombia, sede Medellín. Medellín, Colombia. Correo electrónico: jccorrea@unal.edu.co.
c MSc, docente, Facultad de Ciencias Económicas, Universidad de Antioquia. Medellín, Colombia. Correo electrónico: mloperacl@gmail.com.
Los autores de este trabajo agradecen las buenas observaciones de los dos evaluadores anónimos.
Resumen
Esta investigación tiene como propósito implementar la metodología de regresión cuantil bayesiana en el cálculo del valor en riesgo (VaR, en inglés) en el mercado de valores colombiano. Para este objetivo se valoran algunos requerimientos regulatorios sobre riesgo de mercado definidos por la Superintendencia Financiera de Colombia sobre metodologías, medidas de desempeño y factores de riesgo para el cálculo del VaR, y se compara con el modelo APARCH y de regresión cuantil tradicional; se halla que la regresión cuantil tiene una mejor capacidad para adaptarse a los patrones exhibidos por un portafolio de acciones colombianas dadas varias medidas de desempeño.
Palabras clave: valor en riesgo condicional autorregresivo, regresión cuantil, estadística bayesiana, variables macroeconómicas y financieras, regulación bancaria, mercado de valores.
JEL: C14, C16, C45, E44, G28, G15.
Abstract
The purpose of this research is to implement the Bayesian quantile regression methodology in the estimation of the Value at Risk, VaR, in the colombian stock market. For this objective, some regulatory requirements on market risk are compared using the APARCH model, and traditional quantile regressions. These requirements are defined by the Colombia's Financial Superintendence where they address methodologies, performance measures and risk factors relevant to the calculation of the VaR. We found out that the later technique has a greater capacity to adapt to the patterns exhibited by a portfolio of Colombian stock given several performance measures.
Keywords: Conditional autoregressive Value at Risk, regression quantile, Bayesian statistics, macroeconomics and financial variable, banking regulation, financial market.
JEL: C14, C16, C45, E44, G28, G15
Résumé
Cet article à pour but de propulser la méthodologie de régression quantile bayésienne dans le calcul de la valeur en risque (VaR en anglais) sur le marché des valeurs colombien. Pour cela on évalue certaines réglementations sur le risque du marché définis par la Superintendencia Financiera de Colombia (Institution de contrôle fiscal et financier de Colombie) sur les méthodologies, le rendement et les facteurs à risque pour le calcul du VaR et est comparé avec le modèle APARCH et de régression quantile traditionnelle ; on trouve que la régression quantile possède une meilleure capacité pour s'adapter aux tendances d'un portefeuille d'actions colombiennes étant données plusieurs mesures de rendement.
Mots-clés: valeur en risque conditionnel autorégressif, régression quantile, statistique bayésienne, variables macroéconomiques et financières, régulation bancaire, marché de valeurs.
JEL: C14, C16, C45, E44, G28, G15.
Resumo
Este artigo tem a finalidade de implementar a metodologia de regressão quantílica bayesiana no cálculo do valor em risco (VaR, em inglês) no mercado de valores colombiano. Para isto, são avaliados alguns requerimentos regulatórios sobre risco de mercado definidos pela Superintendência Financeira da Colômbia sobre metodologias, medidas de desempenho e fatores de risco para o cálculo do VaR, e compara-se com o modelo APARCH e de regressão quantílica tradicional; vê-se que a regressão quantílica tem mais capacidade de adaptação aos padrões exibidos por um portfólio de ações colombianas, dadas várias medidas de desempenho.
Palavras-chave:Valor em risco condicional autorregressivo, regressão quantílica, estatística bayesiana, variáveis macroeconômicas e financeiras, regulação bancária, mercado de valores.
JEL: C14, C16, C45, E44, G28, G15.
Este artículo fue recibido el 26 de mayo de 2013, ajustado el 20 de julio de 2013 y su publicación aprobada el 27 de septiembre de 2013.
INTRODUCCIÓN
El crecimiento de los mercados financieros en el ámbito mundial ha mostrado la necesidad que se tiene de propender por una mejor comprensión, conocimiento y supervisión de las inversiones realizadas por bancos, sociedades administradoras de fondos de pensiones y cesantías, y comisionistas de bolsa, a razón de los mayores riesgos a los que se hallan expuestas estas instituciones. Después de la crisis financiera de 2008, se evidenciaron nuevamente los problemas internos de algunas instituciones financieras en la administración del riesgo, principalmente en la evaluación de este cuando se incurre en posiciones de activos con baja liquidez y altamente riesgosos. Por este motivo, el Basel Committee on Banking Supervision (BCBS) ha estado en un proceso de reestructuración de la regulación bancaria actual por medio de la introducción de Basilea III, cuyo objetivo es establecer los estándares sobre los requerimientos de capital que tiendan por un mayor control y cobertura ante la exposición del riesgo (BCBS, 2010).
Los requerimientos regulatorios sobre riesgo de mercado por parte de Basilea III, no se modificaron sustancialmente sobre lo que propone la Superintendencia Financiera de Colombia (SFC). Sin embargo, un cambio importante fue el adicionar ciertos criterios sobre el nivel de liquidez y bursatilidad en los activos (BCBS, 2010). En la Circular Externa 051 de 2007 se recomienda la implementación de un sistema de administración de riesgo de mercado (SARM) que identifique, mida, controle y monitoree las posiciones en valores para las instituciones financieras1, solicitando que se cumplan algunos requerimientos cuando se emplea la medida de valor en riesgo (VaR)2 definida como la máxima pérdida que se podría producir en condiciones normales del mercado a un nivel de probabilidad y en un período de tiempo especificado, como son, entre otros componentes, el uso del índice general de la Bolsa de Valores de Colombia (IGBC) como un factor de sensibilidad; medidas de desempeño que establezcan si se capturó el nivel de probabilidad preespecificado por el VaR; y aplicación de metodologías paramétricas y no paramétricas básicas (SFC, 2007).
Cuando se valoran estos requerimientos, se observan algunos problemas en lo concerniente a buscar homogéneamente mecanismos de control que posibiliten la mejor cobertura hacia el riesgo, a causa de que una mala elección y evaluación metodológica en períodos de alta probabilidad de pérdida puede ocasionar un efecto contagio para todo el sistema3. Concretamente, con relación a la exigencia del IGBC como un factor de sensibilidad mínimo, este no es eficiente en mediavarianza4, implicando una cuantificación inapropiada del riesgo, como lo muestran Fama y French (1992, 1993, 1996a, 1998) en el mercado de valores estadounidense, y Londoño y Cuan (2011) para el mercado colombiano. Asimismo, para introducir este parámetro, se utiliza la multiplicación de la sensibilidad de tal factor por el VaR calculado como la técnica de mapeo de los factores de riesgo, lo que tiene como desventaja, el no tener en cuenta la distribución y dinámica de los activos analizados al realizarse de forma externa al cálculo del VaR.
En lo referente a la evaluación de las metodologías empleadas para el cálculo del VaR, Melo y Granados (2011) muestran que es necesario diagnosticar el buen ajuste del modelo no solo observando los posibles errores en la captura del nivel de probabilidad preespecificado como lo propone la SFC, sino también que debe esclarecerse lo adecuado o no de este sobre los posibles problemas de dependencia en las fallas esperadas cuando se realiza el backtesting. Además, como lo explican Gaglianone, Lima, Linton y Smith (2011), se deben tener en cuenta medidas que sean acordes con los períodos de análisis de riesgo sugeridos por la autoridad reguladora; es decir, que permitan una evaluación que dé cuenta del desempeño del modelo condicional utilizando muestras finitas. Lo anterior puede reducir posibles problemas de riesgo moral incurridos por los administradores de riesgo que se verán obligados a emplear herramientas estadísticas que ofrezcan un adecuado control del riesgo (Lucas, 2001).
Finalmente, sobre la decisión de qué metodología utilizar para el cálculo del VaR, el grado de exigencia por la autoridad reguladora en ocasiones no es coherente con las características de los activos financieros; estos exhiben fuerte no linealidad, colas pesadas, dependencia en el tiempo, heterocedasticidad, asimetrías, entre otros. Cai y Wang (2008) señalan que una mala elección de la metodología econométrica puede generar sesgo en la estimación de los parámetros y restricciones que pueden distorsionar la distribución de los activos.
Una técnica estadística que puede superar tales problemas es la regresión cuantil bayesiana, la cual, como lo establecen Yu y Moyeed (2001), Chernozhukov y Hong (2003) y Aristodemou y Yu (2008), parte de una estructura más flexible que los modelos estadísticos tradicionales usando una distribución a posteriori, lo que permite adaptarse a los patrones exhibidos por la variable de interés; es robusta en la captura de outlier, lo cual avala una mejor adaptación a estados contingentes extremos; disminuye posibles problemas de sobre y subvaloración del riesgo, al poder recoger mejor la dinámica de los activos. Igualmente, avala una estimación de sus parámetros condicionalmente al introducir los factores de riesgo de forma directa en el cálculo del VaR (Cai y Wang, 2008).
Por tanto, esta investigación tiene como propósito implementar la metodología regresión cuantil bayesiana en el cálculo del VaR en el mercado de valores colombiano. Para este objetivo se valoran algunos requerimientos regulatorios sobre riesgo de mercado definidos por la Superintendencia Financiera de Colombia en la Circular Externa 051 de 2007, sobre metodologías, medidas de desempeño y factores de riesgo para el cálculo del VaR, donde con lo último se usan las variables de los modelos de precios de los activos para esclarecer los efectos que tienen sobre los cuantiles extremos de la distribución de un portafolio de acciones colombianas. Además, con la intención de precisar la capacidad predictiva de esta técnica, se confrontará con una de las especificaciones propuestas por Engle y Manganelli (2004) y un modelo de la familia de heterocedasticidad condicional autorregresiva generalizada (GARCH)5.
Este trabajo se divide en seis partes incluida esta introducción. En la segunda, se realiza una definición del VaR y se muestran las ventajas y desventajas de algunas metodologías; luego se presenta una justificación sobre la inclusión de los factores de riesgo directamente en el cálculo del VaR. En la tercera, se esbozan las metodologías utilizadas, donde se ilustra el modelo Asymmetric Power ARCH (APARCH), el GARCH indirecto y el de regresión cuantil bayesiana. En la cuarta, se describen algunas medidas de desempeño no condicionales, condicionales y función de pérdida. En la quinta, se muestran los datos y los resultados sobre desempeño de las metodologías. Por último, se dan unas conclusiones, donde se encuentra que los modelos estimados con regresión cuantil presentan buenos resultados en la captura del riesgo.
CONSIDERACIONES PARA EL CÁLCULO DEL VaR
Valor en riesgo: una revisión metodológica
Un tema de gran interés en finanzas es la determinación de cómo los bancos, las sociedades de pensiones y de cesantías y firmas comisionistas, entre otras, se cubren ante la exposición al riesgo de mercado, ya que la competencia en la captación de recursos y obtención de mejores ganancias les ha exigido incurrir en mayores riesgos en este segmento de su negocio. Estas usan diferentes instrumentos financieros, tales como mecanismos avanzados de inversión y cobertura como los derivados (forward, futuros, opciones y swaps), y activos tradicionales como bonos, acciones, monedas y commodities (Londoño, 2011).
Una herramienta ampliamente utilizada a escala mundial para cuantificar el riesgo de mercado es el VaR, el cual permite (Alexander, 2008):
1) Determinar la cantidad de dinero que se puede perder con una probabilidad dada en un período de tiempo.
2) Medir los riesgos de los factores asociados a estos a través de sus sensibilidades.
3) Comparaciones en diferentes mercados y exposiciones.
4) Ofrecer una medida estándar para cualquier tipo de exposición al riesgo en las distintas líneas de negocio que tiene una institución financiera como un todo.
5) Puede calcularse el VaR utilizando un portafolio de activos o para un(os) activo(s) individual(es) que luego se pueden agregar.
Las condiciones que cumple esta son las siguientes: la monotonicidad (si se tienen dos portafolios hipotéticos X y Y , y Y tiene al menos un mayor rendimiento que X [ X ≤Y ], implica que X tenga un riesgo menor o igual que Y), la homogeneidad (el riesgo es proporcional a la escala del portafolio) y una condición libre de riesgo (adicionar un instrumento libre de riesgo en el portafolio disminuye el riesgo en su proporción invertida). En contraposición, no satisface la condición de subaditividad, la cual implica que cuando se evalúa el riesgo de un portafolio de activos su valor debería de ser menor o igual a cuando se hace la suma de estos activos (Gaglianone et al., 2011). No obstante, Gaglianone et al. (2011) argumentan que para variables aleatorias continuas se puede satisfacer esta última condición, siempre y cuando el primer momento distribucional exista, aunque advierten que para colas pesadas superiores a la distribución Cauchy esta propiedad no se satisface.
Definición del VaR
Formalmente el VaR de un portafolio de activos se puede definir como 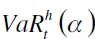 , donde α ∈ (0,1) es su nivel de significancia y h es el horizonte de tenencia máxima de un portafolio riesgoso que se encuentra entre [t, t+h) . Ahora, si rt denota el retorno de un activo o portafolio en el período t y l es el nivel de retorno con función de distribución acumulada (FDA) Frt (l) , esta medida es establecida como
, donde α ∈ (0,1) es su nivel de significancia y h es el horizonte de tenencia máxima de un portafolio riesgoso que se encuentra entre [t, t+h) . Ahora, si rt denota el retorno de un activo o portafolio en el período t y l es el nivel de retorno con función de distribución acumulada (FDA) Frt (l) , esta medida es establecida como
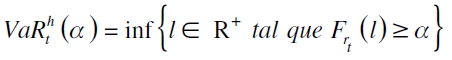 | [1] |
donde 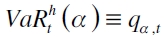 , (Diagne, 2002). De acuerdo con la SFC (2007), el nivel de significancia α recomendado es del 1% , aunque se sugieren otras probabilidades para mostrar lo adecuado del modelo. Para el período máximo de tenencia h se establece que sea de diez días de vigencia del VaR, donde es preciso reescalar el VaR por medio de la regla de la raíz, que consiste en la multiplicación del VaR diario por la raíz de 10
, (Diagne, 2002). De acuerdo con la SFC (2007), el nivel de significancia α recomendado es del 1% , aunque se sugieren otras probabilidades para mostrar lo adecuado del modelo. Para el período máximo de tenencia h se establece que sea de diez días de vigencia del VaR, donde es preciso reescalar el VaR por medio de la regla de la raíz, que consiste en la multiplicación del VaR diario por la raíz de 10 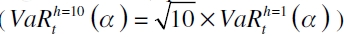 .
.
No obstante, Fedor (2010) y Leiton (2011) señalan que este procedimiento no es adecuado para la explicación correcta del comportamiento de las series financieras, debido a que no satisfacen cabalmente los supuestos del movimiento browniano (continuidad, independencia, estacionaridad y distribución normal). Igualmente, Melo y Granados (2011) muestran que el reescalamiento para el cálculo del VaR genera una sobrestimación del riesgo usando diferentes medidas de desempeño.
Para solventar este inconveniente, McNeil y Frey (2000) sugieren el uso de Power Law Scale Exponents, que consiste en un escalamiento en el VaR de la forma 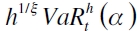 , siendo ξ estable en toda la distribución de la variable bajo análisis y se define como
, siendo ξ estable en toda la distribución de la variable bajo análisis y se define como
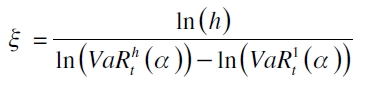
donde 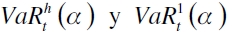 son los VaR empíricos para el pronóstico h y 1 pasos adelante. Por su parte, Kavussanos y Dimitrakopoulos (2011) proponen la ley de escalamiento empírico, donde la fórmula queda como
son los VaR empíricos para el pronóstico h y 1 pasos adelante. Por su parte, Kavussanos y Dimitrakopoulos (2011) proponen la ley de escalamiento empírico, donde la fórmula queda como 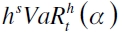 , estando s definido por
, estando s definido por
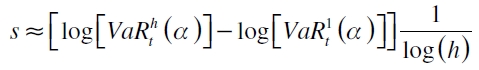
Observando la ecuación precedente, se puede intuir que dicho escalamiento varía con cada ventana de datos que es introducida, indicando un comportamiento tiempo-variante.
De estas dos propuestas, se observa una mejora en el escalamiento del VaR tradicional, pero siguen habiendo ciertos problemas, al no representarse los verdaderos cuantiles teóricos a los que se desea llegar, al requerirse una muestra representativa, estabilidad en el tiempo y que el proceso distribucional a modelar sea independiente e idénticamente distribuido (i.i.d.). Por lo anterior, esta investigación empleará un VaR diario sin hacer ningún escalamiento con el propósito de observar si la técnica por sí sola puede ofrecer los resultados esperados en la captura del cuantil. Como detalles adicionales, para el backtesting, de acuerdo con la regulación, debe contar con 250 días de predicción utilizando un modelo estimado con datos diarios que deben ser actualizados cada trimestre.
Lo precedente son algunos requisitos cuantitativos para el cálculo del VaR estipulados en el parágrafo 5.2.2.1 de la Circular Externa 051 de 2007. Otros detalles de cobertura del riesgo son el análisis de correlaciones entre activos, los requerimientos de capital y el factor multiplicativo. Estos temas no serán abordados, pero pueden ser consultados en Melo y Granados (2011).
Metodologías empleadas para el cálculo del VaR
De la ecuación (1) se puede observar que esta medida es una herramienta intuitiva para modelar el riesgo. Sin embargo, su implementación es un problema estadístico cambiante al diferir en sus supuestos (Engle y Manganelli, 2004). Por este motivo, en la literatura se han empleado diferentes metodologías para el cálculo del VaR. En Colombia, Melo y Granados (2011) estudian la idoneidad de la regulación colombiana utilizando simulación histórica, RiskMetrics, modelos ARMA-GARCH, simulación histórica filtrada, entre otras. Gallón y Gómez (2007) emplean GARCH multivariados para capturar la interrelación de diferentes monedas. Giraldo (2005) combina el filtro de Kalman y modelos GARCH para cuantificar el riesgo.
Estas metodologías muestran ciertas ventajas y desventajas en su implementación en el cálculo del VaR. La simulación histórica calcula el VaR por medio de la distribución empírica de los retornos históricos, utilizando un intervalo de datos ordenados de forma ascendente para encontrar aquellos que exceden el nivel de confianza 1-α. Aquí, este intervalo debe ser actualizado para cada período de tiempo h adelante (Alexander, 2008; Engle y Manganelli, 2001).
Esta metodología tiene la ventaja de no requerir una distribución paramétrica específica. Pero debe asumirse que los intervalos de datos seleccionados no cambian en términos distribucionales, lo que se satisface si todas las variaciones futuras han sido experimentadas en el pasado, haciendo conocida la distribución h períodos adelante, lo que implica varios problemas en la cuantificación adecuada del riesgo al no ser los retornos distribuidos i.i.d. en el tiempo y al excluirse cambios de régimen (períodos de crisis) que son propios de los mercados financieros (Engle y Manganelli, 2001).
Por su parte, el modelo GARCH propuesto por Bollerslev (1986) busca caracterizar la ecuación de la media y la varianza del proceso distribucional y explicar la volatilidad de los retornos de los activos de manera tiempo-variante. De acuerdo con esto, el modelo presenta varias ventajas: a) Captura períodos de baja y alta volatilidad exhibidos por las series financieras, b) No solo modela el primero y segundo momento distribucional, sino también momentos más altos, como es el coeficiente de asimetría y la curtosis (McNeil y Frey, 2000) y c) Esta técnica se encuentra estrechamente relacionada a la especificación de RiskMetrics TM desarrollada por J. P. Morgan, que es una medida estándar para la administración del riesgo de mercado.
Los problemas que presenta esta técnica son el requerir que los residuales estandarizados sean i.i.d. cuando las variables financieras no exhiben ese comportamiento (Engle y Manganelli, 2004). Suponer que la distribución de los errores es invariante en todo el período de evaluación de la serie, descarta posibles cambios distribucionales que produzcan errores en el pronóstico de la volatilidad y la elección en la distribución usada (Taylor, 2005).
La simulación histórica filtrada al fusionar la simulación histórica y RiskMetrics permite el uso de un decaimiento pesado exponencialmente de los retornos pasados combinado con un factor de innovación como es la volatilidad. Su construcción se lleva a cabo en tres pasos: primero, se deben asociar los K retornos más recientes de un portafolio, rt ,rt-1, ,rt-K+1 , con sus respectivos pesos, 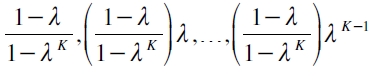 . Segundo, se organizan los retornos en forma ascendente. Tercero, se suman los correspondientes pesos para deducir el VaR del portafolio con un nivel de significancia a, que se haya tomado como punto inicial el retorno más bajo (Engle y Manganelli, 2001; Pritsker, 2006).
. Segundo, se organizan los retornos en forma ascendente. Tercero, se suman los correspondientes pesos para deducir el VaR del portafolio con un nivel de significancia a, que se haya tomado como punto inicial el retorno más bajo (Engle y Manganelli, 2001; Pritsker, 2006).
Aunque esta metodología presenta un progreso con relación a la simulación histórica, tiene la desventaja de suponer una matriz de correlaciones constante en el tiempo, lo que no se satisface en datos de series de tiempo financieras largas que pueden exhibir diferentes cambios de régimen que pueden replantear los resultados de esta matriz. Una alternativa para evitar este inconveniente, es recurrir al uso de un intervalo de datos pequeño que haga posible que la matriz de correlaciones cumpla este supuesto. No obstante, provoca que la precisión en la estimación de la distribución empírica de los errores se reduzca y produzca un problema de submuestreo y sobremuestreo que no permiten una inferencia precisa en la evaluación del riesgo (Pritsker, 2006).
En el caso internacional, una metodología que presenta resultados satisfactorios en el cálculo del VaR, es la regresión cuantil introducida por Koenker y Bassett (1978). Un modelo que popularizó esta técnica aplicada a la administración del riesgo fue el valor en riesgo condicional autorregresivo (CAViaR)6 propuesto por Engle y Manganelli (1999, 2001, 2004). Su forma general
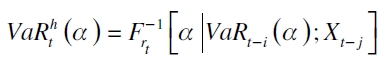 | [2] |
con 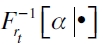 denotando la función cuantil condicional de un activo o portafolio de activos rt (Chernozhukov y Umantsev, 2001);
denotando la función cuantil condicional de un activo o portafolio de activos rt (Chernozhukov y Umantsev, 2001); 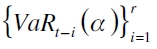 es el vector del α -ésimo cuantil rezagado y
es el vector del α -ésimo cuantil rezagado y 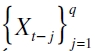 es una matriz de variables explicativas tanto de factores de riesgo endógenos y exógenos rezagados.
es una matriz de variables explicativas tanto de factores de riesgo endógenos y exógenos rezagados.
Estos autores para corroborar su superioridad predictiva, realizan una comparación con metodologías paramétricas (RiskMetricsTM y GARCH), semiparamétricas (modelos de portafolio como simulación histórica e híbridos) y no paramétricas (la EVT, el CAViaR y un modelo GARCH) y empleando como variables dependientes diferentes distribuciones simuladas por Monte Carlo y un conjunto de acciones estadounidenses, encuentran resultados sobresalientes para el cálculo del VaR cuando las distribuciones a modelar exhiben colas pesadas. A partir de esta aplicación, se han elaborado otros trabajos cuyo propósito es mostrar cómo se desempeña esta técnica bajo diferentes modificaciones metodológicas y condiciones de análisis.
Por la parte bayesiana, Chernozhukov y Hong (2003) realizan una justificación teórico-empírica del estimador tipo Laplace o quasi-bayesiano, calculado con el método Markov Chain Monte Carlo (MCMC) en la solución de diferentes problemas econométricos. Esto les permite deducir la media y los cuantiles de la distribución cuasi-posteriori, una descripción completa de la función objetivo, evaluación simultánea de puntos de estimación e intervalos de confianza, incorporación de la distribución a priori e imposición de restricciones sobre los parámetros. Para comprobar las buenas propiedades de esta metodología, realizan una aplicación para el cálculo del VaR utilizando fundamentales macroeconómicos -tasas de interés, tipo de cambio, inflación, entre otros- como variables explicativas sobre el retorno de una acción de petróleos inscrita en el New York Stock Exchange (NYSE), encontrando que esta técnica puede ser una buena alternativa para la medición del riesgo.
Aristodemou y Yu (2008) evalúan la capacidad predictiva de un modelo de regresión cuantil no paramétrico bayesiano bajo la estructura CAViaR. Para este propósito determinan la distribución conjunta estándar por medio del algoritmo MCMC, lo que posibilita la captura de un factor de incertidumbre esbozado en la distribución a posteriori cuando se hace la predicción. Para evaluar el desempeño de este método, hacen un ejercicio de simulación de Monte Carlo y una aplicación con datos reales para el índice NASDAQ Composite, que los lleva a resultados apropiados en sus parámetros cuando se compara con un modelo de regresión cuantil semiparamétrico.
Wang y Song (2008) buscando capturar los impactos asimétricos de los retornos rezagados y sus respectivos cuantiles, proponen un esquema bayesiano nombrado como TARCH-CAViaR indirecto para calcular los parámetros de la distribución a posteriori, usando el método MCMC. A partir de este modelo realizan una aplicación para el índice Changhai Composite, obteniendo resultados satisfactorios en el cálculo del VaR.
Evaluación del requerimiento regulatorio de las sensibilidades de un portafolio de activos
La regulación colombiana propone utilizar una técnica de mapeo de las sensibilidades para introducir el factor de riesgo sistemático más relevante en la valoración de activos, que consiste en estimar el parámetro de sensibilidad del portafolio del factor de riesgo para luego ser insertado en el cálculo del VaR. En los Anexos 1 y 2 que se hallan en la Circular Externa 051 de 2007 parágrafo 2.1.4.1 y 1.4, respectivamente, de acuerdo con lo estipulado en el capítulo 21 parágrafo 5.2.2, se sugiere que para el caso de la cuantificación del riesgo accionario, se debe multiplicar el VaR por el monto a negociar ajustado lo último por el valor del parámetro b de mercado como medida de sensibilidad del portafolio, el cual es la pendiente de la regresión de un activo particular contra un índice de mercado, el valor definido por la SFC es del 14,7%. Concretamente, esta técnica funciona de la siguiente manera: si se define el Equity VaR como la cantidad de dinero invertido ajustado por la sensibilidad y multiplicada por el VaR, se establece
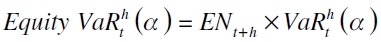 | [1] |
donde ENt+h es el valor absoluto de la exposición neta de posiciones atadas al factor de riesgo. De la ecuación (3), la técnica de mapeo de las sensibilidades factoriales permite una captura eficiente de la tenencia de estos activos, posibilita calcular un valor estándar para todos las acciones contenidas en un portafolio grande y provee una estructura definida para la toma de decisiones en el proceso de administración del riesgo (Alexander, 2008).
No obstante, presenta ciertas desventajas cuando se evalúa el riesgo: una, al tomarse el valor de este parámetro de forma estática, no se está recogiendo la dinámica de los activos que son influenciados por el mercado y la economía en el tiempo. Otra, no se consideran errores en la estimación de los parámetros cuando los supuestos distribucionales no se satisfacen; además que podrían generarse posibles sesgos por omisión de variables en la estimación. Finalmente, cuando se definen diferentes posiciones, hay una interacción entre estos y sus factores de sensibilidad que están en función de varias variables y de su distribución subyacente, generándose una caracterización incompleta utilizando tal sensibilidad (Alexander, 2008, pp. 26-27; Fedor, 2010, pp. 191-192).
De las desventajas mencionadas, se puede deducir que la técnica de mapeo de los factores de riesgo determinada por la SFC no necesariamente está haciendo una cuantificación completa del riesgo, ya que puede subvalorar o sobrevalorar este por no tener una adaptación dinámica en el cálculo del VaR y, como consecuencia, puede ocasionar pérdidas a una institución financiera. Cai y Wang (2008) muestran que para que una herramienta de administración del riesgo sea adecuada, es necesario que esta pueda adaptarse a las condiciones del mercado de una manera dinámica.
Una estrategia que se propone es la de introducir factores de riesgo que puedan afectar un portafolio de acciones de manera directa en el cálculo del VaR. Los argumentos esgrimidos por los modelos de precios de los activos fusionados con la técnica de regresión cuantil bayesiana, pueden solventar estas desventajas sin modificar las fortalezas de la técnica de mapeo. Aquí, varios esquemas de valoración pueden ser relevantes, siendo el modelo de precios de activos de capital (CAPM)7 de Sharpe (1964) y la teoría de precios de arbitraje (APT)8 de Ross (1976), dos esquemas teóricos predominantes. El primero determina que el riesgo de un activo o portafolio puede ser explicado por un índice de mercado. El segundo, establece que el riesgo es cuantificado por medio de variables de carácter macroeconómico (Londoño, 2011; Londoño y Cuan, 2011).
Los resultados que proporcionan estos modelos son bajo condiciones de equilibrio general, implicando que los hechos que ocasionaron las divergencias en el corto plazo no sean totalmente explicadas por tales esquemas, generándose una desventaja en el cálculo del VaR al no recoger completamente diferentes anormalidades que se presentan en dichos mercados, como son el riesgo relativo referente al pánico financiero, que explica, cómo la información que se produce en los estados financieros de las compañías hace que los inversionistas modifiquen su tenencia de activos ante estados contingentes de la economía; la covariación de pequeñas y grandes firmas, que evalúa la interacción de los riesgos entre invertir en firmas de diferentes tamaños; la reversión de largo plazo del retorno de los activos, esta muestra cómo el retorno de los activos tiene un impacto de reversión en su rentabilidad, pasando de períodos de ganancias a pérdidas, y viceversa; la explicación de la continuidad de los retornos en el corto plazo (Fama y French, 1996a; Londoño y Cuan, 2011; Wu, 2002).
Un modelo que puede capturar estas irregularidades es el de Fama y French (1992, 1993, 1996a, 1998), el cual parte de un enfoque microeconómico que explica el comportamiento del retorno de los activos a través de variables internas de la empresa, como son el tamaño de la firma definida como la capitalización bursátil (ME) y el valor en libros a valor de mercado (book-to-market ratio) (BE/ME), al igual que el índice de mercado inscrito en el modelo de Sharpe (1964). Con los dos primeros indicadores se construyen dos portafolios de acciones: el primero es la diferencia del más pequeño menos el más grande ME (SMB)9, y el segundo es la resta entre el más alto y más bajo BE / ME (HML)10. Bajo el esquema de regresión cuantil el modelo es
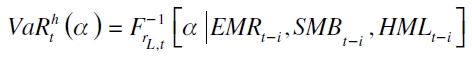 | [4] |
siendo 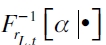 la función del cuantil condicional al retorno del activo L en el período t( rL,t ) del α-ésimo cuantil; EMRt-i es el retorno del portafolio de mercado en t-i; SMBt-i es el retorno de un portafolio que representa el efecto tamaño en t-i ; HMLt-i es un portafolio réplica del retorno de los activos que explica el riesgo relativo a la firma en t-i, siendo una prima de valor que determina cuánto puede ganar un inversionista por invertir en una empresa con BE/ME alto.
la función del cuantil condicional al retorno del activo L en el período t( rL,t ) del α-ésimo cuantil; EMRt-i es el retorno del portafolio de mercado en t-i; SMBt-i es el retorno de un portafolio que representa el efecto tamaño en t-i ; HMLt-i es un portafolio réplica del retorno de los activos que explica el riesgo relativo a la firma en t-i, siendo una prima de valor que determina cuánto puede ganar un inversionista por invertir en una empresa con BE/ME alto.
Una extensa literatura empírica muestra la superioridad predictiva de este enfoque con relación a otros modelos de precios de los activos (véanse: Ali, Hwang y Trombley, 2003; Cao, Leggio y Schniederjans, 2005; Connor y Linton, 2007; Lewellen, 1999; Tai, 2003; Wu, 2002). Para una descripción detallada de tales trabajos y críticas suscitadas en torno al modelo CAPM y APT, véanse a Londoño y Cuan (2011).
De la ecuación (4) se puede observar que esta se enfoca en la valoración del riesgo de mercado de un portafolio de acciones o acción individual. Pero es posible la agregación de otro tipo de activos, como pueden ser los títulos de deuda pública (TES) y bonos corporativos, adicionando otros factores de riesgo en el modelo (véanse a Fama y French, 1993, para los detalles).
METODOLOGÍAS
Modelo Asymmetric Power ARCH
Una técnica que tiene gran relevancia en la modelación del retorno de los activos y consecuentes medidas de riesgo, es el APARCH. Esta anida siete especificaciones de los modelos de la familia GARCH y muestra una mejor capacidad explicativa de las características exhibidas por las series financieras, al poder capturar patrones especiales de autocorrelación de manera no lineal (Ding, Granger y Engle, 1993; Giot y Laurent, 2003).
Si rt es el retorno de un portafolio de activos, el modelo APARCH (1,1) es expresado como
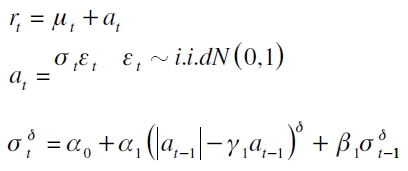 | [5] |
siendo μt la modelación de la media, que puede ser una especificación tipo ARMA; εt es el término de error; at es generado por un APARCH (1,1); σt es la desviación estándar condicional; 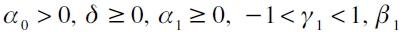 son los parámetros desconocidos. Donde, δ permite la transformación tipo Box-Cox de σt , posibilitando el uso de otras especificaciones no lineales; γ1 hace que prevalezca la propiedad del efecto leverage por medio de la respuesta asimétrica de la volatilidad, que se traduce en que malas noticias vienen acompañadas de alta volatilidad en los retornos, y viceversa, y puede explicarse por la correlación que existe entre el retorno de los activos con la volatilidad (Ding et al., 1993; Giot y Laurent, 2003).
son los parámetros desconocidos. Donde, δ permite la transformación tipo Box-Cox de σt , posibilitando el uso de otras especificaciones no lineales; γ1 hace que prevalezca la propiedad del efecto leverage por medio de la respuesta asimétrica de la volatilidad, que se traduce en que malas noticias vienen acompañadas de alta volatilidad en los retornos, y viceversa, y puede explicarse por la correlación que existe entre el retorno de los activos con la volatilidad (Ding et al., 1993; Giot y Laurent, 2003).
Giot y Laurent (2003) han encontrado evidencia de que la especificación en la ecuación (5) no es óptima, al no tener en cuenta la condición de colas pesadas exhibidas por la distribución de los retornos. Para solventar este problema, un Student APARCH es propuesto, pasando  . Por tanto, el cálculo del VaR sería expresado por
. Por tanto, el cálculo del VaR sería expresado por 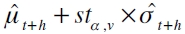 , con stα,v el cuantil α de la distribución t-student con v grados de libertad11.
, con stα,v el cuantil α de la distribución t-student con v grados de libertad11.
Regresión cuantil
Modelo CAViaR
Si rt es el retorno de un portafolio de activos, y xt es el conjunto de variables explicativas, el modelo CAViaR es expresado como
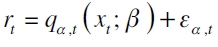 | [6] |
siendo εα,t el término de error (que se asume distribuye igual a cero en su valor esperado) en el α-ésimo cuantil en el período t con distribución fα(·) , 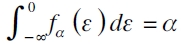 (Aristodemou y Yu, 2008; Taddy y Kottas, 2010), y
(Aristodemou y Yu, 2008; Taddy y Kottas, 2010), y
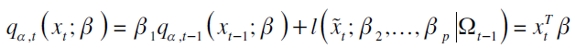
es el α-ésimo cuantil en el período t, donde 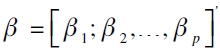 es el vector de parámetros y
es el vector de parámetros y 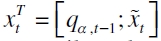 es la matriz de variables explicativas que contiene el α-ésimo cuantil en el período t-1. La expresión
es la matriz de variables explicativas que contiene el α-ésimo cuantil en el período t-1. La expresión 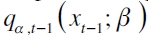 corresponde al α-ésimo cuantil rezagado un período que permite que el cuantil cambie suavemente en el tiempo; sin embargo, no es un requerimiento indispensable para la buena captura del riesgo (Londoño, 2011). Y
corresponde al α-ésimo cuantil rezagado un período que permite que el cuantil cambie suavemente en el tiempo; sin embargo, no es un requerimiento indispensable para la buena captura del riesgo (Londoño, 2011). Y 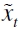 son la variables explicativas introducidas en la función
son la variables explicativas introducidas en la función 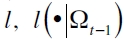 , la cual puede tomar en consideración variables económicas y formas funcionales condicionado al grupo de información Ωt-1; entre ellas se halla el esquema de Fama y French (1992) -descrito en la sección anterior- y la especificación del modelo GARCH indirecto (Engle y Manganelli, 2004) dada por
, la cual puede tomar en consideración variables económicas y formas funcionales condicionado al grupo de información Ωt-1; entre ellas se halla el esquema de Fama y French (1992) -descrito en la sección anterior- y la especificación del modelo GARCH indirecto (Engle y Manganelli, 2004) dada por
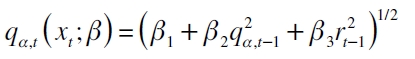 | [7] |
Ambos esquemas se utilizarán en este trabajo. Los valores estimados de los parámetros del modelo se obtienen minimizando
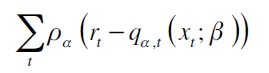 > > | [8] |
siendo ρα la función de pérdida definida como
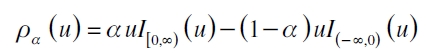 > > | [9] |
con I[a,b) (u) una variable indicadora en [a,b) (Aristodemou y Yu, 2008; Yu y Moyeed, 2001).
Regresión cuantil bayesiana
Recientemente, se propuso un método alternativo de estimación del modelo CAViaR a través de regresión cuantil bayesiana, que tiene como característica diferente a los modelos estadísticos tradicionales el utilizar el algoritmo MCMC para determinar sus parámetros; posibilita una mejor descripción del problema que se está evaluando al poder caracterizar toda la distribución de los parámetros y permite resolver problemas de carácter estadístico de gran complejidad (Aristodemou y Yu, 2008; Chernozhukov y Hong, 2003; Wang y Song, 2008; Yu y Moyeed, 2001).
Aristodemou y Yu (2008) muestran que la minimización de la ecuación (8) es equivalente a la maximización realizada con la función de verosimilitud combinada con la densidad de Laplace asimétrica. Esta distribución es empleada en el modelo de regresión cuantil bayesiana para el cálculo del VaR, gracias a que con este tipo de función se pueden resolver problemas de estimadores extremos. Asimismo, ofrece una estimación eficiente sin tener que incurrir en altos costos computacionales (Aristodemou y Yu, 2008; Chernozhukov y Hong, 2003; Wang y Song, 2008).
Para realizar inferencia sobre q t xt , ( ; ) se deben satisfacer dos supuestos ligados a como se estiman los parámetros de los modelos lineales generalizados (Yu y Moyeed, 2001):
1) La distribuciónsigue la forma de una Laplace asimétrica con función de densidad de probabilidad
, donde
denota el parámetro de escala.
2) Para alguna función enlace g conocida,.
Para estimar los valores de los parámetros de la ecuación (6), es necesario establecer una distribución a posteriori para βb dados los retornos. Si π(β) es la distribución a priori de β, la distribución a posteriori estará definida por
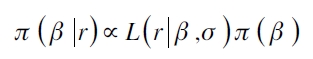 | [10] |
con función de verosimilitud
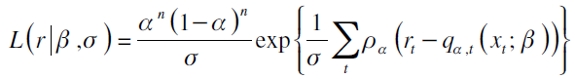 | [11] |
Es posible extraer los parámetros desconocidos de la ecuación (10) vía el algoritmo MCMC que una vez ha convergido permite hacer un muestreo de 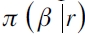 . Específicamente, el algoritmo es un método probabilístico de maximización en el que son trazados los valores de β de una manera secuencial, es decir, si βi para i = 1, 2,... denota los posibles valores que toma β, entonces la secuencia va actualizándose a sus valores más recientes, los trazos son realizados desde una cadena de Markov, la cual se mueve en las zonas de alta densidad, pero también en las colas si el muestreo es lo suficientemente largo. El éxito del procedimiento no es su propiedad de Markov en el cálculo de los parámetros, sino en su manera de aproximar la distribución en cada paso de la simulación (Aristodemou y Yu, 2008; Gelman, Carlin, Stern y Rubin, 2004; Yu y Moyeed, 2001).
. Específicamente, el algoritmo es un método probabilístico de maximización en el que son trazados los valores de β de una manera secuencial, es decir, si βi para i = 1, 2,... denota los posibles valores que toma β, entonces la secuencia va actualizándose a sus valores más recientes, los trazos son realizados desde una cadena de Markov, la cual se mueve en las zonas de alta densidad, pero también en las colas si el muestreo es lo suficientemente largo. El éxito del procedimiento no es su propiedad de Markov en el cálculo de los parámetros, sino en su manera de aproximar la distribución en cada paso de la simulación (Aristodemou y Yu, 2008; Gelman, Carlin, Stern y Rubin, 2004; Yu y Moyeed, 2001).
Yu y Moyeed (2001) muestran que es difícil poder conocer cuál podría ser una buena distribución a priori para β, ya que no existe suficiente información para establecer una que permita explicar apropiadamente el proceso generador de los datos. Los autores proponen utilizar la distribución uniforme, una distribución a priori impropia, pero que puede proporcionar una distribución a posteriori propia.
Para corroborar este resultado, se debe establecer que la verosimilitud definida en la ecuación (11), aunque no sea continua en todos los reales, puede ser integrable en Riemman (Aristodemou y Yu, 2008). Por tanto, para que se satisfaga la correcta especificación de la distribución a posteriori se debe cumplir que
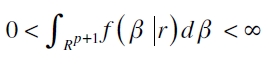
Yu y Moyeed (2001) y Aristodemou y Yu (2008) enuncian y prueban el siguiente teorema que da las herramientas necesarias para probar la condición anterior:
Teorema 1. Suponga que la distribución a priori para β es impropia y uniforme, es decir, π(β)α 1, entonces todos los momentos de la distribución a posteriori existen.
PRUEBAS DE DESEMPEÑO (BACKTESTING)
La selección del modelo interno para administrar el riesgo de mercado por una institución financiera tiene implicaciones de carácter económico, de reputación y de confianza. Por un lado, el hecho de no seleccionar un modelo adecuado involucra pérdidas de capital por sobrevalorar o subvalorar el riesgo cuando no se está recogiendo el comportamiento del activo bajo evaluación; lo último ocasiona un aumento en los niveles de capital requeridos, vía el factor multiplicativo cuando las violaciones del nivel de probabilidad del VaR aumentan y, por consecuencia, disminución de liquidez en la apertura de posiciones. Por otro, el evento de que los errores de los modelos son dependientes en el tiempo (clústeres) hace que los agentes que trabajan en actividades de corretaje sean sancionados constantemente, provocando que la reputación de la respectiva institución se vea aminorada.
Melo y Granados (2011) indican que es necesario seleccionar modelos que no solo se adapten a la captura del nivel de probabilidad preespecificado como lo propone la SFC (Circular Externa 051 de 2007, parágrafo 5.2.2.2), sino que también puedan explicar la dinámica del riesgo ante posibles estados de dependencia y correlación que surge cuando hay períodos de alta probabilidad de pérdida. En la literatura se han propuesto varias medidas de desempeño con el objetivo de determinar qué tan adecuados son en la captura del riesgo. El propósito de su utilización es prevenir posibles problemas de riesgo moral que impliquen una subvaloración del riesgo, debido a que por medio de tal evaluación se pueden elevar los requerimientos de capital cuando el modelo no está ofreciendo una cobertura completa de los posibles riesgos en los que se incurre cuando se abre una posición financiera (Lucas, 2001). Estas medidas consisten en pruebas de cobertura incondicional, de independencia, condicionales y basadas en funciones de pérdida.
Proporción de fallas de Hit
Este estadístico determina si el nivel de probabilidad preespecificado es capturado por el modelo, es decir, si se satisface que 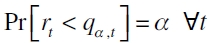 . Bajo una posición larga, el cálculo de la proporción de falla de Hit(%Hit) se define
. Bajo una posición larga, el cálculo de la proporción de falla de Hit(%Hit) se define
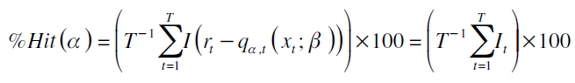 | [12] |
con It siendo una función indicadora de la forma
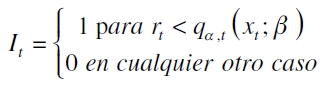
Estableciéndose que un modelo se encuentra bien especificado si la proporción de fallo es igual a la probabilidad α preespecificada o teórica del cuantil (Engle y Manganelli, 2004; Londoño, 2011).
Proporción de fallas de Kupiec
Esta prueba evalúa la significancia en la captura del nivel a -ésimo valorando la hipótesis nula H0: p=α , lo que permite determinar la precisión del modelo en la captura de la probabilidad α. Su estadístico se basa en una prueba de razón de verosimilitud (LRT)12 dada por
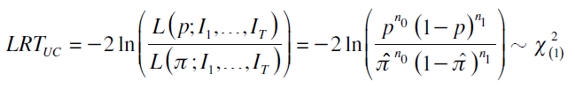 | [13] |
donde 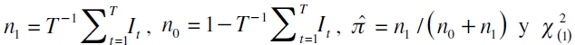 es una chicuadrado con un grado de libertad (Cristoffersen, 1998; Melo y Granados, 2011).
es una chicuadrado con un grado de libertad (Cristoffersen, 1998; Melo y Granados, 2011).
Cuantil dinámico
Este estadístico parte de la crítica de la explicación no condicional de los errores al igual que posibles cambios subyacentes que afecten de forma adversa a un portafolio de activos. Específicamente, una falencia que presentan las anteriores pruebas, es que no se está haciendo una evaluación condicional de los errores cometidos por el modelo, ya que, si bien, pueden determinar la captura del nivel de probabilidad preespecificado α que asume que 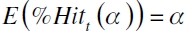 para un modelo bien especificado, no se está estableciendo si tales errores expresados por la función indicadora
para un modelo bien especificado, no se está estableciendo si tales errores expresados por la función indicadora 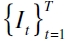 son i.i.d. (Cristoffersen, 1998).
son i.i.d. (Cristoffersen, 1998).
De acuerdo con esto, Engle y Manganelli (2004) proponen la prueba del cuantil dinámico que permite una evaluación correcta contra posibles malas especificaciones del modelo, y una extensión directa a la utilización de otras variables explicativas, como pueden ser los cuantiles estimados rezagados y variables dummy para medir estacionalidades. Ahora, si se tiene
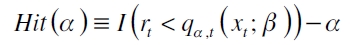
donde Hit(α) es un vector que incluye valores α y 1-α que dependen de si se mantuvo o no corregido el riesgo. De acuerdo con esto, se espera que si el modelo se halla bien ajustado, entonces los factores de riesgo son incorrelacionados y el valor esperado de 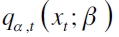 será igual a cero. Para contrastar la anterior hipótesis se parte de la regresión auxiliar
será igual a cero. Para contrastar la anterior hipótesis se parte de la regresión auxiliar
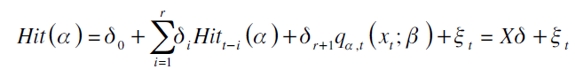
siendo 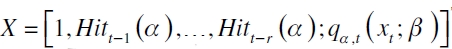 la matriz de variables explicativas y
la matriz de variables explicativas y 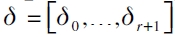 un vector de parámetros desconocidos. Entonces, es construido el estadístico de prueba
un vector de parámetros desconocidos. Entonces, es construido el estadístico de prueba
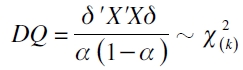 | [14] |
donde k =rango(X)-1 son los grados de libertad de una χ2 (Engle y Manganelli, 2001, 2004).
Prueba basada en análisis de regresión
Clements y Taylor (2003) muestran que por medio de la prueba de Engle y Manganelli (1999), no se está capturando completamente la dinámica de los retornos de los activos porque se soslaya la explicación adecuada de los clústeres de volatilidad y no se modela correctamente la naturaleza de la variable dependiente como función indicadora. Para solventar este problema utilizan la siguiente regresión artificial:
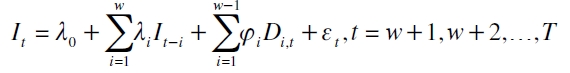 | [15] |
siendo Di,t una variable dummy que explica los clústeres de volatilidad. En tanto, para buscar la modelación correcta de la función indicadora, It, recurren a la regresión logística, que ofrece una estimación eficiente de (15), al modelar una variable discreta como variable dependiente. Su fórmula es
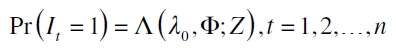
con 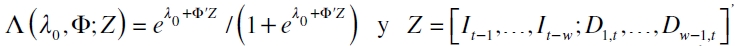 . A partir de este modelo, se evalúa la hipótesis H0: Φ=0 restringida a que λ0=α, con
. A partir de este modelo, se evalúa la hipótesis H0: Φ=0 restringida a que λ0=α, con 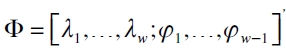 . Concretamente, si λi ≠0 sugiere que la secuencia
. Concretamente, si λi ≠0 sugiere que la secuencia 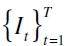 se halla correlacionada serialmente y si φi ≠0 implica que hay efectos periódicos, es decir, esta última hipótesis permite esclarecer si el modelo se adapta a las condiciones de dependencia que presentan las series financieras cuando se hallan en períodos de alta y baja volatilidad. Para ello se utiliza un estadístico LRT definido como
se halla correlacionada serialmente y si φi ≠0 implica que hay efectos periódicos, es decir, esta última hipótesis permite esclarecer si el modelo se adapta a las condiciones de dependencia que presentan las series financieras cuando se hallan en períodos de alta y baja volatilidad. Para ello se utiliza un estadístico LRT definido como
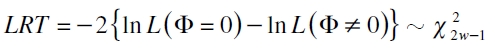 | [16] |
donde L(Φ= 0) y L(Φ≠0) es la verosimilitud bajo la hipótesis nula y alternativa, respectivamente.
Valor en riesgo basado en regresión cuantil (o prueba VQR)
Gaglianone et al. (2011) advierten que las pruebas construidas en función de una variable binaria, como las de Kupiec y Engle y Manganelli (2004) son poco potentes para explicar la dinámica de los activos en muestras finitas, a razón de que se contabilizan pocos eventos extremos. Por lo que proponen una metodología basada en regresión cuantil. Con ella, lo que se busca, es tener una medida de evaluación de modelos que pueda adaptarse a la dinámica del VaR calculado, además de explicar períodos de calma o crisis usando muestras finitas. La prueba se basa en la siguiente regresión cuantil:
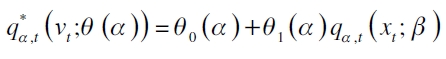
donde 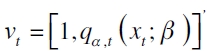 es la matriz de variables explicativas que incluye un intercepto y el cuantil estimado o VaR por la técnica a evaluar (por ejemplo, un modelo GARCH o de regresión cuantil), y
es la matriz de variables explicativas que incluye un intercepto y el cuantil estimado o VaR por la técnica a evaluar (por ejemplo, un modelo GARCH o de regresión cuantil), y 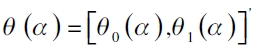 son los parámetros a estimar en el α-ésimo cuantil. El propósito de la prueba es evaluar si
son los parámetros a estimar en el α-ésimo cuantil. El propósito de la prueba es evaluar si 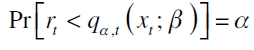 . La hipótesis nula global es
. La hipótesis nula global es
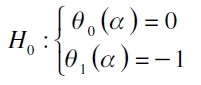
y el estadístico de prueba es definido por
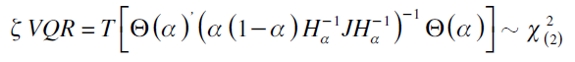 | [17] |
siendo 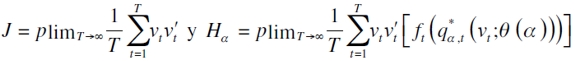 bajo la hipótesis nula del modelo de regresión cuantil
bajo la hipótesis nula del modelo de regresión cuantil 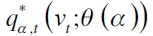 en el que
en el que 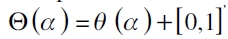 . El término ft (·) es la densidad condicional de rt evaluada en el cuantil a (Gaglianone et al., 2011).
. El término ft (·) es la densidad condicional de rt evaluada en el cuantil a (Gaglianone et al., 2011).
Función de pérdida asimétrica
A partir de la implementación del VaR como una medida de riesgo de mercado, en BCBS (1996) se definen tres zonas de riesgo (verde, amarilla y roja) que, según sean las fallas cometidas por el modelo, determinarían a través de un factor multiplicativo cuál sería la respectiva penalización. Un problema que presenta este requerimiento, es el hecho de evaluar el mayor riesgo de forma binaria sin percatarse si los errores cometidos por el modelo fueron muy amplios (o estrechos) en comparación con el valor pronosticado del VaR, ocasionando pérdidas de liquidez por altas penalizaciones en períodos de crisis cuando no necesariamente se presentó un error de pronóstico de gran cuantía.
Ante lo anterior, es importante poder sancionar posibles desviaciones del pronóstico de su valor objetivo vía una función de pérdida asimétrica, que por medio de su forma exponencial determina el grado de sobrevaloración o subvaloración del riesgo. Este estadístico proporciona al administrador de riesgo no solo estar al tanto de los costos en los que se incurre por tener un valor pronosticado por debajo del estado observado, sino también en los que se infringe por realizar provisiones por encima de su valor objetivo (Londoño, 2011). Por tanto, se evaluará el modelo con la siguiente función lineal exponencial nombrada como Linex:
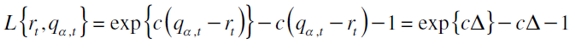 | [18] |
con c denotando una constante fija conocida. Esta función tiene las siguientes propiedades: es igual a cero cuando q α,t= rt y positiva en otro caso; es una función convexa para 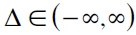 ; es decreciente para
; es decreciente para 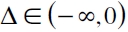 y creciente para
y creciente para 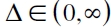 ; la mayor penalización se define según sea el valor que tome c, tal que c < 0 implica mayor penalización por subvaloración del riesgo, y viceversa (Samaniego, 2010).
; la mayor penalización se define según sea el valor que tome c, tal que c < 0 implica mayor penalización por subvaloración del riesgo, y viceversa (Samaniego, 2010).
RESULTADOS
Datos, construcción de indicadores y portafolio
Los datos utilizados se obtuvieron de la página web de la SFC y del Grupo Aval y corresponden a 1.355 observaciones en el período comprendido entre el 3 de enero de 2007 y el 24 de diciembre de 2012. Cada serie fue transformada a través de la expresión rt = ln(zt )-ln(zt-1 ).
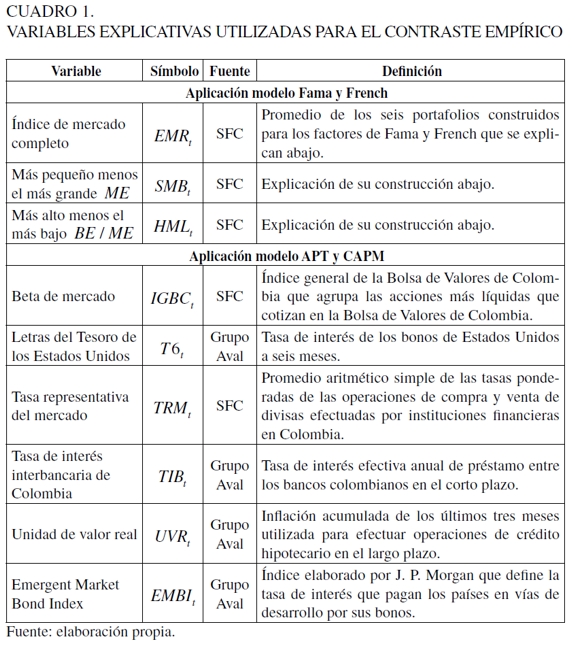
En el Cuadro 1 se pueden observar estas variables, en la parte superior se hallan los factores de riesgo usados para el modelo de Fama y French, y en la inferior, las de los modelos APT y CAPM; de las variables de ambas especificaciones es explicada su construcción, símbolo y la fuente de donde fueron consultadas. Cabe observar de este cuadro, que no se encuentra la variable dependiente que será el único insumo para el modelo APARCH y GARCH indirecto, la cual será explicada abajo.
Para obtener los factores de riesgo de Fama y French (1992, 1993) se calculan las siguientes ecuaciones:
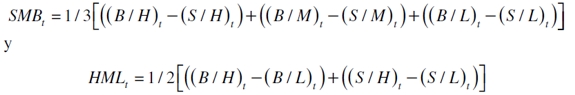
donde,
- (S/L)t: el portafolio está constituido en activos con bajo- ME que también se hallan en el grupo de bajo- BE / ME.
- (S/M)t: el portafolio está constituido por activos que tienen bajo- ME y un nivel medio de BE / ME.
- (S/H)t: el portafolio está constituido en activos con bajo- ME y un nivel alto de BE / ME.
- (B/L)t: el portafolio está constituido por activos que tienen un alto- ME al igual que bajo- BE / ME.
- (B/M)t: el portafolio está constituido en activos que tienen un alto- ME y un valor medio de BE / ME.
(B/H)t: el portafolio está constituido por activos que tienen un alto- ME y un valor alto de BE / ME.
Para la construcción de estas variables se emplearon 45 acciones de empresas que transan en el mercado accionario colombiano. Estas están compuestas de empresas financieras y no financieras. Aquí, lo que se buscó con esta selección es poder tener un conjunto que permita observar la dinámica del mercado de valores colombiano bajo las diferentes características de los activos (nivel de liquidez, tamaño, visibilidad, disponibilidad), pero tratando de evitar activos con una muy baja liquidez, que pueden no generar un aporte a la explicación del mercado (véase Anexo 1 para los detalles).
Para la selección del portafolio de activos como variable dependiente, se siguieron las recomendaciones realizadas por el Comité de Basilea, que consisten en la apertura de posiciones financieras que sean valoradas de manera homogénea por los participantes del mercado (buen nivel de liquidez y profundidad), lo que se halla estrechamente relacionado con una alta calificación crediticia por parte del emisor, visibilidad de la compañía, un bajo riesgo de inflación e incertidumbre cambiaria y que no se esté entrelazado a instituciones con posibles riesgos en el corto plazo (BCBS, 2010).
Por esta razón, se va a emplear un portafolio de activos que tiene en cuenta un nivel de liquidez alto, además de las características propias de una empresa sobre su dinámica en la economía y posibles riesgos de quiebra. Esto puede ser reunido por el portafolio réplica (B/H)t propuesto por Fama y French (1992, 1993), el cual tiene en cuenta a las empresas más representativas del país que presentan una buena capitalización bursátil y alto nivel de ganancias.
Medidas de desempeño para los modelos
La comparación de metodologías aplicadas al VaR se realizó a través de los modelos APARCH (Ding et al., 1993), el GARCH indirecto (Engle y Manganelli, 2004), uno que contiene los factores de Fama y French (1992), uno que incluye variables de carácter macroeconómico y financiero (APT), y uno que tiene un índice de mercado como variable explicativa (CAPM). En el Cuadro 2 se presentan las variables utilizadas en cada especificación.

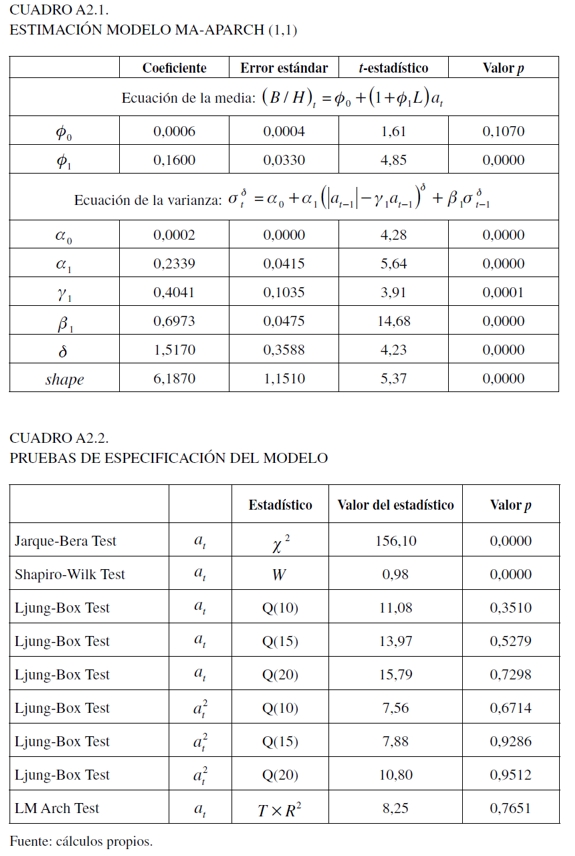
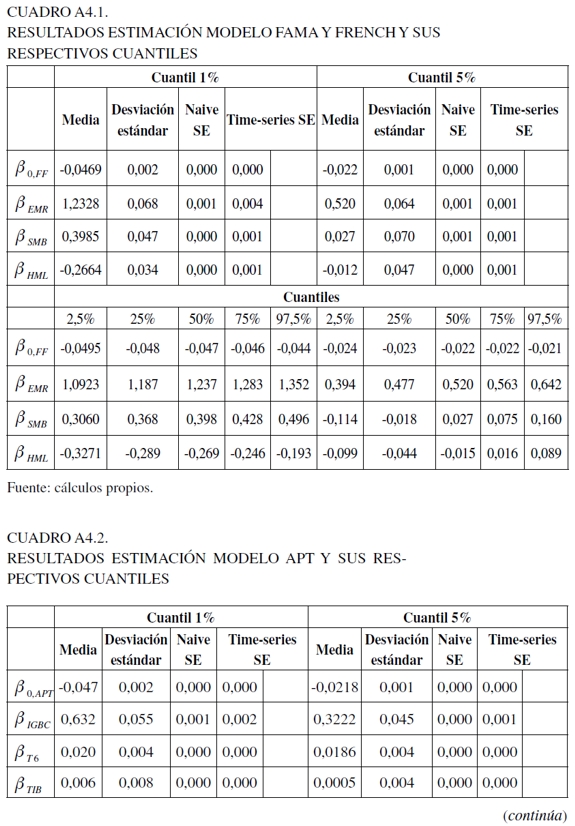
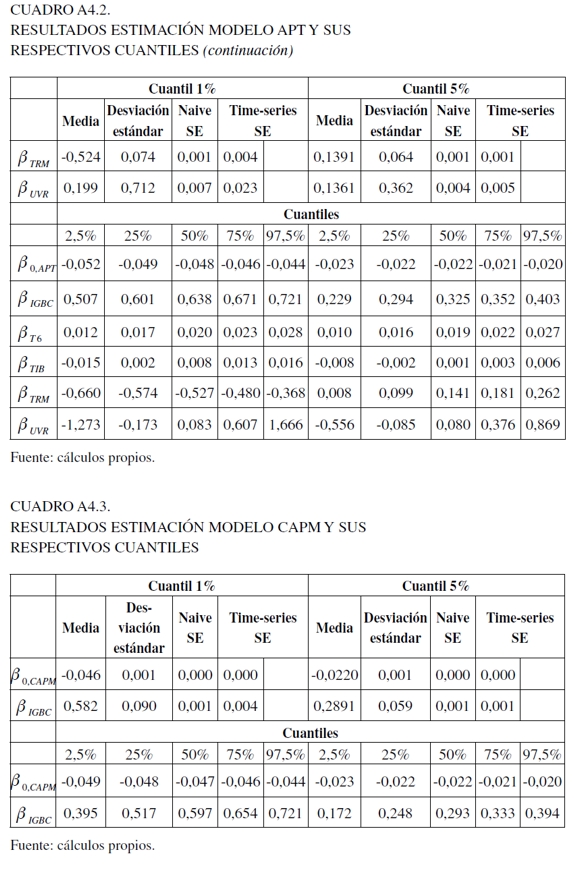
Para determinar las variables del primer modelo se utilizó el análisis de la función de autocorrelación simple (ACF) y parcial (PACF), y dadas las características exhibidas por la variable dependiente, se usó una distribución t para modelar el término de error (véase Anexo 2 para los resultados de parámetros y algunas pruebas de especificación). Para la segunda especificación se siguió la propuesta de Engle y Manganelli (2004) (véase Anexo 3 para los resultados de los parámetros estimados). Para los últimos tres esquemas, se tomó el primer rezago de las respectivas variables utilizadas para cada especificación con el propósito de capturar el comportamiento inmediato del mercado, los cuales fueron estimados a través de la técnica de regresión cuantil bayesiana utilizando el algoritmo MCMC (véase Anexo 4 para la estimación de los parámetros). La estimación de estos modelos fue realizada en Matlab versión 2009a y R (R Development Core Team, 2012)13.
Para estas estimaciones, los costos computacionales fueron de menos de 1 minuto para el modelo APARCH, de cerca de 37 minutos para el GARCH indirecto, y para los modelos estimados con regresión cuantil bayesiana tomó aproximadamente 5 minutos para cada especificación. De acuerdo con estos costos, tales modelos pueden ser implementados en una institución financiera de manera sencilla y sin mayores costos monetarios, ya que la mayoría de las estimaciones y cálculos se hicieron en R, que es un software estadístico libre.
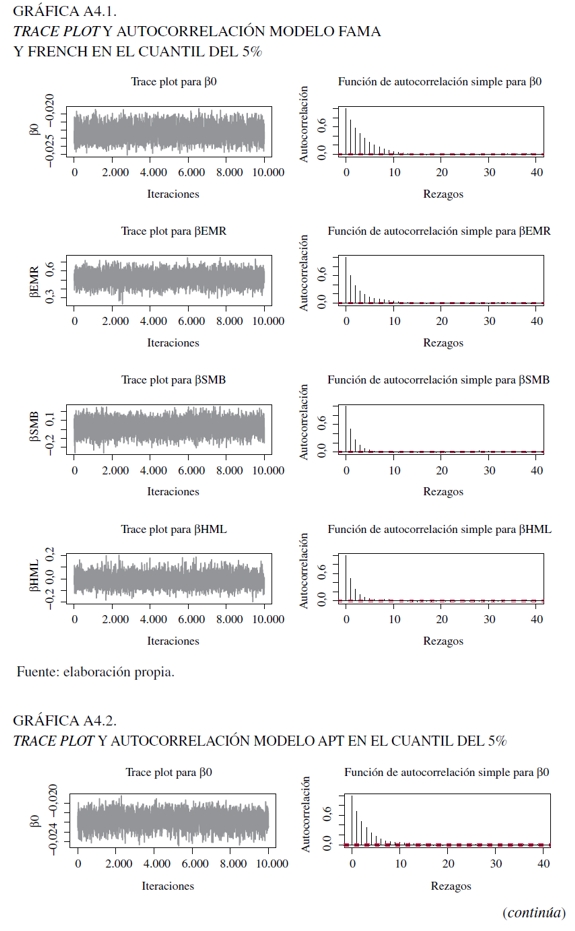
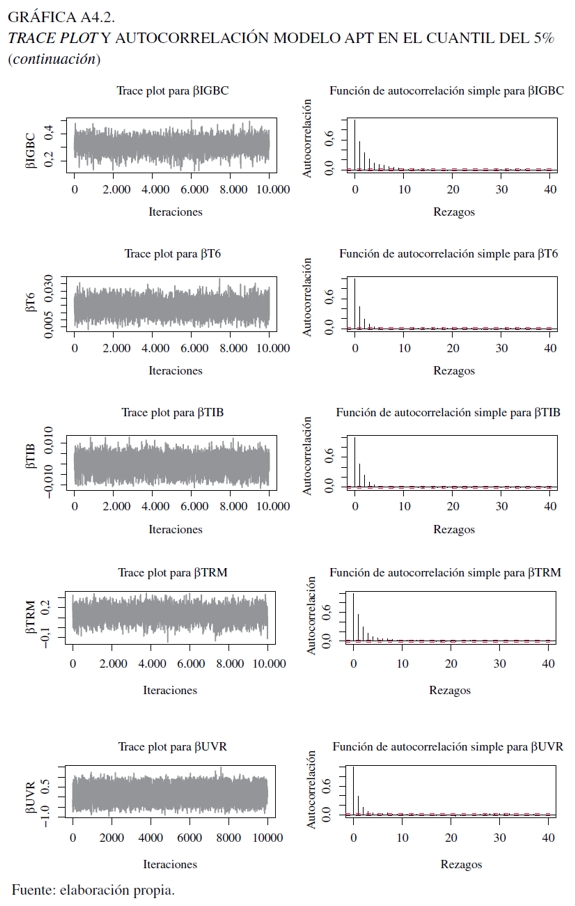
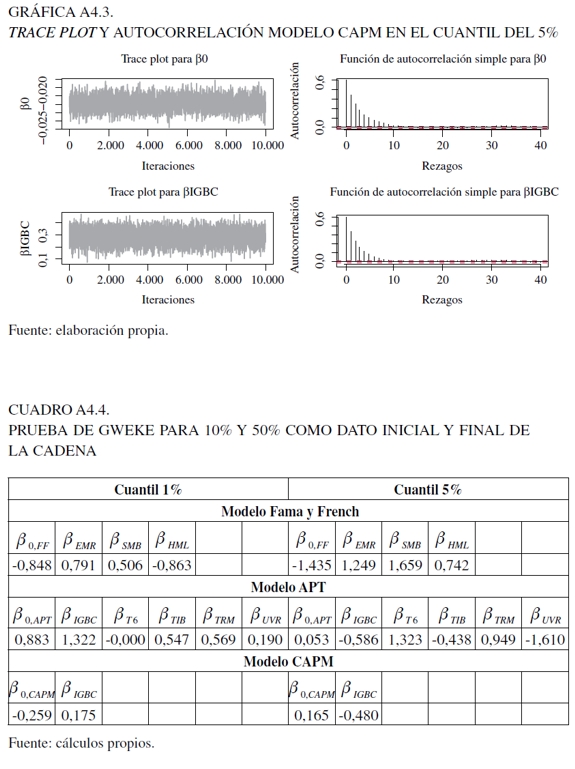
Ahora bien, para los últimos tres modelos, se utilizaron 150.000 iteraciones como base para garantizar su convergencia y la mezcla se descartan los primeros 100.000. Para evaluar esto, en el Anexo 4 se encuentran los análisis gráficos, como el trace plot y la función de autocorrelación, al igual que las pruebas de Gweke y Heidelberger- Welch. Con respecto a estos gráficas (Gráficas 3, 4, 5 y 6), el trace plot muestra que para los parámetros de las tres especificaciones para 10.000 observaciones presentan estacionaridad en la cadena, lo que implica una rápida mezcla y, por consecuencia, convergencia que permite dilucidar una caracterización válida de la distribución a posteriori. En tanto, la función de autocorrelación, presenta resultados eficientes en el algoritmo, al darse un rápido decaimiento que hace posible evitar ruido en las estimaciones extremas al darse un comportamiento estacionario.
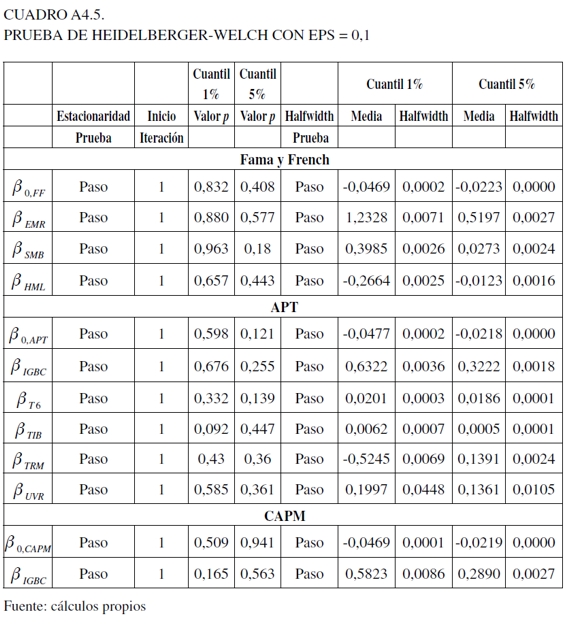
Para la prueba de Gweke (1992), se examina si los valores de los parámetros han convergido a través de la comparación en un estado inicial y final de la cadena de Markov. En esta situación, los datos iniciales y finales para el análisis fueron los del 10% y del 50%. En el Cuadro 4 del Anexo 4 se pueden visualizar los resultados para las tres especificaciones, en los cuales se aceptó y no la convergencia de la cadena (valores menores y mayores que uno, respectivamente). Sin embargo, este resultado debe tomarse con cuidado, ya que no hay una clara justificación del punto inicial y final a evaluar, lo que puede distorsionar los resultados (Jackman, 2009).
Finalmente, para la prueba de Heidelberger-Welch que reporta si el tamaño muestral es adecuado para encontrar una media precisa, valora dos componentes: el primero, evalúa la hipótesis nula de si los valores muestrales provienen de una distribución estacionaria usando el estadístico de Cramér-von-Mises. En este caso, en el Anexo 4 en el Cuadro 5 en su parte izquierda, se observa que esta supera el contraste de estacionaridad para todas las variables. La segunda, usando la proporción de datos que pasaron la primera prueba, se calcula la prueba half-width, la cual construye un intervalo de confianza del 95% para la media. En la parte derecha del mismo cuadro se observa que el valor objetivo para la razón half-width para la media muestral fue superado (la razón half-width para la media muestral es menor que eps = 0,1) (Jackman, 2009).
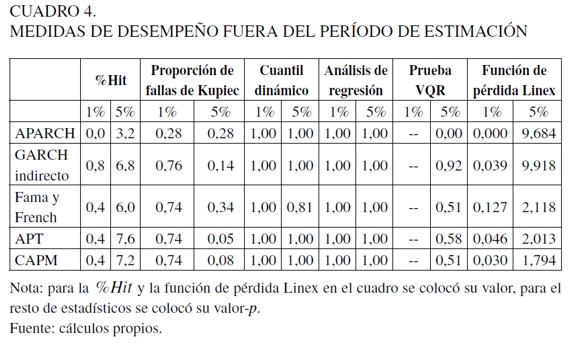
Ahora bien, en los Cuadros 3 y 4 se pueden resumir los resultados de las medidas de evaluación dentro del período de estimación y de backtesting, respectivamente, presentadas en la sección anterior, para un modelo VaR diario y una posición de compra por parte de una institución financiera (posición larga). En estos se halla el valor de la proporción de Hit (%Hit ); los valores p para la proporción de fallas de Kupiec, el cuantil dinámico, el análisis de regresión y la prueba VQR; en tanto para la función de pérdida Linex está su valor entregado. Lo anterior es calculado para los cuantiles de 1% y 5% y las cinco especificaciones propuestas en el Cuadro 2. Para el cálculo del cuantil dinámico se utilizaron los diez primeros rezagos de la función indicadora; para el estadístico de análisis de regresión se usaron los cinco rezagos y se construyó una variable dummy para separar períodos de alta y baja volatilidad, y para la función de pérdida Linex, el factor de asimetría fue c =-4.
Ahora bien, en el Cuadro 3, en términos de la %Hit, en general, todos los modelos para los cuantiles del 1% y 5% se desempeñaron adecuadamente, puesto que su valor empírico se aproxima a su teórico; sin embargo, el modelo APARCH no satisfizo esta tendencia, ya que presenta una sobrevaloración del riesgo (los valores observados fueron muy bajos con relación a los cuantiles teóricos). Para la proporción de fallas de Kupiec (columna 3, Cuadro 3), muestra que a excepción del modelo APARCH, en todos los modelos no se rechaza la hipótesis nula que determina la captura de la probabilidad preespecificada α.
Para el cuantil dinámico, se siguió la misma tendencia de la aceptación del no rechazo de la hipótesis nula sobre la captura del valor teórico α y la no correlación entre los errores dado sus valores p. Del resultado de este estadístico se debe destacar que si bien el modelo APARCH no presenta un buen desempeño en la captura del α-ésimo cuantil, no está rechazando la hipótesis nula de cobertura incondicional y correlación de los errores. Para la prueba de análisis de regresión, se aceptó de forma general la hipótesis nula de cobertura con respecto al nivel de confianza teórico y correlación entre errores de la función indicadora. Con relación a la prueba VQR, se está dando en general la aceptación de la hipótesis nula.
Finalmente, para la función de pérdida Linex, los resultados deben interpretarse conjuntamente dada la dependencia que existe entre esta y los demás estadísticos de prueba (particularmente la %Hit). De acuerdo con estos resultados, el modelo que presenta el mejor ajuste es el modelo de Fama y French, seguido por el CAPM y APT, es decir, los valores entregados por esta medida son los más bajos cuando se observan juntamente con la %Hit.
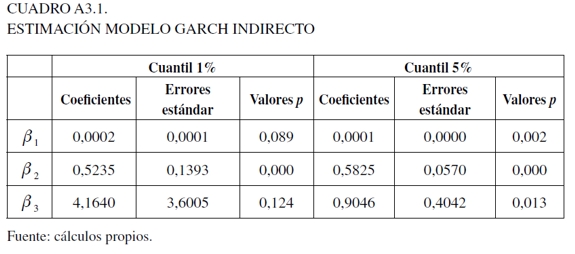
Para el período de backtesting se emplearon 250 observaciones como lo sugiere la regulación (véase Cuadro 4). Aquí, el modelo APARCH sigue presentando el mismo fenómeno de sobrevaloración del riesgo, implicando la no explicación adecuada de este portafolio. Para las especificaciones restantes, se dieron valores similares en la %Hit para el cuantil del 1%, donde se destaca que el modelo GARCH indirecto se aproxime más al valor teórico en el 1 y el de Fama y French en el 5%.
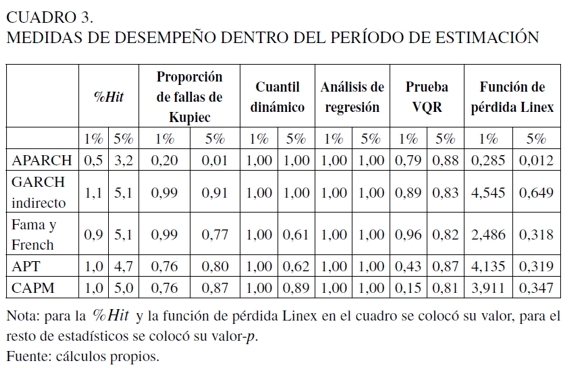
Para el estadístico de la proporción de Kupiec, es aceptada la hipótesis de cobertura incondicional para todos los modelos, al igual que para el cuantil dinámico y el análisis de regresión. Con relación a la prueba VQR en el cuantil del 1%, no se obtuvo ningún resultado, en razón de que la prueba con los datos bajo estudio tiene algunos problemas en el cálculo de las matrices J y Ha , mientras para el cuantil del 5% solo se rechazó la hipótesis nula para el modelo APARCH. Para la función de pérdida Linex, en el cuantil del 1% se observan los valores más bajos en los modelos estimados con regresión cuantil bayesiana. En tanto, para el cuantil del 5% se da que el modelo APARCH y GARCH indirecto presentan una alta función de pérdida con relación a las especificaciones de los modelos de precios de los activos, lo que indica que no se está explicando la dinámica del portafolio de una forma precisa, independientemente de que hayan valores bajos en la %Hit.
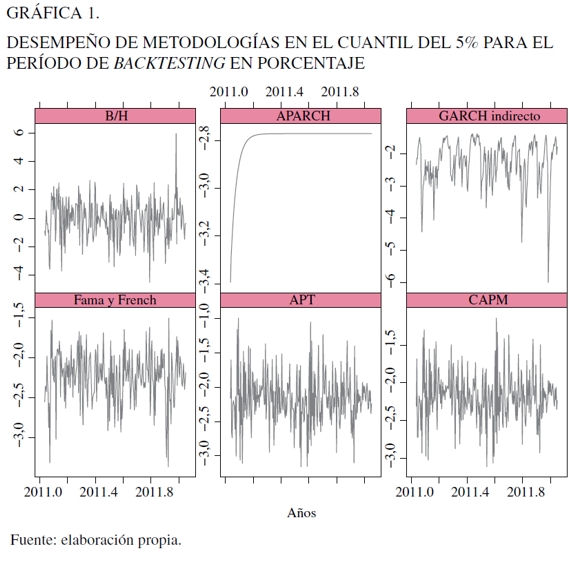
En la Gráfica 1 se puede observar el retorno del portafolio bajo análisis junto con el cuantil del 5% estimado bajo las diferentes especificaciones en valores porcentuales, donde se muestra que el modelo APARCH después de unos pocos días pierde poder de pronóstico y se ubica en un valor aproximado del -2,8%, indicando que su capacidad predictiva dura un período corto de tiempo, hallándose en su último valor pronosticado; lo que apunta a que si está pasando por un período de alta o baja volatilidad, permanece en dicha posición que puede ocasionar subvaloración y sobrevaloración del riesgo. Para el caso del GARCH indirecto, presenta algunos problemas en la predicción de la variable de interés, donde al final predice un valor que no es acorde con la serie analizada en la que se da una caída del 6%. El modelo de Fama y French hace lo propio en la explicación de la dinámica de este cuantil, pero se presenta una subvaloración moderada del riesgo en el período bajo análisis si se vislumbra el rango de predicción; sin embargo, es uno de los modelos que tiene una función de pérdida Linex más baja, lo que indica un buen recogimiento del portafolio bajo análisis. Para el modelo APT y CAPM se presenta el mismo fenómeno.
CONCLUSIONES
Esta investigación tuvo como propósito implementar el modelo de regresión cuantil bayesiana en el cálculo del VaR en el mercado de valores colombiano; para esto, se valoraron algunos requerimientos regulatorios para la medición del riesgo de mercado propuestos por Basilea II y III, y la Superintendencia Financiera de Colombia en la Circular Externa 051 de 2007. Se evaluaron tres problemas referentes a factores de riesgo, metodologías y medidas de desempeño. Se utilizaron cinco modelos diferentes: el modelo APARCH de Ding et al. (1993), el GARCH indirecto de Engle y Manganelli (2004) y tres especificaciones de los modelos de precios de los activos utilizando regresión cuantil bayesiana, que incluyen la teoría de precios de arbitraje (APT), el modelo de precios de los activos de capital (CAPM) y el de Fama y French. Se encontró que las metodologías que utilizan regresión cuantil en este trabajo, presentan un mejor desempeño en la cuantificación del riesgo de mercado de un portafolio de acciones construido según su tamaño y ratio valor en libros a valor de mercado cuando son evaluados mediante diferentes medidas de desempeño condicionales y no condicionales, al igual que una función de pérdida asimétrica con relación al modelo APARCH. Asimismo, se halla que la integración de regresión cuantil bayesiana con los modelos de precios de los activos que incluyen variables macroeconómicas, microeconómicas y financieras pueden ser una buena alternativa de modelación, al posibilitar el cálculo de las sensibilidades factoriales de manera dinámica y ser variables preciadas en los mercados financieros.
Una metodología que no se ajustó a la tendencia exhibida por este portafolio fue el modelo APARCH, que mostró una sobrevaloración del riesgo en períodos de estimación y pronóstico cuando se visualizan las medidas de desempeño; lo que es corroborado mediante un análisis gráfico que muestra que este tiene una explicación limitada en la captura y explicación del riesgo de este portafolio en el período de backtesting.
A modo de resumen, se puede establecer que cuando las instituciones financieras tienen tanto metodologías, factores de riesgo y respectivas medidas de evaluación adecuadas para el cálculo del VaR, esto les puede permitir evitar principalmente una subvaloración del riesgo ante estados contingentes negativos de la economía; además de diversos problemas de carácter regulatorios, de provisiones innecesariamente mayores en períodos de calma, y de efectos negativos en su reputación que disminuyan sus ingresos esperados en períodos de crisis. Por tanto, este trabajo podría ser una guía para seguir mejorando las condiciones que tienen modelos implementados en instituciones financieras para la cobertura del riesgo de mercado.
Para futuras investigaciones se propone el uso de otras metodologías estadísticas, como puede ser la regresión cuantil no paramétrica. También se sugiere un estudio sobre la regulación financiera en Latinoamérica y las posibles repercusiones que tiene para la región no diseñar un marco regulatorio acorde con las tendencias actuales de los mercados financieros, los cuales presentan una mayor interdependencia que ocasiona mayores beneficios, al igual que riesgos de pérdida. Además, sería interesante evaluar los requerimientos regulatorios para otro tipo de activos -bonos, tasas de cambio, derivados y demás productos estructurados-, con el propósito de ver las fortalezas y posibles debilidades en la administración del riesgo por parte de una institución financiera.
En este punto, es importante resaltar sobre la regulación en Latinoamérica, cuando se entra a investigar las posibles repercusiones de la integración del mercado de valores colombiano con el chileno y peruano, y su incidencia sobre el riesgo de mercado por medio del MILA. Se encuentra que en la Circular Externa 051 de 2007 hay ya lineamientos de cómo cubrirse ante riesgos en mercados extranjeros, pero sin tenerse en cuenta las características de tales mercados, ya que lo único que se propone es un factor de riesgo general. En tanto, cuando se entra a analizar la regulación en tales países se halla que están muy ceñidos a los requerimientos realizados por Basilea y no hay un marco claro que permita dilucidar cómo este acuerdo se debe adaptar a las condiciones de dichas economías que tienen una dinámica y riesgos específicos como sí fue buscado en Colombia, lo que hace necesario exigir mayores primas por el riesgo si se desea transar en dichos activos.
ANEXOS
1. Base de datos utilizada para la construcción y explicación de los factores de Fama y French
El Cuadro A1.1. muestra las acciones empleadas para este estudio, se observa heterogeneidad de empresas en tamaño, sector y actividad económica, entre otras características.
Para la elaboración de los factores de riesgo de Fama y French para Colombia, fue necesaria su construcción a través del cálculo de tres variables financieras:
1. Capitalización bursátil (ME): definida como el precio por acción multiplicado por el número de acciones en circulación.
2. Valor en libros (BE): es el patrimonio sobre el número de acciones; sin embargo, Fama y French utilizan el patrimonio de la compañía.
3. Valor en libros a valor de mercado ( BE/ME ): es la división entre el valor en libros de la compañía dividido por el valor de mercado, el último definido como la capitalización bursátil.
Cada una de estas variables en su cálculo fue asociada a cada día en el que se tenía información de las respectivas acciones; es decir, si una empresa solo empezó a transar en 2008, solo tendría datos a partir de 2008 en periodicidad diaria. Si se observa, por ejemplo, la capitalización bursátil, se ve que esta impregna variabilidad diaria al cambiar el precio de la acción (cuando la acción es transada) y al valor en libros a valor de mercado, al ser parte de su cálculo. Una vez se tienen estos datos y dadas las grandes diferencias de las compañías en su tamaño, que algunas pueden ser grandes o pequeñas (altos o bajos patrimonios y, en consecuencia, gran heterogeneidad), se les aplicó una transformación monótona por medio del logaritmo natural a dichos datos para luego transfórmalos a una escala [0,1] . Una vez se tenían estos datos y con los retornos de cada acción, se empezó a dar una clasificación de dichos retornos de estas empresas de acuerdo con dos intervalos utilizando ME (menores e iguales a 0,5 y mayores a 0,5) para luego hacer la última discriminación, que es la clasificación que se muestra en la parte de los resultados antes del Cuadro 1, que, por ejemplo, para (S/L)t, el portafolio está constituido en activos que se interceptan con el bajo- ME (menor e igual a 0,5) que también se hallan en el grupo de bajo- BE / ME (menor a 0,3, estando partido BE / ME en 3) y así sucesivamente para los otros.
Estos son un promedio simple después de hacerse la clasificación. La razón de no utilizar otra forma de agrupación, como un promedio ponderado, o análisis de componentes principales u otra técnica para hacer una agrupación de datos, es debido a las características que tiene el mercado accionario colombiano, que se caracteriza por tener una baja liquidez.
2. Parámetros estimados modelo APARCH y pruebas diagnósticas
3. Parámetros estimados modelo GARCH indirecto
4. Resultados estimados, diagnóstico gráfico y pruebas para evaluar convergencia
NOTAS AL PIE
1 En SFC (2007), la evaluación del riesgo de mercado se realiza para diferentes tipos de activos, como son: tasas de interés, posiciones en bonos y acciones, divisas, productos básicos, índices bursátiles, operaciones a plazos, derivados, entre otros. Esta investigación únicamente se enfocará en el riesgo de mercado debido a la apertura de una posición en acciones por parte de una institución financiera.
2 Por sus siglas en inglés, value at risk.
3 En una carta escrita a la Superintendencia Financiera de Colombia, la respuesta entregada por la SFC permite afirmar que la mayoría de las instituciones utilizan metodologías básicas para el cálculo del VaR, como es establecido en esta investigación.
4 El concepto de eficiencia en media-varianza se refiere al hecho de que las variables explicativas en un modelo puedan capturar todos los riesgos idiosincráticos que pueda tener un portafolio de activos como variable dependiente (Fama y French, 1996b).
5 Por sus siglas en inglés, generalized autoregressive conditional heteroscedasticity.
6 Por sus siglas en inglés, conditional autoregressive value at risk.
7 Por sus siglas en inglés, capital asset pricing model.
8 Por sus siglas en inglés, arbitrage pricing theory.
9 Por sus siglas en inglés, small minus big.
10 Por sus siglas en inglés, high minus low.
11 Lo que afirma Giot y Laurent (2003) es, además de un Student APARCH, la introducción de un componente de asimetría; no obstante, se intentó utilizar varios algoritmos (nlminb, lbfgsb, nlminb + nm, lbfgsb + nm) en el paquete estadístico R que no alcanzaron la convergencia, por eso solo se utiliza esta especificación sin asimetría.
12 Por sus siglas en inglés, likelihood ratio test.
13 El modelo de regresión cuantil bayesiano, se estimó con el paquete estadístico R por medio de la librería bayesQR y las pruebas de evaluación de la librería coda, el GARCH indirecto se realizó en Matlab con el código elaborado por Engle y Manganelli, y el APARCH en la librería fGarch de R.
REFERENCIAS
[1] Alexander, C. (2008). Market risk analysis. Value-at-risk models (vol. IV). England: John Wiley & Sons, Ltd. [ Links ]
[2] Ali, A., Hwang, L. S., & Trombley, M. A. (2003). Arbitrage risk and book-to-market anomaly. Journal of Financial Economics, 69(2), 355-377. [ Links ]
[3] Aristodemou, K., & Yu, K. (2008). CAViaR via bayesian noparametric quantile regression. In D. Barber, A. T. Cemgil, & S. Chiappa (eds). Inference and estimation in probabilistic time-series models (10-17). Cambridge: Isaac Newton for Mathematical Sciences, 10-17. [ Links ]
[4] (BCBS) Basel Committee on Banking Supervision (1996). Supervisory framework for the use of "backtesting" in conjunction with the internal models approach to market risk capital requeriment, Bank for International Settlements. [ Links ]
[5] (BCBS) Basel Committee on Banking Supervision (2010). Basel III: International framework for measurement, standardization and monitoring of liquidity risk, Bank for International Settlements. [ Links ]
[6] Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics, 31, 307-327. [ Links ]
[7] Cai, Z., & Wang, X. (2008). Nonparametric estimation of conditional VaR and expected shortfall. Journal of Econometrics, 147(1), 120-130. [ Links ]
[8] Cao, Q., Leggio, K. B., & Schniederjans, M. J. (2005). A comparison between Fama and French's model and artificial neural networks in predicting the Chinese Stock Market. Computers & Operations Research, 32(10), 2499-2512. [ Links ]
[9] Chernozhukov, V., & Hong, H. (2003). An MCMC approach to classical estimation. Journal of Econometrics, 115(2), 293-346. [ Links ]
[10] Chernozhukov, V., & Umantsev, L. (2001). Conditional value-at-risk: Aspects of modeling and estimation. Empirical Economics, 26(1), 271-292. [ Links ]
[11] Clements, M. P., & Taylor, N. (2003). Evaluating interval forecasts of high- frequency financial data. Journal of Applied Econometrics, 18(4), 445-456. [ Links ]
[12] Connor, G., & Linton, O. (2007). Semiparametric estimation of a characteristic-based factor model of common stock returns. Journal of Empirical Finance, 14(5), 694-717. [ Links ]
[13] Cristoffersen, P. F. (1998). Evaluating interval forecasts. International Economic Review, 39(4), 841-862. [ Links ]
[14] Diagne, M. (2002). Final risk management and portfolio optimization using artificial neural networks and extreme value theory. Tesis para optar al grado de Ph.D., Kaiserslautern, University Kaiserslautern-Mathematics Department / Financial Mathematics. [ Links ]
[15] Ding, Z., Granger, C., & Engle, R. (1993). A long memory property of stock market returns and a new model. Journal of Empirical Finance, 1(1), 83-106. [ Links ]
[16] Engle, R. F., & Manganelli, S. (1999). CAViaR: Conditional autoregressive value at risk by regression quantiles. NBER Working Paper Series (7341). [ Links ]
[17] Engle, R. F., & Manganelli, S. (2001). Value at risk models in finance. Working Paper Series (75), European Central Bank. [ Links ]
[18] Engle, R. F., & Manganelli, S. (2004). CAViaR: Conditional autoregressive value at risk by regression quantiles. Journal of Business & Economic Statistics, 22(4), 367-381. [ Links ]
[19] Fama, E., & French, K. R. (1992). The cross-section of expected stock returns. The Journal of Finance, 47(2), 427-465. [ Links ]
[20] Fama, E., & French, K. R. (1993). Common risk factors in the returns on stock and bond. Journal of Financial Economics, 33(1), 3-56. [ Links ]
[21] Fama, E., & French, K. R. (1996a). Multifactor explanations of asset pricing anomalies. The Journal of Finance, 51(1), 55-84. [ Links ]
[22] Fama, E., & French, K. R. (1996b). The CAPM is wanted, dead or alive. The Journal of Finance, 51(5), 1947-1958. [ Links ]
[23] Fama, E., & French, K. R. (1998). Value versus growth: The international evidence. The Journal of Finance, 53(6), 1975-1999. [ Links ]
[24] Fedor, M. (2010). Financial risk in pension funds: Application of value at risk methodology (Chapter 9). In M. Micicci, G. N. Gregoriou, & G. B. Masala (eds.). Pension fund risk management. Financial and actuarial modeling (185-209). New York: Taylor & Francis Group, LLC. [ Links ]
[25] Gaglianone, W. P., Lima, L. R., Linton, O., & Smith, D. R. (2011). Evaluating value-at-risk models via quantile regression. Journal of Business & Economic Statistics, 29(1), 150-160. [ Links ]
[26] Gallón, S. y Gómez, K. (2007). Distribución condicional de los retornos de la tasa de cambio colombiana: un ejercicio empírico a partir de modelos GARCH multivariados. Revista de Economía del Rosario, 10(2), 127-152. [ Links ]
[27] Gelman, A., Carlin, J. B., Stern, H. S., & Rubin, D. B. (2004). Bayesian data analysis, Second Edition. New York: Chapman & Hall/CRC. [ Links ]
[28] Geweke, J. (1992). Evaluating the accuracy of sampling-based approaches to the calculation of posterior moments. In J. M. Bernardo, J. O. Berger, A. P. Dawid, & A. F. M. Smith (eds). Bayesian Statistics 4. Oxford: Oxford University Press. [ Links ]
[29] Giot, P., & Laurent, S. (2003). Value-at-risk for long and short trading positions. Journal of Applied Econometrics, 18(6), 641-664. [ Links ]
[30] Giraldo, N. (2005). Predicción de betas y VaR de portafolios de acciones mediante el filtro de Kalman y los modelos GARCH. Cuadernos de Administración, 18(29), 103-119. [ Links ]
[31] Jackman, S. (2009). Bayesian analysis for the social sciences. United Kingdom: John Wiley & Sons, Ltd. [ Links ]
[32] Kavussanos, M. G., & Dimitrakopoulos, D. N. (2011). Market risk model selection and medium-term risk with limited data: Application to ocean tanker freight markets. International Review of Financial Analysis, 20, 258-268. [ Links ]
[33] Koenker, R., & Bassett, G. (1978). Regression quantiles. Econometrica, 46(1), 33-50. [ Links ]
[34] Leiton, K. J. (2011). Validez del supuesto de neutralidad del horizonte de tiempo en el CAPM y la metodología del rango reescalado: aplicación para Colombia. Borradores de Economía, (672), 1-43. [ Links ]
[35] Lewellen, J. (1999). The time-series relations among expected return, risk, and book-to-market. Journal of Financial Economics, 54(1), 5-43. [ Links ]
[36] Londoño, C. A. (2011). Regresión del cuantil aplicada al modelo de redes neuronales. Una aproximación de la estructura CAViaR para el mercado de valores colombiano. Revista Ensayos sobre Política Económica, 29(64), 62-109. [ Links ]
[37] Londoño, C. A. y Cuan, Y. M. (2011). Modelos de precios de los activos: un ejercicio comparativo basado en redes neuronales aplicado al mercado de valores colombiano. Lecturas de Economía, (75), 59-87. [ Links ]
[38] Lucas, A. (2001). Evaluating the Basle guidelines for backtesting banks internal risk management models. Journal of Money, Credit and Banking, 33(3), 826-846. [ Links ]
[39] McNeil, A. J., & Frey, R. (2000). Estimation of tail-related risk measures for heteroscedastic financial time series: An extreme value approach. Journal of Empirical Finance, 7(3-4), 271-300. [ Links ]
[40] Melo, L. F. y Granados, J. C. (2011). Regulación y valor en riesgo. Revista Ensayos sobre Política Económica, 29(64), 110-177. [ Links ]
[41] Pritsker, M. (2006). The hidden dangers of historical simulation. Journal of Banking & Finance, 30(2), 561-582. [ Links ]
[42] R Development Core Team (2012). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0, URL http://www.R-project.org/. [ Links ]
[43] Ross, S. (1976). The arbitrage theory of capital asset pricing. Journal of Economic Theory, 13(3), 341-353. [ Links ]
[44] Samaniego, F. J. (2010). A comparison of the bayesian and frequentist approaches to estimation. New York: Springer Series in Statistics. [ Links ]
[45] Sharpe, W. (1964). Capital asset prices: A theory of market equilibrium under conditions of risk. Journal of Finance, 19(3), 425-442. [ Links ]
[46] (SFC) Superintendencia Financiera de Colombia (2007). Circular Externa 051 de 2007. [ Links ]
[47] Taddy, M. A., & Kottas, A. (2010). A bayesian noparametric approach to inference for quantile regression. Journal of Business & Economic Statistics, 28(3), 357-369. [ Links ]
[48] Tai, C.-S. (2003). Are Fama-French and momentum factors really priced? Journal of Multinational Financial Management, 13(4-5), 359-384. [ Links ]
[49] Taylor, J. W. (2005). Generating volatility forecasts from value at risk estimate. Management Science, 51(5), 712-725. [ Links ]
[50] Wang, X., & Song, X. (2008). Indirect TARCH-CAViaR model and its parameter estimation by MCMC method with an application. Systems Engineering-Theory & Practice, 28(9), 46-51. [ Links ]
[51] Wu, X. (2002). A conditional multifactor analysis of return momentum. Journal of Banking & Finance, 26(8), 1675-1696. [ Links ]
[52] Yu, K., & Moyeed, R. A. (2001). Bayesian quantile regression. Statistics & Probability Letters, 54(4), 437-447. [ Links ]
