










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkRevista de Ingeniería
Print version ISSN 0121-4993
rev.ing. no.42 Bogotá Jan./June 2015
https://doi.org/10.16924/riua.v0i42.753
Generación automática de cartografía para edificaciones, utilizando fotografías digitales aéreas verticales de alta resolución espacial y nubes de puntos
LiDAR The Generation of Automatic Mapping for Buildings, Using High Spatial Resolution Digital Vertical Aerial Photography and LiDAR Point Clouds
William Barragán Zaque (1) ,Alexander Martínez Rivillas (2), Pablo Emilio Garzón Carreño (3)
(1) MSc. Photogrammetrie und Geoinformatik, Especialista en Sistemas de Información Geográfica. Profesor Asociado, Universidad Distrital Francisco José de Caldas. Bogotá D.C., Colombia. wbarraganz@udistrital.edu.co
(2) PhD. (c) en Geografía, Instituto Geográfico Agustín Codazzi-Universidad Pedagógica y Tecnológica de Colombia. Profesor Asistente, Universidad del Tolima. Ibagué, Colombia. alexandermartinezrivillas@gmail.com
(3) Especialista en Ingeniería. Decano de la Facultad Tecnológica, Universidad Distrital Francisco José de Caldas. Bogotá. D.C., Colombia. pegarzonc@udistrital.edu.co
Recibido 15 de noviembre de 2014. Modificado 4 junio de 2015. Aprobado 22 de junio de 2015.
DOI: http://dx.doi.org/10.16924/riua.v0i42.753
Palabras clave
Cartografía, extracción automática, fotogrametría, fotografías aéreas, segmentación de imágenes.
Key words
Mapping, automatic extraction, photogrammetry, aerial photography, image segmentation.
Resumen
El objetivo del presente trabajo es generar productos fotogramétricos y obtener de manera totalmente automática y en formato vectorial la cartografía de las edificaciones que se encuentran en la zona de interés. La investigación se desarrolla en Bogotá y se emplean fotografías aéreas verticales de alta resolución, nubes de puntos obtenidas con tecnología Light Detection and Ranging (LIDAR). Además, se utiliza tanto la aplicación de segmentación de imágenes como los procedimientos digitales radiométricos y geométricos. Igualmente, en el proceso se tienen en cuenta las alturas de las construcciones, los algoritmos de segmentación y las combinaciones de bandas espectrales, entre otros. El resultado presenta efectividad de 97,2%. Esta tasa fue validada a través del trabajo de campo.
Abstract
The aim of this paper is to generate photogrammetrie products and to automatically map buildings in the area of interest in vector format. The research was conducted Bogotá using high resolution digital vertical aerial photographs and point clouds obtained using LIDAR technology. Image segmentation was also used, alongside radiometric and geometric digital processes. The process took into account aspects including building height, segmentation algorithms, and spectral band combination. The results had an effectiveness of 97.2 % validated through ground-truthing.
Introducción
El Grupo de Investigación GEOTOPO1, realizó el diseño metodológico de esta investigación, que sometió a prueba de campo, y, cuyo propósito era extraer automáticamente y de manera vectorial los techos de las ediicaciones en la zona de trabajo, ubicada en Bogotá, Colombia. Para ello se tuvieron en cuenta tanto las últimas tendencias para generar cartografía de manera automática, como las directrices impartidas en las comisiones científicas y técnicas de la Sociedad Internacional de Fotogrametría y Teledetección (ISPRS), desarrolladas principalmente en el último lustro (Triglav & Zorn, 2014; Nga & Yanai, 2014). De igual manera, se consideraron los adelantos realizados en Colombia por las diferentes universidades que tenían programas curriculares relacionados con el área de geomática.
Así mismo, se empleó un método integral que permitía el procesamiento digital de imágenes aéreas de alta resolución espacial (Sebari & He, 2013). Una vez se obtenía la orientación interna y externa y el modelo digital del terreno, se producía una ortofoto (Minetto, Thome, Leite & Stolfi, 2014; Martínez, Soria & Arias 2012; Lim & Suter, 2009). Este producto sirvió de insumo para ser integrado con nubes de puntos obtenidas con tecnología LIDAR. Se tuvo en cuenta también la altura de las ediicaciones extraídas del modelo digital de supericie (DSM), y se generaron algoritmos de segmentación de imágenes mediante procedimientos netamente digitales. Lo anterior se complementó con la deinición de umbrales de la desviación estándar de la pseudoimagen, que representa el modelo digital de superficie (Madhavan, Wang, Tanahashi, & Yamamoto, 2006; Kabolizade, Ebadi & Ahma di, 2010).
Para resaltar las características de los elementos, se ejecutaron combinaciones y operaciones algebraicas entre las bandas espectrales en las fotografías, logrando una plena visualización de las construcciones en la zona. Se determinó la geometría, la forma, la compacidad (Awrangjeb, Zhang & Fraser, 2013) y los factores de escala. Estos elementos, de manera conjunta y coordinada, permitieron la extracción automática de las ediicaciones en la zona cubierta por las fotografías aéreas. El resultado de estos trabajos muestra los ediicios conseguidos de manera automática. De esta forma, es posible ver avances importantes y limitaciones en el tema (Gamanya, Maeyer & Dapper, 2009). Además, estos productos inales se conirmaron en campo y se evidenció que las últimas tecnologías en materia de segmentación de imágenes, combinadas con nubes de puntos LIDAR y la integración de diferentes algoritmos de asignación de clases, permiten extraer de manera automática las ediicaciones de la zona de trabajo con una confiabilidad de 97,2%2,. Asimismo, se demuestra también que estas herramientas pueden ser aplicadas a otras zonas de interés del territorio colombiano.
Construcción de la metodología
Para empezar, se realiza todo el procesamiento fotogramétrico que permite obtener ortofotos digitales. Para ello, se construye previamente el modelo digital de terrero (DTM) fuente, la deinición de unidades y el tamaño de pixel de trabajo (8cms), el cual es consecuente con el tamaño final de la imagen. Enseguida, se hace la segmentación de la imagen utilizando el algoritmo de multiresolución (Hermosilla, Ruiz, Sarriá, & Recio, 2008).
Finalmente, se realiza la estipulación de condicionamientos y la creación de reglas que permiten hacer la extracción automática de las ediicaciones. Para esto, se lleva a cabo la clasiicación de los elementos presentes en la ortofoto, utilizando la media de los valores de las alturas del DSM. Después, se hace el análisis de la desviación estándar de las alturas presentadas en el DSM y, se elabora un reinamiento basado en información espectral, y otros ajustes fundamentados en el contexto y la forma, para llegar a la obtención automática de la cartografía de las ediicaciones de la zona.
FASE I - Procesamiento fotogramétrico
Las imágenes de trabajo fueron adquiridas por el Instituto Geográfico Agustín Codazzi - IGAC con la cámara digital aerotransportada Vexcel Ultracam D3,. Para el desarrollo del presente trabajo se tuvieron en cuenta la corrección de la geometría asociada a la cámara/sensor y el tamaño del pixel o Ground Simple Distance (GSD), que en fotogrametría analógica representa la relación promedio entre una distancia en la imagen y la misma distancia en el terreno. Para calcular lo anterior, se dividió la distancia focal entre la altura de vuelo, respecto a la elevación del terreno (García & Lerma, 2013). El tamaño promedio calculado del GSD para el proyecto es de ocho centímetros. En esta primera parte se realiza la generación del modelo estereoscópico, que se convierte en el principal insumo para tomar medidas en coordenadas X, Y y Z, con niveles de precisión acordes a una restitución fotogramétrica que permita obtener la cartografía (Barragán, 2013).
En esta etapa, se realiza la selección del marco de referencia espacial que permite la deinición de localizaciones mediante coordenadas. Esto es un complemento esencial para el establecimiento del bloque fotogramétrico, ya que, se tiene en cuenta la altura media de vuelo para las fotografías y el tipo de sensor (para este caso, los datos de la cámara fotogramétrica Vexcel Ultracam D).
Antes de iniciar la orientación interna de cada una de las fotografías aéreas verticales, se crean las imágenes piramidales que optimizan el tiempo para despliegue y procesamiento (Qin & Gruen, 2014). En esta orientación se ingresa el dato del tamaño de píxel. Además, en la configuración del sensor, es necesario el ingreso de los datos del certificado de calibración de la cámara con la que fueron tomadas las fotografías. En el caso de la generación de datos de orientación externa, es necesario contar con las coordenadas de los fotocentros: Xo, Yo y Zo, el ID de la imagen, y los valores de los ángulos Omega, Phi y Kappa consignados en los datos del Inertial Measurement Unit (IMU)4, (Guarnieri, Vettore, Camarda & Domenica, 2011).
Adicionalmente, para la orientación externa, es necesaria la ubicación en la imagen de puntos de homólogos. Este procedimiento se puede realizar de manera manual o automática. Cuando se ajusta el bloque fotogramétrico es posible elaborar el cálculo de las estadísticas referidas al ajuste de mínimos cuadrados para estimar parámetros de precisión. Los mínimos cuadrados reducen y distribuyen el error a lo largo del bloque. De igual manera, se asignan coordenadas reales al modelo con el apoyo de los puntos de control que fueron obtenidos en campo.
Finalmente, en esta etapa se elabora el DTM. Para comprobar su precisión, este se genera con un parámetro igual al número de píxeles por metro cuadrado del modelo final que se quiere. Los datos del terreno pueden ser vistos de forma mono o estéreo. En la Figura 1 , se observa parte de un par estereoscópico de la zona de trabajo, que tiene la ventaja de ser visualizado en tercera dimensión. Este insumo es importante para la generación del DTM, que se utiliza en la elaboración de la ortofoto a trabajar en la segmentación (Ergun, Sahin & Ustuntas, 2014).

FASE II- Segmentación
Algoritmos de Segmentación
Estos algoritmos ejecutan acciones de subdivisión de imágenes enteras a un nivel de píxeles, o presentan objetos de imagen de otros dominios en objetos de imagen más pequeños. Existen diferentes algoritmos para realizar segmentación de imágenes digitales. Algunos de los más sencillos son los del tablero de ajedrez o Chessboard Segmentation,5, y la segmentación basada en árboles de cuadrángulos o quadtree6,. Existen otros algoritmos altamente soisticados como la segmentación por multiresolución y por contraste de iltros (Awrangjeb et al., 2013). La utilización específica de estos algoritmos se presenta cada vez que se desee crear nuevos objetos de imagen basados en información de las capas de la imagen original. Adicionalmente, son una herramienta muy valiosa para reinar objetos de imagen existente, mediante la subdivisión en fracciones más pequeñas para un análisis minucioso.
Algoritmo de segmentación por multi-resolución
El algoritmo de segmentación por multi-resolución minimiza la heterogeneidad media de los objetos presentes en una imagen, teniendo en cuenta una determinada resolución. Se puede ejecutar a nivel objeto o nivel de píxel, para la creación de nuevos objetos de imagen en un área de interés especíica (Kabolizade et al., 2010).
El algoritmo de segmentación por multiresolución fusiona consecutivamente píxeles o la imagen objeto existente. Por tanto, es un algoritmo denominado "de abajo hacia arriba", pues refleja una segmentación basada en una región por parejas (pairwise7,) (Guarnieri et al., 2011). El procedimiento de segmentación por multiresolución representa un mejor enfoque mutuo (mutualbest- itting) y funciona según las siguientes reglas:
1. El archivo semilla busca su mejor ajuste de vecino para una posible fusión.
2. Si el mejor ajuste no es mutuo, el mejor objeto de imagen candidato se convierte en la nueva semilla.
3. El objeto de imagen encuentra su mejor mutualista apropiado.
4. Cuando el mejor ajuste entre píxeles es mutuo, los objetos de imagen se fusionan.
5. En cada bucle que se ejecute, cada objeto de imagen en el nivel de objeto se manejará una vez.
6. Los ciclos continúan, cuantas veces sea necesario, hasta que ya no sea posible la fusión.
El procedimiento se inicia con la segmentación de objetos de imagen individuales de un píxel, y repetidamente se funden en varios bucles en pares8, a unidades más grandes, siempre y cuando, exista un umbral superior de homogeneidad que no sea superado localmente (Ergun et al., 2014; Minetto et al., 2014). Este criterio se define como una combinación de homogeneidad espectral. En este cálculo únicamente se puede influir mediante la modificación del parámetro de escala. Para el trabajo realizado se asumió un valor correspondiente a 25 pixeles como factor (Jung, Jeon & Cho, 2014). Cuando se asume un valor alto en este parámetro, los resultados de la segmentación son objetos de imagen de mayor tamaño. En cambio, cuando se asigna un valor bajo en esta cuantiicación, los resultados son objetos de imagen de menor tamaño.
En la Figura 2 , se puede ver que cada objeto de imagen utiliza el criterio de homogeneidad para determinar el mejor vecino para fusionarse. Si el primer mejor objeto de imagen vecino (verde) no reconoce la primera imagen objeto (gris) como el mejor vecino, el algoritmo se mueve (flecha verde) a la segunda imagen objeto para encontrar el mejor vecino.
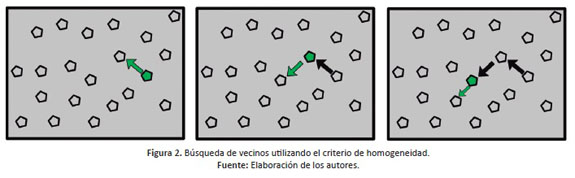
Se realiza una rutina de búsqueda del mejor vecino del objeto de la imagen. Las iteraciones se realizan hasta que no haya fusiones de objetos de imagen adicionales. Este procedimiento se puede realizar sin sobrepasar la máxima homogeneidad permitida para un objeto de imagen, como se ha definido de manera previa (Bucksch & Lindenbergh, 2008; Kabolizade et al., 2010). Con cualquier tamaño promedio de los objetos de imagen, la segmentación por multiresolución presenta una buena abstracción y conformación de áreas. No obstante, tiene como requisito principal que en la estación de trabajo (WS) se tenga una capacidad de memoria alta. Es necesario tener en cuenta que otras técnicas de segmentación pueden consumir más recursos informáticos. En la figura 3 , se observa gráicamente la formación de nuevas regiones. En ella se muestra cómo el algoritmo de segmentación por multiresolución trabaja para que la ubicación salte de objeto en objeto repetidamente hasta que encuentre un mejor vecino.
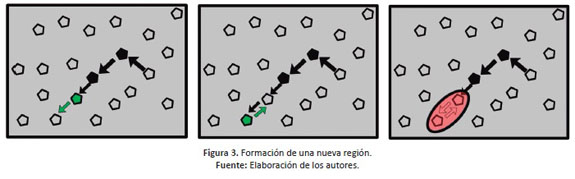
Si la homogeneidad del nuevo objeto de imagen no excede el parámetro de escala, los dos objetos de imagen-pareja se fusionan, formando así la nueva región.
Ajustes de segmentación
Para la realización de la segmentación por multi-resolución se pueden asignar pesos a cada una de las capas de la imagen. Es posible tener resultados más certeros, dado que cuanto mayor sea el valor asignado a una capa de imagen, más relevancia se le dará a la información de píxeles de la capa durante el proceso de segmentación.
Es posible también especiicar las capas temáticas a ser candidatas para la segmentación. Cada capa temática que se utiliza para la segmentación conducirá a la división adicional de objetos de imágenes, al tiempo que permitirá el acceso consistente a su información temática. Es posible segmentar una imagen utilizando más de una capa temática. Los resultados son los objetos de imagen que representan intersecciones adecuadas entre las capas temáticas. Sin duda alguna, la deinición del tamaño de las regiones en la segmentación es el parámetro de escala, el cual determina la heterogeneidad máxima permitida para los objetos de imagen resultante. Este parámetro también deine que los objetos resultantes de un valor de escala determinado, condicionan un número mayor de regiones heterogéneas y un número menor de regiones homogéneas (Sebari et al., 2013).
Es recomendable producir objetos de imagen de la mayor escala posible, los cuales permiten distinguir diferentes regiones de imagen, cumpliendo con el principio de tener regiones inales tan grandes como sea posible y tan inas como sea necesario. Es indispensable también veriicar que la separación de las diferentes regiones sea más importante que la escala de los objetos de imagen.
Criterio para el establecimiento de homogeneidad
El parámetro de escala deine la homogeneidad de las regiones resultantes de la segmentación. Se calculan tres criterios principalmente: el color, la suavidad y la compacidad. El criterio de color es el más importante para crear objetos signiicativos. Cuando la homogeneidad es alta, normalmente mejora la calidad de la extracción de elementos, ya que, la compacidad de estos está asociada con el concepto de forma de la imagen (Awrangjeb et al., 2013). Lo anterior permite que los criterios de forma sean especialmente útiles para evitar resultados de unidades de interés altamente fracturadas. Si existe una resolución espacial alta, la probabilidad también lo es. En la Figura 4 , se muestra una aerofotografía con GSD de 3cms, que corresponde a una zona al norte de Bogotá, adquirida desde un hexacóptero a una altura de 100 metros con una cámara no métrica calibrada.

Forma
El análisis que se realiza, según este juicio, modiica la relación entre los criterios de forma y de color. La alteración de esta variable cuando presenta una cuantía numérica de 1, disminuye el porcentaje de valores espectrales de las capas de imagen que contribuyen al criterio de homogeneidad. Esto se pondera con el porcentaje de la semejanza de forma. Si se otorga un cambio del peso por el criterio de la forma a un valor numérico de 1, esto dará lugar a los objetos más optimizados para homogeneidad espacial. Sin embargo, el criterio de la forma no puede tener un valor numérico mayor de 0,9, debido a que, sin la información espectral de la imagen, los objetos resultantes no estarían relacionados con la información espectral (Ergun et al., 2014). Además de la información espectral, la homogeneidad objeto se está optimizando con respecto a la forma del objeto deinido por el parámetro de la compacidad.
Compacidad
Para poder optimizar el resultado inal de los objetos de imagen se utiliza la compacidad. Este criterio se debe utilizar cuando diferentes objetos de imagen, que son bastante compactos, están separados de objetos no compactos y solamente por un débil contraste espectral. En la figura 5 , se muestra una comparación de aerofotografía segmentada con un parámetro de criterios de homogeneidad, forma 0,1, compacidad 0,5. Adicionalmente, se presenta variación en el factor de escala para a) 800, b) 500, c) 300 y d) 100.

Segmentación de diferencia espectral
Este algoritmo fusiona los objetos de imagen vecinos, de acuerdo a los valores medios y a la capa de intensidad de la imagen, es decir, si la diferencia entre sus intensidades medias de capas está por debajo del valor dado por la diferencia espectral máxima, se fusiona (Ergun et al., 2014). Este algoritmo está diseñado para refinar los resultados de segmentación existente, mediante la fusión espectral de los objetos de imagen similares producidos por segmentaciones anteriores.
Ajustes de segmentación
Es posible deinir la máxima diferencia espectral teniendo en cuenta valores pancromáticos entre los objetos de imagen, los cuales son utilizados durante la segmentación. Si el valor de la diferencia es bajo, los objetos vecinos se fusionan (Sebari et al., 2013). A continuación, se presentan las ecuaciones [ 1 2 3 ] que representan la normalización de cada una de las capas de acuerdo con el peso asignado para cada una de ellas, en donde [k1; k2; k3] corresponden a las capas y [w] concierne al peso asignado.
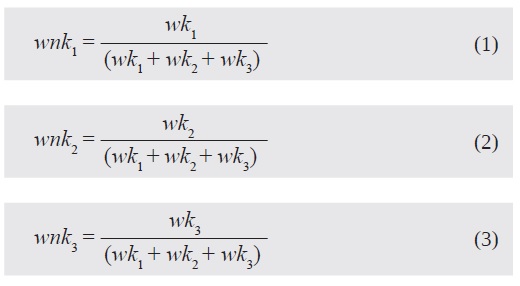
La ecuación 4 presenta la relación de los pesos de las capas de la imagen con sus valores de ponderación, en la que se deduce que a mayor sea el peso asignado a una capa de la imagen, más relevancia se le dará a la información de píxeles de la capa durante el proceso de segmentación. La expresión matemática (Abs) corresponde a la media de diferencias de vecinos. Esta característica describe la diferencia entre una imagen objeto y su imagen de objetos vecinos, en términos de sus valores medios de intensidad de la capa (Awrangjeb et al., 2013). También se puede utilizar una variable como un peso de la capa.
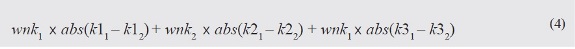
FASE III Extracción automática
Los insumos primordiales para la obtención de la cartografía de manera automática fueron básicamente dos: el primero, la imagen multiespectral obtenida con la cámara Vexel ultra Cam D; y, el segundo, la nube de puntos LIDAR, que fue convertida en una pseudoimagen, y representa el modelo Digital de supericie (Madhavan et al., 2006). La imagen cuenta con tres bandas espectrales (rojo, verde, azul). A esta se le realiza una segmentación por multiresolución, con el objetivo de evidenciar una discriminación de zonas con homo-geneidad y heterogeneidad. Posteriormente, se efectúa una primera clasiicación de las ediicaciones, teniendo como parámetro básico la altura de las mismas, dato extraído de la media del DSM, que para el desarrollo del presente trabajo se estableció mayor o igual a 2610 msnm. Como resultado se obtuvieron áreas que satisfacen esta condición de elevación.
A las áreas obtenidas se les realiza un análisis estadístico del comportamiento de la desviación estándar de las alturas de los elementos clasiicados anteriormente. Se asume que si los valores de la desviación estándar de las alturas tienen una dispersión baja, corresponde a techos de ediicaciones; si, por el contrario, la dispersión es alta, se trata de vegetación. Con este criterio se aplica un algoritmo matemático de asignación de clase, asumiendo que los elementos que tienen un valor de desviación estándar superior a 6 pertenecen a árboles. De esta manera, las áreas que anteriormente fueron clasiicadas como ediicios, y, por los valores de desviación estándar de DSM no lo son, se pueden sustraer (González, Rodriguez & Lagüela, 2012). Aunque la categorización de edificaciones mejora, es posible observar que aún se encuentra clasiicada parte de la vegetación como ediicios. Para mejorar este resultado, se realiza un reinamiento basado en información espectral, donde se utiliza la siguiente operación matemática entre bandas:

Después de aplicar la fórmula anterior, se muestran los lugares en donde existe vegetación. Esta información es útil para identiicar las zonas que aún siguen estando clasiicadas como ediicaciones y no lo son. Esto permite que se genere una clasiicación más acertada. Como la nueva clasiicación de ediicios presenta zonas en donde se evidencia que las construcciones no se encuentran completas en su geometría, es decir, no tienen una forma tan regular y deinida como en la realidad se presentan, se procede a realizar un refinamiento basado en contexto. Para este procedimiento se tiene en cuenta la relación del área con los píxeles vecinos. Al aplicar un algoritmo de asignación de clase y deinir una condición de umbral de relación de los bordes de los edificios, la geometría de la clasificación mejora sustancialmente (Awrangjeb et al., 2013). De esta manera, se llega a un resultado netamente automático y certero de las áreas que corresponden a edificaciones en la zona de estudio. En la figura 6 , se muestran diferentes imágenes que evidencian el proceso de segmentación y extracción automática de edificaciones. En a) Imagen rojo, verde, azul (RGB). b) Segmentación de imagen con parámetro de escala de 100. c) Clasificación de la imagen teniendo en cuenta los valores de las alturas del DSM. d) Realce de la vegetación obtenido por operación matemática de bandas. e) Resultado final, extracción automática de edificaciones, producto de la aplicación de diferentes algoritmos y refinamientos.

Conclusiones
Se puede afirmar que la extracción automática de elementos en fotografías aéreas e imágenes producto de sensores aerotransportados será, a mediano y largo plazo, uno de los métodos más utilizados para la generación de cartografía, gracias a su confiabilidad, su eficiencia y su rapidez en la obtención de elementos representativos del terreno.
En perspectiva general, la segmentación de imágenes es el punto de partida más importante, para brindar trabajos de alta precisión que deriven en productos cartográficos. La calidad de estos resultados es comparable con la de los obtenidos tradicionalmente mediante la restitución de modelos estereoscópicos. De los criterios elegidos para la realización de la segmentación depende la homogeneidad o la heterogeneidad de las regiones segmentadas. Esto va a redundar en la facilidad para realizar refinamiento y establecer algoritmos acertados que permitan el mejoramiento de la clasificación realizada.
La metodología propuesta e implementada en el desarrollo de este trabajo puede ser mejorada, de acuerdo a la finalidad que se tenga, y dependiendo de los elementos que se requieran extraer en las imágenes digitales. Los resultados aquí planteados fueron comprobados en el terreno directamente, y se concluyó que el nivel de confianza en la clasificación final, extraída automáticamente, equivale a 97,2%. Al indicar esto, es claro que los resultados obtenidos son confiables, puesto que de cada 100 píxeles clasificados de manera automática, después de aplicar el método propuesto, por lo menos 97 de ellos fueron clasificados correctamente, si se compara con la realidad de las mediciones directas del terreno.
1 Este grupo de investigación es dirigido por William Barragán Zaque y, desde 2007, desarrolla sus actividades en la Universidad Distrital Francisco José de Caldas en Bogotá. El grupo cuenta con el apoyo del proyecto curricular de Ingeniería topográfica y la maestría en Ciencias de la información y las comunicaciones con énfasis en Geomática. Sus áreas de trabajo se han concentrado en los temas relacionados con Geomática.
2 Esta confiabilidad se estimó con base en el margen de error comparativo simple que existe entre el área de interés medida en campo directamente mediante técnicas que incorporan altos estándares de calidad (posicionamiento global, en donde señales múltiples se reciben simultáneamente desde diversas posiciones de satélites, corrigen ambigüedades y permiten la determinación de la posición tridimensional de puntos con precisión milimétrica), y el área obtenida mediante esta investigación, después de aplicar sus respectivos reinamientos.
3 Cámara métrica digital aérea, propiedad del Instituto Geográfico Agustín Codazzi - IGAC
4 Permite obtener datos de posicionamiento de una foto con respecto a un punto de referencia fijo en tierra, identificando cambios en rotación conocidos como: pitch, roll y yaw.
5 Es un algoritmo de segmentación que divide el dominio de píxeles o un dominio objeto de imagen en objetos de imagen cuadrados. La característica particular es que la segmentación de la imagen digital se presenta con cuadrados de igual tamaño, similar al tablero de un ajedrez. El tamaño de los cuadros es definido en los parámetros de escala.
6 Es un algoritmo de segmentación que divide el dominio de píxeles o un objeto de imagen dominio en una red formada por objetos cuadrados de diferente tamaño. Se aplica a todos los objetos en el dominio y cada objeto se corta a lo largo de las líneas de división. Cada cuadrado tiene un tamaño máximo posible y cumple los criterios de homogeneidad definidos en los parámetros de escala. El tamaño máximo de objeto cuadrado es de 256 x 256, o 65.536 píxeles.
7 Segmentación basada en comparación por parejas. Se refiere a cualquier proceso de comparación de las entidades en pares, para juzgar la entidad preferida, o la que tiene una mayor cantidad de alguna propiedad cuantitativa. El método de comparación por pares se utiliza en el estudio científico de las preferencias, actitudes, y sistemas multiagente de Inteligencia Artificial.
8 Un bucle o loop, en programación, es una sentencia que se realiza repetidas veces a una parte del código, generando iteraciones hasta que la condición deje de cumplirse.
Referencias
Awrangjeb, M., Zhang, C. & Fraser, C. S. (2013). Automatic extraction of building roofs using LIDAR data and multispectral imagery. ISPRS Journal of Photogram-metry and Remote Sensing 83, 1-18. doi: http://dx.doi.org/10.1016/j.isprsjprs.2013.05.06 [ Links ]
Barragán, W. (2013). Historical documentation in San Agustin (Huila), Colombia, world historical heritage using close range photogrammetry techniques. Taking the Benefits of Geographic Information Technologies 93, Applied Geoinformatics for Society and Environment (AGSE Conferences) Stuttgart. [ Links ]
Bucksch, A. & Lindenbergh, R. (2008). CAMPINO A skel-etonization method for point cloud processing. Journal of Photogrammetry and Remote Sensing 63(1), 115-127. doi: http://dx.doi.org/10.1016/j.isprsjprs.2007.10.004 [ Links ]
Ergun, B., Sahin, C., & Ustuntas, T. (2014). Segmentation and determination of grid points of curve points in terrestrial laser scanning data for regular curve surfaces via C-means integrated fuzzy logic approach. Optics and Lasers in Engineering 52, 261-268. doi: http://dx.doi.org/10.1016/j.optlaseng.2013.04.020 [ Links ]
Gamanya, R., Maeyer, P, & Dapper, M. (2009). Object-oriented change detection for the city of Harare, Zimbabwe. Expert Systems with Applications 36(1), 571-588. doi: http://dx.doi.org/110.1016/j.eswa.2007.09.067 [ Links ]
García-San-Miguel, D. & Lerma, J. L. (2013). Geometric calibration of a terrestrial laser scanner with local additional parameters: An automatic strategy. Journal of Photogrammetry and Remote Sensing 79, 122-136. doi: http://dx.doi.org/10.1145/2181037.218107510.1016/j.isprsjprs.2013.02.007 [ Links ]
González-Aguilera, D., Rodriguez-Gonzalvez, P., Armesto, J., & Lagüela, S. (2012). Novel approach to 3D thermography and energy efficiency evaluation. Energy and Buildings 54, 436-443. doi: http://dx.doi.org/10.1016/j.enbuild.2012.07.023 [ Links ]
Guarnieri, A., Vettore, A., Camarda, M., & Domenica, C. (2011). Automatic registration of large range datasets with spin-images. Journal of Cultural Heritage 12(4), S. 476-484. doi: http://dx.doi.org/10.1016/j.culher.2011.03.010 [ Links ]
Hermosilla, T., Ruiz, L.A., Fdez. Sarriá, A., & Recio, J.A. (2008, febrero). Detección automática de edificios en imágenes aéreas mediante técnicas de teledetección y análisis contextual. Ponencia presentada en el Congreso Internacional sobre Ingeniería Geomática y Topográfica, TOP-CART 2008. Valencia, España. [ Links ]
Jung, J., Hong, S., Jeong, S., Kim, S., Cho, H., Hong, S., & Heo, J. (2014). Productive modeling for development of as-built BIM of existing indoor structures. Automation in Construction 42, 68-77. doi: http://dx.doi.org/10.1016/j.autcon.2014.02.021 [ Links ]
Kabolizade, M., Ebadi, H., & Ahmadi, S. (2010). An improved snake model for automatic extraction of buildings from urban aerial images and LiDAR data. Computers, Environment and Urban Systems 34(5), 435-441. doi: http://dx.doi.org/10.1145/2181037.218107510.1016/j.compenvurbsys.2010.04.006 [ Links ]
Lim, E. H. & Suter, D. (2009). 3D terrestrial LIDAR classifications with super-voxels and multiscale Conditional Random Fields. Computer-Aided Design 41(10), 701-710. doi: http://dx.doi.org/10.1016/j.cad.2009.02.010 [ Links ]
Madhavan, B., Wang, C., Tanahashi, H., Hirayu, H., Niwa, Y., & Yamamoto, K. (2006). A computer vision based approach for 3D building modelling of airborne laser scanner DSM data. Computers, Environment and Urban Systems 30(1), 54-77. doi: http://dx.doi.org/10.1016/j.compenvurb- sys.2005.01.001 [ Links ]
Martínez, J., Soria-Medina, A., Arias, P., & Buffara-Antunes, A. F. (2012). Automatic processing of Terrestrial Laser Scanning data of building façades. Automation in Construction 22, 298-305. doi: http://dx.doi.org/10.1016/j.autcon.2011.09.05 [ Links ]
Minetto, R., Thome, N., Cord, M., Leite, N. J., & Stolfi, J. (2014). SnooperText: A text detection system for automatic indexing of urban scenes. Computer Vision and Image Understanding 122, 92-104. doi: http://dx.doi.org/10.1016/j. cviu.2013.10.004 [ Links ]
Nga, D. H. & Yanai, K. (2014). Automatic extraction of relevant video shots of specific actions exploiting Web data. Computer Vision and Image Understanding 118, 2-15. doi:http://dx.doi.org/10.1016/j.cviu.2013.03.009 [ Links ]
Qin, R. & Gruen, A. (2014). 3D change detection at street level using mobile laser scanning point clouds and terrestrial images. Journal of Photogrammetry and Remote Sensing 90, 23-35. doi: http://dx.doi.org/10.1016/j.isprsjprs.2014.01.006 [ Links ]
Sebari, I. & He, D. C. (2013). Automatic fuzzy object-based analysis of VHSR images for urban objects extraction. Journal of Photogrammetry and Remote Sensing 79, 171-184. doi: http://dx.doi.org/10.1016/j.isprsjprs.2013.02.006 [ Links ]
Triglav ekada, M., Zorn, M., & R. Colucci, R. (2014). Changes in the area of the Canin (Italy) and Triglav glaciers (Slovenia) since 1893 based on archive images and aerial laser scanning. geod. vestn. 58(02), 274-313. doi: http://dx.doi.org/10.15292/geodetski-vestnik.2014.02.274-313 [ Links ]

