










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkInnovar
Print version ISSN 0121-5051
Innovar vol.24 no.51 Bogotá Jan./Mar. 2014
https://doi.org/10.15446/innovar.v24n51.41236
http://dx.doi.org/10.15446/innovar.v24n51.41236
Relación entre la creación de valor y la inversión en I+D: una aproximación mediante redes neuronales artificiales
The Relationship Between The Creation Of Value And Investment In R & D: An Approach Employing Artificial Neural Networks
Relation Entre La Création De Valeur Et L'investissement En I + D: Une Approche À L'aide De Réseaux De Neurones Artificiels
Relação Entre A Criação De Valor E O Investimento Em P+D: Uma Aproximação Mediante Redes Neurais Artificiais
Ángel Samaniego AlcántarI, Samuel MongrutII
IProfesor-Investigador, ITESO. Correo electrónico: asamanie@iteso.mx
IIProfesor de la Escuela de Graduados del Tecnológico de Monterrey, Campus Querétaro, México. Profesor asociado del Centro de Investigacion de la Universidad del Pacífico (CIUP), Lima, Perú. Correo electronico: smongrut@itesm.mx
Recibido: febrero de 2012 Aprobado: julio de 2013
Resumen:
Este documento proporciona nueva evidencia sobre la interacción de los efectos del tipo de interés a cinco años, el nivel de apalancamiento (la relación del pasivo y activo), las pérdidas históricas, el crecimiento del PIB, la intensidad del gasto en I+D y los ingresos con el rendimiento de la acción en el corto plazo. El modelo no lineal utilizado (combinación de modelos mediante redes neuronales artificiales) explica 31.59% de la varianza del rendimiento de las acciones en los primeros 5 meses del año, entre 2000-2006, en los mercados AMEX, NASDAQ y NYSE. Existe evidencia en la literatura que el 32% de explicación es alto, en comparación al estudio de la literatura realizado por Coad (2009) donde se utilizan modelos lineales que buscan explicar el crecimiento de la empresa. Se observa que los modelos lineales explican entre el 17% al 32% de la variabilidad de los datos. Al igual que en los trabajos de Bode (1998), Tsai (2005), Wang y Chien (2006) y Chien et al. (2010) se utilizan las redes neuronales artificiales para el estudio de la interacción entre la I+D y la empresa.
Palabras clave: redes neuronales artificiales, inversiones en I+D, crecimiento económico.
Abstract:
This paper provides new evidence concerning the interactions between the effects of five year interest rates, leverage levels (the relationship between assets and liabilities), historical losses, Gross National Product (GNP) growth, levels of investment in Research and Development (R&D), income and short-term share returns. The research was carried out using a non-linear model in which neural networks were used to combine different models. The model predicted 31.59% of variation in the returns on shares traded in the AMEX, NASDAQ and NYSE markets during the first five months of all years between 2000 and 2006. The literature suggests that a 32% level of explanation is at the high end, Coad's (2009) literature review of models used to explain company growth finding that linear models explained between 17 and 32% of variability. Like Bode (1998), Tsai (2005), Wang & Chien (2006) and Chien, Wang & Lin (2010) this paper uses artificial neural networks to examine the interaction between R&D and company performance.
Key words: Artificial neural networks, investment in R&D, economic growth.
Résumé:
Ce document fournit une nouvelle évidence sur l'interaction des effets du type d'intérêts à cinq ans, le niveau de levier financier (la relation entre passif et actif), les pertes historiques, la croissance du Produit Intérieur Brut (PIB), l'importance de la dépense en Investigation et Développement (I + D) et les rentrées avec le rendement de l'action à court terme. Pour cette investigation, un modèle non linéaire a été utilisé (combinaison de modèles par des réseaux de neurones artificiels) qui explique 31,59 % de la variance du rendement des actions dans les cinq premiers mois de l'année, entre 2000 et 2006, sur les marchés AMRX, NASDAQ et NYSE. Il se dégage des publications sur le sujet que 32 % des explications est un bon niveau comparativement à l'étude des publications faite par Coad (2009) utilisant des modèles linéaires qui cherchent à expliquer la croissance de l'entreprise. On constate que les modèles linéaires expliquent entre 17 % et 32 % de la variabilité des données. De même que dans les travaux de Bode (1998), Tsai (2005), Wang & Chien (2006) et Chien, Wang & Lin (2010), on utilise des réseaux de neurones artificiels pour l'étude de l'interaction entre I + D et l'entreprise.
Mots-clés: réseaux de neurones artificiels, investissement en I + D, croissance économique.
Resumo:
Este documento proporciona nova evidência sobre a interação dos efeitos do tipo de juros a cinco anos, o nível de alavancagem (a relação do passivo e ativo), as perdas históricas, o crescimento do Produto Interno Bruto (PIB), a intensidade do gasto em Pesquisa e Desenvolvimento (P+D) e os ingressos com o rendimento da ação no curto prazo. Para esta pesquisa, fez-se uso de um modelo não linear (combinação de modelos mediante redes neurais artificiais) que explica 31,59% da variação do rendimento das ações nos primeiros cinco meses do ano, entre 2000-2006, nos mercados AMEX, NASDAQ e NYSE. Existe evidência na literatura de que 32% de explicação é alto, em comparação com o estudo da literatura realizado por Coad (2009), no qual se utilizam modelos lineares que buscam explicar o crescimento da empresa. Observa-se que os modelos lineares explicam entre 17 e 32% da variabilidade dos dados. Assim como nos trabalhos de Bode (1998), Tsai (2005), Wang & Chien (2006) e Chien, Wang & Lin (2010), utilizam-se as redes neurais artificiais para o estudo da interação entre a P+D e a empresa.
Palavras chave: redes neuronais artificiais, investimentos em P+D, crescimento econômico.
Introducción
A partir del trabajo seminal de Solow (1957) existe un consenso entre académicos que gira en torno al postulado de que la inversión en investigación y Desarrollo (I+D) incrementa la productividad y favorece el crecimiento económico (Griliches, 1995 y Stokey, 1995). Por otra parte, existe abundante evidencia empírica de que la inversión en I+D promueve las actividades innovadoras en las empresas (Dosi, 1988 y Freeman & Soete, 1997).
A su vez, Irwin, Hoffman & Lamont (1998) y Hall & Bagchi-Sen (2002) verificaron que las adquisiciones de innovaciones tecnológicas mejoran el desempeño financiero de las empresas, lo que en la literatura se denomina I+D en productos, a diferencia de I+D en procesos.
La inversión en I+D no solo es importante por su conexión directa con el crecimiento económico, la productividad y el desempeño financiero empresarial, sino también porque, a pesar de lo anterior, su aplicación a nivel mundial se encuentra concentrada en pocos países. De acuerdo con el 2010 R&D Scoreboard Report1 el 78% de la inversión global en I+D ocurre únicamente en cinco países: Estados Unidos, Japón, Alemania, Francia y el Reino Unido. Más aún, la intensidad de la inversión en I+D (gasto de I+D como proporción de las ventas) es del 3.6% (BIS, 2010).
Lo anterior es realmente paradójico debido a que se ha demostrado que un incremento en la inversión en I+D generalmente ofrece rendimientos entre el 10% y 15% o mayores (Hall, 1996 y Hall, Mairesse & Mohnen 2009). Es precisamente debido a este último hallazgo que el principal objetivo del presente trabajo se concentra en la identificación de los factores que influyen sobre el rendimiento accionario de las empresas y que provocan que los inversionistas las compren en el corto plazo, caracterizando por aumentos o disminuciones en el gasto en I+D, así como por otros factores, a través de un modelo no lineal.
La principal contribución de esta investigación es justamente la utilización de un modelo no lineal para la predicción de los rendimientos accionarios en el contexto de inversiones en I+D. La utilización de modelos no lineales en este contexto ha sido sugerido por la literatura previa en diferentes contextos, por ejemplo, Tsai (2005) indicó que existe una relación no lineal entre la productividad de la inversión en I+D y el tamaño de la empresa.
Más aún, existen diversos autores que han utilizado modelos no lineales en el contexto de las actividades de I+D, pero desde diversas perspectivas, por ejemplo, Bode (1998) indicó que es más apropiado utilizar las arquitecturas de las redes neuronales para la gestión de las actividades de I+D, porque tienden a ser más simples, con menor complejidad y se requiere un bajo número de entrenamientos.
Por su parte Wang & Chien (2006) sugieren la utilización de una red neuronal de retropropagación (back propaga tion) para pronosticar los resultados de la innovación. Los resultados de estos autores indican que esta arquitectura de red neuronal tuvo un desempeño superior a los métodos de regresión en términos de pronóstico.
Posteriormente, Chien et al. (2010) propusieron el modelo neurofuzzy, que es una combinación de lógica borrosa con redes neuronales, para pronosticar los resultados de la innovación. Los autores encontraron que este nuevo modelo superaba en desempeño al modelo propuesto anteriormente, basado únicamente en redes neuronales. Por esta razón, la literatura asociada a los temas de I+D está implementando cada vez más modelos no lineales, ya que estos poseen un mayor poder explicativo y permiten un mayor acierto en el pronóstico.
El presente documento contiene una sección en la que se reseñan las investigaciones en torno a la inversión en I+D, donde se procura evidenciar una relación entre este aspecto y el rendimiento accionario de las empresas (mediante el denominado estudio de eventos), por una parte, y el valor de la empresa (mediante modelos lineales), por otra. En la siguiente sección se reseñan investigaciones emblemáticas que utilizan las Redes Neuronales Artificiales (RNA) en el contexto financiero, ya que -según nuestro conocimiento- no existen trabajos que las utilicen simultáneamente en el contexto financiero y con inversión de I+D. En las dos siguientes secciones, se describe la data utilizada y se presentan los modelos lineales y no lineales que serán comparados en la estimación, respectivamente. Para terminar, se discuten los resultados y se concluye el trabajo.
Estudio de la literatura
En la literatura se encuentran varios trabajos donde la innovación se evidencia como una señal de oportunidades de crecimiento empresarial, aunque no está muy claro qué factores externos al anuncio propician la credibilidad del inversionista antes de que los proyectos asociados a estos anuncios obtengan resultados reales. Como se comentó, las inversiones en I+D juegan un papel clave en la innovación empresarial y su anuncio puede provocar que el inversionista bursátil invierta en este tipo de empresas.
Para el mediano plazo, Chan et al. (2001) examinaron la intensidad del I+D (en valor) y observaron que el mercado es pesimista cuando empresas de alta tecnología disminuyen su gasto en esta área. Además este tipo de empresas posee una alta relación entre el gasto en I+D y el valor de sus activos (a valor de mercado) y experimentan altos rendimientos futuros (3 años).
En largo plazo, Eberhart, Maxwell & Siddique (2004) examinaron eventos mayores al 5% de incremento en la intensidad de I+D (en cambios porcentuales), encontrando una baja reacción del inversionista ante este evento en un plazo de 5 años.
McNamara & Baden-Fuller (2007) estudiaron el efecto en los rendimientos accionarios producidos por 1277 anuncios de gastos en I+D, dados por 178 empresas farmacéuticas en tres etapas del desarrollo en I+D: pruebas pre-clínicas, pruebas clínicas en seres humanos y explotación comercial. Los autores encontraron rendimientos anormales entre 3 y 4%, siendo superiores en la etapa inicial para empresas de menor tamaño e iguales en todas las etapas para empresas de gran tamaño.

Moltchanski, Nagm & Powell (2010) estudiaron la respuesta del mercado de capitales australiano, durante el periodo 1994-2006, ante anuncios de gastos de I+D, anuncios de gastos de capital (CAPEX) y anuncios de gastos en Tecnología de la Información (TI). Mediante un estudio de eventos encontraron rendimientos anormales acumulados entre 3 y 5%, asociados a los gastos en I+D y TI.
Samaniego, Trejo-Pech, Mongrut y Fuenzalida (2011) encontraron evidencia de rendimientos anormales positivos en el corto plazo (9 días) ante incrementos en la intensidad del I+D (cambios en valor absoluto), pero no evidencia estadísticamente significativa de rendimientos anormales positivos ante decrementos en le intensidad de I+D. Además, para empresas clasificadas como de alta tecnología la reacción era mayor.
Alternativamente, otros autores decidieron estudiar la relación entre el valor de la empresa u otra variable aproximada con las inversiones (o gastos) en I+D, haciendo uso de otras variables como tamaño y concentración de propiedad. Lo interesante es que todos los estudios han utilizado modelos lineales.
Chauvin & Hirschey (1993) estudiaron los efectos de los gastos en publicidad y en I+D en el valor de mercado del patrimonio común de las empresas Utilizando data de empresas de Estados Unidos de Norteamérica para el periodo 1988 y 1990, mediante una regresión de mínimos cuadrados ordinarios, encontraron que ambas variables influyen sobre el valor de mercado del patrimonio de las empresas estudiadas. Por otra parte, Johnson & Pazderka (1993) estudiaron también la relación entre el valor de la empresa y el gasto en I+D, para lo que utilizaron una muestra de 47 empresas canadienses desde 1985 hasta 1988 con el modelo de regresión de mínimos cuadrados ordinarios. Los autores encontraron una relación consistentemente positiva entre el valor de mercado del patrimonio de las empresas y el gasto en I+D.
Bae & Kim (2003) estudiaron la relación entre la intensidad en I+D y el valor de las empresas en Estados Unidos de Norteamérica, Alemania y Japón. Para ello utilizaron 3.324 empresas de Estados Unidos, 384 empresas de Alemania y 1.181 empresas japonesas, durante el periodo 1996-1998. Utilizando un modelo de corte trasversal, encontraron una relación positiva y estadísticamente significativa entre el ratio valor de mercado/valor en libro y la intensidad en I+D en los tres países.
Ho, Tjahjapranata & Yap (2006) estudiaron las relaciones entre el ratio valor en libros y valor de mercado (market-to-book), a partir de cuatro factores: a) el tamaño de la empresa, b) el sector donde se concentra la empresa, c) el nivel de apalancamiento y d) el gasto en I+D. Encontraron allí que el inversionista valoraba mejor el gasto en I+D en empresas grandes, sólo cuando éstas tenían un apalancamiento bajo: si el apalancamiento era alto, el inversionista valoraba mejor a las empresas pequeñas. El nivel de concentración en el sector no era significativo y el modelo lineal explicaba el 5% de la varianza total.
Nagaoka (2006) investigó la relación entre el gasto en I+D y el valor de las empresas japonesas que cotizaron en el mercado electrónico japonés entre 1991 y el 2000. Utilizando un modelo de datos de panel no balanceado, bajo diferentes especificaciones del modelo, encontró que los gastos de I+D se asociaron positivamente con el valor de la empresa durante el periodo estudiado.
Hall y Oriani (2006), utilizaron una muestra con datos de panel de empresas industriales que cotizaron en los mercados bursátiles de Francia, Alemania, Italia, Reino Unido y Estados Unidos, durante el periodo 1989 y 1998. Con esta muestra, los autores mostraron que el coeficiente de los gastos en I+D en todos los países, con excepción de Italia, era estadísticamente significativo, a partir de factores como activos intangibles y ventas rezagadas en un periodo.
Poletti (2008) estudió la relación entre los gastos en I+D y los pagos de dividendos con el valor de las empresas. Para ello, utilizó una muestra de 8.559 observaciones de empresa-año del Reino Unido, bajo un modelo de datos de panel para el periodo 1994-2005. La autora encontró una relación positiva entre el ratio valor de mercado/valor en libros y el gasto en I+D, y entre el ratio valor de mercado/valor en libros y el pago de dividendos.
Duqi & Torluccio (2010) investigaron la relación entre los gastos en I+D y el valor de mercado de 416 empresas europeas (Reino Unido, Alemania, Francia, Suecia e Italia), listadas en los mercados de capitales durante el periodo 2001 y 2007. Mediante un modelo de datos de panel, estos autores encontraron una positiva influencia entre los gastos en I+D y el valor de la empresa, siendo el efecto más fuerte en empresas jóvenes que operan en sectores de alta tecnología.
Ehie & Olibe (2010) utilizaron un modelo de corte trasversal para estudiar la relación entre la intensidad de los gastos en I+D y el valor de la empresa, medido por el ratio de capitalización bursátil sobre ventas totales. Para probar esta relación, hicieron uso de una muestra de 26.500 empresas-año de Estados Unidos para el periodo de 1990-2007. A partir de esta investigación, encontraron que cerca del 14% de las variaciones en el valor de la empresa podían ser atribuibles a las variaciones en la intensidad del gasto en I+D.
La revisión de la literatura anterior muestra que ante los anuncios de gastos en I+D ocurre una reacción positiva del mercado, presentándose rendimientos anormales positivos, más aún, existe una relación robusta -en términos lineales- entre el gasto en I+D y el valor de la empresa medida de distintas maneras. No obstante, el poder explicativo suele ser bajo, entre el 5% y 14% del valor de la empresa es explicado por los modelos lineales. Luego existe la posibilidad de explicar los rendimientos bursátiles (es una variable más directa para el inversionista) utilizando el gasto en I+D con un modelo no lineal, (por ejemplo, redes neuronales) y así obtener un mayor poder explicativo.
Antecedentes de las Redes Neuronales Artificiales (RNA)
La complejidad del mundo real va más allá de la linealidad. Existen trabajos empíricos donde se comparan los modelos lineales contra los no lineales. Kanas (2001) examina el desempeño de modelos lineales y de RNA en la predicción del índice Dow Jones (DJ) y el Financial Times (FT)2, resultando superior la predicción de la dirección del rendimiento en los modelos no lineales, y mostrándose evidencia de una relación no lineal entre variables rezagadas en el tiempo (porcentaje de cambio del volumen negociado y porcentaje de cambio en dividendos) y los rendimientos de las acciones.
Olson & Mossman (2003) compararon la predicción mediante RNA contra mínimos cuadrados ordinarios y la regresión logística. La predicción es a un año para acciones del mercado canadiense, utilizando 61 razones financieras. Dicha comparación dio como resultando las RNA bajo una estructura de retropropagación, que predicen mejor que los modelos lineales.
Igualmente se pueden encontrar estudios en la literatura relacionados con el uso de las RNA en las finanzas y sus comparativos con modelos lineales. Zhang, Patuwo & Hu. (1998) trabajan sobre modelos de RNA aplicados a la predicción; Huang, Lai, Nakamori & Wang (2004), sobre modelos aplicados a la predicción del tipo de cambio; Vellido, Lisboa, P. & Vaughan (1999), sobre modelos aplicados a la administración; Wong & Selvi (1998), sobre aplicaciones a la administración; Chatterjee, Ayadi, F. & Boone (2000), sobre modelos de RNA utilizados en los mercados financieros; Fadlalla & Lin (2001), sobre tendencias de las aplicaciones de RNA en finanzas.
Esta complejidad va acompañada por información parcial e información irrelevante, sumando ruido al modelo, lo cual provoca la aplicación de técnicas no lineales para modelar toda esta complejidad. Algunas de las razones por las que se eligen las RNA son: 1) por su capacidad de establecer las relaciones no lineales entre las variables de entrada (peso de cada factor) y la(s) variable(s) de salida (variable dependiente); 2) pueden aproximarse a cualquier función continua, y 3) llegan a generalizar sus resultados, entre datos para su aprendizaje y datos para la prueba del modelo.
En la literatura se puede encontrar la integración de RNA y otros métodos complejos para la predicción de la economía y las finanzas, como los algoritmos genéricos, análisis wa velet, lógica borrosa, reconocimiento de patrones y modelos de series de tiempo, entre otros. Igualmente existen trabajos donde se combinan diferentes métodos para mejorar el modelo de predicción. Además, se ha observado que la integración de RNA con otros métodos complejos mejora el modelo de predicción.
Datos utilizados
Se utilizaron las bases de datos de COMPUSTAT, Center for Research in Security Prices (CRSP) e International Sta tistical Yearbook, proporcionado por DSI (Data & Services & Information) entre 1999 y 2006, con un total de 17.234 observaciones.
Las observaciones de COMPUSTAT se filtran a reportes financieros anuales de empresas activas con ventas y activos mayores a 1 millón de dólares (USA). Específicamente los datos anuales utilizados fueron valor en libros (ítem 60), total de activos (ítem 6), gastos en I+D (ítem 46), total pasivo (ítem 181), capital circulante (ítem 4), pasivo circulante (ítem 5), depreciación (ítem 14), utilidad neta (ítem 172) y utilidad de la operación antes de impuestos (ítem 170). De CRSP, se utiliza la tasa de rendimiento de la acción en los primeros 5 meses del año. Por último, de DSI se usa el crecimiento anual del Producto Interno Bruto (PIB) (ítem S201), la tasa a corto plazo en promedio del último mes del año (ítem S201) y la tasa a largo plazo del último mes del año (ítem S202).
Los datos anteriores se utilizaron para calcular las variables del modelo de predicción del rendimiento de las empresas. Estas variables se seleccionaron a partir de los trabajos de Huang, Lai, Nakamori & Yu (2007), Ho et al. (2006), Ohlson (1980) y Samaniego et al. (2008). Se realizan pruebas con diferentes combinaciones de variables de los trabajos anteriores dentro de un modelo lineal. Posteriormente se seleccionan las variables para un mayor análisis (ver Tabla 1).3
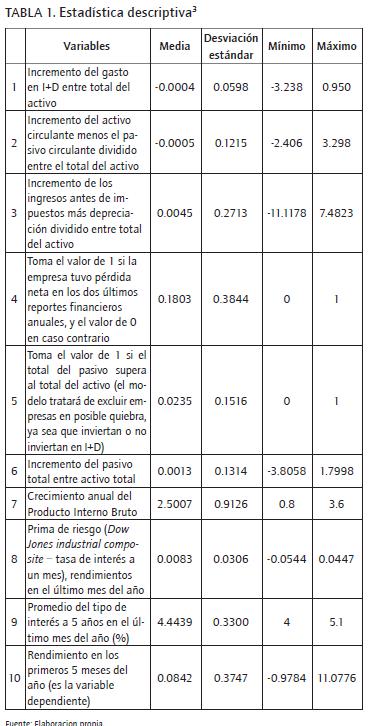
Las variables relacionadas con los resultados de la empresa cumplen con 3 características principales: 1) su valor es diferente de cero si existe un cambio de un año a otro, ya que si no hay cambio en los flujos futuros de la empresa no tiene por qué existir un incremento en el valor de la empresa y por consecuencia un rendimiento de la acción; 2) su valor es comparable con el resto de las empresas, sin importar el tamaño y la volatilidad del rendimiento; 3) los factores que multiplican a cada variable son significativamente diferentes de cero dentro del modelo (ver Ecuación 1).
Con la finalidad de cumplir con la primera característica, se utilizan incrementos; para cumplir con la segunda, se dividió la variable entre el total de activos (para diferenciar tamaños de empresa) y se multiplica por (1+σi) para diferenciar entre los riesgos de las empresas.
Se podría pensar que para cumplir con la primera característica se deben utilizar cambios porcentuales. Un problema con ello es que no se puede cumplir con la segunda característica. Por ejemplo, suponiendo 2 empresas iguales, donde la única diferencia es lo que se gasta en I+D, en un año ambas tienen a un cambio porcentual del 11.11% en esta variable. Esto se logró con los siguientes valores (10 - 9)/9 y (1,000 - 900)/900 respectivamente. En la primera empresa significó un aumento en una unidad monetaria para lograrlo, contra 100 unidades monetarias en la segunda empresa. El esfuerzo de la segunda empresa por incrementar este gasto fue mayor, lo cual no se refleja en el cambio porcentual.
El modelo que predice el rendimiento de la empresa en los primeros 5 meses es el siguiente:
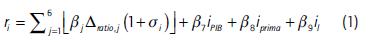
donde:
ri es el rendimiento en los primeros 5 meses del año de la empresa i.
 es la multiplicación de cada factor por el incremento (decremento) de los ratios de la empresa de la Tabla 1 (primeras 6 variables) por uno, más la desviación estándar del precio de la acción.
es la multiplicación de cada factor por el incremento (decremento) de los ratios de la empresa de la Tabla 1 (primeras 6 variables) por uno, más la desviación estándar del precio de la acción.
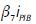 es el factor por el crecimiento del PIB.
es el factor por el crecimiento del PIB.
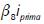 es el factor por la prima de riesgo del mercado.
es el factor por la prima de riesgo del mercado.
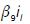 es el factor por el tipo de interés a 5 años.
es el factor por el tipo de interés a 5 años.
Después de obtener los factores (coeficientes) dentro de un modelo de RNA (combinación de modelos lineales y no lineales) se selecciona la mejor combinación y se calcula el valor de probabilidad (p-value) para identificar la significancia de cada factor para cumplir con la tercera característica indicada arriba.
Metodología de investigación
Coad (2009) realiza un estudio de la literatura de modelos que expliquen el crecimiento de la empresa. Se observa que los modelos donde existe la variable innovación se obtienen un R2 entre el 17 y el 32%. Las bondades de estos modelos lineales es la facilidad de su interpretación, donde el valor de cada factor muestra la relación con la variable dependiente. El supuesto del modelo lineal es que los factores tienen una relación lineal con la variable dependiente.
El riesgo, la incertidumbre y la calidad de las variables utilizadas son fundamentos importantes para el estudio del crecimiento de las empresas. Estas variables pueden ponderarse aun más por las transformaciones dinámicas del entorno de la empresa, como por ejemplo, la introducción de nuevas innovaciones por los competidores y el cambio que sufre la empresa a través del crecimiento, el cual muchas veces no se puede manejar (Coad, 2009), cuya complejidad -propia de su estudio- puede ser ocasionada por la interacción no lineal de sus variables.
Bajo el supuesto anterior, se aplican las RNA y se espera que explique en mayor medida la inestabilidad de la variable dependiente. La limitación principal de este tipo de modelos es que no muestra claramente la relación entre las variables, así que hay que realizar otro procedimiento computacional (derivadas parciales) para encontrar esta relación. Al igual que en los modelos lineales, su debilidad principal es encontrar relaciones entre variables que en realidad no existe (relación espuria). Y dependiendo del tipo de RNA, es necesaria una gran cantidad de datos para utilizar estos modelos.
Para la búsqueda de la estructura de la RNA que mejor obtiene conocimiento de los datos, en este estudio, se selecciona entre un modelo de regresión lineal, quince modelos de RNA del tipo MLP (Multi-layer Perception), un modelo que combina un método lineal ACP (Análisis de Componentes Principales) con uno de RNA, y un modelo que combina tres RNA-MLP en la entrada con una RNA en la salida (Meta-learning del tipo 2). Las ecuaciones a resolver, con las metodologías indicadas anteriormente, se indican a continuación4.
Modelo de regresión lineal
Se busca minimizar el error estándar entre el real y el esperado.
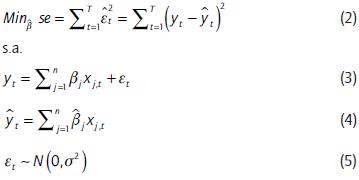
Siendo Minβ la función a minimizar y cambiando los parámetros a estimar 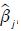 , esta función es la suma de los errores al cuadrado, de tal modo que la variable dependiente (rendimiento de la acción en los primeros 5 meses del año) yt se explica por n número de variables independientes, xi es la variable independiente, βj es el coeficiente y
, esta función es la suma de los errores al cuadrado, de tal modo que la variable dependiente (rendimiento de la acción en los primeros 5 meses del año) yt se explica por n número de variables independientes, xi es la variable independiente, βj es el coeficiente y 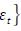 es el error. El rendimiento estimado
es el error. El rendimiento estimado 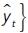 tiene una distribución normal N en los errores con media cero y varianza σ2 constante.
tiene una distribución normal N en los errores con media cero y varianza σ2 constante.
Modelos no lineales5
RNA-MLP (m,1) con m neuronas en la capa oculta y 1 neurona en la capa de salida, la función de transferencia es tangente sigmoidea6 en la capa oculta, la función de transferencia es lineal en la capa de salida, sin sesgo en ambas capas, la función del desempeño se da mediante el error cuadrado medio (mse). La RNA se entrena con el algoritmo de Levenberg Marquardt, método de optimización y aprendizaje donde se cambian los pesos de cada variable para mejorar los resultados.
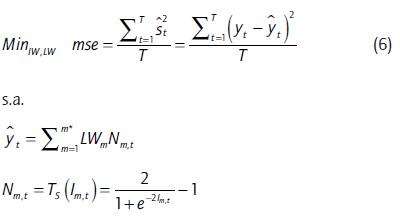

Donde LWm son los pesos de la capa de salida, IWm,j son los pesos de la capa de entrada, m son las neuronas en la capa oculta y n el número de variables independientes, TS es una función tangente sigmoidea.
Meta-learning mediante la combinación de modelos lineales y no lineales
En está sección se aplica ACP para la selección de los modelos de RNA a utilizar. De los resultados  en los 15 modelos de RNA-MLP, se calculan las componentes que explican la varianza entre los resultados y se toman las 3 primeras componentes del ACP que explican la mayor varianza. Cada componente utiliza las 15 variables asignándoles un peso (relación lineal); cuanto mayor sea el peso, mayor influencia tiene la variable (o RNA-MLP) en esa componente. Posteriormente se utiliza una RNA con las 3 componentes del ACP.
en los 15 modelos de RNA-MLP, se calculan las componentes que explican la varianza entre los resultados y se toman las 3 primeras componentes del ACP que explican la mayor varianza. Cada componente utiliza las 15 variables asignándoles un peso (relación lineal); cuanto mayor sea el peso, mayor influencia tiene la variable (o RNA-MLP) en esa componente. Posteriormente se utiliza una RNA con las 3 componentes del ACP.
Meta-learning mediante la combinación de modelos no lineales
Se buscará mejorar los resultados combinando las tres RNA-MLP con mejor desempeño. Se colocan las RNA sin tener conexión entre ellas y sus salidas se conectan a otra RNA-MLP igualmente es parte de la arquitectura total. El algoritmo va a buscar la solución de las cuatro RNA-MLP.
Selección de la mejor arquitectura
Tener un menor error cuadrado medio (Ecuación 8), vendrá acompañado de un máximo R2 (Ecuación 9), lo que se puede interpretar como el porcentaje de varianza que explica el modelo. Un máximo SR (Ecuación 10) nos da el porcentaje de aciertos en la predicción en la dirección positivo/negativo del rendimiento, pero no significa que el modelo es el correcto.

Una manera de interpretar los resultados de los mejores modelos es mediante el análisis de las derivadas parciales del modelo, en otras palabras, ver el efecto que produce una variable independiente sobre la variable dependiente. En un modelo lineal es fácil observarlo, debido a que cada coeficiente de cada variable independiente nos da el efecto que se produce sobre la variable dependiente. Cuanto más grande sea el efecto, mayor es la influencia de la variable. En el caso de una RNA es difícil observarlo debido a las relaciones no lineales del modelo.
Los resultados obtenidos de las derivadas parciales (de un modelo lineal o no lineal) de cada variable independiente deben de ser congruentes con los efectos positivos o negativos que producen sobre la variable dependiente, pues en caso de ser incongruente, el modelo de RNA queda con demasiados parámetros (overfitted model).
Para la obtención de las derivadas parciales se utiliza el método de diferencias finitas, mientras que para saber si las variables empleadas en el modelo son realmente importantes dentro del mismo o son estadísticamente distintas de cero, se utiliza el método bootstrapping.
Para aplicar el método de diferencias finitas, se resuelve la Ecuación 11. Se evalúa la ecuación 11 con un incremento muy pequeño (se utilizó h = 1 x 10-6 para cada observación y se calculó su promedio).
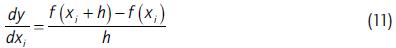
Para verificar que ese promedio es significativamente diferente de cero, se utilizó el método de bootstrapping, que consiste en utilizar muestras aleatorias con reemplazo de los datos utilizados (en este caso se utilizaron 700 muestras tomadas aleatoriamente de las 17.234 observaciones, sin importar que se repitan), donde se recalcula para cada muestra su RNA y su derivada parcial para cada variable independiente. Posteriormente, para las 700 derivadas parciales, resultantes de cada variable independiente, se calcula el estadístico T-student. Si el resultado es mayor o igual a 0.05 (95% de confianza), no podemos rechazar la hipótesis nula, donde el parámetro sea igual a cero. Para mayores detalles de ambos métodos ver McNeils (2005).
Resultados empíricos
En la Tabla 2 se encuentran los resultados empíricos de los modelos utilizados, para la predicción del rendimiento en los primeros 5 meses del año. Conforme va aumentando la complejidad de las estructuras de los modelos, mejoran los resultados. Por ejemplo, para el total de las observaciones, el modelo lineal tiene un R2 de 0.1022, el cual mejora los resultados de Ho et al. (2006), cuyo modelo lineal tiene un R2 de 0.05.
TABLA 2. Modelos para la predicción del rendimiento a corto plazo8
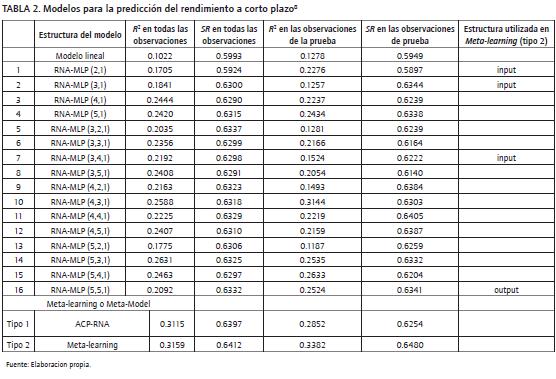
Esta mejora es por la inclusión de otras variables y la sensibilidad del modelo debido al comportamiento del inversionista (optimista o pesimista). La estructura del meta-model o meta-learning, el modelo con mayor complejidad, tiene un R2 de 0.3159. Lo mismo se puede observar con el 20% de los datos utilizados para probar los modelos, siendo los de mayor complejidad los que mejor explican la varianza del rendimiento. Los resultados del modelo no lineal tienen un poco más de tres veces mayor explicación que el modelo lineal.
Aunque la explicación de la varianza (R2) va mejorando entre los modelos, las diferencias en la predicción del movimiento del rendimiento de las acciones en los primeros 5 meses es muy similar.
Los resultados del mejor modelo se encuentran en la Tabla 3. La variable de mayor influencia para el inversionista es la tasa de interés a 5 años. El rendimiento está influido, en promedio, por -0.0807 veces la tasa de interés a 5 años, 0.0084 veces el incremento del pasivo sobre el total activo (por uno más la desviación estándar del activo), 0.0054 por uno más la desviación estándar si el pasivo supera al activo en los últimos 2 años (toma el valor de 0 en caso contrario), 0.0036 por uno más la desviación estándar si la empresa tuvo pérdida en los 2 últimos reportes financieros anuales (toma el valor de 0 en caso contrario), -0.0033 veces el crecimiento del PIB, 0.0007 veces el incremento del I+D entre el activo total (por uno más la desviación estándar) y 0.0002 veces el incremento de utilidad antes de impuestos más depreciación dividido entre total del activo por (1+σ)7.Son variables de influencia significativamente diferentes de cero.
TABLA 3. Derivadas parciales del modelo meta-learning en la predicción del rendimiento a corto plazo9
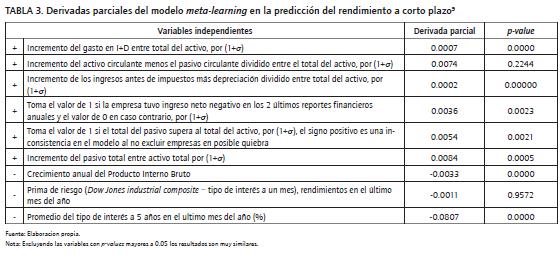
Respecto a la interpretación del signo de la derivada parcial, se concluye que existe una credibilidad por parte del inversionista de mejoras en el desempeño de la empresa ante aumentos en el nivel de apalancamiento, aun cuando puedan existir 2 años anteriores con pérdidas y/o sus pasivos superen al activo. El signo de la derivada parcial del crecimiento del PIB resulta difícil de creer al ser negativa. La derivada parcial de los incrementos en la intensidad del I+D es positiva, como se encontró en Samaniego et al. (2008). Igualmente, el inversionista valora como positivos los aumentos en el capital de trabajo en relación a su activo.
Conclusiones
Se documenta que los modelos de redes neuronales artificiales son superiores a modelos lineales para explicar rendimientos de acciones en el corto plazo. El meta-model explica el 31.59% de la varianza del rendimiento en los primeros 5 meses del año, entre 2000-2006. El modelo lineal explica que el 10.22% de la varianza de los datos es aproximadamente tres veces menor que el modelo no lineal. Aun así, el porcentaje de explicación del modelo es bajo, por lo que se deja a futuras investigaciones la búsqueda de otras variables y la utilización de otros métodos para la selección de las mismas, como -por ejemplo- la utilización de algoritmos genéricos.
Conocer la combinación de factores de influencia en el inversionista (Tabla 1) es útil para administradores, proveedores de créditos y gestores de política económica, para mejorar las oportunidades de crecimiento económico con inversiones en I+D. Este documento contribuye en la generación de oportunidades de crecimiento futuro que eventualmente influirán en el crecimiento del precio de las acciones y, por tanto, en la riqueza de los accionistas.
Existe una relación entre la credibilidad a largo y a corto plazo: si la mayoría no cree en el largo plazo difícilmente creerá en el corto. La predicción o la preocupación por el largo plazo no desaparecen mediante la planificación, sino a través del aprendizaje complejo, que se define 1) en el seguimiento de estrategias, 2) en la identificación de la cultura y (3) en la filosofía de la economía/organización. Todo ello, bajo la incertidumbre inevitable del sistema, propio de todo proceso innovador y creativo (Nieto, 1999). Conforme la economía o la organización transmitan convincentemente ese aprendizaje al mercado, aumentará la credibilidad del inversionista.
Notas
1Fue publicado por el Department for Business, Innovation and Skills (BIS), el 25 de noviembre de 2010. El R&D Scoreboard es una investigación anual de las principales 1000 empresas del Reino Unido y las principales 1000 empresas globales que invierten en I+D.
2El rendimiento de estos índices de bolsa de USA se utilizaron como la variable dependiente. En este documento se utilizará el rendimiento de acciones de USA que cumplan con las características descritas en el apartado datos utilizados.
3Relación de las variables utilizadas en el modelo de predicción de la tasa de rendimiento de las empresas en los primeros 5 meses del año (ver Ecuación 1). La base de datos utilizada es COMPUSTAT (mercados financieros NASDAQ, NYSE y AMEX), Center for Research in Security Prices (CRSP) y del Intertational Statistical Yearbook (proporcionado por DSI, Data & Servicices & Information) entre 1999 y 2006. Para COMPUSTAT se filtra la información a reportes financieros anuales de empresas activas, con ventas mayores a 1 millón de dólares (USA) y activos mayores a 1 millón de dólares (USA). Del CRSP la tasa de rendimiento de la acción en los primeros 5 meses del año. De cada variable se obtuvieron 17,234 observaciones.
4Para mayor detalle se puede consultar McNeils (2005)
5La fuente principal del apartado es Hilera, J.R.; Martínez, V.J. (1995). Redes Neuronales Artificiales: Fundamentos, Modelos y Aplicaciones. RA-MA / Addison Wesley Iberoamericana, Madrid.
6La función de transferencia convierte el valor de la función a un valor dentro de un rango (entre -1 y +1), en este caso es tangente sigmoidea.
7Las primeras seis variables relacionadas con los resultados de la empresa están multiplicadas por uno más la desviación estándar para diferenciar los resultados de una empresa con otra similar (véase Samaniego, Reyes & Bach, 2008).
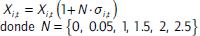
Se buscó que el modelo fuera más robusto con diferentes valores de N, al final con N = 1 fue donde el modelo era más robusto.
8Se dividen las observaciones en tres: para realizar el entrenamiento (60%), la validación (20%) y la prueba (20%). Los parámetros del modelo se estiman con los datos para el entrenamiento. De un total de 17,234 (T) observaciones se utilizan las 9 variables de la Tabla 1 para estimar el rendimiento al 5to mes del año.
9Relación de las variables utilizadas en el modelo de predicción de la tasa de rendimiento en los primeros 5 meses del año. La base de datos utilizada COMPUSTAT (que incluye los mercados financieros: National Association of Securities Dealers Automated Quotation - NASDAQ, New York Stock Exchange - NYSE y American Stock Exchange -AMEX), Center for Research in Security Prices (CRSP) y del Intertational Statistical Yearbook (proporcionado por DSI, Data & Servicices & Information) entre 1999 y 2006. De cada variable se obtuvieron 17,234 observaciones. La estructura de la RNA en la entrada es de MLP (2,1), MLP (3,1), MLP (3,4,1) y en la salida MLP (5,5,1).
Referencias Bibliográficas
Bae, S. & Kim, D. (2003). The effect of R&D investments on the market value of firms: evidence from U.S., Germany and Japan. Multinational Business Review, Vol. 11, 51-75. [ Links ]
BIS (2010). The 2010 R&D Scoreboard, Department for Business Innovation & Skills, Reino Unido. [ Links ]
Bode, J. (1998). Decision support with neural networks in the management of research and development: Concepts and application to cost estimation. Information and Management, Vol. 34, 33-40. [ Links ]
Chan, L., Lakonishok, J. & Sougiannis, T. (2001). The stock market valuation of research and development expenditures. Journal of Finance, Vol. 56, 2431-2456. [ Links ]
Chatterjee, A., Ayadi, F. & Boone, B. (2000). Artificial neural network and the financial markets: A survey. Managerial Finance, Vol. 26, 32-45. [ Links ]
Chauvin, K. & Hirschey, M. (1993). Advertising, R&D expenditures and the market value of the firm. Financial Management, Vol. 22, 128-132. [ Links ]
Chien, S. Ch., Wang, T.Y., & Lin, S.L. (2010). Application of neuro-fuzzy networks to forecast innovation performance -The example of Taiwanese manufacturing industry. Expert Systems with Applications Vol. 37, 1086-1095. [ Links ]
Coad, A. (2009). The growth of Firms: a survey of theories and empirical evidence. Edward Elgar Publishing, Inc., Northampton, Massachussets. [ Links ]
Dosi, G. (1988). Sources, procedures and microeconomic effects of innovation. Journal of Economic Literature 25, 1120-1171. [ Links ]
Duqi, A. & Torluccio, G. (2010). Can R&D Expenditures Affect Firm Market Value? An Empirical Analysis of a Panel of European Listed Firms, consultado el 1 de julio de 2013 en SSRN: http://ssrn.com/abstract=1663205 or http://dx.doi.org/10.2139/ssrn.1663205 [ Links ]
Eberhart A., Maxwell, W. & Siddique, A. (2004). An examination of long-term abnormal stock returns and operating performance following R&D increases. Journal of Finance, Vol. 59, 623-650. [ Links ]
Ehie, I. & Olibe, K. (2010). The effect of R&D investment on firm value: An examination of US Manufacturing and service industries. International Journal of Production Economics, Vol. 128, 127-135. [ Links ]
Fadlalla, A. & Lin, C. (2001). An analysis of the applications of neural networks in finance. Interfaces, Vol. 31, 112-122. [ Links ]
Freeman, C. & Soete, L. (1997). The Economics of Industrial Innovation, third edition. The MIT Press, Cambridge, MA. [ Links ]
Griliches, Z. (1995). R&D and productivity: econometric results and measurements issues. In: Paul S. (Ed.) The Handbook of the Economics of Innovation and Technological Change, Blackwell, Oxford. [ Links ]
Hall, B. (1996). The Private And Social Returns To Research And Development, in Smith, B. and Barfield, C. (Eds.). Technology, R&D and the Economy, Washington, DC: Brookings Institution and American Enterprise Institute. [ Links ]
Hall, B. & Oriani, R. (2006) Does the market value R&D investment by European firms? Evidence from a panel of manufacturing firms in France, Germany, and Italy. International Journal of Industrial Organization, Vol. 24, 971-993. [ Links ]
Hall, B., Mairesse, J. & Mohnen, P. (2009). Measuring the returns to R&D, Working Paper Series 15622, National Bureau of Economic Research (NBER), Cambridge. [ Links ]
Hall, L. & Bagchi-Sen, S. (2002). A study of R&D, innovation, and business performance in the Canadian biotechnology industry. Technovation, Vol. 22, 231-244. [ Links ]
Ho, K., Tjahjapranata, M. & Yap, C. (2006). Size, leverage, concentration, and R&D investment in generating growth opportunities. Journal of Business, Vol. 79, 851-876. [ Links ]
Huang, W., Lai, K., Nakamori, Y. & Wang, S. (2004). Forecasting foreign exchange rates with artificial neural networks: A review. International Journal of Information Technology & Decision Making, Vol. 3, 145-165. [ Links ]
Huang, W., Lai, K., Nakamori, Y. & Yu, L. (2007). Neural networks in finance and economics forecasting. International Journal of Information Technology & Decision Making, Vol. 6, 113-140. [ Links ]
Irwin, J., Hoffman, J. & Lamont, B. (1998). The effect of the acquisition of technological innovations on organizational performance: A resource-based view. Journal of Engineering and Technological Management, Vol. 15, 25-54. [ Links ]
Johnson, L. & Pazderka, B. (1993). Firm Value and Investment in R&D. Managerial and Decision Economics, Vol. 14, 15-24. [ Links ]
Kanas, A. (2001). Neural network linear forecasts for stock returns. International Journal of Finance & Economics, Vol. 6, 245-254. [ Links ]
