











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
PermalinkSe estima que casi un 50 % de la población mundial utiliza, además de su idioma materno (L1), un segundo idioma (L2) en su vida cotidiana (Grosjean, 1994, 2008). Es por esto que, desde hace más de una década, se han realizado varios estudios que indagan los cambios comportamentales (Bialystok, 2017), anatómicos (Kuhl et al., 2016; Li, Legault, & Litcofsky, 2014) y funcionales (Kuipers & Thierry, 2015; Moreno, Wodniecka, Tays, Alain, & Bialystok, 2014) que se producirían en los sujetos como fruto de la adquisición y uso de una segunda lengua a lo largo de la vida (Anderson et al., 2018; Jasiñska, Berens, Kovelman, & Petitto, 2017; Kroll, Bobb, & Hoshino, 2014; Spitzer, 2016). Una definición ampliamente aceptada indica que una persona bilingüe es aquella que utiliza más de un idioma o dialecto en su vida cotidiana, independientemente del nivel de dominio que demuestre en cada uno de ellos (Grosjean, 2008).
En población monolingüe (ML, i.e., que solo utiliza un idioma) se ha estudiado que el contenido emocional de las palabras (i.e., que sean consideradas agradables o desagradables) afecta el posterior recuerdo y reconocimiento de estas (Kensinger & Corkin, 2003), ya que las emociones funcionarían como un sistema de filtro, de manera que se recordarán y reconocerán en mayor medida aquellos estímulos con carga emocional (Justel, Psyrdellis, & Ruetti, 2013; Ruetti, Justel, & Bentosela, 2009). De modo general, las palabras emocionales son mayormente recordadas que las neutras cuando presentan una frecuencia baja de aparición en el lenguaje; en cambio, con una frecuencia alta, las palabras positivas son mayormente recordadas que las negativas y neutras (Ponari, Rodríguez-Cuadrado, Vinson, Fox, & Costa, 2015). Si bien ha aumentado la cantidad de literatura que da cuenta de cómo se procesan los estímulos emocionales en población bilingüe (BL), siguen siendo escasos los estudios, y con resultados contradictorios. Por un lado, hay trabajos que indican que las personas BL experimentan las palabras en L1 como más emocionales que aquellas presentadas en L2; además, alegan que por más que sepan el significado de las palabras en L2 no las sienten del mismo modo (Anooshian & Hertel, 1994; Baumeister, Foroni, Conrad, Rumiati, & Winkielman, 2017; Gawinkowska, Paradowski, & Bilewicz, 2013; Hsu, Jacobs, & Conrad, 2015; Pavlenko, 2005). Otros estudios han mostrado una ventaja emocional para aquellas palabras procesadas en L2 (Ayçiçeği & Harris, 2004), mientras que otros han expuesto que no se hallan diferencias de procesamiento entre L1 y L2 (Ferré, García, Fraga, Sánchez-Casas, & Molero, 2014; Ponari et al., 2015).
Las inconsistencias encontradas en la literatura pueden ser explicadas de diversas formas: por un lado, los resultados de Ayçiçeği y Harris (2004) pueden explicarse por la novedad de los estímulos usados (tabús y reprimendas); por otro lado, la cantidad de estímulos de valencia negativa sobrepasaba a los de valencia positiva y neutra, por lo que los efectos de recuerdo podrían deberse a que los estímulos negativos fueron presentados más cantidad de veces que los otros dos. Anooshian y Hertel (1994), por su parte, no presentan una discriminación de valencia para los estímulos emocionales. Mientras que, en el estudio de Gawinkowska et al. (2013), las palabras que presentaban una mayor emocionalidad en L1 eran improperios a determinado grupo social, dando cuenta del peso cultural que posee el lenguaje. Además, todos los estudios evaluaban tareas de recuerdo libre y reconocimiento inmediatamente después de la presentación de los estímulos, sin evaluaciones diferidas y, por otra parte, los estímulos eran presentados simultáneamente en L1 y L2.
Debido a los antecedentes nombrados, el objetivo del presente trabajo fue indagar la relación entre memoria y emoción en sujetos ML y BL español-inglés a través de una tarea de valoración emocional y dos tareas de memoria. A diferencia de los estudios mencionados, donde los sujetos tenían una presentación simultánea de estímulos en L1 y L2, en esta investigación los participantes BL fueron separados aleatoriamente de acuerdo a dos condiciones: aquellos que procesaban los estímulos en L1, es decir que la presentación de estímulos fue únicamente en español ya sea que los sujetos fueran monolingües o bilingües, y BL que procesaban los estímulos en L2, para quienes la presentación de estímulos fue únicamente en inglés (solamente participantes bilingües). Esto permitirá la identificación de posibles diferencias en la emocionalidad, según se adquiera un estímulo en L1 o L2. Además, como se estima que el tiempo podría modular la recuperación de la información emocional en L1 y L2 (Quevedo et al., 2003; Toyama, Katsuhara, Sakurai, & Ohira, 2014); las tareas de memoria se realizaron en dos ocasiones: inmediatamente después de la codificación de los estímulos y al cabo de una semana.
Metodología
Participantes
Colaboraron 52 voluntarios (18 hombres, edad M=25.2 años, SD=4.17, rango 19-52 años). Todos ellos declararon ser hablantes nativos de español y tener visión y audición normal o corregida. Cada participante fue evaluado en cuanto a su competencia lingüística para ser considerado ML o BL (ver sección Instrumentos). El trabajo se rigió de acuerdo con las normas éticas vigentes (Asamblea Médica Mundial, Declaración de Helsinki, 2013). Se les solicitó a los participantes que firmasen un consentimiento informado, en cual se detallaban los propósitos del estudio y el compromiso de asegurar el anonimato y la confidencialidad de los datos. Además, se les informó que, si lo deseaban, podían abandonar el estudio en cualquier momento de su realización. Tres participantes (2 ML y 1 BL) abandonaron el estudio antes de finalizar la evaluación diferida, por lo que sus datos fueron excluidos de la muestra final, por ende, los grupos quedaron conformados de la siguiente forma: Monolingües que codificaron la lista de palabras en español (ML)=15 participantes; Bilingües que codificaron la lista de palabras en español (BL1)=17 participantes; Bilingües que codificaron la lista de palabras en inglés (BL2)=17 participantes.
Instrumentos
Cuestionario de datos personales. En este documento los participantes anotaban información sociodemográfica: edad, sexo, años de educación, enfermedades relevantes, consumo de sustancias. Se agregó la información referida a conocimientos musicales, ya que estudios previos indican que esta variable incide en el procesamiento de L2 (Schroeder, Marian, Shook, & Bartolotti, 2016) y en las tareas de memoria verbal (Díaz Abrahan & Justel, 2019).
Competencia lingüística. Para recabar información sobre experiencia, competencia y dominio de L1 y L2, todos los participantes completaron el Cuestionario de Competencia y Experiencia Lingüística (LEAP-Q, por sus siglas en inglés Language, Experience and Proficiency Questionnaire,Marian, Blumenfeld, & Kaushanskaya, 2007), y realizaron dos tareas de fluencia verbal fonológica de un minuto, en español e inglés. Con base en la competencia lingüística, los participantes fueron calificados en monolingües (ML) o bilingües (BL). Dentro del grupo de BL se dividió a los sujetos en dos subgrupos, de modo aleatorio: BL1 y BL2. El grupo BL1 escuchó los estímulos verbales en su L1 mientras que el grupo BL2 escuchó los estímulos verbales en su L2.
Cuestionario de Experiencia y Competencia Lingüística (LEAP-Q). El LEAP-Q (Marian et al., 2007) es un cuestionario autoadministrable, diseñado para evaluar los perfiles lingüísticos de adolescentes y adultos bilingües y multilingües. Las puntuaciones obtenidas se analizan en forma separada para obtener información sobre las diferentes habilidades lingüísticas y la competencia autopercibida en cada uno de los idiomas que emplea. Los análisis de validez realizados con el cuestionario original indican que la competencia autopercibida es un buen predictor de comprensión oral: lectura de L1, R =.661, habla de L1, R=.541, y comprensión de L1, R =.481; habla de L2, R =.739, comprensión de L2, R =.621, y lectura de L-2, R =.575 (Marian et al., 2007). Para este trabajo, siete hablantes nativos de español residentes en el Área Metropolitana de Buenos Aires evaluaron cualitativamente la adecuación del cuestionario al español rioplatense, utilizando tres criterios: claridad de los enunciados, comprensión en la modalidad de respuesta y ajuste a sus experiencias en el aprendizaje de L2. Se consideraron ml aquellos participantes que reportaron no tener conocimiento de inglés como L2, o contar con un conocimiento limitado (promedio <3 en una escala de 10 puntos para habla, comprensión y lectura de L2). Mientras que aquellos considerados BL reportaron un dominio alto de inglés como L2 (promedio >8 en habla, comprensión y lectura) y expresaron haber adquirido su segunda lengua antes de los 13 años (Pavlenko, 2012).
Fluencia verbal fonológica. La tarea de fluencia verbal, en su modalidad fonológica, es una labor de producción lingüística en la que se le solicita al participante enunciar la mayor cantidad posible de palabras que comiencen con un fonema determinado, durante 60 segundos. Esto permite la activación de los mecanismos necesarios para el acceso lexical (Labos, Trojanowski, del Río, Zabala, & Renato, 2013) y es utilizado para determinar la dominancia en Li y L2 (Aycicegi-Dinn & Caldwell-Harris, 2009; Baumeister et al., 2017), midiendo si hay diferencia entre ambas producciones. Para esta tarea, se les solicitó a los participantes que escribiesen la mayor cantidad posible de palabras que comiencen con /p/ en español (Butman, Allegri, Harris, & Drake, 2000) y con /f/ en inglés (Tombaugha, Kozakb, & Rees, 1999), durante 60 segundos cada uno (Knepp, Krafka, Boulton, & Myers, 2014). El orden de las instrucciones fue contrabalanceado.
Lista de palabras. Todos los participantes fueron evaluados a través de un paradigma de codificación y recuperación de palabras tomadas de las Normas Afectivas para Palabras en Inglés (ANEW, por sus siglas en inglés Affective Norms for English Words;Bradley & Lang, 1999). Se seleccionaron 216 palabras, 108 en inglés y 108 de su traducción al español (Redondo, Fraga, Padrón & Comesaña, 2007; ver apéndice Tabla A1), para generar seis listas: dos listas de codificación, dos de reconocimiento inmediato y dos de reconocimiento diferido (ver Figura 1).
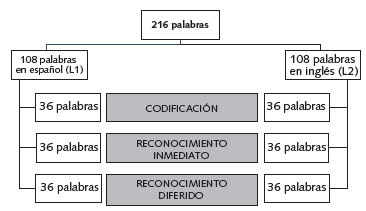
Figura 1 Diagrama de distribución de palabras. Las 108 palabras en español corresponden a las traducciones de las 108 palabras en inglés. Cada grupo de 36 palabras estaba dividido en 12 con valencia positiva, 12 con valencia negativa y 12 neutras. Tanto para reconocimiento inmediato y diferido, las 36 palabras novedosas fueron combinadas con las 36 palabras de la fase de codificación.
Para la codificación, se generaron dos listas, una de 36 palabras en español (Lista Li) y otra con las mismas 36 palabras en inglés (Lista L2). Cada una de las listas estaba compuesta por 12 palabras agradables o positivas, 12 palabras desagradables o negativas y 12 palabras neutras. Se seleccionaron aquellas palabras que no fueran homógrafos en Li y L2 (e.g., tumor, doctor), ni homófonos (e.g., confort/comfort, kétchup/ketchup). Además, se comparó la frecuencia de aparición de las palabras en ambos idiomas a través de CLEARPOND (Marian, Bartolotti, Chabal, & Shook, 2012), una base de datos que provee información fonológica y ortográfica para palabras en inglés, español, holandés, francés y alemán. Para asegurar que ambos corpus (español e inglés) sean comparables, se aplicó el logaritmo de la frecuencia por 1 millón de apariciones (Frecuencia Log; siguiendo los criterios de Conrad, Recio, & Jacobs, 2011). En relación con la frecuencia de palabras en castellano o inglés, no se hallaron diferencias significativas entre los tres tipos de palabras, ni para codificación ni para reconocimiento (inmediato o diferido), p>.05 (ver apéndice Tabla A2).
Para el reconocimiento, se conformaron cuatro listas: dos listas en español, para ser administradas de forma inmediata y diferida; y otras dos, en inglés. Estas listas se encontraban compuestas por palabras relacionadas semánticamente con las palabras de las listas de codificación. Por ejemplo, si la lista L1 de codificación contenía la palabra sexo, en las listas de reconocimiento se encontraban las palabras goce o placer. Cada lista de reconocimiento tenía un total de 72 palabras, con las 36 palabras escuchadas anteriormente (codificación) y 36 palabras nuevas. Los valores de valencia y activación fueron similares en ambos idiomas.
Para todas las listas, los archivos fueron grabados por una voz femenina con prosodia monocorde en ambos idiomas y posteriormente procesados a través del software Audacity para Windows (versión 2.2.1) con el fin de eliminar posibles ruidos y diferencias de volumen. Los archivos fueron finalmente convertidos a formato de compresión de alta calidad (MP3). Para los estímulos en inglés, un docente de enseñanza superior en fonética inglesa identificó el acento como Received Pronounciation (RP), el acento estándar de Inglaterra (Reino Unido).
Al momento de la evaluación, los participantes escucharon las listas a través de auriculares diadema (Sony MDR-ZX110), conectados a un reproductor de música portátil. Para las listas L1 y L2, los estímulos se presentaron en orden pseudoaleatorio (comenzando y finalizando con palabras neutras) en intervalos variados de 5 a 7 segundos. Para las listas de reconocimiento, cada 5 segundos.
Procedimiento
El estudio se realizó en dos sesiones, separadas entre sí por siete días. En la primera sesión, los participantes firmaron el consentimiento informado y completaron el cuestionario de datos sociodemográficos, así como la versión en papel del LEAP-Q adaptada al español rioplatense. Después, se les presentó la tarea de codificación. De acuerdo con el grupo al que pertenecieran, los participantes escucharon una lista de palabras en español (ML y BU) o inglés (BL2) y se les pidió que asignaran un valor de 0 a 10, de acuerdo con el grado de emoción/activación que percibían al escuchar la palabra, siendo 0 nada emocionante y 10 muy emocionante. La activación o arousal fue la primera medida dependiente evaluada. Asimismo, se les dio la instrucción de que consignaran para cada una de las palabras la clasificación positiva, si la consideraban una palabra agradable; negativa, si la consideraban desagradable; o neutra, si no correspondía a uno u otro criterio. Esto correspondería a la variable dependiente de Valencia. Previo a la presentación de la lista, se les mostraron tres palabras a manera de ejemplo para asegurar la comprensión de la consigna.
Inmediatamente después de escuchar la lista, todos los participantes realizaron una tarea de recuerdo libre, en la que se les solicitó que, por cinco minutos, escribieran todas las palabras que recordasen de la lista que acababan de escuchar. Pasados los 5 minutos, se evaluó el reconocimiento. Para ello, se les proporcionó una grilla de respuesta en donde, a medida que escuchaban las 36 palabras-blanco mezcladas con 36 palabras novedosas, debían indicar si la palabra presentada pertenecía o no a la lista oída en primera instancia.
Una semana después, los participantes regresaron para volver a evaluar tanto recuerdo libre como reconocimiento. Cantidad de palabras recordadas o reconocidas (de modo inmediato y diferido) fueron las medidas dependientes analizadas luego.
Una vez finalizado el reconocimiento, los participantes realizaron dos tareas de fluencia verbal fonológica escrita. Para estas tareas, se les solicitó que produjeran la mayor cantidad posible de palabras que comiencen con /p/ y con /f/, en español e inglés respectivamente. El orden de las instrucciones de ambas fluencias fue contrabalanceado para todos los participantes.
Análisis de Datos
Los datos fueron analizados a través del paquete estadístico SPSS (versión 21; IBM, 2012). Para evaluar las variables Edad, Educación, Conocimiento musical, Fluencia fonológica (inglés y español), Edad de Adquisición de L2, y los autorreportes de competencia lingüística se utilizó un análisis de varianza (ANOVA) de una vía, siendo el factor intersujeto Grupo (ML, BL1, BL2). La variable Sexo fue analizada mediante chi cuadrado (X2). Para evaluar la frecuencia de las palabras, tanto en inglés como castellano (en codificación, así como ambos reconocimientos), se usaron pruebas no paramétricas (U de Mann Whitney) debido a que los datos no cumplieron con los supuestos de homocedasticidad y normalidad.
La valencia, la activación, el recuerdo y el reconocimiento (inmediato y diferido) fueron analizados de modo independiente mediante un ANOVA de medidas repetidas (MR), donde Grupo (ML, BL1 o BL2) fue el factor intersujeto y Palabra (Neutra, Positiva, Negativa) fue la MR. Además, se utilizó ANOVA de una vía para comparar a los grupos en la cantidad de intrusiones cometidas para el recuerdo libre (inmediato y diferido). Se realizaron análisis post hoc (LSD), para evaluar efectos significativos principales o interacciones. El parcial Eta cuadrado se usó para estimar el tamaño del efecto (η2p). El valor de alfa se situó en .05.
Resultados
Datos Sociodemográficos y Competencia Lingüística
En la Tabla 1 se encuentra detallada la información de ambos cuestionarios. No se hallaron diferencias significativas entre los tres grupos para las variables Edad, Sexo, Educación, Conocimiento musical, Fluencia en español (p>.05). Con relación a Edad de Adquisición de L2, Competencia lingüística y Fluencia en inglés no se hallaron diferencias entre los grupos de BL (p>.05).
Tabla 1 Datos Sociodemográficos y de Competencia Lingüística
| Grupo | |||
|---|---|---|---|
| ML (n=15) | BL1 (n=17) | BL2 (n=17) | |
| Edad (años) | 24.87 (4.49) | 25.71 (7.55) | 24.94 (6.66) |
| Mujeres/Hombres | 10 / 5 | 12 / 5 | 10 / 7 |
| Educación musical (años) | 1.73 (4.76) | 3.47 (4.69) | 1.59 (3.24) |
| Educación académica (años) | 16.73 (1.53) | 17.24 (2.88) | 16.76 (2.11) |
| Edad de adquisición L2 (años) | 8.1 (2.18) | 6.65 (2.15) | 6.94 (2.7) |
| Habla L1 | 9.73 (0.7) | 10 (0) | 9.71 (0.59) |
| Lectura L1 | 9.53 (0.74) | 10 (0) | 9.71 (0.69) |
| Comprensión L1 | 9.8 (0.56) | 9.88 (0.49) | 9.88 (0.33) |
| Habla L2 | 2.93 (2.55) | 9.12 (1.11) | 8.94 (0.83) |
| Lectura L2 | 2 (2.2) | 8.24 (1.64) | 8.06 (1.3) |
| Comprensión L2 | 2 (1.85) | 8.94 (0.97) | 8.82 (0.73) |
| Fluencia L1 | 13.47 (4.03) | 14.18 (2.56) | 12.18 (3.26) |
| Fluencia L2 | 3.13 (3.87) | 10.76 (2.77) | 11.71 (2.85) |
Nota. L1: Español, L2: Inglés, ml: Participantes monolingües, BL1 : Participantes bilingües que escucharon la lista de palabras en L1, BL2: Participantes bilingües que escucharon la lista de palabras en L2. Los valores expresan M (SD).
Activación
Los sujetos escucharon una lista de palabras en español (ML y BU) o inglés (BL2) y debían indicar el grado de activación o arousal que le producía cada una de las palabras. Los resultados se encuentran graficados en la Figura 2. Se halló un efecto significativo de Palabra f(2, 92)=91.32, p<.0001, η2p=.665. Los análisis posteriores indicaron que las palabras positivas (M=7.99, SE=.17) fueron más activantes que las negativas (M=6.40, SE=.37) y neutras (M=3.17, SE=.25), a su vez, las negativas fueron más activantes que las neutras.
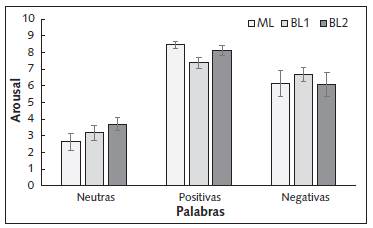
Figura 2 Grado de activación que les producían las palabras a los diferentes grupos (0-10, nada a muy emocionante, activante). ML: Grupo de participantes monolingües. BL1: Grupo de participantes bilingües que escucharon las palabras en su lengua nativa. BL2: Grupo de participantes que escucharon las palabras en su L2. Las líneas verticales representan el error estándar.
Valencia
A medida que escuchaban las palabras también debían indicar si estas eran consideradas positivas, negativas o neutras. Se codificaron las palabras de acuerdo con el valor de valencia, siendo las positivas de mayor valencia, neutras de valencia media y negativa de menos valencia. Por ende, se le asignó un 3 a aquellas palabras consideradas positivas, un 2 a las neutras y un 1 a las negativas. Los resultados se hallan en la Figura 3. Se halló un efecto significativo de Palabra f(2, 92)=1475.74,p<.0001, η 2 p=.97, donde las palabras positivas (M=2.88, SE=.02) fueron calificadas por encima de las neutras (M=2.01, SE=.02) y negativas (M=1.14, SE=.03), y las neutras fueron calificadas con mayor valencia que las negativas. Además, se halló una interacción significativa entre Palabra y Grupo f(2, 92)=4.03, p=.005, η 2 p =.149. Los análisis post hoc indicaron que el grupo de BL que escuchó las palabras en castellano (BU) les dio una mayor valencia a las palabras neutras (M=2.08, SE=.03) que el grupo de bilingües que escuchó las mismas palabras en inglés (BL2; M=1.94, SE=.03). En relación con las palabras positivas, el grupo ML (M=2.94, SE=.22) las calificó con mayor valencia que el grupo de BL (M=2.82, se=.04) que las escuchó en inglés (BL2). Finalmente, las palabras negativas fueron calificadas con mayor valencia por el grupo BL2 (M=1.21, SE=.05) que ML (M=1.08, SE=.04).
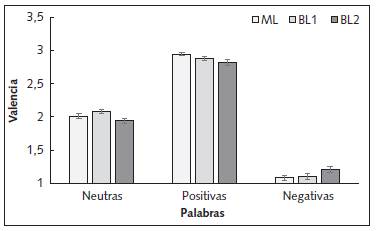
Figura 3 Valencia otorgada a cada tipo de palabra por los grupos. ML: Grupo de participantes monolingües. BL1: Grupo de participantes bilingües que escucharon las palabras en su lengua nativa. BL2: Grupo de participantes que escucharon las palabras en su L2. Las líneas verticales representan el error estándar.
Medidas Inmediatas
Luego de escuchar y calificar activación y valencia de las palabras, los participantes debían escribir aquellas que recordaban haber escuchado (Figura 4, panel superior). Se halló un efecto significativo de Palabra f(2, 92)=21.85, p<.0001, η2p=.322, donde las palabras positivas (M=5.20, SE=.26) fueron mayormente recordadas que las neutras (M=3.9, SE=.22) y que las negativas (M=3.43, SE=.20; sin diferencias entre estos dos últimos estímulos). Se encontró una tendencia en relación a la variable Intrusiones F(2, 48)=2.93, p=.064, presentando más intrusiones el grupo ML (M=2.13, SE =.35) que el grupo BL1 (M=1.24, SE=.37; datos no mostrados).
Después del recuerdo libre, los participantes escuchaban las palabras originales mezcladas con palabras novedosas y debían indicar si era un estímulo novel o no (reconocimiento inmediato), los falsos reconocimientos se sustrajeron del reconocimiento total para cada una de las palabras. El ANOVA indicó un efecto significativo de Palabra F(2, 92)=3.41, p=.037, η2p =.069 siendo las palabras neutras (M=10.73, SE=.34) mayormente reconocidas que las negativas (M=10.16, SE=.31; Figura 4, panel inferior).
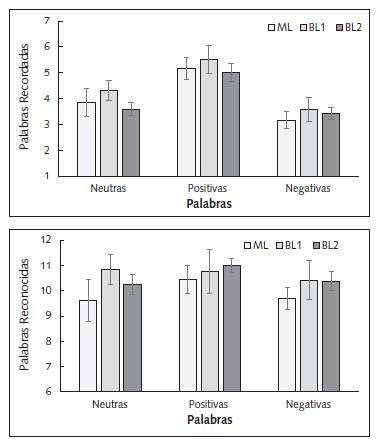
Figura 4 Medidas Inmediatas de Evaluación de la Memoria. Panel Superior: Palabras recordadas de modo inmediato por los diferentes grupos. Panel Inferior: Palabras reconocidas de modo inmediato por los diferentes grupos. ML: Grupo de participantes monolingües. BL1: Grupo de participantes bilingües que escucharon las palabras en su lengua nativa. BL2: Grupo de participantes que escucharon las palabras en su L2. Las líneas verticales representan el error estándar.
Medidas Diferidas
Luego de una semana, los participantes debían volver a escribir aquellas palabras que recordaban haber oído (recuerdo libre diferido, Figura 5 Panel superior). Se halló un efecto significativo de Palabra F(2, 92)=48.55, p<.0001, η 2 p =.513, siendo las palabras positivas (M=4.31, SE=.027) mayormente recordadas que las neutras (M=2.92, SE =.21) y negativas (M=1.9, SE =.19), a su vez se recordaron las palabras neutras por encima de las negativas. Se halló, además, un efecto significativo en relación con las Intrusiones F(2, 48)=3.29, p=.046, y los análisis a posteriori indicaron que el grupo de ML cometió más intrusiones (M=3, SE =.4) que ambos grupos de BL, sin diferencias entre BL1 (M=1.71, SE =.38) y BL2 (M=1.64, SE =.44).
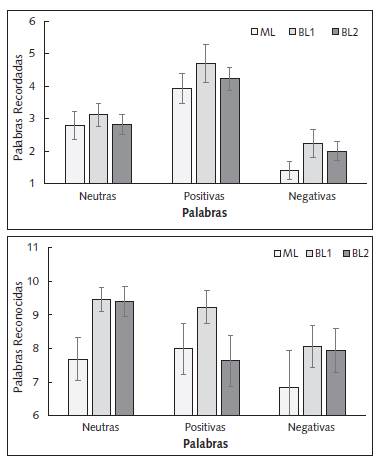
Figura 5 Medidas Diferidas de Evaluación de la Memoria. Panel Superior: Palabras recordadas de modo diferido por los diferentes grupos. Panel Inferior: Palabras reconocidas de modo diferido por los diferentes grupos. ML: Grupo de participantes monolingües. BL1: Grupo de participantes bilingües que escucharon las palabras en su lengua nativa. BL2: Grupo de participantes que escucharon las palabras en su L2. Las líneas verticales representan el error estándar.
Con relación al reconocimiento diferido, se halló un efecto significativo de Palabra F(2, 92)=6.39, p=.003, η 2 p =.122, siendo las palabras neutras (M=9.02, SE=.29) más reconocidas que las negativas (M=7.59, SE =.45; Figura 5, Panel inferior).
Discusión
Debido a la prevalencia mundial del bilingüismo, los costos y beneficios de este fenómeno se han convertido en un área de estudio de las ciencias cognitivas (Bialystok, Abutalebi, Bak, Burke, & Kroll, 2016). Por ello, el objetivo de este trabajo fue indagar la relación entre memoria y emoción en personas ML y BL.
Hoy en día, la literatura acerca de cómo es procesada y recordada o reconocida la información neutra y emocional en personas BL es escasa y con resultados contradictorios. Hay estudios que indican que las palabras en Li son más emocionales que en L2, otros estudios hallan el patrón opuesto, mientras otros trabajos muestran que no hay diferencia de procesamiento entre ellas (Anooshian & Hertel, 1994; Aycicegi & Harris, 2004; Baumeister et al., 2017; Ferré et al., 2014). El presente estudio apuntaría a una valoración emocional más intensa en L1, pero que no afectaría el patrón mnésico. A continuación, se discuten en profundidad estos hallazgos.
En relación con el nivel de activación, la selección de las palabras fue realizada a partir de la versión española del ANEW (Redondo et al., 2007), con base en el cual se obtuvieron los valores de arousal, que no presentaban diferencias entre palabras positivas y negativas; sin embargo, en nuestro trabajo hallamos que las palabras positivas fueron las más activantes, seguidas de las negativas y, por último, de las neutras. Este resultado daría cuenta de la necesidad de una validación del ANEW para población latinoamericana, ya que los datos españoles, por más que se hallen en castellano, no serían similares y aplicables a nuestra población.
En relación con la valencia, las palabras positivas fueron calificadas por encima de neutras y estas a su vez por encima de negativas. Este resultado daría cuenta de que la valoración de las palabras es acorde a lo presentado para población española. En esta dimensión, resaltan dos resultados interesantes. Por un lado, los participantes BL que procesaron los estímulos en su L1 calificaron con una mayor valoración las palabras neutras en comparación a los sujetos que escucharon estas mismas palabras en su L2, además, los participantes ml calificaron con mayor valencia los estímulos positivos en comparación al grupo BL2, quienes escucharon estos estímulos en su L2. Por otro lado, las palabras negativas fueron calificadas con mayor valencia por el grupo de personas BL, quienes las escucharon en inglés (BL2) en comparación con los participantes ml. Ambos resultados soportan los datos de la literatura, que apuntan a una disminución de la percepción de emociones cuando estas son presentadas en el segundo idioma (Pavlenko, 2012), ya que las palabras positivas y neutras fueron calificadas con menor valencia por el grupo que escuchó las palabras en su L2, y las palabras negativas fueron calificadas con mayor valencia, es decir como menos negativas al ser escuchadas en L2. En relación con el tema, Gawinkowska et al. (2013) proponen que los estímulos verbales negativos presentados en L2 no alcanzan el mismo nivel de desagrado que aquellos que fueron presentados en L1, siendo valorados como palabras neutras.
Respecto al recuerdo libre inmediato, las palabras positivas fueron mayormente recordadas que las neutras y negativas, sin diferencias entre grupos. Mientras que en el recuerdo libre diferido las palabras positivas se recordaron más que las neutras, y estas a su vez más que las negativas, sin encontrarse diferencias entre los grupos. Estos resultados se hallan en concordancia con los hallados por Ferré et al. (2010), quienes encuentran que las palabras positivas son mayormente recordadas que las neutras y/o negativas, sin verse afectado este resultado porque las mismas sean presentadas en L1 o L2. Además, un sesgo hacia los estímulos positivos se ha encontrado en la literatura. Yang et al. (2013), por ejemplo, evaluaron la discriminación de palabras de acuerdo a su valencia (altamente positiva, medianamente positiva, neutra, medianamente negativa y altamente negativa), utilizando la técnica de potenciales relacionados con eventos en participantes adultos monolingües. Encontraron que las palabras positivas producen mayores amplitudes a tiempos más tempranos que las palabras negativas. Para los autores, estos resultados dan cuenta de una mayor sensibilidad hacia los estímulos positivos.
Concordantemente, Shiekh y Titone (2016) utilizaron la técnica de seguimiento ocular con personas BL, durante la lectura de oraciones semánticamente neutras con palabras-blanco de valencia variada. Encontraron que los participantes leían más rápidamente las palabras positivas que las negativas cuando estas se presentaban en L2. A partir de estos resultados, los autores proponen que el procesamiento de palabras positivas se encuentra facilitado, mientras que esta facilitación se encuentra ausente en el procesamiento de palabras con valencia negativa.
Por otro lado, se halló que el grupo ml presentó una mayor cantidad de intrusiones en ambas tareas de recuerdo libre, comparado con ambos grupos BL. Este es un resultado inesperado, ya que la literatura previa muestra que las personas BL presentan interferencias por parte de su L2 en el procesamiento de estímulos en L1 (Alsaigh & Kennison, 2017) y viceversa (Ben-Yehudah, Hirshorn, Simcox, Perfetti, & Fiez, 2018), que impactan en el desempeño de tareas verbales (e.g., Portocarrero, Burright, & Donovick, 2007). Sin embargo, investigaciones recientes que comparan poblaciones BL y ML encontraron que los grupos ML presentan una mayor susceptibilidad a la percepción de ilusiones audiovisuales (Bidelman & Heath, 2018, 2019). Por otro lado, se observa que las personas BL presentan un mejor desempeño en tareas de atención selectiva orientada al habla, tanto en la niñez como en la edad adulta (Rama et al., 2018; Kuipers & Thierry, 2015), por lo que, frente a la presentación oral de estímulos emocionales, las personas BL podrían discriminar de forma más eficiente las palabras verdaderamente presentadas de aquellas que resultan distractoras o intrusivas.
En cuanto al reconocimiento, tanto inmediato como diferido, las palabras neutras fueron mayormente reconocidas que las negativas, sin diferencias entre los grupos. Este resultado se encuentra en concordancia con resultados previos de nuestro equipo de investigación (Bossio & Justel, 2018; Diaz Abrahan, Shifres, & Justel, 2019), aunque se necesitan mayores estudios para poder dar una explicación certera de estos hallazgos.
Es relevante resaltar que este estudio presenta una serie de limitaciones. En primer lugar, para la selección de estímulos no se consideró la elección de palabras de acuerdo a sus características abstractas y concretas. Existe evidencia de que tanto la valencia como la activación son modulados por el carácter concreto de las palabras (Yao et al., 2016), entendido como la cantidad de referentes sensoriales asociados a cada palabra. Estas propiedades semánticas que poseen las palabras influyen en el procesamiento (Margulis & Ferreres, 2011) y podrían incidir en la posterior evocación del contenido codificado. En segundo lugar, el tamaño de la muestra es reducido, lo cual limita la generalización de los resultados. Además, se utilizaron diferentes tipos de palabras emocionales: estados afectivos (dolor), comportamientos relacionados a emociones (abrazo), palabras cargadas de emoción (violación), por lo que sería importante en futuros estudios diferenciarlas, para poder dar cuenta de un resultado con mayor especificidad.
Próximas investigaciones podrán continuar en esta línea, implementando diseños de valoración emocional contextuados o ahondando en la especificidad de las características del reconocimiento en sujetos bilingües, por ejemplo, utilizando índices de certeza en las respuestas, midiendo los tiempos de respuesta entre L1 y L2 o utilizando modalidades multisensoriales.
Comprender la forma en que dos idiomas son procesados en el cerebro es indispensable para el desarrollo de prácticas orientadas a la adquisición y el aprendizaje de varias lenguas. Este trabajo provee evidencia que aporta a un entendimiento más amplio de la memoria emocional, su relación con los idiomas, y el rol del acceso lexical en la recuperación de información.

