










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkCiencia en Desarrollo
Print version ISSN 0121-7488
Ciencia en Desarrollo vol.7 no.1 Tunja Jan./June 2016
Una técnica de clasificación con variables categóricas
A Classification Technique With Categorical Variables
J. A. Clavijo M.a,*
H. A. Granada D.a
a Universidad del Tolima, Facultad de Ciencias, Departamento de Matemáticas y Estadística. Tolima, Colombia
* Autor de correspondencia: jaclavijom@ut.edu.co.
Recepción: 15-oct-2015 Aceptación: 20-ene-2016
Resumen
Presenta un algoritmo de clasificación para elementos caracterizados por variables categóricas, usando k-modas, un algoritmo similar a k-medias. A la vez, se incluyen diagramas de flujo para la implementación del algoritmo en cualquier lenguaje de programación. También se presenta un ejemplo con datos reales que ilustra la propuesta.
Palabras clave: conglomerado, distancia, disimilaridad, k-medias, k-modas.
Abstract
This paper presents a classification algorithm for elements characterized by categorical variables, using k-modes, a procedure analogous to k-means. At the same time we have included flowcharts for the algorithm implementation in any programming language. We also present a simple example, with real data, illustrating the proposal.
Key words: Cluster, Distance, Dissimilarity, k-means, k-modes.
1. Introducción
La clasificación de individuos en diferentes conglomerados a partir de los valores que tome un conjunto de variables definidas sobre ellos es un procedimiento de gran interés en estadística, ya que tiene numerosas aplicaciones en las que se busca determinar segmentos muy homogéneos de una población.
El caso en que todas las variables que describen a los individuos sean de tipo numérico es ampliamente conocido [2, 4, 5], y se han proporcionado varias técnicas para formar conglomerados: unas de tipo jerárquico, como el single linkage oel método de Ward, y otras de tipo no jerárquico, como el método k-means. Sin embargo, el caso en que las variables observadas sean de tipo categórico ha sido menos estudiado y prácticamente no existen técnicas que de manera directa conduzcan a la formación de conglomerados. Podría citarse un método indirecto, subproducto del análisis de correspondencias, en el que se pueden calcular las coordenadas de los individuos y de las categorías sobre un biplot para agruparlos aplicando técnicas del caso numérico a dichas coordenadas.
El propósito de este artículo es presentar un método de clasificación que actúe directamente sobre los valores de las variables categóricas y agrupe los individuos basándose en la semejanza de los valores categóricos que ellos asumen. El método que se propone es una adaptación del método k-means de variables numéricas, utilizando el concepto de moda, en vez del concepto de media, idea que ha sido propuesta por varios autores, entre ellos [1, 6, 7], y que ha servido de inspiración para este trabajo.
2. Disimilaridad entre individuos
Todos los métodos de clasificación buscan reunir en un solo grupo los individuos que más se parecen entre sí de acuerdo con los valores que ellos asumen en las variables que se estudian. Si se consideran p variables X1,X2,...,Xp, donde cada variable Xk tiene nk categorías, cada individuo xi se asocia con una p-upla xi = (ci11,ci22,...,cipp), donde 1 ≤ ik ≤ nk y cik =cikk es la categoría que dicho individuo adopta en la variable Xk con k = 1,2,...,p. Naturalmente, dos individuos se parecen más cuando coinciden en un número alto de categorías en las p-uplas correspondientes y se diferencian según el número de discrepancias que tengan.
Definición 1. Dados dos individuos xi = (ci1,ci2, ...,cip) y xj =(cj1,cj2,...,cjp) diremos que entre ellos hay una discrepancia en la k-ésima variable si i &≠j, la cual se representa mediante la métrica discreta:
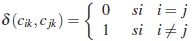
Definición 2. Para todo par de individuos xi, xj definimos la disimilaridad:
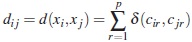
Observación 1. Dados dos individuos xi y xj, dij = 0 indica una máxima semejanza entre los dos individuos, mientras que dij =p indica máxima diferencia o ningún parecido entre ellos.
3. Moda de un conjunto
Definición 3. Consideremos el conjunto X = {x1,...,xn} de n individuos descritos por p variables categóricas X1,...,Xp. Definimos una moda de X como una p-upla Q =(q1,...,qp) tal que 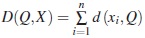 sea mínima [1].
sea mínima [1].
Observación 2. Se garantiza la existencia de un mínimo para D, ya que es una suma finita de números enteros y está acotada por:
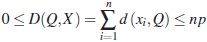
Ejemplo 1. Sea X el conjunto formado por seis individuos definidos por:
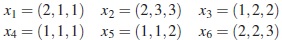
Estas triplas han sido definidas como respuesta a tres variables categóricas, así:
X1 con dos categorías codificadas como 1 y 2.
X2 con tres categorías codificadas como 1, 2 y 3.
X3 con tres categorías codificadas como 1, 2 y 3.
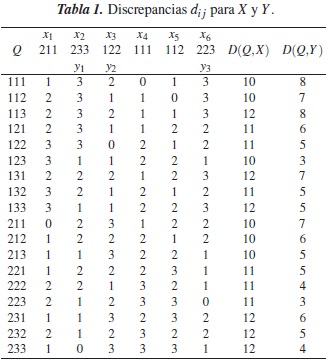
Las posibilidades de respuesta son en total 18,y la moda de X será una terna Q que haga mínimo el valor 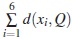 . Como se puede ver en la tabla 1, hay 6 posibles modas para el conjunto dado, a saber: (1,1,1), (1,1,2), (1,2,3), (2,1,1), (2,1,2) y (2,1,3).
. Como se puede ver en la tabla 1, hay 6 posibles modas para el conjunto dado, a saber: (1,1,1), (1,1,2), (1,2,3), (2,1,1), (2,1,2) y (2,1,3).
Es claro que el procedimiento descrito en el ejemplo anterior no es eficiente para encontrar una moda. Será particularmente engorroso cuando se manejen muchos individuos y un número grande de variables categóricas. Por ejemplo, una encuesta con solo 20 preguntas categóricas, cada una con 5 modalidades o categorías, exige un cálculo de más de 95 billones de sumas con tantos sumandos como individuos hayan contestado la encuesta, lo que genera un alto costo computacional!
Definición 4. Dado un subconjunto cualquiera Y ⊆ X con r ≤ nelementos y una variable categórica Xj, para cada categoría ckj de Xj se define la frecuencia relativa como el número:
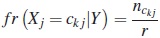
donde 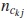 es la cantidad de veces que ckj pertenece a las p-uplas asociadas a los r elementos de Y.
es la cantidad de veces que ckj pertenece a las p-uplas asociadas a los r elementos de Y.
Una manera práctica de obtener las frecuencias es mediante tablas de frecuencias relativas.
Ejemplo 2. Consideremos el conjunto Y ={y1, y2,y3} ={x2,x3,x6} de r =3 elementos (ver tabla 1), calculamos las frecuencias relativas:
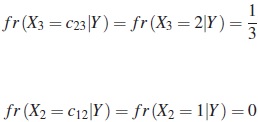
De manera similar se calculan las demás frecuencias relativas de las variables Xi en Y dadas por las tablas 2 y 3.

 3
3El Teorema 1 referenciado en [1] proporciona una forma eficiente de encontrar una moda para los elementos de un subconjunto Y de X.
Teorema 1. El valor D ( Q,Y )es mínimo si y solo si fr ( Xj =qj|Y )≤ fr ( Xj= ckj) para qj≠ckj y j = 1,...,p.
En esencia, este teorema nos dice que la moda Q para Y es la p-upla Q = ( q1,...,qp ), formada por las categorías q1,...,qp correspondientes a las máximas frecuencias en las tablas de frecuencia de cada variable.
Así, por ejemplo, para el conjunto Y del ejemplo anterior, Q debe ser la tripla Q = ( c21, c22, c33 ) = ( 2, 2, 3 ), como se puede apreciar en la última columna de la tabla 1. Este vector Q es uno de los dos vectores que hacen mínima la suma 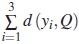 con yi ∈ Y.
con yi ∈ Y.
4. El algoritmo k-Modas
Ya que hemos establecido una metodología para encontrar modas en un conjunto de individuos determinados por variables categóricas, proponemos un algoritmo para agrupar dichos individuos en k conglomerados. El algoritmo que se propone es análogo al conocido método k-means para el caso de variables numéricas, pero usando modas en vez de medias. Es por esto que el mejor nombre que podemos elegir para identificar la propuesta es el de algoritmo de k-modas. Dicho algoritmo se define por medio de los cuatro pasos siguientes:
Paso 1: si se tienen n individuos en X que se pretenden agrupar en k clusters ( k < n ), comenzamos por elegir k de dichos individuos para que actúen como núcleos de aglutinamiento. Hay varias formas de elegir estos núcleos: aleatoriamente, a partir de una lista predefinida o simplemente tomando los k primeros. Estos primeros núcleos actúan como modas transitorias. La última opción es la que adoptamos en este trabajo.
Paso 2: examinamos uno a uno los n - k individuos restantes y asignamos cada uno al núcleo que le sea más cercano con la distancia d de la Definición 2. De esta manera vamos formando los diferentes grupos. En caso de empate en la distancia, el elemento en consideración se puede asignar aleatoriamente a uno de los núcleos que producen el empate. Una vez asignado un elemento a uno de los grupos, utilizamos el teorema visto anteriormente para actualizar la moda de dicho grupo. La nueva moda asumirá el papel de núcleo para el grupo en consideración.
Paso 3: una vez se hayan asignado todos los elementos de X a alguno de los grupos, se revisa la disimilaridad de cada elemento en cada grupo respecto a su propio núcleo y a los núcleos de los demás grupos. Si se encontrase un elemento que está más cercano al núcleo de un grupo que no es el suyo, reasignamos dicho elemento a ese grupo y actualizamos las modas tanto del grupo receptor como del emisor. Como antes, las nuevas modas actuarán como núcleos de estos dos grupos.
Paso 4: repetir el paso 3 cuantas veces sea necesario hasta que no se produzcan más cambios.
4.1. Implementación del método
Como se puede apreciar, el algoritmo es relativamente simple, pero es demasiado dispendioso por la cantidad de veces en que se debe buscar una moda para actualizar una ya existente en cada conglomerado. Es este un proceso que difícilmente puede llevarse a cabo en forma manual, siendo necesario el uso de procedimientos computacionales. Se programaron en Matlab las rutinas necesarias para implementar el método anterior, que fue probado en la clasificación de 45 usuarios de los sistemas de salud del Tolima. La muestra fue recolectada en las ciudades de Ibagué y Espinal, mediante la aplicación de una encuesta de 7 preguntas con respuestas categóricas, relacionadas con la percepción que tienen los usuarios de las EPS que les prestan servicios médicos. Este trabajo fue realizado por las estudiantes Nataly J. Roa y Luisa Fernanda Pastrán, dentro de su trabajo de grado, relacionado con este tema [3]. En este trabajo presentaremos únicamente los diagramas de flujo de la programación del algoritmo, el cual se desarrolla en dos fases cuyos fines son los siguientes:
Fase 1. Búsqueda del núcleo más cercano para cada elemento y cálculo de la moda del grupo receptor.
Fase 2. Comparación de todos los elementos de cada grupo con los diferentes núcleos para determinar si siguen en su grupo o si deben ser reasignados a otro grupo. Actualización de las modas tanto en el grupo emisor como en el grupo receptor en caso de alguna transferencia de elementos.
4.2. Diagramas de flujo
Como se mencionó anteriormente, el algoritmo de k-modas se realiza en dos fases, donde se hace necesario implementar una subrutina para búsqueda de modas y otra para el cálculo de disimilaridades. Los diagramas de flujo presentados en este trabajo fueron implementados en el software Matlab, y es por esta razón que damos por conocidas las funciones internas: cell, length, find, min, max y unique.

5. Aplicación del método k-Modas
La tabla 4 proporciona los resultados de aplicar una encuesta de 7 preguntas de tipo categórico a 45 usuarios de EPS de las ciudades de Ibagué y Espinal, en el Tolima [3].
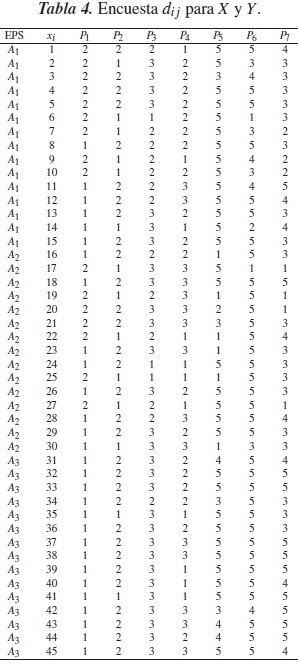
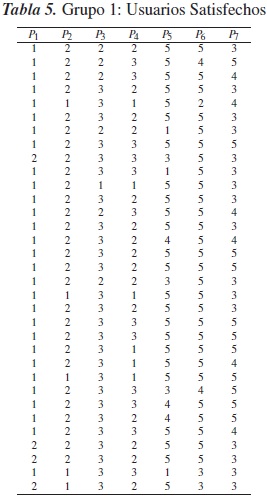
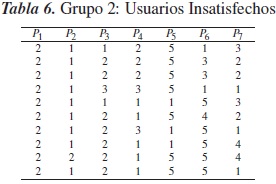
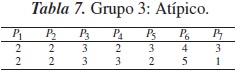
Los datos de la tabla 4 fueron procesados aplicando las rutinas antes mencionadas para realizar una clasificación en tres grupos, obteniéndose los resultados de la clasificación en las tablas 5, 6 y 7. En la tabla 8 se presentan las modas de cada uno de los grupos.

Conclusiones
Un examen de caracterización o tipología de estos grupos mediante la tabla de frecuencias de la tabla 9, muestra que el grupo mayoritario, con 33 individuos, está conformado por personas satisfechas con el servicio médico, que consideran que las instalaciones son buenas y que han conseguido sus citas médicas oportunamente en menos de una semana, que a la vez han recibido a tiempo sus medicamentos y que creen que la imagen de su EPS mejora cada vez más.
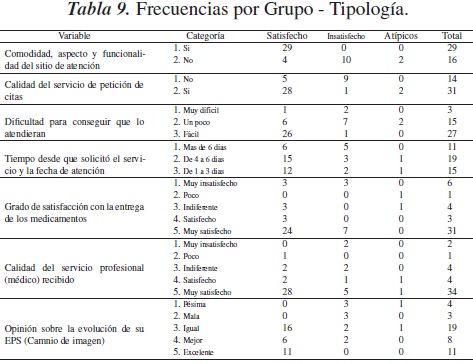
El grupo mediano, con 10 individuos, es un grupo de usuarios inconformes que han dado una baja calificación a las instalaciones y al sistema de citas, pues han tardado más de una semana para conseguirlas. En general, son individuos insatisfechos con el ser vicio médico. Finalmente, se formó un grupo atípico con dos individuos que no encajaron adecuadamente en ninguno de los dos grupos anteriores.
Referencias
[1] Z. Huang, "Extensions to the k-Means Algorithm for Clustering Large Data Sets with Categorical Values Data Mining and Knowledge Discovery", Kluwer Academic Publishers, vol. 2, no. 3, pp. 283-304, 1998. [ Links ]
[2] A. C. Rencher, "Methods of multivariate analysis", John Wiley & Sons, vol. 492, 2003. [ Links ]
[3] N. Roa y L. F. Pastrán, "Una técnica de Clasificación con Variables Categóricas", Trabajo de Grado, Universidad del Tolima, Colombia, 2014. [ Links ]
[4] W. Dillon, and M. Goldstein, "Multivariate Analysis, Methods and Applications", Jhon Wiley and Sons, pp. 186-190, 1984. [ Links ]
[5] D. F. Morrison, "Multivariate Statistical Methods", Mc Graw Hill, pp. 389-391, 1990. [ Links ]
[6] B. Tian, C. A. Kulikowsky, G. Leiguang, Y. Bin, H. Lan, and Z. Chunguang, "A Global Kmodes Algorithm for Clustering Categorical Data", Chinesse Journal of Electronics, vol. 21, no. 3, 2012. [ Links ]
[7] S. Mingoti, and R. Matos, "Clustering Algorithms for Categorical Data: A Monte Carlo Study", International Journal of Statistics and Applications, vol. 2, no. 4, pp. 24-32, 2012. [ Links ]

