











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1 Introducción
Los datos con censura a intervalo ocurren comúnmente en muchos campos, tales como: demografía, epidemiología y estudios médicos. En tales estudios, los participantes se someten periódicamente a observaciones o exámenes y los tiempos de falla no son observados exactamente, pero se conoce que se encuentran dentro de algún intervalo [1]. Esto último es un problema ya que convencionalmente se ha usado el límite inferior, el punto medio o el límite superior del intervalo de inspección como tiempo de falla, esto es conocido en la literatura como imputación simple y ha sido bastante utilizado por su simpleza frente a otros métodos [2]. Sin embargo, estos métodos presentan problemas de sesgo de los estimadores de la función de supervivencia, especialmente cuando los intervalos son de gran tamaño, o son de diferentes longitudes [3, 4]. El uso de los métodos de imputación múltiple incorporando variables auxiliares, es decir, información auxiliar acerca del tiempo de falla para las observaciones con censura a intervalo, pueden mejorar la eficiencia de los estimadores y reducir el efecto de visitas perdidas en comparación con enfoques más simples [3].
Algunos métodos de imputación múltiple para estimar el modelo de riesgos proporcionales de Cox para datos con censura a intervalo fueron estudiados inicialmente por [5], donde proponen los algoritmos denominados PMDA (Poor Man's Data Augmentation) y ANDA (Asymptotic Normal Data Augmentation) para datos con censura a intervalo, basados en imputación múltiple para el modelo de regresión de Cox, y demostró que los resultados de las estimaciones de los coeficientes de regresión y el error estándar asociado suministra una alternativa prometedora para el estimador de máxima verosimilitud no paramétrico (NPMLE).
Un método alternativo de estimación de los parámetros del modelo de riesgos proporcionales de Cox para datos con censura a intervalo, que no involucra imputación de los tiempos de falla no observados, fue propuesto por [6] y consiste en un algoritmo ICM (Iterative Convex Minorant). En [7] se reformuló el algoritmo ICM como un método de proyección gradiente generalizado el cual conduce a una extensión natural al modelo de Cox. Los enfoques Bayesianos para el análisis de datos con censura a intervalo nos presentan otra opción para abordar el problema de estimación. En [1] proponen un novedoso y eficiente enfoque Bayesiano para el análisis de los datos con censura general bajo el modelo de riesgos proporcionales de Cox.
En este trabajo, se comparará vía simulación el desempeño de los estimadores de los parámetros del modelo de riesgos proporcionales de Cox, producidos por el algoritmo ICM, por un enfoque Bayesiano y luego de aplicar los métodos de imputación múltiple PMDA y ANDA, para datos con censura a intervalo. La comparación se realizará utilizando el error cuadrático medio (ECM) de las respectivas estimaciones de los parámetros de interés y la probabilidad de cobertura empírica obtenida bajo un nivel de confianza nominal del 95%.
En la Sección 2 se describen brevemente los datos de vida censurados a intervalos, el modelo de riesgos proporcionales de Cox y los métodos de estimación basados en el algoritmo ICM (Iterative Convex Minorant) y en un enfoque Bayesiano. La Sección 3 describe los métodos de imputación múltiple PMDA y ANDA. Un estudio de simulación y el análisis de sus resultados es presentado en la Sección 4. La Sección 5 presenta una aplicación en datos reales asociados a un estudio de mastitis en ganado lechero. Finalmente, en la Sección 6 se presentan las conclusiones del trabajo.
2 Conceptos básicos
2.1 Datos de vida censurados a intervalo
Una de las características de los datos de tiempos de vida es la censura. Para las observaciones con censura a intervalo, sólo se conoce un intervalo, dentro del cual la falla ha ocurrido. Los tiempos de falla exactos y la censura a la derecha pueden ser registrados como un caso especial de los tiempos de falla con censura a intervalo, en tales casos, el intervalo se reduce a un simple punto en los tiempos exactos y para la censura a la derecha el intervalo consiste del límite inferior y el límite superior se toma como infinito, es decir, un número muy grande, ya que el evento de interés no se presenta.
Suponga que los tiempos de vida para n individuos independientes consisten de n intervalos (uno por individuo), dados por
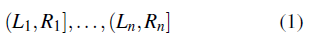
Los datos de vida censurados por intervalo que incluyen al menos un intervalo (L, R] con ambos L y R pertenencientes a (0, ∞), son usualmente referidos como datos con censura a intervalo general o tipo II [6, 8, 9]. Es decir, los datos con censura a intervalo tipo II son datos con censura que incluyen algunos intervalos finitos que no contienen el cero. Otra manera de representar una observación con censura a intervalo tipo II es usar:
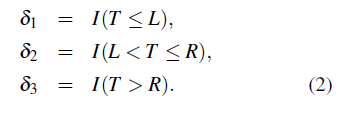
donde 0 ≤ L i ≤ T i ≤ R i ≤ ∞y L i < R i para todo i, es decir, una observación censurada a intervalo por individuo, donde Ti es el tiempo de falla no observado del individuo i.
Asumiendo que cada sujeto es observado dos veces, donde L y R son dos variables aleatorias que satisfacen L < R con probabilidad 1, es decir, las observaciones son censuradas a intervalo. Note que, si L = R se tienen datos exactos y por lo tanto no existe la necesidad de la imputación. Este trabajo se enfocará estrictamente en observaciones censuradas a intervalo. Sea T una variable aleatoria que representa el tiempo de falla de un individuo, δ1 es la indicadora de una censura a la izquierda, es decir, el evento de interés sucedió antes de inicio del proceso de observación, δ2 es la indicadora de una censura a intervalo, es decir, el evento de interés sucedió dentro de un intervalo de dos observaciones consecutivas y δ 3 es la indicadora de una censura a la derecha, es decir el evento de interés no sucedió hasta el final del proceso de observación. Este tipo de datos surgen de estudios longitudinales con seguimientos periódicos.
2.2 Modelo de riesgos proporcionales de Cox
En los modelos de riesgos proporcionales de Cox, la función de riesgo depende en general del tiempo y un conjunto de variables explicatorias, las cuales pueden ser por ejemplo un indicador de tratamiento, la edad y el género. Un análisis de regresión suministra una evaluación de los efectos de las variables explicatorias en el tiempo de falla. El modelo de riesgos proporcionales propuesto por [10], separa estos componentes especificando que el riesgo en el tiempo t para un individuo cuyo vector de variables explicatorias es x, está dado por:
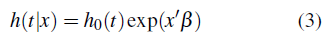
donde h0(t) es la función de riesgo de la distribución base F 0 y β es un vector de coeficientes de regresión. El segundo término está escrito en forma exponencial porque debe ser positivo, X’ β es llamado el predictor lineal. El modelo en (3) implica que la razón de riesgos para dos individuos depende únicamente de la diferencia entre sus predictores lineales en cualquier tiempo. Este modelo especifica que las variables explicatorias actúan multiplicativamente en la función de riesgo.
Bajo el modelo de riesgos proporcionales la función de supervivencia condicional de T dado x tiene la forma
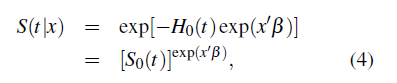
Donde
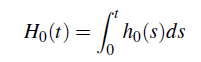
y
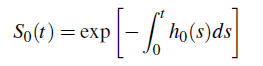
son la función de riesgo acumulada base y la función de supervivencia base.
La función de riesgo acumulada condicional de T dado x tiene la forma
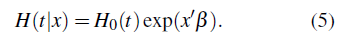
El modelo de riesgos proporcionales es el modelo de regresión más usado en el análisis de tiempos de falla.
2.3 Estimación del modelo de Cox para datos con censura a intervalo usando el algoritmo ICM
Para entender el algoritmo ICM, se debe revisar la proyección gradiente generalizada (GGP), un esquema de optimización general [11, 12]. Específicamente, suponga que se quiere maximizar una función f (x) en un conjunto cerrado convexo X. Denote ∇f la primera derivada de f, H una matriz simétrica definida positiva. La GGP actualiza su estimación actual x(i) por
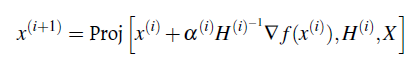
donde, α (i) > 0 y Proj es la operación proyección definida por
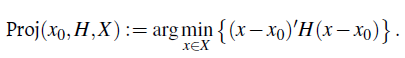
La iteración x(i) en la convergencia se toma como una solución del problema de maximización.
Observe que en el modelo de Cox, la ecuación (4) se puede escribir en términos de las funciones de distribución, así:
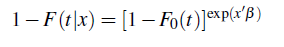
donde F0 es la distribución de base desconocida, β es el vector de coeficientes de regresión y las n observaciones son: (L1, R1, X1),..., (Ln, Rn, Xn).
El log de la verosimilitud es [13]:
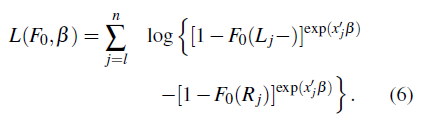
L se maximiza para obtener el NPMLE de los coeficientes de regresión junto con la distribución de base,
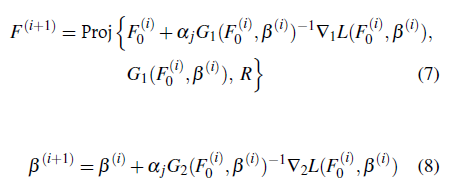
donde α
j
y Proj fueron definidos anteriormente. La proyección se toma para asegurar que la estimación de F
0 sea una función de distribución apropiada lo que requiere que
En [7] se propone maximizar la verosimilitud conjuntamente con F 0 y β.
Este método no suministra información necesaria para calcular los intervalos de confianza para los parámetros de regresión, esta característica es un gran inconveniente para este método. Se usó bootstrap para calcular los intervalos de confianza de los parámetros.
2.4 Enfoque Bayesiano
Siguiendo a [1], suponga que existen n sujetos independientes en el estudio. Por cada sujeto j denote por Tj el tiempo de falla de interés y xj el vector de variables explicatorias. Tj no es observado exactamente pero se conoce que cae en un intervalo observado (Lj, Rj]. Denote por F (t |x) la función de distribución acumulada del tiempo de falla de interés dado el vector de variables explicatorias x. Por lo tanto, para el modelo de riesgos proporcionales de Cox, F(t|x) = 1−exp[−Δ0(t)exp(x′β)], donde Δ0 (t) denota la función de riesgo acumulada base. La verosimilitud basada en los datos observados (Lj,Rj,x j)n j es
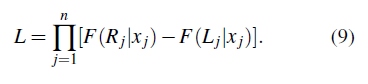
El intervalo observado (Lj, Rj] para el tiempo de falla Tj toma (0, Rj] en el caso de la censura a la izquierda y (Lj, ∞) en el caso de la censura a la derecha. Para diferenciar los tipos de censura la función de verosimilitud está dada por:
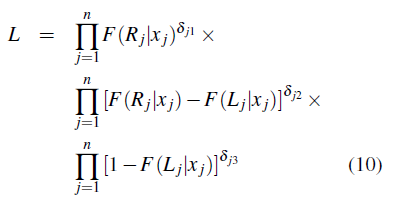
donde δj1, δj2, δj3 son las indicadoras de censura para el sujeto j, denotando censura a la izquierda, intervalo y derecha, respectivamente, y δj1 + δj2 + δj3 = 1. Este enfoque está basado en la función de verosimilitud dada en (11).
Es mejor usar la función de verosimilitud porque no requiere especificar ningún supuesto de la distribución del proceso de observación. Cuando la distribución del proceso de observación no contiene los parámetros de interés β y Δ0, la función de verosimilitud hace una inferencia eficiente de β y Δ0 [14].
El modelo de la función de riesgo acumulada base, Δ0(t), está basado en una combinación lineal de splines monótonos [15, 16, 17]. Esta estrategia ha sido efectivamente usada para modelar funciones no decrecientes desconocidas en otros modelos de supervivencia, tales como modelar la distribución acumulada base transformada del modelo probit [18] y la odds base [19] o el logaritmo de la odds base [20] en el modelo de odds proporcionales. La función de riesgo acumulada base es modelada así,
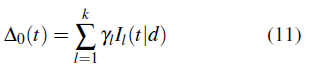
donde cada I l (.|d) es una función base de splines monótonos con grado d, cada una de ellas es una función no decreciente de 0 a 1, y las yi's son coeficientes no negativos de los splines con el fin de asegurar que Δ0 (t) sea una función no decreciente, d controla el suavizamiento de los splines, tomando primero las funciones por tramos lineales, luego las funciones cuadráticas seguido de las funciones cúbicas, etc. Los splines monótonos son llamados I-splines (o integrados) porque ellos son funciones integradas de M-splines [15].
Los métodos Bayesianos por lo general requieren muestrear todos los parámetros desconocidos y las variables latentes de sus distribuciones posteriores formadas por la combinación de la función de verosimilitud y la distribución apriori. Con el fin de facilitar el cálculo de la distribución posterior en [1] se propone un aumento de datos tomando ventaja de la relación del modelo de riesgos proporcionales y un proceso de Poisson latente no homogéneo.
Se especifican las distribuciones apriori de los parámetros desconocidos β y y = (y 1 ,y2,y k ). Se asignaron distribuciones apriori exponenciales, exp(λ), para los yl's y se asignó una distribución apriori Gamma G(α λ , b λ ) al hiperparámetro x, con media α λ /b λ y varianza α λ / b 2 λ . Esta especificación de la apriori es favorable desde una perspectiva computacional porque conduce a formas conjugadas para cada una de las distribuciones condicionales posteriores de los yl's y de λ. Este enfoque trata a λ como aleatoria y asigna a este hiperparámetro una distribución apriori Gamma, con el fin de permitir un ajuste automático con mucho menos esfuerzo computacional. Para β r , r = 1,2,...,p se asignaron distribuciones apriori normales, π(βr) = N(µ r , σ r 2 ), esto conduce a una distribución posterior condicional log-concava para cada βr, que se puede muestrear fácilmente usando el muestreo de rechazo adaptado (ARS) [21]. Los valores especificados para α λ = b λ = 1 y σ2 j = 100.
3 Métodos de imputación múltiple
Los datos con censura a intervalo son realmente datos incompletos, y no exactamente datos faltantes, sin embargo, es posible realizar el proceso de imputación de este tipo de datos a través de los tiempos observados. La imputación múltiple a diferencia de la imputación simple reemplaza cada valor no observado por dos o más valores probables lo que conduce a múltiples conjuntos de datos imputados cada uno de los cuales es analizado separadamente por un método estándar, los análisis de estos conjuntos de datos toman en cuenta la variabilidad debida a los valores no observados de los datos originales [22].
3.1 Algoritmo PMDA para los datos con censura a intervalo
En [5] se utilizó el algoritmo PMDA dado en [23] con el fin de imputar los tiempos de supervivencia de datos con censura a intervalo, esto implica crear conjuntos de datos múltiples imputados usando el siguiente algoritmo iterativo.
El superíndice (i) representa la i-ésima iteración, el subíndice k da cuenta del k-ésimo conjunto de datos imputados y el subíndice j corresponde al número de observaciones.
Para un conjunto de datos arbitrario, se define ( L j , R j ) como la j-ésima observación con censura a intervalo, y sea X una matriz que representa las variables explicatorias del modelo de Cox, con X j la j-ésima fila de esta matriz, j = 1,..., n. Entonces, los parámetros a ser estimados incluyen al vector de coeficientes de regresión β y a la función de supervivencia base S 0 .
a. Para comenzar, suponga que las estimaciones actuales del coeficiente de regresión y la supervivencia base son
b. Genere m bases de datos de posibles observaciones con censura a la derecha. Para ello, el k-ésimo conjunto de datos (k = 1,..., m) se obtiene así:
Para cada observación (L
j
, R
j
, X’
j
), j = 1,..., n: si R
j
< ∞, obtenga Z
j
de la distribución
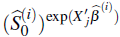 , condicional en que (L
j
< Z
j
≤ R
j
) y haga Tk
j
= Z
j
y δ
kj
= 1. Si R
j
= ∞, haga T
kj
= L
j
y δ
kj
= 0.
, condicional en que (L
j
< Z
j
≤ R
j
) y haga Tk
j
= Z
j
y δ
kj
= 1. Si R
j
= ∞, haga T
kj
= L
j
y δ
kj
= 0.
c. Use cada base de datos del paso anterior para ajustar un modelo de Cox y obtener las estimaciones
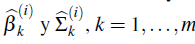 .
.
d. Basado en
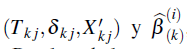 , calcule el estimador de Breslow de la supervivencia base
, calcule el estimador de Breslow de la supervivencia base
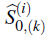 parak = 1,...,m.
parak = 1,...,m.
e. Haga
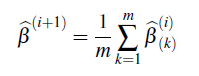
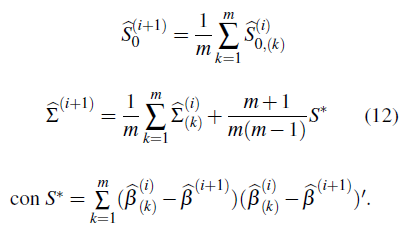
f. Verifique que
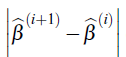 es suficientemente pequeño (la estimación i +1 convergió). Si no, haga i + 1 igual a i, vuelva al paso a. y repita el procedimiento hasta que la estimación converja.
es suficientemente pequeño (la estimación i +1 convergió). Si no, haga i + 1 igual a i, vuelva al paso a. y repita el procedimiento hasta que la estimación converja.
Los valores de
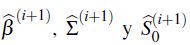 donde se obtiene la convergencia son las estimaciones finales.
donde se obtiene la convergencia son las estimaciones finales.
3.2 Algoritmo ANDA para datos con censura a intervalo
El algoritmo ANDA se implementa modificando el algoritmo PMDA, así:
• A partir de la primera iteración, en el paso e. se aproxima la posterior del coeficiente de regresión como una mezcla de distribuciones normales,
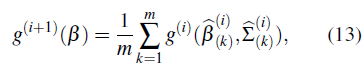
donde g
(i)
es una función de densidad de probabilidad normal multivariada, con media
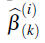 y matriz de vananzas-covananzas
y matriz de vananzas-covananzas
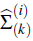 .
.
• A partir de la segunda iteración, en el paso b. primero se muestrea m veces de g
(i)
(β) para obtener β
(i)
k, k = 1 , 2, .. , m. Luego, para cada k y cada observación con censura a intervalo ( L
j
, R
j
, X
j
) , se obtiene Z
j
de la distribución
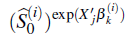 , condicional en que (Lj < Z
j
≤ R
j
) y conserva las observaciones con censura a la derecha.
, condicional en que (Lj < Z
j
≤ R
j
) y conserva las observaciones con censura a la derecha.
• Los otros pasos son los mismos que en el método PMDA.
4 Estudio de simulación
Se desarrolla un estudio de simulación con el fin de comparar los resultados en la estimación de los parámetros de un modelo de Cox producidos por el Algoritmo ICM, el enfoque Bayesiano y al aplicar los métodos de imputación múltiple PMDA y ANDA en los datos con censura a intervalo. El protocolo de simulación usado en este trabajo siguió el propuesto por [1], donde los datos corresponden a individuos que se someten periódicamente a observaciones o exámenes.
Los pasos del estudio de simulación son los siguientes:
Generación de los datos. Se generaron 500 bases de datos con tres tamaños de muestra: 50, 100, 200, del siguiente modelo:
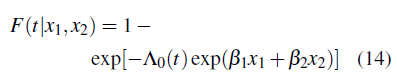
donde x1 es una variable aleatoria Bernoulli(0.5) y x2 es una variable aleatoria Normal(0, 0.52) y la función de distribución acumulada base se tomó Λ0 (t) = t + log (1 +1). Cada individuo tiene un número aleatorio de observaciones, correspondientes a visitas periódicas, las cuales son aleatorias para cada sujeto (el sujeto puede no asistir a una visita programada), pero para cada uno se garantiza al menos una visita. El número de visitas está determinado por 1 mas una variable aleatoria Poisson con media igual a 2. Los tiempos de las visitas se determinan con una distribución exponencial con media igual a 1. El intervalo observado es determinado por dos observaciones adyacentes dentro del cual se encuentra el tiempo de falla verdadero.
Se tomaron varias configuraciones para los valores de los parámetros: β1 = 1 y β2 = 0, β1 = 0 y β2 = 1, β1 = 1 y β2 = 1 y β1 = 0 y β2 = 0. De acuerdo a este esquema de generación de datos, la tasa de censura a la derecha se encuentra entre el 9% y el 21% para todas las configuraciones de los valores de los parámetros.
2. Implementación de los métodos de estimación de los parámetros del modelo de riesgos proporcionales de Cox, los cuales son: Los métodos PMDA y ANDA a través del paquete MIICD, el algoritmo ICM a través del paquete intcox y el enfoque Bayesiano a través del paquete ICBayes.
4.1 Resultados
En las Tablas 1, 2 y 3, se presentan los resultados de cada uno de los métodos de estimación antes descritos, basado en 500 bases de datos simuladas con tamaños de muestra 50, 100, y 200, respectivamente. En cada tabla, se presentan los parámetros estimados del modelo de Cox, junto con el error cuadrático medio estimado (ECM) y la probabilidad de cobertura empírica (CR).
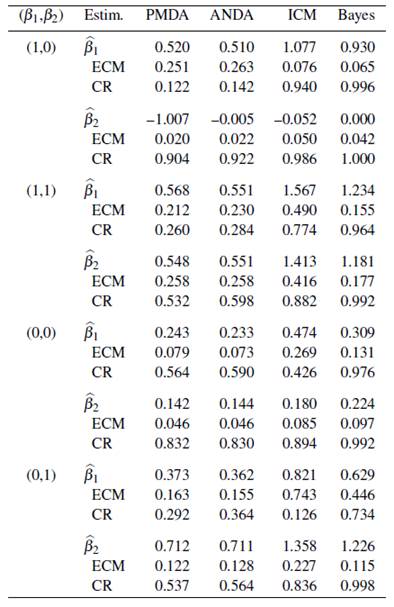
Tabla 2 Resultados de los métodos de estimación del modelo de Cox para un tamaño de muestra n = 100.
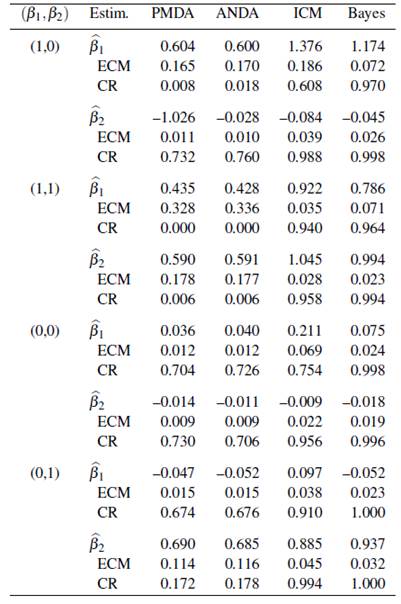
Tabla 3 Resultados de los métodos de estimación del modelo de Cox para un tamaño de muestra n = 200.

En la Figura 1, se muestran las probabilidades de cobertura (CR) de los métodos estudiados para cada uno de los escenarios (cada fila corresponde a una combinación de parámetros distinta).
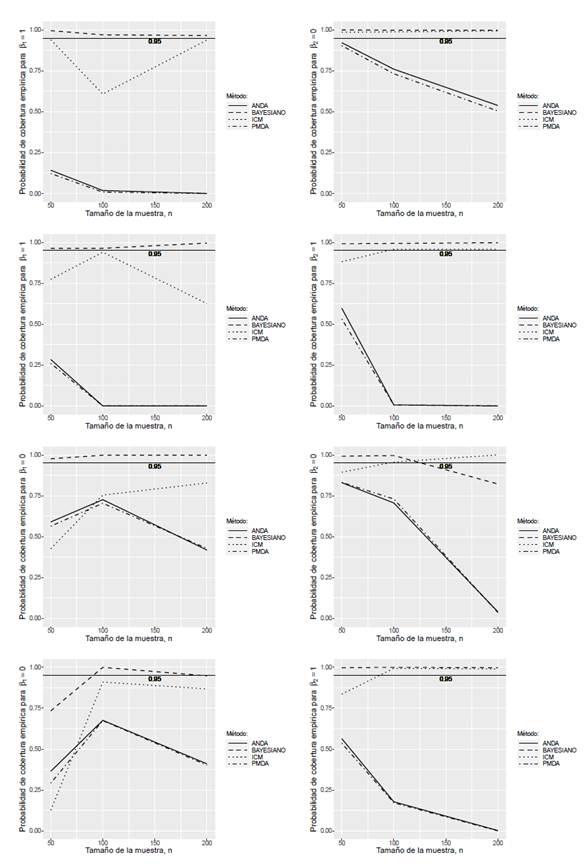
Figura 1 Probabilidades de cobertura alcanzadas por los métodos estudiados a un nivel de confianza nominal del 95%
En la Figura 2, se muestran los errores cuadráticos medios (ECM) de los métodos estudiados para cada uno de los escenarios (cada fila corresponde a una combinación de parámetros distinta).
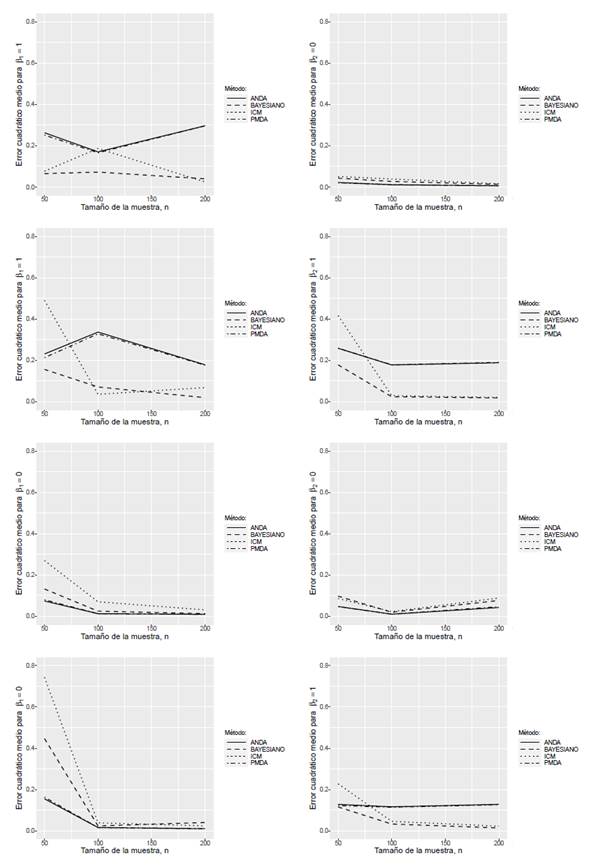
4.2 Análisis de los resultados de simulación
De acuerdo a los resultados obtenidos en el estudio de simulación se puede observar que las estimaciones resultantes del algoritmo ICM y del enfoque Bayesiano presentan en la mayoría de las configuraciones de los parámetros del modelo de Cox mejores probabilidades de cobertura que los métodos de imputación PMDA y ANDA. En relación al error cuadrático medio, se puede apreciar que en algunas configuraciones de los parámetros los métodos de estimación basados en imputación a través de los algoritmos PMDA y ANDA presentan valores más bajos que los otros dos métodos.
Al aumentar el tamaño de la muestra los métodos de estimación bajo estudio tienden a disminuir el error cuadrático medio en la mayoría de los escenarios de parámetros considerados. Con respecto a la probabilidad de cobertura, se observa que al aumentar el tamaño de la muestra el método basado en un enfoque Bayesiano produce valores altos en la mayoría de las configuraciones, seguido del método de estimación basado en el algoritmo ICM (especialmente para muestras mayores a 50), mientras que los métodos de imputación PMDA y ANDA producen probabilidades de cobertura considerablemente bajas.
Para los métodos de imputación PMDA y ANDA se observa que la estimación de la variable continua presenta valores de probabilidad de cobertura más altos y errores cuadráticos medios más bajos que en la variable discreta. En el método basado en un enfoque Bayesiano no se aprecian diferencias apreciables entre las probabilidades de cobertura ni entre los errores cuadráticos medios obtenidos con los dos tipos de variables. En el método basado en el algoritmo ICM los valores más altos de probabilidad de cobertura y los valores más bajos de error cuadrático medio se presentan en la variable continua.
No se observan diferencias en los esquemas de imputación múltiple PMDA y ANDA, pues sus resultados son muy similares en todas las configuraciones de los parámetros.
Los métodos de imputación PMDA y ANDA presentan los mayores tiempos de simulación (1 a 3 días), seguido del método basado en un enfoque Bayesiano (30 a 40 minutos), mientras que los menores tiempos de simulación fueron obtenidos por el método de estimación basado en el algoritmo ICM (3 a 4 minutos).
5 Aplicación a una base de datos real
Se aplican los métodos de estimación del algoritmo ICM y el enfoque Bayesiano para un modelo de riesgos proporcionales de Cox a una base de datos real con censura a intervalo y se analiza el desempeño de las estimaciones de los parámetros. Estos dos métodos fueron seleccionados, ya que mostraron un mejor desempeño en el estudio de simulación presentado en la Sección 4.
Datos de mastitis en ganado lechero.
La mastitis en el ganado lechero es la inflamación de la ubre y la más importante enfermedad en el sector lechero del mundo occidental. La mastitis reduce la producción y la calidad de la leche. En [24] se llevó a cabo un estudio de mastitis donde se incluyeron 100 vacas desde el momento del parto (se asume que están libres de la infección). Fueron examinadas mensualmente a nivel de cuarto de ubre para detectar infecciones bacterianas. Dado que los cuartos de ubre están separados, un cuarto puede estar infectado mientras que el resto de los cuartos permanecen libres de infección. Las vacas fueron examinadas hasta el final del período de lactancia que dura aproximadamente entre 300 a 350 días. Algunas vacas se perdieron el seguimiento debido por ejemplo, al sacrificio. Debido al seguimiento mensual aproximado (excepto en julio/agosto en el cual sólo se planeó una visita por falta de personal), y a que en estas condiciones, es imposible observar exactamente los tiempos en los que ocurren los eventos de interés (infección de mastitis), los datos son censurados a intervalo. Los datos con censura a la derecha se presentan cuando no ocurre la infección antes del final del período de lactancia o por el tiempo perdido en el seguimiento. En este caso se tiene un porcentaje de datos con censura a derecha del 20.7%. Se registraron dos variables explicatorias, la primera (x 1 ) es la posición del cuarto de ubre (delantera o trasera) y la segunda (x 2 ) es el número de partos, con los siguientes niveles: (1) un parto, (2-4) 2 a 4 partos y (>4) más de 4 partos. Ambas variables han sido sugeridas en la literatura que impactan la incidencia de la mastitis [25, 26].
En la Tabla 4 se muestran los resultados obtenidos aplicando el método de estimación basado en un enfoque Bayesiano para los datos de mastitis.
Tabla 4 Parámetros estimados
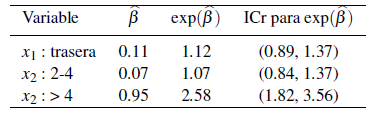
De acuerdo a los resultados se tiene lo siguiente:
El riesgo de que una vaca contraiga mastitis es 1.12 veces más alto si la posición de la ubre es trasera en relación a si la posición de la ubre es delantera (nivel de referencia).
El riesgo de que una vaca que ha tenido entre 2-4 partos contraiga mastitis es 1.07 veces mayor que si la vaca ha tenido 1 parto (nivel de referencia).
El riesgo de que una vaca que ha tenido más de 4 partos contraiga mastitis es 2.58 veces mayor que si la vaca ha tenido 1 parto (nivel de referencia).
La Tabla 5 presenta los resultados obtenidos aplicando el algoritmo ICM para los datos de mastitis.
Tabla 5 Parámetros estimados
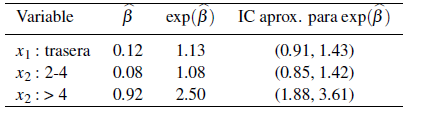
De acuerdo a los resultados se tiene lo siguiente:
El riesgo de que una vaca contraiga mastitis es 1.13 veces más alto si la posición de la ubre es trasera en relación a si la posición de la ubre es delantera (nivel de referencia).
El riesgo de que una vaca que ha tenido entre 2-4 partos contraiga mastitis es 1.08 veces mayor que si la vaca ha tenido 1 parto (nivel de referencia).
El riesgo de que una vaca que ha tenido más de 4 partos contraiga mastitis es 2.5 veces mayor que si la vaca ha tenido 1 parto (nivel de referencia).
A pesar de que el algoritmo ICM no suministra información necesaria para calcular intervalos de confianza para los parámetros de regresión se construyeron intervalos de confianza aproximados del 95% basados en remuestreo. El número de remuestras usado fue R = 10000.
6 Conclusiones
En términos generales el algoritmo ICM y el enfoque Bayesiano presentan valores de probabilidad de cobertura más altos y errores cuadráticos medios más bajos que los obtenidos de los métodos de imputación PMDA y ANDA.
Los métodos de imputación múltiple requieren aumentar las bases de datos para mejorar la probabilidad de cobertura pero para esto se necesitan tiempos de simulación demasiado grandes.
A medida que aumenta el tamaño de la muestra todos los métodos estudiados basados o no en imputación, tienden a mejorar tanto las probabilidades de cobertura como los errores cuadráticos medios.
Los métodos de imputación múltiple PMDA y ANDA no presentan diferencias considerables en sus resultados de desempeño.
En todos los métodos estudiados, se observa un mejor desempeño en la estimación del parámetro asociado a la variable continua, comparado con la estimación del parámetro asociado a la variable discreta.
En la aplicación a una base de datos real se puede observar que los valores de los parámetros obtenidos son muy similares tanto en el algoritmo ICM como del enfoque Bayesiano, lo cual es un resultado esperado, ya que en el estudio de simulación estos métodos presentaron resultados y desempeños muy parecidos.

