










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkIngeniería y Universidad
Print version ISSN 0123-2126
Ing. Univ. vol.14 no.1 Bogotá Jan./June 2010
Gestión de recursos de almacenamiento masivo en un ambiente de investigación virtual*
Massive Data Storage Resource Management in a virtual Research Environment**
Gestão de recursos de armazenamento massivo num ambiente de pesquisa virtual***
* Este artículo se deriva de un proyecto de investigación denominado Línea de investigación en ciencia y tecnología de la información y del conocimiento, financiado por el Centro de Investigaciones y Desarrollo Científico de la Universidad Distrital Francisco José de Caldas.
** This article results from the research project called Research on Science and Technology Related to Both Information and Knowledge, financed by the Research and Scientific Development Center of the Universidad Distrital Francisco José de Caldas.
*** Este artigo deriva-se de um projeto de pesquisa denominado Linha de pesquisa em ciência e tecnologia da informação e do conhecimento, financiado pelo Centro de Pesquisa e Desenvolvimento Científico da Universidade Distrital Francisco José de Caldas.
**** Ingeniera de sistemas. Especialista en Auditoría de Sistemas. Estudiante de Maestría en Ciencias de la Información y Comunicaciones, Universidad Distrital Francisco José de Caldas, Bogotá, Colombia. Correo electrónico: indiraduarte@gmail.com.
***** Ingeniero de sistemas. Máster en Teleinformática, Universidad Distrital Francisco José de Caldas, Bogotá, Colombia. Doctor en Informática, Universidad de Oviedo, España. Profesor titular de la Universidad Distrital Francisco José de Caldas. Correo electrónico: nelsonp@udistrital.edu.co.
Fecha de recepción: 21 de agosto de 2009. Fecha de aceptación para publicación: 18 de noviembre de 2009.
Submitted on August 21, 2009. Accepted on November 18, 2009.
Data de recepção: 21 de agosto de 2009. Data de aceitação para publicação: 18 de novembro de 2010.
Resumen
La administración de repositorios de almacenamiento masivo de datos es uno de los problemas importantes de resolver en entornos virtuales de investigación, donde la complejidad de manipular grandes volúmenes de datos implica ofrecer un alto grado de control para asegurar que los datos se ubiquen correctamente y estén permanentemente disponibles para su procesamiento. Este documento discute la creación novedosa de un sistema de almacenamiento masivo en un centro de computación de alto desempeño, que utiliza las ventajas del almacenamiento jerárquico para el manejo eficiente de la información y el adecuado aprovechamiento de los recursos de almacenamiento disponibles. Los resultados de la investigación están orientados a suplir las necesidades de investigadores que requieren almacenar los archivos resultantes de tareas ejecutadas en recursos distribuidos, sin tener que preocuparse por los detalles técnicos de las tecnologías de almacenamiento utilizadas.
Palabras clave: Computación distribuida (sistemas para computador), administración de redes de computadores, entornos virtuales compartidos.
Abstract
Managing massive data storage repositories is one of the most important problems to solve in virtual research environments, where the complexity of handling large volumes of data involves providing a high degree of control to ensure that data are located properly and are permanently available for processing. This paper discusses the innovative creation of a massive storage system at a highperformance computer center, which uses the advantages of hierarchical storage for an efficient management of information and a proper utilization of available storage resources. Research results seek to meet the needs of researchers who need to store files resulting from tasks performed on distributed resources, without a concern about technical details of the storage technologies used.
Key words: Computational grids (computer systems), computer networks - management, shared virtual environments.
Resumo
A administração de repositórios de armazenamento massivo de dados é um dos problemas importantes a resolver em entornos virtuais de pesquisa, onde a complexidade de manipular grandes volumes de dados implica oferecer um alto grau de controle para assegurar que os dados se encontrem corretamente e estejam permanentemente disponíveis para seu processamento. Este documento discute a criação de um sistema de armazenamento massivo em um centro de computação de alto desempenho que utiliza as vantagens do armazenamento hierárquico para o gerenciamento eficiente da informação e o adequado aproveitamento dos recursos de armazenamento disponíveis. Os resultados da pesquisa estão orientados a suprir as necessidades de pesquisadores que requerem armazenar os arquivos resultantes de tarefas executadas em recursos distribuídos, sem ter que preocupar-se pelos detalhes técnicos das tecnologias de armazenamento utilizadas.
Palavras-Chave: Computação distribuída (sistemas para computador), administração de redes de computadores, entornos virtuais compartilhados.
Introducción
El crecimiento exponencial del avance tecnológico y la omnipresencia de la web han posibilitado una profunda revolución y marcado nuevos derroteros en la práctica de la investigación científica en este siglo, fundamentada en gran medida en la colaboración, la simulación numérica a gran escala, el análisis de grandes volúmenes de datos, el acceso remoto al aparato experimental y un profundo apoyo en las comunidades científicas virtuales, más allá los esfuerzos experimentales y teóricos individuales.
Los archivos multipetabyte (1015 bytes) son comunes en campos como la astronomía, la biología, la medicina, la ingeniería ambiental y la física de partículas (Hey y Threfeten, 2003). El análisis de esta enorme cantidad de datos permite generar nuevo conocimiento referente a la naturaleza de la materia, la vida, el ambiente y otros aspectos del mundo físico, todo esto gracias a la aptitud y capacidad de los sensores, sistemas de almacenamiento, computadores y las redes avanzadas, que permiten crear grandes repositorios de datos.
Por ejemplo, la comunidad de física de partículas ha desarrollado un ambicioso conjunto de experimentos en la facilidad experimental conocida con el nombre de gran colisionador de hadrones. Se experimenta a una escala nunca antes vista por los físicos y se cuenta con la colaboración de cientos de instituciones y miles de físicos en todo el planeta. Para ello se requiere una infraestructura informática y de comunicaciones que permita el transporte y la minería de datos distribuidos de gigantesco volumen. La creación de esta infraestructura se logró mediante la colaboración en varios proyectos de computación Grid (Avery y Foster, 2001; Particle Physics Data Grid (PPDG), s. f.; Avery et al., 2001; EU DataGrid, 2010; DataTAG, 2010; Starlight, 2010).
De igual manera, se generan enormes volúmenes de datos, resultado de grandes procesos de detección mediante sensores en campos tan diversos como la observación ambiental y de la tierra, astronomía y cuidado de la salud humana. Se estima que el Observatorio Virtual Nacional (NVO, por su sigla en inglés) de Estados Unidos almacenará 500 terabytes por año (NVO, 2010).
De manera similar, el proyecto del Observatorio Gravitacional de Interferometría Láser genera 250 petabytes por año a partir de 2002 (Barish y Weiss, 1999). Una nueva generación de exploración astronómica, como el proyecto VISTA, en las regiones del visible y del infrarrojo (VISTA, 2010), contribuye a transformar los requerimientos de captura de datos de la comunidad de astronomía. El telescopio del proyecto VISTA genera desde 2004 aproximadamente 250 gigabytes de datos brutos por noche y alrededor de 10 terabytes por año.
Así mismo, en los diversos campos de la medicina, las técnicas de escanografía digital están permitiendo que mamogramas y otras imágenes médicas se procesen y almacenen en línea, en lugar de bibliotecas de filminas. En los hospitales se están ensamblando bases de datos multiterabyte y para los laboratorios está siendo más fácil comparar imágenes a lo largo del tiempo, para individuos y entre poblaciones, lo cual es de gran utilidad y permite detectar anomalías fisiológicas; además, facilita estudios epidemiológicos de un alcance sin precedentes y a una escala que proveerá una nueva visión respecto al impacto ambiental y el ciclo evolutivo de las enfermedades.
En disciplinas científicas como la climatología y la astrofísica, donde los experimentos físicos no pueden realizarse, pero las simulaciones computacionales son factibles, el cálculo numérico representa otra nueva metodología de solución de problemas, que por derecho propio, crece cada vez más en importancia (Kaufmann y Smarr, 1993).
Con la aparición de grandes y ultrarrápidos computadores considerados una importante instrumentación científica externa se han generado simulaciones que logran decenas de terabytes de datos por ejecución. Todas estas transformaciones ocurren en las ciencias de la vida: un ejemplo claro es el proyecto Enciclopedia of Life, que busca producir una base de datos referente al genoma humano y que requiere una capacidad computacional considerable en la medida en que nuevas secuencias del genoma estén disponibles.
Las simulaciones físicas y numéricas —para desarrollar modelos cada vez más precisos, completos y complejos, junto con las herramientas colaborativas— ayudan en la planeación de los experimentos y permiten a la comunidad de las ciencias de la información geográfica emplear recursos de telepresencia que les permitan, desde sitios remotos, realizar teleobservación y teleoperación de experimentos y acceder a recursos computacionales y a herramientas analíticas de fuente abierta, para la simulación y el análisis de datos experimentales (Hadida et al., 2000; Johnston et al., 1997; Takaoka et al., 2000).
En la ciencia e ingeniería del siglo XXI es muy importante la naturaleza distribuida y colaborativa, cada vez mayor, de los equipos que se conforman para explotar este potencial. La naturaleza colaborativa de la ciencia, en muchos de sus aspectos, es inseparable de las nuevas capacidades aportadas por el desarrollo tecnológico (Goble et al., 2004a y 2004b; Atkinson et al., 2004).
El objetivo es permitir a los científicos usar la información necesaria puesta en la red de manera colaborativa, al tiempo que se ayuda a formar grupos dinámicos que aborden los nuevos problemas de investigación. Las facilidades de personalización relativas a la selección de recursos, la gestión de datos y la promulgación de procesos permitirán crear conjuntos de datos y vistas personales sobre repositorios, así como adicionar anotaciones personales a conjuntos de datos y un servicio de notificación personalizado respecto a los cambios en bases de datos relevantes, todo esto en beneficio de la ciencia y del mejoramiento de la calidad de vida de la sociedad.
1. Infraestructuras para e-ciencia
Las redes avanzadas de alta velocidad, como es el caso de la Red RENATA en Colombia, constituyen el soporte estratégico para la colaboración en el ámbito científico. Bajo la denominada e-ciencia, los científicos de todo el mundo están en condiciones de colaborar para construir un conjunto de herramientas de software y servicios, a fin de ser desplegados por encima de estas infraestructuras de comunicación. La meta es disponer de un conjunto de servicios que permitan a los científicos establecer ambientes seguros y controlados para el uso compartido de recursos distribuidos para la investigación científica. En conjunto, estos servicios informáticos avanzados, en conjunción con las redes avanzadas, constituyen la denominada e-infraestructura requerida para la investigación científica colaborativa.
En particular, el proyecto EELA (e-infraestructura compartida entre Europa y Latinoamérica) busca construir un puente digital entre las iniciativas de e-infraestructuras existentes, las que están en proceso de consolidación en Europa y aquellas que están emergiendo en América Latina, mediante la creación de una red colaborativa que compartirá una infraestructura Grid interoperable, basada en las redes GEANT2 y CLARA, para el desarrollo y puesta en marcha de aplicaciones avanzadas en biomedicina, física de altas energías, e-educación y climatología. Dado su rango de acción, EELA ayudará a reducir la brecha digital en la región latinoamericana, al poner a disposición de los investigadores una e-infraestructura muy poderosa sobre la cual podrán desarrollar investigaciones complejas de una manera sencilla, extensible, en un futuro, a una amplia comunidad de usuarios.
Por otra parte, el interés por consolidar la iniciativa nacional denominada Grid Colombia ha logrado concretar apoyos muy sólidos, gracias a alianzas internacionales en las que el apoyo de la Open Science Grid tiene un carácter decisivo y estratégico para la investigación científica nacional.
1.1 Redes avanzadas
En la economía internacional basada en el conocimiento es de gran importancia que la producción teórica encuentre su camino hacia la comunidad de investigadores y hacia la sociedad misma en los ámbitos público y privado. Es crucial crear un acceso amplio a los resultados de la investigación básica y aplicada, situación que puede alcanzarse de manera concertada. Se requiere una infraestructura que marque un cambio definitivo en las prácticas institucionales, conformada por colaboratorios, ambientes de aprendizaje colaborativo, un nuevo ciclo de vida del conocimiento y nuevos modelos evolutivos y de publicación de resultados.
Lo anterior implica el diseño, la construcción y el uso experimental de una infraestructura de redes avanzadas, considerando tres elementos clave:
- Establecimiento de colaboratorios (internamente en las instituciones e interinstitucionalmente en los ámbitos nacional e internacional).
- Innovación del ciclo de vida del conocimiento.
- Desarrollo y prueba de nuevos modelos de publicación de resultados.
En concordancia con lo anterior, la Universidad Distrital ha abordado la construcción de la Red de Investigaciones de Tecnología Avanzada (RITA), de modo que esté completamente operacional en el menor tiempo posible. Se requiere que la nueva combinación de IP y de las tecnologías ópticas se adecúe a los entornos de producción a gran escala. Adicionalmente, innovaciones como la de IP versión 6 deberán implantarse en el ambiente operacional.
1.2 Computación Grid
La computación Grid es un modelo tecnológico que hace virtuales recursos de computación, de modo distribuido sobre redes, usando estándares abiertos para facilitar operaciones heterogéneas. En su forma más simple, integra sistemas y computadores dispares dentro y entre varias instituciones, porque los considera un gran sistema (Stanzione y Jones, 2002). Puede usarse para manejar tareas muy grandes o que exigen alta demanda de recursos, difícil de obtener en sistemas y computadores individuales. Proporciona, además, una vista consolidada de enormes cantidades de datos localizados en bases de datos y sistemas de archivos distribuidos. Además, la Grid puede permitir el uso compartido de recursos de laboratorio, escasos y costosos, al tiempo que estimula mayor colaboración entre instituciones y las distintas instancias que los componen.
La Grid-UD será la infraestructura de computación de alto rendimiento que potenciará el pleno logro de la tarea estratégica fundamental, de convertir a la Universidad Distrital Francisco José de Caldas en una institución que logre "saberes, conocimientos e investigación de alto impacto para el desarrollo humano y social", según el eslogan de su Plan Estratégico de Desarrollo 2007-2016.
1.3 e-infraestructura del Centro para la Computación de Alto Desempeño
El objetivo fundamental del Centro para la Computación de Alto Desempeño (Cecad) de la Facultad de Ingeniería de la Universidad Distrital, como una novedosa infraestructura de apoyo a las actividades inherentes a la e-ciencia, es dar un sólido paso hacia la constitución de un colaboratorio interinstitucional con universidades nacionales y del exterior. La configuración física básica del Cecad, se muestra en la Figura 1.
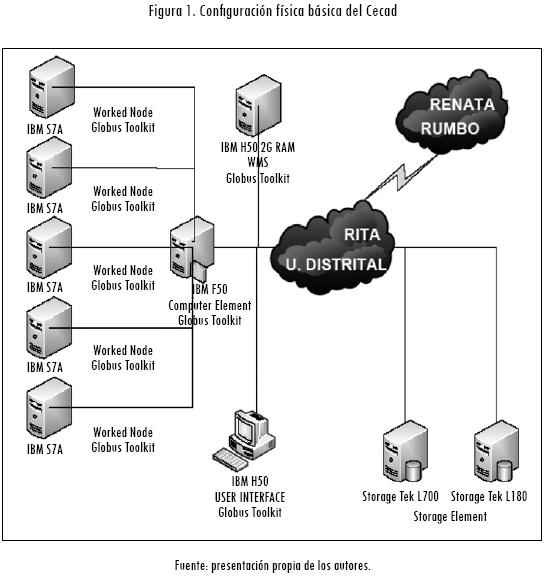
Se dice en la literatura científica que un colaboratorio es "un centro sin paredes, en el que los investigadores pueden realizar su trabajo, sin preocuparse de su localización física, interactuando con colegas, teniendo acceso a la instrumentación, compartiendo datos y recursos computacionales y accediendo a información en bibliotecas digitales" (Wulf, 1989, p. 1). El término colaboratorio es un híbrido que resulta de colaborar y laboratorio. De ahí que las elaboraciones del concepto laboratorio hagan hincapié en la necesidad de resolver los problemas del control y operación de instrumentos sobre internet, la interacción conveniente y flexible entre colegas y la gestión de recursos de almacenamiento masivo.
2. Metodología
2.1 Modelo para la gestión de los recursos de almacenamiento
Hoy en día, los requerimientos de almacenamiento de la comunidad científica se atienden mediante diversos dispositivos que abarcan desde sistemas de disco sencillos hasta grandes sistemas con cintas y robótica específica para el efecto. En los entornos de computación a gran escala, la comunidad científica necesita acceder a grandes sistemas de almacenamiento, gracias a diversos protocolos de computación Grid. En este documento se presenta la estrategia de diseño y construcción de un sistema de almacenamiento masivo como un recurso de software y de hardware para que pueda ser aprovechado de la mejor manera por la comunidad investigativa.
La cantidad de datos científicos generados por experimentos de simulaciones o recolectados a partir de experimentos a gran escala, como se dijo en párrafos anteriores, es tan grande que no puede ser almacenada localmente en la estación de trabajo de un investigador o en su centro de cómputo local. Tales datos son de importancia crucial para los experimentos científicos realizados en los ambientes virtuales de investigación de hoy en día. Además de los aspectos computacionales y del ancho de banda requerido en las redes avanzadas, es imprescindible contar con auténticos gestores de recursos de almacenamiento para una eficiente administración de enormes conjuntos de datos distribuidos. El acceso a los datos es un cuello de botella importante en aquellas aplicaciones intensivas en datos, puesto que son imposibles de reproducir en todos los sitios. Los sistemas de gestión de recursos de almacenamiento masivo resultan de importancia crítica para superar el mencionado cuello de botella.
Los gestores de recursos de almacenamiento no realizan operaciones de movimiento de archivos de forma directa, sino que interactúan con los sistemas de almacenamiento masivo subyacentes al sistema operativo, para realizar la conservación de los archivos e invocar los componentes de software como GridFTP para realizar operaciones de transferencia. Existen varios tipos de gestores de recursos de almacenamiento: gestores de recursos de discos, gestores de recursos de cintas y gestores de recursos jerárquicos. A diferencia de un sistema de almacenamiento que asigna espacio a los usuarios de un modo estático, un gestor de recursos de almacenamiento se diseña para asignar recursos y espacio de manera ágil, lo que es de suma importancia para la naturaleza dinámica de los recursos que se comparten en computación Grid.
Un gestor de recursos de disco gestiona dinámicamente un caché de disco compartido simple. Este caché de disco puede ser un solo disco, una colección de discos o un conjunto redundante de discos independientes (RAID, por su sigla en inglés). El caché de disco está disponible para el cliente a través de un sistema operativo que provee una vista del sistema de archivos del caché del disco, con la capacidad usual para crear leer, escribir, abrir, cerrar y borrar archivos o directorios; sin embargo, el espacio no es preasignado a los clientes.
En su lugar, la cantidad de espacio asignado a cada cliente se maneja dinámicamente por el gestor de recursos de disco. La función de un gestor de recursos de disco es gestionar el caché del disco, usando alguna política de gestión de recursos del cliente que puede ser establecida por el administrador de caché del disco. La política puede restringir el número de peticiones simultáneas a cada cliente o puede dar un acceso preferencial a los clientes con base en su prioridad asignada. Además, un gestor de recursos de disco puede realizar operaciones para obtener archivos a partir del gestor de recursos de almacenamiento sobre la Grid.
Esta capacidad llegará a ser clara más tarde cuando se describa cómo los gestores de recursos de discos se usan en una Grid de datos. Utilizando un gestor de recursos de disco para múltiples clientes, se puede proveer una ventaja agregada de uso compartido de archivos entre los clientes y el uso repetido de los archivos. Esto es especialmente útil para comunidades científicas que probablemente tengan patrones de acceso a un archivo de modo traslapado. Se pueden usar políticas de gestión de caché que minimicen transferencias repetidas al caché del disco para sitios Grid remotos. Estas pueden basarse en la historia de uso o peticiones anticipadas.
Un gestor de recursos de cinta es un middleware que cuenta con una interfaz con sistemas que manejan cintas robóticas. Las cintas son accesibles a un cliente mediante un sistema de almacenamiento masivo sofisticado. Tales sistemas, por lo general, tienen un caché de disco que se usa para organizar archivos temporalmente antes de transferirlos a los clientes.
Un sistema jerárquico de almacenamiento es un gestor de recursos de disco que migra de forma automática archivos poco accedidos a un almacenamiento alternativo, manteniendo los archivos más frecuentemente usados en un medio de almacenamiento más ágil. Entonces, puede verse como una combinación de un gestor de recursos de disco y un gestor de recursos de cinta. Esta funcionalidad puede ser muy útil en una Grid de datos, puesto que el gestor de recursos jerárquico siempre dispone de los archivos para su procesamiento desde un medio de almacenamiento más ágil de una manera transparente.
Además, la transferencia de archivos grandes sobre una red de área extensa puede ser tan lenta que mientras un archivo es transferido, otro puede estar disponible desde la cinta. Dado que los sistemas de cinta robóticos son mecánicos por naturaleza, en consecuencia, tienen una latencia correspondiente al montaje de una cinta y la búsqueda hacia la localización de un archivo. La puesta en escena por anticipado puede ayudar a enmascarar la latencia. Similar al uso compartido de archivos sobre un gestor de recursos de disco, el prealistamiento del disco en un gestor de almacenamiento jerárquico puede usarse para compartir archivos. El objetivo es minimizar el prealistamiento de archivos desde el sistema robótico de cinta. El concepto de gestor de recursos de almacenamiento puede generalizarse a la gestión de recursos de almacenamiento múltiples en un sitio. En tales casos, el sitio del gestor de recursos de almacenamiento puede usar nombres-archivositio que no reflejan la localización física y los nombres de los archivos.
Esto le da al sitio la flexibilidad para mover archivos de un dispositivo a otro sin el cambio de nombres-archivo-sitio. Cuando un cliente accede un archivo usando nombre-archivo-sitio, este puede darse en respuesta a la localización física y el nombre del archivo. El cliente puede entonces usar el nombre físico del archivo para ejecutar una transferencia de archivos.
IBM Tivoli Storage Manager (TSM) es un software de almacenamiento que trata los desafíos de administración de almacenamiento compuesto en ambientes heterogéneos distribuidos. Soporta múltiples plataformas y proporciona una consistente interfaz gráfica de usuario. TSM proporciona gestión de almacenamiento jerárquico para migrar automáticamente archivos eventualmente accedidos a un almacenamiento alternativo, sin afectar los archivos más frecuentemente usados en almacenamiento local.
2.2 Experimento informático
El sistema propuesto se centra en el almacenamiento, la seguridad y el acceso a los archivos en la Grid del Cecad, de la Facultad de Ingeniería de la Universidad Distrital Francisco José de Caldas. El resultado de la investigación es un sistema de almacenamiento masivo que puede utilizarse desde una aplicación o desde un portal Grid, como se puede observar en la Figura 2.
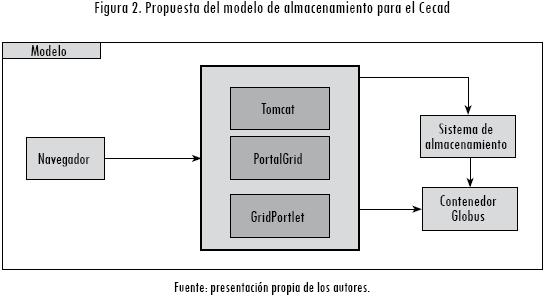
El experimento informático implementa el Globus Tool Kit (Lee, 2008) como contenedor de servicios en el nodo del sistema de almacenamiento y en el nodo del portal, incluidos los servicios requeridos para la gestión de los datos. El nodo servidor de aplicaciones utiliza el contenedor Tomcat como servidor web, junto con el marco de trabajo de Gridsphere para el despliegue de aplicaciones en el portal y un conjunto de portlets que usan propiamente los servicios Grid que se encuentran en el contenedor Globus. A su vez, los clientes utilizan un navegador web con el fin de visualizar las aplicaciones Grid a través del portal.
Uno de los principales objetivos del portal es facilitar las tareas al usuario presentando una interfaz sencilla y de fácil acceso, y así buscan solucionar problemas como que el acceso a los recursos de la Grid no sea complicado y de larga duración. Para lograrlo es necesario configurar los portlets y servicios básicos que permiten volver al sistema sencillo y seguro, confiando en la transmisión de información y en la autenticación de los usuarios en el portal.
2.3 Arquitectura
El experimento informático consta de un sistema de almacenamiento masivo en la Grid que proporciona el servicio utilizando la combinación de elementos de almacenamiento como disco y librerías de cintas robotizadas configuradas con software especializado de administración de almacenamiento y de transferencia de archivos en un entorno Grid.
El experimento está orientado a grupos de trabajo que tengan requerimientos de espacio para alojar archivos de tipo insumo o resultantes de trabajos ejecutados en la Grid. Se implementó la potente característica HSM (IBM, 2003) de Tivoli Storage Manager para el manejo eficiente de la administración del almacenamiento. Con el fin de proveer el servicio en la web, se utilizaron los portlets de autenticación de usuarios, registro de recursos y transferencia de archivos disponibles en el portal Grid del Cecad. Para la implementación y medición de resultados se definió la infraestructura de recursos mostrada en la Figura 3.
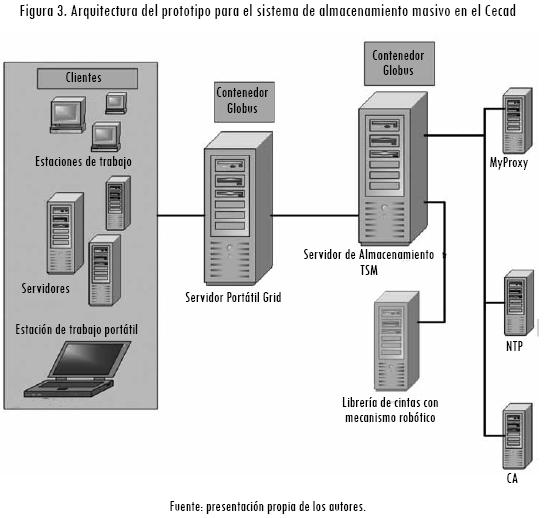
Un servidor IBM AS400 ejerce las funciones de administración del almacenamiento, en el que se instalaron los componentes del modelo: Tivoli Storage Manager Server, Tivoli Storage Manager Cliente, Hsm Client y Globus Tool Kit, con el servicio Grid FTP para transferencia de archivos. El servidor de almacenamiento se conectó físicamente través de un cable con puerto serial de tipo scsi a la biblioteca de cintas, que en el prototipo es el principal elemento de almacenamiento masivo. Otro servidor definido como el Servidor Portal Grid, producto del proyecto de Portal Grid (Montañez y Pérez, 2008), contiene el portal y sus componentes: Globus Toolkit, Tomcat, Gridsphere y Gridportlets.
3. Resultados
En la evaluación del prototipo del portal para el Cecad se utilizaron los métodos de evaluación heurísticos y el test de usuarios con el objetivo de medir su usabilidad. Para la evaluación por parte de los usuarios se determinó una valoración positiva si se cumplió con las expectativas de resultado esperado y como negativa si no se cumple con alguna o ninguna de las expectativas. Los resultados de la evaluación se pueden observar en la Tabla 1.

Como se puede observar, se encontraron algunos inconvenientes a lo largo del proyecto, los cuales se solucionaron en su gran mayoría. Uno de ellos fue superar los límites definidos en el sistema de archivos de almacenamiento jerárquico. Para resolver este inconveniente se implementaron umbrales menores en el sistema de archivos, con el fin de que el proceso de migración iniciara tempranamente y así tomar ventaja sobre la agilidad del copiado a disco. Para dotar de seguridad al servicio Grid, la transferencia de archivos no es posible sin la previa autenticación del usuario para la recuperación de credenciales.
Se lograron obtener los resultados esperados en la utilización del prototipo de almacenamiento masivo y se pudo apreciar la adecuada transferencia de los archivos a los dispositivos configurados con la característica de almacenamiento jerárquico. Adicionalmente, el proceso de migración de archivos se comportó de acuerdo con la configuración de las políticas asignadas al sistema de archivos y a las definiciones de pool de almacenamiento, con la oportuna ejecución automática del proceso cuando los umbrales del sistema de archivos fueron superados.
En los resultados obtenidos de tiempos (Deeths y Brunette, 2001) y tamaños de archivos se pudo apreciar que su transferencia toma menos tiempo cuando se transfieren archivos de tamaño pequeño. Esta tarea mantiene tiempos de menos de cuatro segundos, demuestra que los pequeños caben totalmente en el buffer de la memoria del servidor de almacenamiento y posibilita la transferencia del archivo completo en una sola trama sin necesidad de dividir la transferencia en varias tramas pequeñas. Se pudo también apreciar cómo a medida que el tamaño del archivo aumenta, la tasa de transferencia disminuye; ello indica que a mayor tamaño de archivo, hay menor desempeño. Los resultados corresponden a una muestra aleatoria del comportamiento probable, ya que deben tenerse en cuenta factores como la red, la memoria de la tarjeta de red, la memoria del disco, la memoria del servidor, la actividad en la red y la actividad en los servidores.
Cualquiera de los administradores del portal Grid o el usuario final puede acceder al portlet siguiendo una serie de pasos para utilizar el recurso de almacenamiento masivo. Primero, desde un navegador web se ingresa la URL del portal Grid. Seguidamente, el usuario debe introducir su nombre de usuario y contraseña que se lo autorice. Una vez que el usuario ha entrado a su sesión, deberá ser capaz de ingresar al portlet y escoger el recurso al cual podrá acceder al almacenamiento masivo. El usuario activa la acción de transferencia una vez determine el archivo o archivos que desea transferir.
4. Conclusiones
En este trabajo se abordó el problema de la administración de recursos de almacenamiento en un entorno virtual de investigación, sustentado en computación Grid, que se caracteriza por el procesamiento de grandes cantidades de datos como producto de diversos tipos de experimentos científicos en la actualidad. Se describió el modelo computacional, el diseño experimental y el desarrollo de un experimento informático conducente a un novedoso gestor de almacenamiento masivo jerárquico, cuya finalidad consiste en garantizar espacio de almacenamiento de forma dinámica para ponerlo a disposición de otros proyectos de investigación, como los servicios de notificación y observación de datos adquiridos a partir de observaciones hechas por geosensores (Báez y Pérez, 2009), servicios Grid inteligentes para la clasificación de imágenes usando algoritmos genéticos (Hoyos y Pérez, 2007) y de autómatas celulares (Amézquita y Pérez, 2010), en los que el requerimiento de espacio de almacenamiento disponible es vital por la magnitud en el número y tamaño de los archivos utilizados.
Durante el trabajo se identificaron las ventajas y desventajas de estándares usados para administración de recursos de almacenamiento masivo, usando de manera creativa e innovadora el TSM, al incorporarlo de manera novedosa al entorno de computación Grid del Cecad y al lograr una adecuada utilización del almacenamiento y del servicio de transferencia de archivos, en recursos remotos sobre la plataforma Globus.
Para configurar de manera total el Cecad se sugiere incorporar a la plataforma computacional el servicio de transferencia confiable de archivos (Stewart, 2006), donde el movimiento de los archivos no esté orientado a conexión, sino a una tarea determinada o servicio. Contando con HSM, para obtener un mejor desempeño, podrían utilizarse los resultados de esta investigación en un esquema tipo Storage Area Network (SAN) con conexión de fibra óptica entre servidores y dispositivos de forma que estos recursos estén compartidos a través de la red de almacenamiento sin necesidad de utilizar la red Ethernet, de modo que las operaciones lleguen directamente a cada dispositivo.
Referencias
AMÉZQUITA, G. y PÉREZ, J. N. Servicio grid para la clasificación no supervisada de imágenes satelitales utilizando autómatas celulares. Revista Ciencia e Ingeniería Neogranadina, 2009, vol. 19, núm. 2, pp. 59-76. [ Links ]
ATKINSON, M. et al. Data access, integration and management. En The Grid 2: Blueprint for a new computing infrastructure. 2a ed. New York: Elsevier, 2004. [ Links ]
AVERY, P. y FOSTER, I. The GriPhyN project: toward petascale virtual data Grids [Documento en línea]. Technical Report GriPhyN-2001-14, 2001. <http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.113.5195&rep=rep1&type=pdf> [Consulta: 23-03-2010]. [ Links ]
AVERY, P. et al. An international virtual-data Grid laboratory for data intensive science [documento en línea]. Technical Report GriPhyN-2001-2, 2001. <http://www.phys.ufl.edu/~avery/ivdgl/itr2001/proposal_all.pdf> [Consulta: 23-03-2010]. [ Links ]
BÁEZ, C. y PÉREZ, J. N. Planteamiento de un modelo para los servicios Grid de notificación y registro de información geográfica. Revista Gerencia Tecnológica Informática, 2009, vol. 8, núm. 20. [ Links ]
BARISH, B. C. y WEISS, R. LIGO and the detection of gravitacional waves. Physics Today, 1999, vol. 52, núm. 10, p. 44. [ Links ]
DataTAG. Research and Tecnological Development for a TransAtlantic Grid Project [web en línea]. <http://datatag.web.cern.ch/datatag/> [Consulta: 23-02-2010]. [ Links ]
DEETHS, D. y BRUNETTE, G. Using NTP to control and Synchronize System Clocks [documento en línea]. Palo Alto (CA): Sun Microsytems, 2001. <http://www.sun.com/blueprints/0701/NTP.pdf> [Consulta: 13-04-2010]. [ Links ]
EU DATAGRID. European Union DataGrid Project [web en línea]. <http://eu-datagrid.web.cern.ch/eu-datagrid/> [Consulta: 23-03-2010]. [ Links ]
GOBLE, C. A. et al. Enhancing services and applications with knowledge and semantics. En The Grid 2: blueprint for a new computing infrastructure. 2a ed. New York: Elsevier, 2004. [ Links ]
GOBLE, C., GREENHALGH, PETTIFER, S., STEVENS, R., Knowledge Integration: In Silico Experiments in Bioinformatics. The Grid 2. Blueprint for a New Computing Infrastructure. Second Edition. Elsevier, 2004. [ Links ]
GRIDLAB. Proyecto GridLab [web en línea]. <http://www.gridlab.org/> [Consulta: 10-5-2009]. [ Links ]
HADIDA, M. et al. Advanced networking for telemicroscopy. 10 th Annual Internet Society Conference, Yokohama, Japan, 2000. [ Links ]
HEY, A. y THREFETEN, A. The data deluge: An escience perspective. En Grid computing: making the global infrastructure a reality. New York: Wiley, 2003. [ Links ]
HOYOS, G. y PÉREZ, J. N. Aplicación de los algoritmos genéticos a la clasificación de imágenes de satélite en el marco de los servicios Grid inteligentes estado del arte. Ciencia e Ingeniería Neogranadina, 2007, vol. 17, núm. 2, pp. 59-76. [ Links ]
IBM. IBM Tivoli Storage Manager for space management for UNIX [libro en línea], 2003. <http://publib.boulder.ibm.com/tividd/td/TSPMGR/GC32-0794-02/en_US/PDF/ansh0000.pdf> [Consulta: 25-6-2009]. [ Links ]
JOHNSTON, W. et al. High-speed distributed data handling for on-line instrumentation systems. Conference on High Performance Networking and Computing. San José, 1997. [ Links ]
KAUFMANN, W. J. y SMARR, L. L. Supercomputing and the transformation of science. New York: Scientific American Library, 1993. [ Links ]
LEE, L. Open Globus Primer: introduction to Globus software. Source Grid and Cluster Conference, University of Chicago, Argonne National Laboratory, 2008. [ Links ]
MONTAÑEZ, S. y PÉREZ, J. N. Modelo de portal para el laboratorio de computación Grid. Revista Ingeniería y Universidad, 2008, vol. 12, núm. 2, pp. 213-228. [ Links ]
NATIONAL VIRTUAL OBSERVATORY (NVO) [web en línea]. <http://www.us-vo.org/> [Consulta: 23-02-2010]. [ Links ]
PARTICLE PHYSICS DATA GRID (PPDG) [web en línea]. <http://www.ppdg.net/> [Consulta:23-02-2010]. [ Links ]
STANZIONE, D. y JONES W. Computational mini-Grid at Clemson University. Clemson: Parallel Architecture Research Lab, 2002. [ Links ]
STARLIGHT. The optical START TAP [web en línea]. <http://www.startap.net/starlight/> [Consulta: 23-02-2010]. [ Links ]
STEWART, G. A. Grid data management: reliable file transfer services' performance. Glasgow: University of Glasgow, 2006. [ Links ]
TAKAOKA, A. et al. International telemicroscopy with a 3MV ultrahigh voltage electron microscope. Ultramicroscopy, 2000, vol. 83, núms. 1-2, pp. 93-101. [ Links ]
VISTA. Visible & Infrared Telescope for Astronomy Project [web en línea]. <http://www.vista.ac.uk/> [Consulta: 23-02-2010]. [ Links ]
WIKIPEDIA. Storage Area Network [web en línea]. <http://en.wikipedia.org/wiki/Storage_area_network> [Consulta: 25-4-2009]. [ Links ]
WULF, W. The national collaboratory. En Towards a national collaboratory. New York: Rockefeller University, 1989. [ Links ]

