










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares en
SciELO
Similares en
SciELO -
 Similares en Google
Similares en Google
Compartir

 Permalink
PermalinkIngeniería y Universidad
versión impresa ISSN 0123-2126
Ing. Univ. vol.16 no.2 Bogotá jul./dic. 2012
Evolución diferencial aplicada a la sintonización de clasificadores difusos para el reconocimiento del lenguaje de señas1
Applying Differential Evolution to Tune Fuzzy Classifiers Intended for Sign-Language Recognition2
Evolução diferencial aplicada ti sintonização de classificadores difusos para o reconhecimento da língua de sinais3
Andrea Villate-Gil4
David Eduardo Rincón-Arandia5
Miguel Alberto Melgarejo-Rey6
1Este artículo se deriva del proyecto de investigación Propuesta e Implementation de un método de reconocimiento del Auslan basado en un clasificador difuso tipo-2 de intervalo sintonizado con evolución diferencial, desarrollado por el Laboratorio de Automática e Inteligencia Computacional (Lamie), de la Universidad Distrital Francisco José de Caldas. Bogotá, Colombia.
2Submitted on: September 30,2011. Accepted on: May 25,2012. This article is derived from the research project Proposai and Implementation of an Auslan Récognition Method based on a Fuzzy Classiñer Type-2, Interval Tuned with Differential Evolution, developed by the Laboratory of Automatizaron and Computation Intelligence, LAMICof Universidad Distrital FranciscoJosé de Caldas, Bogota, Colombia.
3Data de recebimento: 30 de setembro de 2011. Data de aceite: 25 de maio de 2012. Este artigo deriva se do projeto de pesquisa Proposta e implementado de um método de reconhecimento do Auslan baseado num classificador difuso tipo-2 de intervalo sintonizado com evolu¡do diferencial, áesemoMáo pelo Laboratório de Automática e Inteligência Computacional (Lamie), da Universidade Distrital Francisco José de Caldas. Bogotá, Colombia.
4Ingeniera electrónica, Universidad Distrital Francisco José de Caldas, Bogotá, Colombia. Estudiante investigadora del Laboratorio de Automática e Inteligencia Computacional (Lamie). Correo electrónico: avillateg@correo.udistrital.edu.co.
5Ingeniero electrónico, Universidad Distrital Francisco José de Caldas, Bogotá, Colombia. Estudiante investigador del Laboratorio de Automática e Inteligencia Computacional (Lamie). Correo electrónico: derincona@correo.udistrital.edu.co.
6Ingeniero electrónico, Universidad Distrital Francisco José de Caldas, Bogotá, Colombia. Magister en Ingeniería Electrónica y Computadores, Universidad de los Andes, Bogotá. Colombia, en cooperación con la École Polytechnique Fédérale, Lausanne, Suiza. Investigador del Laboratorio de Automática e Inteligencia Computacional (Lamie), profesor asociado de la Facultad de Ingeniería, Universidad Distrital Francisco José de Caldas. Bogotá, Colombia. Correo electrónico: mmelgarejo@udistrital.edu.co.
Fecha de recepción: 30 de septiembre de 2011. Fecha de aceptación: 25 de mayo de 2012.
Resumen
Este artículo presenta una propuesta metodológica para la sintonización de clasificadores difusos aplicados al reconocimiento del lenguaje de señas australiano para dos contextos particulares. Se expone la arquitectura de clasificación y la metodología de sintonización basada en evolución diferencial. Los resultados de validación muestran que es posible encontrar un clasificador difuso cuyo porcentaje de error está alrededor del 13,0% sobre una muestra de palabras derivadas de varios intérpretes para cada uno de los contextos definidos. Esta particularidad es relevante, dado que trabajos anteriores se centran en el reconocimiento de las palabras provistas por tan solo un intérprete.
Palabras clave: Auslan, clasificación difusa, evolución diferencial, lenguaje de señas, reconocimiento de patrones, optimización, sistemas difusos TSK.
Abstract
This paper presents a methodological approach for tuning fuzzy classifiers intended to recognize the Australian sign-language considering two particular contexts. We describe the fuzzy classification architecture and the tuning process based on differential evolution. The validation results show that it is possible to find a fuzzy classifier whose classification error is around 13.0% over a group of words taken from several experts for each interaction context. This characteristic is relevant as previous works only considered recognizing words provided only by one interpreter.
Key words: Auslan, differential evolution, fuzzy classification, pattern recognition, sign language, optimization, TSK Fuzzy Systems.
Resumo
Este artigo apresenta uma metodologia para a sintonização de classificadores difusos aplicados ao reconhecimento da língua de sinais australiano em dois contextos particulares. Expõe-se a arquitetura de classificação e a metodologia de sintonização baseada na evolução diferencial. Os resultados de validação mostram que é possível encontrar um classificador difuso cuja porcentagem de erro este ao redor de 13,0% sobre uma amostra de palavras derivadas de vários intérpretes para cada um dos contextos definidos. Esta particularidade é relevante, pois trabalhos anteriores centraram-se no reconhecimento das palavras providas por um intérprete só.
Palavras-chave: Auslan, classificação difusa, evolução diferencial, língua de sinais, reconhecimento de padrões, otimização, sistemas difusos TSK.
Introducción
El reconocimiento de los gestos de las manos ha impulsado el desarrollo de aplicaciones de alta tecnología, como la realidad virtual, el entretenimiento, las animaciones en tiempo real y la domótica (De Falco et al., 2008). El reconocimiento del lenguaje de señas se puede entender como un problema de clasificación que ha despertado interés en la comunidad científica, en busca de una comunicación transparente y efectiva entre las personas que emplean el lenguaje de señas y las que utilizan el lenguaje oral. Trabajos precedentes concuerdan en que el desempeño de los sistemas de reconocimiento del lenguaje de señas está sujeto a factores como las variaciones producidas por los cambios intrapersonales e interpersonales, las condiciones de iluminación, la apariencia y el solapamiento de la manos (Culver, 2004; Kadous, 1996; Saliza et al., 2006) y la similitud de los gestos.
Varios métodos se han propuesto para el reconocimiento del lenguaje de señas, entre los que se encuentran: modelos ocultos de Markov (HMM, por sus siglas en inglés) (Goh, 2005), máquinas de aprendizaje (ML, por sus siglas en inglés) (Kadous, 1996), sistemas difusos (Dimuro, 2007) y agrupamiento difuso (De Falco et al., 2008). Sin embargo, ninguno de estos trabajos tiene en cuenta los contextos particulares ni la incertidumbre de los movimientos que se genera entre persona y persona por factores culturales, económicos y educativos del intérprete. Lo anterior se debe a que solo se emplean las señas de un intérprete para el reconocimiento del lenguaje de señas.
Las inevitables variaciones presentes en el reconocimiento del lenguaje de señas han impulsado el uso de modelos que tienen la capacidad de manejar la incertidumbre (Villate y Rincón, 2011). Los sistemas difusos han sido una solución alterna en el proceso de clasificación de los movimientos de las manos (Dimuro, 2007). Un aspecto importante al emplear sistemas difusos en el reconocimiento del lenguaje de señas es la sintonización de sus parámetros, aspecto en el cual el modelado lingüístico presenta limitaciones asociadas al tipo de problema y a la intuición del experto (Peña, 2004). Por otra parte, el modelado de estos sistemas puede optimizarse utilizando métodos heurísticos como los algoritmos evolutivos (Peña, 2004). En los últimos años varias se han presentado aplicaciones para la sintonización de parámetros de sistemas difusos utilizando algoritmos evolutivos (Shill et al., 2010; Muñoz et al., 2008).
El algoritmo de evolución diferencial (ED) fue diseñado como optimizador de funciones en espacios continuos (Price et al., 2005; Mendes et al., 2005) además, se han realizado estudios comparativos en los que se muestra que el desempeño de la ED, así como sus variantes en problemas de optimización, es superior a otros algoritmos evolutivos (Moraglio y Togelius, 2009; Villate et al., 2011). Por otra parte, en Villate et al. (2011) se presenta una propuesta metodológica para la sintonización de los parámetros de sistemas de inferencia difusa mediante la ED para la predicción de una serie de tiempo. Al comprar los resultados estadísticos de la predicción empleando el método propuesto frente a un modelo difuso sintonizado con un algoritmo genético simple, se observan mejoras significativas al emplear la ED en la sintonización de los parámetros del modelo.
En este trabajo se desarrolla una metodología para la sintonización de los parámetros de las funciones de pertenencia de clasificadores difusos utilizando la ED, con el objetivo de reconocer las señas realizadas por cinco intérpretes derivadas de la base de datos del lenguaje de señas australiano (Auslan, por sus siglas en inglés). Los parámetros de la ED se seleccionan experimentalmente según los valores típicos presentados en la literatura consultada.
Este artículo está organizado de la siguiente manera: en el apartado 1 se presenta una descripción de la base de datos Auslan y su acondicionamiento. En el 2 se expone la arquitectura de clasificación propuesta para el reconocimiento del lenguaje de señas. El 3 presenta el acoplamiento entre la DE y la arquitectura de clasificación para ajustar sus parámetros. El apartado 4 describe los experimentos y se muestran los resultados obtenidos. Finalmente, en el 5 se presentan algunas conclusiones y trabajos futuros.
1. Descripción y acondicionamiento de la base de datos Auslan
La base de datos donada por Kadous y Sammut está compuesta por 95 señas del Auslan (Kadous, 1996). Cada instancia de la base de datos cuenta con las medidas de posición y orientación de la mano derecha, así como una medida de flexión de los dedos. Para el reconocimiento del lenguaje de señas se seleccionaron dos contextos particulares, cada uno con cinco palabras. Lo anterior, con el fin de considerar dos situaciones particulares que involucren la interacción de los sordomudos con su entorno social, como atención médica (contexto I) y compras en centros comerciales o supermercados (contexto II). Para el contexto I las palabras seleccionadas fueron: cold, crazy, alive, hear y head. Para el II las palabras fueron: money, shop, spend, surprise y drink (Villate y Rincón, 2011).
1.1. Selección de metacaracterísticas
Para la extracción de características relevantes, se utilizan metacaracterísticas, tal como lo propone Kadous (1996). Posteriormente se aplica un método de selección a las metacaracterísticas extraídas (Villate y Rincón, 2011). El objetivo de este método es seleccionar las que presentan la menor similitud entre clases. Para esto se modelan las metacaracterísticas mediante conjuntos difusos que permitan representar la tipicidad de las diferentes muestras que conforman una característica (Jalali et al., 2009).
Si se tiene el conjunto de clases |C1,...,Ck|, donde k = 1,2 ... K y ck ε RN y donde N es el conjunto de características M = {M1,...,MN} (i. e., metacaracterísticas), que para el caso del Auslan es N = 384 según Kadous (1996) y K = 5, y si, además, para cada clase ck se tienen m muestras del conjunto (i. e., m = 70) N -dimensional y si se denota como el m — ésimo conjunto de características, entonces:

Para proyectar cada uno de los elementos del conjunto de datos originales Ckm sobre un espacio difuso para cada una de las K clases según (2) utilizando K conjuntos difusos (i. e., uno por cada clase) denotados como AkN, se debe definir el tipo de función de pertenencia que se utilizará. En este caso se emplean funciones de pertenencia gaussianas, dado que representan distribuciones de posibilidad que se ajustan relativamente bien a los datos.
Después de la proyección de las clases, se calcula una medida de similitud entre los conjuntos difusos que modelan una característica. Mendel y Wu (2007) proponen utilizar una medida vectorial de similitud (MVS) entre conjuntos difusos, la cual está compuesta por una medida de proximidad y una de forma entre estos. Estudios comparativos han demostrado que esta medida vectorial provee mejores resultados al compararse con otras medidas de similitud entre conjuntos difusos. La MVS cumple las cuatro propiedades de una medida de similitud S para conjuntos difusos: la medida de similitud entre dos conjuntos es 1 si ellos son exactamente iguales, debe existir alguna medida de similitud S si dos conjuntos se interceptan, si la distancia entre dos conjuntos aumenta, la medida de similitud S entre ellos debe disminuir y la medida de similitud entre dos conjuntos debería ser constante, independientemente del orden en que son comparados.
Finalmente se aplica un criterio de selección de metacaracterísticas a partir de las medidas de similitud obtenidas. El criterio de selección está basado en los valores de similitud de las proyecciones de las clases para cada una de las metacaracterísticas. Se propone seleccionar las metacaracterísticas cuyos valores MVS están por debajo del umbral, el cual pertenece al intervalo [0,1].
2. Arquitectura propuesta del clasificador difuso
En la figura 1 se muestra la arquitectura del clasificador difuso que se propone para el reconocimiento del lenguaje de señas Auslan. En primer lugar, se descompone el problema de clasificación de K clases en K problemas de clasificación binaria donde cada clasificador binario difuso tiene una estructura no normalizada tipo Takagi-Sugeno-Kang (TSK) de orden cero (Tanaka et al., 1995). Esto permite que cada sistema difuso tenga un subconjunto de características de entrada Dkv que permita discriminar una clase de las restantes. Dado un vector de entrada x = [x1, x2,..., xp], la salidayk de cada sistema difuso de la figura 1 está dada por (2) cuando se emplean funciones de pertenencia tipo gaussianas y la t — norma producto como método de implicación.

Donde M yp se refieren al tamaño de la base de reglas y la longitud del vector de entrada, respectivamente. Además, el parámetro yi de cada clasificador binario para la regla Ri solo toma dos valores (i. e., -1 o 1). Donde "1" se refiere al valor que toma la salida de la regla R' en el caso de que un vector de características de entrada represente una clase, y al valor que toma la salida de la regla Ri en el caso de que un vector de características de entrada no represente una clase. Además, la arquitectura de clasificación propuesta tiene un seleccionador duro, el cual se encarga de determinar cuál sistema obtiene el máximo valor de salida de los K clasificadores difusos binarios. Los clasificadores que emplean diferentes conjuntos de características para cada clase se denominan clasificadores de clase dependiente y presentan varias ventajas sobre los clasificadores de clase independiente (Wang et al., 2008).
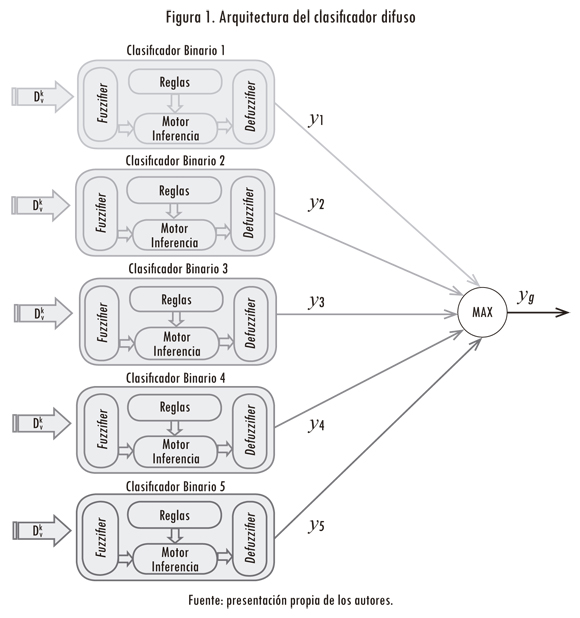
3. Método de sintonización
La figura 2 muestra la metodología propuesta para sintonizar los parámetros de cada sistema difuso (i. e., parámetros operacionales) de la figura 1 (Villate et al., 2011). Al representar cada sistema difuso de acuerdo con (2), se pueden sintonizar los parámetros de las funciones de pertenencia mediante la ED. Los demás parámetros del modelado difuso evolutivo son definidos por el diseñador, dependiendo del problema que pretende resolver (Hostos et al., 2011). Según la arquitectura de clasificación propuesta, se implementan cinco sistemas difusos para cada contexto, donde cada clasificador difuso binario se sintoniza de manera independiente, con el objetivo de discriminar una clase de las restantes, como se representa en la figura 1.
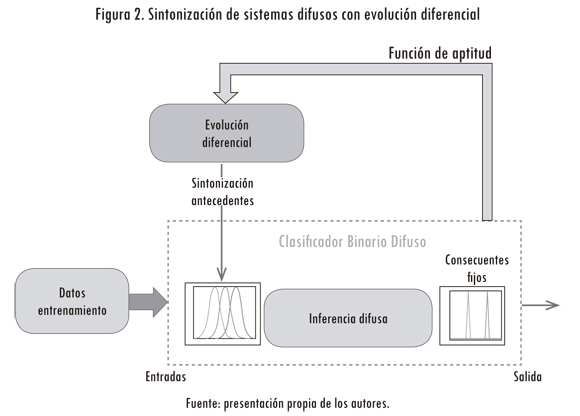
3.1. Evolución diferencial
La evolución diferencial (ED) es un método paralelo de búsqueda directa que utiliza Np vectores de D parámetros con valores reales (Price et al., 2005). La población actual P está compuesta de vectores X :
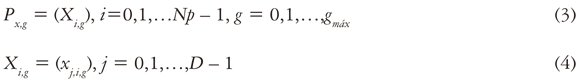
El índice g = 0,1, — ,gmáx indica la generación a la cual pertenece el vector. Además, a cada vector se le asigna un índice de población i, el cual se extiende desde 0 hasta Np — 1. A los parámetros dentro de los vectores se les asignan el índiceJ, el cual se extiende desde 0 hasta D — 1. Una vez inicializada la población, la ED muta aleatoriamente escogiendo los vectores con el objetivo de producir una población intermedia, Pv,g , de Np vectores mutantes, vi,g:
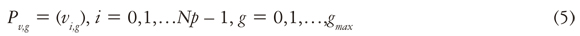

Cada vector en la población actual se recombina con un mutante para producir una población de prueba, Pu, de Np vectores de prueba, ui,g:
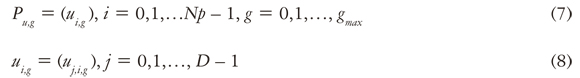
Inicialización: Cada vector de la población se inicializa aleatoriamente. El valor inicial (g =0) del j-ésimo parametro del i-ésimo vector es:

La función rand. (0,1) retorna un número aleatorio uniformemente distribuido dentro del rango [0,1]. Los vectores bL y bu definen los límites mínimos y máximos, respectivamente, para inicializar cada vector de la población.
Mutación: La ED muta y recombina la población actual para producir una población de prueba de Np individuos. En particular, la mutación diferencial adiciona un vector diferencia escalado, muestreando aleatoriamente un tercer vector:

El factor de escala F e (0,1) es un número real positivo que controla la tasa a la cual evoluciona la población. Valores efectivos de F rara vez son mayores a 1. El índice del vector base r0 puede ser determinado de varias formas, pero en general se escoge aleatoriamente; además, es diferente del índice del vector objetivo i.
Cruce: La ED emplea un cruce uniforme para completar la estrategia de búsqueda. En particular, cada vector se cruza con un vector mutante:
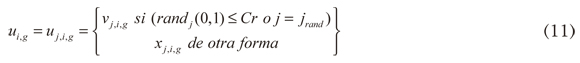
La probabilidad de mutación, Cr ∈(0,1), es un valor definido por el usuario para controlar la fracción de los valores de los parámetros copiados del vector mutante. El índice escogido aleatoriamente jrand del parámetro de prueba se toma del vector mutante para asegurar que el vector de prueba Xi,g no se duplique.
Selección: Si el vector de prueba, u , tiene un valor de la función objetivo menor o igual que el del vector objetivo, xi,g, reemplazará al vector objetivo en la próxima generación; de otra forma, el vector objetivo mantendrá su lugar en la población por al menos una generación más (18).

Una vez que la población se ha conformado, el proceso de mutación, recombinación y selección se repite hasta satisfacer un criterio de parada particular.
Las variantes de la ED difieren en el operador usado para la recombinación y en la forma en que la mutación se computa (Mezura et al. , 2006). Por ejemplo, en la variante de la ED llamada DE/best/1/bin se escoge el mejor individuo de la población para calcular la mutación y tan solo se selecciona una pareja para efectuar una recombinación binomial.
3.2. Construcción del cromosoma
Un vector de parámetros (i. e. , un cromosoma) representa a cada individuo de la población en el proceso evolutivo. Dentro del cromosoma se les asigna una posición a los parámetros que representan las funciones de pertenencia del antecedente; i. e., media (m) y desviación estándar (a). Al tratarse de un problema de clasificación en el que las clases son conocidas, los parámetros de los consecuentes permanecen constantes.
Si se define pa como el número de parámetros que caracterizan la forma de las funciones de pertenencia del antecedente (i. e., gaussianas), n como la longitud del vector de entrada del sistema difuso y M como el número de reglas, para un sistema difuso no normalizado con una base de reglas completa, múltiples entradas y única salida (MISO, por sus siglas en inglés), la longitud Lv del cromosoma está dada por:
L = M · n · p (13)
3.3. Parámetros de la evolución diferencial
Los parámetros de la ED se muestran en la tabla 1. La población inicial del algoritmo se conforma aleatoriamente con una distribución de probabilidad uniforme, como en Mezura et al. (2006) y Jeyakumar y Velayutham (2009). El número de individuos np que conforman la población se establece experimentalmente.
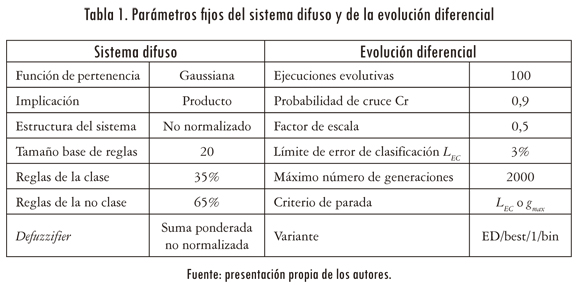
El factor de escala F se varía experimentalmente según valores típicos que garanticen la exploración de la ED sobre el espacio de las posibles soluciones, según Ed et al. (2008). En cuanto a la probabilidad de cruce Cr se establece en un valor cercano a 1 (i. e, 0,9) como en Mezura et al. (2006) y Noman e Iba (2008). Adicionalmente, se utiliza la variante DE/best/1/bin debido a que presenta el mejor rendimiento en problemas de optimización sobre otras variantes de la ED (Mezura, et al., 2006; Villate y Rincón, 2011).
4. Experimentación y resultados
En este apartado se describe el proceso experimental y sus resultados con el fin de establecer la configuración de algunos parámetros del método de clasificación expuesto en el apartado 3. Todos los experimentos se realizan sobre un computador con las siguientes especificaciones: Intel® Core 2TM Duo E8400 de 3 GHz, 3 Gb de memoria RAM y sistema operativo Ubuntu 10.10. Adicionalmente, los experimentos se realizaron utilizando el software libre de análisis numérico SCILAB-5.3.2.
En la tabla 1 se muestran los valores de los parámetros que permanecen constantes durante todos los experimentos. Se realizan 100 ejecuciones evolutivas en cada experimento debido a la naturaleza estocástica de la DE (Jeyakumar y Velayutham, 2009; Mezura et al., 2006). El número de reglas de los clasificadores se establece de forma experimental según (Villate y Rincón, 2011) en aras de lograr un desempeño aceptable con un costo computacional razonable. La distribución de las reglas no se realiza de manera uniforme debido a que existe un número mayor de instancias de la clase que de la no clase. Se utiliza el 80% del conjunto de instancias para entrenamiento y el 20% para validación (datos que no se usan durante el proceso de entrenamiento de los clasificadores) como propone Kadous (1996); este último porcentaje corresponde a 70 instancias provenientes de cinco intérpretes de Auslan.
La función de aptitud de los individuos Fa se calcula como se propone Peña (2004). Esta función combina dos criterios: FEC, que se refiere al error de clasificación y se computa como el porcentaje de instancias incorrectamente clasificadas (18), y FRMSE . que se refiere al error medio cuadrático que existe entre el valor esperado f y el valor obtenido y. del sistema difuso, como en (19), siendo MC las instancias incorrectamente clasificadas y LD el tamaño del conjunto de las instancias de entrenamiento.

4.1. Resultados del proceso de evolución
Por cada ejecución evolutiva se registró el mínimo error de clasificación en cada generación. Después estos errores se promediaron, en aras de observar el proceso evolutivo regular de los mejores individuos. El resultado de este promedio para las 100 ejecuciones evolutivas sobre un total de 2000 generaciones por ejecución se muestra en la figura 3.
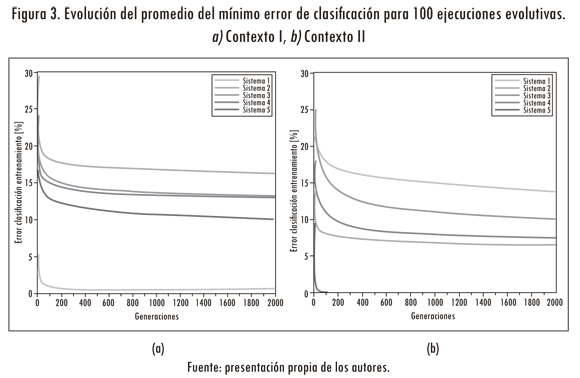
Los resultados se presentan diferenciados en los dos contextos seleccionados y en cada uno de ellos se muestra la evolución del mejor clasificador por palabra.
Para el contexto I, se muestra el desempeño de cinco sistemas clasificadores (i. e., cold, crazy, alive, hear y head, de los sistemas 1, 2, 3, 4 y 5, respectivamente). Se observó que los mínimos errores de entrenamiento promedio comienzan por debajo del 25,0% y al final de proceso evolutivo se encuentran por debajo del 20,0% en su totalidad. Nótese que el resultado de la evolución fue dependiente de la palabra que se clasificó; en tan solo un caso el resultado final en cuanto a error mínimo de clasificación quedó por debajo del 3%.
En cuanto al contexto II, (i. e., money, shop, spend, surprise y drink, de los sistemas 1, 2, 3, 4 y 5, respectivamente) se observan resultados similares a los ya comentados. El promedio del mínimo error por generación quedó al final de proceso evolutivo por debajo del 20,0% para todos los sistemas clasificadores y tan solo en un caso el resultado estuvo por debajo del 3,0%.
4.2. Resultados de validación
Los resultados de validación para el contexto I se presentan en la tabla 2. Se observa que el error porcentual de clasificación promedio sobre las 100 ejecuciones en validación CEy presentó una mejora porcentual del 6,21% y del 8,0% en la desviación estándar, respectivamente, al utilizar un tamaño de población np de 60 individuos sobre un tamaño de población np de 30 individuos. El mejor resultado encontrado en las ejecuciones, en términos de diseño, se presentó en el caso de np = 60, en el cual un individuo es capaz de clasificar correctamente 61 instancias de 70 (i. e., error de clasificación de 12,85%).

En la tabla 3 se presentan los resultados de validación para el contexto II. Se puede notar que al incrementar el tamaño de la población de 30 a 60 individuos, no existe una mejora en el error promedio de clasificación para las 100 ejecuciones, ni en su respectivo valor de desviación estándar. Sin embargo, sí es posible encontrar un mejor individuo clasificador en términos de diseño al aumentar el tamaño de la población. Para el caso de np = 60, el mejor individuo es capaz de clasificar correctamente 61 instancias de 70, al igual que el caso anterior.

4.3. Discusión
Los resultados obtenidos para los dos contextos presentan estadísticas similares en cuanto a error promedio de clasificación y desviación estándar para 100 ejecuciones evolutivas. Aun cuando el incremento del tamaño de la población np de la ED no tiene mayor incidencia sobre dichos resultados, sí tiene un efecto positivo en cuanto a resultados de diseño, dado que permite encontrar un mejor individuo clasificador en los dos contextos. El error de este individuo es inferior al del promedio obtenido de las 100 ejecuciones evolutivas. Esto se puede explicar sobre la base de que una población más grande favorece la diversidad genética y, por lo tanto, la exploración del espacio de soluciones.
La extrapolación de los resultados aquí obtenidos sobre una muestra de 10 palabras de la base de datos de Auslan no podría darse directamente a la totalidad de las 85 palabras restantes, dada la utilización de clasificadores de clase dependiente. La diferenciación de una clase respecto al resto está en función de su separabilidad respecto a las características seleccionadas. La ED tan solo busca la mejor configuración de parámetros de un sistema difuso que permite construir una función de separación para esa clase particular, como se evidenció en los resultados del proceso de evolución. Sin embargo, la evidencia obtenida en cuanto a validación sobre dos contextos independientes de cinco palabras nos permitiría sugerir que si bien la extrapolación no se puede dar directamente al resto de la base de datos, los resultados que se obtendrían podrían llegar a ser favorables.
5. Conclusiones
Se ha presentado una metodología para el reconocimiento de palabras del lenguaje de signos australiano (Auslan), la cual se fundamenta en un proceso de clasificación difusa sintonizado por medio de un algoritmo de evolución diferencial. El método también incluye un procedimiento de selección de características basado en el concepto de similitud vectorial entre conjuntos difusos. La evolución diferencial se enfoca en la búsqueda de los parámetros del antecedente de las reglas difusas de los clasificadores, los cuales se construyen desde la perspectiva de la clasificación de clase dependiente. El método se valida sobre dos grupos de palabras derivadas de dos contextos particulares de interacción.
Los resultados indican que es posible encontrar un individuo clasificador cuyo porcentaje de error es del 12,85% para cada uno de los contextos cuando el tamaño de la población de la evolución diferencial se configura en 60 individuos. Las instancias empleadas en la validación provienen de diferentes intérpretes. Esta particularidad es relevante, dado que trabajos anteriores se limitan únicamente a una validación sobre los ejemplos provistos por tan solo un intérprete.
Los autores consideran que los resultados aquí presentados se limitan a los contextos e instancias empleadas en este trabajo. No sería posible hacer una extrapolación directa al resto de las instancias de la base de datos Auslan; sin embargo, la aplicación del método sobre el resto de palabras podría ofrecer resultados favorables. En ese sentido, se propone como trabajo futuro extender la experimentación aquí desarrollada hacia el resto de ejemplos de la base de datos. Además, sería interesante y pertinente consolidar la construcción de una base de datos para el lenguaje de señas colombiano.
Referencias
CULVER, V. R. A hybrid sign language recognition system. Eighth International Symposium on Wearable Computers IEEE, 2004, pp 30-33. [ Links ]
FALCO, I.; DELLA CIOPPA, A.; MAISTO, D. et al. Automatic Recognition of Hand Gestures with Differential Evolution. Applications of Evolutionary Computing. Berling: Springer, 2008. pp. 265-274. [ Links ]
DIMURO, G. IP Hand gesture recognition in an interval fuzzy approach. TEMA, Tend. Matemática Aplicada e Computacional. 2007, vol. 8 núm. 1, pp 21-31. [ Links ]
ED, U. K. C.; BULL, V L.; y EDS, J. H. Advances in differential evolution. Computational intelligence. Berlin: Springer, 2008. pp 1-7. [ Links ]
GOH, P Automatic recognition of auslan finger spelling using hidden Markov models. Undergraduate. Australia: University of Western Australia, 2005. [ Links ]
HOSTOS, H.; SANABRIA, E; MÉNDEZ, O. et al. Towards a revolutionary approach for interval type-2 fuzzy modeling. IEEE International symposium on advances in type-2 fuzzy systems. Paris: 2011. [ Links ]
JALALI, L., NASIRI, M. y MINAEI, B. A Hybrid Feature Selection Method Based on Fuzzy Feature Selection and Consistency Measures. IEEE Science and Technology. Edinburgh: 2009, pp. 718-722. [ Links ]
JEYAKUMAR, G., y VELAYUTHAM, C. S. A comparative performance analysis of differential evolution and dynamic differential evolution variants. IEEE World Congress on Nature y Biologically Inspired Computing (NaBIC). Coimbatore: 2009, pp. 463-468. [ Links ]
KADOUS, M. W. Machine recognition of auslan signs using power gloves: towards large lexicon recognition of sign language. Workshop Integration of Gestures in Language and Speech. 1996, pp. 165-174. [ Links ]
MENDEL, J y WU, L. A vector similarity measure for type-1 fuzzy sets. IFSA 2007, LNAI 4529. Berlin Heidelberg: Springer-Verlag, 2007, pp. 575-583. [ Links ]
MENDES, R., y MOHAIS, A. DynDE: A Differential Evolution for Dynamic Optimization Problems. IEEE Congress on Evolutionary Computation. Edinburgh: 2005, pp. 2808-2815. [ Links ]
MEZURA, E.; VELÁSQUEZ, J., y COELLO, C. A. A comparative study of differential evolution variants for global optimization. Genetic Evol. Comput. Conf. (GECCO). Washington: 2006, pp. 485-492. [ Links ]
MORAGLIO, A., y TOGELIUS, J. Geometric differential Evolution. GECCO '09 Proceedings of the 11th Annual conference on Genetic and evolutionary computation. New York: 2009, pp. 1705-1712. [ Links ]
MUÑOZ, R.; AGUIRRE, E.; CORDÓN, O. et al. Automatic tuning of a fuzzy visual system using evolutionary algorithms : single-objective versus multiobjective approaches. IEEE Transactions on Fuzzy Systems. 2008, vol. 16. pp. 485-501. [ Links ]
NOMAN, N., y IBA, H. Accelerating differential evolution using an adaptive local search. IEEE Transactions on Evolutionary Computation. 2008, vol. 12, num. 1, pp. 107-125. [ Links ]
PEÑA, C. Coevolutionary fuzzy modeling. Lecture notes in computer science. Berlin: Springer, 2004, pp 51-68. [ Links ]
PRICE, K. V; STORN, R. M.; y LAMPINEN, J. A. Differential evolution a practical approach to global optimization. Journal of Global Optimization. 2005, pp. 1-37. [ Links ]
SALIZA, N.; JAIS, J.; MAZALAN, L. et al. Sign language to voice recognition: hand detection techniques for vision based approach. Image Processing Formatex. 2006, pp. 967-972. [ Links ]
SHILL, P. C.; AKHAND, M. A. H.; DAS, S. R., et al. Application of evolutionary algorithm in optimizing the fuzzy rule base for nonlinear system modeling and control. IEEE International Conference on Computer and Communication Engineering. Malaysia: 2010, pp. 1-6. [ Links ]
TANAKA, K., SANO, M., y WATANABE, H. Modeling and control of carbon monoxide concentration using a neuro-fuzzy technique. IEEE Transactions on Fuzzy Systems. 1995,vol. 3. pp. 271-279. [ Links ]
VILLATE, A., y RINCON, D. Propuesta e implementación de un método de reconocimiento del AUSLAN basado en un clasificador difuso tipo-2 de intervalo sintonizado con evolución diferencial. Director: Miguel A. Melgarejo R. Universidad Distrital Francisco José de Caldas. 2011. [ Links ]
VILLATE, A.; RINCON, D. E., y MELGAREJO, M. A. Sintonización de sistemas difusos utilizando evolución diferencial. IEEE XVIII International Congress of Electronic and Systems Engineering. Lima: 2011, pp. 1-8. [ Links ]
WANG, L.; ZHOU, N., y CHU, F. A general wrapper approach to selection of class dependent features. IEEE Transactions on Neural Networks. 2008, vol. 19, num 7, pp. 1267-1278. [ Links ]
