











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
Permalink
Introducción
Las criptomonedas son una moneda digital donde cada transacción se realiza de forma segura y se almacena en un bloque, conocido como Blockchain 1. Las transacciones en la Blockchain es una forma nueva, novedosa y segura de transferir dinero saltándose las regulaciones monetarias. Cada una de estas transacciones están disponibles para todos los usuarios para su verificación, lo que da transparencia en el proceso 2. La primera criptomoneda se desarrolló en el año 2008 y se ha convertido en la moneda digital más valiosa. A través de los años se han introducido muchos tipos de criptomonedas y actualmente, la segunda en transacciones es Ethereum.
Las criptomonedas se han convertido en un activo importante en los mercados financieros debido a que ha aumentado el interés para realizar inversiones especulativas. Adicionalmente, se están popularizando como medio de pago para compras de bienes y servicios. El precio de las criptomonedas tiene un rango de movimiento más amplio que el precio del oro, índices bursátiles y materias primas. Esto se debe a que tienen independencia porque no tienen una institución que las controle lo que elimina la gestión monetaria de los bancos centrales 3.
Debido a esta independencia, los precios de las criptomonedas son ampliamente volátiles, son inestables y cambian rápidamente con el tiempo, por tanto, la predicción de los precios es una tarea desafiante y crucial para los investigadores 2,4. De esta manera, la alta volatilidad y el comportamiento errático en los precios de las criptomonedas han causado interés en la literatura científica por tratar de predecir los precios con diferentes técnicas. A continuación, se mencionan algunos estudios encontrados en la base de datos de Scopus por medio de la siguiente ecuación de búsqueda: TITLE-ABS (cryptocurrency AND {deep learning} AND price).
Algunos autores 5 predicen los precios los precios de las criptomonedas Bitcoin (BTC), Digital Cash y Ripple con los métodos de Deep Learning LSTM y una Red Neuronal de Regresión Generalizada (GRNN-Generalized regression neural networks), la cual es un sistema paralelo y basado en memoria que estima la superficie de regresión de una variable continua. Esta investigación encuentra que el modelo LSTM es de mayor carga computacional, pero obtiene mejores resultados en el reconocimiento de patrones no lineales, por tanto, es más eficiente para pronosticar la dinámica caótica inherente en los mercados de criptomonedas.
Otros autores 4 proponen un esquema híbrido entre LSTM y GRU con el cual obtuvieron mayor precisión en el pronóstico de los precios de las criptomonedas Litecoin y Monero. Por su parte, 6 aplica tres tipos de enfoques para predecir el precio de Bitcoin: modelo LSTM convencional, modelo LSTM con AR(2) (autorregresivo de segundo orden para eliminar la estacionariedad) y aplicación de un modelo AR(2) (modelo convencional de modelamiento de series de tiempo). Los autores determinaron que el modelo LSTM AR(2) superó al modelo LSTM convencional y al modelo AR(2).
Estos autores 7implementaron modelos híbridos de CNN-LSTM y CNN-BiLSTM (LSTM Bidireccional) en los precios de Bitcoin, Ethereum y XRP. Con estos modelos los autores afirman que se puede obtener beneficios para desarrollar modelos de pronóstico fuertes, estables y confiables. 8 demostraron eficacia para pronósticas el precio del Bitcoin con modelos LSTM y GRU para manejar la volatilidad.
Entre los estudios más recientes se encuentran, 9 estudió la evaluación del rendimiento de un algoritmo genético con técnicas de Deep Learning para predecir el precio de seis criptomonedas: Bitcoin, Ethereum, Binance, Litecoin, Stellar Lumens y Dogecoin. Los modelos de Deep Learning considerados fueron, CNN, redes neuronales directas profundas y GRU. Concluyeron que el mejor modelo es CNN. 10 obtiene que el mejor modeló es el híbrido GRU-BiLSTM para pronosticar el precio de Bitcoin, Ethereum, Ripple y Binance. Por su parte, 1 con un modelo híbrido entre CNN-GRU, consideran que supera a los métodos existentes para pronosticar el precio de Bitcoin, Ethereum y Ripple. No obstante, 3 presenta el modelo LSTM como el de mayor rendimiento y más efectivo para las criptomonedas AMP, Ethereum, m, ElectroOptical System y XRP. Por último, 2 utilizaron LSTM para conocer los patrones dentro del precio de cierre de EOS, Bitcoin, Ethereum y Dogecoin. El rendimiento de este modelo de Deep Learning fue comparado con un modelo ARIMA. Similarmente, 11 comparó el método LSTM con otros modelos por medio de métricas como RMSE, MAE, MAPE y R2.
El presente estudio representa una contribución significativa al campo de la predicción de series de tiempo univariadas de precios de criptomonedas mediante la aplicación de métodos avanzados de Deep Learning. En particular, este trabajo se destaca por su enfoque exhaustivo que abarca cinco métodos diferentes: RNN (Recurrent Neural Networks), LSTM (Long Short-Term Memory), GRU (Gated Recurrent Units), CNN (Convolutional Neural Networks) y un método híbrido que combina CNN y LSTM. Una de las principales contribuciones radica en la rigurosa optimización de hiperparámetros realizada en este estudio. Esta optimización permite una comparación objetiva y fundamentada entre los métodos mencionados, lo que arroja luz sobre cuál de ellos presenta el mejor rendimiento en términos de precisión en la predicción de la serie de tiempo de precios de criptomonedas. Este enfoque metodológico es particularmente valioso, ya que proporciona una base sólida para la elección del modelo más adecuado, a diferencia de otros estudios en la literatura que pueden carecer de este nivel de análisis comparativo. Además, en este artículo se demuestra la mitigación del sobreajuste (overfitting), un problema crítico en la predicción de series de tiempo. Para abordar este desafío, se emplean técnicas de regularización como la detención temprana (early stopping) y el Dropout, que contribuye a mejorar la generalización de los modelos desarrollados. Otra contribución notable es la evaluación de la confiabilidad de los modelos propuestos mediante la aplicación de la prueba de ACF (Autocorrelation Function) a los residuales. Esta evaluación aporta una capa adicional de validación de la calidad de las predicciones, lo que aumenta la confianza en los resultados obtenidos. Por último, este estudio va más allá al comparar de manera sistemática los métodos de mejor desempeño identificados con otros métodos encontrados en la literatura. Esta comparación proporciona una perspectiva valiosa sobre el estado actual de la investigación en el campo y puede ayudar a orientar futuras investigaciones en la dirección más prometedora.
En conjunto, la aplicación y análisis de múltiples métodos de Deep Learning, la optimización de hiperparámetros, la atención al sobreajuste, la evaluación de la confiabilidad y la comparación con la literatura existente hacen de este trabajo una valiosa contribución científica que avanza en la comprensión y el uso efectivo de la predicción de series de tiempo de precios de criptomonedas en un contexto financiero y tecnológico en constante evolución. Por su parte, la predicción precisa de los precios de las criptomonedas es esencial para diferentes agentes; por ejemplo, para los inversionistas que buscan maximizar sus ganancias y minimizar sus pérdidas, para las compañías de inversión en la gestión del riesgo y para las entidades de control para tomar decisiones en el ámbito regulatorio.
El resto de este artículo se estructura de la siguiente manera: en la sección 2 se presenta la metodología implementada en este artículo con la exposición de los datos y los métodos de Deep Learning. Luego, en sección 3 se discuten los resultados. Finalmente, en la sección 4 se presentan las conclusiones.
Metodología
Datos
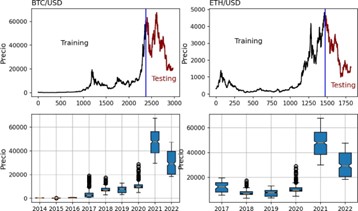
En este documento se evalúa el rendimiento de varios métodos de Deep Learning para el pronóstico de las dos principales criptomonedas: Bitcoin (BTC) y Ethereum (ETH). Del sitio web https://finance.yahoo.com se obtuvieron los precios de cierre diarios de las dos criptomonedas. Para BTC se utilizaron los precios desde el 17 de septiembre de 2014 hasta el primero de noviembre de 2022, obteniendo un total de 2,968 precios. El conjunto de datos de ETH es de 1,819 precios con una ventana de tiempo desde el 9 de noviembre de 2017 hasta el primero de noviembre de 2022.
Los modelos de Deep Learning se entrenaron con el conjunto de entrenamiento (training) y se evaluaron con el conjunto de prueba (testing) de cada criptomoneda. En BTC se evaluaron los modelos con los 600 precios más recientes, desde el 13 de marzo de 2021 hasta la fecha más reciente, primero de noviembre de 2022. Los demás precios se usaron como conjunto de training. En ETH se usaron los 350 precios más recientes como conjunto de testing, desde el 17 de noviembre de 2021 hasta el primero de noviembre de 2022. El conjunto de training de BTC es aproximadamente el 80% del conjunto de datos y el 20% aproximadamente es el conjunto de testing. Lo mismo se aplicó de forma aproximada para los conjuntos de datos de ETH.
La Figura 1 muestra el comportamiento de cada criptomoneda, el conjunto de entrenamiento y de prueba, y la forma de la distribución de los precios por año representada por un boxplot. Las dos criptomonedas tuvieron un comportamiento similar en los últimos dos años: generaron precios máximos en el año 2021, pero disminuyeron en el último período. En los años anteriores al 2021, cada criptomoneda tenía un comportamiento con precios atípicamente altos cada año. De esta manera, se destaca que los conjuntos de training tienen patrones diferentes que los conjuntos de testing. Los modelos de Deep Learning se evaluaron (testing) donde los patrones en el precio mostraron rangos amplios y mayor dispersión.
Métodos de Deep Learning
En esta sección se introducirán los métodos de Deep Learning empleados para el pronóstico de las series de tiempo. En este artículo, evaluamos algunos de los algoritmos de aprendizaje profundo más exitosos y ampliamente utilizados para pronosticar los precios de las criptomonedas.
RNN
Una RNN (Recurrent Neural Network) es un tipo de arquitectura de una red neuronal profunda que tiene una estructura en la dimensión temporal, se parece a la red neuronal Feedforward, excepto que tiene conexiones que apuntan hacia atrás y envía la salida a sí misma. En las redes neuronales tradicionales, los batch o vectores de los datos de entrada son independientes entre sí, como consecuencia, no logran hacer uso de la información secuencial. Por el contrario, el método RNN agrega un estado oculto que almacena la información secuencial y arroja una salida dependiente de este estado oculto 12. Para series temporales, en cada paso de tiempo, RNN recibe el vector de entradas 𝑥𝑡 y su propia salida del paso de tiempo anterior, es decir, la salida 𝑦 que también es una entrada para el siguiente estado de la neurona.
En cada paso de tiempo 𝑡, la neurona RNN recibe el vector de entrada 𝑥𝑡 y la salida del paso de tiempo anterior, 𝑦𝑡-1. El resultado de la neurona, 𝑦𝑡, se calcula en la Ec. (1).
Los pesos de las entradas son el vector 𝑊𝑥, los pesos para las salidas de los pasos anteriores se representan con 𝑊𝑦, b es el bias, y 𝜙 representa la función de activación.
LSTM
LSTM (Long Short-Term Memory) es una de las variaciones de la arquitectura de RNN. LSTM es un método de Deep Learning útil para predicción de datos secuenciales como las series de tiempo. Las redes RNN no tienen la capacidad de reconocer patrones a largo plazo debido al problema del desvanecimiento o explosión del gradiente, esto ocurre en el método de backpropagation cuando aprende los pesos y debe propagar la pendiente calculada con la regla de la cadena. A medida que los valores de la pendiente se propagan hacia atrás en la función de activación, la pendiente se vuelve extremadamente pequeña o extremadamente grande, lo que genera que el gradiente desaparezca o explote. LSTM utiliza celdas de memoria (memory cells) para superar este problema y puede aprender de dependencias a largo plazo. En 1997 se introdujo la primera LSTM que usaban celdas y compuerta de memoria para almacenar información durante largos períodos de tiempo o para olvidar información innecesaria 13.
Los LSTM actuales están compuestos por una celda de memoria (𝑐𝑡) y tres compuertas: una compuerta de entrada (𝑖𝑡), una compuerta de olvido (𝑓𝑡), y una compuerta de salida (𝑜𝑡). Cada compuerta tiene una función única: sigmoide 14. En el tiempo 𝑡, 𝑥𝑡 representa la entrada de los datos secuenciales y ℎ𝑡 el estado oculto 13.
La compuerta de olvido (𝑓𝑡) permite que la red neuronal LSTM ignore la información de la celda de estado del paso de tiempo anterior (𝑐𝑡-1) o la conserve. Esta compuerta de olvido es alimentada por lo valores de entrada 𝑥𝑡 y el estado oculto del paso de tiempo anterior (ℎ𝑡-1), este último a su vez es la salida del paso de tiempo anterior (𝑦𝑡-1). Estas dos entradas se combinan (+) y pasan por una función sigmoide que genera un número entre 0 y 1 que multiplica elemento por elemento. Resultados cercanos a 1 en la compuerta de olvido permite que la información se mantenga, en cambio, la información se olvida con un resultado cercano a 0 15. En la Ec. (2) se muestra la forma de calcular el valor de la compuerta de olvido, donde 𝑤ℎ𝑓 es la matriz de pesos para la celda de estado del paso anterior (𝑐𝑡-1), 𝑤𝑖𝑓 es la matriz de pesos para los valores de entrada 𝑥𝑡 y los bias son 𝑏ℎ𝑓 y 𝑏𝑖𝑓11.
Luego, la celda de memoria (𝑐𝑡) se actualiza mediante la Ec. (3). En esta fase la información anterior se recuerda o se olvida en 𝑐𝑡 para activar la memoria a largo plazo correspondiente 16.
Nuevamente las dos entradas, ℎ𝑡-1 y 𝑥𝑡 pasan a través de una función tangente hiperbólica (tanh) con sus respectivos pesos, 𝑤ℎ𝑔 y 𝑤𝑖𝑔, y sus respectivos bias, 𝑏ℎ𝑔 y 𝑏𝑖𝑔. Este cálculo se muestra en la Ec. (4) y representa el almacenamiento de la información nueva del paso de tiempo actual 11. El objetivo de pasar la información por la función tangente hiperbólica es comprimir los valores entre -1 y 1 15.
La compuerta de entrada (𝑖𝑡) evalúa la información actual contenida en 𝑔𝑡. Esta compuerta funciona de forma similar a la compuerta de olvido, con las mismas entradas (ℎ𝑡-1 y 𝑥𝑡) que pasan a una función sigmoide. El resultado de 𝑖𝑡 reduce el efecto de 𝑔𝑡 al arrojar un valor cercano a 0 o permite pasar la información con un valor cercano a 1. En este último caso, se almacena la información en la memoria de largo plazo (𝑐𝑡). La Ec. (5) muestra cómo se forma la salida de la compuerta de entrada (𝑖𝑡) y la Ec. (6) muestra cómo se actualiza la celda de memoria (𝑐𝑡) 11. Las matrices de pesos son 𝑤ℎ𝑖 y 𝑤𝑖𝑖, y los bias son 𝑏ℎ𝑖 y 𝑏𝑖𝑖
El valor de 𝑐𝑡 actualizado es el estado actual de la celda LSTM y es transferido al siguiente paso de tiempo.
La última compuerta, la compuerta de salida (𝑜𝑡), determina cuánta información de la memoria a largo plazo (𝑐𝑡) debe transferirse a la salida (ℎ𝑡 y 𝑦𝑡). Esta compuerta también tiene una función sigmoide, pero tiene tres entradas: ℎ𝑡-1, 𝑥𝑡 y 𝑡𝑎𝑛ℎ(𝑐𝑡). El valor de 𝑐𝑡 primero pasa por la función tangente hiperbólica antes de multiplicarse por la compuerta de salida para generar la salida ℎ𝑡. Las Ec. (7) y (8) muestran cómo se generan estos resultados 11.
Por lo tanto, las redes neuronales LSTM superan el problema de la memoria de corto plazo con este diseño de tres compuertas y la celda de memoria de largo plazo. Así que la información en los pasos de tiempo anteriores puede reflejarse en el estado actual de la celda 15.
GRU
Los modelos GRU (Gated Recurrent Unit) son otra variación a la red neuronal recurrente. El algoritmo GRU tiene una arquitectura simplificada que LSTM y también permite la memoria de largo plazo. GRU tiene dos compuertas: la compuerta de actualización (update gate) 𝑧𝑡 y la compuerta de reinicio (reset gate) 𝑟𝑡.
En las dos compuertas de la red GRU, las entradas son las mismas: resultado del paso de tiempo anterior (ℎ𝑡-1) y los valores de entrada (𝑥𝑡) 17. La función de activación de las compuertas es la sigmoide y el resultado se genera con las Ec. (9) y (10):
Donde 𝑤𝑖𝑧 y 𝑤𝑖𝑟 son las matrices de pesos para los valores de entrada 𝑥𝑡, 𝑤ℎ𝑧 y 𝑤ℎ𝑡 son las matrices de pesos para la memoria de largo plazo del paso de tiempo anterior ℎ𝑡-1 y 𝑏𝑟 es el bias.
En el resultado de la red GRU, ℎ𝑡, se muestra en la Ec. (11).
Donde 𝑔𝑡 es la función de activación tangente hiperbólica por defecto, pero se podría cambiar por cualquier otra. En la Ec. (12) se muestra cómo se genera 𝑔𝑡.
CNN
La arquitectura de las redes CNN (Convolutional Neural Networks) se componen de tres capas principales: capa de convolución, capa de agrupamiento o pooling y capa totalmente conectada. La capa de convolución extrae características de los datos de entrada. Esta capa se compone de varios kernels de convolución que se utilizan para calcular varios Feature Maps 18. La operación de la capa de convolución se expresa en la Ec. (13).
Donde 𝑥 son los datos de entrada, 𝑊 los pesos, * operación de convolución y el bais es 𝑏. 𝑓(·) es la función de activación de la capa de convolución 19. Por medio de esta operación se crean los Features Maps. Para datos secuenciales, se usa la estructura convolucional unidimensional 14.
La capa de agrupación o pooling reduce la dimensión de los Feature Maps. Esta reducción acelera el cálculo y evita el sobreajuste 14. Las operaciones de agrupamiento de mayor uso son la media y agrupación máxima (max pooling). En este artículo se utiliza el max pooling debido a que reduce efectivamente la dimensionalidad de los datos y mejora la solidez de los resultados 14.
Los kernels de las primeras capas de convolución están diseñados para detectar características de bajo nivel, mientras que los kernels de las capas superiores aprenden a identificar características más abstractas. Al apilar varias capas de convolución y de agrupamiento, se puede detectar características de nivel superior.
Después de apilar varias capas de convolución y de agrupamiento, sigue una o varias capas totalmente conectadas. Estas capas totalmente conectadas son opcionales y pueden reemplazarse por una sola capa de convolución de 1 x 1 para general la salida de la red neuronal 18.
Método híbrido: CNN-LSTM
El método híbrido combina la red neuronal CNN con la arquitectura LSTM para realizar el pronóstico. El conjunto de datos primero pasa por las capas de Convolución para luego pasar por las capas de una red tipo LSTM.
Optimización de hiperparámetros
Los modelos de Deep Learning tienen diferentes hiperparámetros que determinan la estructura de la red neuronal y la manera de entrenamiento. El rendimiento de los modelos varía según el conjunto de hiperparámetros elegidos, por tanto, para lograr un rendimiento óptimo, se debe seleccionar los hiperparámetros que generan mejores resultados 19). En la búsqueda de los hipeparámetros se prueba la red neural con las combinaciones posibles de hiperparámetros.
Los hiperparámetros a optimizar son: capas ocultas, cantidad de neuronas por capa, funciones de activación, tasa de aprendizaje, optimizadores y tamaño del catch. La Tabla 1 muestra los resultados experimentales de las configuraciones óptimas.
Tabla 1 Hiperparámetros óptimos de los modelos para BTC y ETH
| BTC | ETH | |||||
|---|---|---|---|---|---|---|
| Hiperparámetros óptimos | RNN | LSTM | GRU | RNN | LSTM | GRU |
| Capas ocultas | 2 | 2 | 1 | 1 | 1 | 1 |
| Neuronas por cada | 50 | 50 | 50 | 20 | 50 | 20 |
| Funciones de activación | ELU | selu | selu | selu | ReLU | ReLU |
| Tasa de aprendizaje | 0.001 | 0.001 | 0.1 | 0.01 | 0.001 | 0.1 |
| Optimizadores | Adam | RMSProp | Adam | Adam | RMSProp | Adam |
| Tamaño del Batch | 128 | 32 | 64 | 32 | 128 | 128 |
Resultados y discusión
Comparación modelos optimizados
En esta sección, se evalúa el desempeño de cada modelo de Deep Learning optimizado y se hacen comparaciones con los modelos de predicción encontrados en la literatura. Cada modelo fue entrenado de nuevo, pero a escala completa con cada uno de los hiperparámetros optimizados.
La Tabla 2 presenta la comparación de las métricas de desempeño de los métodos de Deep Learning para el Bitcoin y Ethereum. Cada método optimizado se entrenó con el conjunto de train correspondiente y se calcularon las métricas de desempeño sobre el conjunto de test de cada activo.
Tabla 2 Métricas de desempeño de los métodos para BTC y ETH.
| MAE | MSE | RMSE | MAPE | R2 | |
|---|---|---|---|---|---|
| BTC | |||||
| RNN | 1,048 | 2,273,495 | 1,508 | 2.64% | 0.9873 |
| LSTM | 1,066 | 2,355,762 | 1,535 | 2.71% | 0.9868 |
| GRU | 1,205 | 2,777,147 | 1,666 | 3.06% | 0.9844 |
| CNN-LSTM | 1,226 | 2,776,962 | 1,666 | 3.08% | 0.9844 |
| ETH | |||||
| RNN | 95 | 15,334 | 124 | 4.13% | 0.9830 |
| LSTM | 77 | 10,975 | 105 | 3.31% | 0.9885 |
| GRU | 93 | 15,351 | 124 | 4.13% | 0.9835 |
| CNN-LSTM | 122 | 23,214 | 152 | 5.29% | 0.9751 |
Conforme a los resultados presentados en la Tabla 2, se observa un rendimiento destacado en los cuatro métodos DL en lo que respecta a la predicción de los precios de las criptomonedas BTC y ETH, evidenciado por la obtención de coeficientes de determinación (R2) superiores a 0.97. Específicamente, en el caso de BTC, se destaca el rendimiento sobresaliente del método RNN. Este método exhibe los valores más bajos en métricas tales como el MAE, MSE, RMSE y MAPE, y además, obtiene el R2 más elevado. La magnitud del MAE, que se sitúa en 1,048 USD, denota que, en el proceso de pronóstico de los precios de BTC, el modelo presenta una desviación promedio de 1,048 USD por día. En consonancia, se constata que el método RNN exhibe los valores más favorables en las métricas MSE y RMSE, lo cual indica una mayor calidad en las proyecciones. Conviene señalar que el MSE, al calcular el promedio de los cuadrados de los errores, manifiesta una mayor sensibilidad a valores atípicos en comparación con el MAE. Por último, el MAPE correspondiente al modelo, se cifra en 2.64%, reflejando el porcentaje de error en las predicciones con respecto a los valores reales.
En el marco de los resultados para el precio de la criptomoneda ETH, se determinó que el mejor método para el pronóstico es el de LSTM. En primer lugar, el MAE de 77 indica que, en promedio, las predicciones generadas por el modelo LSTM se desvían aproximadamente en 77 unidades de la moneda con respecto a los valores reales de ETH. Este bajo nivel de error absoluto es un indicativo de la capacidad del modelo para predecir los precios con precisión. El MSE de 10,975, aunque es un valor más elevado que el MAE, es de suma relevancia. El MSE promedia los cuadrados de las diferencias entre las predicciones y los valores reales, lo que lo hace más sensible a las desviaciones significativas. A pesar de este aspecto, el MSE es considerablemente bajo, lo que subraya la capacidad del modelo LSTM para minimizar errores sustanciales en la predicción. El RMSE de 105, que se obtiene al calcular la raíz cuadrada del MSE, ofrece una métrica más intuitiva, ya que se expresa en la misma unidad que los valores originales de la serie de tiempo. En este contexto, el RMSE refleja que las predicciones del modelo tienen una desviación promedio de aproximadamente 105 unidades de la moneda ETH con respecto a los valores reales. El MAPE del 3.31% es un indicador particularmente destacado. Este valor representa el porcentaje de error promedio en las predicciones en comparación con los valores reales. Un MAPE bajo demuestra que el modelo LSTM es capaz de realizar pronósticos altamente precisos y que las desviaciones porcentuales de las predicciones con respecto a los valores reales son mínimas. Por último, el coeficiente de determinación (R2) de 0.9885 es una métrica que evalúa cuánta varianza en los datos es explicada por el modelo. En este caso, un R2 tan cercano a 1 indica que el modelo LSTM es altamente efectivo en capturar y explicar la variabilidad presente en la serie de tiempo de ETH, lo que sugiere un ajuste excepcional del modelo a los datos observados. En resumen, el método LSTM demuestra ser altamente competente en la predicción de la serie de tiempo de ETH, respaldado por sus bajos valores de MAE, MSE, RMSE, MAPE y un elevado coeficiente R2. Estos resultados respaldan su elección como el método más efectivo en este contexto de pronóstico.
En el código en Python se usó un Callbacks con patience igual a 5 con el fin de optimizar el tiempo de ejecución. De esta manera, el entrenamiento de capa modelo se detenía si después de cinco epochs no se obtenía una mejora en la función de pérdida (Loss). La Figura 2 muestra la evolución del entrenamiento a medida que aumenta la cantidad de epochs por cada modelo de Deep Laerning para BTC, en esta figura se transformó cada función de pérdida aplicando logaritmo con el fin de visualizarlo mejor. El modelo que más epochs necesitó fue LSTM con 14 epochs, por el contrario, el modelo CNN-LSTM necesitó ocho epochs. Se observa que las funciones de pérdida de los cuatro modelos en el conjunto de test convergen rápidamente a la función de pérdida del conjunto de train, entre tres y cuatro epochs los modelo convergen. Adicionalmente, no se evidenció sobre ajuste (overfitting) debido al uso del Callbacks y al Dropout de 0.20 aplicado en las capas ocultas de cada una de las arquitecturas.
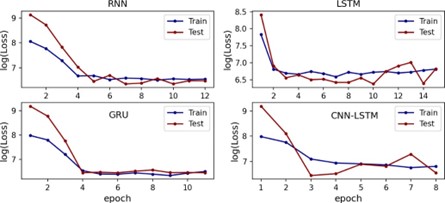
Figura 2 Logaritmo de las funciones de pérdida con respecto a la cantidad de epoch de los modelos optimizados para BTC.
La Figura 3 muestra el comportamiento de la función de pérdida por cada epoch para los modelos aplicados en ETH. Se aplicó el logaritmo al eje y para visualizar mejor el cambio por epoch. Se destaca que la función de pérdida sobre el conjunto de prueba es menor que el conjunto de entrenamiento en los cuatro métodos. Lo anterior es una muestra de que no se tienen modelos sobre entrenados (con overfitting), esto se evitó con una tasa de Dropout de 0.20 en cada capa oculta.
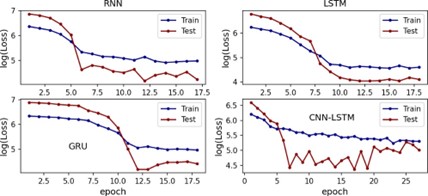
Figura 3 Logaritmo de las funciones de pérdida con respecto a la cantidad de epoch de los modelos optimizados para ETH.
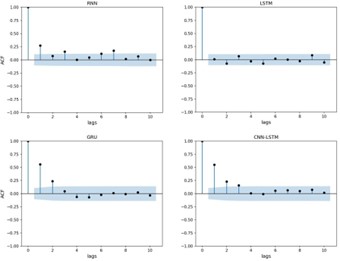
Para evaluar la confiabilidad del pronóstico, se calculó la Función de Autocorrelación (ACF-Autocorrelation Function) para cada uno de los modelos optimizados. El objetivo del ACF es probar la existencia de autocorrelación entre los residuos. La ACF se obtiene a partir de la correlación lineal de cada residuo con los demás en diferentes rezagos (lags) para examinar si el modelo se ha ajustado correctamente a la serie de tiempo y si los residuos están idénticamente distribuidos y asintóticamente independientes 20. La Figura 4 presenta la función ACF para los cuatro modelos optimizados para BTC, los puntos por fuera de las bandas muestran la intensidad de la autocorrelación temporal. Las bandas se construyen suponiendo que los residuos siguen una distribución de probabilidad gaussiana. De esta forma, en la Figura 4 se observa que existe autocorrelación con el noveno rezago en los modelos RNN y LSTM; sin embargo, esta autocorrelación es de baja intensidad. Lo anterior se contrasta con lo hallado en las métricas de desempeño en que son los dos modelos de mejor rendimiento para BTC. En contraste, los modelo GRU y CNN-LSTM mostraron autocorrelación alta con el primer rezago, esto indica ineficiencias para la predicción y es evidencia de que no capturan toda la estructura determinística de la serie de tiempo

Figura 4 Función ACF de los residuos sobre el conjunto de test de Bitcoin de los modelos optimizados.
La ACF de los residuales de los modelos aplicados en ETH se muestran en la Figura 5. Se observa que los modelos RNN, GRU y CNN-LSTM tienen presencia de rezagos en los residuales. Existe correlación alta entre el primer rezago en RNN y en los dos primeros rezagos en GRU y CNN-LSTM; sin embargo, el modelo optimizado LSTM no presenta autocorrelación entre los rezagos de los residuos, en consecuencia, este modelo es confiable para pronosticar el precio de Ethereum y tiene la capacidad de capturar la estructura determinística de la serie de tiempo.
Comparación modelos de la literatura
En esta sección, se compara el método de Deep Learning optimizado de mejor desempeño hallado por cada criptomoneda con los métodos encontrados en la literatura en el último año y que realizaban pronóstico sobre el precio del Bitcoin y Ethereum. Todos los modelos fueron entrenados con el mismo conjunto de datos.
El modelo de 2) contiene una arquitectura LSTM con una capa oculta con 250 neuronas, seguido de una capa de Dropout con una tasa de 0.20, la ventana de tiempo para pronosticar es de 10 días para predecir el siguiente día, las neuronas tienen la función de activación ReLU, el optimizador es Adam, tasa de aprendizaje de 0.001 y tamaño del Batch de 64. Este modelo se entrenó con 100 epochs.
El modelo de 1 es un híbrido entre CNN y GRU. Tiene una sola capa de Convolución con 256 filtros, tamaño del Kernel de 1. En GRU tiene dos capas ocultas, cada una con 256 neuronas, función de activación ReLU. Usa el optimizador Adam, ventana de tiempo de un día, Batch de 64 y el modelo se entrenó con 100 epochs.
La Tabla 3 presenta la comparación entre los dos modelos anteriores 2 y 1) y los dos modelos optimizados que se proponen en este artículo: RNN para BTC y LSTM para ETH. El modelo RNN optimizado presenta mejor desempeño en el pronóstico en el precio del Bitcoin que los dos modelos de la literatura que se componen de una estructura LSTM 2 y una estructura híbrida CNN-GRU 1. Incluso, los demás modelos optimizados, LSTM, GRU y CNN-LSTM son más precisos para modelar el precio de BTC. Por su parte, el modelo LSTM optimizado propuesto en este artículo tiene mejores resultados en las métricas de desempeño, pero con resultados aproximados que el método 1 CNN-GRU de la literatura. Estos dos métodos tienen mejor desempeño que el modelo de la literatura LSTM 2 el cual tiene un RMSE de 144, valor más alto que los modelo RNN y GRU optimizado, pero un mejor valor que el híbrido CNN-LSTM optimizado.
El análisis de los residuales de los dos modelos de la literatura se muestra en la Figura 6 con el AFC de los residuales de BTC. El modelo CNN-GRU 1 presenta baja autocorrelación con el noveno rezago, por lo que se determina que el modelo es confiable para predecir el precio del Bitcoin. Por el contrario, el modelo de la literatura LSTM 2 no tiene la capacidad de predecir de forma confiable el precio de BTC debido a que se encontró alta autocorrelación entre los primeros cinco rezagos. Esto último es evidencia de que este modelo no es confiable en la predicción del Bitcoin.
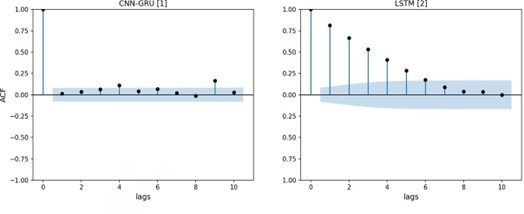
Figura 6 Función ACF de los residuos sobre el conjunto de test de BTC de los modelos de la literatura.
Finalmente, en la Figura 7 el modelo CNN-GRU 1 no tiene rezago con autocorrelación, pero el modelo LSTM 2 tiene los residuos de los dos primeros rezagos con alta autocorrelación. Esta evidencia es similar a la encontrada con estos dos modelos aplicados sobre el precio de BTC.
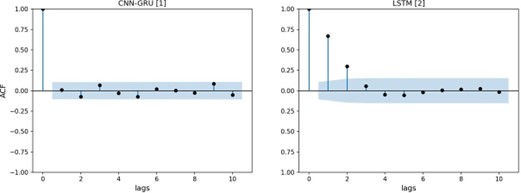
Conclusiones
Pronosticar el mercado de criptomonedas es una tarea desafiante y una preocupación para los inversionistas debido a su comportamiento altamente volátil. De esta manera, en los últimos años ha aumentado el interés de los investigadores por tratar de predecir el precio de las criptomonedas con técnicas de Deep Learning, la cuales tienen la capacidad de capturar patrones no lineales y con dependencias de largo plazo.
En este artículo se utilizó una metodología innovadora de inteligencia artificial en lugar de los modelos tradicionales de series de tiempo para estimar el precio de las dos criptomonedas de mayor transacción: Bitcoin y Ethereum. Se realizó un análisis experimental extenso y detallado teniendo en cuenta la evaluación del desempeño de los siguientes modelos de Deep Learning: RNN, LSTM, GRU y CNN-LSTM. Además, se estudió la fiabilidad y eficiencia de las predicciones de cada modelo examinando la autocorrelación de los residuos.
Este estudio ha arrojado luz sobre las notables implicaciones prácticas de la aplicación de métodos DL en el pronóstico de series de tiempo univariadas. Nuestra investigación ha revelado que estos enfoques representan una herramienta poderosa y efectiva para modelar y predecir con precisión las dinámicas de datos temporales. Específicamente, los modelos RNN y LSTM demostraron un rendimiento sobresaliente en términos de precisión de pronóstico, minimizando el MAE, el MSE, el RMSE y el MAPE. También, el estudio ofrece perspectivas valiosas sobre las implicaciones prácticas que los métodos de DL tienen para los tomadores de decisiones e inversionistas en el contexto del pronóstico de series de tiempo univariadas. Nuestros hallazgos resaltan que la aplicación de estas técnicas avanzadas puede revolucionar la toma de decisiones en una variedad de industrias y sectores financieros. Para los tomadores de decisiones, los modelos de DL proporcionan la capacidad de obtener predicciones más precisas y detalladas sobre las tendencias futuras. n el ámbito de la inversión, los métodos de DL ofrecen una herramienta poderosa para analizar y pronosticar los movimientos de los activos financieros. La precisión mejorada de las predicciones puede llevar a estrategias de inversión más informadas y rentables. Sin embargo, es importante destacar que la adopción de estos enfoques requiere un enfoque prudente y una comprensión sólida de su funcionamiento, ya que los modelos de DL son inherentemente complejos.
Los resultados experimentales mostraron que, para el precio diario del Bitcoin, el modelo RNN tiene mayor rendimiento que los otros métodos, incluyendo los dos métodos de la literatura debido a que generó menos errores predictivos (MAE, RMSE, MSE y MAPE) y una evaluación más precisa (R2). El modelo RNN presentó el RMSE más bajo de 1,508 para el conjunto de datos de Bitcoin. No obstante, los cuatro métodos evaluados presentaron R2 mayores a 0.98, demostrando alta precisión de pronóstico, pero los modelos GRU y CNN-LSTM no capturan adecuadamente la estructura determinística del precio de la criptomoneda porque presentaron alta autocorrelación en el primer rezago de los errores. Posteriormente, los dos modelos de la literatura evaluados fueron el de CNN-GRU 1 y LSTM 2, los cuales lograron buen ajuste, pero en menor medida que los modelos optimizados y además, el modelo LSTM 2 presentó alta autocorrelación en los primeros cinco rezados de los errores.
Por su parte, para el precio de cierre de ETH, los cuatro modelos optimizados tienen R2 alto, siendo CNN-LSTM el de más bajo rendimiento con un R2 de 0.97. En este caso, el modelo LSTM es de mejores resultados en las cinco métricas de desempeño y presentó un RMSE de 105. Comparando estos métodos con los de la literatura, se encontró que CNN-GRU 1 tiene un desempeño similar, pero LSTM 2 tiene rendimiento contrario siendo similar al modelo CNN-LSTM. Ambos métodos presentaron problemas en el pronóstico por la presencia de autocorrelación en los residuos.
Como trabajo futuro se podría evaluar y optimizar el modelo híbrido CNN-GRU e implementar la variación Bidireccional para GRU y LSTM y que incluya un modelo híbrido con CNN. En los datos de entrada se podría analizar primero la serie de tiempo si presenta autocorrelación para aplicar diferenciación antes de entrar a las redes neuronales y así ayudar a los modelos para no capturar más patrones. Por último, se podría combinar técnicas de pronóstico de series de tiempo tradicionales con los modelos de Deep Learning con el fin de aumentar la capacidad de pronóstico.

