Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
PermalinkIntroducción
El fenómeno de transferencia lingüística se empezó a documentar con consistencia en la literatura sobre adquisición de segundas lenguas (ASL) durante el siglo xx, mediante los trabajos de Fries (1945), Weinreich (1953) y Lado (1957), hecho que va acompañado al desarrollo de la hipótesis del análisis contrastivo (HAC) (Hansen y Zampini, 2008). Sin embargo, registros de este fenómeno han estado presentes desde mucho antes de esto en trabajos como los de Müller (1861/1965 ) sobre pidgins y criollos, y Trubetzkoy (1987 [1939]), quien mencionaba cómo la lengua materna (L1) filtraba elementos de una segunda lengua (L2)2 al momento de comunicarse. Aunque a través de los años no se ha logrado llegar a un consenso respecto a la naturaleza, rol e incluso un único nombre para el fenómeno de la transferencia (Alonso Rey, 2011), es posible afirmar que existen errores de producción a lo largo del proceso de ASL, los cuales parecieran tener una influencia de los elementos de la L1 de los hablantes.
Desde mediados del siglo xx, la transferencia cumplió un rol fundamental en explicar fenómenos de errores de producción en ASL; sin embargo, con el surgimiento del generativismo y de conceptos como interlengua, universales y marcado, el rol de la transferencia como causante de errores de producción en ASL perdió el protagonismo que tenía en la HAC. No obstante, la transferencia sigue siendo un factor importante en el análisis de fenómenos de error en cualquiera de los cuatro niveles lingüísticos: morfología, sintaxis, pragmática y, sobre todo, fonología, y ha sido tema de estudio en las teorías de distintos autores contemporáneos como Flege (1995) y Best (1995) (Hansen y Zampini, 2008).
El presente estudio está enmarcado en un contexto de enseñanza de inglés como L2 en un colegio de la ciudad de Concepción, Chile, en el cual los alumnos están inmersos en un ambiente de aprendizaje bilingüe desde Infant School (3 a 4 años de edad) hasta Junior School (11 a 12 años), tiempo en el que ellos tienen la oportunidad de recibir el 80% de sus lecciones en inglés con profesores en su mayoría no nativos. En el contexto de aprendizaje de este colegio en particular es posible apreciar que los alumnos de quinto año básico presentan problemas en su producción escrita en diferentes tipos de texto en inglés, a nivel de ortografía, especialmente en las grafías asociadas a los fonemas vocálicos /iː/, /ɪ/, /ʌ/ y /æ/.
El objetivo principal de este trabajo es investigar si los errores ortográficos en textos en inglés de los alumnos de quinto básico de este colegio son causados por un fenómeno de transferencia lingüística negativa, originada por la percepción auditiva respecto al sistema fonético-fonológico del español. Esta investigación permite indagar en el fenómeno de transferencia lingüística negativa del español en el inglés, específicamente la manera en que la percepción auditiva de los fonos del castellano afecta la producción escrita en inglés de alumnos pertenecientes a un colegio bilingüe español-inglés con inmersión parcial. Se espera, además, que este trabajo refuerce o refute las teorías ya existentes respecto a esta materia en el contexto educativo ya señalado.
Marco teórico
Transferencia
La transferencia lingüística puede ser entendida como la influencia resultante entre las similitudes y diferencias de la lengua meta y cualquier otra lengua que haya sido adquirida con anterioridad por un hablante (Odlin, 1989). También se reconoce como el uso del conocimiento o información de L1 u otra lengua en la adquisición de una L2 (Gass y Selinker, 1992). Similar definición es compartida por otros autores, quienes se refieren a este fenómeno como aquel en el cual los aprendientes transportan o generalizan aspectos de su L1 a L2 para ayudarse cuando se desenvuelven en ella (Shaozhong, 2001; Gil Valdés, 2010). El sistema lingüístico de L1 se apropia de los hablantes,3 y cuando estos oyen hablar otro idioma emplean involuntariamente, para el análisis de lo que perciben, el inventario que les es inconscientemente habitual, es decir, el de su L1. La transferencia lingüística -en cualquiera de sus niveles- es un fenómeno que puede ser asumido tanto beneficioso como negativo para un aprendiente, tomando en consideración si esta se manifiesta como transferencia positiva o negativa (generando "aciertos" o "errores"), en cualquiera de sus niveles lingüísticos (Juhasz, 1970; Odlin, 1989).
Dentro de las hipótesis en el campo de la ASL, la HAC suponía que los aspectos, los elementos o las estructuras (en cualquiera de los niveles lingüísticos) que eran diferentes entre dos lenguas serían difíciles de adquirir por un aprendiz de L2, mientras que los que eran similares serían más fáciles; por ende, los errores de producción en L2 tendrían su origen en la influencia negativa de la L1 de los aprendientes (Hansen y Zampini, 2008, pp. 64-65). Aquellas estructuras diferentes que hubieran sido trasladadas de L1 a L2 serían posibles errores en la producción y, por consiguiente, todos los errores en L2 podrían ser predichos. Esto fue perdiendo terreno con el desarrollo de nuevas corrientes y teorías sobre la lengua y la ASL durante la segunda mitad del siglo xx, como el generativismo y los principios universales, el trabajo de autores como Selinker (1972) sobre fosilización e interlengua, y Eckman (1977) y su hipótesis del marcado diferencial (HMD), entre otros, quienes si bien aceptan la existencia de la transferencia como causante de errores, no la consideran la única causa. Una descripción detallada de las características de los sistemas de L1 como L2 de los hablantes (acento o dialecto de L1 y variedad de L2 que se está aprendiendo), el rol de la edad en el proceso de ASL y otros factores individuales del aprendiente son necesarios para comprender el rol que tiene la transferencia en el proceso de la ASL y el desarrollo de la interlengua (Ioup, 2008).
Transferencia fonético-fonológica: percepción
Al nacer, se está provisto con la capacidad de adquirir cualquier lengua, ya que el ser humano posee la habilidad de detectar diferencias entre una gran variedad de contrastes fonéticos de cualquier idioma en el mundo (Liberman, Harris, Hoffman, y Griffith, 1957; Strange y Shafer, 2008). Alrededor del año de vida, la capacidad de los niños para discernir entre unidades fonéticas de la lengua nativa se incrementa, mientras que la habilidad para diferenciar unidades fonéticas en lenguas extranjeras se pierde, y no es hasta aproximadamente los ocho años de edad que los niños son capaces de producir los sonidos que caracterizan su L1 de manera correcta (Kuhl, 2010a, 2010b; Kuhl y Rivera-Gaxiola, 2008). Ya como adultos, las representaciones fonéticas de L1 están tan integradas a la percepción de los individuos, que la percepción de los sonidos de L1 tiende a ser robusta y automática, requiriendo un bajo esfuerzo cognitivo para tal tarea (Strange y Shafer, 2008).
Durante la primera mitad del siglo xx, Polivanov (1931) estableció que aun cuando los hablantes escuchan fonos de otras lenguas, ellos tienden a adaptarlas a su propio sistema fonológico de L1. De acuerdo con la teoría de la criba fonológica (Trubetzkoy, 1987 [1939]), los sonidos pertenecientes a lenguas distintas a L1 pasan por un filtro perceptivo, donde son ordenadas en categorías preestablecidas en el cerebro por la propia lengua materna de los hablantes: cada vez que un aprendiente de L2 escucha sonidos distintos a los existentes en su L1, hace una recategorización de los fonos de la lengua extranjera de acuerdo con la estructuración dada por su lengua materna, utilizando parámetros de similitud entre estos fonos. La teoría de la sordera fonológica (Polivanov, 1931) explica por qué un aprendiente nativo de español no podría pronunciar la palabra inglesa man como /mæn/, sino que con una forma castellanizada en la forma de /man/ o /men/: para este aprendiente de inglés como L2, la vocal /æ/ no constituye un fonema en español propiamente tal, ya que, en castellano, este sonido no es contrastado con ningún otro fono de manera natural y espontánea en el habla; por lo tanto, él o ella no "oiría" la vocal inglesa, sino un fonema del castellano en su lugar. El modelo de asimilación perceptual (Best, 1995) explica el modo en que hablantes que no están necesariamente aprendiendo una segunda lengua perciben los fonemas de otros idiomas. En este modelo se determinan tres categorías en los que estos sonidos pueden ser percibidos: 1) sonido de L2 asimilado a una categoría existente en L1; 2) sonido de L2 asimilado, pero sin poder clasificarlo en una categoría de L1, y 3) sonido de L2 percibido como un sonido que no corresponde al habla (como un chasquido, atoramiento, respiración, etc.). El modelo magneto de lengua materna (Kuhl e Iverson, 1995) también hace referencia al fenómeno de transferencia negativa fonético-fonológica, explicando la manera en que los fonos ya adquiridos de la L1 funcionarían como un magneto que atrae a los fonos de L2 en categorías ya establecidas en el inventario del hablante: los fonos de la L2 serían atraídos hasta los espacios ocupados por los fonos bien definidos de L1, dependiendo de rasgos de similitud entre ellos. Esto sería causado por la temprana exposición de los hablantes a su lengua materna, lo que produce un cambio en los límites entre los espacios de percepción fonética en la mente de los hablantes, alterando tanto la percepción como posterior producción de los fonos de una L2.
De acuerdo con el modelo de aprendizaje del habla (Flege, 1995), mientras más diferente sea un sonido en L2, mayor será la probabilidad de que se cree una categoría diferente a las ya establecidas por la lengua materna del hablante, y, por ende, este sonido será adquirido más fácilmente en una nueva categoría de las del sistema de L1 (Flege, 1995). Por lo tanto, no todos los sonidos de una L2 son asimilados en categorías preestablecidas por la L1 de un hablante.
Algunas investigaciones sugieren que los contrastes entre los puntos de articulación de las consonantes son menos prominentes que los contrastes de sonoridad al momento de ser percibidos, mientras que, en las vocales, los contrastes de altura y posición son más prominentes en comparación a los contrastes en la duración (Strange y Shafer, 2008). Para hablantes de español como L1 cuya L2 es el inglés, los fonemas vocálicos en general constituirían la mayor dificultad para ser percibidos, debido a que muchos de ellos comparten el espacio fonémico destinado a solo una vocal en el español (Swan y Smith, 2001). La figura 1 ilustra los formantes tanto del español como del inglés Received Pronunciation (RP) para los fonemas vocoides (Bradlow, 1995).

En la figura 1 se puede observar que para la vocal del español /ä/ hay una vocal del inglés que comparte rasgos de centralidad y altura con ella: /ʌ/. A su vez, existen otras vocales que comparten el espacio fonético o entorno cercano, a las que se le asignaría un solo sonido en español dependiendo de factores como la variante o el acento de inglés que se hable (por ejemplo, /æ/ norteamericana y /e/ española, /a:/ americana y /a/ española, o /æ/ británica y /a/ española). Flege (1995) expuso que hablantes de inglés como L2 avanzados tenían problemas para distinguir contrastes entre /e/ y / æ/ o / ʌ/ y /ɑː /, mas no ocurría lo mismo con otros contrastes, como /ʌ/ y / ʊ/, o con el caso de /ɪ/ e /i:/.
Transferencia fonético-fonológica: producción
Los errores ortográficos son evidencia indirecta de transferencia negativa tras una percepción parcial de los fonemas del inglés, una posterior recategorización de estos y, finalmente, una incorrecta proyección por medio de grafemas asociados a los sonidos del castellano (Alonso Rey, 2011). La evidencia sobre este proceso se puede encontrar como fundamento de la hipótesis de transferencia cros-lingüística (Hornberger, 1994; Koda, 1997; Odlin, 1989; Bialystok, 2001), la cual sugiere que el conocimiento lingüístico de L1 es transferido a la ejecución de tareas cognitivas y lingüísticas de L2, como, por ejemplo, decodificar una palabra escrita en inglés utilizando la relación grafema-fonema del español. En particular, la grafía del inglés podría ser causante de errores en la pronunciación, ya que la relación grafema-fonema es más opaca que en español: en castellano existen 27 grafemas que representan 24 fonemas, mientras que en inglés existen 26 grafemas que representan 44 fonemas (en su variante RP). Existen muchos ejemplos de fonemas e inglés que pueden ser representados por más de un grafema o combinación de grafemas (/u:/ blue, through) y viceversa (<u> cute /ju/, sun /ʌ/). Mientras que en español estos casos son más reducidos (ejemplo: <g> "gallo" /g/, "gitana" /x/), existe menor opacidad.
Considerando la variedad de fonemas vocálicos y posibles representaciones gráficas para estos en inglés, los hablantes nativos también se ven enfrentados a vicisitudes a la hora de desarrollar la habilidad de lectura y primordialmente la de escritura en su lengua. Sin embargo, estos errores radican en un problema diferente al de la transferencia, como la característica de opacidad del inglés o el mayor requerimiento de habilidades de procesamiento fonológico para un hablante, en el caso de palabras menos frecuentes (Sun-Alperin, 2007).
Ciertos estudios han demostrado que existe tanto una relación de causalidad como de correlación entre el desarrollo de habilidades de procesamiento fonológico durante la etapa preescolar de un niño y el desarrollo de la lectura y la habilidad para representar palabras de manera escrita en etapas posteriores de la vida escolar (Bradley y Bryant, 1983; Denton, Hasbrouk, Weaver, y Riccio, 2000; Defior, Martos, y Cary, 2002; Sun-Alperin, 2007). Los patrones de ortografía en inglés siguen alguna regla, aunque posiblemente complejas para los aprendientes de este como L1, las cuales se van desarrollando en etapas durante la infancia (Venezky, 1967; Bryant, 2002). Además, a medida que los errores básicos de ortografía se van superando, otros obstáculos ortográficos surgen, debido a la dificultad de los ítems que se van incluyendo en el repertorio del niño que adquiere inglés como L1 (Schlagal, 1992). Los errores ortográficos para representar fonemas vocálicos son los más comunes en los aprendientes de inglés como L1, esto debido a razones como la substitución de vocales que son fonéticamente similares por los niños (como ocurriría en el caso de los hablantes de español como L1 y que están aprendiendo inglés como L2) y la inconsistencia en la relación fonema-grafema propia del inglés (Treiman, 1993; Kessler y Treiman, 2001).
Método
Esta investigación busca corroborar si los errores ortográficos en textos en inglés de los alumnos de quinto básico de un colegio bilingüe en Concepción son causados por un fenómeno de transferencia lingüística negativa, originada por la percepción auditiva respecto al sistema del español, en palabras que contienen los fonemas /ʌ/ y /æ/.
Para la recolección de datos se seleccionaron dos grupos independientes de sujetos, quienes se sometieron a dos pruebas diferentes de audición y completación. Para la realización de la primera prueba se consideró un grupo de 56 alumnos de quinto básico de un colegio bilingüe de inmersión parcial (27 varones y 29 damas), y para la segunda prueba se trabajó con un grupo de 29 alumnos (14 varones y 15 damas), también de quinto básico del mismo colegio. Las edades de ambos grupos varían entre los 10 y 12 años, todos provenientes del mismo estrato sociocultural y con la misma cantidad de tiempo de exposición a la lengua inglesa, tanto en horas a la semana en el colegio (80% del currículo) como en años de enseñanza en el sistema de inmersión parcial.
Selección del material
Para esta investigación se llevaron a cabo dos pruebas de percepción y posterior escritura de seudopalabras que incluían los fonemas vocálicos del inglés /æ/ y /ʌ/. Esta decisión se originó a partir de la observación y la experiencia del autor al trabajar redacción y ortografía con alumnos de estas características. Para este estudio se propusieron los siguientes casos de grafía, como ideales o predictivas, y como indicadores de transferencia:4
1. Para el fonema /ʌ/ se estableció, como grafía ideal, el grafema <u>, y como indicador de transferencia, el grafema <a>.
2. Para el fonema /æ/ se estableció, como grafía ideal, el grafema <a>, y como indicador de transferencia, el grafema <e>.
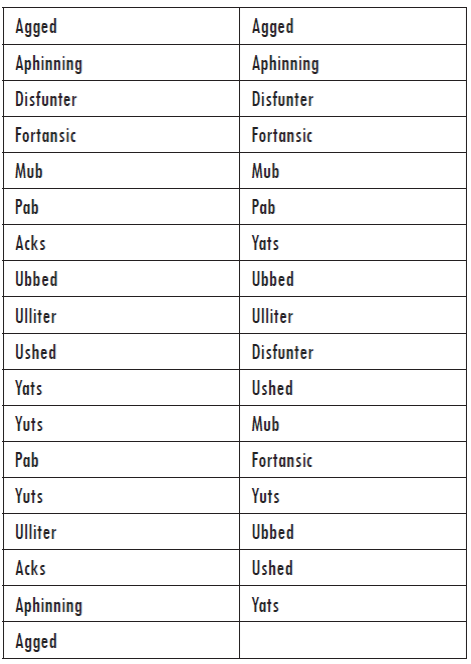
Tanto /ʌ/ como /æ/ fueron incluidas en seudopalabras pertenecientes a un corpus de 12 ítems, inventados especialmente para esta investigación, los cuales jamás habían sido escuchados por los alumnos hasta el momento de realizar la prueba de percepción auditiva. A continuación se presenta el listado con las seudopalabras creadas, en la forma de transcripción fonética que se les asignó, junto con una posible ortografía predictiva5 en inglés con base en la pronunciación.6
1. /mʌb/ "Mub"
2. /pæb/ "Pab"
3. /jʌts/ "Yuts"
4. /jæt/ "Yat"
5. /ʌbd/ "Ubbed"
6. /ægd/ "Agged"
7. /ʌʃt/ "Ushed"
8. /æk/ "Ack"
9. /'ʌlɪtə/ "Ulliter"
10. /'æfɪnɪŋ / "Aphinning"
11. / dɪs'fʌntə / "Disfunter"
12. / fə'tænsɪk / "Fortansic".
Estas seudopalabras fueron creadas con el fin de asegurarse de que los estudiantes escucharan elementos que no pudiesen ser escritos con base en conocimiento previo, sino solo utilizando el conocimiento adquirido tanto del sistema fonológico como de las reglas de escritura en inglés. Se optó por crear tanto palabras monosílabas como polisílabas, únicamente con el fin de generar mayor variedad de estímulos al momento de realizar la prueba. En ningún caso se buscó que las seudopalabras cumplieran con la condición de formar pares mínimos entre ellas.
Procedimiento e instrumentos
Para esta investigación se diseñaron dos instrumentos. El primero consistió en una prueba de completación, con base en un poema en inglés creado específicamente para esta investigación, el cual los 56 sujetos del primer grupo tuvieron que escuchar.7 La extensión de este poema fue de 160 palabras y su duración de 1´ 52´´. Los alumnos recibieron una copia escrita del poema, con dieciocho espacios en blanco, los cuales tuvieron que completar con la palabra que ellos oían a medida que se reproducía el poema. Doce de los espacios a completar correspondían a las seudopalabras del corpus inventado que contenían los fonemas /ʌ/ o /æ/ en diferentes contextos segmentales, mientras que los seis espacios restantes correspondían a palabras reales del inglés, conocidas por todos los alumnos, y borradas al azar en el texto escrito.
Previo a la audición del poema, los alumnos tuvieron unos minutos para ver el instrumento y conocer con anterioridad el espacio en blanco donde se encontraban las palabras faltantes. Después de esto, el poema fue reproducido cinco veces, tras las cuales los alumnos pudieron completar cada uno de los dieciocho espacios en blanco. La primera prueba se realizó de esta manera (con seudopalabras inmersas en un contexto semántico), con el fin de enmascarar la recolección de datos y, además, hacer la prueba atingente al trabajo que los alumnos estaban desarrollando en la asignatura de inglés en ese momento.
Para asegurarse de que las grafías de las respuestas de los alumnos dependían solo de percepción auditiva y conocimiento fonológico y no del contexto (adivinar qué palabra calzaba en el espacio), se diseñó y aplicó el segundo instrumento a un grupo nuevo de estudiantes. Este segundo instrumento consistió en una segunda prueba de percepción y escritura de las mismas doce seudopalabras del corpus inventado, pero esta vez reproducidas tres veces de manera aleatoria a lo largo de la grabación, conformando un audio de 36 palabras, con una duración de 3´ 30´´. La grabación fue reproducida en dos oportunidades: la primera vez para que los estudiantes escribieran las palabras de manera enumerada en una hoja de respuestas, y la segunda, para que revisaran cualquier error o palabra omitida.8
Las grabaciones de audio de ambos instrumentos fueron narradas en la voz de un hablante nativo de inglés de la región de Oxfordshire, Inglaterra, para asegurarse que los alumnos oyeran un acento lo más estándar posible. Estas fueron grabadas en un archivo digital y posteriormente fue reproducido en una computadora portátil (laptop), con la ayuda de altavoces en la sala de clases con una calidad de 192 kbps.
Análisis
Los grafemas usados por los estudiantes para representar los fonemas /æ/ y /ʌ/ se clasificaron en tres grupos: grafía correcta, ideal o predictiva, si el grafema utilizado en la palabra corresponde a lo que un hablante nativo de inglés utilizaría para tal fonema en ese contexto; grafía que sugiere transferencia, si el grafema utilizado corresponde a una grafía más cercana a lo que se utilizaría en español para representar un fonema similar en esta lengua; y otra grafía, si el grafema utilizado no pertenece a ninguno de los dos grupos anteriores.9
Para determinar la naturaleza de las grafías para /æ/ y /ʌ/ solo se consideró el grafema o grupo de grafemas que los alumnos utilizaron para representar estos fonemas dentro de la palabra, y luego fueron clasificados de acuerdo con las características definidas en las tablas 1 y 2.10
Tabla 1: Clasificación para palabras con el fonema /æ/, utilizando como ejemplo la palabra /pæb/

1 No se consideró como un error el no duplicar la consonante en la palabra para mantener la vocal. Paged correspondería a la grafía predictiva de /peɪdʒd/, y no de /pægd/.
2 En este caso, la palabra small se pronuncia /smɔ:l/, debido a que la combinación "<all>" se utiliza para representar gráficamente el fonema /ɔ:/; por lo tanto, en este ejemplo, el grafema <a> no correspondería a una combinación de grafías ideal o predictiva.
Tabla 2: Codificación para palabras con el fonema /ʌ/, utilizando como ejemplo la palabra /mʌb/
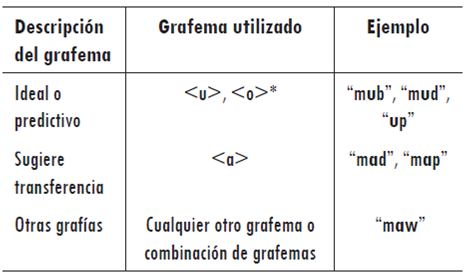
* Existe un caso, dentro de las respuestas entregadas, en el cual <o> corresponde al fonema /ʌ/, esto es, en la palabra other. Si bien la palabra dista de lo que fue reproducido en audio, se asume correcta, debido a que lo que se busca es la presencia del fonema a percibir y producir.
El análisis estadístico que se llevó a cabo para esta etapa fue, en primera instancia, un análisis de correspondencias multivariado, para relacionar pares de variables que pudieran tener eventualmente una estructura de dependencia. En segunda instancia se efectuó un análisis descriptivo univariado, para explicar y concluir de forma general y detallada. Ambos análisis se realizaron para seudopalabras en un contexto semántico, como a las aisladas.
Palabras en contexto semántico
Tras el análisis descriptivo multivariado, se obtuvo un valor altamente significativo (p < 0,0001) del estadístico Chi cuadrado de Pearson; por lo tanto, se puede establecer que existe una relación entre las variables "Fonema" y "Tipo de grafía", es decir, los errores ortográficos de los alumnos sí están influenciados por el fenómeno de transferencia fonológica negativa de los fonos del español, como lo indica la tabla 3.
Tabla 3: Tabla de contingencia para las palabras de estudio que contienen la vocal /æ/ o /ʌ/, y escritura dada por los alumnos

gl: Grados de libertad; p: Medida de significación estadística, utilizado para validar el análisis; Chi Cuadrado MV-G2: Cociente de máxima verosimilitud, estadístico análogo al Chi Cuadrado de Pearson para muestras más grandes
Para un total de 659 palabras válidas, menos de la mitad corresponde a aquellas con vocales escritas predictivamente (39,9%). Por otro lado, un porcentaje mayor (45,8%) corresponde a casos en los cuales los alumnos optaron por utilizar un grafema más cercano a lo que el español podría ofrecer para tales ítems. Significativa también es la cifra de palabras escritas con otros grafemas, los cuales constituyen el 18% del total de ítems, como se grafica en la figura 2.
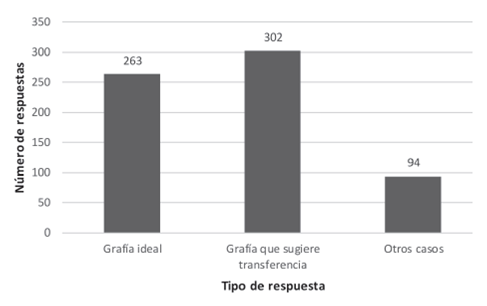
Figura 2 Número de respuestas dependiendo del tipo de grafema para los fonemas /æ/ y /ʌ/ en conjunto, para palabras en contexto semántico
En la figura 3 se ilustra de manera específica cada fonema.

Figura 3 Porcentaje de respuestas para las diferentes opciones de grafía según fonema a representar en palabras dentro de un contexto semántico
Se puede observar que, para el fonema /æ/, el número de respuestas para grafías ideales o predictivas es mucho mayor (64,1%) que el de aquellas palabras con grafías que sugieren transferencia (29%). Estos resultados serían consistentes tanto con las opciones que la lengua inglesa ofrece para la representación de /æ/, como la opción que el español ofrece para la vocal /a/. En la tabla 4 se entrega un detalle de las respuestas a los fonemas en cada seudopalabra.
Tabla 4: Cantidad de casos por cada una de las opciones para representar los fonemas de manera escrita en palabras dentro de un contexto semántico

* Del total de respuestas se omitieron aquellas palabras cuyo número de sílabas era menor al de la palabra a escribir (ej. full para fortansic), ya que resultaría complicado establecer la sílaba que contenía la vocal que los alumnos querían representar. Tampoco se consideraron las omisiones en el test dentro del total.
La figura 4 ilustra de mejor manera la cantidad de tipos de respuesta por seudopalabra. El caso de yuts, la cual no presentó ningún grafema ideal por parte de los alumnos, puede deberse al hecho que esta palabra fue expuesta en el audio del poema después del ítem yats, con la que conforman un par mínimo; es muy probable que los alumnos las hayan percibido como el mismo ítem dentro del poema y, por ende, las representaran en la grafía de forma similar, aun cuando fonémicamente se trataba de dos realizaciones diferentes. La vocal de ushed (/ʌ/) es la que tiene el mayor porcentaje de grafías que sugieren transferencia (representada principalmente con <a>), observándose que un número alto corresponde a la palabra del inglés ash (/æʃ/).

Figura 4: Opciones de grafía utilizados para representar las vocales en palabras dentro de un contexto semántico
Similar es lo que ocurre con la seudopalabra ulliter, para la cual la mayoría de los alumnos dio como respuesta el sintagma a Little (/ə 'lɪt.l̩/). Tras el análisis y la reflexión se llegó a dos posibles explicaciones para los casos de grafías no ideales tanto de ushed como ulliter: primero, podría tratarse de un error de tipo intralingual, en el que los estudiantes no fueron capaces de percibir el fonema producido (/ʌ/), limitándose a escribir las palabras del corpus inventado con la forma de ítems reales del inglés con los cuales ya estaban familiarizados. La segunda explicación, y por la cual se apuesta en esta investigación, podría ser que la percepción de los estudiantes se basa en su conocimiento fonético-fonológico del español y, como consecuencia, al no poder distinguir claramente el contraste entre los tres fonemas /ʌ/, /æ/ y /ə/, decidieron representar la vocal de manera escrita utilizando el grafema <a> ,el cual les resultaba más familiar para dicho sonido, esto sobre la base de la influencia que el repertorio fonético-fonológico de L1 español tiene en la percepción y posterior producción.
En cuanto a la vocal en mub, el 57% de los alumnos escribió el grafema <a>, por lo que creemos que es un caso de transferencia negativa de la vocal /a/ del español. Pab, aphininning y acks fueron los ítems con más grafías predictivas, superando el 50% de respuestas ideales. En el caso de pab se esperaba una palabra ya común para el nivel de los alumnos en este caso (pub), mas esto no ocurrió así. Tampoco hubo respuestas de alumnos con grafema <e>; por lo tanto, pab fue la única palabra sin grafemas que sugieran transferencia fonético-fonológica negativa.
La vocal /æ/ en aphinning también tuvo un alto porcentaje de grafías ideales (83%), aun cuando se trataba de una palabra polisílaba, la cual podría haber representado mayor dificultad en percepción comparada con una seudopalabra monosílaba del corpus. Finalmente, acks fue otro ítem con un alto porcentaje de grafías predictivas para su fonema /æ/, llegando al 59%; sin embargo, hay que mencionar que dentro de las opciones de respuesta, los alumnos escribieron la palabra homófona del inglés axe (/æks/). Si bien en este caso <a> en axe también representa el fonema /æ/, se vuelve a apreciar que la influencia del conocimiento léxico del inglés por parte de los alumnos, junto con el contexto semántico en el cual estaba inserta la seudopalabra, pudieron haber sido un factor determinante al momento de representar gráficamente este fonema. Caso similar se observó en otra grafía en las respuestas, la que, sin embargo, fue clasificada como transferencia negativa: eggs (/egz/).
Dentro del grupo de seudopalabras cuyas vocales fueron representadas con grafemas que no corresponden ni a grafías predictivas ni a casos que sugieren transferencia negativa, ubbed y yuts son los dos ítems con mayor frecuencia. En el caso de yuts, se especula que los estudiantes pudieron haber percibido yuts y yats como la misma palabra, pero reproducida dos veces en el audio. Muchas de las respuestas para la vocal /ʌ/ en yuts incluyen la vocal <e> (yets o llets), lo que se asemeja en frecuencia a lo ocurrido con las opciones de grafía para la palabra yats que los alumnos entregaron en la misma prueba, la que en dicho caso sí fue considerada como ejemplo de transferencia fonético-fonológica negativa.
Palabras sin contexto semántico
Tras realizar el análisis descriptivo multivariado de los datos obtenidos de las grafías proporcionadas por los alumnos para las palabras con ambas vocales, se obtuvo un valor altamente significativo (p < 0,0001) del estadístico Chi cuadrado de Pearson, como ocurrió en las palabras dentro de un contexto semántico. Por lo tanto, se puede establecer que existe una relación entre las variables "Fonema" y "Tipo de grafía" (véase tabla 5).
Tabla 5: Tabla de contingencia para las palabras de estudio que contienen la vocal /æ/ o /ʌ/, y escritura dada por los alumnos
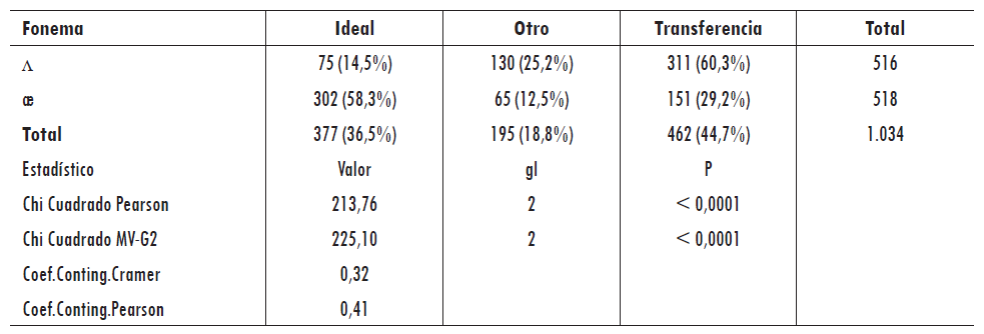
gl: Grados de libertad; p: Medida de significación estadística, utilizado para validar el análisis; Chi Cuadrado MV-G2: Cociente de máxima verosimilitud, estadístico análogo al Chi Cuadrado de Pearson para muestras más grandes
Para un total de 1.034 palabras válidas, menos de la mitad corresponde a aquellas con vocales escritas utilizando un grafema ideal para esos sonidos (36,5%). Por otro lado, un porcentaje mayor (44,7%) corresponde a casos que sugieren transferencia negativa. Significativa también es la cifra de palabras escritas con otros grafemas, los cuales constituyen aproximadamente el 19% del total de ítems (véase figura 5).

Los alumnos en general se inclinaron por representar el fonema /æ/ con el grafema <a>, siendo esto consistente con las opciones que la lengua inglesa ofrece para representar tal fonema, aunque también es la opción que el español ofrece para la vocal /a/. En el caso de la grafía para /ʌ/, los alumnos utilizaron más grafemas distintos de <u>, el cual fue el considerado ideal o predictivo para este fonema vocálico. La figura 6 ilustra de manera más clara esta tendencia.

Figura 6: Porcentaje de respuestas para las diferentes opciones de grafía según fonema a representar, en palabras aisladas
Las respuestas ideales para representar /ʌ/ alcanzan el 14,5%, mientras que las que sugieren transferencia negativa, el 60,3%. También hay que destacar que el 25,2% de palabras fue representado con otros grafemas. Por otro lado, para el fonema /æ/, el número de respuestas de grafemas ideales o predictivos es mucho mayor (58,3%) y aquellas palabras con grafías que sugieren transferencia alcanzan el 29,2%. Solamente el 12,5% del total de palabras corresponde a otros casos. En la tabla 6 se aprecia la cantidad de casos por cada grupo en cada una de las seudopalabras.
Tabla 6: Número de casos de cada opción de grafema para representar los fonemas en palabras aisladas

La figura 7 grafica los resultados presentados anteriormente, ilustrando los porcentajes por cada tipo de respuesta.

La vocal en acks de nuevo tuvo un alto índice de respuestas ideales (94%), esto en su mayoría porque los alumnos escribieron esta seudopalabra con la forma axe, como ocurrió en el primer grupo de estudiantes, quienes realizaron la prueba con palabras dentro de un contexto semántico. Sin embargo, en las otras dos seudopalabras con alto índice de respuestas ideales, pab y agged, los alumnos no utilizaron como referencia ninguna palabra del inglés para representarlas de manera gráfica.
La vocal /ʌ/ en ushed nuevamente registró un alto porcentaje de grafías que sugieren transferencia negativa (92%), principalmente por elementos iguales o similares a la palabra inglesa ash. En fortansic, /æ/ obtuvo el 84% de respuestas que sugieren transferencia negativa, representadas con <e>. En cuanto a la vocal en ulliter, 79% de las respuestas de los alumnos incluyó <a> para representar /ʌ/. Similar a lo ocurrido con el primer grupo de estudiantes que realizó la prueba con palabras dentro de un contexto semántico, la mayoría de este grupo percibió el sintagma a Little.
El porcentaje en el grupo "Otros casos" para la palabra yuts podría deberse a algo similar a lo ocurrido con las respuestas del primer grupo de estudiantes en la misma prueba: ellos pudieron haber percibido yuts y yats como la misma palabra, pero reproducida dos veces en el audio (uso de <e> en la grafía para representar /ʌ/, como "yets"), hecho que se asemeja en frecuencia a lo ocurrido con las respuestas en la grafía para la seudopalabra yats (situación en la que <e> sí fue considerada como ejemplo de transferencia negativa). En cuanto a ubbed, los alumnos optaron por escribir la vocal utilizando diptongos como <ou> y <au>11 (/aʊ/ y /o:/ respectivamente), lo que justificaría el alto índice de grafías que fueron consideradas como otros casos.
Reflexiones finales
En esta investigación se ha recogido evidencia para descubrir si los errores ortográficos en los textos escritos de los alumnos de quinto año básico de un colegio bilingüe inglés de Concepción, Chile, estaban influenciados por el fenómeno de transferencia fonético-fonológica negativa producida por la percepción de los fonos del español. Hay que recalcar nuevamente que los sujetos de este estudio han adquirido durante su proceso escolar, y de manera simultánea, las habilidades lingüísticas en ambos idiomas, tanto oral como escrita, a nivel de producción y comprensión.
Los resultados de ambas pruebas sugieren que los errores ortográficos de los alumnos sí tendrían una base en la transferencia fonético-fonológica negativa, esto según los resultados para todas las grafías asociadas a las vocales en las seudopalabras, tanto dentro de un contexto semántico como aisladas (46 y 45% de grafías que sugieren transferencia negativa respectivamente). Con estos resultados quedó de manifiesto que sí existen dificultades en los alumnos para poder percibir y distinguir contrastes en estos dos sonidos vocálicos del inglés, /æ/ y /ʌ/, y problemas en su posterior representación gráfica, debido a la interferencia principalmente del fonema español /a/ sobre /ʌ/, y en menor medida el fonema español /e/ sobre /æ/. Esto tendría su explicación en lo expuesto en teorías como la criba fonológica (Trubetzkoy, 1987 [1939]), sordera fonológica (Dupoux y Peperkam, 2002), el modelo de asimilación perceptiva (Best, 1995) y el modelo magneto de lengua nativa (Kuhl e Iverson, 1995)
Al analizar por separado los casos de transferencia negativa de acuerdo con el fonema a representar, se descubrió que para el sonido /æ/ el número de respuestas ideales fue mayor que los casos existentes de transferencia negativa. Considerando la transparencia en la relación fonema-grafema de /æ/ y <a> para los hablantes nativos de inglés, se esperaba en el estudio que se cumpliera esa tendencia. A pesar del alto porcentaje de grafías ideales para representar /æ/, no habría que apresurarse en generalizar y establecer una causa única a esta cifra, ya que no existe certeza total de que los aciertos de los alumnos se deban primordialmente a su capacidad para distinguir los fonemas del inglés y asociarlos con una grafía predictiva en esta lengua: se puede concluir que los sujetos usaron <a> para representar el fonema español /a/ erróneamente percibido, transformándose de este modo en un caso de transferencia positiva (Best, 1995; Kuhl e Iverson, 1995; Dupoux y Peperkam, 2002). Por ende, si bien existe un alto número de grafías ideales para la vocal, no queda clara la razón de tal fenómeno. No obstante, lo que sí queda de manifiesto al revisar los resultados de grafías para /æ/, es que existe un bajo porcentaje de casos atribuibles netamente a la transferencia negativa de los fonos del español, en particular aquellas escritas con <e>.
En cuanto a /ʌ/, se encontraron mayores casos de grafías que sugieren transferencia negativa graficadas en <a>, siendo esto consistente con la opción de grafía que el español entrega para /a/, vocal que puede considerarse como la más cercana en el espacio fonémico del hablante de español como L1. Sin embargo, podría cuestionarse el hecho de que en inglés existe una relación fonema-grafema bastante asimétrica para el sonido /ʌ/, lo que se refleja en que no existe un grafema único para este fonema y, por lo tanto, representar este sonido en la grafía constituiría una tarea más compleja para los sujetos, en comparación con representar /æ/. Sin embargo, existen reglas o combinaciones de letras que los aprendientes generalizan al aprender a escribir en inglés (Bryant, 2002), dentro de las cuales <u> es la más común para representar /ʌ/, grafema que se consideró como grafía predictiva en las pruebas, por sobre <o> y <oo>, combinaciones que fueron escasas dentro de las respuestas de los sujetos.
Al momento de analizar los resultados para las palabras dentro de un contexto semántico se encontraron ejemplos de palabras en los que se creyó que los alumnos pudieron haber "adivinado" los ítems que iban en los espacios en blanco, o haberse limitado a escribir lo que "mejor les sonaba" de acuerdo con la oración, en vez de escribir lo percibido en la grabación (eggs y axe por acks, ash por ushed, y a Little por ulliter). Sin embargo, se logró establecer que existe una similitud en los resultados de ambas pruebas; por lo tanto, no hay evidencia para aceptar la idea de que el contexto semántico es el responsable de las grafías para los fonemas de las seudopalabras, desechándose tal supuesto, y volviéndose a inclinar por la influencia de los fonos del español como causantes de las grafías no ideales.
Se sugiere que en futuras investigaciones relacionadas al tema de la transferencia fonético-fonológica negativa se observe minuciosamente la selección de los fonemas a ser estudiados (contrastes entre pares mínimos, vocales alófonas en español, vocales que comparten espacios fonémicos en L1 y L2), contextos donde los fonemas estarán insertos (en palabras, seudopalabras, inmersas en un contexto semántico, aisladas) y la manera en que se le pedirá a los informantes que produzcan los fonemas gráficamente (escoger entre distintas opciones encerrando una alternativa, completación de espacio en una palabra con un grafema de manera libre, representar de manera gráfica una palabra inserta en un texto más complejo, etc.). Además, se debe tener presente un detalle minucioso de los repertorios fonológicos de L1 de los informantes y L2 del sistema a ser percibido, para contar con mayor información al momento de analizar resultados y generar conclusiones.