French (pdf)
French (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroduction
L’essor de la société de l’information à notre époque et la multiplication vertigineuse des échanges entre les individus ont mis en évidence, depuis quelques années, l’importance du rôle des communications entre personnes de langues premières (L1) différentes et donc l’importance de pouvoir s’exprimer en différentes langues.
Parallèlement à cela, l’éventail des situations de communication s’est aussi diversifié avec la mobilité de la population mondiale, qui s’accroît sans cesse en ce qui a trait aux besoins habituels des interlocuteurs. Ainsi, ce n’est plus uniquement les personnes avec des emplois langagiers très spécifiques qui s’intéressent à la maîtrise d’une langue, mais également des personnes qui désirent échanger sur les plans académique, politique, économique, culturel, social, de loisir, etc. (Tarone, 2015, p. 448). De plus, l’apprentissage des langues autres que la langue première est de plus en plus encouragé par des États et des communautés, en tant qu’élément garant de leur développement et de leur épanouissement (Eurostat, 2016).
Dans le domaine de l’apprentissage des langues secondes (ALS), l’analyse d’erreurs (AE) s’avère une discipline de longue date qui regroupe des études et des recherches très variées. Erdogan (2005, p. 269) propose trois caractéristiques communes qui permettraient de décrire de façon générale les recherches en lien avec l’AE en ALS :
L’AE identifie les stratégies utilisées par les apprenantes et apprenants d’une langue.
Elle cherche à expliquer pourquoi les apprenantes et apprenants font des erreurs.
lle détermine les difficultés communes dans l’apprentissage et contribue au développement de ressources et de matériel pour y remédier.
Dans notre projet de recherche intitulé « Compétence Communicative Transitoire et Enseignement des langues », nous nous intéressons à l’analyse des erreurs recensées dans des rédactions d’apprenantes et d’apprenants du catalan, dans le but d’expliciter des remarques ou observations pédagogiques pour éviter les erreurs inventoriées comme récurrentes (Joan Casademont, sous presse).
Déjà en 1967, Corder distinguait les erreurs systématiques (qui concernent la norme) et les erreurs de production (commises de façon ponctuelle). On appelle les premières erreurs (errors) et les deuxièmes fautes ou équivocations (mistakes). Les deuxièmes sont causées par la fatigue, le manque de concentration, etc. L’apprenante ou l’apprenant peut s’autocorriger, le cas échéant, avec les mécanismes adéquats (Fernández Jódar, 2006, p. 13). Dans notre projet, nous travaillons avec les erreurs qui caractérisent l’interlangue de l’apprenante ou l’apprenant, ce stade intermédiaire dans l’apprentissage d’une langue qui comporte souvent des caractéristiques de la L1 et qui est défini par Fernández Jódar de la façon suivante :
La IL [interlangue], sin embargo, es un sistema lingüístico mental recreado por cada aprendiz para expresar en una L2 aquello que podría expresar en su L1. Con tal fin recurre a veces a la L1 (transferencias) o realiza hipótesis que pueden ser correctas o incorrectas, sobre la L2. Este sistema lingüístico mental no debe ser considerado como erróneo sino como un sistema evolutivo entre la L1 y la L2, con características de ambas y propias al mismo tiempo, y que refleja la competencia comunicativa transitoria del aprendiz. (2006, p. 10)
Le but ultime de notre recherche est de contribuer à l’évolution de la compétence communicative transitoire de l’apprenante ou l’apprenant vers une maîtrise encore plus ancrée de la L2 (catalan). Les erreurs sont donc vues comme une occasion d’améliorer les stratégies que l’apprenante ou l’apprenant pourra utiliser au moment de communiquer dans la L2 (Astolfi, 2015).
Notre cadre de départ est le modèle CAF [complexity, accurancy, fluency; complexité, précision, aisance] (Skehan, 1998; Ellis, 2003, 2008; Ellis et Barkhuizen, 2005; Housen, Kuiken et Vedder, 2012, entre autres) et nous mettons l’accent sur la précision aux niveaux lexical et grammatical, mais également aux niveaux expressif et communicatif.
L’apprentissage de la langue catalane au niveau universitaire se fait actuellement selon une approche communicative basée sur les tâches (Ellis, 2003, entre autres), c’est-à-dire, des mises en contexte à partir de différentes situations communicatives qui permettent d’assurer une communication efficace en fonction de buts établis. Le sujet même des rédactions qui est à la base du corpus (écrire une lettre à un ami ou une amie depuis l’étranger; voir ci-dessous pour plus de détails) reflète cette vision, qui correspond au Cadre européen commun de référence pour les langues (Conseil d’Europe, 2001; 2018).1 Quant à l’AE en particulier, dans cette recherche nous nous concentrons sur la détection de l’erreur dans le corpus, sur sa description linguistique (voir le critère descriptif ci-dessous) et sur un essai d’explication de celle-ci. L’un des sujets incontournables dans le domaine de l’AE est l’établissement de typologies ou taxonomies d’erreurs, puisqu’il s’agit d’une étape indispensable pour le traitement ultérieur des données de corpus et l’obtention de résultats. Pour cela, les chercheuses et chercheurs ont considéré les erreurs de différents niveaux du système linguistique ou se sont concentrés sur des aspects précis, comme la morphologie ou la sémantique. En outre, elles et ils ont choisi différents critères de classification, en accord avec le but de leur recherche, et donc proposé ou utilisé des taxonomies qui leur permettaient d’étudier les éléments pertinents. En même temps, nous trouvons des travaux dans lesquels on réfléchit sur l’erreur de façon générale ou abstraite, et d’autres dans lesquels les recherches sont basées sur l’analyse d’une ou de plusieurs langues. Ainsi, nous soulignons, parmi d’autres, les travaux de Lado (1957), Corder (1971, 1973, 1981), Burt, Dulay et Krashen (1982), Krashen et Terrell (1983), Krashen (1985), Vázquez (1991), Santos Gargallo (1993), Ellis (1997), Fernández (1997), Vázquez (1998), Brown (2000), Julià i Muné (2000), Pastor Cesteros (2004), Griffin (2005), Erdogan (2005), Alexopoulou (2005, 2006), Fernández Jódar (2006), Hamel et Milicevic (2007), Alba Quiñones (2009), Ferris (2011), Astolfi (2015).
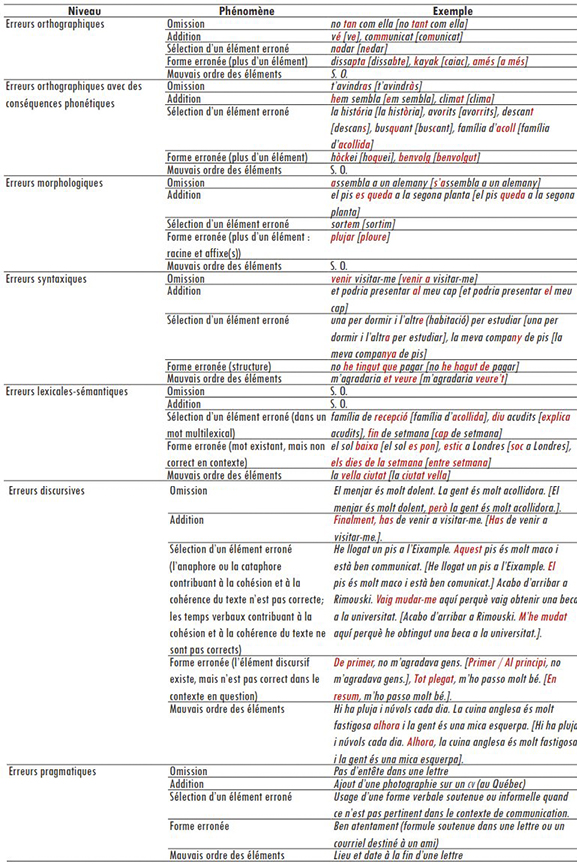
À partir de certains de ces travaux, nous avons modelé une taxonomie qui nous permettait d’observer des aspects précis, à savoir les caractéristiques des erreurs du point de vue du système linguistique et des possibles explications concernant la parution de ces erreurs. Dans notre cas, nous avons axé notre analyse sur l’approche descriptive et étiologique et nous avons donc adapté une liste de champs qui nous convenait (Tableau 1).
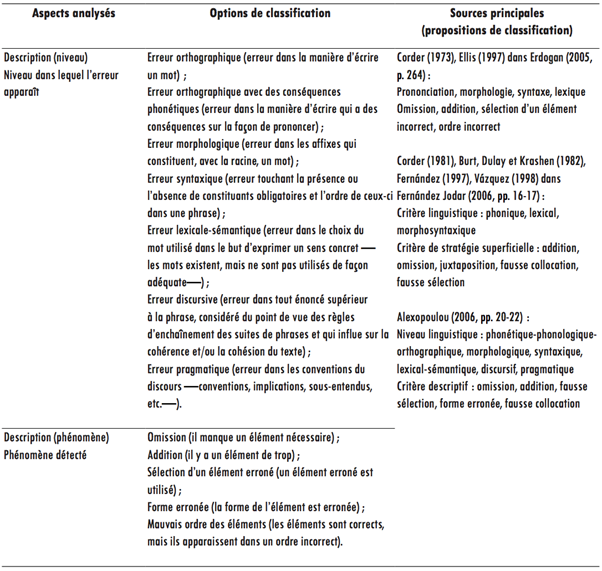
Afin de bonifier notre première proposition de classification, lors de l’analyse qualitative, nous considérons également quelques-uns de nos résultats en les comparant avec la classification d’erreurs d’Hamel et de Milicevic (2007), qui s’insère dans la théorie linguistique Sens-Texte et dont le but est notamment lexicographique-pédagogique. Les trois groupes principaux d’erreurs considérés dans leur recherche sont les suivants :
Méthode
Dans cette recherche, nous avons utilisé un corpus tiré des examens officiels de langue catalane de l’Institut Ramon Llull pour le niveau B1 (seuil) du Cadre européen commun de référence pour les langues (CECRL). Du point de vue chronologique et géographique, il s’agit des examens réalisés à Montréal entre 2009 et 2016.
Concrètement, nous avons travaillé sur des rédactions libres à partir d’un sujet, qui font partie de l’une des questions des examens officiels (production écrite). Les étudiantes et étudiants devaient écrire une lettre informelle à un ami pour expliquer leurs premières expériences lors d’un stage à l’étranger (hébergement, cours ou stages, caractéristiques de l’endroit, personnes rencontrées, etc.) et pour inviter le récipiendaire de la lettre à leur rendre visite (genre : explication de soi-même entre pairs). Selon les nouveaux descripteurs du CECRL, il s’agirait d’écriture créative dans la production écrite générale (Conseil d’Europe, 2018, p. 71), ainsi que de correspondance dans l’interaction écrite générale (Conseil d’Europe, 2018, p. 85).
Même si les examens du corpus de l’Institut Ramon Llull sont anonymes ou rendus anonymes, des données sur les émetteurs sont disponibles afin de réduire le nombre de variables lors d’analyses linguistiques des textes. Ainsi, à partir du premier tri de 22 rédactions faites à Montréal, nous avons seulement choisi les rédactions des personnes dont la langue première est le français, ce qui donne un total final de 17 rédactions pour le corpus de cette première recherche. Ensuite, chacune des rédactions a été corrigée manuellement, et 237 erreurs de différents types ont été détectées. Nous sommes consciente que l’échantillon est petit en comparaison d’autres études de ce type. Or, nous l’avons choisi ainsi dans le but de tester notre méthodologie d’annotation.
Nous avons décrit les erreurs avec la classification créée ad hoc montrée ci-dessus. Nous verrons que cette première analyse nous a permis de proposer ensuite une version améliorée de la classification d’erreurs utilisée.
Pour une présentation un peu plus exhaustive et exemplifiée des valeurs en lien avec les champs traités précisément dans cet article, c’est-à-dire pour le niveau et le phénomène décrits, vous pouvez consulter l’Annexe.
Dans les sections suivantes, nous présentons quelques résultats quantitatifs et plusieurs analyses qualitatives réalisées à partir des données recueillies en suivant la méthode que nous venons de décrire. Nous observerons concrètement les résultats obtenus pour les valeurs en lien avec le niveau linguistique dans lequel les erreurs se situent, ainsi que pour le phénomène lié à l’erreur en question. D’un point de vue statistique, pour chaque type d’erreur, le nombre d’erreurs commises pour chacun des sous-types est résumé à l’aide de fréquences et pourcentages, parmi l’ensemble des 237 erreurs de toutes les étudiantes et tous les étudiants du corpus. De plus, nous avons obtenu des tableaux de fréquences croisés, afin d’étudier la relation entre deux types d’erreurs à la fois. Des corrélations de Spearman ont permis de mesurer l’association entre le nombre d’erreurs de chaque type par étudiante et étudiant (corrélations significatives à <0,05). Aucune des analyses effectuées n’a comme hypothèse la normalité. Nous n’avons pas détecté de données extrêmes.
Résultats quantitatifs
Les résultats quantitatifs sont présentés dans l’ordre qui suit : informations en lien avec le niveau du système linguistique, informations sur le phénomène linguistique qui provoque l’erreur, et combinaison des deux types de valeurs.
Niveaux du système linguistique
Du point de vue du niveau du système linguistique, les erreurs orthographiques avec des conséquences phonétiques (30,38 %) et les erreurs syntaxiques (30,38 %) constituent plus de la moitié du total des erreurs détectées (62,45 %) (Figure 1).
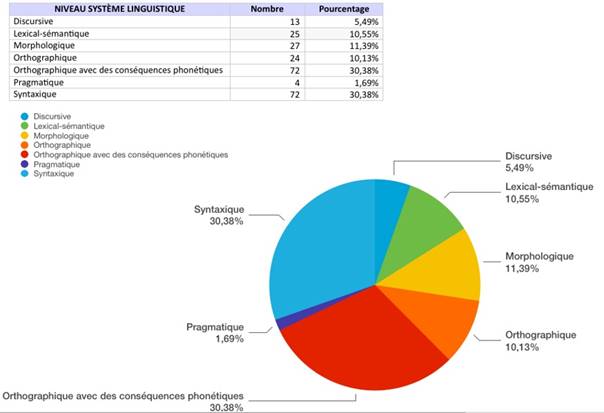
Par contre, les erreurs morphologiques (11,39 %) et lexicales-sémantiques (10,55 %) sont moins fréquentes dans le corpus. Quant aux erreurs orthographiques au total, même si elles représentent 40,51 % des erreurs du corpus, celles sans conséquences phonétiques sont présentes seulement 10,13 % des fois, ce qui est un chiffre moindre par comparaison avec 30,38 % d’erreurs orthographiques avec des conséquences phonétiques que nous avons mentionnées précédemment. Les erreurs discursives et pragmatiques sont les moins fréquentes dans les rédactions analysées (5,49 % et 1,69 %, respectivement).
Phénomènes linguistiques selon le niveau
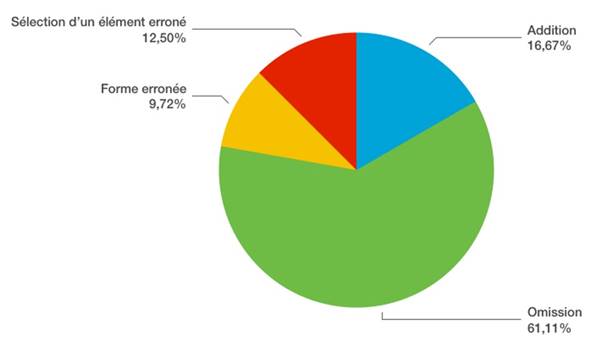
Si nous observons les données du niveau du système linguistique en lien avec le phénomène linguistique établi pour chaque erreur, quelques tendances de comportement peuvent être mentionnées. Au niveau orthographique avec des conséquences phonétiques, plus de la moitié des erreurs sont produites par une omission (61,11 %). Ensuite, les causes les plus fréquentes seraient l’addition (16,67 %) et la sélection d’un élément erroné (12,50 %) (Figure 2).
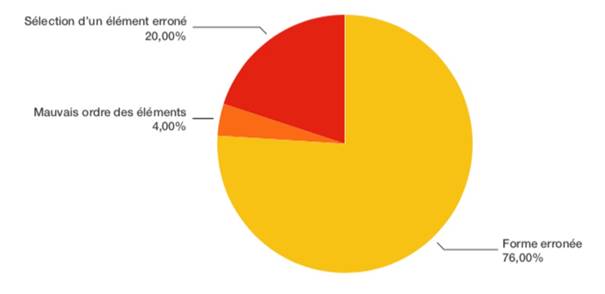
Au niveau orthographique sans conséquences sur la prononciation, les différences quantitatives sont moins prononcées en comparaison des données précédentes : plus d’un tiers des erreurs sont produites par l’addition (37,50 %), mais la sélection d’un élément erroné (33,33 %) et l’utilisation d’une forme erronée (25 %) sont également assez fréquentes (Figure 3).
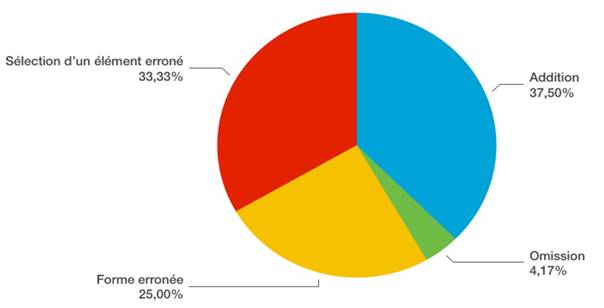
Au niveau syntaxique, plus de la moitié des erreurs sont produites par la sélection d’un élément erroné (55,56 %). Suivraient par fréquence l’addition et l’omission, à pourcentage égal (18,06 %) (Figure 4).
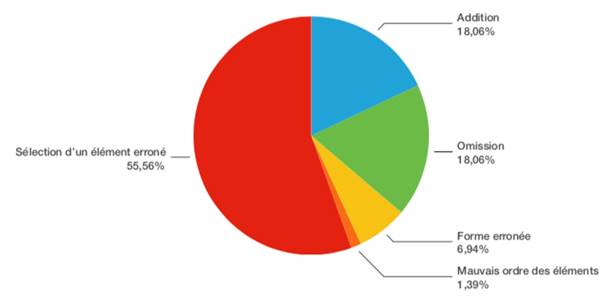
Au niveau morphologique, plus de la moitié des erreurs sont produites par la sélection d’un élément erroné (70,37 %). La deuxième raison pour ce type d’erreurs serait l’addition (18,52 %) (Figure 5).
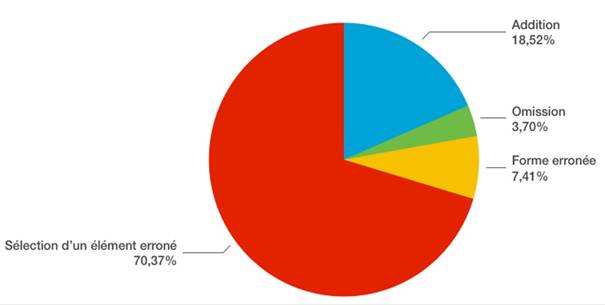
Au niveau lexical-sémantique, les trois quarts des erreurs se trouvent dans l’utilisation d’une forme erronée (76 %), et presque un quart dans la sélection d’un élément erroné (20 %) (Figure 6).
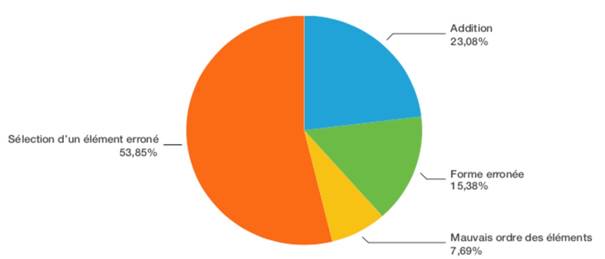
Au niveau discursif, plus de la moitié des erreurs se trouvent dans la sélection d’un élément erroné (53,85 %), et presque un quart des erreurs restantes sont provoquées par l’addition d’un élément non pertinent (23,08 %) (Figure 7).
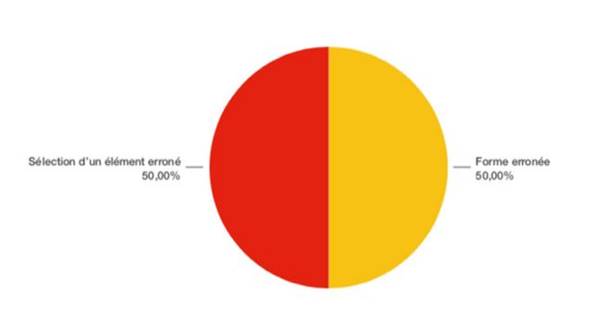
Finalement, au niveau pragmatique, la moitié des cas sont causés par la sélection d’un élément erroné et l’autre moitié par une forme erronée (Figure 8).
Dans la section suivante, nous considérerons les données quantitatives précédentes d’un point de vue qualitatif.
Analyse linguistique qualitative des résultats
Dans la section précédente, nous avons observé une prédominance des erreurs orthographiques (principalement avec des conséquences phonétiques), ainsi que des erreurs syntaxiques. Nous commencerons donc par fournir des exemples concrets de ces erreurs et, ensuite, nous regarderons celles qui influent sur les niveaux morphologique, lexical-sémantique, discursif et pragmatique.
Niveau orthographique (principalement avec des conséquences phonétiques)
Quant à l’orthographe, les erreurs ayant des conséquences phonétiques sont principalement en lien avec l’absence ou la présence d’accent (corrélations significatives).2 Dans ces cas, les problèmes sont notamment l’omission d’accents (Oc. 1) ou leur addition incorrecte (Oc. 2) :
Oc.1 : Podríem anar junts al Parc de la Mauricie, un racó natural molt bonic amb gran varietat d’especies [espècies] d’ocells. (CE, p. 118)3
Oc. 2 : En tercer lloc, Mont-real és una ciutat on és [es] pot fer moltes coses. (CE, p. 180)
De surcroît, la sélection d’un élément erroné provoquant des conséquences phonétiques est souvent liée à l’usage incorrect de l’accent (Oc. 3, où l’erreur pourrait avoir été influencée par la langue première) :
Oc. 3 : A més, desprès [després] del partit, podríem anar a sopar a un restaurant al carrer Sainte-Catherine. (CE, p. 190)
Or, les erreurs orthographiques sans conséquences phonétiques sont souvent en lien avec les accents (addition), mais également avec l’usage d’une voyelle erronée pour reproduire à l’écrit un son atone (sélection d’un élément erroné : a/e, o/u). Dans le premier cas, il s’agit notamment de l’utilisation d’un accent qui indique la voyelle tonique correcte du mot, mais qui n’est pas correct selon les règles d’accentuation (Oc. 4); dans le deuxième cas, il s’agit principalement d’un usage erroné de la voyelle atone qui peut être un « a » ou un « e », selon les cas (Oc. 5) :
Oc. 4 : És força divertit, sempre diu acudits amb l’accent del nord del país, on vivía [vivia] abans. (CE, p. 114)
Oc. 5 : Hi ha un lloc molt bonic on es pot nadar [nedar] al riu. (CE, p. 132)
En outre, on trouve plusieurs cas où l’erreur est liée à l’écriture d’une expression en un seul mot ou d’un seul mot divisé en deux, sans que cela provoque des changements phonétiques, et que nous avons étiqueté comme forme erronée (Oc. 6) :
Oc. 6 : Perquè [per què] no vens a visitar-me un cap de setmana? (CE, p. 44)
Après l’observation de ces premières données, nous avons décidé de traiter les erreurs orthographiques en un seul groupe, indépendamment du fait qu’un locuteur natif ou de niveau avancé pourrait détecter ou pas des changements lors de la production orale de ces erreurs. Ces dernières correspondraient aux erreurs de forme erronée de la classification d’Hamel et de Milicevic (2007).
Niveau syntaxique
Nous avons vu que plus de la moitié des erreurs syntaxiques étaient en lien avec la sélection d’un élément erroné (corrélation significative).4 En fait, la plupart des sélections d’éléments erronés détectés sont en lien avec l’accord du genre ou du nombre entre le nom et l’adjectif (Oc. 7, Oc. 8, Oc. 9) :
Oc. 7 : El meu pis és molt lluny del centre. Per gràcia, és molt lluminós i té dues habitacions, una per dormir i l’altre [l’altra] per estudia.r (CE, p. 77)
Oc. 8 : A més, la cuina no és gaire bona tampoc, i els anglès [anglesos] són més aviat avorrits. (CE, p. 80)
Oc. 9 : Pel que fa als curs, són molt ben fet [fets]. (CE, p. 11)
Même si l’accord en genre et en nombre existe au niveau syntaxique dans la langue première des apprenantes et apprenants, il semblerait que l’influence du français viendrait plutôt de l’oral, où « autre », « anglais », « faits » se prononceraient de la même manière, même en s’accordant dans les versions françaises des phrases ci-dessus.
D’autres erreurs qui semblent être récurrentes au niveau syntaxique sont celles liées aux prépositions, que ce soit par l’utilisation d’une forme erronée (sélection d’un élément erroné comme pour les cas de l’accord vus ci-dessus), par addition ou par omission. Ces cas problématiques semblent être notamment liés aux structures existantes et correctes dans la langue première des apprenantes et apprenants ou même dans une langue apprise. Toutefois, ils sont quantitativement moins fréquents dans le corpus que les problèmes d’accord et donc il faudrait analyser cela avec un corpus plus large, afin de confirmer cette tendance. Voici un exemple d’omission (Oc. 10), d’addition (Oc. 11) et de l’utilisation d’une forme erronée (Oc. 12) du corpus :
Oc. 10 : Si vols venir [venir a] passar unes setmanes aquí, sempre seràs benvingut. (CE, p. 237)
Oc. 11 : I saps, segons sembla, estem buscant més empleats a la feina i potser et podria presentar al [el] meu cap! (CE, p. 165)
Oc. 12 : De fet, no et sembla una bona idea venir a Canadà en [el/al] desembre? (CE, p. 72)
Nos hypothèses sont les suivantes : l’erreur de l’occurrence 10 semblerait être attribuable à l’influence de la langue première de l’apprenante ou l’apprenant; l’erreur de l’occurrence 11 pourrait être une conséquence d’une autre langue apprise (l’espagnol, selon les données sociolinguistiques du corpus). Finalement, l’erreur de l’occurrence 12 pourrait avoir été attribuable à l’influence de la langue première, ainsi que par une autre langue apprise (l’espagnol) de l’apprenante ou l’apprenant en question. En effet, en français et en espagnol, on utilise la structure «en + MOIS », tandis qu’en catalan deux autres structures différentes sont les seules possibles : « el + mois » ou « al + MOIS », sans la préposition « en ».
Après l’observation de ces premières données, nous avons décidé de traiter les erreurs liées à l’accord en genre et en nombre dans le groupe des erreurs morphologiques. Il resterait, donc, dans le groupe des erreurs syntaxiques, celles que nous venons de mentionner en lien avec les prépositions, qui correspondraient aux erreurs de régime de la classification proposée par Hamel et Milicevic (2007).
Niveau morphologique
Nous avons vu que la plupart des erreurs morphologiques dans le corpus impliquaient la sélection d’un élément erroné. Il s’agit notamment d’erreurs dans la conjugaison des verbes :
Oc. 13 : És una ciutat del meu país que no coneixava [coneixia]. (CE, p. 210)
Oc. 14 : Treballa [Treballo] cada dia de la setmana des de les nou del matí fins a les set del vespre. (CE, p. 168)
Oc. 15 : [...] una noia que ve d’Alemanya i hem sembla que ens avenirem [avindrem] bé. (CE, p. 43)
Les erreurs de conjugaison détectées semblent être une conséquence d’une application incomplète des règles : par exemple, on applique la conjugaison du premier groupe à un verbe du deuxième groupe (Oc. 13) ou on utilise la mauvaise personne au moment de conjuguer le verbe (Oc. 14). Dans ce cas, on pourrait considérer que l’influence de la langue première joue un rôle dans la réalisation de l’erreur : « je travaille, il travaille », mais « jo treballo, ell treballa ». Également, il existe de nombreux cas qui dérivent d’une non-application de la restriction des règles : par exemple, on conjugue le verbe comme s’il était un verbe régulier, mais il ne l’est pas (Oc. 15).
Il faut également souligner les caractéristiques similaires des erreurs morphologiques d’addition et d’omission. En effet, elles semblent presque toutes être en lien avec des formes pronominales ou non pronominales des verbes en question :
Oc. 16 : Com t’he dit, el meu nivell d’anglès ja s’ha [ha] millorat. (CE, p. 13)
Oc. 17 : Com que no tenia cap feina aquí, he decidit marxar-me [marxar] cap a Austria. (CE, p. 195)
Oc. 18 : El pis, que es queda [queda] a la tercera planta, és bastant gran i hi toca el sol… (CE, p. 55)
Certaines de ces erreurs semblent être une conséquence de l’influence de la langue première (Oc. 16), de l’influence d’une autre langue apprise (Oc. 17; pour l’espagnol) ou même d’une confusion par analogie avec d’autres structures existantes en catalan (Oc. 18; «queda = être »; «es queda = rester/pas partir »). En fait, compte tenu de la taille du corpus ici, la seule corrélation statistiquement significative au niveau morphologique est celle impliquant une hypergénéralisation par fausse analogie (coefficient de corrélation : 0,484; signification : 0,049). Il serait donc pertinent de réaliser d’autres analyses avec un corpus plus grand.
Finalement, il faut mentionner que ces erreurs feraient partie également, avec les erreurs orthographiques de notre classification, des erreurs de forme erronée de la classification d’Hamel et de Milicevic (2007).
Niveau lexical-sémantique
Lors de l’analyse quantitative, nous avons vu que plus des trois quarts des erreurs lexicales-sémantiques impliquaient l’utilisation d’une forme erronée (corrélation significative).5 À leur tour, la plupart de ces erreurs sont provoquées par une utilisation erronée des verbes « ser » et « estar » en catalan : dans tous les cas analysés, le verbe « estar » est utilisé de façon incorrecte au détriment de « ser » (Oc. 19 et Oc. 20) :
Oc. 19 : D’aquí a 30 minuts estaré [seré] a l’escola. (CE, p. 40)
Oc. 20 : Estic [Soc] a Portugal, a la capital del país, Lisboa. (CE, p. 135)
Dans tous les cas détectés, et selon les données sociolinguistiques du corpus, nous pourrions expliquer l’erreur par la combinaison de deux circonstances interlinguistiques :
Les usages des deux verbes en catalan sont comblés par l’utilisation d’un seul verbe (« être ») en français et donc dans la langue première des apprenantes et apprenants.
Les apprenantes et apprenants commettant ces erreurs ont appris avant la langue espagnole, où l’usage du verbe « estar » est beaucoup plus prolifique que celui du « ser ».
Quant à la sélection d’éléments erronés au niveau lexical-sémantique (corrélation significative),6 les occurrences du corpus montrent notamment des exemples de syntagmes nominaux, dont un des éléments n’est pas correct (Oc. 21) ou des expressions phraséologiques où l’un des éléments n’est pas adéquat (Oc. 22) :
Oc. 21 : Et voldria convidar a Mont-real durant la fin [el cap] de setmana que ve (CE, p. 188).
Oc. 22 : És força divertit, sempre diu [explica] acudits amb l’accent del nord del país, on vivia abans (CE, p. 113).
Il faut mentionner que notre approche des erreurs lexicales-sémantiques est assez différente de celle d’Hamel et de Milicevic (2007). En premier lieu, les cas d’erreurs de collocation ont été classifiés comme lexicaux-sémantiques dans cette première recherche. Ensuite, nous n’avons pas classifié de façon détaillée les erreurs lexicales-sémantiques (Hamel et Milicevic (2007) proposent six sous-types d’erreurs de ce genre). Or, après l’observation de ces premières données, nous avons décidé de traiter les erreurs lexicales-sémantiques en ajoutant la classification fine proposée par ces auteures.
Niveau discursif
Lors de l’analyse quantitative, nous avons vu que plus de la moitié des erreurs discursives impliquait la sélection d’un élément erroné. Deux erreurs se répètent à ce niveau et pour ce phénomène : l’usage erroné du temps verbal, notamment en lien avec l’aspect (Oc. 23), et l’usage erroné de l’indicatif ou du subjonctif (Oc. 24) :
Oc. 23 : Ens hem conegut [vam conèixer] al cafè de la universitat el primer dia del curs. (CE, p. 112)
Oc. 24 : Si vinguis [vens] a visitar-me te’l presentaré! (CE, p. 201)
Dans la plupart de ces cas, l’influence de la langue première semble être en cause, que ce soit directement (Oc. 23) ou par ce qui semble être des hypercorrections, quand l’étudiante ou l’étudiant pense que la structure doit être différente de celle de sa langue première, mais ce n’est pas précisément le cas (Oc. 24). Par exemple, le conditionnel fonctionne de façon similaire en français et en catalan : dans le cas vu ci-dessus, une forme indicative serait nécessaire dans les deux langues (« Si vens… », « Si tu viens… »). Or, l’apprenante ou l’apprenant utilise la forme subjonctive en catalan (« Si vinguis… »), ce qui n’est pas correct.
Les quelques cas d’addition dans les erreurs discursives de notre corpus ne nous permettent pas de proposer des tendances. Or, les deux cas de formes discursives erronées semblent montrer, même s’ils ne sont pas quantitativement significatifs, l’existence de quelques confusions où les étudiantes et étudiants utilisent des éléments discursifs qui sont corrects linguistiquement et qu’ils ont travaillé en salle de classe (« aller au restaurant »), mais qui ne sont pas adéquats dans le contexte :
Oc. 25 : De primer [Primer / Al principi], trobava algunes coses del país horrible. (CE, p. 3)
Dans la phrase ci-dessus (Oc. 25), par exemple, l’étudiante ou l’étudiant utilise « de primer » dans le but d’indiquer « au début », mais il utilise « de primer » que l’on utilise très fréquemment au moment de commander un repas au restaurant (« comme entrée… »).
Que ce soit par sélection d’un élément erroné, par addition ou par forme erronée, toutes les occurrences détectées dans le corpus au niveau discursif semblent fonctionner comme distracteurs de la communication. Or, les quelques exemples discursifs du corpus étudié ne constituent pas des erreurs qui nuisent à la compréhension (causant de l’ambiguïté dans le texte), surtout parce que, à l’écrit, la lectrice ou le lecteur peut relire pour comprendre le message.
Niveau pragmatique
Nous avons seulement quatre occurrences d’erreurs au niveau pragmatique dans notre corpus, alors l’explication d’une tendance semble être difficile à argumenter. Nous considérons comme pertinent de souligner, toutefois, que la sélection d’éléments erronés et l’usage de formes erronées à ce niveau-ci est en lien notamment avec des usages typographiques (Oc. 26) ou des confusions de formules en lien avec le niveau de formalité (Oc. 27) :
Oc. 26 : La propietària, la Sra Smith, em va rebre amb un bon sopar i per postre… (CE, p. 33)
Oc. 27 : Ben atentament. (CE, p. 134)
En effet, l’abréviation correcte de « senyora » (« madame ») en catalan est « Sra. » sans exposants (Oc. 26). Finalement, l’usage de « Ben atentament » (Oc. 27) demande une communication épistolaire formelle, et il n’est pas donc pertinent dans le cas d’une lettre informelle écrite à un ami ou une amie à qui on raconte notre séjour à l’étranger. Des options pour remplacer cette formule pourraient être : « Fins aviat », « Una abraçada », « Petons », etc. Pour notre corpus, nous émettons l’hypothèse que l’apprenante ou l’apprenant cherche un registre plus formel en oubliant les traits du destinataire de la tâche demandée, puisqu’elle ou il se trouve dans un contexte officiel d’évaluation.
Conclusions
Dans cet article, nous avons recensé quantitativement et analysé qualitativement les erreurs les plus fréquentes dans un corpus de rédactions de niveau B1 en langue catalane par des apprenantes et apprenants francophones.
Même si plusieurs résultats ne sont pas nécessairement significatifs à cause de la taille de l’échantillon, nous pensons qu’ils sont intéressants du fait qu’ils permettent d’observer certaines tendances dans les erreurs commises par ces apprenantes et apprenants et, entre autres, d’établir certains aspects sur lesquels il semble pertinent de se pencher davantage lors des explications pédagogiques.
Ce premier échantillon nous a permis également de tester la classification d’erreurs que nous proposions et de l’améliorer pour des analyses postérieures. Notamment, les changements proposés à partir des descriptions travaillées dans cet article seront les suivants :
Sur le plan de la description linguistique :
Les erreurs orthographiques se trouveront dans un seul groupe.
Les erreurs morphologiques incluront les erreurs d’accord en genre et en nombre.
Les erreurs syntaxiques indiqueront les erreurs de régime (en lien avec les prépositions).
Les erreurs lexicales-sémantiques incluront les erreurs de collocation.
Sur le plan du phénomène linguistique :
Les erreurs lexicales-sémantiques seront considérées de façon plus détaillée à partir de la classification d’erreurs de sens d’Hamel et de Milicevic (2007) : (quasi)-synonyme, sens proche, sens fictif, générique, sens incompatible, situation incompatible.
Quant aux connaissances spécifiques en catalan langue étrangère qui devraient être travaillées davantage avec les apprenantes et apprenants, nous pouvons les énumérer comme suit :
les règles d’accentuation ;
les règles d’usage des voyelles atones ;
l’accord (en genre et en nombre) quand les exemples sonnent d’une façon semblable dans la langue première ;
les structures syntaxiques avec des prépositions différentes dans la langue première ou la langue apprise le plus fréquemment ;
les sens et les nuances entre formes pronominales et non pronominales des verbes ;
les usages concrets de « ser » et « estar »;
les usages de l’indicatif et du subjonctif ;
l’aspect verbal.
Fernández (1997, p. 48) établissait les tendances des stratégies d’apprentissage selon le stade de cet apprentissage : les stratégies intralinguistiques prennent de l’importance en relation avec le niveau de compétence dans une langue et au fur et à mesure que ce dernier augmente aussi (et cela au détriment des stratégies interlinguistiques, plus présentes aux stades initiaux d’apprentissage). De son côté, Alexopoulou (2005, p. 33), dans le cas des erreurs morphologiques, établissait une relation inversée entre les erreurs interlinguistiques et intralinguistiques : lors d’une augmentation des compétences dans une langue, l’apprenante ou l’apprenant commettrait moins d’erreurs interlinguistiques et plus d’erreurs intralinguistiques.
Le corpus analysé ici correspond au niveau B1 (Seuil) et, donc, se trouve au milieu de cette oscillation de l’interlinguistique à l’intralinguistique. En fait, nous avons détecté plusieurs cas d’erreurs récurrentes qui peuvent être expliquées par des stratégies interlinguistiques (influence de la langue première ou d’une autre langue apprise). Dans Hamel et Milicevic (2007, p. 41), les erreurs de forme fictive sont précisément souvent des emprunts. L’apprenante ou l’apprenant semble donc, au niveau Seuil, faire appel encore à la langue première (ou à une langue plus maîtrisée) quand elle ou il a des doutes sur la façon de s’exprimer. Des approches pédagogiques ciblant ce type d’erreurs sembleraient donc être une bonne voie pour améliorer l’efficacité de l’enseignement, incluant des approches pédagogiques en lexicographie (voir Hamel et Milicevic, 2010). Toutefois, on pourrait aussi penser que même si un travail était fait à ce niveau, il faudrait attendre un niveau plus avancé pour constater l’intégration de certaines structures dans la production des apprenantes et apprenants (Lightbown et Spada, 2018, p. 45).
Quant aux problèmes concrets soulevés ici, plusieurs techniques et stratégies pourraient être utilisées pour essayer de les régler. Même si nous en proposons quelques-unes, il ne faut surtout pas oublier que plusieurs options s’offrent aux enseignantes et enseignants, qui choisiront les techniques et les stratégies les plus adéquates, compte tenu des traits spécifiques de leurs apprenantes et apprenants, de la formule en salle de classe, des outils à la portée des étudiantes et étudiants, des objectifs du cours, etc. Voici, donc, à titre d’exemple, quelques propositions pour surmonter les problèmes vus en production écrite (Tableau 2).
Tableau 2 Problèmes et propositions de solutions
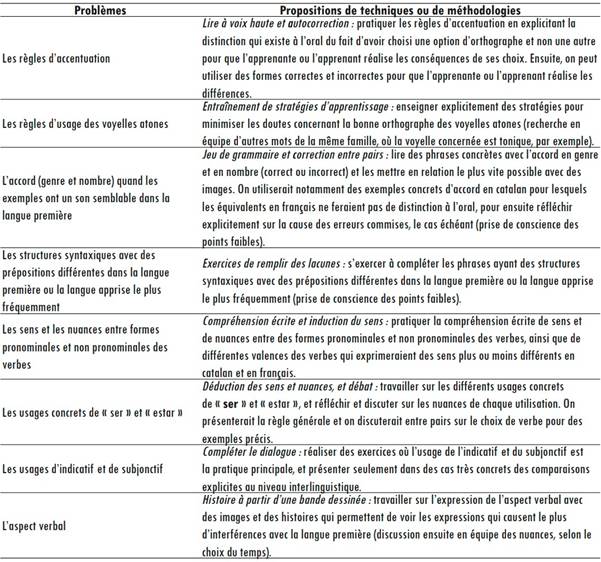
Notes: Les techniques et les propositions mentionnées sont tirées de Larsen-Freeman et Anderson (2016)
Bien que, dans le cadre de cette recherche, plus de détails sur les aspects étiologiques (interlinguistiques et intralinguistiques) et les aspects communicatifs des erreurs soient à venir, nous pensons avoir confirmé ici qu’une étude systématique des erreurs linguistiques nous permet d’établir les erreurs dans les productions écrites des étudiantes et étudiants en catalan, puis de les caractériser.
Les prochaines étapes de cette recherche incluront :
la mise en place de la nouvelle version de classification que nous avons indiquée dans les différentes sections précédentes ;
l’obtention d’un plus grand nombre de productions écrites afin d’élargir le corpus ;
la réalisation de tests pour les techniques proposées dans le but d’observer si elles permettent effectivement de remédier à certaines erreurs récurrentes détectées chez les francophones qui apprennent le catalan langue étrangère au niveau intermédiaire ;
C’est ainsi que nous pourrons envisager, ensuite, des stratégies pédagogiques vraiment efficaces et les intégrer dans nos cours, une étape intéressante à venir.