










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkRevista Colombiana de Biotecnología
Print version ISSN 0123-3475
Rev. colomb. biotecnol vol.13 no.2 Bogotá July/Dec. 2011
ARTÍCULO DE INVESTIGACIÓN
Análisis de las polihidroxialcanoato sintasas (PhaC1 y PhaC2) en una cepa de Pseudomonas fluorescens IBUN S1602,aislada en suelos colombianos.
Analysis of polyhydroxyalkanoate synthases (PhaC1 and PhaC2) in a strain of Pseudomonas fluorescens IBUN S1602 isolated from Colombian soil.
Julieth Serrano Riaño1 , Luz Ángela Sastoque Rivera2 , Dolly Montoya Castaño3 , Nubia Moreno Sarmiento4
1Instituto de Biotecnología, Universidad Nacional de Colombia, Sede Bogotá. Grupo de Bioprocesos y Bioprospección. juliethse@hotmail.com
2Instituto de Biotecnología, Universidad Nacional de Colombia, Sede Bogotá. Grupo de Bioprocesos y Bioprospección. sastoque99@yahoo.com
3Instituto de Biotecnología, Universidad Nacional de Colombia, Sede Bogotá. Grupo de Bioprocesos y Bioprospección. dmontoyac@unal.edu.co
4Depto. Ingeniería Química y Ambiental - Facultad de Ingeniería. Instituto de Biotecnología, Universidad Nacional de Colombia, Sede Bogotá. Grupo de Bioprocesos y Bioprospección. ncmorenos@unal.edu.co
Recibido: septiembre 05 de 2011 Aprobado: noviembre 30 de 2011
Resumen
La cepa Pseudomonas fluorescens IBUN S1602 conforma el grupo de aislamientos provenientes de suelos colombianos de caña de azúcar, que acumula polihidrioxialcanoato (PHA), fue seleccionada como promisoria para escalamiento comercial por tener afinidad por sustratos alternativos y económicos como el glicerol, aceites usados, suero de leche, entre otros. Dada la importancia de la enzima sintasa en la síntesis de los PHAs, en el presente trabajo se realizó el análisis molecular de los genes phaC1 y phaC2 que codifican las enzimas sintasas tipo II (PhaC1 y PhaC2). Para la obtención de los amplímeros requeridos en la secuenciación, se utilizó la técnica de PCR bajo condiciones estandarizadas para iniciadores diseñados reportados en las bases de datos. Se identificaron dos fragmentos de 1680 pb y 1683 pb correspondientes a phaC1 y phaC2. El análisis comparativo de las secuencias proteicas resultantes de estos genes demuestra que la sintasa IBUN S1602 contiene la región α/β hidrolasa y 8 residuos de aminoácidos conservados, que son características de las sintasas examinadas a nivel mundial. Se analizó la estructura enzimática a nivel primario y se predijo la secundaria. Se concluyó que las sintasas de la cepa Pseudomonas fluorescens IBUN S1602 presentan alta homología con las sintasas tipo II que se reportan para Pseudomonas. Los resultados obtenidos contribuyen al entendimiento básico de la biosíntesis de PHA, la cual permitirá, en un futuro, el aumento de la calidad de PHA debida a la modulación del nivel de sintasa que se exprese en un organismo recombinante, con el fin de variar el peso molecular del biopolímero, propiedad esencial en el estudio de aplicaciones industriales.
Palabras clave: polihidroxialcanoatos, PHA sintasa, bioinformática, biopolímero, PhaC1, PhaC2.
Abstract
The strain Pseudomonas fluorescens IBUN S1602 forms the group of isolates from colombian sugarcane soil´s, which accumulates polyhydroxyalkanoate biopolymer (PHA) and was selected as promising for commercial scale by having affinity for economic and alternative substrates such as glycerol, oils, whey, among others. Given the importance of the synthase enzyme in the synthesis of PHAs, was realized the molecular analysis of genes phaC1 and phaC2 which encode type II synthases (PhaC1 y PhaC2). To obtain the amplimers required in the sequencing, was used the PCR technique under standardized conditions for primers designed based on the updated review in databases. Were identified two fragments of 1680 bp and 1683 bp for phaC1 and phaC2. Comparative analysis of the resulting protein sequences of these genes shows that the IBUN S1602 synthases containing the region α/β hydrolase and 8 conserved amino acid residues that are characteristic of synthases examined worldwide. Enzyme structure was analyzed at the primary level and was predicted the secondary. It is concluded that synthase strain Pseudomonas fluorescens IBUN S1602 has high homology with type II synthases that are reported for Pseudomonas. The results contribute to basic understanding of the biosynthesis of PHA, and will allow in the future, increasing the quality of PHA due to modulation of the level of synthase is expressed in a recombinant organism, in order to vary the weight molecular biopolymer, an essential property in the study of industrial applications.
Key words: polyhydroxyalkanaotes, PHA synthase, bioinformatics, biopolymer, PhaC1, PhaC2.
Introducción
Los biopolímeros de tipo polihidroxialcanoato (PHAs) son una alternativa a los polímeros de origen petroquímico (derivados del petróleo). Tienen aplicaciones en los sectores doméstico, industrial, médico y de construcción, convirtiéndose en un material imprescindible en la época actual (Dobroth et al., 2011; Posada et al., 2011; Anderson y Dawes, 1990), con la ventaja de ser biodegradados a dióxido de carbono y agua en condiciones aerobias, a los pocos meses de uso (Boskhomdzhiev et al., 2010; Braunegg et al., 1998; Weng et al., 2011;).
Las especies pertenecientes al género Pseudomonas acumulan PHAs de cadena media (6-14 carbonos) que presentan propiedades elastoméricas de interés en aplicaciones médicas especialmente (Chardron et al., 2010; Marchessault et al., 2011; Rai et al., 2011). Se caracterizan por contener dos genes diferentes, phaC1 y phaC2, que codifican una clase de sintasa tipo II (De Eugenio et al., 2010; Slawomir et al., 2011). Para la producción del biopolímero solo se necesita la expresión de uno de los genes (Rehm, 2007).
El cluster en la producción de PHAs de cadena media posee seis genes de los cuales dos genes phaC (phaC1 y phaC2) codifican PHA sintasas de clase II y están separados por el gen phaZ que codifica para un PHA depolimerasa intracelular (De Eugenio et al., 2007). Además, corriente abajo de estos genes está localizado el gen phaD (codifica para una proteína estructural que estabiliza los gránulos PHA) seguido por los genes phaI y phaF que se transcriben en dirección opuesta al resto de los genes y codifican proteínas estructurales y reguladoras (Arias et al., 2008; Olivera et al., 2010; Rehm, 2003; Sandoval et al., 2007).
La enzima PhaC sintasa es indispensable en la biosíntesis de PHA. Su función es tomar las unidades R-3 hidroxiacil-CoA y formar el polímero (Olivera et al., 2001; Rehm, 2007; Rehm, 2006; Stubbey Tian, 2003). La sintasa se divide en cuatro clases según su afinidad por sustratos de diferentes átomos de carbono. La clase II tiene afinidad por sustratos con cinco carbonos o más unidades en su estructura. Las sintasas presentan las principales características de la súper familia α/β hidrolasa: la triada catalítica posee en el sitio activo una serina, cisteína o aspartato; presenta un aminoácido acídico entre asparto o glutamato e incluye histidina (Wahab et al., 2006; Rehm, 2003).
Rehm, en 2007, explica que en la comparación de los alineamientos de 88 genes de sintasas provenientes de 68 bacterias diferentes se encuentra la presencia de 6 bloques conservados de acuerdo con la similaridad de los aminoácidos. De otro lado, la región N-terminal es altamente variable. Se destaca la identificación de 8 residuos de aminoácidos idénticos y presentes en todas las sintasas que se compararon.
En la actualidad, la principal limitante para la producción de los PHAs, a nivel comercial, radica en el costo del producto final frente a los plásticos petroquímicos. El uso de organismos genéticamente modificados hace parte de las principales estrategias que utilizan las empresas de mayor trascendencia en el mercado de los PHAs y es tema de estudio de los principales grupos de investigación (García et al., 2004; Choi et al., 1998; Hein et al., 1997). El conocimiento de los genes de síntesis y enzimas asociadas a la estabilización del gránulo de PHAs es imprescindible para llevar a cabo la manipulación genética de las células de interés. .
Por ello el objetivo del presente trabajo se centró en la determinación de la organización de los genes phaC1 y phaC2 en la cepa nativa Pseudomonas fluorecens IBUN S1602, escogida como promisoria por la capacidad que poseen sus enzimas sintasas de utilizar sustratos económicos como el glicerol, aceites usados, suero de leche , entre otros, a la vez se realizó el análisis a nivel de estructura primaria y secundaria de la enzima sintasa, para de esta manera poder contribuir con el entendimiento básico de la biosíntesis de PHA en esta cepa, que permitirá el aumento de la calidad de PHA debida a la modulación del nivel de sintasa que se exprese en un organismo recombinante, con el fin de variar el peso molecular del biopolímero, propiedad esencial en el estudio de aplicaciones industriales.
Materiales y métodos
Microorganismos y condiciones de crecimiento
Se emplearon dos cepas de Pseudomonas como control positivo: Pseudomonas fluorecens IBUN 066 y Pseudomonas aeruginosa ATCC 1040. La cepa Clostridium sp IBUN 13A se tomó como control negativo. La cepa IBUN S1602 proviene de cultivos de caña de azúcar colombiana, en la región de Norte de Santander, y se mantiene por criopreservación. Todos los aislamientos empleados fueron proporcionados por el Instituto de Biotecnología de la Universidad Nacional de Colombia. En estudios previos del grupo de investigación (Moreno et al., 2004 y 2007;). Se verificó la acumulación de polihidroxialcanoato por tinción con sudán negro, prueba de hipoclorito y gravimetría. Las cepas se activaron en caldo nutritivo de 12 a 24 horas a 30°C, se sembró por agotamiento en agar nutritivo de 12 a 24 horas a 30°C. Se verificaron las características morfológicas por medio de tinción de Gram, y la acumulación de PHA se comprobó mediante el crecimiento en un medio mínimo de sales minerales (MSM) ajustado a pH 7,0 (Ramsay et al., 1990).
Identificación de la cepa IBUN S1602
Se utilizaron dos metodologías para la identificación: a) por sus propiedades bioquímicas y b) mediante la amplificación del gen que codifica para ADN ribosomal 16s. Para la caracterización bioquímica se utilizó la coloración de Gram, la siembra en agares selectivos y diferenciales (Mac-Conkey, Cetrimide, KingB) y la prueba de oxidasa. La amplificación del gen ribosomal 16s RNA se realizó a partir de 20 ng de ADN, bajo las siguientes condiciones de la reacción en cadena de la polimerasa, PCR: un ciclo de 10 min a 94 °C, 2 min a 59 °C y 2 min a 72 °C; 30 ciclos de 1 min a 95 °C, 1 min a 56 °C y 1 min 30 seg a 72 °C, y un ciclo de extensión final de 5 min a 72 °C. Cada 25 μl de reacción contenían: Buffer 1X, dNTPs 0,8 mM, 0,4 μM de cada iniciador, MgCl2 1,5 mM y 0,05 U/μl de Taq ADN Polimerasa. Los iniciadores que se emplearon fueron: iniciador sentido 5´GATCATGGCTCAGATTGAACG3´, iniciador antisentido 5´GTTCCCCTACGGCTACCTTG 3´ (Uribe, 2009). La secuencia parcial del gen 16S ARNr fue ensamblada por el programa Cap3, se utilizó ClustalW2 para realizar un alineamiento múltiple con secuencias de referencias obtenidas a partir de la base de datos del Genbank, y a partir de dicho alineamiento se elaboró un dendrograma con el programa MEGA 4.0 utilizando el método de agrupamiento Neighborg Joning con 500 repeticiones- bootstrap.
Construcción de iniciadores
Para los genes phaC1 y phaC2 se recuperó 21 secuencias de dos bases de datos para nucleótidos: servidor Entrez en NCBI (http://www.ncbi.nlm.nih.gov/Entrez) y el portal de búsqueda de European Bioinformatics Institute, EBI a través del Sistema de Recuperación de Secuencias, SRS (http://srs.ebi.ac.uk). Los números de acceso al Genbank de los microorganismos que se incluyeron en el diseño son: Pseudomonas chlororaphis subs aurefaciens (AB049413), Pseudomonas putida (AF150670.2), Pseudomonas aeruginosa LESB58 (NC_011770), Pseudomonas aeruginosa PAO1 (NC_002516.2), Pseudomonas entomophila L48 (NC_008027), Pseudomonas aeruginosa PA7 (NC_009656), Pseudomonas sp GI-3 (AB014758), Pseudomonas corrugata CFBP5454 (AY910767), Pseudomonas mediterránea CFBP5447 (AY910768.1), Pseudomonas sp USM4-55 (EU275728), Pseudomonas pseudoalcaligenes 45L (AY043314.1), Pseudomonas putida KT2440 (AY113181), Pseudomonas putida KTCC1639 (AY286491.1), Burkholderia caryophylli (AF394660), Pseudomonas stutzeri 1317 (AY278219.1), Pseudomonas corrugata (EF067339.1), Pseudomonas resinovorans (AF129396.2), Pseudomonas nitroreducens 0802 (AF336849), Pseudomonas putida CA-3 (AY714618.1), Pseudomonas sp KBOS17 (AY790329), Pseudomonas fluorecens (FJ472656.1).
Las secuencias de nucleótidos se alinearon con el programa de licencia libre CLUSTALW2 dispuesto en la página web de EBI (http://www.ebi.ac.uk/Tools/clustalw2). Se identificaron los bloques conservados y se diseñaron de forma manual los iniciadores para cada gen, de acuerdo con criterios establecidos. Se realizó un análisis de similitud con las bases de datos de GenBank, usando el algoritmo BLASTN (http://blast.ncbi.nlm.nih.gov/Blast.cgi) y la opción de MEGABLAST con el fin de observar la especificidad y su sitio de unión en el gen. Las propiedades de los iniciadores se obtuvieron mediante el programa CLC Main Work bench 5.1 (http://www.clcbio.com).
Detección y amplificación de los genes phaC1 y phaC2 en el aislamiento IBUN S1602 mediante reacción en cadena de la polimerasa (PCR)
La extracción y cuantificación de ADN se realizó con uso de solventes orgánicos y lavados con CTAB según los protocolos de Sambrook et al. (1989). Se cuantificó por fluorometría en kit Quant ITTM (Invitrogen).
Se optimizó la PCR con un volumen total de 25 ml y se estandarizó con diferentes concentraciones de los reactivos, hasta obtener un único fragmento de ADN de la intensidad y tamaño esperado: 0,05 U/ml Taq ADN Polimerasa (Fermentas); buffer1X (Fermentas) complementado con 20 mM de sulfato de amonio; 0,2 mM de dNTPs; 3% de DMSO; iniciadores 0,7 μM; MgCl2 a 1,5 mM; ADN molde a 50 ng y 25 ng para el fragmento (JY2s/JY3a). El protocolo general de amplificación se realizó en un equipo Labnet- Multigene: 1 ciclo inicial a 94 °C por 10 min, 61,8 °C por 2 min, y 72 °C por 2 min, 30 ciclos a 94 °C por 1 min, 58,8 °C por 1 min, y 72 °C por 1,5 min y 1 ciclo final a 72 °C por 5 min.
Visualización de los productos de PCR
Los amplímeros de PCR fueron separados por electroforesis convencional en geles de agarosa 1,5% (w/v) con TBE 0.5X y comparados con marcadores de tamaño conocido de la serie Hyperladder (Bioline): II (50-200 pb), III (500-5000 pb). Se usó SYBR® Safe (Invitrogen) para visualizar los fragmentos de ADN. Los geles se digitalizaron en el equipo Gel Doc® con software Quantity One® (Biorad). La secuenciación se realizó en las dos hebras de ADN a través de la empresa Macrogen (Corea). Todos los fragmentos se secuenciaron por duplicado y se hizo un sobrelapamiento de secuencias resultantes de acuerdo con los iniciadores utilizadores.
Análisis de secuencias
Se utilizaron los programas BIOEDIT (http://www.mbio.ncsu.edu/BioEdit/bioedit.html) y CAP3 (http://pbil.univ-lyon1.fr/cap3.php) en el ensamblaje de secuencias. Se realizó depuración de forma manual a partir de alineamientos múltiples sucesivos con el programa CLUSTALW2 (http://www.ebi.ac.uk/Tools/Clustalw2/index.html).
Se buscó marcos abiertos de lectura (ORF) de acuerdo con la aplicación NCBI/ORF FINDER (http://www.ncbi.nlm.nih.gov/projects/gorf/). Las secuencias traducidas de cada ORF resultante se compararon con las secuencias que se reportan en las bases de datos mediante BLASTP (http://blast.ncbi.nlm.nih.gov/Blast.cgi). Se realizó alineamiento múltiple CLUSTALW2 con secuencias curadas de los siguientes microorganismos: Pseudomonas chlororaphis subs aurefaciens (AB049413), Pseudomonas putida (AF150670.2), Pseudomonas aeruginosa LESB58 (NC_011770), Pseudomonas aeruginosa PAO1 (NC_002516.2), Pseudomonas entomophila L48 (NC_008027), Pseudomonas fluorescens Pf0-1 (NC_007492.2). Se identificó motivos o perfiles estrictamente conservados en las secuencias traducidas a proteínas (PhaC1 y PhaC2).
Las distancias filogenéticas de las secuencias obtenidas con respecto a las familias de proteínas que se reportan en las bases de datos y la función de dicha familia se determinó mediante PSI- BLAST (http://www.ebi.ac.uk/Tools/psiblast/). Se buscó dominios proteicos con la ayuda de CDD (Conserved Domains Database) a través de la aplicación RPS-BLAST (http://www.ncbi.nlm.nih.gov/Structure/cdd/wrpsb.cgi). Se realizó la predicción de las estructuras secundarias con el programa PSIPRED (http://bioinf.cs.ucl.ac.uk/psipred). Todas las herramientas bioinformáticas que se utilizaron, se desarrollaron con los parámetros predeterminados.
Resultados y discusión
Una vez cultivada la cepa IBUN S1602 en caldo nutritivo, se observaron las características morfológicas (bacilos Gram negativos); en agar Mc-Conkey se observaron colonias no fermentadoras, la prueba de oxidasa fue negativa. Se observó crecimiento en el agar cetrimide (colonias redondas verdosas regulares) y en el agar King B, que estimula la producción de fluoresceína, se observó crecimiento y una clara fluorescencia a las 48 horas de incubación a 30 °C lo cual es típico del género Pseudomonas, especie fluorecens, por lo que se concluyó que bioquímicamente la cepa IBUN S1602 corresponde a Pseudomonas fluorecens, siendo consistente con los resultados preliminares de pruebas bioquímicas. Posteriormente, para la caracterización molecular se amplificó una secuencia aproximada de 1500 pb, se realizó un Dendrograma de similitud construido por el método de agrupamiento de Neigbour Joining con las secuencias seleccionadas anteriormente (figura 1). Las secuencias se ubicaron en tres clusters, un primer cluster corresponde a las bacterias del género Pseudomonas: P. aeruginosa, P. chlororaphis, P. fulva, P. stutzeri y P. aurantiaca a excepción de P. putida y P. fluorencens que se ubicaron externas a este grupo. En el primer cluster se agruparon las especies del género Burkholderia que se relacionan estrechamente con Pseudomonas.

En un estudio realizado por Revelo en el 2007, el aislado S1602 fue considerado como perteneciente al género Burkholderia, sin embargo en el mismo se recomienda comprobar dicho resultado. En el presente estudio se comprobó tanto bioquímica como molecular mente que el aislado S1602 corresponde a una cepa Pseudomonas fluorecens.
De acuerdo con la revisión del gen sintasa tipo II en las bases de datos, se identificó que Pseudomonas presenta una organización del tipo phaC1ZC2DFI. En la figura 2 se observa la ubicación de los iniciadores que se utilizaron en el presente trabajo: JY2s (5´GGACAAYGGAGCGTYGTAGATGAGT3´) y JY3a (5´TGGCRCCKATGCCGTTGAAGATC3´); JY1s (5´GACTCSTGGTGGYTGCACTGGCAG3´) y JY4a (5´GGCTTGTACTGGATCAGCTCCARCA3´); JY4s (5´TGYTGGAGCTGATCCAGTACAAGCC3´) y JY6a (5´ACGATMAGGTGCAGGAACAGCCAGT3´).

Debido a la estandarización del proceso en la amplificación de los genes, a través de PCR se modificó el protocolo propuesto con los siguientes cambios: MgCl2 a 2.0mM (JY4s/ JY6a). La temperatura de anillamiento de la segunda etapa se incrementó a 60 °C (JY4s/JY6a) y a 61 °C (JY1s/JY4a).
Ensamblaje de secuencias y análisis bioinformático
Se obtuvo el siguiente resultado del ensamblaje de las secuencias y la transcripción de las mismas.
>IBUN S1602 PhaC1 MSNKSNDECPYQASETTLGLNPVVGLRGKDLLASARMVVTHAITQRIHSVKQITLFGIDLKNVLFGKSKLQPAGDDRRFVDPAWSQNPLYKRYLQTYLAWRKELHAWIDDSSLSPKDIARGHFVINLMTEAMAPTNTAANPAAVKRFFETGGKSLLDGLSHLAKDLVHNGGMPSQVNMGAFEVGKTLGVSEGSVVFRNDVLELIQYKPITEQVHERPLLVVPPQINKFYVFDLSPDKSLARFCLRNNVQTFIVSWRNPTKEQREWGLSTYIEALKEAVDVVTAITGSKDVNMLGACSGGITCTALLGHYAATGENKVNALTLLVSVLDTTLDSDVALFFDEQTLEMTKRHSYQAGVLEGKDMAKVFTWMRPNDLIWNYWVNTYLLGNEPPVFDILFWNKDTTRAPAMFHGDLIEMFKNKPLTLPDALEECGTPINLKKGSPEIFSLADATDHTSPWKSCYKSAQPFCGKVEFLLSSTGHIQSILNPPGNPKSRDTTSEEKTAKIDDWQKKSTKHADSWRLPWQAWQGERSGELKKAPRKLGSTGYLAGESSPGALVHAR
>IBUN S1602 PhaC2
MRDKPATGVVPSPAVFINAQSAMTGLRGRDLISTLRSVAAHGLRNPIHSAKHALKLGGALGRVLLGETLHPTNPNDSRFADPAWSLNPFYRRSLQAYLSWQKQVKSWIDESSMSDDDRARAHFAFSLINDAVAPSNTLLNPLAIKELFNSGGHSLVRGLSHLFDDLLHNDGLPRQVTKQAFEVGKTVATTTGSVVFRNELLELIQYKPMSEKQYSKPLLVVPPQINKYYIFDLSPSNSFVQFALKNGLQTFMISWRNPDVRHREWGLSTYVEAVEEAMNICRAITGAREVNLMGACAGGLTIAALQGHLQAKRQLRRVSSATYLVSLLDSQIDSPATLFADEQTLEAAKRRSYQKGVLDGRDMAKVFAWMRPNDLIWSYFVNNYLLGKEPPAFDILYWNNDSTRLPAAFHGDLLDFFKHNPLIHPGGLEVCGTPIDLQKVTVDSFSVAGMNDHITPWDAVYRSTLLLGGERRFVLSNSGHVQSILNPPSNPKATYVENGKLSSDPRAWYYDAKKVDGSWWPQWLEWVQQRSGTLRETQMALGNANYPPMEAAPGTYVRVR
Análisis de la estructura primaria para los genes phaC1 y phaC2
El gen phaC1 tiene 1680 pb con una secuencia deducida de 559 aminoácidos y el gen phaC2 presenta 1683 pb con 560 aminoácidos. El análisis de BLASTP comprobó que la proteína PhaC1 y PhaC2 de la cepa Pseudomonas fluorecens IBUN S1602 presentan un alto grado de similaridad con las reportadas en las bases de datos para sintasa. El 50% de las coincidencias correspondieron a la proteína sintasa I y II respectivamente, principalmente del género Pseudomonas (48/50). Se observó un porcentaje de identidad de 70 a 88 % para PhaC1 y de 71 a 96% para PhaC2, con un E-value de 0,0 y de 100% de área de cubrimiento de secuencia para PhaC1 en todos los registros y 97% para PhaC2 en 2 coincidencias y 100% en el restante.
En el alineamiento que se realizó de la secuencia de PhaC1, se observó que la proteína de cepa IBUN S1602 presenta los 8 residuos estrictamente conservados (S229; C287; G290; D319; W388; D442; G469; H470) que reporta la literatura (Rehm, 1993; Rehm, 2007). También se identificó la secuencia del motivo denominado caja lipasa [GA (C) SG], que es característica de las sintasas. Se encontró el cambio que reporta la literatura de serina por cisteína en la caja lipasa [GX(C) XG] (Amara y Rehm, 2003; Jiang et al., 2004) (figura 3 ). Para la secuencia PhaC2 se encontraron idénticos resultados que para la sintasa I (PhaC1), con excepción en el motivo de la caja lipasa, en donde la serina posterior a la cisteína es reemplazada por una alanina [GA (C) AG] (figura 4 ). Lo anterior representa un cambio entre un aminoácido de tipo polar por uno de tipo apolar. No se encontró evidencias experimentales que comprueben la función de estos aminoácidos en la caja lipasa.


Hasta la fecha no se tiene evidencia suficiente que permita inferir la función exacta de los 8 residuos conservados. Sin embargo, se teoriza que la triada catalítica compuesta de Cys-Asp-His se encuentra en el núcleo de la estructura de todos los modelos tridimensionales generados para la PHA sintasas. Aunque para la estructura terciaria de las sintasas solo se ha obtenido por simulación con otras proteínas (no se ha realizado cristalografía), sí se conoce la función por mutaciones dirigidas de cada aminoácido de la triada, por lo que se afirma que el aminoácido que realiza la función catalítica es la cisteína, y que el ácido aspártico y la histidina le dan estabilidad al complejo. Se conoce también el papel del triptófano que actúa directamente en la interacción proteína-proteína (Amara y Rehm, 2003; Jia et al., 2000; Muh et al., 1999; Nomura y Taguchi, 2007; Nuttawee et al., 2004; Rehm et al., 2002; Wodzinska et al., 1996).
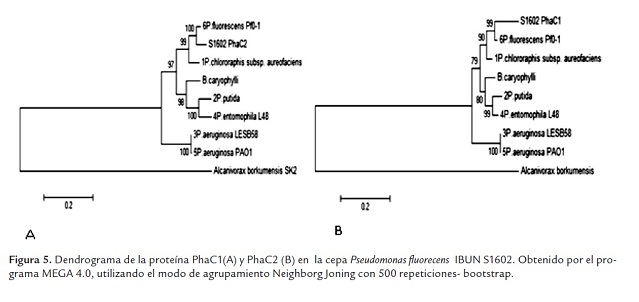
Para realizar una aproximación filogenética de las proteínas PhaC1 y PhaC2 que codifican para sintasa tipo I y II respectivamente, se realizó un alineamiento múltiple con CLUSTALW2, con secuencias de 6 cepas curadas y tomadas como referencia del GenBank (ver materiales y métodos). Se incluyó una cepa que posee sintasa tipo I (Burkholderia caryophylli /AF394660.1) y una cepa con sintasa tipo III (Alcanivorax borkumensis /YP_693138.1) control externo. Se observa en la figura 5 que la cepa IBUN S1602 se agrupa con Pseudomonas fluorecens con un puntaje de 99% para PhaC1 y de 100% para PhaC2. Lo que indica que las proteínas PhaC1 y PhaC2 de la cepa nativa IBUN S1602 tienen gran porcentaje de identidad con la cepa de referencia Pseudomonas fluorecens Pf0-1.
Se analizaron las secuencias PhaC1 y PhaC2 correspondientes en busca de dominios proteicos que revelan la familia a la que pertenece; se encontraron en las dos secuencias la presencia de dos dominios conservados, el primero (phaC_N) correspondiente a la superfamilia (pfam07167), que representa la región N- terminal de los microorganismos que producen polihidroxialcanoatos; la PhaC une monómeros de 3-hidroxibutiril-CoA para crear polímeros por la formación de un enlace ester, aunque la región N-terminal de esta enzima no es muy estudiada sí se han hecho estudios en donde se realizaron deleciones de este segmento, demostrando que la composición del polímero se ve afectada ya que esta región puede estar relacionada con la especificidad del sustrato, esto se puede deber al cambio de configuración de la enzima que afecta directamente la relación con el sustrato, además se observa un cambio de polaridad que contribuye al mismo fenómeno (Ziqiang et al., 2007). El segundo dominio conservado encontrado, corresponde a la superfamilia de las α/β hidrolasas (pfam00561), que involucra la función de la catálisis covalente, dos grupos tiol provistos por los residuos conservados de la cisteína; esta familia conserva la triada catalítica compuesta por (Cys-Asp-His) en donde la cisteína cumple el papel del aminoácido catalítico y el aspartato y la histidina dan estabilidad a la unión de la proteína al sustrato. También se muestran los multidominios pertenecientes a los tres tipos de sintasa, lo que es coherente ya que estas son similares entre sí y cumplen la misma función (Akon et al., 2004; Amara y Rehm, 2003; Arpigny y Jaeger, 1999; Stubbe et al., 2003; Wahab et al., 2006).
Análisis de la predicción estructura secundaria para los genes phaC1 y phaC2
El plegamiento regular de los aminoácidos dentro de la cadena polipeptídica forma la estructura secundaria de las proteínas. Se adopta gracias a la formación de enlaces de hidrógeno entre las cadenas laterales (radicales) de aminoácidos cercanos en la cadena, los métodos de predicción de estas estructuras se basan en el alineamiento múltiple de las sintasas; se reporta que al menos el 72% de ellas poseen (39,9%) de α- hélice, (10,4%) de β-plegada y (49,7%) de giros variables, sin embargo la evidencia experimental muestra ligeros cambios entre las sintasas en cuanto a este tipo de estructura, por ejemplo Pseudomonas sp USM 4-55 presenta un 41,3% de α- hélice, un 12,4% de β-plegada y (46.3%) de giros variables, por lo tanto se sugiere que las sintasas tengan una estructura mixta entre ellas respecto a la predicción de la estructura secundaria (Rehm, 2003). La región correspondiente al dominio de las α/β hidrolasas no presenta ningún patrón establecido de α- Helice y de β-plegada (Wanab et al., 2006).
Los resultados de este análisis, mostraron que la secuencia de PhaC1 presentó un 49,2% de α- hélice, 11,4% de β-plegada y 39,2 % de giros variables, y la secuencia PhaC2 presentó un 52,3% de α- hélice, 12,7 % de β-plegada y 34,9 % de giros variables, a la vez en las dos secuencias la caja lipasa no presentó una conformación establecida acorde con lo reportado; se observó que la región del aminoácido 1 aproximadamente hasta el aminoácido 170 no presentó ninguna representación de β-plegada, se buscó en la literatura y se observó el mismo fenómeno (Wanab et al., 2006). Aunque se conservó la tendencia en los porcentajes representados, en su mayoría por α- hélices, se observaron ciertas diferencias en la predicción de la estructura secundaria entre las sintasas (PhaC1, PhaC2), y con las sintasas de otros microorganismos según lo observado en la literatura; esto se puede atribuir a que estas enzimas a pesar de presentar una especificidad a cierto tipo de sustratos, estos sustratos son amplios, sugiriendo que los ligeros cambios le dan cierta flexibilidad requerida para ajustar su estructura al sustrato (figura 6 y 7).


Conclusiones
Se logró identificar la cepa IBUN S1602 como Pseudomonas fluorescens por medio de pruebas moleculares y bioquímicas, a su vez se determinó que los análisis de la estructura primaria y secundaria tienen concordancia con lo que se reporta en la literatura para este tipo de enzimas, como la presencia de los ocho residuos conservados para las sintasas (S229; C287; G290; D319; W388; D442; G469; H470) y de la caja lipasa como característica primordial de la familia de las α/β hidrolasas; se mostró también que en la estructura secundaria hay ligeros cambios entre ellas y con las reportadas, lo que sugiere que dichos cambios le dan esa flexibilidad requerida por ser tan versátiles a tan múltiples sustratos. La maquinaria genética, en cuanto a las sintasas se refiere de esta cepa, es muy similar a las reportadas, lo que indica que en cuanto a formación de las sintasas y su posterior producción de PHA puede ser utilizada en una cepa recombinante en estudios posteriores.
Agradecimientos
El presente trabajo se realizó en el grupo de Bioprocesos y Bioprospección y contó con el apoyo de los laboratorios de Microbiología, Fermentaciones, Caucho, Virus Vegetales, Epidemiología Molecular y Biopesticidas del Instituto de Biotecnología de la Universidad Nacional de Colombia.
Referencias bibliográficas
1 Akoh, C., Lee, G., Liaw, Y., Huang, T., Shaw, J. 2004. GDSL family of serine esterases/lipases. Progress in Lipid Research. 43(6):534-552. [ Links ]
2 Amara, A., Rehm, B. 2003. Replacement of the catalytic nucleophile Cys-296 by serine in class II polyhydroxyalkanoate synthase from Pseudomonas aeruginosa mediated synthesis of a new polyester: identification of catalytic residues. Biochemical Journal. 374: 413-421. [ Links ]
3 Anderson, A., Dawes, E. 1990. Occurrence, metabolism, metabolic role, and industrial uses of bacterial polyhydroxyalkanoates. Microbiological reviews. 54(4):450-472. [ Links ]
4 Arias, S., Sandoval, A., Arcos, M., Canedo, LM., Maestro, B., Sanz, JM., Naharro, G., Luengo JM .2008. Poly-3-hydroxyalkanoate synthases from Pseudomonas verificar) putida U: substrate specificity and ultrastructural studies. Microbial Biotechnology .1(2):170-176. [ Links ]
5 Arpigny, J., Jaeger, K. 1999. Bacterial lipolytic enzymes: classification and properties Biochemical Journal.343:177-183. [ Links ]
6 Boskhomdzhiev, A., Bonartsev, A., Makhina, T., Myshkina, V., Ivanov, E., Bagrov, D., Filatova, E., Iordanskii, A., Bonartseva, G. 2010. Biodegradation kinetics of poly(3_hydroxybutyrate) based biopolymer systems. Biochemistry Supplement Series B: Biomedical Chemistry. 4(2): 177-182. [ Links ]
7 Braunegg, G., Lefebvre, G., Genser, K. 1998. Polyhydroxyalkanoates, biopolyesters from renewable resources: physiological and engineering aspects. Journal of Biotechnology. 65:127-161. [ Links ]
8 Chardron, S., Bruzaud, S., Lignot, B., Elain, A., Sire, O. 2010. Characterization of bionanocomposites based on medium chain length polyhydroxyalkanoates synthesized by Pseudomonas oleovorans, Polymer Testing. 29: 966-971. [ Links ]
9 Choi, J., Lee, S., Han, K. 1998. Clonning of the Alcaligenes latus polyhydroxyalkanoate biosynthesis genes and use of these genes for enhanced production of poly(3hydroxybutyrate) in Escherichia coli. Applied and Environmental Microbiology. 64: 4897-4903. [ Links ]
10 De Eugenio, LI., García, P., Luengo, JM., Sanz, JM., San Roman, J., García, JL., Prieto, MA. 2007. Biochemical evidence that phaZ gene encodes a specific intracellular medium-chain-length polyhydroxyalkanoate depolymerase in Pseudomonas putida KT2442 - Characterization of a paradigmatic enzyme. The Journal of Biological Chemistry. 282(7):4951-4962. [ Links ]
11 De Eugenio, L., Escapa, I., Morales, V., Dinjaski, N., Galán, B., García, J., Prieto, M. 2010. The turnover of medium-chain-length polyhydroxyalkanoates in Pseudomonas putida KT2442 and the fundamental role of PhaZ depolymerase for the metabolic balance. Environmental Microbiology. 12(1): 207-221. [ Links ]
12 Dobroth, Z., Hu, S., Coats, E., McDonald, A. 2011. Polyhydroxybutyrate synthesis on biodiesel wastewater using mixed microbial consortia. Bioresource Technology. 102: 3352-3359. [ Links ]
13 García, B., Olivera, E., Sandoval, A., Barrau, E., Arias, S., Naharro, G., Luengo, J. 2004.Strategy for cloning large gene assemblages as illustrated using the phenylacetate and polyhydroxyalkanoate gene clusters. Applied and environmental Microbiology. 70(8):5019-5025. [ Links ]
14 Hein, S., Söhling, B., Gottschalk, G., Steinbüchel, A. 1997. Biosynthesis of poly (4-hydroxybutyric acid) by recombinant strains of Escherichia coli. Federation of European Microbiological Societies Microbiology Letters. 153:411-418. [ Links ]
15 Jia, Y., Kappock, T., Frick, T., Sinskey, A., Stubbe, J. 2000. Lipases provide a new mechanistic model for polyhydroxybutyrate (PHB) synthases: characterization of the functional residues in Chromatium vinosum PHB synthase. Biochemistry. 39:3927-3936. [ Links ]
16 Jiang, Y., Ye, J., Wu, H., Zhang, H. 2004. Cloning and expression of the polyhydroxyalkanoate depolymerase gene from Pseudomonas putida, and characterization of the gene product. Biotechnology Letters. 26:1585-1588. [ Links ]
17 Marchessault, R., Dou, H., Ramsay, J. 2011. Microbial medium chainlength poly[(R)-3-hydroxyalkanoate] shows liquidcrystal behaviour. International Journal of Biological Macromolecules. 48: 271-275. [ Links ]
18 Moreno, L., Forero, M. 2004. Biosíntesis de polímeros biodegradables del tipo poli-b-hidroxialcanoatos (PHAs) a partir de cepas nativas. Trabajo de Grado. Facultad de Ingeniería. Departamento de Ingeniería Química. Universidad Nacional de Colombia. Bogotá, D.C. Colombia. [ Links ]
19 Moreno, N., Gutiérrez, I., Malagón, D., Grosso, V., Revelo, D., Suárez, D., González, J., Aristizábal, F., Espinosa, A., Montoya, D. 2007. Bioprospecting and characterization of poly-bhydroxyalkanoate (PHAs) producing bacteria isolated from Colombian sugarcane producing areas. African Journal of Biotechnology. 6(13):1536 -1543. [ Links ]
20 Muh, U., Sinskey, A., Kirby, D., Stubbe, J. 1999. PHB synthase from Chromatium vinosum: cysteine 149 is involved in covalent catalysis. Biochemistry. 38:826-837. [ Links ]
21 Nomura, C., Taguchi, S. 2007. PHA synthase engineering toward super biocatalysts for custom-made biopolymers. Applied Microbiology and Biotechnology. 73:969-979. [ Links ]
22 Nuttawee, N., Soazig, D., Young-Rok, K., Carl, B. 2004. Engineering of Chimeric Class II Polyhydroxyalkanoate Synthases. Applied and Environmental Microbiology. 70(11): 6789-6799. [ Links ]
23 Olivera, E., Carnicero, D., García, B., Miñambres, B., Moreno, M., Cañedo, L., Concetta, C., DiRusso, Naharro, G., and Luengo, J., 2001. Two different pathways are involved in the b-oxidation of n-alkanoic and n-phenylalkanoic acids in Pseudomonas putida U: genetic studies and biotechnological applications. Molecular Microbiology. 39:863-874. [ Links ]
24 Olivera, E., Arcos, M., Naharro, G., and Luengo, J. 2010. Unusual PHA Biosynthesis. Plastic from Bacteria: Natural Functions and Applications. Edited by Chen, G. Microbiology Monographs. 14: 133‐186. [ Links ]
25 Posada, J., Naranjo, J., López, J., Higuita, J., Cardona, C. 2011. Design and analysis of poly-3-hydroxybutyrate production processes from crude glicerol. Process Biochemistry. 46: 310-317. [ Links ]
26 Ramsay, B., Lomaliza, K., Chavarie, C., Dubé, B., Bataille, P., Ramsay, J. 1990. Production of poly-(b-hydroxybutyric-co-b-hydroxyvaleric) acids. Applied and Environmental Microbiology. 56: 2093-2098. [ Links ]
27 Rai, R., Keshavarz, T., Roether, J.A., Boccaccini, A., Roy, I. 2011. Medium chain length polyhydroxyalkanoates, promising new biomedical materials for the future. Materials Science and Engineering. 72: 29-47. [ Links ]
28 Rehm, B., Antonio, R., Spiekermann, P., Amara, A., Steinbüchel, A. 2002. Molecular characterization of the poly (3-hydroxybutyrate) (PHB) synthase from Ralstonia eutropha: in vitro evolution, site-specific mutagenesis and development of a PHB synthase protein model. Biochimica et Biophysica, Acta.1594:178-190. [ Links ]
29 Rehm, B. 2003. Review Article. Polyester synthases: natural catalysts for plastics. Biochemical Journal. 376: 15-33. [ Links ]
30 Rehm, B. 2006. Genetics and biochemistry of polyhydroxyalkanoate granule self-assembly: The key role of polyester synthases. Biotechnology Letters.28: 207-213. [ Links ]
31 Rehm, B. 2007. Biogenesis of microbial polyhydroxyalkanoate granules: a platform technology for the production of tailor-made bioparticles. Current Issues in Molecular Biology. 9: 41-62. [ Links ]
32 Revelo, D., Grosso, M., Moreno, N., Montoya, D. 2007. A most effective method for selecting a broad range of short and medium chain- length polyhidroxyalcanoate producing microorganisms. Electronic Journal of Biotechnology. 10 (3): 348-35. [ Links ]
33 Sambrook, J., Fritsch, E., Maniatis, T. 1989. Molecular cloning. A laboratory manual. Cold Spring Harbor Laboratory, NY Second edition. Vol. 1, 2, 3. [ Links ]
34 Sandoval, A., Arias-Barrau, E., Arcos, M., Naharro, G., Olivera E., and Luengo J. 2007. Genetic and ultrastructural analysis of different mutants of Pseudomonas putida affected in the poly-3-hydroxy-n-alkanoate gene cluster. Environmental Microbiology. 9:737-751. [ Links ]
35 Slawomir, C., Justyna, M., Grzegorz, P. 2010. The influence of nitrogen limitation on mcl-PHA synthesis by two newly isolated strains of Pseudomonas sp. Journal of Industrial Microbiology and Biotechnology. 37:511-520. [ Links ]
36 Stubbe, J., Tian, J. 2003. Polyhydroxyalkanoate (PHA) homeostasis: the role of the PHA synthase. Natural Product Reports. 20: 445-457. [ Links ]
37 Uribe, D. 2009. Informe final de proyecto: "Evaluación de estrategias de control biológico para el manejo de Rhizoctonia solani y Spongospora subterranea en cultivos de papa". Ministerio de Agricultura y Desarrollo Rural y Asohofrucol. 78. [ Links ]
38 Wahab, H., Ahmad, Khairudin, N., Samian, M., Najimudin, N. 2006. Sequence analysis and structure prediction of type II Pseudomonas sp. USM 4-55 PHA synthase and an insight into its catalytic mechanism. BioMed Central Structural Biology. 6(23):2-14. [ Links ]
39 Weng, Y., Wang, X., Wang, Y. 2011. Biodegradation behavior of PHAs with different chemical structures under controlled composting conditions. Polymer Testing. 30: 372-380. [ Links ]
40 Wodzinska, J., Snell, K., Rhomberg, A., Sinskey, A., Biemann, K., Stubbe, J. 1996. Polyhydroxybutyrate synthase: evidence for covalent catalysis. Journal of the American Chemical Society. 118:6319-6320. [ Links ]
41 Wong, P., Chua, H., Lo, W., Lawford, H., Yu, P. 2002. Production of specific copolymers of polyhydroxyalkanoates from industrial waste. Applied Biochemistry and Biotechnology. 99: 641-654. [ Links ]
42 Ziqiang, Y., Ge, S., Guoqiang, C., Jingyu, C. 2007. Location of functional region at N-terminus of polyhydroxyalkanoate (PHA) synthase by N-terminal mutation and its effects on PHA synthesis. Biochemical Engineering Journal. doi:10.1016/j.bej.2008.03.006. [ Links ]

