










Serviços Personalizados
Journal
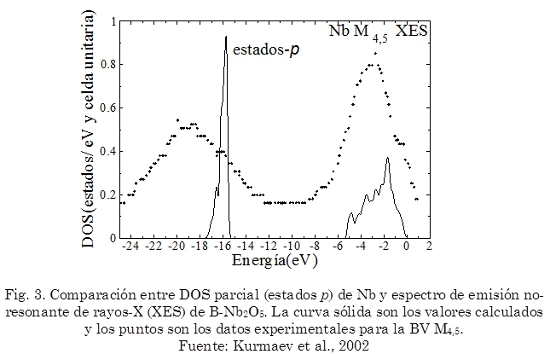
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkTecnoLógicas
versão impressa ISSN 0123-7799versão On-line ISSN 2256-5337
TecnoL. no.27 Medellín jul./dez. 2011
Artículo de Investigación/Research Article
Optimización de la Segmentación Local de Sauvola Aplicada a la Detección de Defectos Superficiales en Escenas con Iluminación No Homogénea
Jeyson Molina-Cortés1, Alejandro Restrepo-Martínez2, John W. Branch-Bedoya3
1Grupo de Investigación y Desarrollo en Inteligencia Artificial, Universidad Nacional de Colombia sede Medellín, Medellín-Colombia, jjmolinac@unal.edu.co
2Grupo de Investigación en Automática y Electrónica, Instituto Tecnológico Metropolitano, Medellín-Colombia, alejandrorestrepo@itm.edu.co
3Grupo de Investigación y Desarrollo en Inteligencia Artificial, Universidad Nacional de Colombia sede Medellín, Medellín-Colombia, jwbranch@unal.edu.co
Fecha de recepción: 15 de febrero de 2011 / Fecha de aceptación: 21 de septiembre de 2011
Resumen
La presencia de iluminación no homogénea en imágenes de escenas reales es un problema actual que dificulta la adecuada segmentación de estas. En este trabajo se presenta una metodología para la optimización de la segmentación local de Sauvola para la detección de defectos superficiales en imágenes no homogéneamente iluminadas ajustando sus parámetros mediante algoritmos genéticos. La metodología consta de estas etapas: Primero se plantea el problema desde la perspectiva de los algoritmos genéticos donde cada individuo de la población representa los valores para los parámetros de Sauvola. Luego, varias funciones de aptitud son propuestas utilizando métricas de comparación entre una segmentación de Sauvola y una realizada manualmente. Cada función es evaluada ejecutando el algoritmo genético utilizando esta en un subconjunto de imágenes. La mejor función de aptitud según los resultados de la optimización, es utilizada nuevamente en una muestra más grande. Finalmente, a los últimos resultados de optimización se les realiza un análisis de agrupamientos. Los resultados muestran que si es posible ajustar los parámetros de Sauvola para segmentar correctamente cada imagen pero estos no exhiben un agrupamiento hacia un punto específico que permita establecer unos parámetros únicos para segmentar todo el conjunto de imágenes con un alto desempeño.
Palabras clave: Segmentación, iluminación no homogénea, segmentación local de Sauvola, algoritmos genéticos, optimización.
Abstract
The presence of non-homogeneous illumination in real scenes images is an actual problem that difficult the correct segmentation of these. This paper presents a methodology for optimizing Sauvola local segmentation for the detection of superficial defects in non-homogeneous illuminated images by adjusting its parameters through genetic algorithms. The methodology consists of these stages: First, the problem is proposed from the perspective of genetic algorithms where each individual in the population represents the values for Sauvola's parameters. Then several fitness functions are proposed using comparison metrics between a Sauvola's segmentation and one performed manually. Each function is evaluated by running the genetic algorithm with it in a subset of images. The best fitness function, according to the results of optimization, is used again in a larger sample. Finally, the last optimization results are analyzed by a clustering analysis. The results show that it is possible to adjust Sauvola's parameters to successfully segment each image but these do not exhibit a tendency to a specific point that allow to suggest unique parameters to segment all images with a high performance.
Keywords: Segmentation, non-homogenous illumination, Sauvola local segmentation, genetic algorithms, optimization.
1. Introducción
La segmentación es un proceso fundamental en el análisis de una imagen, ya que permite separar los elementos de la misma que son relevantes de los que no lo son respecto a un problema particular según varias medidas o características visuales (color, contraste, brillo, etc.), reduciendo así la complejidad de este análisis. Lograr una segmentación deseada, puede llegar a ser una actividad complicada si la calidad de la imagen no es la apropiada. Esta situación se puede apreciar en imágenes que tienen una iluminación no homogénea la cual es un tipo de iluminación que varía a través de toda el área de la imagen generando cambios importantes que degradan la calidad de las imágenes.
Una de las aplicaciones prácticas en las que se puede utilizar segmentación es cuando se desea realizar algún proceso de inspección visual de forma automática a algún producto a partir de imágenes. Este tipo de aplicaciones es ampliamente visto en el sector industrial donde el control de calidad es crítico en el proceso de producción. En este trabajo se aborda un problema de inspección visual consistente en la detección de defectos superficiales en piezas de fabricación industrial a partir de imágenes tomadas de estas las cuales presentan problemas de iluminación no homogénea. Se requiere un alto grado de efectividad en la segmentación y la mala iluminación genera un importante obstáculo a ese objetivo. Es por eso que deben plantearse soluciones que sean robustas aun cuando las condiciones de iluminación no sean las ideales.
La no homogeneidad en la iluminación se puede presentar por varios factores en escenas reales, entre ellos, un sistema de iluminación que no está ajustado correctamente y otros casos donde la misma naturaleza del objeto al que se le toma la imagen tienen propiedades que contribuyen a que surja esta condición. Es el caso, por ejemplo, de objetos que tienen superficies altamente reflectantes que generan brillos y sombras. Esta situación hace que algunos algoritmos clásicos de segmentación, como algunos que actúan de manera global sobre la imagen, que no tienen un buen desempeño ya que no son sensibles a los cambios locales que se generan. Asimismo si se añaden otros problemas comunes como el ruido o el bajo contraste, la segmentación se ve más afectada llevando a casos en donde las regiones de interés no son completamente segmentadas (subsegmentación), o casos en donde se segmenta más de lo deseado (sobresegmentación).
Dentro de las diferentes técnicas de segmentación que se tienen en la literatura (Sezgin & Sankur, 2004; Gupta et al., 2007), se destacan las de umbralización local, las cuales actúan localmente en pequeñas partes de la imagen resultando en una imagen binaria que separa las regiones de interés del fondo. En este conjunto la segmentación de Sauvola (Sauvola & Pietaksinen, 2000) ha mostrado mejores resultados frente a otros algoritmos a la hora de segmentar imágenes con problemas de variabilidad en su iluminación (Gupta et al., 2007). Sin embargo, Sauvola disminuye su rendimiento cuando la imagen tiene bajo contraste o exceso de ruido. Por otro lado la calidad de la segmentación también está determinada por los valores que se le den a los parámetros con los que esta técnica funciona por lo que un ajuste de estos es necesario para tener una adecuada segmentación.
El ajuste de estos parámetros se puede abordar por medio de los algoritmos genéticos (Goldberg, 1989) los cuales son técnicas de búsqueda de un óptimo de forma estocástica usando mecanismos basados en la evolución biológica. Estos algoritmos constituyen una herramienta sólida y ampliamente utilizada para resolver problemas de optimización. Han sido aplicados exitosamente en varios problemas de distinta naturaleza (Chou & Ghaboussi, 2001; Shin & Lee, 2002; Jarvis & Goodacre, 2005). En visión por computador también han sido aplicados para resolver problemas de mejora de segmentación y similares (Jeon et al., 2002; Hamid et al., 2003; Tao et al., 2003). Su generalidad y buen desempeño hace que sean fácilmente adaptables a varios escenarios de optimización. Un factor importante en los algoritmos genéticos es determinar la función de aptitud, la cual determina que tan buena es cada solución y condiciona en gran medida el resultado final.
El objetivo de este trabajo consiste, primero, en ver, a partir de un conjunto de imágenes con iluminación no homogénea, cómo responde el algoritmo de Sauvola en relación a la detección de ciertas regiones de interés (defectos superficiales) y averiguar si existe un conjunto de valores para sus parámetros que optimicen la segmentación obtenida para cada una de estas (sin usar otros algoritmos auxiliares de preprocesamiento en la imagen que también implicarían un ajuste de sus parámetros); se utiliza una estrategia de optimización basada en algoritmos genéticos, para lo que se debe determinar una función de aptitud que permita obtener los parámetros óptimos para Sauvola; y segundo en analizar si estos valores obtenidos se agrupan en algún punto que permita determinar unos valores fijos que funcionen adecuadamente para todo el conjunto de imágenes analizadas. Es importante destacar que para la segmentación de Sauvola no se encontró un trabajo similar para el ajuste de sus parámetros desde el punto de vista de un problema de optimización.
1.1 La problemática de las imágenes de iluminación no homogénea
Las imágenes con iluminación no homogénea se pueden identificar porque muestran degradados en sus niveles de intensidad haciendo que estos sean muy variables. Asimismo se pueden presentar sombras y brillos, así como la alteración del contraste en la imagen. En este trabajo se cuenta con un conjunto de 275 imágenes en escala de grises (previamente recortadas) las cuales fueron tomadas utilizando una cámara monocromática con una resolución de 640x480 píxeles y usando una iluminación difusa tipo domo. Las imágenes tomadas son de una superficie que es altamente reflectante la cual presenta condiciones de iluminación no homogénea influenciada por la forma de la superficie irregular presentando depresiones y elevaciones en varias partes. Las regiones a segmentar las cuales son consideradas como defectos del objeto analizado, son regiones más oscuras que la región que les rodea. Estas varían en tamaño, forma, así como en su nivel de intensidad y contraste con el fondo el cual puede llegar a ser muy bajo. En la Fig. 1 se pueden apreciar algunos ejemplos de estos defectos en (a) y varias segmentaciones aplicadas (b-d).
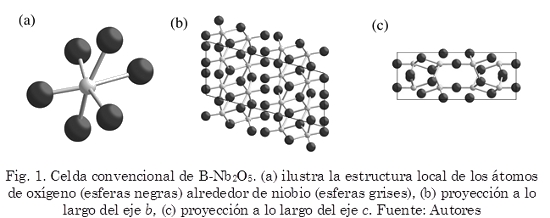
En (b) se muestra el resultado de una segmentación global, como es la umbralización doble. Se puede observar las dificultades que se generan pues estos no tienen en cuenta cambios locales presentes en la imagen. En (c) se muestra la segmentación de Sauvola con unos parámetros seleccionados arbitrariamente. Esta segmentación es más sensible a los cambios locales aunque esta puede ser mejorada por ajuste. Por último, en (d) se muestran los resultados de aplicar un filtro de bordes Canny utilizando valores fijos para sus parámetros la cual también implicaría un ajuste de sus parámetros si se desea mejorar.
1.2 Segmentación local de Sauvola
La segmentación de Sauvola (Sauvola & Pietaksinen, 2000) es un algoritmo que actúa localmente sobre subregiones de la imagen calculando un valor de umbral para cada píxel teniendo en cuenta algunas propiedades de su vecindario. La ecuación de Sauvola para determinar el valor del umbral para cada píxel viene dada por (1).
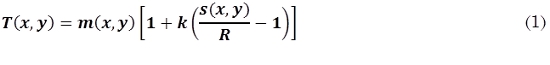
Donde T (x, y) es el valor del umbral calculado para el píxel en la posición (x, y). k y R son parámetros constantes que modifican el valor de umbral obtenido, m(x, y) es la media aritmética y s(x, y) es la desviación estándar halladas en una ventana de tamaño w x w centrada en (x, y). Según Sauvola & Pietaksinen (2000) el uso de m(x, y) como factor multiplicativo de k y R tiene un efecto de amplificar la contribución de s(x, y) de forma adaptativa. Si el nivel de intensidad en (x, y)esmayor a T(x, y) se asigna uno en la imagen binaria. De lo contrario se asigna cero.
1.3 Algoritmos genéticos
Estos algoritmos (Goldberg, 1989) buscan una solución óptima en un espacio de soluciones a través de varios mecanismos basados en la evolución biológica. Se parten de una población inicial de individuos donde cada uno de estos representa una posible solución al problema en forma codificada, usualmente una cadena binaria. A esta población se le aplican varios procesos que generan individuos más aptos cada vez de forma iterativa. Para cuantificar esta aptitud o desempeño se utiliza una función de aptitud cuya formulación depende del problema.
Durante la ejecución del algoritmo primero se presenta un proceso de inicialización de la población donde se crea una población de individuos al azar. Luego se seleccionan los mejores individuos según su aptitud a los cuales se les realiza un de cruce genético para generar nuevos individuos con características similares a las de sus padres, y por último un proceso de mutación para alterar algunos individuos y poder mantener variabilidad en la población. Una nueva población es conformada productos de estos procesos a la cual se le vuelven a realizar los mismos de forma iterativa. El algoritmo termina su ejecución luego de un número de generaciones (iteraciones) realizadas.
2. Metodología
La estructura general de la metodología propuesta se resumen en las siguientes etapas: En la etapa 1 se comienza por plantear el problema como un problema de optimización por medio de un algoritmo genético, definiendo todos los elementos que lo conforman. En la etapa 2 se formulan varias funciones de aptitud las cuales son evaluadas en la etapa 3 midiendo el rendimiento general del algoritmo genético al optimizar las segmentaciones de un conjunto de imágenes de prueba usando estas funciones. Esta parte es importante pues permite establecer la función de aptitud que mejores resultados de optimización ofrezca. En la etapa 4, una vez se tiene establecida dicha función se realiza nuevamente la optimización mediante el algoritmo genético para todas las imágenes. Por último se hace un análisis de los resultados, entre ellos, un análisis de agrupamientos para medir que tan buenas son estas segmentaciones con estos parámetros optimizados obtenidos así como el comportamiento de estos.
2.1 Planteamiento del algoritmo genético
El algoritmo se desarrolló en el lenguaje C utilizando la herramienta Dev C++ y la librería Galib. La estructura general del algoritmo planteado se puede ver en la Fig. 2.
2.2 Inicialización (Población inicial)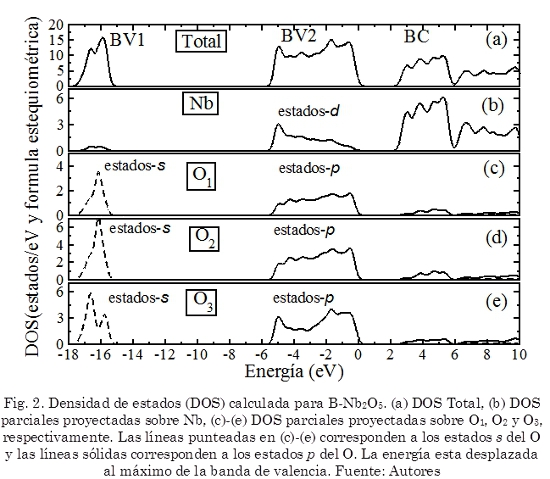
La población inicial está conformada por 50 individuos generados al azar conformados por los tres parámetros de Sauvola (k, R y w) por lo que cada uno representa una posible solución a la segmentación. Cada uno de estos parámetros tiene su respectivo intervalo definido a saber: k entre (0,1, 2,0), R entre (1, 128) y w entre (3, 15). Estos intervalos fueron propuestos teniendo en cuenta los valores sugeridos y explorados en Sauvola & Pietaksinen (2000) así como la carga computacional que se pueda generar ya que, por ejemplo, grandes valores para w incrementan considerablemente el tiempo de procesamiento. Cada individuo está representado por una cadena binaria compuesta por las codificaciones concatenadas de cada parámetro de Sauvola. La cantidad de bits para representar cada parámetro es escogida de manera tal que se puedan representar números reales contenidos en el intervalo de cada parámetro. Se escogieron 8 bits para el parámetro k, 10 bits para R y los últimos 4 bits para w. La decodificación se realiza según (2).

Donde v es el valor real del parámetro, minl y maxl son los límites inferior y superior del intervalo del parámetro, x es el valor obtenido al transformar el código binario a su respectivo número decimal y n es el número de bits utilizados para representar el parámetro. Solo para el parámetro w, donde solo se necesitan valores enteros, el valor de v es redondeado. En la Fig. 3 se puede ver un ejemplo de código binario para un individuo de la población.
2.3 Selección
La selección según el desempeño del individuo está dada por la función de aptitud. El método utilizado es el de selección por ruleta. Este es como sigue: Se determina la suma S de todas las aptitudes de los individuos de la población. A cada individuo se le asigna un segmento de dicha recta con una longitud igual a su medida de aptitud. Por último se selecciona un número al azar en el intervalo (0, S). El individuo que tenga asignado el segmento que contiene ese número es seleccionado.
2.4 Cruce
Los individuos seleccionados se cruzan por medio del cruce de un punto. En esta técnica se escoge un punto p al azar que esté dentro de la cadena binaria de alguno de los individuos padre y se intercambian los bits a la derecha de esa posición como se muestra en la Fig. 4. Se utiliza una probabilidad de cruce de 0,7.
Si el punto escogido para el cruce queda en medio de los bits que representan un valor para un parámetro, los hijos resultante tendrán en ese parámetro los bits más significativos de un padre y los menos significativos del otro generando así un valor copia del padre más una perturbación (Wright, 1991).
2.5 Mutación
La mutación es aplicada a los nuevos individuos, por medio de la inversión de los bits de la cadena binaria como se ve en la Fig. 5. Se utiliza una probabilidad de mutación de 0,05 para garantizar variabilidad en la población.
Para la terminación del algoritmo se establece a 100 el número de generaciones. Todos los valores numéricos de los parámetros que configuran el algoritmo genético se escogieron a partir de la experiencia del proceso y con el fin de evitar una alta carga computacional.
2.6 Formulación de función de aptitud
La definición de la función de aptitud depende completamente del problema que se está trabajando. En este caso, se necesita saber que tan bien segmentada está la imagen luego de ser procesada con Sauvola con los valores de los parámetros que proporciona el individuo evaluado. La aproximación consiste en comparar la segmentación generada con una segmentación manual deseada del defecto. Esta segmentación manual se realiza utilizando un editor de imágenes común marcando las regiones defectuosas en negro y el resto en blanco (ver Fig. 6). Esta es realizada bajo la supervisión de un experto en este tipo de defectos. La comparación se realiza calculando las medidas estadísticas de sensibilidad (3) y 1-especificidad (4) (Fawcett, 2006). Estas medidas son comúnmente utilizadas para medir el desempeño de clasificadores binarios y fueron utilizadas para calcular la calidad de una segmentación en Carrasco y Mery (2004).


Donde, Sn es la sensibilidad o tasa de verdaderos positivos, 1 – Sp es 1-especificidad o tasa de falsos positivos, TP es la cantidad de verdaderos positivos, es decir, la cantidad de píxeles que pertenecen al defecto y que son correctamente segmentados correctamente, FN es la cantidad de falsos negativos, píxeles del defecto que no fueron segmentados, FP es la cantidad de falsos positivos, píxeles que son erróneamente segmentados como defectos y TN que es la cantidad de verdaderos negativos que son los píxeles del fondo. La sensibilidad (Sn) mide que tanto de la región defectuosa es segmentada. Por otro lado 1-especificidad (1 – Sp) mide que tanto se segmentaron otras regiones que no pertenecen al defecto. Idealmente la sensibilidad tiene el valor de uno (no hay falsos negativos) y 1-especificidad cero (no hay falsos positivos).
Haciendo uso de estas métricas se plantearon varias funciones de aptitud en (5-8) que devuelven valores más grandes en la medida en que se segmente mayor parte del defecto (mayor sensibilidad o mayor TP y menor FN) y disminuya la sobresegmentación (menor 1-especificidad o menor FP y mayor TN), todo esto a partir de la segmentación manual. Adicionalmente se utilizaron otras funciones de aptitud presentes en la literatura. En (9) se muestra una función propuesta en (Ntirogiannis, et al., 2008) que usa mediciones que indican efectividad al segmentar la región de interés en su totalidad (Recall) así como su efectividad al segmentar el esqueleto de la misma (Precision). Por último, en (10), se utilizó el inverso de una métrica clásica de estadística, el error cuadrático medio (MSE) definida como la raíz cuadrada de la media aritmética de los cuadrados de los errores en las medidas siendo xi el valor de intensidad de un píxel de la segmentación manual y yi el valor de intensidad de la segmentación evaluada.






3. Resultados y discusión
3.1 Evaluación de funciones de aptitud
Se realizó una ejecución de prueba del algoritmo genético para un subconjunto de imágenes con el fin de obtener un resultado rápidamente. Se procesaron 50 imágenes para analizar el desempeño de cada una de estas funciones. Para cada una se calcularon la Sn y 1 – Sp promedio así como los casos no segmentados donde el óptimo hallado no pudo segmentar el defecto (Se estableció una sensibilidad mínima de 0.2 como criterio). Los resultados se resumen en la Tabla 1.
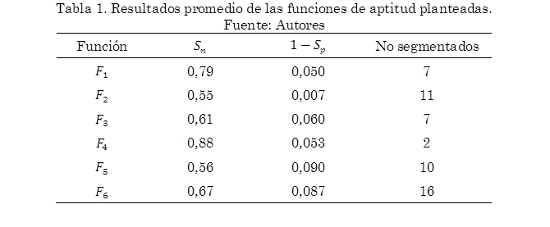
La posición adoptada para este trabajo es que lo más importante es segmentar la totalidad de la región defectuosa, esto es, tener la sensibilidad más alta posible así se presenten casos de sobresegmentación (mayor FP). A partir de esto se seleccionó la función F4 definida en (8) pues, según los resultados de la Tabla 1, esta mostró una sensibilidad promedio más alta y aunque su medida de 1-especificidad no fue la más baja sí logró segmentar el defecto en la mayoría de los casos el cual es el objetivo principal. En la Fig. 7 se puede apreciar cómo va mejorando una segmentación de una imagen durante la optimización.
3.2 Optimización con mejor función de aptitud
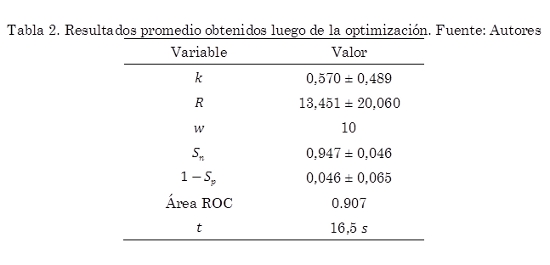
Se ejecutó el algoritmo genético con la función de aptitud seleccionada para todo el conjunto de imágenes (275). En la Tabla 2 se muestran los resultados promedio para los parámetros (mediana para w) así como para Sn, 1 – Sp y el área de la curva ROC calculada a partir de estas. Se incluye el tiempo t promedio de procesamiento aunque no es un factor crítico para este trabajo.
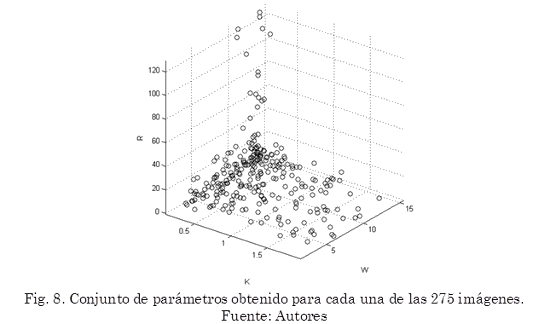
En la Fig. 8 se muestra un gráfico de todos los valores hallados para los parámetros. Los histogramas del conjunto de valores de cada parámetro se muestran en la Fig. 9. Por último en la Fig. 10 se muestran algunos de los mejores y peores resultados de segmentación luego de la optimización.

3.3 Análisis de agrupamientos
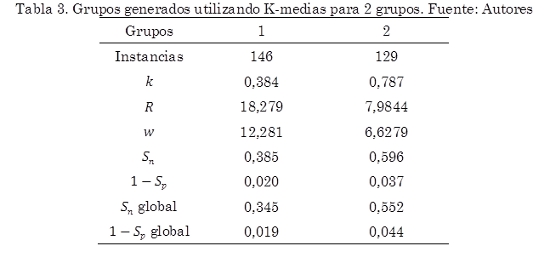
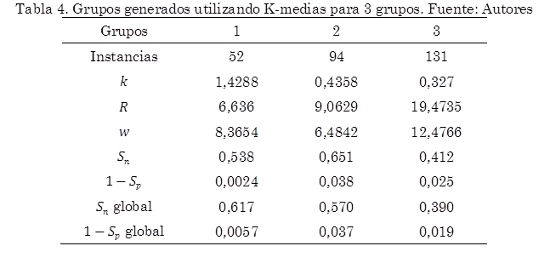
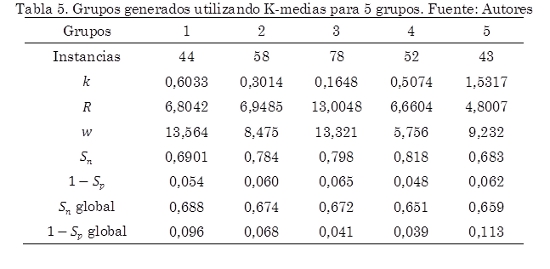
El análisis de agrupamiento o clustering se realiza para encontrar los agrupamientos que se puedan dar en un conjunto de datos. En este caso, para examinar los agrupamientos de los parámetros de Sauvola optimizados con el fin de ver si estos parámetros tienden hacia algún punto en particular. Se realizó el análisis sobre los resultados obtenidos de la última optimización utilizando el algoritmo de K-Medias, el cual agrupa los datos según una distancia Euclídea y calcula un centroide que representa cada grupo o clúster Se realizó K-Medias varias veces para hallar 2, 3 y 5gruposutilizando la herramienta de software WEKA. Para cada agrupamiento se evaluó la segmentación de Sauvola con los valores de los parámetros en el centroide del grupo midiendo la sensibilidad y 1-especificidad (Sn y 1 – Sp) en las imágenes de ese grupo. Asimismo se evaluaron estos parámetros segmentando toda la muestra de imágenes para evaluar su desempeño global (Sn y 1 – Sp global). Los resultados se muestran en las Tablas 3 a 5.
3.4 Análisis de resultados
La sensibilidad promedio obtenida tras la optimización fue de 0,947 (Tabla 2), esto es, de todos los píxeles pertenecientes a regiones defectuosas (según las segmentaciones manuales) en promedio el 94,7% fueron segmentados para cada imagen. Por otro lado, la tasa de falsos positivos, 1-especificidad, tuvo un valor promedio de 0,046, es decir un 4,6% de píxeles pertenecientes al fondo (región no defectuosa) fueron segmentados. Ambos resultados son buenos teniendo en cuenta los valores óptimos para estas medidas.
Al observar el conjunto de parámetros de Sauvola optimizados para las imágenes en la Fig. 8, se puede apreciar que no hay un agrupamiento ni una tendencia clara de estos valores hacia algún punto en particular. Esto da cuenta de que las regiones defectuosas en las imágenes procesadas tienen condiciones diferentes entre sí, en sus niveles de intensidad en la región del defecto y en el fondo que la contiene ya que los parámetros de Sauvola influyen sobre la media y desviación estándar de los mismos para determinar el valor de umbral.
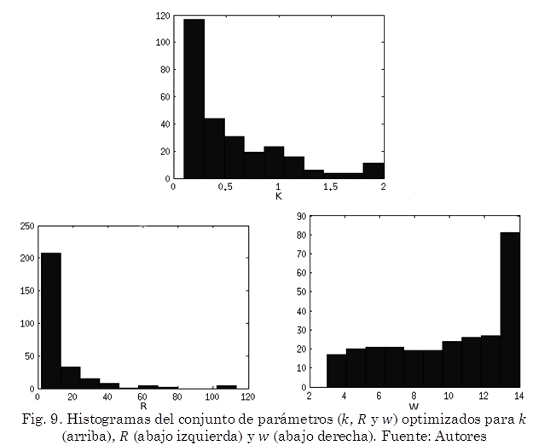
Respecto al comportamiento de cada parámetro en la Fig. 9 se puede observar que el histograma para el parámetro k más del 50% de los valores devueltos estuvo por debajo de 0,6 tendiendo a valores cercanos al límite inferior establecido para este parámetro. El parámetro R tuvo su mayor concentración por debajo de 20 donde más del 75% de los datos se ubicaron; un resultado importante teniendo en cuenta el intervalo dado para este parámetro (0,128). Los peores resultados, segmentaciones con muchos falsos positivos y/o baja sensibilidad, se dieron para imágenes de defectos que tienen bajo contraste con el fondo, como los peores de la Fig. 10. Para estos casos se apreció una tendencia hacia la sobresegmentación con valores para R más pequeños (inferiores a 5). El parámetro w tuvo una distribución uniforme en todo su rango destacando los valores superiores a 13.
En el análisis de agrupamientosse observa en las Tablas 3 a 5 un aumento en la sensibilidad promedio a medida que aumentan los grupos si bien la tasa de falsos positivos no varía mucho. Los mejores resultados en cuanto a sensibilidad se vieron para el caso de 5 grupos (Tabla 5). Aquí las medidas de sensibilidad fueron buenas alcanzando un valor máximo de 0,81. Por otro lado la tasa de falsos positivos 1 – Sp tuvo valores entre el 0,05 y 0,10 que a pesar de ser valores cercanos al óptimo, son suficientes para introducir falsos positivos que pueden reducir la precisión en la segmentación. Estos valores cercanos a los valores óptimos para estas medidas dan cuenta de que hay subconjuntos de imágenes con propiedades similares que pueden ser segmentadas con un mismo conjunto de parámetros.
En cuanto al desempeño de estas soluciones aplicadas a todas las imágenes dados por las medidas de Sn global y 1 – Sp global los mejores resultados para la sensibilidad global estuvieron alrededor de 0,67 en promedio lo cual es un resultado bajo que indica una considerable subsegmentación en estos casos.
4. Conclusiones
En este trabajo se planteó una estrategia de optimización de la técnica de segmentación Sauvola aplicada a imágenes con iluminación no homogénea utilizando algoritmos genéticos para optimizar sus parámetros cuya función de aptitud fue determinada por la comparación de la segmentación de Sauvola y una manual deseada calculando medidas de sensibilidad y especificidad.
Los resultados de la optimización mostraron que para cada caso en particular el algoritmo genético logró optimizar los parámetros de Sauvola los cuales lograron segmentar el defecto en cada imagen promediando una sensibilidad de 0,946 cercana al valor óptimo 1, y con una tasa de falsos positivos aceptable, 1-especificidad de 0,046 cercana al valor óptimo 1. Esta estrategia puede ser generalizada y aplicada a otros algoritmos de segmentación.
Los resultados obtenidos dan cuenta de que no hay una tendencia clara de los parámetros de Sauvola donde los mejores valores para estos son específicos para cada caso dependiendo sus características, las cuales son más variables cuando hay iluminación no homogénea. No obstante por el análisis de agrupamientos se encontró que hay subconjuntos de imágenes donde los mismos parámetros logran la segmentación. Algunos parámetros (k y R) no utilizaron todos los valores de sus intervalos establecidos lo que puede sugerir una redefinición de los mismos y una reducción del espacio de búsqueda para estos. Un trabajo futuro consistiría en realizar un análisis más riguroso de las propiedades de estas imágenes que hacen que los parámetros de Sauvola funcionen para unas situaciones pero no para otras.
Referencias
Carrasco, M.A. & Mery, D., (2004); Segmentation of welding defects using a robust algorithm. Materials Evaluation, 62(11): 1142-1147. [ Links ]
Chou, J.H. & Ghaboussi, J., (2001); Genetic algorithm in structural damage detection, Computers & Structures, 79(14): 1335-1353. [ Links ]
Fawcett, T., (2006); An introduction to ROC analysis, Pattern Recognition Letters, 27(8): 861-874. [ Links ]
Goldberg (1989); Genetic algorithms in search, optimization, and machine learning, 1. [ Links ]
Gupta, M.R., Jacobson N.P. & Garcia E.K., (2007); OCR binarization and image pre-processing for searching historical documents, P. Recognition, 40: 389-397. [ Links ]
Hamid, M.S., Harvey, N.R. & Marshall, S., (2003); Genetic algorithm optimization of multidimensional grayscale soft morphological filters with applications in film archive restoration, Circuits and Systems for Video Technology, IEEE Transactions on , 13(5): 406-416. [ Links ]
Jarvis, R.M. & Goodacre, R., (2005); Genetic algorithm optimization for pre-processing and variable selection of spectroscopic data, Bioinformatics, 21(7): 860. [ Links ]
Jeon, B.K., Jang, J.H. & Hong, K.S., (2002); Road detection in spaceborne SAR images using a genetic algorithm, Geoscience and Remote Sensing, IEEE Transactions on, 40(1): 22-29. [ Links ]
Ntirogiannis, K., Gatos, B. & Pratikakis, I., (2008); An objective evaluation methodology for document image binarization techniques, The Eighth IAPR International Workshop on Document Analysis Systems, 217-224. [ Links ]
Sauvola, J. & Pietaksinen, M., (2000); Adaptive document image binarization. Pattern Recognition. 33: 225-236. [ Links ]
Sezgin, M. & Sankur, B., (2004); Survey over image thresholding techniques and quantitative performance evaluation, Journal of Electronic imaging, 13: 146. [ Links ]
Shin, K.S. & Lee, Y.J, (2002); A genetic algorithm application in bankruptcy prediction modeling, Expert Systems with Applications, 23(3): 321-328. [ Links ]
Tao, W.B., Tian, J.W. & Liu, J., (2003); Image segmentation by three-level thresholding based on maximum fuzzy entropy and genetic algorithm, Pattern Recognition Letters, 24, 3069-3078. [ Links ]
Wright, A.H., (1991); Genetic algorithms for real parameter optimization. Foundations of Genetic Algorithms, CA: Morgan Kaufmann Publishers, 205-218. [ Links ]

