











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. INTRODUCCIÓN
Las redes sociales acumulan una gran cantidad de usuarios que conversan digitalmente, guardan textos y comentan textos de otros usuarios. En particular, en la actualidad, Facebook posee más de 2217 millones de usuarios, que la convierten en la red social más usada, y Twitter cuenta con más de 326 millones de usuarios [1], que a diario generan unos 500 millones de tweets en todo el mundo [2].
Esta gran cantidad de información resulta muy difícil de procesar manualmente, por este motivo se utilizan técnicas de Procesamiento de Lenguaje Natural, que permiten automatizar su procesamiento. Este trabajo, se centra en el uso de métodos estadísticos [3], [4], en la eliminación de términos que se consideran superfluos, en la normalización de los textos y la aplicación de técnicas de lematización, para reducir las palabras a su raíz y parametrizar los documentos, mediante la asignación de un peso a cada uno de los términos relevantes, con la técnica tf-idf [5].
La minería de textos (text mining) consiste en un conjunto de técnicas que permiten extraer información relevante y desconocida, de manera automática, de grandes volúmenes de información textual, normalmente, en lenguaje natural y por lo general no estructurada [6]. En este trabajo, se revisan varios métodos de clasificación automática como svm, con varias funciones kernel y Random Forests. Se compara la precisión y cobertura obtenida para la identificación automática de clases que etiqueten el contenido de tweets recopilados automáticamente de organismos oficiales.
El objetivo es proporcionar un procedimiento para la clasificación automática multiclase de la información contenida en tweets de usuarios de organismos oficiales y su representación gráfica. Se enfatiza en la necesidad de que la clasificación sea multiclase y en la búsqueda de los métodos de clasificación automática, cuando dos clases no cubran todos los casos existentes en la información [7]; así mismo, se selecciona Twitter, puesto que contiene un gran volumen de textos disponibles, con api abierta para procesarlos. La escogencia de los usuarios de Twitter pertenecientes a organismos oficiales obedece al interés que puedan tener en identificar de qué están hablando los ciudadanos y, concretamente, de qué se están quejando.
La (Fig. 1) proporciona una visión global del procedimiento sugerido, que consta de las siguientes fases:
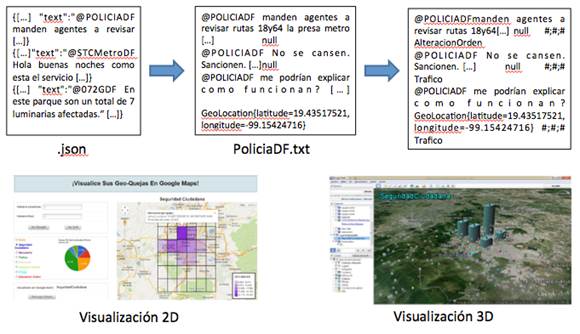
Recopilación de datos a través del api de Twitter (.json)
Etiquetado de una parte de los datos recopilados de forma supervisada (.txt)
Clasificación de forma automática de los datos no etiquetados (svm versus Random Forests)
Visualización geolocalizada 2D y 3D de los tweets etiquetados.
Al aplicar este procedimiento en 190 000 tweets recopilados durante un año de Metro, Protección Civil, Policía, y Gobierno de México (organismos seleccionados por presentar libre acceso), y etiquetar más de 2000 de estos tweets a mano, para entrenar en los métodos de clasificación automática, se recomienda el uso de Random Forests como método de clasificación, ya que se obtiene una precisión media del 81.46 % y una cobertura media del 59.88 %.
Este artículo se compone de las siguientes secciones: en la Sección 2, se recoge el estado del arte; en la Sección 3, se presenta la propuesta de clasificación automática multiclase de tweets, y, por último, en la Sección 4, termina el artículo con las principales conclusiones y líneas de trabajo futuro.
2. REVISIÓN DEL ESTADO DEL ARTE
En general, en la clasificación de microblogging hay que tener en cuenta la técnica o combinación de técnicas para la recopilación de tweets y su clasificación, el dominio, idioma y tipo de clasificador, según el número de clases con las que es capaz de trabajar.
Respecto a la recopilación de tweets -con base en que el objetivo es clasificar los tópicos en clases generales para facilitar la recuperación de información-, esta se puede hacer mediante servicios web como What the Trend [8].
De esta manera, todos los tweets que contienen un trending topic constituyen un documento. En el caso de que un tweet contenga más de dos trending topics, este se guarda en todos los documentos relevantes.
Se experimentan dos enfoques para la clasificación de tópicos: 1) el enfoque Bag-of-Words [9] para la clasificación de textos y 2) la clasificación network-based [10].
En el método de clasificación basado en textos, se construyen vectores de palabras con definiciones de trending topics y tweets, y se asignan los pesos tf-idf [11], para clasificar los tópicos mediante el clasificador multinomial Naive Bayes (nb) [12]. En el método de clasificación basado en la red, se identifican los cinco tópicos similares más relevantes para un tópico dado, con base en el número de usuarios influyentes comunes.
Se construyen los modelos predictivos, para lo cual se utilizan varias técnicas de clasificación y se selecciona el que tiene como resultado la mejor precisión de clasificación. Gracias al uso de Naive Bayes Multinomial (nbm) [13], Naive Bayes (nb) [12] y Support Vector Machines (svm-l) [14] con kernels lineales, se obtiene que la precisión de la clasificación es una función del número de tweets y la frecuencia de los términos.
Los resultados arrojados fueron: para nbm, con 100 tweets y 1000 términos, se obtiene un accuracy del 65.36 %. Para svm, con esos mismos datos, se obtiene un 59.81 % y con nb un 45.31 % de accuracy.
Al emplear la clasificación network-based con diferentes técnicas de clasificación, se consigue un accuracy del 70.96 %, para el árbol de decisión C 5.0 [15] como mejor resultado.
Para mejorar el filtrado de la información, otros autores proponen usar un pequeño conjunto de características específicas del dominio, extraídas a partir del perfil del autor y del texto, para clasificar noticias, eventos y mensajes privados [16].
En general, se puede decir que, para la clasificación, se suelen usar combinaciones de minería de datos y Procesamiento de Lenguaje Natural [17], así como comparaciones de nb, svm y knn entre otras técnicas [18].
Respecto al dominio, suele ser habitual que esté relacionado con emociones [19], opiniones [20], situaciones de emergencia [21] o con análisis de redes sociales [22].
En cuanto al lenguaje, suele ser inglés, aunque también hay casos en los que se dan otros idiomas como turco o multiidioma, con técnicas que pueden aplicarse a cualquier idioma [23].
Sobre el número de clases que puedan clasificarse, lo habitual es que sean dos, esto es, que sean clasificadores biclase.
En los últimos años también se están proponiendo algunos clasificadores multiclase, capaces de clasificar más de dos clases, con lo cual se obtienen valores de precisión entre 68.16 y 73.24 [17], [24].
Por último, se registran mejoras en la clasificación de tweets, al tener en cuenta no solo su contenido sino también url, retweets y usuarios influyentes [18] y, en general, el multiequitado de la web social con procesamiento multinúcleo [25].
3. PROPUESTA DE CLASIFICACIÓN AUTOMÁTICA MULTICLASE DE TWEETS
Es importante destacar que, normalmente, en la literatura se encuentran clasificadores biclase limitados en el dominio, en el idioma y las técnicas que utilizan. La propuesta de este trabajo está contextualizada en el dominio social, particularmente, en las quejas.
Se centra en el lenguaje castellano, pero, como en [23], las técnicas se pueden aplicar a otros idiomas. Utiliza como técnicas svm y Random Forests, como en [17], que está basado en técnicas de minería de datos y Procesamiento de Lenguaje Natural, o en [18], que usan svm, entre otras técnicas.
De esta manera, la principal contribución propuesta es un clasificador multiclase para el dominio social, en castellano, aplicable a otros idiomas, que sigue los pasos principales de Minería de Datos, que se irán describiendo en detalle en los siguientes subapartados:
Selección del conjunto de datos, tanto en lo que se refiere a las variables que se quieren predecir como a las variables que sirven para hacer el cálculo.
Transformación del conjunto de datos de entrada, también conocido como pre-procesamiento de los datos, con el objetivo de prepararlo para aplicar la técnica de Minería de Datos que mejor se adapte a los datos y al problema.
Selección y aplicación de la técnica de Minería de Datos, y construcción del modelo predictivo de clasificación.
Extracción de conocimiento mediante una técnica de Minería de Datos, se obtiene un modelo de conocimiento, que representa patrones de comportamiento observados en los valores de las variables del problema.
Interpretación y evaluación de datos.
Una vez obtenido el modelo, se procede a su validación, tras comprobar que las conclusiones que arroja son válidas y satisfactorias.
3.1 Recogida de datos
En primer lugar, se recogieron de forma paralela tweets de dos formas diferentes a, través de las funciones que proporciona el api Stream de Twitter. Con base en la idea que se planteó -identificar las quejas de los usuarios de México D. F.-, se recopilaron de forma genérica todos los tweets localizados dentro de las coordenadas que cercan la ciudad de México D. F., mediante la opción que nos proporciona la función post statuses/filter, llamada “locations”.
De forma adicional y paralela, también se recopilaron los tweets de algunos de los organismos oficiales que se encuentran en México D. F. Para eso, se buscaron los organismos oficiales existentes en México; finalmente, se seleccionaron cuatro de ellos, en los que se intuyó podría haber más posibilidades de recopilar quejas de usuarios. Los usuarios seleccionados son: el Metro, la Protección Civil, el Gobierno y la Policía.
Para conseguir la recopilación de estos tweets, se empleó otra función llamada “follow” que recoge todos los tweets pertenecientes a un identificador (id) único para cada uno de los usuarios.
Con este objetivo, se desarrolló un script que se ejecutó de forma continua durante un año, al almacenar los tweets en ficheros con extensión “.json”.
3.2 Extracción de datos
Una vez terminada la recogida de datos, se procedió al tratamiento y extracción de los datos necesarios para hacer la clasificación. Para atender a la estructura de un tweet y a la cantidad de campos que contiene, el procedimiento a seguir fue el estudio de cada uno de esos campos a fin de establecer cuáles eran los necesarios para este proceso de clasificación y cuáles no.
Finalmente, se decidió que los únicos campos necesarios iban a ser el texto del tweet, representado por el campo “text”, que contiene una longitud de 140 caracteres alfanuméricos, y la ubicación geográfica del tweet, representada por el campo “coordinates”, que contiene la latitud y longitud de su ubicación. Se tomó esta decisión, de acuerdo al objetivo marcado inicialmente para la recogida y clasificación de tweets geolocalizados, con lo que el campo “coordinates” proporciona la geo-localización del tweet, que servirá para ubicarlo en la visualización, y el campo “text” proporciona la información necesaria para la identificación de quejas.
Para poder extraer cada uno de estos campos del fichero. json, se empleó una librería desarrollada en código Java llamada “twitter4j” [26], cuya funcionalidad permite procesar el api de Twitter.
El texto y la geolocalización de todos los tweets recogidos para cada uno de los usuarios específicos se guardan en un fichero “.txt”, para su posterior clasificación.
De esta forma, se crean cuatro ficheros “.txt”, que contienen un total de 34 839 tweets para el Gobierno de México D. F., 123 873 para el Metro, 4122 para la Protección Civil y, finalmente, 13 944 tweets para la Policía.
3.3 Aplicación de técnicas de Procesamiento de Lenguaje Natural
Con los datos guardados en el fichero “.txt”, el siguiente paso es aplicar técnicas estadísticas de Procesamiento de Lenguaje Natural a los textos [3]. Este tipo de procesamiento representa el modelo clásico de los sistemas de recuperación, y se caracteriza porque cada documento está descrito por un conjunto de palabras clave denominadas término índice. En este modelo, el procesamiento de los documentos consta de las siguientes etapas:
-Preprocesado de los documentos: se eliminan aquellos elementos que se consideran superfluos. Consta de tres fases básicas:
-Eliminación de elementos del documento que no son objeto de indexación; en este caso, pueden ser etiquetas, enlaces http, etc.
-Normalización de textos, que consiste en homogeneizar todo el texto e identificar N-Gramas que pueden ser unigramas (1-gramas), bigramas o digramas (2-gramas), trigramas (3-gramas), etc.
-Lematización de los términos, cuyo objetivo es reducir una palabra a su raíz mediante algoritmos de radicación o stemming, que permiten representar de un mismo modo las distintas variantes de un término, con el fin de reducir el tamaño del vocabulario y mejorar, en consecuencia, la capacidad de almacenamiento de los sistemas y el tiempo de procesamiento de los documentos.
-Parametrización: se hace una cuantificación de las características (es decir, de los términos) de los documentos, mediante la asignación de un peso a cada uno de los términos relevantes de un documento. El peso de un término se calcula normalmente mediante la función tf-idf (en inglés, Term Frecuency-Inverse Document Frecuency) [5], que consiste en una medida numérica que expresa cuán relevante es una palabra para un documento en una colección. El valor tf-idf aumenta proporcionalmente al número de veces que una palabra aparece en el documento, pero es compensada por la frecuencia de la palabra en la colección de documentos, lo que permite manejar el hecho de que algunas palabras son generalmente más comunes que otras.
3.4 Métodos de identificación de clases
Con los textos preprocesados, el siguiente paso para poder iniciar el proceso de clasificación es identificar cuáles van a ser las clases bajo las cuales se van a catalogar los tweets. Para eso, se emplearon dos técnicas: k-means y nubes de palabras, que se describen a continuación.
El método k-means tiene como objetivo la partición de un conjunto n en k grupos, en el que cada observación pertenece al grupo más cercano a la media. Una de las aplicaciones de este algoritmo es emplearlo como preprocesamiento para otros algoritmos, por ejemplo, para buscar una configuración inicial.
Es en este aspecto, cobra sentido la aplicación de este método en la identificación de clases para la colección de tweets. Se empleó k-means para obtener varios grupos de términos y observar si entre ellos se encontraba alguno que pudiera ser identificado como queja.
Para la obtención de diferentes clusters que pudieran ofrecer una idea inicial de algunas de las clases, se probó con múltiples números clusters, hasta que, con el número 12, se obtuvo una muestra orientativa de clusters que contenían un conjunto de seis términos en cada uno de ellos, y se hizo la función k-means, también disponible en el programa R.
En los resultados de los diferentes clusters obtenidos, se identificaron a priori quejas como robo, maltrato animal, circulación, extorsión, abandono. Con esta idea inicial, se consiguieron algunas de las etiquetas que posteriormente serían verificadas como clases, con las que se etiquetaría el training set.
El método nubes de palabras (wordclouds) permite obtener una representación visual, en forma de nubes de palabras, sobre la frecuencia con la que se repite cada una de las palabras.
La Fig. 2 muestra un ejemplo de nubes de palabras, identificadas para el usuario Policía. Estas etiquetas se pueden usar de forma complementaria a las identificadas en los k-means.

El resto de los tweets, que no pertenecían a ninguna de las clases identificadas, fueron etiquetados con la clase “No Etiquetado”, que correspondía con un alto porcentaje de los tweets. Debido a esto, se identificó el problema de las Clases No Balanceadas, que ocurre cuando en un problema de clasificación hay muchas más instancias de unas clases que de otras.
Las clases que tienen minoría de instancias son las que rara vez aparecen, pero son, asimismo, las que más importancia tienen [27].
3.5 Clasificación automática multiclase
El siguiente paso es obtener un clasificador de forma supervisada, para poder clasificar de forma automática los tweets recogidos. En este ámbito, cabe aclarar que los métodos de clasificación automática se engloban dentro del concepto de Aprendizaje Automático, cuyo objetivo es crear programas capaces de generalizar comportamientos, a partir de una información no estructurada. Este es, por lo tanto, un proceso de inducción al conocimiento.
En el Aprendizaje Automático existen técnicas de clasificación supervisada y no supervisada. La clasificación supervisada cuenta con modelos ya clasificados, que permiten clasificar los no clasificados.
Se pueden diferenciar dos fases en este tipo de clasificación:
En la primera fase, se dispone de un conjunto de entrenamiento o de aprendizaje y de otro llamado de test o de validación; estos sirven para construir un modelo o regla general para la clasificación. El proceso de entrenamiento es cuando un clasificador debe aprender cómo clasificar los objetos, al generalizar, a partir de los datos de entrenamiento, las situaciones no vistas.
En la segunda fase, se clasifican los objetos o muestras de las que se desconoce la clase a la que pertenecen.
La salida de un clasificador supervisado puede ser la etiqueta de la clase del nuevo objeto clasificado, un conjunto de etiquetas ordenadas por la probabilidad de ser la etiqueta correcta, así como un vector numérico, en el que cada valor representa el valor de pertenencia otorgado por el clasificador a cada clase.
En la actualidad, existen diversos clasificadores supervisados. Entre los más usados, se encuentran el Vecino más Cercano (KNN), las Redes Neuronales (ANN), el clasificador Bayesiano (NB), los Random Forests (RF), y la Máquina de Soporte de Vectores (SVM).
A diferencia de la clasificación supervisada, la clasificación no supervisada no cuenta con conocimiento a priori, por lo que se tiene un área de conocimiento disponible para la tarea de clasificación.
A la clasificación no supervisada se le suele llamar también clustering. En este tipo de clasificación, se cuenta con “objetos” o muestras que tienen un conjunto de características, de las que no se sabe a qué clase o categoría pertenecen; en razón a esto, su finalidad es el descubrimiento de grupos de “objetos” cuyas características afines permitan separar las diferentes clases.
Para la clasificación de las clases identificadas en la sección anterior, se optó por la técnica de clasificación supervisada.
En particular, se etiquetó un conjunto de 2000 tweets de un total de 13 944, recogidos de la Policía de forma manual y leído texto por texto. En estos casos, juega un papel importante la objetividad para identificar a qué etiqueta pertenece cada uno de los tweets; por este motivo, el encargado de etiquetarlos debe hacerlo con la mayor objetividad posible.
Posteriormente, para entrenar los clasificadores, los pasos a realizar son:
Dado un conjunto de 2000 tweets etiquetados por completo, se subdivide en dos conjuntos de tweets diferentes: el conjunto de entrenamiento (trainingset), que contiene el 60 % de los tweets seleccionados de forma aleatoria, y el conjunto de testeo (testset) que contiene el restante 40 % de los tweets. El conjunto de entrenamiento abarca las clases etiquetadas, en cambio, en la predicción, el conjunto de testeo no.
Esto se hace para ver qué precisión y cobertura alcanza el clasificador sobre una muestra inicial.
Se aplica el clasificador sobre el conjunto de entrenamiento y, a continuación, una predicción entre el resultado obtenido por el clasificador y el conjunto de testeo.
Mediante una matriz de confusión, en la que cada columna representa el número de predicciones de cada clase y cada fila el número de instancias de la clase real, se visualizan los resultados predichos y se calcula la precisión y la cobertura para cada una de las clases, a fin de obtener, finalmente, una media de la precisión y una media de la cobertura.
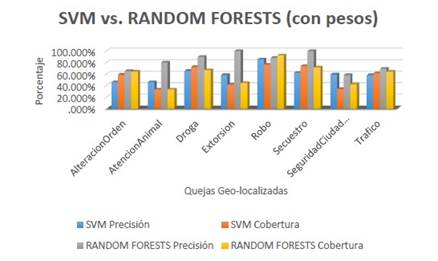
Con el conjunto de entrenamiento etiquetado, se procedió a hacer un estudio de SVM y Random Forests como clasificadores a entrenar para clasificar los tweets. Los resultados recogidos en las (Fig. 3) y (Fig. 4) indican que, tanto en el caso de aplicar o no función de pesos, Random Forests obtiene mejores resultados, por lo que fue el clasificador escogido. Se pueden encontrar más tablas en [28].

Fuente: elaboración propia.
Fig. 3 Comparación de los resultados de los clasificadores sin aplicar la función de pesos
Para este proceso de clasificación, en este caso no se selecciona el 40 % de las muestras aleatoriamente, para separar el conjunto de testeo del conjunto de entrenamiento. En su lugar, el conjunto de entrenamiento serán los tweets etiquetados de forma manual y el conjunto de testeo los tweets que se van a etiquetar de forma automática.
Tras hacer la predicción de la clasificación automática, se construye una matriz que contiene una nueva columna añadida con la clase a la que pertenece cada uno de los tweets no etiquetados inicialmente, con el fin de añadir esa columna al fichero de tweets y hacer las visualizaciones como se explica en el siguiente apartado.
4. CONCLUSIONES Y TRABAJO FUTURO
En este trabajo se ha investigado el procedimiento para una clasificación automática multiclase de los tweets recogidos de algunos de los organismos oficiales de México D. F., cuyos datos almacenados rondan los 190 000 tweets acopiados a lo largo de un año.
Con este objeto, se hizo un estudio comparativo de varios clasificadores supervisados según sus resultados de precisión y cobertura, lo que arrojó que, Random Forests, con unos resultados de precisión en el entrenamiento entre el 58.46 % y el 100 %, y de cobertura de entre el 33.33 % y el 92.68 %, es el clasificador propuesto.
Estos resultados son interesantes para el estado del arte, puesto que, al revisar la literatura, los datos se suelen limitar a valores de accuracy y no de precisión-cobertura por separado.
En particular, el trabajo mayormente vinculado al desarrollo de esta parte del proyecto es el adelantado por Malkani & Gillie en 2012, que emplea svm multiclase y Random Forests, para la clasificación de dos conjuntos de datos con clases diferentes centrados en tópicos y actitudes.
En este caso, se han empleado estos clasificadores de forma diferente. svm se probó con one-vs-one y distintos tipos de kernel, aunados a la función pesos y Random Forests, con 150 árboles aleatorios; asimismo, la función pesos fue usada para identificar ocho clases diferentes de quejas en usuarios específicos.
En consecuencia, la principal contribución al estado del arte radica en la clasificación multiclase al usar clasificadores Support-Vector Machines (svm) multiclase y Random Forests (rf) para 35 000 tweets, para la identificación de quejas. De lo anterior, se obtuvo como resultado:
-Con svm:
-Precisión: entre 55.83 % y 92.26 %
-Cobertura: entre 33.33 % y 76.53 %
-Para rf:
-Precisión: entre 58.46 % y 100 %
-Cobertura: entre 33.33 % y 92.68 %.
Además, las técnicas utilizadas son aplicables a otros idiomas y dominios.
El código y el dataset se han publicado en [29] para otros investigadores que requieran avanzar en sus estudios.
Respecto al trabajo futuro, se está trabajando en mejorar la precisión y cobertura obtenidas con otros métodos de clasificación y añadir mayor variedad de organismos oficiales.

