











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
1. INTRODUCCIÓN
1.1 Disfagia y diagnóstico
La disfagia es la alteración del proceso deglutorio, lo que puede generar desnutrición, deshidratación, neumonía e incluso la muerte [1]. Sus causas se dividen en dos grupos: trastornos neuromotores y lesiones obstructivas [2]. Las personas con esta afección han tenido que adoptar distintas medidas en sus hábitos alimenticios, de sueño y del habla para poder contrarrestar los efectos de la disfagia, algo que no solo afecta al paciente, sino también a su círculo familiar y social inmediato [3]. Está asociada a diversas enfermedades neurológicas de base y tiene incidencia, principalmente, en la población de edad avanzada [4].
En Colombia, la población mayor a 59 años pasó de dos millones en el año 1985, a seis millones en 2018, con un crecimiento anual del 3,5 %, superior al 1,7 % de la población total, y se proyecta un aumento de esta población debido a la disminución de la mortalidad y al aumento de la expectativa de vida [5]. Esta población es vulnerable a distintas enfermedades o afecciones como lo son la enfermedad de Parkinson (EP), Alzheimer, esclerosis lateral amiotrófica (ELA), entre otras, las cuales aumentan la incidencia y prevalencia de la disfagia [4].
Los métodos validados clínicamente para la evaluación instrumental de la disfagia son la videofluoroscopia y la endoscopia de fibra óptica (VFSS y FEES, por sus siglas en inglés, respectivamente) [6]. Sin embargo, la VFSS es la prueba de referencia aceptada clínicamente [4]. Ambas técnicas son invasivas y dependientes de la experticia y capacitación del personal que las utiliza [7]. La VFSS, además de ser invasiva, es costosa -con un valor aproximado de medio millón de pesos colombianos-, lo que tiene un impacto sobre el sistema de salud.
Debido a las limitaciones presentadas arriba, distintas investigaciones han propuesto aproximaciones basadas en señales no invasivas (ej. electromiografía de superficie [8] o auscultación cervical con acelerometría [9]), aunque aún no han sido implementadas en el consultorio para tratamiento, diagnóstico o seguimiento de la disfagia. Una de las aproximaciones que podrían complementar el diagnóstico es el estudio de las señales de voz y habla, debido a que estas guardan estrecha relación, tanto a nivel estructural como neurológico, con el proceso deglutorio [10], [11].
Debido a esta relación, algunos pacientes con disfagia presentan trastornos de la voz y del habla, tales como disfonía y la voz húmeda. La disfonía ocurre cuando los músculos alrededor de la laringe se encuentran muy tensos durante el habla y se manifiesta como voz ronca, débil, tensa, entrecortada y/o áspera. Algunos pacientes manifiestan además opresión e incluso dolores musculares en la garganta [12]. Por otra parte, la voz húmeda es la presencia de material extraño en el área de la laringe, normalmente restos de alimentos sólidos o líquidos, y se caracteriza por ser una voz gorgoja o con sonidos guturales anormales [13], [14].
1.2 Análisis de la voz y del habla en pacientes con disfagia
El análisis de voz se refiere al estudio de las características acústico-fonatorias en vocales sostenidas. Por otro lado, el análisis del habla hace referencia al estudio de las características asociadas al habla continua.
Estos análisis se han abordado preliminarmente en estudios de pacientes con disfagia y otras comorbilidades [15]. Lo anterior debido a que este tipo de análisis presenta baja intrusión y fácil implementación en la práctica clínica. Una correlación significativa entre las características de voz contrastada con el análisis de VFSS podría llegar a avances importantes en un diagnóstico más simple y menos estresante para los pacientes, además de un menor costo e impacto en el sistema de salud [16]. Además, cuando se logra una automatización lo suficientemente robusta, la evaluación basada en el habla se podría llevar a cabo de manera remota, reduciendo el costo para los pacientes y ampliando el espectro de atención hacia personas que viven en áreas rurales.
En 2004, se realizó un estudio en 93 pacientes para determinar el valor diagnóstico del análisis de voz para la detección de aspiraciones laríngeas en pacientes con alto riesgo [17]. Se midieron cinco variables acústicas pre y pos VFSS: el valor medio de la frecuencia fundamental de vibración de los pliegues vocales (F 0 ), la perturbación promedio relativa (RAP, por sus siglas en inglés), el porcentaje de Shimmer, la relación ruido-armónico y el índice de turbulencia de voz. Se observó que el RAP, el Shimmer, la relación ruido-armónico y el índice de turbulencia permiten detectar pacientes con alto riesgo de aspiración, en especial el RAP.
En una investigación posterior [15], se analizaron señales de voz obtenidas de pacientes con desórdenes neurológicos de diferentes etiologías -EP, accidente cerebrovascular y ELA-, bajo tres condiciones de evaluación: actividades predeglutorias, después de tragar una solución líquida y después de tragar una solución pastosa. Adicionalmente, utilizaron tres enfoques: análisis acústico, basado en F 0 , Jitter y Shimmer; un método basado en dinámica no lineal en vocales; y un análisis de entropía relativa entre los grupos de señales. Los autores encontraron que únicamente el análisis de dinámica no lineal arrojó diferencias estadísticamente significativas en los grupos.
Otro estudio evaluó un grupo de pacientes con disfagia y un grupo de control en el que se analizó la producción vocal a partir del registro de la vocal sostenida \a\ antes y después de la ingesta de sustancias pastosas mediante la escala GRBAS -siglas en inglés para grado, aspereza, respiración, astenia y tensión- y el parámetro de voz húmeda. Los autores observaron una disminución significativa en el grado y la astenia y un aumento importante de la tensión en las personas con disfagia, mientras que los controles no presentaron variación en estos parámetros después de la deglución. Por otra parte, la voz húmeda no mostró variaciones entre los grupos [18].
En el 2016 se realizó un estudio en el que extrajeron características lineales y no lineales en señales de habla continua, que pueden ser interpretados como indicadores o predictores confiables en la determinación de alteraciones de deglución en pacientes con EP, los cuales también presentaron un alto riesgo de aspiración relacionado a la disfagia. Los autores extrajeron múltiples características como la clasificación sonora-insonora, la relación ruido-armónico, la frecuencia fundamental y sus variaciones, Jitter, Shimmer, coeficientes cepstrales de frecuencia en la escala Mel (MFCC, por sus siglas en inglés), y la entropía de permutación. Se halló que, además de la frecuencia fundamental, se presentaron fuertes variaciones en la relación ruido-armónico y en la entropía de permutación en pacientes después de la deglución de una solución pastosa [16].
1.3 Contribuciones del trabajo
En este trabajo se buscó establecer una correlación entre las características del habla y condiciones de voz húmeda y disfonía, en pacientes diagnosticados con disfagia. Para ello, se realizó un análisis de las dimensiones del habla con el fin de contribuir a un diagnóstico de la disfagia oportuno, no invasivo, con menor sesgo del evaluador y costo-efectivo.
2. MATERIALES Y MÉTODOS
2.1 Base de datos
Se construyó una base de datos con registros de voz de 45 pacientes con disfagia (23 hombres y 22 mujeres, edad promedio de 59,7 ± 12,3 y 30 personas de control (13 hombres y 17 mujeres, edad promedio de 63,2 ± 9,9 años). Los voluntarios firmaron consentimiento informado aprobado por el Comité de Ética de la Universidad Pontificia Bolivariana, el cual está definido siguiendo los lineamientos del acuerdo de Helsinki.
La muestra de pacientes se dividió en tres subgrupos diferenciados por condición clínica de la voz: voz húmeda (VH), voz disfónica (VDf) y voz normal o no determinada (ND). Dicha condición es etiquetada por una fonoaudióloga con experiencia certificada en pacientes con disfagia. La Tabla 1 muestra la distribución demográfica de la base de datos, en donde la edad está dada en años y presentada en media y desviación estándar.
Tabla 1 Distribución demográfica de la base de datos.
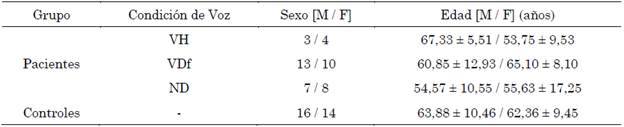
Nota: VH: voz húmeda; VDf: voz disfónica; ND: condición no determinada
Fuente: elaboración propia.
Con el fin de evitar sesgos, el grupo de control se dividió en otros dos, uno con siete voluntarios para comparaciones con el grupo de VH y otro con 23 voluntarios para comparaciones con el grupo de VDf. La selección de ambos subgrupos fue realizada teniendo en cuenta un emparejamiento en términos de edad y género (prueba t con p = 0,82, prueba ꭕ^2 con p = 1,00 para comparaciones con VH; prueba t con p = 0,7, prueba, ꭕ^2 con p = 1,00 para comparaciones con VDf).
2.2 Protocolo de grabación
En este trabajo se pretende cubrir el análisis de voz y habla en pacientes con disfagia. Para el análisis de voz se consideró la producción de vocales sostenidas, y, para el análisis del habla, se consideraron tareas de habla continua y diadococinesia. Para la adquisición de las señales se utilizó la diadema Logitech H390. El micrófono se posicionó a una distancia aproximada de 5 cm de la boca, como se observa en la Figura 1.

Las grabaciones fueron adquiridas con el software Audacity con una frecuencia de muestreo de 44,1 kHz y exportadas en formato .wav de 16 bits con signo.
Se solicitó a cada voluntario realizar las siguientes tareas de voz orientadas a la evaluación de tres dimensiones del habla: fonación, articulación y prosodia [19]:
Vocales sostenidas: consistió en pedirle al participante que pronunciara las vocales de forma sostenida durante al menos tres segundos o hasta que se le agote el aire:
\a\, \e\, \i\, \o\, \u\. Repitiendo el ejercicio tres (3) veces.
Tareas diadococinéticas (DDK): se le solicitó al participante que repitiera rápidamente las siguientes palabras y sílabas:
a) \pa-ta-ka\
b) \pa-ka-ta\
c) \pe-ta-ka\
d) \pa\
e) \ta\
f) \ka\
Lectura: se le requirió al participante que leyera el siguiente párrafo, haciendo las respectivas pausas y entonaciones donde indiquen los signos de puntuación, interrogación y exclamación:
“Ayer fui al médico. ¿Qué le pasa? Me preguntó. Yo le dije: ¡Ay, doctor! Donde pongo el dedo me duele. ¿Tiene la uña rota? Sí. Pues ya sabemos qué es. Deje su cheque a la salida”.
Esta lectura es fonéticamente balanceada y contiene todos los fonemas del español hablado en Colombia [20].
Monólogo: consistió en que el participante hablara acerca de las actividades que realiza en un día común.
Las señales de los pacientes fueron etiquetadas por el experto en fonoaudiología de acuerdo con sospecha de voz húmeda, disfonía o voz con alteración no determinada.
2.3 Preprocesamiento
Con el fin de eliminar sesgo a causa del ambiente acústico, se aplicó una normalización de canal basada en la compresión GSM full-rate, utilizando el software Sound eXchange (SoX). Su tasa de bits se redujo a 13 bps, submuestreó a 8 kHz, y se filtró entre 0,2 kHz y 3,4 kHz.
2.4 Extracción de características
Se extrajeron distintas características de los registros de habla asociados a las dimensiones del habla mediante Python y la librería Parselmouth [21], la cual permite acceder de manera indirecta a la interfaz de Praat [22]. A continuación, se describen las características asociadas a cada dimensión del habla.
Fonación: estudiada principalmente en las vocales sostenidas, se entiende como el análisis que se realiza al primer momento de la producción vocal [23]. En ocasiones referido como el análisis acústico de la voz, los descriptores que se evaluaron en este estudio son: F 0 , Jitter, Shimmer, los cocientes de perturbación temporal o de amplitud (PPQ y APQ, respectivamente) y la intensidad de la señal o energía en forma logarítmica, estudiados en [19].
F 0 es la frecuencia fundamental de vibración de los pliegues vocales [24]. Para hallarla, se utilizó el método desarrollado por Paul Boersma [25], [26]. Adicionalmente, se hallaron la primera y segunda derivadas de F 0 , es decir, ∆F 0 y ∆2 F 0 , respectivamente, donde ∆F 0 representa el cambio entre ventanas, mientras que ∆2 F 0 representa el cambio entre ventanas de la primera derivada, que se interpretan como la velocidad y la aceleración de la característica, respectivamente [27], [28].
La intensidad o energía de la señal es extraída de forma logarítmica, tal como se describe en (1). Representa la intensidad de la señal y está expresada en decibelios (dB).

donde N es el número de muestras en la i-ésima ventana y s es el valor de la señal en el k-ésimo punto.
El Jitter permite medir las perturbaciones temporales que se presentan en las señales de voz. La ecuación (2) describe la forma de calcular Jitter.
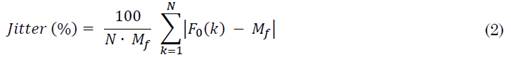
Donde N corresponde al número de ventanas, M f es el valor máximo del pitch de la señal y F 0 (K) es el valor del pitch en la k-ésima ventana.
Por otro lado, el Shimmer permite estimar las perturbaciones en la amplitud y se calcula con (3).
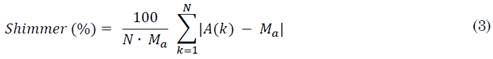
Donde N corresponde al número de ventanas, M a es el valor máximo de la amplitud de la señal y A(K) es el valor de la amplitud en la K-ésima ventana.
Los cocientes de perturbación, ya sea de amplitud o de F 0 (APQ o PPQ), son medidas empleadas para estimar la variabilidad de la amplitud pico a pico o F 0 de la señal, y se calcula con (4),
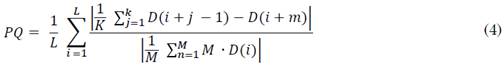
donde L=M -(K -1), D(i) corresponde a la secuencia del período de F 0 o amplitud según corresponda (PPS, cuando se calcula PPQ, y PAS, cuando se calcula APQ), M es la longitud de la PPS o PAS, K es la longitud de la media móvil (normalmente 11 para APQ y 5 para PPQ), y m=(K -1)/2.
Para estos descriptores se empleó el método de ventana deslizante con un tamaño de ventana de 40 ms y una superposición del 50 %, a excepción del APQ y PPQ, en donde se utilizó un tamaño de ventana de 150 ms.
Articulación: esta dimensión hace referencia al movimiento muscular de los articuladores del tracto vocal, en el que los cambios de posición de estos producen diferentes sonidos y resonancias [29]. En el estudio de la articulación se emplearon tanto acercamientos espectrales como cepstrales y se realizó sobre vocales sostenidas y en habla continua:
a) Articulación en vocales sostenidas: en el dominio espectral se determinaron los formantes F1 y F2 que permiten rastrear la apertura mandibular y posición lingual, respectivamente [30]. En términos de estas características, las vocales \a\, \i\ y \u\ representan los movimientos articulatorios extremos, por lo que reciben el nombre de “vocales de las esquinas del triángulo vocal”, estudiadas en [31], [32], [33]. En cuanto al dominio cepstral en el análisis de las vocales sostenidas, se calcularon los coeficientes cepstrales de frecuencia de Mel (MFCC, por sus siglas en inglés), que se pueden entender como la representación del habla que se basa en la percepción auditiva humana [34].
El proceso comúnmente empleado para determinar los MFCC se ilustra en la Figura 2, en donde se aplica un método de ventana deslizante a la señal, posteriormente se calcula el espectro de potencia con la transformada rápida de Fourier (FFT) sobre cada uno de las ventanas, luego se le aplica un banco de filtros a los espectro de potencia y se suma la energía de cada uno, se lleva esta energía a forma logarítmica, después se realiza una transformada discreta coseno (DCT) sobre las energías, para finalmente obtener los coeficientes de frecuencia deseados [35], [36].
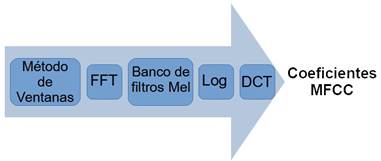
Para el caso del presente estudio solamente se analizaron los primeros 12 MFCC, que son los que se encuentran dentro del rango de frecuencias del habla humana [37]. Para hallar los valores de frecuencia f en Hertz a escala Mel M y viceversa se emplea (5):

b) Articulación en habla continua: contrario al análisis en vocales sostenidas, para el habla continua se calcularon las primeras 22 bandas de energía de Bark (BBE, por sus siglas en inglés) descritas en [38], una escala basada en las transiciones sonoro-insonoro e insonoro-sonoro -offset y onset, respectivamente- [39]. Se plantea el análisis de estas transiciones debido a la producción de sonidos anormales o a la dificultad para iniciar/detener la vibración de las cuerdas vocales que presentan algunos pacientes con otras enfermedades neurológicas de base, como en el caso del párkinson [19], [40].
Las BBE se diferencian de los MFCC en la escala y en las frecuencias utilizadas: mientras que los MFCC emplean la frecuencia de Mel y su comportamiento es netamente logarítmico, las BBE emplean la frecuencia de Bark y su comportamiento es logarítmico en sus primeras bandas y posteriormente lineal, de acuerdo con la ecuación (6):
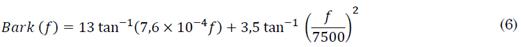
Finalmente, se determinó el contorno del operador de energía de Teager-Kaiser (TKEO, por sus siglas en inglés), tanto para las vocales sostenidas, como para el habla continua. El TKEO es muy sensible a los cambios en la energía de la señal y resulta muy útil al momento de determinar los instantes de activación en una señal [41], [42]. La ecuación (7) se emplea para calcular este descriptor.
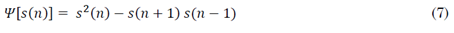
donde s(n) es el valor de la amplitud de la señal en el n-ésimo punto de la señal.
Prosodia: hace referencia a la entonación y sincronización en la producción del habla natural [43]. Los descriptores que se decidieron extraer para esta dimensión son la media, desviación estándar y el máximo de F 0 y la intensidad de la señal. También se compararon segmentos sonoros e insonoros, en donde se evaluó la tasa sonora y la tasa de silencios, (8) y (9) respectivamente, así como la media y la desviación estándar de la duración de los segmentos sonoros e insonoros.


Diadococinesia - DDK: se emplea para estudiar movimientos repetitivos de los órganos articuladores involucrados en el habla [40]. Los descriptores que se calcularon son similares a los de la dimensión de la prosodia, excepto que en lugar de determinar las tasas sonoras se determinaron las tasas DDK.
2.5 Pruebas estadísticas
Se aplicó la prueba estadística no paramétrica Mann-Whitney U con un nivel de significancia del 5 % (α = 0,05) sobre los grupos de comparación establecidos en tres escenarios propuestos (Ver Figura 3).
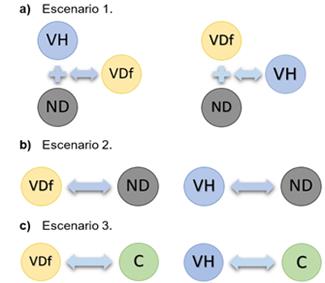
Escenario 1: comparación entre pacientes con una determinada condición clínica vs. los demás pacientes con cualquier otra condición, ej., pacientes con voz húmeda vs. los demás pacientes (voz disfónica y condición de voz no determinada). Lo anterior se ilustra en la Figura 3a).
Escenario 2: comparación entre pacientes con alguna de las condiciones clínicas conocidas (VH o VDf) vs. los pacientes con condición no determinada. El proceso se ilustra en la Figura 3b).
Escenario 3: comparación entre pacientes de alguna de las condiciones clínicas conocidas vs. los sujetos control. La Figura 3c) ilustra el esquema de este escenario.
3. RESULTADOS Y DISCUSIÓN
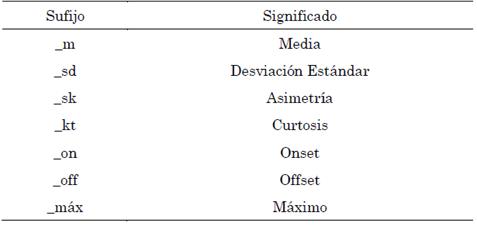
Con el fin de hacer más sencilla la lectura e interpretación de los resultados, en la Tabla 2 se observa un listado de sufijos empleados en el reporte de características y su respectivo significado.
3.1 Fonación en vocales sostenidas
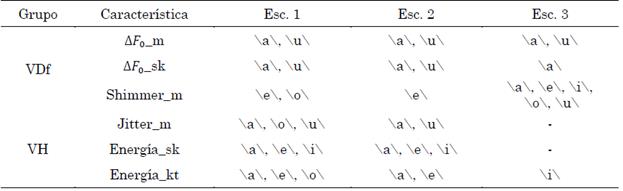
Para el reporte de las características en la dimensión de la fonación se seleccionaron aquellas con diferencias estadísticamente significativas (DES) en dos o más vocales en cualquiera de los escenarios y con p-valor < α.
En la Tabla 3 se muestran las características con el criterio de reporte establecido, en donde cada uno de los grupos evaluados presentaron características estadísticamente diferentes entre sí, es decir, el grupo VDf reporta DES en la media de ∆F 0 y el Shimmer y la asimetría de la ∆F 0 , mientras que el grupo VH las exhibe en la media del Jitter y en la asimetría y curtosis de la energía.
Tabla 3 Características de la fonación con DES en los escenarios evaluados
Fuente: elaboración propia.
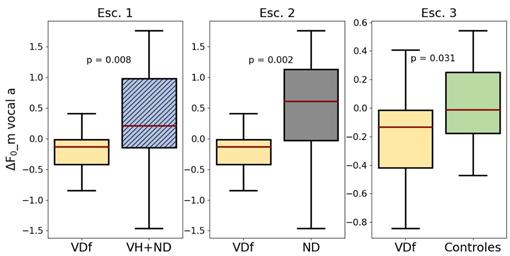
La Figura 4 ilustra la distribución de la media de ∆F 0 de la vocal \a\ del grupo VDf a lo largo de los tres escenarios, en el que se puede apreciar que la mediana de este grupo se encuentra por debajo de la de los datos de los otros grupos de comparación, y que la distribución del grupo VDf en el escenario 2 se encuentra por debajo de la mediana del grupo ND, además de presentar un p-valor inferior al de los otros dos escenarios, lo que sugiere un posible biomarcador. Se plantea que la variación de F 0 en el grupo VDf es menor debido a que la disfonía se relaciona con una disminución en el control de la vibración de las cuerdas vocales [12].
Fuente: elaboración propia.
Figura 4 Distribución de ∆F 0 _ m para la vocal \a\ del grupo de pacientes con VDf en los escenarios evaluados
En contraste con lo hallado en [15], se determinó que hay características acústicas o fonatorias con potencial capacidad de diferenciar entre pacientes y controles, hallazgo similar a lo reportado en [44], además de una posible diferenciación entre pacientes con distintos trastornos de voz. En un análisis preliminar también se emplearon las características que se usaron en este estudio de fonación y en el que presentaron que las combinaciones entre estas características muestran gran potencial en su uso como factores de diferenciación en pacientes con disfagia [45].
3.2 Articulación en vocales sostenidas
En vista del volumen de información a raíz del espacio de características (176 por vocal), se aplicó como criterio de reporte mostrar aquellas características con DES en al menos dos de las vocales de las esquinas del triángulo vocal.
Siguiendo este criterio de inclusión, no se encontraron características del grupo VDf en los escenarios 1 y 2, lo que sugiere que esta dimensión no suministra información para diferenciar entre pacientes con VDf y pacientes con otras condiciones. Sin embargo, se encontraron múltiples características en el escenario 3, como la media y la desviación estándar de los formantes y sus respectivas derivadas, la desviación estándar del TKEO, la media del segundo al séptimo MFCC, entre otros. Esto indica que esta dimensión, más que diferenciar entre condiciones específicas de voz en pacientes, tiene capacidad de discriminación entre pacientes con disfagia y personas sanas.
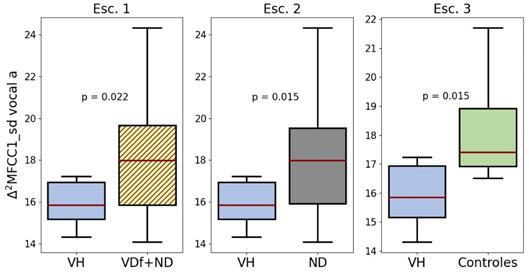
Para el caso del grupo VH, se encontró que solamente la desviación estándar de Δ2MFCC1 cumplió con el criterio de reporte y está presente en todas las vocales de las esquinas del triángulo vocal en los escenarios 1 y 2, mientras que sólo está presente en la vocal \a\ en el escenario 3. Esta característica tiene una DES en todas las vocales de los escenarios 1 y 2 con excepción de la vocal \o\.No se aceptan tablas incrustadas como imagen.
En la Figura 5 se ilustra la distribución de esta característica en la vocal \a\ en los tres escenarios de este grupo, en donde se observa que el comportamiento de las distribuciones es muy similar puesto que las de los datos del grupo VH se encuentran por debajo de la mediana de la distribución de los grupos de comparación en todos los escenarios.
Fuente: elaboración propia.
Figura 5 Distribución de ∆ 2 MFCC1_sd de la vocal \a\ en el grupo VH en escenarios evaluados
Si bien cada una de las vocales también revelaron múltiples características en el grupo VH, muchas de ellas están presente en una o dos vocales a lo largo de los tres escenarios propuestos, por lo que no cumplieron los criterios de reporte establecidos.
3.3 Articulación en habla continua
La Tabla 4 muestra las características relacionadas al habla continua con una DES. Como criterio de reporte se estableció que la característica presentara DES significativa en al menos dos escenarios, en cualquier tarea de voz, sea monólogo o lectura.
Tabla 4 Características de la articulación del habla continua con DES en los escenarios evaluados
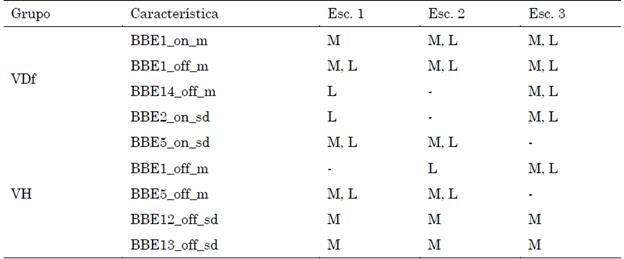
Nota: M: Monólogo; L: Lectura.
Fuente: elaboración propia.
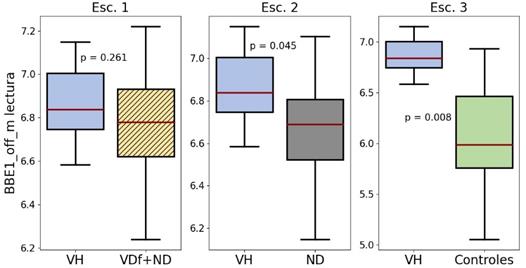
Se puede apreciar que los grupos VDf y VH solo tienen como característica común la media de la energía de la primera banda de Bark en offset (BBE1_off_m). Mientras que en VDf se presenta en las dos tareas en todos los escenarios, el grupo VH solo reportó diferencia en la lectura del escenario 2 y en ambas tareas del escenario 3. Adicionalmente, el monólogo muestra ser la tarea más robusta y consistente, lo cual puede dar lugar a evaluaciones no intrusivas.
La Figura 6 y la Figura 7 ilustran el comportamiento estadístico, esta característica en común en la lectura de texto realizada por los grupos VDf y VH, respectivamente. Se observa que para ambos grupos la mediana de la distribución se encuentra por encima de sus respectivos grupos de comparación, especialmente en el escenario 3, donde la distribución de los grupos VDf y VH se encuentran sobre la mediana de sus grupos de control. Para el caso del grupo VH en el escenario 1, si bien la mediana se encuentra por encima de la del grupo de comparación, la diferencia presentada no es estadísticamente significativa. Estos resultados son similares a las comparaciones en pacientes con EP en [46], indicando una posible extensión de dichos hallazgos en pacientes con disfagia caracterizados por VH y VDf.
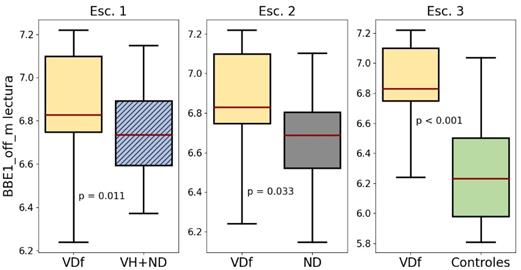
Fuente: elaboración propia.
Figura 6 Distribución de BBE1_off_m de la lectura del grupo VDf en los escenarios evaluados
3.4 Prosodia
Igual que en experimentos anteriores, solo se incluyeron características de prosodia con DES en por lo menos dos de los escenarios evaluados en alguna de las tareas de voz.
La Tabla 5 muestra las características que cumplieron con el criterio de reporte, en el que se puede apreciar que las tres características de la energía presentan DES en alguna de las tareas o escenarios evaluados. La característica con menor incidencia de las tres es la desviación estándar de la energía, pues solo se presenta en el escenario 3 del grupo VH, en ambas tareas. También se puede apreciar que se presenta DES en la energía media del grupo VDf, en ambas tareas en todos los escenarios.
Tabla 5 Características de la prosodia con DES en los escenarios evaluados
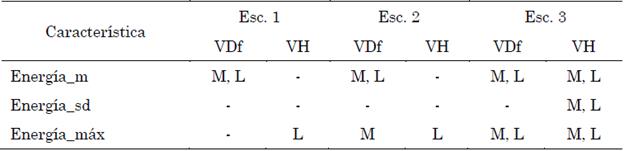
Nota: M: Monólogo; L: Lectura.
Fuente: elaboración propia.
La distribución de la energía media de la lectura del grupo VDf se ilustra en la Figura 8, donde se ve que la mediana de la distribución de este grupo se encuentra por encima de la mediana de los otros grupos de comparación en todos los escenarios, en especial en el escenario 3, donde la mediana del grupo VDf se encuentra por encima de la distribución del grupo de controles y tiene una fuerte DES. Esto puede estar relacionado con el hecho de que los pacientes con VDf deben de hacer un esfuerzo mayor que los demás individuos para realizar la lectura debido a los cambios de entonaciones y fonemas que esta tarea presenta.
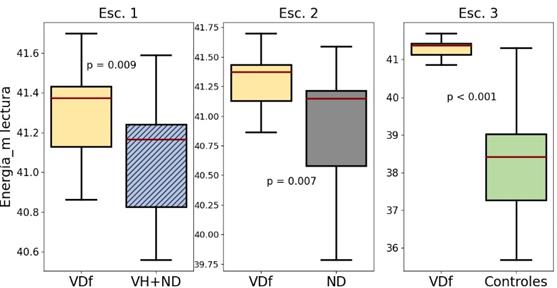
3.5 DDK
En el caso del análisis DDK, el criterio de reporte se estableció en las características con DES en al menos tres de las tareas DDK en cualquiera de los grupos o escenarios evaluados.
En la Tabla 6 se muestran las características que cumplieron con el criterio de selección establecido. Muy similar al análisis de la prosodia, se observa que las tres características de la energía están nuevamente presentes en este análisis, siendo la desviación estándar de la energía la que menos veces presenta DES para alguna de las tareas. También se observó una DES en la media y desviación estándar DDK de las tareas \pe-ta-ka\ y \pa\, pero solamente en los escenarios 1 y 3. Adicionalmente, la energía máxima es la característica que más relevancia presenta en este análisis, teniendo una DES en por lo menos una tarea de los dos grupos en todos los escenarios, exceptuando el escenario 3 del grupo VH.
Tabla 6 Características DDK con DES en los escenarios evaluados.
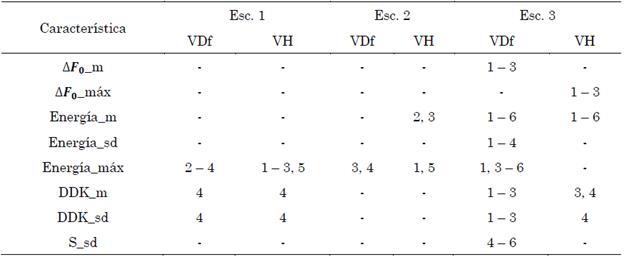
Nota: pa-ta-ka: 1; pa-ka-ta: 2; pe-ta-ka: 3; pa: 4; ka: 5; ta: 6.
Fuente: elaboración propia.
La Figura 9 ilustra la distribución de la energía máxima de la tarea \pa\ del grupo VDf en los escenarios evaluados, en la que se observa que la mediana de la distribución de los datos para este grupo es inferior a la mediana de las de los grupos de comparación, en especial en el escenario 3 donde la distribución del grupo VDf se encuentra cercanamente por debajo de la mediana de la distribución del grupo de control, además de presentar una fuerte DES.
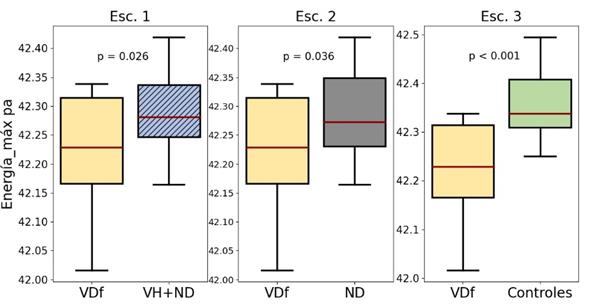
Fuente: elaboración propia.
Figura 9 Distribución de Energía_máx de la tarea DDK \pa\ del grupo VDf en los escenarios propuestos
Se observa que los pacientes tienen una energía menor a la de los grupos de comparación, en especial a la del grupo de control. Esto se relaciona con el hecho de que en los pacientes con VDf se observó que la intensidad de la señal se reduce rápidamente en las tareas DDK.
4. CONCLUSIONES
Se encontraron múltiples características asociadas a las dimensiones del habla con potencial uso, como biomarcadores para la discriminación de diferentes alteraciones de la voz y del habla en pacientes con disfagia. Adicionalmente, se encontró que las características asociadas a la fonación, la prosodia y al análisis DDK son las que mejor permiten diferenciar entre los grupos estudiados, lo que sugiere que un análisis multidimensional logra detectar las variaciones de las cualidades acústicas del habla bajo condiciones de disfagia. Lo anterior es promisorio para realizar abordajes no invasivos y objetivos que mejoren y complementen los métodos disponibles de evaluación de trastornos deglutorios.
5. TRABAJOS FUTUROS
Se plantea ampliar la base de datos construida para reducir sesgos por la diferencia en el número de muestras de los diferentes grupos de comparación establecidos. También se deberá caracterizar el comportamiento bajo condiciones de disartria, condición que se asocia a varias patologías de base que desencadenan disfagia. Adicionalmente, se plantea realizar una evaluación más robusta en la capacidad discriminatoria de las características con DES, modelos basados en reconocimiento de patrones. Finalmente, se podrán establecer escenarios de comparación pre y posdeglutoria, y el seguimiento de las alteraciones de las cualidades para fines de complementación diagnóstica.

