










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkTecnura
Print version ISSN 0123-921X
Tecnura vol.14 no.27 Bogotá July/Dec. 2010
1 Ingeniero Electrónico, Magíster en Teleinformática. Docente de la Universidad Distrital Francisco José de Caldas. Bogotá, Colombia. egomezvargas@udistrital.edu.co
2 Ingeniero Civil. Doctorado en Hidrología. Docente e Investigador de la Universidad Nacional de Colombia. Bogotá, Colombia. nobregon@javeriana.edu.co
3 Ingeniero Electrónico. Estudiante de la Maestría en Ciencias de la Información y las Comunicaciones de la Universidad Distrital Francisco José de Caldas. Bogotá, Colombia. vssocarrasq@correo.udistrital.edu.co
Fecha de recepción: febrero 26 de 2010 Fecha de aceptación: agosto 3 de 2010
Resumen
Este artículo muestra los resultados obtenidos en la exploración de la bondad de la implementación del modelo neurodifuso ANFIS y de las redes neuronales para la predicción de caudales medios mensuales en la cuenca del Rio Bogotá en la ciudad de Villapinzón. Se desarrolla e implementa el modelo ANFIS y se evalúa el comportamiento de seis modelos, al variar el número de entradas, y el número y tipo de conjuntos difusos (funciones de pertenencia), que son los parámetros fundamentales del modelo ANFIS. Los resultados se comparan con los obtenidos con las redes neuronales perceptrón multicapa.
Palabras clave: ANFIS, Inteligencia artificial, Redes neuronales.
Abstract
This paper shows the results in the exploration of the benefits of the implementation of neuro-fuzzy AN-FIS model and neural networks for the prediction of monthly mean flows in the basin of Bogota River in Villapinzón. The ANFIS model is developed, implemented and the performance of six models is evaluated bychanging entries number, number and type of fuzzy sets (membership functions), which are the basic parameters of the ANFIS model. The results are compared with those obtained with multilayer perceptron neural networks.
Key words: ANFIS, Artificial intelligence, Neural networks.1. Introducción
En hidrociencias, específicamente en el área de la hidrología, son de importancia el análisis y la predicción de series de tiempo. Dichas series son registros históricos generalmente obtenidos de la medición de variables hidroclimáticas como la precipitación, la evaporación, el caudal en los ríos, etc.
El análisis y la predicción de series de tiempo permiten obtener información básica para la planeación, diseño y evaluación de hidrosistemas, con base en la optimización del manejo de los recursos hídricos para el bienestar social. Los procesos hidroclimáticos son de tipo no lineal, debido a la complejidad de los fenómenos que los generan, por lo cual se ha hecho necesario implementar herramientas de aproximación para estimar las variables involucradas en dichos procesos.
El reciente avance y desarrollo de modelos computacionales y su aplicación en diversas áreas de la ciencia ha incrementado la implementación de herramientas para resolver problemas y aproximar magnitudes desconocidas. La hidrología no ha sido ajena a este proceso y ha requerido metodologías desarrolladas para otras disciplinas, como la inteligencia artificial. En esta se encuentran los modelos basados en la lógica difusa (LD) y las redes neuronales (RN), las cuales tienen como ventajas el conocimiento de expertos y la facilidad de "razonamiento", para el caso de la LD, y la capacidad de aprendizaje y adaptación de las RN. La combinación de estas ventajas dan origen a los modelos neurodifusos. Para la presente investigación se seleccionó el modelo ANFIS, propuesto por Jang en 1993, debido a la existencia de herramientas enfocadas a la implementación del modelo, específicamente un aplicativo computacional desarrollado en Matlab para la obtención y optimización de los parámetros de ANFIS. El comportamiento de este tipo de modelo es incierto; de allí la necesidad de plantear la pregunta a resolver en esta investigación: ¿Cuál será la bondad de la aplicación del modelo neurodifuso ANFIS a la predicción de caudales medios mensuales? Esto conlleva a determinar si es factible su implementación en hidrología y concretamente en nuestro medio. Para dar respuesta a esta pregunta, se implementará el modelo en la cuenca del Río Bogotá en la Ciudad de Villapinzón.
En la primera parte el artículo se muestra la descripción general de los modelos utilizados para la predicción; posteriormente se analiza la estructura del modelo ANFIS seleccionado para cada modelo y, finalmente, se muestran los resultados obtenidos, comparados con los de las redes neuronales.
2. Modelos de predicción
Es importante mencionar que se decidió predecir caudales medios mensuales, debido a que la información base obtenida tenía resolución mensual. Para el caso de las series de caudal, valores promedio y para el caso de las series de precipitación, valores de precipitación acumulada mensual.
Para la predicción del caudal medio se utilizará la función (1) que depende de los valores de precipitación y caudal predecesores. De forma general, para cualquier número de entradas será así:
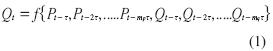
Dónde:
τ : Tiempo de rezago
mp : Dimensión de inmersión en P
mq: Dimensión de inmersión en Q
Aunque existen muchos métodos, como utilizar la correlación, la entropía, y el vecino cercano para estimar el valor más adecuado de τ, mp y mq [1], el presente trabajo se centra en la exploración del modelo ANFIS y las redes neuronales, bajo las mismas condiciones del modelo. Para esto se tomaron seis modelos, los cuales se sometieron a un modelo ANFIS y a las redes neuronales perceptrón multicapa para la correspondiente predicción de caudales medios mensuales.
Modelo 1: Para este modelo se tiene en cuenta solamente el caudal del mes anterior, como se muestra a continuación:

Modelo 2: Para este modelo se tiene en cuenta solamente la precipitación del mes anterior:

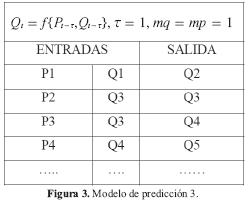
Modelo 3: Para este modelo se tiene en cuenta el caudal medio y la precipitación del mes anterior:
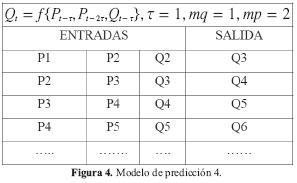
Modelo 4: Para este modelo se tiene en cuenta el caudal medio del mes anterior y la precipitación de los dos meses anteriores:
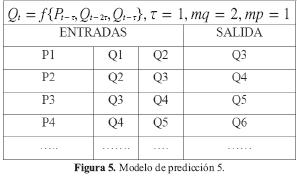
Modelo 5: Para este modelo se tiene en cuenta la precipitación total del mes anterior y el caudal medio de los dos meses anteriores, como se muestra a continuación:
Modelo 6: Para este modelo se tiene en cuenta la precipitación total y el caudal medio de los dos meses anteriores, como se muestra a continuación:
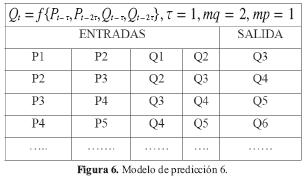
3. Metodología
El modelo ANFIS (Adaptive Network- based in Fuzzy Inference Systems) fue desarrollado por J.R. Jang en 1993 [2]. Las capacidades adaptativas de las redes ANFIS las hacen directamente aplicables a una gran cantidad de áreas como control adaptativo, procesamiento y filtrado de señales y series de tiempo, clasificación de datos y extracción de características a partir de ejemplos. Una propiedad interesante del modelo es que el conjunto de parámetros puede descomponerse para utilizar una regla de aprendizaje.
Para crear modelos ANFIS se pueden utilizar reglas difusas generadas por medio de dos metodologías: una es de manera automática, con la cual se generan reglas de tipo Takagi-Sugeno; la otra es con el algoritmo Wang - Mendel, con el que se construyen reglas de tipo Mandani. Sin embargo, esta última genera un error de pronóstico muy alto [3],lo que hace a la primera metodología más recomendable para esta investigación.
Las reglas difusas del tipo Takagi-Sugeno utilizadas en el modelo ANFIS se representan de la siguiente forma [4]:
Regla n: Si X es An y Y es Bn, entonces fn = pnX + qnY + rn, Donde An y Bn son los conjuntos difusos de entrada y pn, qn y rn son constantes. Para este caso pn y qn son cero, obteniendo un modelo Takagi-Sugeno de orden cero. Las salidas individuales de cada regla son obtenidas como una combinación lineal entre los parámetros del antecedente de cada regla: fn = pnX + qnY + rn, n= 1,2,.... La salida de control del modelo f se obtiene por la normalización de los grados de activación de las reglas por la salida individual de cada regla:
3.1. Estructura del modelo ANFIS
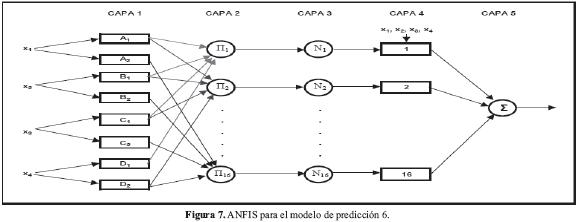
La estructura del modelo ANFIS para el modelo 6 de predicción, se muestra en la Figura 7 y será descrita a continuación:
-
El sistema de inferencia difuso bajo consideración presenta cuatro entradas x1, x2, x3 y x4.Cada entrada tiene dos términos lingüísticos (conjunto difuso), por ejemplo {A1 =bajo, A2 =alto} para la variable de entrada x1. Por consiguiente, hay 16 reglas difusas tipo "if-then", para el modelo 6 de predicción.
-
Para este ejemplo de cuatro entradas y para el caso del Modelo Difuso TSK de Primer Orden, una primer regla sería de la forma, Regla 1: Ifx1 es A1 and x2 es B1 and x3 es C1 and x4 es D1, then f1=p11*x1 + p12*x2 + p13*x3 + p14*x4 +pl, el superíndice en el coeficiente p denota el número de la regla, y los parámetros p11, p21, p13, pl4 y p11 son los parámetros consecuentes.
-
Se denota la salida del i-ésimo nodo en la capa k como Oki. Cada nodo de la capa 1 puede ser cualquier función de activación parametrizada µA(x), como por ejemplo la función "campana" generalizada, µA(x)=1/(1+1(x-c)/a|)2b, donde las constantes a, b y cson referidas como los parámetros "de premisa" o "antecedentes".
-
La función en cada nodo (regla) en la capa 2 genera como salida el producto de todas las entradas, en términos de la evaluación de las funciones de membresía respectivas que estipule la regla. Así, para: i=1,2,...,16,
-
En la capa 3, la función de un nodo fijo se usa para normalizar las "fortalezas activadas de entrada".
-
Cada nodo en la capa 4 es una función parametrizada dada por:
-
Para la capa 5 solo hay una salida, que es el valor aproximado determinado por el modelo (salida calculada).
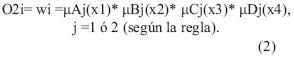
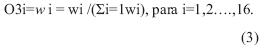
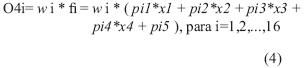
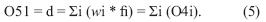
En el proceso de calibración del modelo se obtienen los valores de los "pi" (parámetros consecuentes e la regla TSK y los valores de a, b, c y d (parámetros de premisa), dependiendo del tipo de conjunto difuso con el que se esté trabajando; la red ANFIS permite a los sistemas difusos "aprender" los parámetros, usando el algoritmo de aprendizaje.
3.2 Aprendizaje del modelo ANFIS
El modelo ANFIS tiene dos tipos de parámetros que deben ser entrenados:
-
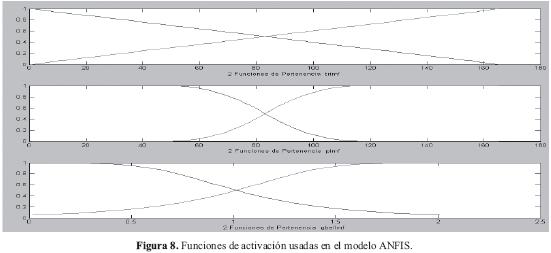
Los parámetros de los antecedentes, los cuales corresponden a las constantes que caracterizan las funciones de activación de los conjuntos difusos. En la siguiente figura se muestran tres tipos de funciones de activacion usadas en el modelo ANFIS:
-
Los parámetros del consecuente (VT). Estos son parámetros lineales de la salida del modelo de inferencia. El paradigma de aprendizaje del modelo ANFIS emplea algoritmos de gradiente descendente para optimizar estos parámetros y el algoritmo de mínimos cuadrados para determinar los parámetros lineales del VT. A esta combinación se le conoce como regla de aprendizaje híbrido, la cual es usada en el aprendizaje de este modelo [5].
Ahora se aplica lo descrito en [5] y [6], en donde para aplicar el aprendizaje híbrido en grupo en cada periodo de entrenamiento debe ejecutarse un paso hacia adelante y un paso hacia atrás. En el paso hacia adelante, los parámetros de las funciones de los conjuntos son inicializados y se presenta un vector de entrada-salida. Se calculan las salidas del nodo para cada capa de la red y, entonces, los parámetros de la VT son calculados usando el método de mínimos cuadrados. Una vez identificados los parámetros de la VT, el error es calculado como la diferencia entre la salida de la red y la salida deseada presentada en los pares de entrenamiento. En este caso se usa una de las medidas más empleadas para calcular el error de entrenamiento, que es la suma del error cuadrado (SEC), definido como:
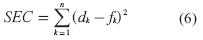
Los dk corresponden a los patrones de entrenamiento proporcionados (salidas deseadas) y fk es la correspondiente salida de la red. En el paso hacia atrás, las señales de error son propagadas desde la salida, en dirección de las entradas y el vector gradiente es acumulado para cada dato de entrenamiento. Al final del paso hacia atrás para todos los datos de entrenamiento, los parámetros en la capa 1 (parámetros de los conjuntos) son actualizados por el método descendente en una magnitud Δα igual a:
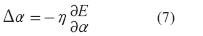
Donde E es el error de salida y η es la velocidad de aprendizaje, que puede ser expresada como:
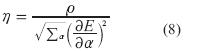
Aquí p es el tamaño del paso, o sea la longitud de cada transición a lo largo de la dirección del gradiente en el espacio de parámetros. Generalmente se puede cambiar el valor de p para variar la velocidad de convergencia de la siguiente manera: si p es pequeño, el método del gradiente aproxima de cerca la trayectoria del gradiente, pero la convergencia será lenta puesto que el gradiente se debe calcular muchas veces. Por otra parte, si p es grande, la convergencia será inicialmente muy rápida, pero el algoritmo oscilará sobre el grado óptimo. De acuerdo con estas observaciones, se actualiza p según las siguientes reglas heurísticas:
-
Si la medida del error experimenta cuatro reducciones consecutivas, se aumenta p en el 10%.
-
Si la medida del error experimenta dos combinaciones consecutivas de un aumento y de una reducción, se disminuye p en un 10%. Sin embargo, los valores de cuatro reducciones, dos combinaciones y el aumento o disminución de p en el 10% son elegidos de manera un poco arbitraria, aunque, como se observa más adelante, muestran un buen resultado en la respuesta de la VT; lo importante es no escoger un valor inicial de p muy grande, para que este no sea critico [7].
3.3. Estructura de las redes neuronales seleccionadas
Para verificar los seis modelos de predicción seleccionados, se utilizó también además del ANFIS, un perceptrón multicapa (PMC), que es una red neuronal artificial (RNA) formada por múltiples capas que permiten resolver problemas que no son linealmente separables, lo cual es la principal limitación del perceptrón (también llamado perceptrón simple). El perceptrón multicapa puede estar totalmente o localmente conectado. En el primer caso cada salida de una neurona de la capa "i" es entrada de todas las neuronas de la capa "i+1", mientras que en el segundo caso cada neurona de la capa "i" es entrada de una serie de neuronas (región) de la capa "i+1".
Las capas pueden clasificarse en tres tipos:
-
Capa de entrada: Constituida por aquellas neuronas que introducen los patrones de entrada en la red. En estas neuronas no se produce procesamiento.
-
Capas ocultas: Formada por aquellas neuronas cuyas entradas provienen de capas anteriores y cuyas salidas pasan a neuronas de capas posteriores.
-
Capa de salida: Neuronas cuyos valores de salida se corresponden con las salidas de toda la red.
En la siguiente figura se observa la estructura de la red para el modelo de predicción 6:
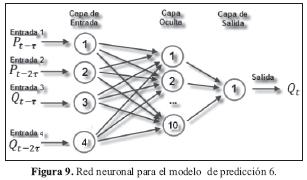
El algoritmo utilizado en el entrenamiento de estas redes es la propagación hacia atrás (también conocido como retropropagación del error o regla delta generalizada); por ello, el perceptrón multicapa también es conocido como red de retropropagación.
4. Resultados
Para el desarrollo del presente trabajo se utilizó el software MATLAB, para el diseño y entrenamiento tanto del sistema ANFIS como de las redes neuronales. En las siguientes tablas se muestran los resultados de entrenamiento y de verificación de la correlación entre la salida deseada y la calculada, para todos los modelos de predicción utilizados. Para la verificación del modelo se tomaron una serie de patrones diferentes a los utilizados en el entrenamiento.
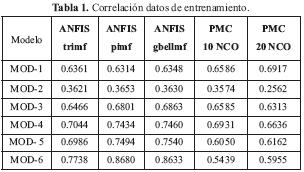
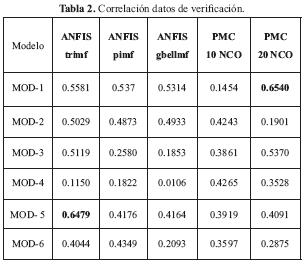
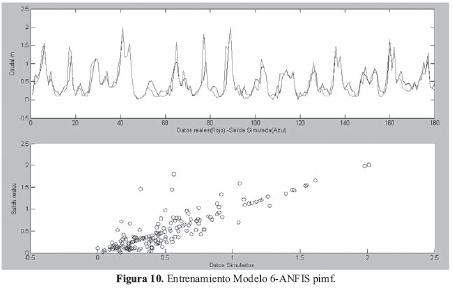
Para el entrenamiento de los sistemas se tomaron un total 500 patrones. Se puede apreciar que el mejor resultado con datos de entrenamiento se obtuvo con el modelo 6 y el sistema ANFIS, que usando la función de activación "primf' (campana) tuvo una correlación de 0.868. El modelo 6 tiene en cuenta los dos meses anteriores tanto en precipitación como en caudal y la diferencia en la correlación es significativa con respecto a los otros modelos. En la Figura 10 se puede apreciar la comparación de los datos de entrenamiento deseados y los calculados por el modelo ANFIS de mejor resultado.
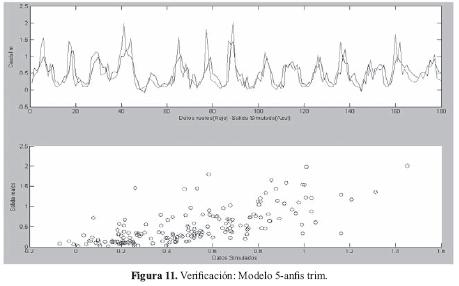
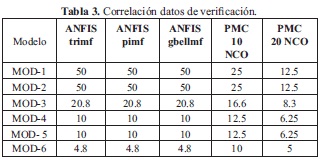
El mejor resultado con los datos de verificación se obtuvo con el modelo 5 y el sistema ANFIS usando la función de activación "trim" (rampa). En la Figura 11 se puede apreciar la comparación de los datos de verificación deseados y los calculados por el modelo ANFIS de mejor resultado.
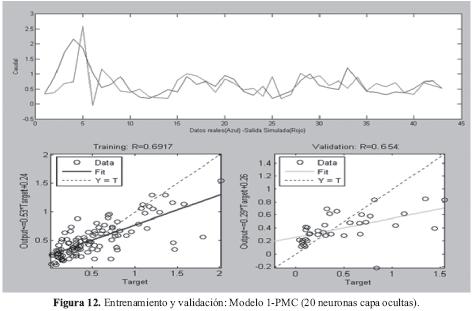
En el caso de los sistemas PMC, se observa que el mejor resultado con datos de entrenamiento y verificación se encontró con el PMC de 20 neuronas en la capa oculta y el modelo 1, el cual tiene en cuenta solamente el caudal del mes anterior. Los resultados gráficos de los datos deseados y calculados para esta red neuronal se pueden apreciar en la Figura 12.
En términos generales se observa que en la mayoría de los modelos el comportamiento del sistema ANFIS es mejor que el del PMC. Esta situación se puede evidenciar en las siguientes gráficas (Figuras 13 y 14) en donde se muestra el desempeño de cada sistema diseñado en cada uno de los modelos de predicción.
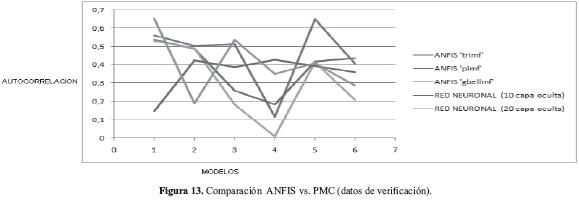
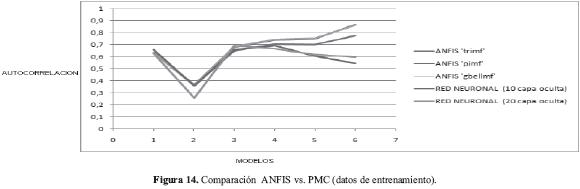
En las gráficas anteriores se puede apreciar que con los datos de verificación, en términos generales, son más estables a través de los diferentes modelos los diseños PMC que los ANFIS. Con respecto a los datos de entrenamiento, el comportamiento de todos los diseños fue muy similar en términos generales. De igual forma es importante evidenciar que de los modelos de predicción seleccionados el modelo 2 fue el de peor resultado con los datos de entrenamiento, mientras que el modelo 4 fue el menos acertado con los datos de verificación.
4.1. Análisis de parsimonia de los modelos
En la Tabla 3 se muestra el resumen del factor de compresión (relación entre el número de patrones y el número de parámetros) da cada uno de los modelos diseñados. Para el caso del modelo ANFIS el número de parámetros tiene en cuenta los parámetros antecedentes y los parámetros consecuentes. La siguiente expresión permite el cálculo del número de parámetros en un sistema ANFIS [8].
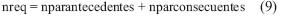
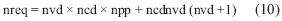
Dónde: nvd es el número de variables difusas, ncd el número de conjuntos difusos y npp es el número de parámetros que definen la función de pertenencia del conjunto.
De la tabla anterior se puede concluir en términos generales que, para las condiciones dadas en este trabajo, son necesarios un número similar de parámetros en ambos sistemas (PMC y ANFIS), lo cual resalta aún más los resultados de correlación obtenidos en los sistemas neurodifusos.
5. Conclusiones
En términos generales las mejores predicciones (asociadas al proceso de validación) realizadas con ANFIS y PMC a caudales medios mensuales presentan una correlación promedio de 0.64, valor moderadamente aceptable. Los resultados de las mejores combinaciones de calibración presentan coeficientes de correlación superiores a 0.8 para el ANFIS y 0.7 para el PMC, demostrando la facilidad que tienen este tipo de modelos para encapsular la información que le es presentada.
La ventaja de ANFIS frente a las PMC es su flexibilidad, ya que permite generar topologías sencillas para contar con un número de registros restringido y topologías más complejas para tener bastante información. Para el caso de la validación se recomienda tener entre una y tres variables difusas, y dos o tres conjuntos difusos son suficientes; para el caso de la calibración se pueden incrementar el número de conjuntos difusos y el número de variables difusas. Definir un tipo de conjunto difuso que describa de una manera generalizada el comportamiento de las serie de caudal es complicado, ya que este depende de los datos que se desea modelar.
Se recomienda, a la hora de implementar este modelo, diseñar estructuras o topologías sencillas; realmente la precisión no siempre aumenta al incluir mayor información, o al usar muchas variables de entrada. Lo fundamental es determinar previamente cuáles serán las posibles mejores entradas.
Referencias bibliográficas
[1] S. Infante, J. Ortega, F Cedeño, "Estimación de datos faltantes en estaciones meteorológicas de Venezuela vía un modelo de redes neuronales", Revista de Climatología, Departamento de Matemáticas, Facyt, Universidad de Carabobo, 2008. [ Links ]
[2] J. S. Jang, "ANFIS: Adaptive-Network-based Fuzzy Inference Systems", IEEE Transactions on Systems, Man, and Cybernetics, Vol. 23, 1993. [ Links ]
[3] Y. Mendoza, A. Mazo, F Cedeño. (2009). "Análisis del modelo ANFIS en el pronóstico de un título de renta variable", Facultad de Minas, Universidad Nacional De Colombia, pp. 44-45. [En línea]. Disponible: http://www.bdigital.unal.edu.co/803/l/1052942363_2009.pdf [ Links ]
[4] M. Wiering, J. Vreeken, J. Van Veenen, A. Koopman, "Simulation and optimization of traffic in a city", IEEE Intelligent Vehicles Symposium (1V'04).1EEE.A system level study. Technical Report 1991-09-01, 2004. [ Links ]
[5] T. Takagi, M. Sugeno, "Derivation of fuzzy control rules from human operator's control actions", Proceedings of the IAFC Symposium on Fuzzy Information, Knowledge Representation and Decision Analysis, 1983, pp. 55-60. [ Links ]
[6] S. Zak, Systems and Control. Oxford: Oxford University Press, 2003. [ Links ]
[7] J-S. R. Jang "Input Selection for ANFIS Learning", IEEE International Conference on Fuzzy Systems, New Orleans, 1996. [ Links ]
[8] C. Plazas, N. Obregón, "Aplicación de un modelo neurodifuso ANFIS al problema predictivo de caudales medios mensuales en la ciudad de Bogotá", Tesis de Postgrado Aprovechamiento de Recursos Hidráulicos. Universidad Nacional De Colombia, Bogotá, 2006. [ Links ]

