










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkTecnura
Print version ISSN 0123-921X
Tecnura vol.16 no.31 Bogotá Jan./Mar. 2012
Software basado en agentes inteligentes y servicios web para búsqueda de productos en la web
Intelligent-agents-based software and web services for products searchover the internet
Yeismer Espejo Bohórquez1, Magaly Téllez2, Jorge Enrique Rodríguez3
1 Ingeniero en Telemática. Coordinador de Desarrollo de Investigación y Tecnología S.A. Bogotá, Colombia. yespejo@invytec.com
2 Ingeniera en Telemática. Coordinadora de Desarrollo de Investigación y Tecnología S.A. Bogotá, Colombia. magtel_1@yahoo.es
3 Ingeniero en Sistemas, magíster en Ingeniería de Sistemas. Docente de la Universidad Distrital Francisco José de Caldas. Bogotá, Colombia. jrodri@udistrital.edu.co
Fecha de recepción: 5 de Mayo de 2011 Fecha de aceptación: 28 de Noviembre de 2011
Resumen
La localización y recuperación de la información en la Web es uno de los principales retos en la actualidad. Existen diferentes herramientas que permiten la búsqueda de información en la Web: los motores de búsqueda, los índices temáticos o directorios y los metabuscadores. Estas aplicaciones pese a los problemas de poca exhaustividad, baja precisión y el gran porcentaje de recursos repetidos e inactivos que arrojan son las más utilizadas a la hora de comparar productos y precios en la red. Existe otra aproximación que pretende obtener resultados mucho más precisos, basándose en el uso de agentes inteligentes que rastrean la red según las necesidades informativas del usuario.
Palabras claves: Agente inteligente, agente móvil, buscador, recuperación de información.
Abstract
The location and retrieval of information on the web is one of the greatest challenges today. There are different tools to find information on the web: search engines, indexes, directories and thematic or metasearch. These applications despite the low completeness problems, low accuracy and high percentage of repeat and inactive resources are throwing the most commonly used when comparing products and prices on the net. Another approach that seeks to obtain much more accurate results based on the use of intelligent agents that crawls the network as the user's information needs.
Keywords: Intelligent agent, mobile agent, Search, Information retrieval.
1. Introducción
A pesar del crecimiento y el desarrollo de tecnologías existentes que facilitan la búsqueda de información en la Web, aún existen ciertas limitaciones en cuanto a la calidad de la información obtenida y el tiempo invertido en ello. Los mecanismos para aumentar la precisión en la búsqueda (refinamientos, búsquedas avanzadas, acotación por dominios, etc.), a veces, no funcionan como se espera, a ello, hay que añadir el mínimo valor de algunos de los sitios Web recuperados, el porcentaje de recursos repetidos y el porcentaje de recursos inactivos (que ya no existen físicamente en la red aunque continúan indexados). Esto implica que un usuario debe dedicar una considerable cantidad de tiempo y esfuerzo en revisar o navegar a través de una lista ordenada de páginas, donde normalmente varias de ellas no son de su interés, antes de encontrar información verdaderamente relevante. Como una alternativa aparece el concepto de agentes inteligentes. Estos pueden asistir activamente al usuario proveyéndole información personalizada mientras navega o realiza sus actividades normales en la Web. Mediante agentes inteligentes se puede explorar automáticamente la World Wide Web, con el fin de recuperar las páginas relevantes para unas necesidades informativas determinadas. De esta manera, la formulación de tales necesidades sería parte de las especificaciones iniciales proporcionadas al agente; este exploraría la red, eligiendo los enlaces más prometedores, accediendo a nuevas páginas, recopilando las que pudiesen satisfacer las especificaciones iniciales.
En este artículo se describe cuáles son las herramientas tradicionales para llevar a cabo la búsqueda de información de productos vía Web y cómo la utilización de agentes inteligentes se ha convertido en una opción de creciente desarrollo en esta área. De igual manera, se muestra el diseño del sistema multiagente para la búsqueda de productos en línea, junto con un análisis de pruebas y resultados obtenidos. Por último, se plantean algunos trabajos futuros y unas conclusiones.
2. Búqueda y Recuperación de Productos Via Web
En el contexto de Internet se puede definir el objetivo de la recuperación como la identificación de una o más referencias de páginas web que resulten relevantes para satisfacer una necesidad de información. Existen diferentes herramientas que permiten la recuperacion de informacion en la Web, entre los que se encuentran los motores de búsqueda o rastreadores, los indices tematicos o directorios y los metabuscadores. Los buscadores o motores de busqueda son las aplicaciones más utilizadas para encontrar servicios y productos, información y hacer compras en la red. Según un estudio de la compañía Web Side Story el 90% de los enlaces a través de los cuales los usuarios acceden a las tiendas de comercio electrónico proceden directamente de los motores de búsqueda. Google ocupa el primer lugar con un porcentaje del 27.16 %, le siguen Yahoo! (25.92%), MSN (24.11%) y AOL NetFind (15.60%) [1]. Con ello se concluye que cualquier negocio en Internet que no esté localizado a través de los buscadores difícilmente podrá captar usuarios o potenciales clientes. Los motores de búsqueda infuencian también las compras off-line: en Europa, 3 de cada 4 usuarios han afrmado que han buscado en Internet información sobre servicios y productos on-line antes de hacer una compra off-line [2]. Este hecho revela que millones de usuarios están constantemente buscando productos y empresas a través de estas herramientas.
2.1. Los motores de búsqueda
Los motores de búsqueda o buscadores tienen sus antecedentes en los simples listados de direcciones de recursos y documentos de la red, y son la respuesta al rápido volumen de crecimiento de la red, que supera la capacidad de los recursos humanos de los directorios, que por ello suelen ser selectivos. "Los buscadores son bases de datos creadas por indización automática del texto completo de las páginas web, y realizada por un programa llamado robot" [3]. Aun cuando los programas lleguen a ser similares, no existen dos programas de búsqueda exactamente similares en términos de tamaño, velocidad y contenido; no existen dos motores de búsqueda que utilicen coincidentemente el mismo listado de relevancia y tampoco cada motor de búsqueda ofrece las mismas opciones de búsqueda. Por tanto, su búsqueda resultará diferente en cada motor utilizado.
2.1.1. Funcionamiento
El proceso llevado a cabo por cualquier sistema de búsqueda se puede resumir en las siguientes fases: -recogida y análisis de datos (indización o clasificación por categorías), - búsqueda propiamente dicha, y - recuperación.
Los motores de búsqueda suelen utilizar la recogida de datos automática rastreando la red, otros piden la dirección URL para darse de alta. Disponen de un robot que visita y analiza la página principal y todas las páginas enlazadas y que suele ser capaz de leer las etiquetas META o metadatos y extraer toda la información contenida en ellas mediante el lenguaje HTML. Sin embargo, muchas páginas no disponen de tales etiquetas. Con dicha información, el buscador es capaz de indizar palabras clave como el título, idioma, autor, propietario, localización, temas, entre otros.
Elementos de un motor de búsqueda
Robot: las bases de datos de los buscadores se suelen construir utilizando robots, esto es, programas que recorren la Web y recuperan los documentos de forma automática. Normalmente los robots comienzan con un listado de URLs preseleccionadas y visitan periódicamente los documentos en ellas referenciados.
Indexador: se trata de un programa que recibe las páginas recuperadas por un robot (muchas veces el robot y el indexador son el mismo programa), extrae una representación interna de la misma y la vuelca en forma de índice en una base de datos. Motor de búsqueda: programa que se encarga de analizar una consulta de usuario y buscar en el índice los documentos relacionados. Los motores de búsqueda suelen estar implementados mediante alguna de las tecnologías que permiten a los programas interactuar con los datos enviados sobre HTTP, por ejemplo CGI, Servlets, ASP, CFML, etc. Interfaz: la interfaz más utilizada es la basada en páginas Web con formularios.
Los directorios o índices temáticos. Un directorio es, básicamente, una lista alfabética de materias que puede ser subdividida más ampliamente hasta llegar a los recursos que se almacenan en el directorio [4]. Las búsquedas se hacen descendiendo a través de estos encabezamientos y subencabezamientos hasta llegar a la información deseada. Los directorios se exploran mediante la navegación (browsing) de una base de datos de documentos web compilados, recogidos y organizados manualmente por expertos. La búsqueda jerárquica sirve al usuario de guía, permitiendo acceder a la información en el contexto temático al que pertenece y en relación con otras áreas temáticas.
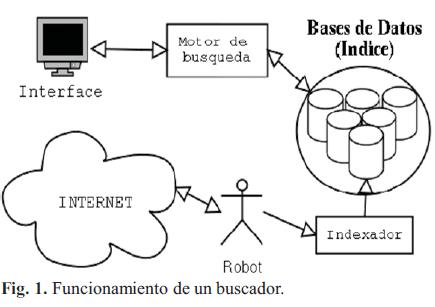
Los directorios también presentan un motor de búsqueda interno para localizar directamente re cursos de la base de datos, mediante diferentes ecuaciones de búsqueda y palabras clave, obviando de esta manera el uso del directorio temático. Los sistemas de búsqueda por palabras pueden actuar de dos maneras:
- Sobre la clasificación, en una sección de ella (cuando, por ejemplo, se sabe en qué parte del directorio se puede localizar la información que es de interés)
- Sobre las páginas, pero en este caso se limitan a la información recopilada por el índice (fundamentalmente sitios web, no páginas).
Así pues, la búsqueda de información en los directorios puede hacerse de forma guiada, mediante clasificaciones jerárquicas, o a partir de términos específicos. Los directorios más comunes son aquellos que ofrecen una navegación por temas, y con una cobertura generalista, como por ejemplo Yahoo! (Yet Another Hierarchical Officious Oracle). Sin embargo, también existen directorios que permiten, una navegación geográfica (Virtual Tourist http://www.virtualtourist.com) o directorios especializados. Los servicios de consulta basados en directorios han ido incorporando prestaciones, y han evolucionado hacia lo que actualmente se llaman portales, un conjunto de servicios que pretende satisfacer todas las necesidades de los usuarios de Internet (cuentas de correo electrónico, chat, páginas amarillas y blancas, información meteorológica y de la bolsa, servicio de noticias).
3. Uso de Agentes inteligentes en la búsqueda de productos en la web
La verdadera y generalizada utilización de agentes inteligentes para beneficios de búsqueda de productos en comercio electrónico irá precedida de un cambio en la metodología de publicación de contenidos en Internet. Hoy los sitios web publican información para personas, mañana publicaran información para ordenadores. Por un lado los compradores y los vendedores necesitan intercambiar diferentes documentos: facturas, listas de precios, etc. y necesitan que exista una interacción automática. Por otro lado las aplicaciones de comercio electrónico necesitan extraer información de los diversos recursos web para comparar precios, localizar productos, etc. Tareas que actualmente no pueden ser llevadas a cabo en sitios web implementados con HTML, al contrario, el lenguaje XML posibilita la disponibilidad de la información web para máquinas. Los agentes pueden actuar en la Web como representantes de las personas. De esta manera, si un cliente quiere comprar algo en Internet, un agente puede realizar la búsqueda y compra del producto deseado por él, Fig. 2. De alguna forma el usuario delega en el agente, después de haberle facilitado algunas instrucciones (por ejemplo, indicándole qué clase de información se desea). Se deja al agente hacer su trabajo de forma autónoma y tomándose su tiempo, en espera de que en un plazo razonable (el propio usuario podría establecer plazos máximos) entregue el resultado de su trabajo, esto es, las páginas web encontradas útiles para satisfacer las necesidades de información expresadas por el usuario. El uso de estos agentes permite a un comprador reducir la búsqueda del producto en numerosas tiendas en línea simultáneamente, de forma que se crean mercados económicamente eficientes a partir de diversas ofertas. Esto creará un ambiente donde las compañías sean más ágiles y los mercados consigan una eficiencia perfecta [5]. Hasta el momento se han desarrollado varios agentes inteligentes para búsqueda de productos en comercio electrónico. Entre ellos se encuentran los shopbots, los cuales pueden obtener información sobre el precio de un producto en los diferentes sitios web y comparar la oferta de los distintos competidores, normalmente ordenada de acuerdo con un criterio elegido por el usuario. Los shopbots simplifican la ardua tarea de buscar y comparar productos y precios. Entre los tipos de agentes utilizados para el comercio electrónico se encuentran: agentes de recomendación, agentes de compra comparativa, agentes notificadores, agentes observadores, agentes de negociación.
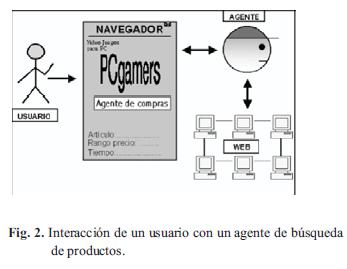
Los agentes inteligentes se han convertido en software básico para ayudar a las compañías a dirigirse a su mercado, pues con ellos se logra conocer los intereses más profundos de los clientes por medio de sus patrones de navegación, y así el agente determina qué información mostrarles dependiendo de sus intereses [6]. En los últimos tiempos están surgiendo un conjunto de proyectos que pretenden ir más allá de los meros agentes para la búsqueda, recuperación, filtrado y comparación de productos y ofertas en el marco del comercio electrónico, sino que suponen un nuevo mercado basado en agentes. El Swedish Institute of Computer Science propone una infraestructura de mercado basada en agentes denominada SICS MarketSpace. En esta infraestructura los agentes soportan todo tipo de usuarios y servicios,ayudan a los clientes y a las tiendas electrónicas a encontrar perfiles de su interés (matching), y cuando se desee son capaces de negociar y cerrar tratos. La infraestructura es totalmente abierta y descentralizada, cualquier participante puede jugar cualquier rol en el mercado [7]. El núcleo de SICS Market-Space es un modelo de informacion para describir intereses de usuario, items, contrato, etc.. y un modelo de interaccion que define un vocabulario básico para la búsqueda.
2. Metodología
El sistema de agentes inteligentes propuesto para la búsqueda de productos en línea está integrado por dos subsistemas: Un subsistema de Gestión de Clientes donde se ejecutarán los procesos de gestión de usuario, y un subsistema de Agentes, donde se llevarán a cabo las tareas de búsqueda de productos, optimización de productos, administración de preferencias y monitoreo de agentes.
4.1. Arquitectura global del sistema
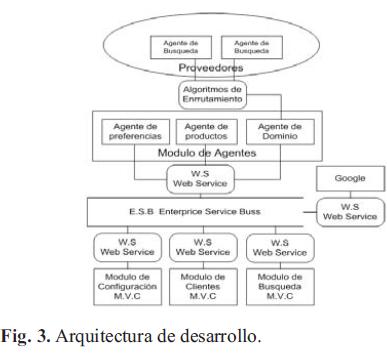
La arquitectura global del sistema está basada en Servicios Web, Agentes Inteligentes y Aplicaciones Web. (Fig. 3). A continuación se detalla cada componente que participa dentro de la arquitectura:
ESB: es la columna vertebral del sistema, ya que es el encargado de administrar la comunicación entre todos los módulos, esta comunicación se realiza basada en servicios WEB.
Módulo de configuración: módulo donde se realiza toda la configuración básica del sistema para su posterior uso por parte de los clientes.
Módulo de clientes: permite configurar la información general de todos los clientes información del usuario, perfil, búsquedas y preferencias de los mismos.
Módulo de búsqueda: encargado de entregar la información de los productos al usuario por medio del sistema o consultas remotas generadas a solicitud del sistema de agentes.
Agente de preferencias: administra las preferencias y sugiere nuevas búsquedas o productos con base en el conocimiento adquirido de cada cliente o del entorno, puede en dado momento modificar las preferencias del usuario si no concuerdan con las búsquedas realizadas por el usuario o si el entorno de la gente obliga a cambiarlas para mejorar la productividad del sistema.
Agente de productos: se encarga de optimizar las búsquedas realizadas por el usuario con base en la información percibida del entorno, y de entregar los resultados basados en conceptos de calidad, precio y especificaciones y horarios de entrega de los productos toda esa información el agente la aprenderá y debe estar mejorándola constantemente, dependiendo de cómo se comporte el entorno.
Agente de dominio: administra la búsqueda de cada uno de los agentes basado en la información generada por el usuario, y por el agente de productos se encargará de manejar el Dominio de área y de garantizar que no se entregue información de los proveedores que no se encuentran disponibles por medio de servicios web, será el sistema que realice el seguimiento de los agentes de búsqueda básica, manejar los algoritmos de enrutamiento y gestionar que todos los agentes sean atendidos al momento de entregar la información.
Agente de búsqueda: consulta las diferentes tiendas de los proveedores y recoger la información de la búsqueda solicitada, entregándola al agente de suscripción para su respectiva organización de acuerdo con las preferencias.
4.2. Diseño del sistema de agentes inteligentes
4.2.1. Definición de la arquitectura
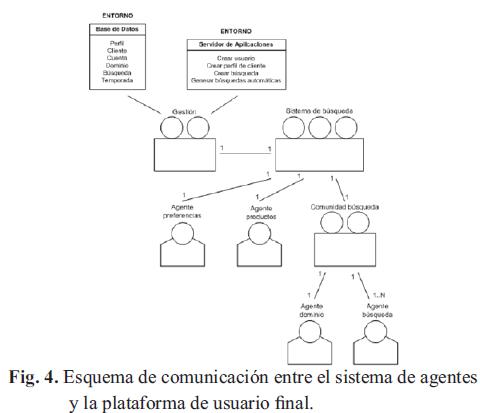
El Sistema de Multiagente (Fig. 4) está integrado por el Agente Preferencias, el Agente Productos y un sub-sistema de búsqueda compuesto por el Agente Dominio y uno o varios Agente Búsqueda.
4.2.2. Plataforma JADE
JADE (Java Agent Development Framework) es un middleware desarrollado por TILAB para el perfeccionamiento de aplicaciones distribuidas multiagente. JADE proporciona, tanto el entorno de desarrollo para la creación de aplicaciones basadas en agentes como el entorno de ejecución [8]. Fue desarrollada bajo la filosofía Open Source para el impulso de aplicaciones distribuidas basadas en agentes que cumplen con las especificaciones de la FIPA (Foundation for Intelligent Physical Agents). El proyecto JADE comenzó en 1998, y la primera versión (v. 1.3) estuvo lista en febrero del 2000, y fue lanzada bajo licencia LGPL. JADE se puede ejecutar en un amplio rango de ambientes: desde los empresariales, hasta en dispositivos móviles (PDA's y teléfonos móviles) gracias a una extensión (API) que se desarrolló para el proyecto LEAP (Light Weight Extensible Agents Plataform). Los agentes proporcionan servicios, cada agente puede buscar a otros dependiendo de los servicios que proporcionen otros agentes. La comunicación entre agentes se lleva a cabo a través de mensajes asíncronos, es decir, el agente que envía el mensaje y el destinatario del mensaje no tienen por qué estar disponible al mismo tiempo [9]; es más, el destinatario no tiene porqué existir en ese instante.
4.2.3. Arquitectura JADE
La Fig. 5 muestra los principales elementos arquitectónicos de la plataforma JADE. Una plataforma JADE se compone de contenedores de agentes que pueden ser distribuidos por la red. Los agentes viven en contenedores que son procesos que proporciona JAVA junto a todos los servicios necesarios para mantener y ejecutar los agentes [10].
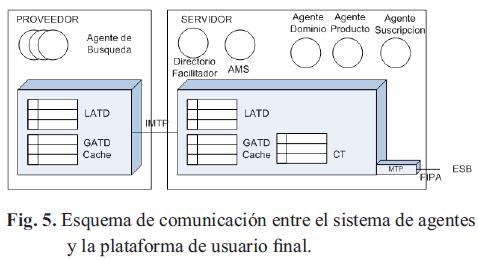
Para nuestro sistema existe un contenedor especial denominado contenedor principal (maincontainer), donde se encuentran el Agente de Dominio, el Agente de Producto y el Agente de Suscripción. Y adicional, hay varios contenedores secundarios donde se ejecutan los Agentes de Búsqueda. El contenedor principal cuenta con los siguientes servicios:
AMS (Agent Management System): proporciona el servicio de nombres asegurando que cada agente en la plataforma disponga de un nombre único. También representa la autoridad, es posible crear y matar agentes en contenedores remotos requiriéndoselo al agente AMS.
DF (Directory Facilitator): proporciona el servicio de Páginas Amarillas. Gracias al agente DF, un agente puede encontrar otros agentes que provean los servicios necesarios para lograr sus objetivos.
CT (Containertable): contiene el registro de las referencias de los objetos y las direcciones de transporte de todos los nodos contenedores que componen la plataforma.
GADT (Global Agent Descriptor Table): registro global de todos los agentes presentes en la plataforma, incluyendo su estado actual y el lugar donde se encuentran.
LADT (Local Agent Descriptor Table): registro local de todos los agentes presentes en la plataforma, incluyendo su estado actual y el lugar donde se encuentran.
4.3. Servicios Web
La plataforma de Servicios Web cuenta con una serie de servicios que ofrecen cada uno, una o más operaciones posibles (funciones). Cada servicio cuenta con una página Web llamada "SOAP API Home Page", que da acceso al fichero WSDL, documentación de la interface XML, y la lista de operaciones o funciones disponibles para el servicio. El fichero WSDL (SOAP API Descriptor Language) es un fichero XML que indica principalmente, qué formato utilizar en la conformación de una petición al servicio y el significado de la petición. Se indican a continuación los servicios y el esquema de comunicación de las plataformas desarrolladas Fig. 6, con una descripción genérica de su funcionalidad y las direcciones a sus correspondientes "Home Page".
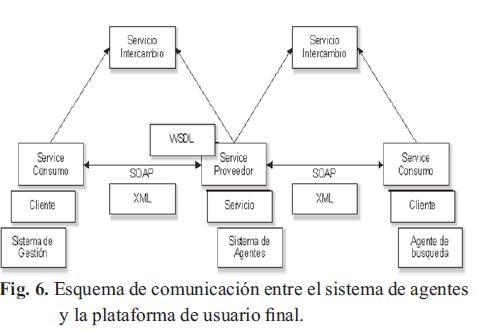
4.3.1. Servicio búsqueda articulo método busqueda articulo
El método búsqueda-Artículo, entrega a la capa de aplicación de los artículos conocidos por el agente para cada uno de los proveedores y que pueden ser consultados por los clientes, ofreciendo las siguientes búsquedas y consultas: Búsqueda Marca, Búsqueda Producto, Búsqueda Sugerida, Consulta Artículos, Consulta Proveedores, Hobbies Cliente, Profesión Cliente.
5. Resultados
Se definieron algunas pruebas para evaluar el rendimiento de la arquitectura desarrollada y la efectividad de la búsqueda. El ambiente en el que se desarrollaron dichas pruebas consta de una máquina física para la ejecución del servidor de Aplicaciones y tres máquinas virtuales, en las que se ejecutan los servidores de las tiendas on line (Principal, Sucursal 1 y Sucursal 2).
5.1. Análisis del tiempo de Búsqueda por resultado
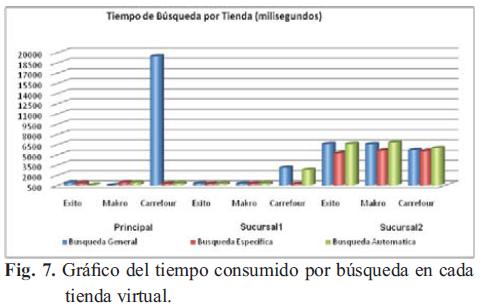
Se realizaron pruebas para medir el tiempo (milisegundos) que el sistema tarda en hacer la Búsqueda de los productos en las diferentes tiendas virtuales. En la Fig. 7 se encuentra el gráfico del tiempo obtenido por cada tipo de búsqueda en cada una de las tiendas virtuales. Se muestran tres series de datos que corresponden a las mediciones del tiempo por búsqueda general, búsqueda específica y búsqueda automática.
En la Tabla 1 se encuentran los datos obtenidos en la prueba.
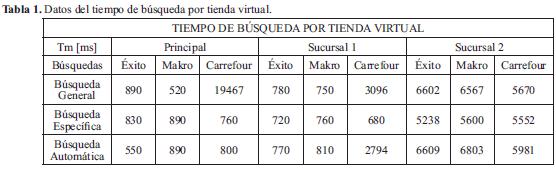
El tiempo de mayor relevancia fue el que se consumió al hacer una Búsqueda general en la Tienda Virtual Carrefour (19467 ms). Se puede observar que las Búsquedas Generales son aquellas que mayor tiempo de respuesta presentan, debido a que deben traer gran cantidad de información de los productos de acuerdo con las especificaciones; el usuario sigue las Búsquedas Automáticas que van de acuerdo con el perfil y por último las Búsquedas Específicas por Marca del Producto. Dentro de las Búsquedas Generales se observa que las que más consumen tiempo promedio son las que se realizan en la Tienda Virtual de Carrefour, seguida de Éxito y por último Makro. Con respecto a las Búsquedas Especificas el tiempo es casi el mismo en todas las tiendas, siendo significativo en la Sucursal 2. El mismo caso ocurre con las Búsquedas Automáticas, el mayor de los tiempos se registra en la Sucursal 2, en todas las tiendas.
5.2. Análisis del tiempo de Comunicación entre plataformas
Se realizaron algunas pruebas para medir el tiempo (milisegundos) de comunicación entre plataformas. Se tuvo en cuenta la comunicación entre la aplicación y el ESB, el ESB y el agente, el agente y la plataforma remota y la distribución de los agentes en las plataformas remotas. A continuación se describen los resultados obtenidos.
5.2.1. Comunicación entre la aplicación y el ESB
La Fig. 8 muestra el gráfico del tiempo consumido en la comunicación de las diferentes aplicaciones con el ESB, haciendo uso de los Servicios Web requeridos. Se tienen seis series de datos que corresponden a las aplicaciones búsqueda, cliente, dominio, perfil, resultados y temporada.

Los resultados se describen en la Tabla 2.
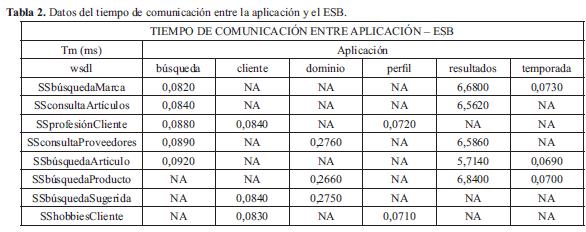
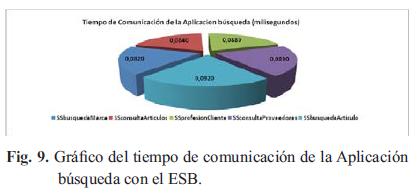
Se observa que la aplicación de resultados es la que más tarda en comunicarse con el ESB, seguida de la de dominio y las que más rápido se comunican son la aplicación temporada y perfil. Para la aplicación búsqueda, la Fig. 9 muestra el tiempo de comunicación, detallándolo por Servicio Web. Se puede observar que el mayor de los tiempos está dado para el Servicio Web búsqueda Artículo, que permite que el usuario cree las búsquedas. Sin embargo, la diferencia de tiempo con los otros servicios no es muy significativa. Para la aplicación dominio, Fig. 10, se observa que los tiempos de comunicaciones son muy similares para los diferentes servicios. Se puede resaltar el mayor de los tiempos dado para el Servicio Web SSconsulta Proveedores, este es el servicio que el cliente utiliza para crear las temporadas de las ofertas.
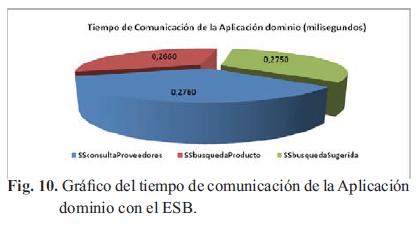
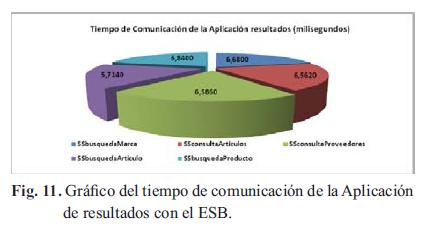
Al igual que en los anteriores diagramas la Fig.11 muestra tiempos muy similares para la comunicación de la aplicación de resultados con el ESB.
5.2.2. Comunicación entre el ESB y el Agente
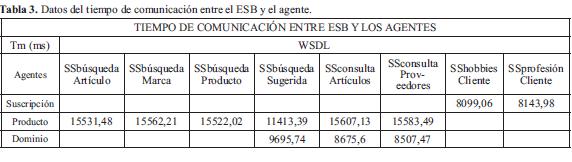
La Fig. 12 muestra los tiempos que tarda cada servicio en conectarse con el respectivo agente. Las barras rojas describen el tiempo más significativo, que es el tiempo de comunicación con el agente de producto. Se pude observar que es mucho mayor a los demás, esto debido a la gran cantidad de información que este agente recibe y procesa para ejecutar las búsquedas respectivas (ver Tabla 3).
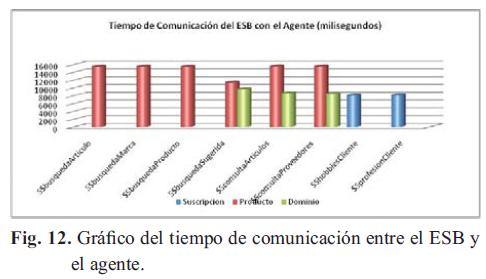
5.2.3. Comunicación entre el agente y la plataforma remota
En cuanto a la comunicación del agente principal con cada plataforma remota, para realizar las búsquedas respectivas, el mayor tiempo de comunicación corresponde a la conexión con la tienda Makro, esto debido a que es la que mayor distancia guarda con el Servidor Principal, ver Tabla. 4.

5.2.4. Comunicación entre el agente y Google
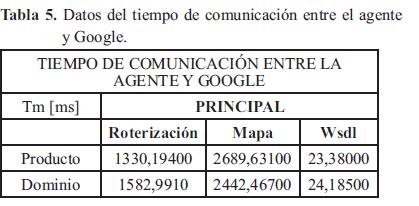
El tiempo de comunicación con Google para el cálculo de la ruta, el mapeo de los puntos y la ubicación de los datos se puede observar en la Fig. 14. Para el agente de dominio el tiempo para el cálculo de las rutas es mayor que para el agente de producto, sin embargo, para el mapeo de los proveedores ocurre lo contrario, el tiempo es mayor para el Agente de Producto. En términos generales los tiempos de conexión no difieren significativamente en estos dos.
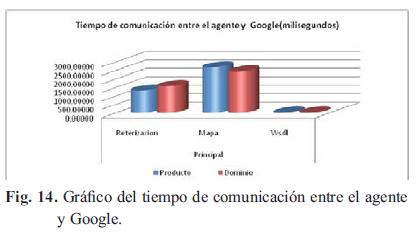
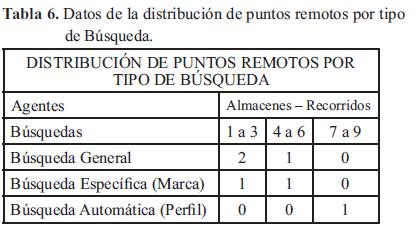
5.3. Distribución de puntos remotos por tipo de búsqueda
Para las búsquedas de los productos la plataforma distribuye cierto número de agentes dependiendo del tipo de búsqueda. Por ejemplo se observa que para las Búsquedas Generales se crean dos agentes que recorran de uno a tres puntos y un adicional agente para recorrer de la cuarta a sexta tienda. Para las búsquedas específicas se crea un agente para el recorrido de uno a tres puntos y un agente para el recorrido de la cuarta a sexta tienda y solo se crea un agente que recorra todos los puntos en el caso de las búsquedas automáticas.
5.4. Efectividad de las búsquedas
En la Fig. 16 se observa el porcentaje de complejidad en las condiciones de búsqueda de los resultados obtenidos de acuerdo con la cantidad de búsquedas realizadas. Para cinco búsquedas realizadas con un nivel de complejidad del 20%, 40% y 60% se concluye que todas las búsquedas traen el resultado esperado, es decir, hay una efectividad del 100% en la búsqueda, mientras que para un nivel de complejidad del 80% y del 100% disminuye la efectividad a aproximadamente un 20%, con cuatro búsquedas que traen el resultado esperado.
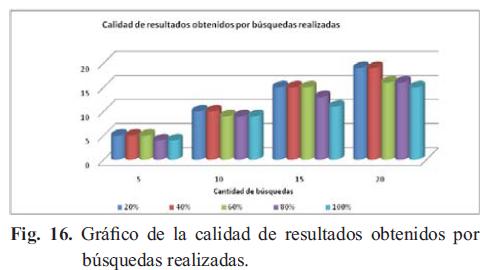
Para diez búsquedas los resultados son muy similares al caso anterior, manteniéndose la efectividad de la búsqueda para un nivel de complejidad del 20% y del 40%.Podemos observar que a medida que aumenta la cantidad de las búsquedas y la complejidad de las condiciones el porcentaje de efectividad disminuye significativamente.
La siguiente tabla muestra los datos obtenidos
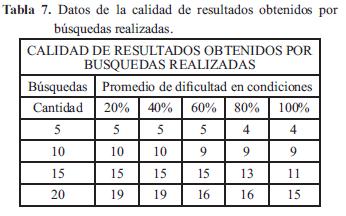
Tabla 7. Datos de la calidad de resultados obtenidos por búsquedas realizadas.
6. Conclusiones
En términos de la arquitectura los resultados fueron positivos. El sistema respondió como se esperaba y cumplió con lo planeado. No se generaron problemas al realizar varias solicitudes de búsqueda y pedir los resultados. Los agentes de búsqueda pudieron ubicar los servicios solicitados sin importar que se encontraran en distintas máquinas y pudieron regresar a su lugar de origen con los resultados esperados.
Por medio de la arquitectura planteada se pudo ver que los agentes móviles reducen el costo de comunicación al determinar la información relevante de los productos para el usuario y transmitir un resumen organizado de esta información, encapsulando y filtrando los datos enviados de un lado a otro.
La plataforma utilizada fue de gran apoyo, porque permitió desarrollar el software de una manera más sencilla, admitiendo centrarse más en el aspecto lógico que en el desarrollo de las comunicaciones entre los diferentes agentes.
7. Trabajos Futuros
Se plantea la idea de desarrollar un buscador genérico que permita comunicarse no solo con la plataforma de agentes sino que pueda acceder a diferentes plataformas de búsqueda por medio de servicios web. Otra alternativa interesante consiste en crear un servicio de búsqueda para que múltiples aplicaciones puedan acceder a él haciendo uso de diferentes estándares y protocolos de comunicación mediante servicios Web. También se puede contemplar la posibilidad de usar dispositivos móviles para la consulta de la información por parte del usuario.
Referencias
[1] R. Fornas, "Revista Métodos de Busca", Buscadores y Comercio Electrónico, 2002. Disponible: http://www.metodos-debusca.com/index5.html [ Links ]
[2] "La importancia de los buscadores", Altercat Internet Solutions S.L., [en línea]. Disponible en: http://www.altersem.com/buscadores.html [ Links ]
[3] P. Lara y J. S. Martínez, Agentes Inteligentes en la Búsqueda y Recuperacion de la Informacion, 2004, [en línea]. Disponible en: http://eprints.ucm.es/5840/1/2004Lib-Agentes.pdf [ Links ]
[4] J. Peña, Mesa Redonda: Las nuevas tecnologias aplicadas a la documentacion. Comunicación: Internet, Sistema de Búsqueda, Biblioteca Virtual. Jornadas sobre la Documentacion y la Comunicación en los CCEESS, 2003, [en línea]. Disponible: http//:www.ces-galicia.org/jornadas/j1/4.doc. [ Links ]
[5] H. Nwana, J. Rosenschein, T. Sandholm, C. Sierra, P. Maes and R. Guttman, "Agent-mediated electronic commerce: Issues, challenges, and some viewpoints", En Proceedings o1 the Workshop on Agent Mediated Electronic Trading (AMET98), Minneapolis, Minnesota, 1998. [ Links ]
[6] O. R. Nafarrete, Aplicación para Agentes Inteligentes en Mercadotecnia. Disponible: http://www.mktglobal.iteso.mx. [ Links ]
[7] J. A. Martínez, P. Martins, "Desarrollo de Servicios de Información para utilidades de Comercio Electrónico: nuevas necesidades, nuevos usuarios, nuevas herramientas", 2a Jornada Andaluzas de Documentación, 1999, [en línea]. Disponible en: http://eprints.ucm.es/5666/1/1999capt-JADOC-desarrolloservicios.pdf [ Links ]
[8] J. F. Garamendi, Agentes Inteligentes: JADE, 2004, pp. 1, [en línea]. Disponible en: http://zenon.etsii.urjc.es:8080/foros/AgentesInteligentes0032004/1082414149/1082495069/Jade.pdf [ Links ]
[9] J. F. Garamendi, Agentes Inteligentes: JADE, 2004, pp. 3-4, [en línea]. Disponible en: http://zenon.etsii.urjc.es:8080/foros/AgentesInteligentes0032004/1082414149/1082495069/Jade.pdf [ Links ]
[10] F. Bellifemine, G. Caire and D. Greenwood, Developing multi-agent systems with JADE, Inglaterra: Michael Wooldridge, Liverpool University, 2004. [ Links ]
