











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
Permalink
Introducción
Los resultados de pruebas nacionales e internacionales muestran que Colombia posee un sistema educativo con bajos logros académicos por parte de sus estudiantes en cada uno de los niveles de estudio (Posada and Mendoza, 2014). Esta situación es crítica pues, si persisten estos desempeños académicos en la mayor parte del estudiantado colombiano, los rendimientos asociados a las economías de escala entre el capital físico y el capital humano seguirán llevando al país por una senda de desarrollo restringido y bajo crecimiento económico (OECD, 2016).
La Ley 1324 le confiere al Instituto Colombiano para Evaluación de la Educación (ICFES) la misión de evaluar, mediante exámenes externos estandarizados, la formación que se ofrece en los distintos niveles del servicio educativo. Esta ley también establece que el MEN define lo que debe evaluarse en estos exámenes (ICFES, 2014). Actualmente, el ICFES diseña y aplica las pruebas Saber 3°, Saber 5°, Saber 9° y Saber 11°, con las cuales evalúa la Educación Básica y Media; y Saber Pro, para evaluar la Educación Superior.
La prueba Saber 5° está dirigida a estudiantes de quinto grado de Básica Primaria, y su objetivo es contribuir al mejoramiento de la calidad de la educación. Esto, mediante la realización de pruebas periódicas en las que se evalúan las competencias básicas de los estudiantes y se analizan los factores que inciden en sus logros. Los resultados de estas evaluaciones permiten que los establecimientos educativos, las secretarías de educación, el Ministerio de Educación Nacional (MEN) y la sociedad en general conozcan cuáles son las fortalezas y debilidades del sistema educativo y, a partir de estas, puedan definir planes de mejoramiento en sus respectivos ámbitos de actuación. Su carácter periódico posibilita, además, valorar cuáles han sido los avances en un determinado periodo de tiempo, así como determinar el impacto de programas y acciones específicas de mejoramiento (ICFES, 2014). Según la Guía de Orientación de las pruebas Saber 5º del ICFES (2017), en la prueba de matemáticas se evalúa el uso flexible de esta ciencia en diversas situaciones. Las competencias comunicativas en lenguaje se evalúan a través de dos instrumentos: uno enfocado en evaluar la comprensión lectora y otro enfocado en evaluar la competencia escritora. En las competencias ciudadanas se evalúa la capacidad de los estudiantes para participar de manera constructiva y activa como ciudadanos en la sociedad. En la prueba de ciencias naturales se evalúa la capacidad de comprender y usar nociones, conceptos y teorías de las ciencias naturales en la resolución de problemas. La prueba, además, involucra el proceso de indagación, lo que implica observar y relacionar patrones en los datos para derivar conclusiones de fenómenos naturales.
En el caso de esta investigación, se analizaron los resultados en matemáticas y lenguaje. Dichas competencias se evaluaron en el año 2017, y esta es la última información disponible en las bases de datos del ICFES. En el año 2022, el ICFES volvió aplicar estas pruebas, pero, por el momento, no hay información disponible sobre los resultados obtenidos.
Se han realizado varios estudios sobre el desempeño académico en las pruebas Saber 5º, tales como los realizados por Torres et al. (2014), Martín (2015) y Gutiérrez (2015), quienes buscaban identificar las variables asociadas al rendimiento académico, en especial al desempeño en las pruebas Saber 5°, con base en solo una de las áreas fundamentales, i.e., ciencias naturales, matemáticas y lenguaje respectivamente. En otro estudio (ICFES, 2009) se analizaron los factores asociados de las pruebas de grado 5° y 9°. Una de las conclusiones de dicho estudio fue que, entre más alto sea nivel socioeconómico de los alumnos y sus familias, mayor será el desempeño esperado en ambas áreas y grados evaluados. Además, los estudiantes matriculados en colegios privados tienden a obtener puntajes más altos en las pruebas, y las diferencias frente a quienes asisten a planteles oficiales aumentan en la medida en que mejoran las condiciones socioeconómicas. En el informe realizado sobre factores asociados en las pruebas Saber 5° y 9° del ICFES (2011), se identificaron variables relacionadas con el rendimiento. Se aplicaron técnicas estadísticas que permitieron visualizar los elementos que inciden en el desempeño académico. Por otra parte, para extender sus procesos de evaluación, el ICFES dio paso al estudio de los factores asociados al rendimiento escolar, utilizando modelos teóricos para explicar las relaciones existentes entre los elementos que determinan el aprendizaje y están presentes en tres niveles: instituciones educativas, aulas de clase y estudiantes (ICFES, 2017).
Según Timarán et al. (2021a) , 2021b) los estudios que se han realizado hasta el momento, con respecto al análisis de los resultados de las pruebas Saber 5o se basan en información procesada mediante análisis estadístico, donde fundamentalmente se consideran variables y relaciones primarias, sin tener en cuenta las verdaderas interrelaciones, que generalmente están ocultas y únicamente se pueden descubrir utilizando un tratamiento más complejo de los datos. Esto es posible con la minería de datos, que descubre patrones no previstos con la estadística en vista de que la estadística plantea hipótesis que deben ser validadas a partir de los datos disponibles.
En este artículo se aplican técnicas de minería de datos para descubrir patrones de desempeño académico en matemáticas en las pruebas Saber 5°. Este estudio se centra en los estudiantes de grado quinto de las instituciones educativas colombianas de básica primaria en el año 2017.
Metodología
Esta investigación fue de tipo descriptivo y empleó un enfoque cuantitativo aplicando un diseño no experimental. Se utilizó la metodología CRISP-DM (cross-industry standard process for data mining), que involucra la minería de datos. Según Timarán et al. (2013) y Valero et al. (2005), CRISP-DM es uno de los modelos utilizados, principalmente, en los ambientes académico e industrial y la guía de referencia más ampliamente utilizada en el desarrollo de este tipo de proyectos. CRISP-DM está compuesta por seis fases: análisis del problema, análisis de los datos, preparación de los datos, modelado, evaluación e implementación.
En la fase de análisis del problema, se recopiló y seleccionó el material bibliográfico necesario para que los investigadores pudieran conocer y apropiar el conocimiento acerca de las pruebas Saber 5o y de las competencias que evalúa, haciendo énfasis en el área de matemáticas. Este proceso posibilitó la recolección de los datos correctos para obtener resultados adecuados.
En la fase de análisis de datos, los investigadores identificaron, recopilaron y se familiarizaron con la información socioeconómica, académica e institucional que, al momento de realizar el estudio, estaba disponible en las bases de datos del ICFES y correspondía a los resultados en matemáticas obtenidos por los estudiantes colombianos que presentaron las pruebas Saber 5o en el año 2017. Como resultado, se obtuvo un conjunto de datos inicial, denominado sbr5_776436A56, con 776 436 registros y 56 atributos.
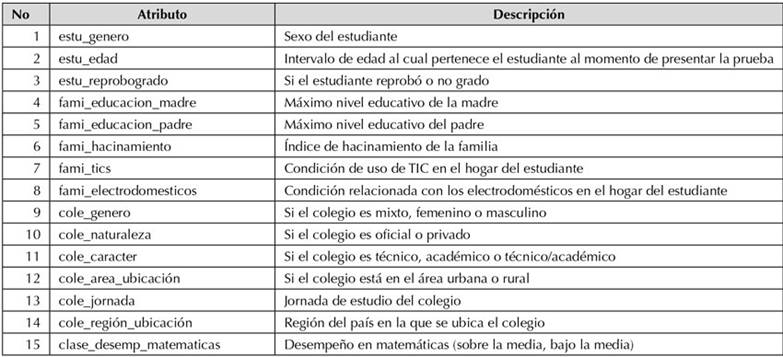
En la fase de preparación de los datos, y teniendo en cuenta que la alta dimensionalidad es un problema para descubrir patrones en minería de datos, al conjunto sbr5_776436A56 se le aplicaron técnicas de limpieza y transformación, con el fin de eliminar los datos ruidosos, nulos y atípicos, así como transformar algunos atributos para obtener mayor ganancia de información y eliminar los atributos irrelevantes que no aportaban al proceso de detección de patrones. Esto resultó en el conjunto de datos denominado sbr5_776436A15, compuesto por 776436 registros y 15 atributos, el cual sirvió de base para la fase de modelado. En la Tabla 1 se muestra el diccionario de datos del conjunto sbr5_776436A15.
En la fase del modelado se seleccionó un modelo de clasificación con árboles de decisión como la técnica de minería de datos más adecuada para solucionar el problema del estudio, dada su facilidad y simplicidad para interpretar los patrones obtenidos (Azevedo and Santos, 2008; Hernández et al., 2005; Timarán et al., 2017). Esta técnica tiene varias ventajas. En primer lugar, el proceso de razonamiento detrás del modelo resulta claramente evidente cuando se examina el árbol. Esto contrasta con otras técnicas de modelado de caja negra, en las que la lógica interna puede resultar difícil de averiguar. En segundo lugar, de manera automática, el proceso incluye en su regla únicamente los atributos que realmente importan en la toma decisiones; los atributos que no contribuyan a la precisión del árbol se omiten (Han et al., 2011, Sattler and Dunemann, 2011; Timarán et al., 2006).
De acuerdo con las recomendaciones de Hernández et al. (2005), para probar la calidad y validez del modelo, se utilizó el método de validación cruzada con 10 particiones (10-fold cross validation), con el fin de reducir la dependencia del resultado del modelo con respecto al modo en que se realiza la partición. Se tomó como atributo clase o variable objetivo el puntaje obtenido en la prueba de matemáticas, el cual se discretizó en dos valores: “sobre la media” y “bajo la media” nacional. En la fase de evaluación, se estimó el coste del clasificador para los repositorios de entrenamiento y prueba a través de una matriz de confusión (Sattler and Dunemann, 2011). Por otra parte, se evaluaron los patrones descubiertos con el fin de determinar su validez, remover los patrones redundantes o irrelevantes e interpretar los patrones útiles en términos que sean entendibles para el usuario, teniendo en cuenta el soporte y la confianza del patrón.
En la fase de implementación se documentaron los patrones descubiertos, los cuales constituyen información de calidad para la toma de decisiones del MEN, las secretarías de educación y las directivas de las instituciones educativas de Básica Primaria en la definición de planes de mejoramiento que redunden en la calidad de la educación en Colombia.
Resultados
Análisis exploratorio de datos
Con el fin de entender los datos, se analizaron las variables socioeconómicas de los estudiantes de las instituciones educativas de Colombia que presentaron las pruebas Saber 5º en el año 2017. En la Tabla 2 se muestran los resultados.
Tabla 2 Características socioeconómicas de los estudiantes de grado quinto que presentaron las pruebas Saber 5º en el año 2017
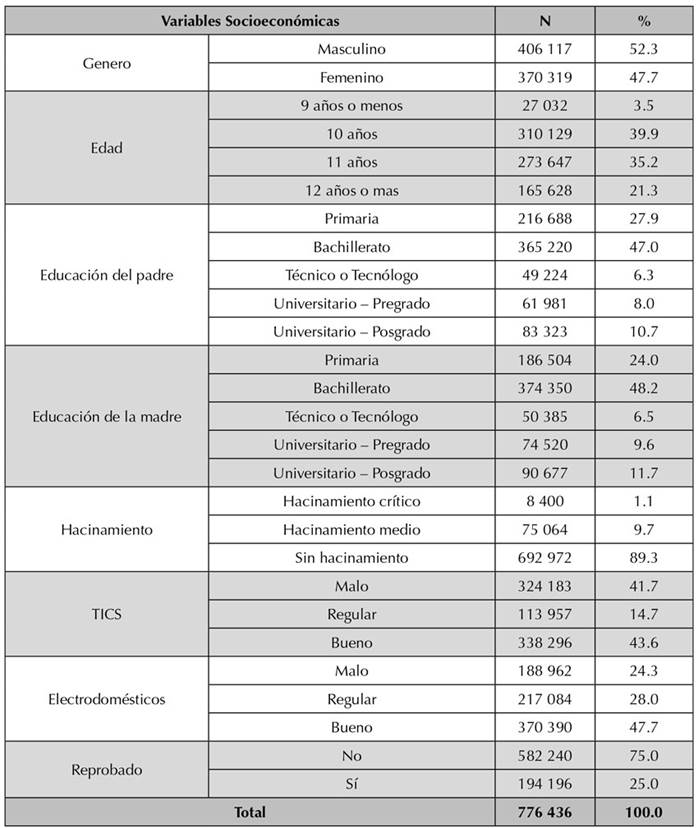
La Tabla 2 muestra que, por género, la mayoría de los estudiantes son hombres, con un 52.3%; por edad, la mayoría está entre los 10 (39.9 %) y los 11 años (35.2 %). Casi la totalidad de los estudiantes (89.3%) no presentaba hacinamiento en su vivienda. Por otra parte, los padres de los estudiantes que presentaron las pruebas son mayoritariamente bachilleres (en las madres el 48. 2% y en los padres el 47 %). La mayoría de los estudiantes tienen buenos índices de TIC y electrodomésticos en sus hogares (43.6 y 47.7 % respectivamente). Finalmente, el 75 % de los estudiantes que presentaron las pruebas Saber 5º en el año 2017 no habían reprobado ningún grado.
Definición del modelo
Se evaluaron diferentes algoritmos de árboles de decisión con la herramienta Weka versión 3.9.4, un software de minería de datos desarrollado en la Universidad de Waikato de Nueva Zelanda (Hall et al.,2011), con el fin de seleccionar la técnica de árboles de decisión que mejor clasificara el conjunto de datos sbr5_776436A15. Los resultados se muestran en la Tabla 3.
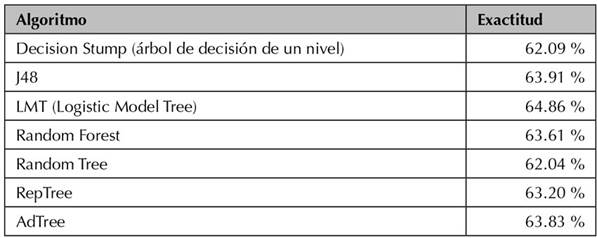
Según la Tabla 2, el algoritmo con mayor exactitud fue LMT, pero, dada la dificultad para interpretar los patrones, no fue posible escogerlo. Por esa razón se escogió el algoritmo J48 para la construcción de los modelos de clasificación con árbol de decisión, además del hecho de que facilita el entendimiento de los patrones.
Una vez seleccionado el algoritmo y el método para el entrenamiento y prueba de los modelos, se procedió a construir los diferentes árboles de decisión con la herramienta Weka 3.9.4 y su algoritmo J48, el cual implementa el algoritmo C4.5 (Quinlan, 1993, 1996).
Para la poda del árbol se tuvo en cuenta el nivel de confianza C (confidence level), que influye en el tamaño y capacidad de predicción del árbol construido. El valor por defecto de este factor es del 25 % y, conforme va bajando este valor, se permiten más operaciones de poda y, por tanto, árboles cada vez más pequeños (García and Álvarez,2010). Se utilizó también el parámetro M, que determina el mínimo número de registros por nodo del árbol. Se escogió como clase el atributo del puntaje obtenido en matemáticas, cuyos valores fueron discretizados en las categorías “sobre la medial” y “bajo la media”.
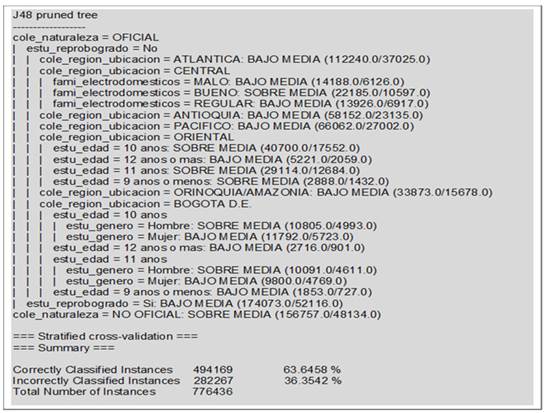
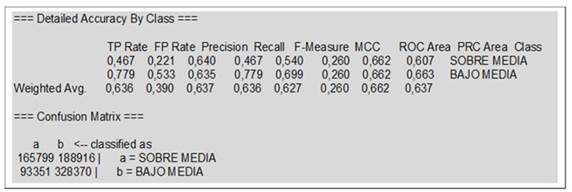
Para la competencia de matemáticas, el mejor árbol se obtuvo con los parámetros C 0.5 % y M 1 %, como se muestra en la Figura 1. La matriz de confusión se muestra en la Figura 2.
Discusión
Analizando los resultados del desempeño en matemáticas en las pruebas Saber 5º de 2017, el modelo que se muestra en la Figura 1 clasifica 494 169 instancias correctamente, lo que corresponde a una exactitud del 63.6 %, y 282 267 instancias incorrectamente (36.4 % de exactitud).
Evaluando el modelo con la matriz de confusión (Figura 2), obtenido con la herramienta Weka, este predice correctamente 165 799 casos de estudiantes cuyo desempeño en matemáticas está sobre la media (true positives, TP) y 328 370 casos que están bajo la media (true negatives, TN). Por otra parte, en el caso de 93 351 estudiantes cuyo desempeño está bajo la media, el modelo los clasifica incorrectamente sobre la media (false positives, FP). Asimismo, hay 188 916 casos cuyo desempeño está sobre la media y el modelo los clasifica incorrectamente (false negatives, FN).
Para el caso de los estudiantes que están sobre la media en el puntaje de matemáticas, el modelo tiene una precisión de predicción de 0.64, lo que quiere decir que, del total de casos predichos que están sobre la media, el 64 % son correctos. La sensibilidad (TPR) y el recall del modelo muestran un valor de 0.47, lo que indica que el modelo clasifica correctamente al 47 % de los estudiantes que realmente están sobre la media. Por otra parte, la tasa de falsos positivos (FP rate) del modelo es de 0.22, lo que significa que el 22 % de estudiantes que estaban bajo la media fueron clasificados incorrectamente. El F-measure es de 0.54. Esto significa que la media armónica entre la precisión y el recall de los que están sobre la media es de 54. En la combinación de estas medidas se aprecia un peor desempeño del modelo para los que están sobre la media.
Para el caso de los estudiantes que están bajo la media en el puntaje de matemáticas, el modelo tiene una precisión de predicción de 0.64, lo que quiere decir que, del total de casos predichos que están bajo la media, el 64 % son correctos (igual que para lenguaje). La sensibilidad (TPR) y el recall del modelo reportan un valor de 0.78. Esto indica que el modelo clasifica correctamente al 78 % de los estudiantes que realmente están bajo la media. Por otra parte, la tasa de falsos negativos (FP rate) del modelo es de 0.54, lo que significa que el 54 % de estudiantes que estaban sobre la media fueron clasificados bajo la media. El F-measure es de 0.70, i.e., la media armónica entre la precisión y el recall de los que están bajo la media es de 70. En la combinación de estas medidas se aprecia un mejor desempeño del modelo para los estudiantes que están bajo la media.
Dentro de las métricas de evaluación calculadas anteriormente para la competencia de matemáticas, se puede decir que el modelo tiene una exactitud del 63.6 % y que predice mejor a los estudiantes que están bajo la media. Esto también lo muestra en la relación entre el recall y la precisión dada en el PRC area. Aquí, para los estudiantes que están bajo la media, el valor es de 0.66, y, para los que están sobre la media, es de 0.61. El coeficiente de correlación de Mathews (MCC) del modelo es de 0.26, lo que indica que hay una concordancia media entre lo predicho y lo observado, es decir, una calidad regular en la predicción. Finalmente, en cuanto a las áreas, el área ROC de 0.66 del modelo, al ser mayor que 0.5, indica que el modelo tiene un desempeño bueno en la clasificación de los estudiantes colombianos con respecto al puntaje en matemáticas obtenido en las pruebas Saber 5o.
Para escoger los patrones más representativos del desempeño en matemáticas en las pruebas Saber 5o que presentaron los estudiantes colombianos de las instituciones educativas de educación Básica Primaria en el año 2017 (Figura 1), se tuvieron en cuenta aquellos que superaran un soporte mínimo del 1 % y una confianza mínima del 60 %. Las siguientes reglas son la interpretación de los patrones que cumplen estas métricas.
Regla 1. Si el estudiante es de un colegio oficial, no reprobó grados y el colegio está ubicado en la región Atlántica, entonces su desempeño en matemáticas probablemente está bajo la media nacional, con un soporte del 14.5 % y una confianza del 67 %. El 17.8 % del número total de estudiantes analizados que están bajo la media cumple este patrón.
Regla 2. Si el estudiante es de un colegio oficial, no reprobó grados y el colegio está ubicado en la región de Antioquia, entonces su desempeño en matemáticas probablemente está bajo la media nacional, con un soporte del 7.5 % y una confianza del 60.2 %. El 8.3 % del número total de estudiantes analizados que están bajo la media cumple este patrón.
Regla 3. Si el estudiante es de un colegio oficial y reprobó grados, entonces su desempeño en matemáticas probablemente está bajo la media nacional, con un soporte del 22.4 % y una confianza del 70.1 %. El 28.9 % del número total de estudiantes analizados que están bajo la media cumple este patrón.
Regla 4. Si el estudiante es de un colegio no oficial, entonces su desempeño en matemáticas probablemente está sobre la media nacional, con un soporte del 20.2 % y una confianza del 69.3 %. El 30.6 % del número total de estudiantes analizados que están sobre la media cumple este patrón.
Conclusiones
Este estudio presenta los resultados obtenidos al aplicar la técnica de minería de datos y clasificación por árboles de decisión con el fin de detectar patrones de desempeño académico en la competencia de matemáticas de los estudiantes de Básica Primaria que presentaron las pruebas Saber 5º en el año 2017.
Es importante destacar que la naturaleza del colegio es un factor determinante para el desempeño académico en la competencia analizada. Para los estudiantes que son de colegios privados o no oficiales se muestra un buen desempeño, con altos porcentajes tanto de soporte como de confianza. Por otra parte, para los estudiantes de colegios oficiales, el desempeño no es bueno, si bien se tienen en cuenta otros factores, e.g., si el estudiante reprobó grados o no y la zona de ubicación del colegio.
Estos hechos deben tenerse en cuenta para que las instituciones gubernamentales relacionadas con la educación Básica Primaria, como el MEN, las secretarías de educación departamentales y municipales y las instituciones educativas, tomen medidas para mejorar la calidad de la educación, especialmente en los colegios oficiales.
Se plantean como trabajos futuros aplicar técnicas descriptivas de minería de datos con el fin de analizar las relaciones de asociación existentes entre los atributos socioeconómicos, académicos e institucionales de los estudiantes, teniendo en cuenta el desempeño en las competencias de lenguaje y matemáticas de las pruebas Saber 5º; y analizar la manera en la que se pueden agrupar estos estudiantes de acuerdo con su similitud en el rendimiento en estas pruebas.

