










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares en
SciELO
Similares en
SciELO -
 Similares en Google
Similares en Google
Compartir

 Permalink
PermalinkRevista de Economía Institucional
versión impresa ISSN 0124-5996
Rev.econ.inst. vol.17 no.32 Bogotá ene./jun. 2015
https://doi.org/10.18601/01245996.v17n32.03
DOI: http://dx.doi.org/10.18601/01245996.v17n32.03
Artículo
La distribución global del ingreso. De la caída del muro de Berlín a la gran recesión
Global Income Distribution from the Fall of the Berlin Wall to the Great Recession
Christoph Lakner* Branko Milanovic**
* DPhil in Economics, Universidad de Oxford; Departamento de Investigaciones del Banco Mundial, USA clakner@worldbank.org.
** Doctor en Economía/Estadística, Universidad de Belgrado; Departamento de Investigaciones del Banco Mundial, USA bmilanovic@worldbank.org.
Agradecemos a Statistics Finland, Statistics Portugal y Eurostat por proporcionar micro datos tabulados; a María Ana Lugo y Philippe van Kerm por la ayuda en la implementación empírica de las CIC no anónimas; a Shaohua Chen por la ayuda con Povcal Net; a Tony Atkinson y La-Bhus Jirasavetakul por muchas discusiones útiles. Se tuvo acceso a los datos BHPS vía UK Data Service. El trabajo fue financiado en parte por el Banco Mundial bajo el Proyecto Conocimiento para el Cambio TF012968. Presentamos partes del artículo en talleres realizados en el Banco Mundial y en la OCDE; agradecemos a los participantes por sus útiles comentarios. Las interpretaciones y las conclusiones son de los autores; no representan los puntos de vista del BIRD, del Banco Mundial ni los de los Directores Ejecutivos del Banco Mundial o de los gobiernos que representan. El original se publicó como "Global income distribution, from the fall of the Berlin Wall to the Great Recession", Banco Mundial, [http://www-wds.worldbank.org/external/default/WDSContentServer/WDSP/IB/2013/12/11/000158349_20131211100152/Rendered/PDF/WPS6719.pdf]. Licencia: Creative Commons Reconocimiento (CC BY 3.0 IGO).
Traducción de Alberto Supelano; no fue elaborada por el Banco Mundial y no es una traducción oficial del Banco, el cual no se hace responsable de ningún error contenido en ella. Se publica con las autorizaciones correspondientes.
Sugerencia de citación: Lakner, C. y B. Milanovic. "La distribución global del ingreso de la caída del muro de Berlín a la gran recesión", Revista de Economía Institucional 17, 32, 2015, pp. 71-128. DOI: 10.18601/01245996.v17n32.03
Fecha de recepción: 22 de enero de 2015, fecha de aceptación: 9 de febrero de 2015
Resumen
Este artículo presenta una base de datos recién compilada y mejorada de encuestas nacionales de hogares entre 1988 y 2008. En 2008, el índice global de Gini es de un 70,5% después de disminuir en cerca de 2 puntos Gini en este periodo. Cuando se ajusta por el probable subregistro de los ingresos superiores de las encuestas usando la brecha entre el consumo de cuentas nacionales y el promedio de las encuestas junto con una imputación tipo Pareto de la cola superior, resulta un Gini global mucho más alto de casi un 76%. Con tal ajuste la tendencia decreciente del Gini casi desaparece. El seguimiento de la evolución de los deciles-país individuales muestra los elementos subyacentes que impulsan los cambios en la distribución global: China salió de los rangos más bajos, en el proceso se modificó la forma total de la distribución global del ingreso y se creó una importante clase "mediana" global que transformó la distribución de dos picos de 1988en una de un pico. Los "ganadores" fueron los deciles-país que en 1988 estaba alrededor de la mediana de la distribución global, el 90% de los cuales, en términos de población, son de Asia. Los "perdedores" fueron los deciles-país que en 1988 estaban alrededor del percentil 85 de la distribución global, casi el 90% de los cuales, en términos de población, son de economías maduras.
Palabras clave: distribución del ingreso, globalización, ingresos superiores; JEL: D31.
Abstract
The paper presents a newly compiled and improved database of national household surveys between 1988 and 2008. In 2008, the global Gini index is at 70.5 percent having declined by approximately 2 Gini points over this twenty year period. When it is adjusted for the likely under-reporting of higher? incomes in surveys by using the gap between national accounts consumption and survey means in combination with a Pareto-type imputation of the upper tail, the estimate is a much higher global Gini of almost 76 percent. With such an adjustment the downward trend in the Gini almost disappears. Tracking the evolution of individual country- deciles shows the underlying elements that drive the changes in the global distribution: China left the bottom ranks, modifying the overall shape of the global income distribution in the process and creating an important global "median" class that transformed a twin-peaked 1988 global distribution into a single-peaked one. The "winners" were country-deciles which in 1988 stood at the median of the global income distribution, 90 percent of which are from Asia in terms of population. The "losers" were the country-deciles in 1988 were around the 85th percentile of the global income distribution, almost 90 percent of which are from mature economies in terms of population.
Keywords: Income distribution, globalization, higher incomes; JEL: D31.
Este artículo presenta nueva evidencia sobre la evolución de la desigualdad del ingreso interpersonal global entre 1988 y 2008. Este concepto mide la desigualdad entre individuos de todo el mundo sin importar el país de residencia; supone implícitamente una función de bienestar social "cosmopolita" y traduce la preocupación por la desigualdad dentro de los países a nivel global. En el periodo 1988-2008, el rostro de la globalización cambió drásticamente con la integración de muchos países en desarrollo a la economía mundial. La desigualdad interpersonal global capta los efectos de estos cambios sobre la desigualdad dentro los países y entre países.
Encontramos que la desigualdad en la distribución global del ingreso (medida, p. ej., por un índice de Gini) no cambia mucho en este periodo. Pero esto oculta una reordenación sustancial de los deciles-país y los cambios en la composición regional de diferentes partes de la distribución global. Primero presentamos nueva evidencia sobre la evolución de la desigualdad interpersonal global. Después profundizamos y analizamos los cambios en la composición de la distribución global del ingreso.
Medir la desigualdad global es mucho más difícil que medir la desigualdad en cada país. En ausencia de una encuesta global de hogares, debemos combinar encuestas nacionales. Nuestra base de datos incluye 565 encuestas de hogares de cinco años de referencia y cada observación año-país se representa mediante el ingreso promedio de los diez grupos de deciles de ingreso1. Las encuestas nacionales reúnen información en monedas locales y debemos convertirlas en una moneda común, preferiblemente ajustándolas por las diferencias en el nivel de precios (entre países y en el tiempo)2. Debemos señalar que al construir nuestra distribución global mezclamos encuestas de ingreso y de consumo. Nos referimos a ellas en forma intercambiable, como es típico en la literatura, aunque somos plenamente conscientes de las importantes diferencias entre ambos conceptos3.
Este artículo hace cuatro contribuciones al estudio de la desigualdad global del ingreso. Primera, compila una nueva y mejor base de datos de encuestas nacionales de hogares en respuesta a la crítica a conjuntos de datos anteriores (p. ej., de Anand y Segal, 2008). Segunda, esto permite presentar resultados más creíbles de la desigualdad interpersonal global del ingreso entre 1988 y 2008.Tercera, construye paneles balanceados y desbalanceados de los deciles-país para cinco años de referencia. Esto permite ir más allá de señalar qué países afectaron (y cuánto) la desigualdad global, examinando una distribución más desagregada de deciles-país. Así podemos identificar aquellos que más ganaron y perdieron en estos 20 años. Cuarta, presenta uno de los primeros ajustes integrales de los ingresos superiores omitidos en el estudio de la desigualdad global4. Ofrece una nueva y valiosa comprensión empírica acerca de por qué no es claro a priori el efecto de la falta de respuesta del grupo superior de cada país sobre la desigualdad global (Deaton, 2005)5.
Calculamos que el índice de Gini está alrededor del 70%. El índice global de Gini disminuyó en estos 20 años, y la mayor disminución ocurrió entre 2003 y 2008. Pero estos cambios observados quizá no sean robustos a errores estándar razonables. El patrón de las series de tiempo es robusto a medidas alternativas de la desigualdad, como los índices de Theil. Gran parte de la desigualdad global es explicada por las diferencias entre países, aunque esta contribución ha descendido en el tiempo, lo que sugiere que los países se han vuelto más similares. Sin embargo, el componente dentro de los países de la desigualdad global ha aumentado continuamente en estos 20 años.
Presentamos varias pruebas de robustez. Cuando escalamos los ingresos de las encuestas al consumo final de los hogares de cuentas nacionales obtenemos un nivel más bajo del índice global de Gini y un mayor descenso en el tiempo6. También presentamos una prueba simple de robustez del subregistro de los ingresos más altos en las encuestas de hogares. Tratamos la discrepancia entre el consumo de cuentas nacionales y el de encuestas de hogares, un asunto que ha recibido mucha atención en la literatura, como una proxy del grado de "omisión" de los ingresos más altos. Obtenemos los cuantiles superiores detallados de la distribución asignando esta brecha al decil superior y ajustando una distribución de Pareto. El índice de Gini de esta distribución revisada es casi 5 puntos Gini mayor y no disminuye sustancialmente entre 1988 y 2008. La diferencia de niveles se debe ante todo a la asignación del exceso de consumo de cuentas nacionales al decil superior y no a la imputación de Pareto, es decir, a la elongación de la cola superior de la distribución.
La composición regional de la distribución global cambió sustancialmente en estos 20 años. China salió de los rangos más bajos de la distribución global, lo que ha tenido un gran efecto no solo en la composición regional sino también en la forma total de la distribución global. El crecimiento del ingreso promedio y el cambio en la desigualdad del ingreso en China fueron excepcionalmente fuertes. India creció más lentamente, pero su desigualdad también creció mucho menos. Como resultado del crecimiento en China (y en menor medida en India), África subsahariana ahora está en la parte inferior de la distribución global.
No es sorprendente que China (en particular la parte urbana) esté entre los deciles-país que más crecieron entre 1988 y 2008. En América Latina, algunos deciles-país también tuvieron buen desempeño. Los nuevos estados miembros de la UE se pueden encontrar entre los ganadores y perdedores más grandes, así como África subsahariana después de 1993.
En la construcción de la distribución global del ingreso intentamos ser tan cuidadosos como nos fue posible dada la restricción de datos, y corregir algunos sesgos de estudios anteriores (ver más adelante). No obstante, subsisten fuentes de incertidumbre sobre nuestras estimaciones que son difíciles (e imposibles en algunos casos) de cuantificar. Sugerimos un enfoque conservador y concluimos que los cambios que observamos en el tiempo no son estadísticamente significativos. En la conclusión volvemos a algunos de estos asuntos y sugerimos maneras de abordarlos en futuros trabajos.
El artículo consta de seis partes. Primero revisa la literatura sobre desigualdad global, la medición de la paridad del poder adquisitivo (PPA), la discrepancia entre cuentas nacionales y encuestas de hogares, la subestimación de los ingresos más altos en las encuestas de hogares, y esboza nuestro enfoque de estos asuntos. La sección 2 resume la construcción de datos y la metodología, incluidos el concepto de bienestar y la imputación de Pareto que usamos para tener en cuenta los ingresos más altos. La sección 3 presenta estadísticas sumarias de nuestra base de datos, en particular de la cobertura del PIB global y regional y de la población, así como los principales resultados sobre la desigualdad en la distribución global del ingreso. Probamos la robusteza diferentes medidas de desigualdad e investigamos el cambio en la composición regional así como las curvas globales de incidencia del crecimiento. La sección 4 propone un límite superior del Gini global que tiene en cuenta la subestimación de los ingresos más altos. La sección 5 pasa del enfoque de corte transversal a un análisis de panel que tiene en cuenta el movimiento de cada decil-país en la distribución global. La sección 6 presenta las conclusiones.
REVISIÓN DE LA LITERATURA Y NUESTRO ENFOQUE
El artículo está relacionado con diversas vertientes de la literatura. Primero resumimos la literatura sobre desigualdad global y definimos qué entendemos por este término. Luego explicamos los diversos problemas asociados con la derivación de tasas de cambio PPA y porqué consideramos que las tasas que aquí usamos son las más robustas. Por último abordamos trabajos anteriores sobre (a) el subregistro de los ingresos más altos en las encuestas de hogares y (b) la discrepancia entre medidas del ingreso o el consumo de cuentas nacionales y sus equivalentes de encuestas de hogares. Argumentamos que ambos asuntos están estrechamente relacionados y los consideramos conjuntamente en nuestro análisis.
La desigualdad global
Milanovic (2005) distingue tres conceptos de desigualdad global. Primero, la desigualdad internacional no ponderada es la desigualdad del ingreso per cápita entre los países del mundo. Segundo, la desigualdad internacional ponderada por la población, o desigualdad entre países (Anand y Segal, 2008), mide la desigualdad entre las personas asignándoles a todas el ingreso per cápita de su lugar de residencia; ignora así la desigualdad dentro de los países. Tercero, la desigualdad interpersonal global capta la desigualdad de los ingresos individuales en el mundo dando a todos su propio ingreso7.
Aquí nos centramos en el último concepto, la desigualdad interpersonal global, y siempre que usamos el término "desigualdad global" nos referimos a ese concepto. La desigualdad internacional no ponderada (concepto 1) puede ser apropiada en estudios de convergencia del ingreso entre países (p. ej., Barro y Sala-i-Martin, 1992), pero no mide la desigualdad interpersonal, entre otras cosas porque el peso asignado a los individuos depende de su país de residencia. Bourguignon (2011b) muestra que entre 1989 y 2006 la desigualdad internacional no ponderada (concepto 1) siguió aumentando, mientras que la desigualdad global (concepto 3) disminuyó, medida por la proporción P90/P10. Esto puede ser explicado por el hecho de que algunos países asiáticos populosos crecieron muy rápido, mientras que algunos países más pequeños (en su mayoría africanos) se rezagaron o incluso declinaron. La desigualdad internacional ponderada por la población (concepto 2) ignora la desigualdad dentro de los países, lo que parece inapropiado dada la extendida preocupación por este tema. Podría ser mejor verla como un paso intermedio (sesgado hacia abajo) hacia la desigualdad interpersonal global cuando no se dispone de datos de encuestas para medir la distribución dentro de los países (Milanovic, 2005).
Anand y Segal (2008) distinguen dos razones por las que podemos estar interesados en medir el grado de desigualdad global. Primera, debido a la preocupación por la "justicia global" podemos estar intrínsecamente interesados en la distribución de recursos entre los ciudadanos del mundo que refleja la preocupación por la desigualdad a nivel de países (Pogge, 2002; Singer, 2002). Esta visión cosmopolita del mundo supone una función global de bienestar social que trata por igual a las personas, independientemente de su país de residencia (Atkinson y Brandolini, 2010)8. Segunda, los cambios en la desigualdad global captan algunos efectos de la globalización. En el periodo de 20 años que aquí analizamos, la economía mundial se volvió más integrada. Queremos subrayar que a las estimaciones que aquí se presentan no se les puede dar una interpretación causal porque no existen economías mundiales contrafactuales. Además, la globalización no empezó en 1988. Pero desde entonces el patrón del comercio y de los flujos globales de capital cambió dramáticamente, con la integración de China (Haskel et al., 2012), de otros países en desarrollo (Goldberg y Pavcnik, 2007) y de Rusia a la economía mundial. Bourguignon (2012) también considera los efectos de la globalización sobre la desigualdad global, pero se centra en sus efectos sobre la distribución dentro de los países9.
La desigualdad global se mediría idealmente a partir de una encuesta única de hogares mundial representativa, lo que sería análogo a medir la desigualdad en cada país a partir de su encuesta nacional de hogares. En ausencia de esa encuesta, debemos combinar las encuestas nacionales de hogares. La mayor parte de la literatura sobre desigualdad global usa 1) información distributiva (p. ej., índices de Gini) de bases de datos secundarios, como Deininger y Squire (1996); 2) supone que en todas partes el ingreso o el consumo se distribuyen según una distribución log-normal, y 3) usa ingresos promedio de cuentas nacionales (p. ej., Bourguignon y Morrisson, 2002, y Sala-i-Martin, 2006). El punto (3) implica un rechazo del ingreso o consumo promedio de las encuestas de hogares, que suele estar disponible. Los puntos 1-3 son conjuntamente necesarios para obtener el nivel de ingresos en todos los puntos de la distribución supuesta. Según Anand y Segal (2008), Milanovic (2002, 2005, 2012) es el único autor que trabaja directamente con los datos de encuestas de hogares sin escalar a cuentas nacionales; seguimos este enfoque en nuestra especificación básica.
Anand y Segal (2008) revisan en detalle la literatura sobre desigualdad interpersonal global hasta la fecha. Todos los estudios coinciden en que el nivel de desigualdad es muy alto, con un índice de Gini del 63,0% al 68,6% en los años noventa. Debido a que las metodologías y las fuentes de datos difieren sustancialmente (p.ej., el uso de agregados de cuentas nacionales, la estimación de la distribuciones dentro los países, el uso de tasas de cambio PPA diferentes y a menudo inconsistentes), hay mucha incertidumbre sobre la dirección del cambio en la desigualdad global. De allí que haya "insuficiente evidencia para rechazar la hipótesis nula de ningún cambio en la desigualdad interpersonal global en 1970-2000" (p. 91), en lo que Pinkovskiy (2013) coincide usando una metodología muy diferente (ver más atrás). En la sección de resultados comparamos nuestras estimaciones con estos resultados anteriores.
Tasas de cambio PPA
La comparación de ingresos en países diferentes requiere usar tasas de cambio. Si la ley de un precio se mantuviese y no hubiese bienes no transables, simplemente podríamos usar tasas de cambio de mercado (Deaton y Heston, 2010). Pero este no es el caso y estas tasas subestimarían el nivel de vida real de los países pobres, sobrestimando así la desigualdad global (Anand y Segal, 2008)10. Usamos tasas de cambio PPA para tener en cuenta las diferencias en el costo de vida entre países. Las tasas de cambio PPA convierten una moneda local dada en dólares, el numerario. Puesto que nos ocupamos del ingreso o el consumo de los hogares, usamos las tasas de cambio PPA para el consumo privado en vez de los factores de conversión del PIB.
El primer paso en el cálculo de las PPA involucra la recolección de datos de precios en todo el mundo por el Programa de Comparación Internacional, que en su ronda más reciente fue coordinado por el Banco Mundial. La última ronda de comparación de precios se refiere a 2005. Esta ronda tiene la mayor cobertura global e incluye 146 países, frente a 117 de la ronda anterior de 1993. China participó por primera vez, e India por primera vez desde 1985.
Además de las mejoras en la cobertura de los países, la metodología de las encuestas también se mejoró en la última ronda del IPC, sobre todo en la especificación de los productos. Pero el problema del sesgo urbano en la recolección de precios (es decir, de datos recolectados desproporcionadamente en áreas urbanas) ha recibido particular atención en el caso de China, donde la ronda del IPC de 2005 llevó a una sustancial revisión hacia arriba del nivel de precios anterior (el cual se basó principalmente en conjeturas). La encuesta de precios se hizo en 11 áreas metropolitanas y periurbanas escogidas porque era probable que hubiese lugares de venta de los productos comparados en la encuesta del IPC (Cheny Ravallion, 2010a); estos autores argumentan que el nivel de precios medido es representativo de los precios urbanos y sobrestima notablemente el nivel de precios rural. Aquí seguimos el enfoque adoptado por Chen y Ravallion (2010b): tratar la tasa PPA oficial como representativa de China urbana y usar una tasa PPA ajustada hacia abajo para China rural.
El segundo paso para estimar las tasas de cambio PPA es calcular un índice de precios, es decir, un esquema ponderado particular que combina los precios nacionales recolectados en el primer paso. En la ronda del IPC de 2005, el Banco Mundial usó el índice EKS debido a Eltetö y Koves (1964) y Szulc (1964). Las Penn World Tables y las estimaciones anteriores del Banco Mundial usaron el método Geary-Khamis (GK) (Khamis, 1972). El índice EKS es un índice multilateral de precios que combina todos los índices bilaterales de precios de Fischer11. Más precisamente, es la media geométrica de todos los índices indirectos de Fisher entre el país base y el país de interés12. El índice EKS satisface la transitividad, de modo que tenemos un índice por país en vez de una matriz de índices. Pero elmétodo EKS viola la propiedad de "independencia de país irrelevante", puesto que el índice entre dos países cualesquiera es afectado por precios y ponderaciones de terceros países (porque combina los índices indirectos de Fisher).
El índice GK compara precios nacionales y precios mundiales. El problema es que en el cálculo de estos precios mundiales el peso asignado a un país depende de su volumen físico de consumo. Así, en la práctica, los países ricos dominan estos precios mundiales compuestos. Como los bienes que son relativamente caros en países ricos (p. ej., los servicios) tienden a consumirse en cantidades relativamente grandes en países pobres, precisamente porque son más baratos, el uso de un índice GK tiende a sobrestimar el valor del consumo en países pobres. Esta es una manifestación del conocido efecto Gerschenkron (1947) (o sesgo de sustitución) que dice que el consumo de un país es sobrevalorado cuando se evalúa a los precios de otro país, y que cuanto más alejados están los dos vectores de precios mayor es la sobrevaluación. El índice EKS no padece este sesgo porque promedia los pesos del consumo de ambos países, haciendo "un compromiso que es posiblemente lo mejor que se puede hacer en tales circunstancias" (Deaton y Heston, 2010, 11)13. Como resultado del efecto Gerschenkron, el índice GK subestima la desigualdad global (y la pobreza global; ver Ackland et al., 2013). Deaton y Heston (2010) calculan la desigualdad del PIB per cápita entre países ponderada por la población usando diferentes índices. Obtienen un índice de Gini del 53,3% para el EKS y un valor del52,7% para el GK.
En resumen, usamos el índice EKS, como sugieren Anand y Segal (2008), Deaton y Heston (2010), Ravallion (2010) y Ackland et al.(2013). Para otros propósitos podría ser más relevante el índice GK, que satisface la aditividad14. Usamos una sola tasa de cambio PPA por país (diferenciando únicamente entre China urbana-rural, India e Indonesia), ignorando así cualquier diferencia de consumo y precios a lo largo de la distribución del ingreso15.
El problema final en el uso de PPA es cómo extender las PPA en el tiempo. Comparamos precios entre países solo una vez usando la ronda más reciente del IPC, confiando en la inflación doméstica de los precios al consumidor para las comparaciones dentro de los países. En otras palabras, nuestro enfoque solo requiere una ronda del IPC: las unidades de moneda local doméstica de cualquier año se convierten a precios domésticos de 2005 usando un deflactor doméstico del IPC, y a estas unidades de moneda local (a precios constantes) luego les aplicamos la tasa de cambio PPA de 2005 obtenida de las comparaciones directas de precios bajo el IPC.
Conceptualmente, nuestro enfoque es simple porque mantiene separadas las comparaciones en el espacio y en el tiempo. Todas nuestras comparaciones dentro de los países son independientes de los precios internacionales y solo dependen de los precios nacionales, lo que es atractivo ante todo porque los precios domésticos son apropiados para valorar los trade-offs a nivel de país (Nuxoll, 1994).
Cuentas nacionales y encuestas de hogares
Normalmente, el consumo per cápita de los hogares de cuentas nacionales es mayor que el consumo o el ingreso promedio registrados en las encuestas (Deaton, 2005)16. Además, como muestra Deaton, la discrepancia parece haber aumentado en el tiempo no solo en India (que es en cierto modo una cause célèbre a ese respecto) sino también en países ricos como Estados Unidos y Gran Bretaña. Los estudios sobre desigualdad global difieren en la manera de explicar esta discrepancia. En nuestra especificación principal, seguimos el enfoque sugerido por Anand y Segal (2008), y simplemente usamos el ingreso promedio registrado en las encuestas.
Como ya mencionamos, otros trabajos (excepto Milanovic, 2002,2012) anclan el nivel de ingreso a cuentas nacionales (usualmente al PIB per cápita), combinado con información distributiva de las encuestas de hogares y suponiendo log-normalidad. Anand y Segal argumentan que el PIB per cápita "no es una medida adecuada del ingreso de los hogares" (2008, 67) y que no se debería usar para anclar la media de las encuestas de hogares, porque incluye rubros como la depreciación, las utilidades retenidas o impuestos qufrdxsw3s" no se redistribuyen a los hogares, que solo están remotamente relacionados con el ingreso de los hogares. Además, hay "una incongruencia básica al suponer quelas distribuciones relativas dentro de los países son medidas aceptablemente bien por las encuestas, pero no su media" (Anand y Segal,2008, 70). Además, sustituir la media de las encuestas por un PIB per cápita normalmente mayor implica un ajuste equiproporcional de todos los ingresos. Es improbable que este tipo de ajuste, que llamamos "proporcional", sea correcto porque implica la misma subestimación del ingreso, en términos relativos, en la distribución total.
En comparación con el PIB, el gasto final en consumo de los hogares de cuentas nacionales está más cerca del ingreso (o el consumo) de los hogares registrado en las encuestas (Anand y Segal, 2008)17. Pero se debe señalar que los datos y los métodos utilizados para estimar el consumo de cuentas nacionales no son necesariamente más confiables que los de las encuestas de hogares (Anand y Segal ,2008; Deaton, 2005)18. También hay diferencias en la definición del consumo de las encuestas de hogares y de cuentas nacionales, como la inclusión del valor imputado de la vivienda ocupada por el dueño (aunque conceptualmente se debería incluir en ambos, pero en la práctica no se suele incluir en el de las encuestas de hogares), de los servicios financieros imputados y del consumo de entidades sin ánimo de lucro (Deaton, 2005).
Ingresos superiores
El trabajo reciente sobre desigualdad de la participación de los grupos superiores usando registros tributarios argumenta que los ingresos más altos están subestimados en las encuestas de hogares comunes. Esta literatura estudia la desigualdad en la parte más alta de la distribución, expresada típicamente como participación de la parte superior, por ejemplo la participación del ingreso total recibido por el 1% superior (Atkinson y Piketty, 2007, 2010). Los datos de impuestos pueden dar información más precisa sobre el ingreso de la parte superior por diversas razones: primera, puede ser más difícil entrar a las comunidades cerradas de los ricos que hacer encuestas en zonas pobres, de modo que la falta de respuesta a la encuesta aumentaría con el ingreso (Groves y Couper, 1998). Segunda, el1% superior es raro por definición, de modo que una encuesta de hogares con el tamaño de muestra estándar de unos pocos miles daría estimaciones poco precisas de la participación de los grupos superiores, o podría omitir del todo a estas personas. Por su parte, los datos de impuestos sobre muestrean intencionalmente a los ricos. Tercera, aspectos de diseño de las encuestas, como la codificación de los grupos superiores o la supresión de "valores atípicos", manipulan los ingresos más altos. Además, los datos de impuestos no están exentos de problemas, debido por ejemplo a la evasión de impuestos y a la minimización del ingreso, que pueden ser muy fuertes en los países en desarrollo.
Hay evidencia para apoyar el argumento de que los ingresos más altos se omiten en las encuestas de hogares. Alvaredo (2010) encuentra que una encuesta de hogares en Argentina no registra observaciones de ingresos mayores de 1 millón de dólares mientras que los datos de impuestos contienen cerca de 700 observaciones en ese rango. En una comparación de encuestas de hogares de 16 países de América Latina, Székely e Hilgert (1999) encuentran que los 10 hogares más ricos de las encuestas reciben ingresos similares al salario de un gerente. Parece razonable que los propietarios de capital en estos países reciban ingresos mucho mayores que los de un gerente. Algunos estudios comparan la participación estimada de los grupos superiores de encuestas de hogares y de datos de impuestos, y en algunos casos obtienen resultados muy similares, aunque esto suele depender de la disponibilidad de encuestas excepcionales que tengan tamaños de muestra suficientes y no estén sujetas a codificación de los ingresos más altos (Burkhauser et al., 2012, con datos internos de la CPS de Estados Unidos; Leigh y van der Eng, 2009, para Indonesia, y Morival, 2011, para Sudáfrica).
Dado que los datos de impuestos parecen ser más precisos para medir los ingresos más altos y que las encuestas de hogares ofrecen información más precisa del resto de la distribución, un paso natural sería combinar las dos fuentes de información para obtener una distribución del ingreso completa. Pero la aún escasa disponibilidad de datos de impuestos entre países limita la utilidad de ese ejercicio para analizar la distribución global. Además, las medidas de la población y del bienestar son esencialmente diferentes en las dos fuentes de datos, lo que dificulta ese ejercicio19.
Tratamiento conjunto de los ingresos superiores subreportados y de la discrepancia de cuentas nacionales
El subregistro de los ingresos más altos en las encuestas de hogares y su discrepancia con cuentas nacionales son asuntos estrechamente relacionados. Es razonable esperar y hay evidencia empírica para corroborar que la discrepancia entre encuestas y cuentas nacionales no es una distribución neutral, y que se debe principalmente a la falta de participación de los ricos en las encuestas de hogares (Mistaenen y Ravallion, 2003; Korinek et al., 2006)20. Deaton (2005) señala que, debido a que el consumo de cuentas nacionales hace seguimiento al dinero y no a las personas, es más probable que los datos de cuentas nacionales capten las grandes transacciones. Usando datos de registros tributarios de India, Banerjee y Piketty (2010) encuentran que una parte significativa de la discrepancia entre el crecimiento del consumo de cuentas nacionales y el de encuestas de hogares puede ser explicada por el subregistro de los ricos. Finalmente, se puede argumentar que las encuestas de hogares dan una buena aproximación al 90% inferior de la distribución (ignorando, sin embargo, el subregistro del ingreso entre los muy pobres)21.
En la segunda parte del análisis asignamos la brecha entre el consumo final de los hogares en cuentas nacionales y en las encuestas de hogares al 10% superior de la distribución y obtenemos cuantiles superiores más desagregados ajustando una distribución de Pareto a la cola superior. Nuestro enfoque se basa en Atkinson (2007), que usa una imputación de Pareto en combinación con los datos de Bourguignon y Morrisson (2002). Atkinson usa el PIB per cápita, repartiendo así de modo uniforme en la distribución la discrepancia entre cuentas nacionales y encuestas de hogares, pero para la parte superior "elonga" la distribución usando una interpolación de Pareto22. Llamamos "ajuste proporcional con cola de Pareto" al enfoque de Atkinson. En cambio, nuestra metodología propone asignar el "exceso" de consumo registrado en cuentas nacionales solo al decil superior y usar una interpolación de Pareto, elevando así el promedio y modificando la desigualdad. Llamamos "ajuste superior fuerte con cola de Pareto" a este ajuste.
Justificamos el ajuste de la media de las encuestas al consumo de cuentas nacionales en razón de los ingresos superiores omitidos. Esto, sin embargo, está sujeto a crítica. Se puede argumentar que algunos elementos del consumo de cuentas nacionales deberían (1) excluirse del todo o (2) repartirse a lo largo de toda la distribución y no solo en el 10% superior. Por ejemplo, parte de la discrepancia entre el consumo de cuentas nacionales y el de encuestas de hogares obedece a diferencias en la definición, como la inclusión de gastos de entidadessin ánimo de lucro que prestan servicios a los hogares (ESLSH) o al consumo imputado de bienes proporcionados colectivamente23. Debemos restar estos componentes del consumo de cuentas nacionales, pero no se dispone por separado de datos suficientemente detallados para un gran número de países. Se podrían incluir (si no se estiman en las encuestas de hogares) otras fuentes de discrepancia, como los arriendos imputados de los propietarios ocupantes en cuentas nacionales, pero repartidas en toda la distribución y no solo en el 10% superior24. Por estas razones nuestras estimaciones deben verse como un primer paso aproximado, a falta de un análisis más cuidadoso que use datos de registro por unidad.
CONSTRUCCIÓN DE DATOS Y METODOLOGÍA
Fuentes de datos
En este artículo se usan como datos el ingreso-consumo promedio de los deciles año-país del periodo 1988-2008, es decir, el ingreso promedio per cápita de un decil dado en un país i en el año t. Los datos provienen de varias fuentes. PovcalNet es el punto de partida de nuestra base de datos, que aporta más de dos terceras partes de las encuestas25. PovcalNet compila un gran número de encuestas de hogares acopiadas por el departamento de investigación del Banco Mundial. Se ha usado sobre todo para estimar la pobreza mundial, como en Chen y Ravallion (2010b), y entonces carece de datos de los países ricos. A partir de PovcalNet obtenemos ingresos per cápita promedio, ya convertidos en dólares PPA de 2005, y participaciones de los deciles, que combinamos para calcular el ingreso promedio de los deciles26.
Después, combinamos los datos de la World Income Distribution (WYD) actualizados (Milanovic, 2012). PovcalNet y WYD proporcionan casi el 98% de los datos. Convertimos estos datos en deciles año-país para obtener una base de datos consistente27. Donde es posible, llenamos los vacíos restantes con datos del Luxembourg In-come Study (LIS), de la British Household Panel Survey (BHPS), de la European Union Survey of Income and Living Conditions (SILC)y de las oficinas estadísticas de los países28. En total terminamos con 565 encuestas en los cinco años de referencia: 1988, 1993, 1998, 2003y 2008 (cuadro 1).
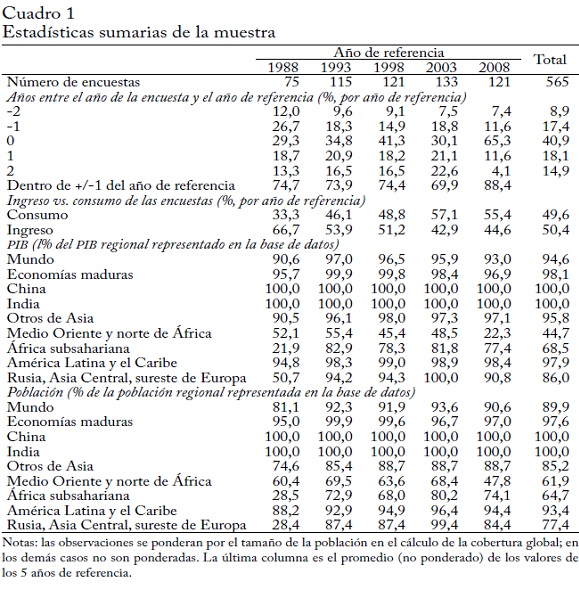
La distribución de cada país se representa mediante los ingresos promedio de los diez deciles. Esto no difiere de otros estudios como el de Bourguignon y Morrisson (2002), que usa 11 cuantiles, pero ignora cualquier desigualdad dentro de los deciles y, como argumentan Anand y Segal (2008), subestima entonces la desigualdad dentro de los países y quizá la desigualdad global. Nuestra elección de los grupos de deciles fue dictada por PovcalNet, donde no se disponía de información más detallada29. Por consistencia y facilidad de discusión,también decidimos usar deciles en las encuestas donde se disponía de información más detallada.
Selección de las encuestas
Las encuestas incluidas en la base de datos deben cumplir dos condiciones: primera, estar en un intervalo de dos años con respecto al año de referencia. Segunda, distar al menos tres años y no más de siete de la encuesta anterior y la siguiente. La justificación de la segunda condición es no permitir encuestas demasiado cercanas o lejanas del intervalo de cinco años, puesto que gran parte del análisis supone que los intervalos de cinco años se mantienen en toda la muestra. El cuadro 1 muestra los años que distan el año de la encuesta y el año de referencia30. La elección de los años de referencia es en esencia arbitraria, y seguimos a Milanovic (2012) al escoger 1988, 1993 y 1998. La cobertura de la encuesta global de hogares es muy baja antesde 1988. Los años 2003 y 2008 se escogieron para obtener años de referencia igualmente espaciados. En comparación con Milanovic(2012), logramos obtener un ajuste más cercano al año de referencia en todos los años con cerca de tres cuartas partes de las encuestas realizadas un año distante del año de referencia.
Usamos una mezcla de encuestas de ingreso y de consumo, como se acostumbra en la literatura. Aunque hay diferencias obviamente importantes entre el ingreso y el consumo, nos referimos a ellos en forma intercambiable, como ya se mencionó31. No ajustamos las diferencias entre ingreso y consumo de las encuestas porque ese ajuste, aplicado a los deciles, sería arbitrario32.
Una de las innovaciones de nuestra base de datos es que restringimos el concepto de ingreso para que sea igual en el tiempo para un país dado. Esto evita cambios espurios provenientes de un cambio en el concepto de bienestar que se está usando33. Para cada país, el ingreso/consumo se escogió a fin de maximizar el número de años de referencia cubiertos (sujeto a las dos condiciones antes mencionadas)34. Como muestra el cuadro 1, en la muestra total el número de encuestas de consumo y de ingreso es casi igual. En los años anteriores, la mayoría de las encuestas recogía información del ingreso, mientras que en los últimos años sucede lo contrario. Esto puede ser explicado por la mejor cobertura de las encuestas en países pobres, donde son más comunes las encuestas de consumo (salvo en América Latina)35.
El concepto de bienestar
Nos interesa analizar la distribución global (anual) del ingreso per cápita (en dólares PPA de 2005). Los ingresos per cápita ignoran algunas economías de escala en el consumo de los hogares y la desigualdad dentro de los hogares. Los ingresos per cápita tienen la ventaja de que es fácil calcularlos y tienen contrapartes naturales en cuentas nacionales (que no calculan ingresos equivalentes). El efecto de usar una escala de equivalencia diferente sobre la desigualdad mundial no es claro a priori36.
En nuestra base de datos, cada distribución año-país del ingreso per cápita se representa mediante los ingresos promedio de los diez deciles37. En el análisis, cada decil se pondera por su población (es decir, el 10% de la población nacional de los Indicadores Mundiales del Desarrollo, WDI). Siempre que estemos interesados en el desempeño de nuestra estimación o base de datos, por ejemplo, en la división de las encuestas de consumo e ingreso o en el valor de las constantes de Pareto, las observaciones no son ponderadas, como se indica en los cuadros.
Usamos el consumo PPA para tener en cuenta las diferencias de precios entre países. Los ingresos obtenidos de PovcalNet ya están convertidos a dólares PPA de 2005. Para las encuestas adicionales replicamos el enfoque de PovcalNet: como se explicó antes, y después de tener en cuenta la conversión de monedas38, convertimos los ingresos promedio en unidades de moneda local a precios de 2005 usando IPC domésticos39. Luego aplicamos las tasas de cambio del consumo PPA de 2005 para convertirlas a dólares internacionales40.
Es importante señalar que las tasas de cambio PPA solo existen a nivel de países, de modo que ignoramos toda diferencia de precios que exista dentro de los países. En consecuencia, posiblemente sobrestimemos la desigualdad dentro de los países. Como ya se mencionó,tratamos las zonas rurales y urbanas de los tres países en desarrollo más populosos -China, India e Indonesia- como "países" separados. Debido a la falta de datos desagregados, suponemos un IPC para las zonas rurales y urbanas, pero permitimos tasas de cambio PPA diferentes41.
La inmensa mayoría de las encuestas cubren todo el país, salvo en algunos países, sobre todo de América Latina, que solo encuestan zonas urbanas42. Tratamos estas encuestas como representativas de todo el país43.
Definición de regiones
Agrupamos los países en ocho regiones. El primer grupo consiste en economías maduras, 27 países de la EU (los miembros en 2008) más los países de alto ingreso en el mundo44. Tratamos a India y China como regiones por derecho propio. Los demás grupos se definen como residuos de acuerdo con las regiones geográficas de los WDI.
I Imputación de pareto y escalamiento al consumo de cuentas nacionaLes
Asignamos el exceso de consumo de cuentas nacionales frente al de las encuestas de hogares en tres pasos. Primero ajustamos el promedio país para igualar el consumo promedio máximo de las encuestas y el consumo de cuentas nacionales45. Después recalculamos la participación de todos los deciles excepto el más alto usando los ingresos promedio originales de los deciles y el promedio ajustado (por tanto, la participación en el ingreso total de aquellos deciles disminuye).Luego calculamos la nueva participación del decil más alto como la diferencia entre el 100% y la suma de las participaciones revisadas de los 9 deciles más bajos. Usamos las participaciones revisadas del 10% y el 20% superiores en la imputación de Pareto.
Obtenemos el gasto en consumo final de los hogares46 (en PPA de 2005) de los WID para los años de las encuestas47. Cabe señalar que la muestra cambia en esta parte del análisis por dos razones. Primera, debido a la falta de datos macro perdemos algunas observaciones año-país. Segunda, por falta de datos macro desagregados usamos las distribuciones de todo el país en los casos de China, India e Indonesia(donde antes usamos distribuciones urbana/rural por separado). En el caso de China, ahora usamos encuestas de ingreso donde antes usamos encuestas de consumo48.
Usamos una imputación de Pareto para dividir el decil superior en cuantiles más pequeños. Elegimos dividir el 10% más alto en P90-P95, P95-P99 y P99-P100. El conjunto de datos resultante consiste entonces en 12 grupos (desiguales) de fractiles por país (que son ponderados por la población en el análisis). El supuesto implícito es que el decil más alto de nuestra base de datos sigue una distribución continua de Pareto. Sea Hi la participación acumulativa de la población de individuos con ingresos mayores o iguales a y, por ejemplo, la población del i 10% superior. Sea S la participación del ingreso total recibido por este i grupo. Atkinson (2007) muestra que para esa distribución de Pareto, la participación relativa de los dos grupos superiores está dada por:
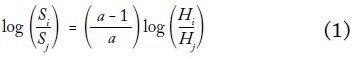
Podemos reordenar así para calcular el coeficiente de Pareto a:
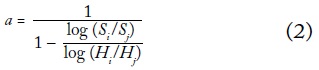
Usamos las participaciones del 10% y el 20% superiores para calcular el coeficiente de Pareto a para cada observación año-país49. Después calculamos las participaciones del 1% y el 5% superiores usando esta estimación de a y resolviendo la ecuación (1) para Si. Entonces podemos construir fácilmente los nuevos grupos de cuantiles. P99-P100 es simplemente el 1% superior. P95-P99 es la participación del 5% superior menos la participación del 1% superior. Y P90-P95 es la participación del 10% superior menos la participación del 5% superior. Para cada año-país, tenemos así 12 fractiles de ingreso.
La validez de nuestros resultados depende obviamente de los supuestos paramétricos. Nuestra elección de la forma funcional es relativamente común en la literatura, donde se argumenta que las colas superiores son aproximadamente de Pareto. Además, la estimación es relativamente flexible, pues estimamos una constante de Pareto diferente para cada observación año-país.
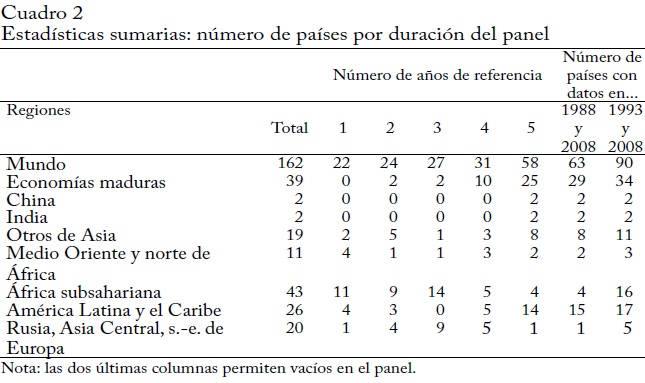
La dimensión de panel de nuestros datos
También nos interesan los cambios de un decil-país dado en el tiempo. Por ello, la dimensión del panel de nuestros datos es crucial. El cuadro2 cuenta el número de países por el número de años de referencia en los que un país aparece en los datos. Por ejemplo, para 58 países (de un total de 162), en su mayoría de economías maduras y de América Latina, tenemos el panel completo. Cuando examinamos los cambios entre dos años de referencia, no requerimos observaciones de los años intermedios, o sea que puede haber vacíos en el panel. Para 63 países, podemos entonces considerar los cambios entre 1988 y 2008. Como prueba de robustez, también consideramos el periodo 1993-2008, para el cual tenemos 90 países y en particular mejora la cobertura regional de África subsahariana, Rusia/Asia Central/sureste de Europa.
LA DISTRIBUCIÓN DE CORTE TRASVERSAL EN EL TIEMPO
Estadísticas sumarias
Como nos interesa analizar la distribución mundial del ingreso, una primera pregunta es qué tan representado está el mundo en las encuestas incluidas en nuestra base de datos (cuadro 1). Puesto que es más probable que los países de altos ingresos tengan una encuesta que puede estar incluida en nuestros datos, nuestra cobertura es mayor cuando se mide en términos del PIB que en términos de población. Nuestros datos representan el 95% del PIB mundial en promedio y más del 90% en todos los años de referencia. En promedio (y en todos los años desde 1993), también cubren el 90% de la población mundial.
Hay, sin embargo, grandes diferencias entre regiones. La cobertura de África subsahariana y Rusia/Asia Central/sureste de Europa mejoró notablemente, en particular después de 1988. Nuestra cobertura del Medio Oriente/norte de África parece haber disminuido, en particular en el año de referencia más reciente, más en términos del PIB quede la población50. En esta última parte del análisis nos centramos en el periodo 1993-2008, porque 1988 tiene mala cobertura de África subsahariana y Rusia/Asia Central/sureste de Europa.
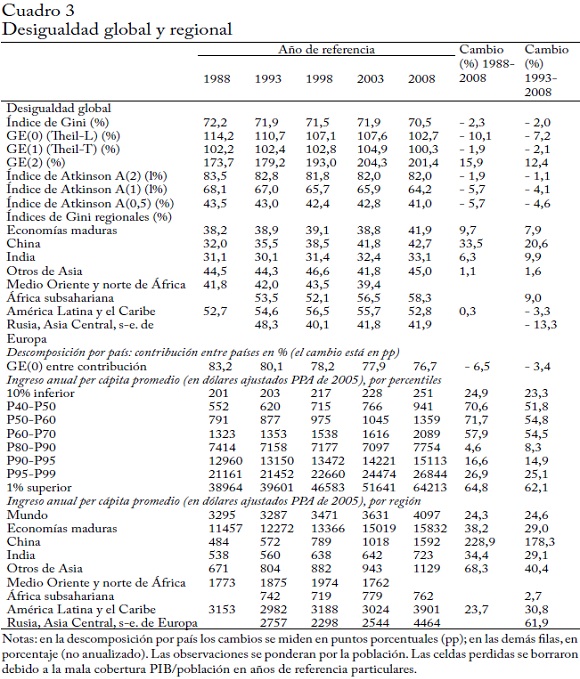
El índice de GINI de La distribución global del ingreso
El cuadro 3 presenta nuestros principales resultados sobre la desigualdad en la distribución global del ingreso calculada para el panel desbalanceado de deciles-país. En comparación con las distribuciones dentro de los países, encontramos un nivel muy alto de desigualdad medido por el índice de Gini: entre el 70,5% y el 72,2%51. El índice global de Gini se ha mantenido prácticamente sin cambios. Los cambios entre los años de referencia son de un 0,5%, excepto en el periodo 2003-2008, cuando el Gini disminuyó en un 1,89%, o 1,35 puntos Gini. Las curvas de Lorenz de 1988 y 2008 (que aquí no se muestran) se intersecan.
Podríamos calcular fácilmente los errores estándar de remuestreo del índice de Gini para tener en cuenta la incertidumbre de muestreo (es decir, del hecho de que usamos una muestra en vez de la población). Pero como argumentan Anand y Segal (2008), estos errores estándar no son apropiados, porque suponen que existe una sola encuesta de hogares global con una incertidumbre de muestreo claramente definida. En cambio, combinamos un gran número de encuestas nacionales de hogares, cada una con su propia incertidumbre de muestreo. Como resultado, los errores estándar plausibles pueden ser mucho mayores que los errores estándar de remuestreo, haciendo insignificantes los cambios observados.
Como muestra el cuadro 1A, nuestras estimaciones del índice de Gini global son mucho mayores que las estimaciones anteriores de la literatura52. Los estudios allí mencionados difieren esencialmente en su metodología, como en el uso de cuentas nacionales agregadas, en el tipo de tasas de cambio PPA y en la interpolación de años perdidos. Sin embargo, la mayor parte de la diferencia se debe a que estos estudios usan las "viejas" tasas de cambio PPA de 1993 que dan niveles de precios mucho más bajos para China, India, Indonesia, Bangladesh y otros países de Asia y, por tanto, implican ingresos más altos en esos países relativamente pobres. El estudio más cercano al nuestro es el de Milanovic (2012) que también usa únicamente encuestas, y aplica las tasas de cambio PPA de 2005. Nuestra estimación del índice de desigualdad global de Gini es mayor que la de Milanovic (2012), aunque la brecha disminuye en el tiempo, de 4,35 puntos Gini en 1988 a 1,76 puntos Gini en 2003. La dirección del cambio entre los años de referencia es similar, excepto la del periodo 1988-1993.
Medidas alternativas de desigualdad
Probamos la robustez de estas conclusiones a diferentes medidas de desigualdad, como las de Entropía Generalizada y de Atkinson. El índice de Gini da un peso particular a la desigualdad en los diferentes puntos de la distribución del ingreso. El índice de Theil-L (GE(0) o desviación logarítmica promedio) es muy sensible a diferencias en la participación de los ingresos bajos, mientras que el índice GE(2) es sensible a diferenciales en la parte superior (Cowell, 2009) y a valores extremos (Cowell y Flachaire, 2007). El índice de Theil-T (o GE(1))es un caso intermedio.
Conforme al índice GE(2), la desigualdad aumentó entre todos los años de referencia del periodo 1988-2003. Por su parte, conforme al índice Theil-L la desigualdad disminuyó entre 1988 y 1998 y tuvo un aumento marginal, pero quizá insignificante, de 1998 a 2003. Esto parece sugerir que entre 1988 y 2003 la desigualdad entre los ingresos más bajos disminuyó, mientras que aumentó entre los ingresos más altos. Entre 2003 y 2008 hubo una disminución en términos generales, pero un cambio más fuerte de la medida (0) sensible a diferencias en la parte inferior.
Calculamos el índice de Atkinson (1970) para tres niveles de aversión a la desigualdad e. Cuanto más alto es e más fuerte es la aversión a la desigualdad de la distribución del ingreso y mayor el peso asignado a los ingresos más bajos. Para e = 0, la sociedad es indiferente al grado de desigualdad del ingreso. Con e = ∞, solo importa la posición del grupo más pobre.
Según todos los tres niveles de e, la desigualdad es más alta en 198853. A(1) y A(0,5) coinciden en la ordenación relativa de los años de referencia (de la desigualdad más baja a la más alta: 2008, 1998,2003, 1993, 1988). Para A(2), el mayor nivel de aversión a la desigualdad que aquí se considera, 2008 tiene un nivel de desigualdad más alto que 1998, y el nivel no es diferente entre 2003 y 2008 (al menos para un punto decimal). Además, e > 2 mostraría un aumento de la desigualdad entre 2003 y 2008 (en contraste con las demás medidas que aquí se reportan). En suma, entre 2003 y 2008 los ingresos bajos no mejoraron mucho, lo que lleva al mismo valor de A(2) en 2008 y 2003, mientras que grados de aversión a la desigualdad menores -A(1) y A(0,5)- muestran una mejoría.
Desigualdad regional y descomposición de la desigualdad global entre países
El índice de Gini calculado para todos los individuos que viven en una región es más alto en América Latina y África subsahariana. En las economías maduras hubo un fuerte aumento en el último año de referencia. La desigualdad en China aumentó fuertemente entre 1988y 2008, en más de 10 puntos Gini. El incremento en India fue mucho más moderado. El índice de Gini de África subsahariana aumentó en cerca de 5 puntos Gini entre 1993 y 2008. En el Medio Oriente y Rusia/Asia Central/sureste de Europa la desigualdad parece haber disminuido. La desigualdad en América Latina y otros de Asia se mantuvo prácticamente inalterada, con altibajos, en el periodo considerado.
Presentamos una descomposición de las medidas de Entropía Generalizada, que, a diferencia de los índices de Atkinson y de Gini, son descomponibles aditivamente54. Nos concentramos en el índice GE(0), porque la interpretación del componente dentro-de-grupos como la desigualdad residual después de igualar los ingresos promedio entre países solo es correcta para este índice del tipo GE (Anand y Segal, 2008)55. La contribución dentro-de-países disminuyó en este periodo de 20 años, lo que sugiere que los países, ponderados por sus poblaciones, se han vuelto más similares56. En 2008 la igualación de los ingresos promedio entre países, manteniendo igual la distribución dentro de los países, reduciría la desigualdad global en un 77%. En cambio, la igualación de los ingresos dentro de cada país solo la reduciría en un 23%. En otras palabras, a pesar de su disminución relativa, el componente dentro-de-países sigue siendo de lejos la fuente más importante de desigualdad global.
Curvas de incidencia del crecimiento
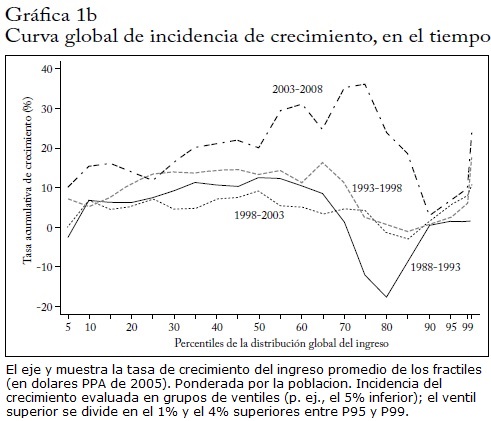
La parte inferior del cuadro 3 muestra el crecimiento del ingreso promedio por fractiles de ingreso. El grupo que creció con más rapidez es el que se sitúa entre los percentiles 50 y 60 (con una tasa de crecimiento del 71,7% en 20 años), seguido por el grupo P40-P50 (70,6%) y el 1%global más alto (64,8%). Quizá una manera más útil de ilustrar este patrón sea mediante una variante de la curva global de incidencia del crecimiento (CIC) (Ravallion y Chen, 2003)57. Esta compara el ingreso medio del grupo de un fractil dado (p. ej., el 10% inferior, el 1% superior) en 2008 (p. ej.) con el ingreso medio del mismo grupo en 1988. Esto se muestra en las gráficas 1a, 1b y 1c, donde el eje y es la tasa de crecimiento total entre esas dos fechas. Una CIC inclinada hacia abajo (hacia arriba) implica que el crecimiento económico tiene un efecto de igualación (desigualación) en la distribución del ingreso, es decir, que es pro pobre (pro rico). Estas CIC son anónimas porque ignoran la composición de la población que se encuentra en el mismo fractil de ingresos en dos años diferentes.
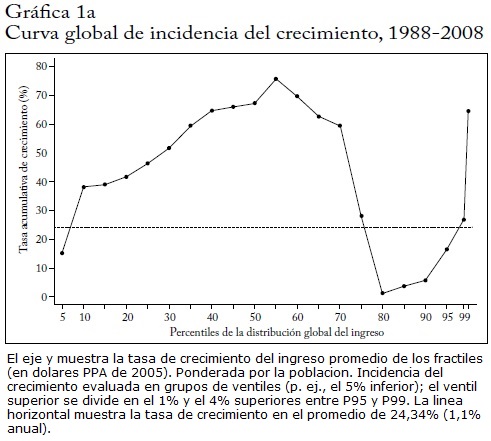
La gráfica 1a muestra la CIC global del periodo 1988-2008. Como vimos en el cuadro 3, el crecimiento fue más alto en el rango P50-P60. Desde cerca del percentil 75, el crecimiento es menor que el crecimiento del promedio global. Luego, para el 1% superior de la distribución global, el crecimiento vuelve a ser más alto que el promedio. Esto da a la curva CIC una forma de S ladeada, con dos picos, cerca de la mediana y en la parte muy superior, y un engrosamiento alrededor de los percentiles 80-85. Debido a que la CIC es siempre mayor que 0, la distribución global estocástica de primer orden de 2008 domina la distribución de 1988.
La gráfica 1b repite la CIC global para periodos de 5 años separados entre años de referencia. La CIC de 2003-2008 está en forma casi uniforme por encima de la de los demás periodos, lo que sugiere que el crecimiento fue mayor en este periodo. Durante 1988-1993 los ingresos disminuyeron particularmente para los percentiles situados entre el 70 y alrededor del 88. Las curvas quinquenales sugieren que la forma de S ladeada estuvo presente en todo el periodo de 20 años. Las ganancias de los percentiles mediano y superior fueron particularmente fuertes en el último periodo (2003-2008), mientras que las pérdidas de los grupos situados alrededor del percentil 80 fueron excepcionalmente altas en el primer periodo (1988-1993).
La última parte del cuadro 3 muestra el crecimiento del ingreso promedio de las diferentes regiones. No es sorprendente que China sea la región de mayor crecimiento; los ingresos promedio se triplicaron entre 1988 y 2008. Es seguida por Rusia/Asia Central/sureste de Europa (solo tasas de crecimiento de 15 años) y Otros de Asia. Las economías maduras e India crecieron a una tasa muy similar, superio ral promedio mundial. América Latina creció a una tasa más baja (marginalmente) que el promedio mundial. África subsahariana casi no creció entre 1993 y 2008. La ordenación regional del crecimiento ilustra claramente entonces el éxito de China y del resto de Asia, un buen desempeño de las economías maduras e India y un resultado muy decepcionante en África.
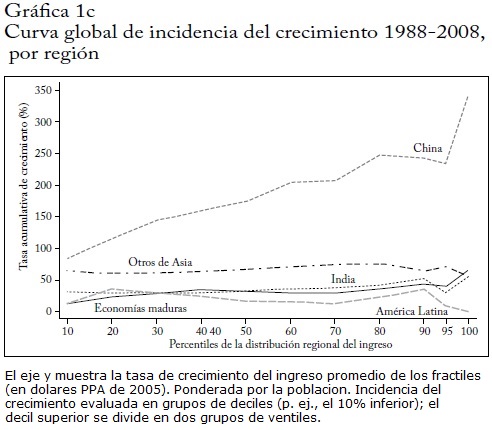
La gráfica 1c muestra las CIC de 20 años de cinco regiones58. Con la posible excepción del 5% superior en América Latina, siempre están por encima de 0, de modo que las distribuciones estocásticas de primer orden de 2008 dominan las distribuciones de 1988. El crecimiento parece ser fuertemente pro rico en China y menos en las economías maduras e India, mientras que la CIC es plana para Otros de Asia y no muestra una dirección clara en América Latina.
Mientras que la CIC global mostró ganancias relativamente grandes para la parte de la distribución cercana a la mediana, debemos recordar que estas ganancias fueron medidas en términos relativos (porcentaje). Pero precisamente debido a que la desigualdad global del ingreso es sumamente alta, y a que el ingreso de la parte superior es varios órdenes de magnitud mayor que el ingreso de la parte mediana (en 1988, el ingreso medio per cápita del 1% superior era de unos 39.000 dólares PPA mientras que el ingreso mediano era de unos 600 dólares PPA), las ganancias absolutas son mucho mayores para los percentiles más altos. La gráfica 1d muestra que el ingreso medio per cápita del 1%superior aumentó en 25.000 dólares PPA entre 1988 y 2008, mientras que la ganancia absoluta de la mediana global fue de solo 400 dólares PPA. Las ganancias absolutas en los percentiles más pobres fueron aún menores. El resultado total fue entonces que el 44% del incremento del ingreso global entre 1988 y 2008 fue al 5% superior de la población mundial59.
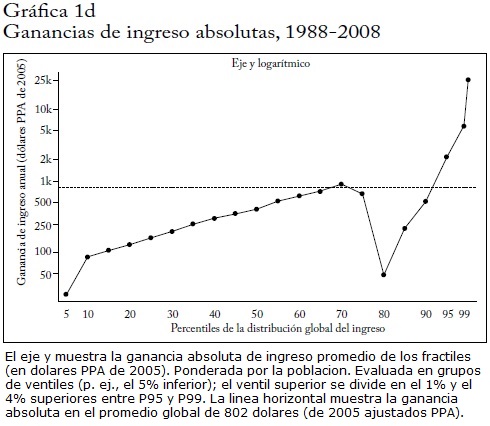
La composición regional de la distribución global
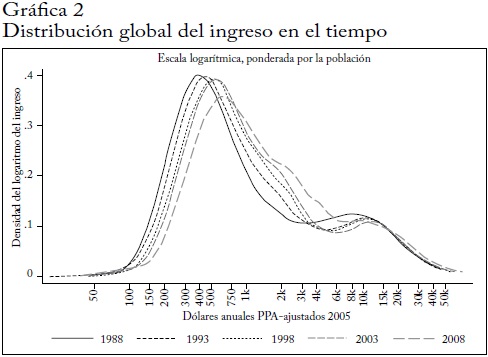
La gráfica 2 muestra cómo ha cambiado en el tiempo la distribución global del ingreso60. El crecimiento del ingreso se muestra mediante el desplazamiento de la distribución hacia la derecha. La distribución de 1988 parece tener dos picos, uno alrededor de 400 dólares PPA y otro alrededor de 10.000 dólares PPA. En 2008, el segundo pico desapareció y hay más masa cerca de la marca de 3.000 dólares PPA. Como implican las casi universalmente positivas CIC del periodo de cinco años (gráfica 1b), la gráfica de la distribución global se desplaza a la derecha en cada periodo de cinco años y el cambio más notable es la expansión de la proporción de la población global con ingresos de 750 a 6.000 dólares PPA (es decir, de aproximadamente 2 a 16 dólares PPA diarios). Esa población pasó de 1,16 mil millones de personas, un 23% de la población mundial, en 1988 a casi 2,7 mil millones, un 40% de la población mundial, 20 años después61.
Para desenmarañar aún más estos cambios, la gráfica 3 muestra las densidades del núcleo agrupadas por regiones62. No es sorprendente que el crecimiento de China haya tenido un profundo efecto en la distribución global. El cambio en la forma total de la distribución parece ser indicado por el movimiento ascendente del ingreso de los deciles superiores de China. China e India ascendieron a lo largo de la distribución mientras que África subsahariana (que no se muestra en la gráfica) parece estar atrapada en la parte inferior.
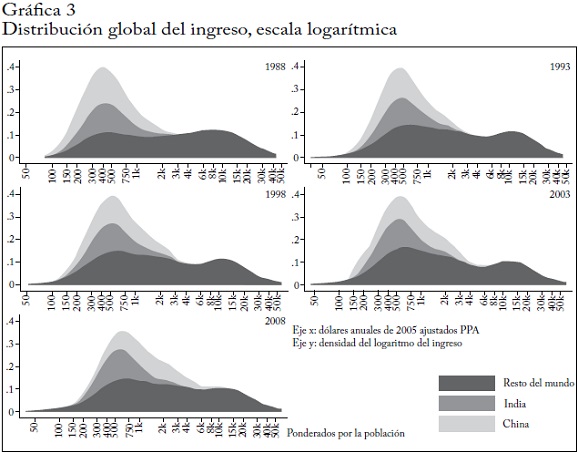
El movimiento ascendente de China, por su magnitud en términos de población y cantidad de crecimiento, está muy bien ilustrado en las densidades del núcleo agrupadas. En 1988, la población china se distribuyó simétricamente sobre la moda de la distribución global (excluida China). En otras palabras, China y el resto del mundo tenían casi el mismo ingreso modal. Con cada periodo sucesivo de cinco años, la distribución china se desplazó más hacia la derecha (hacia niveles de ingreso más altos), hasta que en 2008 unas cuatro quintas partes de la población china tenían un ingreso mayor que el ingreso modal mundial sin China. La moda del ingreso en China es ahora claramente mayor que en el resto del mundo. Este desplazamiento hacia la derecha de la distribución china es lo que más contribuyó al cambio de una distribución global de dos picos en 1988 a una distribución de un solo pico 20 años después. Esto ocurrió en su mayor parte porque China "llenó" la parte relativamente vacía de la distribución global del ingreso entre 2.000 y 6.000 dólares PPA.
La gráfica 4 se centra en el cambio de la composición regional de la distribución global del ingreso entre 1988 y 2008. La gráfica muestra la composición regional de la población en cada ventil de la distribución global63. Igual que antes, podemos ver un claro movimiento ascendente de China. El decil superior de China llega hasta el ventil 17 (es decir, entre los percentiles 80 y 85) de la distribución global en 2008, mientras que en 1988 los chinos más ricos solo estaban entre los percentiles 65 y 70. A la inversa, en 2008 China salió totalmente del 5% inferior del mundo, mientras que en 1988 casi el 40% de la población estaba en ese grupo.
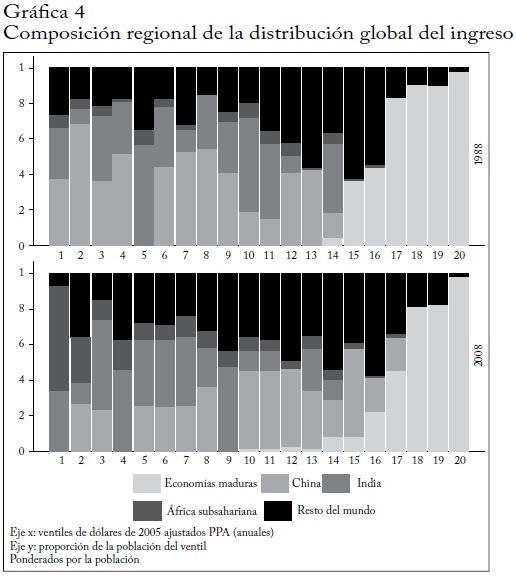
A medida que los ingresos más bajos de China han ascendido en la distribución global, en África subsahariana y en menor grado en India ha aumentado la proporción de la población situada en el ventil más bajo. La distribución de África subsahariana es muy dispersa y algunos grupos de deciles (de Sudáfrica y las Seychelles) llegan al 10% superior de la distribución global. India no se ha movido dramáticamente, porque su tasa de crecimiento ha sido similar al promedio mundial.
Las CIC globales de 20 años muestran que los grupos de los fractiles situados entre el percentil 75 y aproximadamente el 95 crecieron más lentamente que el promedio mundial (gráfica 1a). En 1988, los percentiles situados entre el 70 y el 85(ventiles 15, 16 y 17) se originaron principalmente en las economías maduras y América Latina, y en menor grado en Medio Oriente y norte de África. En 2008, China y en menor medida Rusia64 se movieron a estos percentiles, reduciendo la participación de las economías maduras y América Latina y Medio Oriente, que los abandonaron casi del todo (no todas las regiones se muestran por separado). Estos cambios en la composición son los que explican la forma de la CIC global. La CIC no hace seguimiento a un grupo particular de fractiles sino que compara los ingresos de un fractil dado en las diferentes distribuciones iniciales y finales. Cuando comparamos los ingresos chinos más altos de 2008 con los ingresos latinoamericanos de 1988, obtenemos una baja tasa de crecimiento promedio. A pesar de que los ingresos chinos más altos crecieron mucho más rápidamente que el promedio global. Pero este tema, las curvas de incidencia del crecimiento (cuasi) no anónimas, que mantienen la composición de los fractiles igual a la del año original, se discute más adelante.
CONTABILIZACIÓN DE LOS INGRESOS SUPERIORES OMITIDOS EN EL CÁLCULO DE LA DESIGUALDAD GLOBAL
Hasta ahora, en el análisis usamos nuestra principal muestra de corte trasversal y únicamente la información contenida en las encuestas, es decir, no ajustamos los promedios de las encuestas a cuentas nacionales. En esta parte del análisis probamos la robustez de nuestras conclusiones: 1) al anclaje a cuentas nacionales, esto es, a la distribución del "exceso" de ingreso de la brecha entre el consumo de cuentas nacionales y el promedio de la encuesta de hogares bien sea en toda la distribución o solo en el decil superior, y 2) al uso de una interpolación de Pareto para "elongar" la distribución del decil superior.
El cuadro 4 presenta los resultados. Puesto que aquí remplazamos el promedio de las encuestas por el consumo privado de cuentas nacionales (solo cuando este último es mayor; si no lo es mantenemos el promedio de las encuestas65), perdemos los años-país para los cuales no tenemos información de cuentas nacionales. Esto deja 520 encuestas en los cinco años de referencia en vez de 565. Además, ahora tratamos a China, India e Indonesia como países únicos porque no tenemos información de cuentas nacionales para zonas rurales y urbanas por separado. El nuevo Gini de base de esta nueva muestra (cuadro 4, fila 1) es muy similar al Gini de la muestra completa (cuadro 3): la diferencia es de menos de 0,5 puntos Gini salvo en 2008, cuando el nuevo Gini de base es 0,9 puntos Gini menor que el obtenido con la muestra total.
Primero remplazamos el promedio de las encuestas por el consumo privado de cuentas nacionales, un "reanclaje" que se hace a menudo en la literatura, excepto que se suele hacer usando el PIB en vez del consumo privado. Tal "reanclaje" obviamente no cambia la desigualdad dentro de los países. El efecto total sobre la desigualdad global proviene del cambio dentro de los componentes (y, en el caso del índice de Gini, indirectamente del cambio en el componente de traslapo). Los cambios dentro de los componentes obviamente varían debido a que el promedio-país cambia. A priori no es clara la dirección en la que esperamos que cambie el Gini global. Pero los cálculos anteriores muestran sobre todo que el reanclaje al PIB (sin otros ajustes) tiende a disminuir la desigualdad global en los años más recientes (ver Milanovic, 2005, 118, y el cuadro 1A). Aquí encontramos el mismo resultado. Como se ve en el cuadro 4 (fila 2), el Gini disminuye en cerca de 1 punto, excepto (de nuevo) en 2008 cuando disminuye en 2 puntos Gini. Intuitivamente, la razón del cambio hacia abajo es que la subestimación de las encuestas es mayor en países más pobres (ponderados por la población). En otras palabras, los países pobres parecen menos pobres cuando remplazamos el consumo privado de las encuestas por el de cuentas nacionales.
Después suponemos que la distribución del 10% superior puede ser aproximada por una distribución de Pareto, lo cual es similar al enfoque de Atkinson (2007)66. Este "ajuste proporcional con cola de Pareto" deja aumentar la desigualdad dentro de los países, mientras que la desigualdad entre países permanece igual (pues los promedios no se alteran), y el término de traslapo permanece igual o aumenta. Es posible que el componente de traslapo aumente porque la "elongación" de las distribuciones tiende a aumentar la "confusión" entre el ingreso de la población de los países más pobres y más ricos (o en el caso extremo, no la cambia)67. En consecuencia, esperaríamos que el Gini global, comparado con el de la fila 2, sea mayor. Este es de hecho el caso (ver fila 3) aunque el incremento es muy moderado: a lo sumo medio punto Gini.
Por último aplicamos nuestro "ajuste fuerte superior con cola de Pareto", donde se permite que aumenten aún más las desigualdades dentro de los países. Esto se hace asignando toda la brecha entre el consumo privado y el promedio de las encuestas al decil superior y aplicando (como en el caso anterior) una "elongación" de Pareto. Debería ser intuitivamente claro que el aumento de la participación del decil superior aumenta la desigualdad del ingreso y reduce la constante de Pareto68. Como mostramos en el anexo 2, en algunos casos ese ajuste puede parecer excesivo, un problema que debemos abordar más exhaustivamente en futuros trabajos. Por ejemplo, si el promedio de las encuestas solo es igual al 50% del consumo privado (similar al valor observado en India), "atribuir" simplemente este 50% al decil superior es probablemente excesivo. Es posible que los ingresos de los deciles más bajos también se subestimen69, porque consideramos que el "ajuste fuerte superior con cola de Pareto" es un caso extremo. Los resultados (cuadro 4, fila 4) muestran que el incremento del Gini (comparado con el "ajuste proporcional con imputación de Pareto", fila3) es ahora de 4,5 a casi 8 puntos. De nuevo, el cambio más dramático ocurre en 2008. En el anexo 2 probamos la robustez de estos valores a un rango más plausible de coeficientes de Pareto.
En resumen, el Gini global calculado únicamente con datos de encuestas se reduce entre 1 y 2 puntos Gini cuando remplazamos el promedio de las encuestas por el consumo privado de cuentas nacionales (asignando así la brecha proporcionalmente entre distribuciones nacionales del ingreso). Cuando también suponemos una cola superior de Pareto, el Gini total apenas cambia: aumenta en cerca de 0,5 puntos Gini70. Solo si incrementamos más la desigualdad al no asignar proporcionalmente la brecha, sino imputarla únicamente al decil superior, el Gini global aumenta sustancialmente, entre 4,5 y casi 8 puntos. Pensamos entonces que esto fija el rango dentro del cual es probable que esté el Gini global "verdadero". En 2008, por ejemplo, ese rango está entre 68% y 76%. Nos inclinamos a pensar que está más cerca del límite superior pero no hay manera de probarlo.
El resultado principal de este ejercicio no es, sin embargo, el rango del nivel de desigualdad global, sino el cambio probable entre 1988 (o 1993) y 2008. Como aclaran las dos últimas columnas del cuadro 4, con un ajuste "fuerte superior" la reducción de la desigualdad global, presente cuando usamos todos los demás ajustes, casi se disipa totalmente. El cambio en el Gini global durante estos 20 (o 15) años es ahora de apenas -0,2 o -0,4 puntos, debido a que la brecha entre el promedio de cuentas nacionales y el de las encuestas aumentó de un promedio del 19% en 1988 al 25% en 200871 (ver el cuadro 2A). Cuando asignamos totalmente esta brecha a la cola superior, obtenemos una desigualdad creciente dentro de los países, y en últimas global. Antes argumentamos que la variación del índice Gini global observado de la muestra completa (y usando los ingresos reportados directamente en las encuestas) probablemente no era robusta a errores estándar plausibles. Esta prueba de robustez apoya una visión más cautelosa de la reducción de la desigualdad global: si las encuestas tienden de hecho a subregistrar los ingresos de la parte superior, bien podría ser que la desigualdad global, medida por el índice de Gini, no se haya reducido en el periodo de 20 años que consideramos.
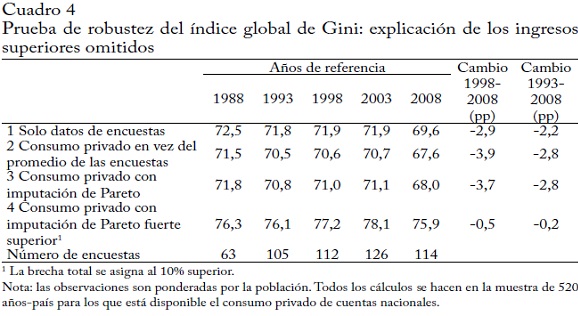
Usando el ingreso reportado en las encuestas, más atrás concluimos que la distribución global del ingreso había pasado de dos picos a un solo pico. Esto se mantiene para la distribución global del ingreso ajustada por los ingresos superiores perdidos (gráfica 5). No es sorprendente que la imputación fuerte superior de Pareto alargue la cola superior y la engruese alrededor de 40.000 dólares PPA. Más abajo de la distribución, la masa parece desplazarse de 3.000 a 5.000 dólares PPA, que son los fractiles más altos en países pobres.
CAMBIOS EN EL TIEMPO: ¿CUÁLES SON LOS GANADORES Y LOS PERDEDORES?
En esta sección volvemos al tema de los deciles-país que han contribuido a los cambios totales de la distribución global. La evidencia sobre el cambio de la composición regional (gráficas 3 y 4) fue un primer paso en esta dirección, aunque no dijo nada del movimiento de los deciles-país individuales. Esta sección intenta identificar los deciles-país que ganaron o perdieron más en el periodo.
La muestra usada en el texto principal incluye todos los países observados en 1988 y 2008, aunque hay vacíos en los años de referencia. En el anexo replicamos los resultados usando todos los países observados en 1993 y 2008, lo que mejora la cobertura sobre todo en África subsahariana y Rusia/Asia Central/sureste de Europa.
Curvas de incidencia del crecimiento cuasi no anónimas
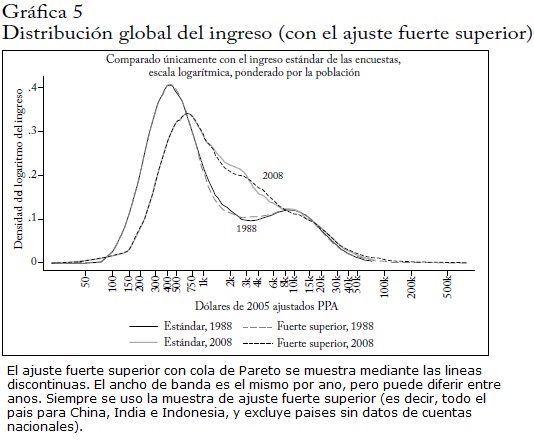
Para identificar los ganadores y perdedores, primero consideramos los "perfiles de movilidad del ingreso" (van Kerm, 2009), o "curvas de incidencia del crecimiento no anónimas" (Bourguignon, 2011a;Grimm, 2007). Cuando se aplica a datos de registro individuales, la distinción entre CIC anónimas y no anónimas es clara: la CIC anónima (estándar) compara el ingreso de un percentil dado en las distribuciones de los periodos inicial y final. En la medida en que hay alguna movilidad en la distribución, los individuos de este percentil pueden ser diferentes. En cambio, la CIC no anónima es la regresión (no paramétrica) del crecimiento del ingreso contra el rango (percentiles) de la distribución inicial72. Como esta tasa de crecimiento se obtiene para cada individuo, es no anónima, teniendo en cuenta la distribución conjunta del ingreso inicial y final. Pero en nuestro caso la unidad de análisis son los deciles de ingreso de un país particular, de modo que mientras preservamos la identidad de un decil -país particular, estos deciles se definen con respecto a personas diferentes. Por ello nos referimos a nuestras gráficas como curvas de incidencia del crecimiento "cuasi no anónimas".
La gráfica 6 muestra las CIC cuasi no anónimas de 1988-2008 y 1993-2008. Grafica el crecimiento durante los siguientes 20 (15) años contra el rango fraccionario normalizado de la distribución global transversal del ingreso de 1988 (1993). Para explotar las dimensiones transversal y de panel de los datos, cada observación incluida en la CIC cuasi no anónima se ordena en la distribución transversal (ponderada por la población) completa de 1988 (no solo entre los 63 países observados en 1988 y 2008)73. Para cada periodo, presentamos las gráficas con y sin el diagrama de dispersión74. Los diagramas de dispersión muestran la amplia dispersión de las tasas de crecimiento alrededor de la línea ajustada. A juzgar por la escala del eje y, la dispersión parece haber aumentado, pero esto podría ser inducido por un valor atípico cerca de los rangos más bajos en 1993-2008. La línea ajustada (una regresión polinomial local del núcleo ponderado) se muestra en un eje y más detallado del panel inferior para los periodos 1988-2008 y 1993-2008.
Es inmediatamente claro que la forma de las curvas cuasi no anónimas es muy similar a la forma de la CIC anónima (gráfica 1a): una forma de S ladeada inducida esencialmente por el muy lento crecimiento alrededor de los percentiles 80 y 90 de la distribución global, con máximos locales alrededor de la mediana de la distribución y en la parte muy superior. Pero si comparamos los resultados de 1988-2008, es claro que las ganancias de los deciles-país que estaban en el 1% más alto en 1988 fueron menores que las que obtenemos comparando simplemente los niveles de ingreso del 1% más alto en 2008 y 1988. Esto se esperaba: no todos los deciles-país que estaban en el 1% más alto en 1988 lograron un alto crecimiento en los siguientes 20 años. En forma similar, algunos deciles-país que no estaban en el 1% más alto en 1988 y mostraron alto crecimiento ahora están en el 1% más alto (en 2008). Encontramos el resultado equivalente para el decil-país más pobre de 1988 cuya tasa de crecimiento fue mayor que la que encontramos a partir de la CIC anónima. Además, algunas de estas diferencias pueden provenir de la restricción de la muestra a los países presentes en 1988 y en 2008.
En el periodo 1988-2008, el crecimiento más alto fue el de los deciles-país situados alrededor del percentil 40 de la distribución global de 1988, y el más bajo el de los alrededor del percentil 85. Los grupos de más éxito provienen en su gran mayoría de China e India y los de menos éxito sobre todo de economías maduras. Así, tres cuartos de la población que estaba entre los percentil globales 36 y 45 (incluido el percentil 45) en 1988 pertenecían, en general, a deciles-país de alrededor de la mitad de las distribuciones nacionales del ingreso, de China e India. Si incluimos a Otros de Asia, el porcentaje de personas perteneciente a estos grupos de más éxito llega al 90%. Los deciles chinos, por ejemplo, multiplicaron su ingreso por un factor de 2,7-2,8.
En cambio, los deciles-país situados entre los percentiles 81 y 90 (incluido el 90) en 1988 son abrumadoramente de economías maduras, y vienen de la mitad inferior de su distribución nacional del ingreso. De un total de 420 millones de personas pertenecientes a este grupo, cerca de 365 millones son de economías maduras (o, en otros términos, 135 de 165 deciles-país). Aunque de las economías maduras excluimos las que en 1988 eran comunistas, la participación de las economías ricas "tradicionales" en este grupo es aún muy grande: el 78% de las personas. Algunos ejemplos de economías ricas con tasas de crecimiento real particularmente bajas incluyen casi la mitad total inferior de las distribuciones del ingreso de Austria, Alemania, Dinamarca, Grecia y Estados Unidos. Todas ellas tuvieron tasas de crecimiento de menos del 20% en 20 años, lo que se traduce, en el mejor de los casos, en un 0,9% per cápita anual.
En el periodo 1993-2008, el crecimiento más alto fue el de alrededor del percentil 60. La forma de la línea ajustada también parece haber cambiado, con algunas tasas de crecimiento altas en los rangos más bajos de 1993. Esto se debe principalmente a la inclusión de Rusia en 1993 (ausente en 1988), cuyos deciles bajos experimentaron un alto crecimiento entre 1993 y 2008.
Más exitosos y menos exitosos
Consideremos ahora los 20 ganadores y perdedores más grandes (deciles-país) en este periodo de 20 años (cuadro 5)75. Ordenamos los deciles-país según el promedio de las tasas de crecimiento (anualizadas) de 5 años entre 1988 y 200876, 77.
Entre 1988 y 2008, los veinte deciles-país superiores (excepto uno) crecieron más del 5% al año, lo que significa que su ingreso aumentó al menos 2,65 veces. Para los deciles que crecieron alrededor del 8% al año, el ingreso real se multiplicó por un factor mayor de 4,5. Casi todos los grupos de deciles urbanos chinos se cuentan entre los veinte deciles de más rápido crecimiento del mundo. Además, se clasifican nítidamente entre los deciles más altos de más rápido crecimiento. Esto ilustra el patrón de aumento de la desigualdad del crecimiento ya observado en China. La China rural tiene un crecimiento más lento pero cabe observar que los dos deciles rurales más altos también están entre los veinte ganadores, y de nuevo se cuentan entre los deciles rurales superiores que crecieron más rápidamente que el segundo decil rural más alto. En general, el carácter notable del crecimiento chino -sumamente rápido y creador de mayor desigualdad- está bien ilustrado en estos datos: la mitad o más de los deciles-país más exitosos son de China. Cabe señalar que esto nada tiene que ver con el tamaño de la población porque aquí se trata por igual a cada decil-país. En efecto, debido al enorme tamaño de los deciles chinos, se podría argumentar que es más difícil elevar el ingreso promedio de esa gran masa de personas de lo que sería el caso en un país más pequeño. Aparte de China, los otros deciles de más rápido crecimiento son los deciles relativamente pobres de El Salvador, Costa Rica, Irlanda, Reino Unido y Chile.
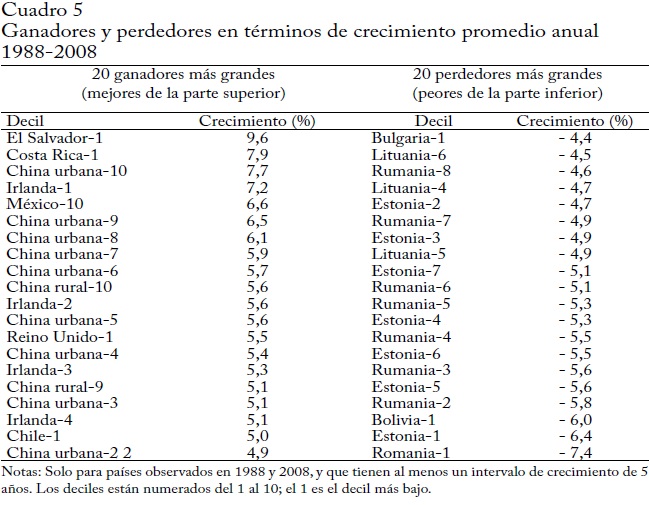
En la parte inferior hay una concentración similar. Con la excepción de Bolivia, los deciles del este europeo llenan casi exclusivamente los rangos de los grupos menos exitosos78. Casi todos los deciles de Rumania y Bulgaria parecen haber experimentado un crecimiento negativo. Una disminución promedio del 3-4% al año se traduce, después de 20 años, en una pérdida de ingreso real de cerca de la mitad. Los resultados son diferentes para el periodo 1993-2008 (cuadro 4A)79. Los deciles-país que más perdieron entre 1993 y 2008 son en su mayoría de África subsahariana y América Latina; los deciles del este europeo se recuperaron. Estos resultados son consistentes con las desastrosas reducciones del ingreso en Europa Oriental entre 1988 (el comienzo del proceso de reforma) y mediados de los noventa, seguidos en algunos países por una fuerte recuperación, y en otros por una lenta recuperación.
Otra manera simple de evaluar el éxito de los diversos deciles-países comparar su posición en la distribución global del ingreso. Esto se puede hacer obviamente para cada decil-país y cada año. En la gráfica7, lo hacemos para varios países seleccionados. El panel izquierdo superior ilustra la notable movilidad ascendente (en la distribución global) ya discutida de los deciles rurales y urbanos chinos. En 2008, el decil urbano chino superior está en el percentil global 83 mientras que 20 años antes estaba en el 68. En otras palabras, si alguien siguió en el mismo decil chino durante 20 años y su ingreso siguió la senda de crecimiento promedio del decil, superó, en términos de ingreso, a más de 900 millones de personas de todo el mundo. Es interesante que en 2008 el percentil rural chino superior esté en una posición global más alta que la del percentil urbano chino en 1988. Esa misma evolución, aunque menos dramática, es ilustrada por las mejoras en la posición de los deciles rurales y urbanos indonesios que se muestra en el panel superior derecho de la gráfica 7.
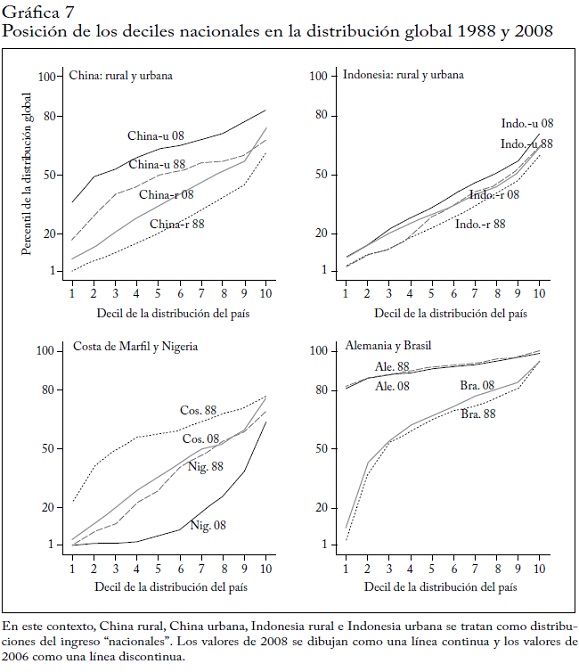
Pero cuando pasamos al panel izquierdo inferior la situación es exactamente la contraria. Allí vemos que los deciles de Nigeria y Costa de Marfil se desplazaron casi uniformemente hacia abajo en la distribución global del ingreso. Solo el decil superior marfileño logró conservar su posición de 1988. Por último, en el panel inferior derecho mostramos la evolución de Alemania y Brasil. La posición de los deciles alemanes se mantuvo muy alta y muestra muy poca variación. Brasil es un ejemplo de un crecimiento razonablemente rápido en todo su espectro de ingresos y de mejoras en la distribución, hasta el punto de que todos sus deciles, excepto el más alto, ahora se sitúan globalmente más arriba que en 1988.
CONCLUSIÓN
El artículo presenta evidencia sobre la evolución de la distribución global del ingreso durante un periodo crucial de globalización acelerada que va desde el fin de los regímenes comunistas en Europa Oriental y la Unión Soviética hasta el comienzo de la crisis financiera global. En muchos aspectos, este puede haber sido el periodo más globalizado (y más optimista, en el sentido de confiar en el potencial de la globalización) de la historia. Es muy importante estudiar cuáles fueron sus efectos sobre el nivel y la distribución del ingreso entre la población mundial. Nuestros resultados confirman los hallazgos anteriores de que el nivel de desigualdad global sigue siendo alto, con un Gini de alrededor del 70%, y que aunque la desigualdad parece haber disminuido en los años más recientes, probablemente estos cambios no son robustos a errores estándar plausibles (si se pudieran formular y calcular).
Una prueba de robustez por medio de la cual los ingresos perdidos, definidos como la brecha (positiva) entre el consumo per cápita de los hogares de cuentas nacionales y el ingreso per cápita promedio de las encuestas de hogares, se asignan al 10% superior de los individuos receptores, y se supone que los ingresos más altos siguen una distribución de Pareto, da estimaciones del índice global de Ginicerca de 5 puntos mayores. La mayor parte del incremento se debe a la asignación de toda la brecha al decil superior, no a la elongación de Pareto de la parte superior de la distribución. Un valor del 75% se puede considerar como el límite superior del Gini global "verdadero".
El enfoque mediante el cual se asigna la brecha total a los deciles nacionales más altos nos parece más realista que la alternativa usada hasta ahora en la literatura de repartir uniformemente la brecha. En efecto, argumentamos que los dos problemas que se han discutido por separado -la gran, y en algunos casos, creciente brecha entre el consumo de cuentas nacionales y el promedio de las encuestas de hogares, y la comprensión, debida a los resultados obtenidos de datos fiscales, de que las encuestas tienden a subestimar los ingresos superiores- son en realidad uno y el mismo problema.
Nuestro enfoque arroja otro resultado importante. La desigualdad global, medida por el índice de Gini, puede no haber disminuido en absoluto si todo el ingreso perdido (o su mayor parte) proviene de la subestimación del ingreso en la parte superior de las distribuciones nacionales. Es obvio que este importante problema requiere más investigación, pero pone de relieve los posibles efectos globales del subregistro en la parte superior señalados en varios países.
La forma de la distribución global del ingreso también cambió en los 20 años considerados aquí (con respecto al escenario de base sin ajustar por los ingresos superiores perdidos). En 1988, la distribución global del ingreso mostró una forma de dos picos que desde entonces desapareció en gran parte gracias al alto crecimiento de China, cuyos deciles "llenaron" el rango situado entre 2.000 y 6.000 dólares PPA, que estaba relativamente "vacío" en 1988. El periodo también presenció un notable incremento de lo que se puede llamar una "clase media global", con ingresos de 2 a 16 dólares PPA per cápita al día: la participación de la población mundial perteneciente a ese grupo pasó del 23% al 40%.
Particularmente importante es la forma de las CIC anónimas y cuasi no anónimas en el periodo 1988-2008. Ambas muestran grandes ganancias relativas alrededor de la mediana de la distribución global del ingreso, que fueron principalmente a los deciles medio o medio superior de Asia y especialmente de China. En cambio, las ganancias de ingreso real más bajas se registraron en el rango situado alrededor de los percentiles globales 80-85, donde los deciles de bajos ingresos de las economías maduras estaban sobrerrepresentados. Un hecho sorprendente es que en los percentiles de 1988 que 20 años después resultaron ser la parte más exitosa de la distribución global del ingreso, el 90% de las personas provenía de Asia. Entre los percentiles de 1988 que 20 años después resultaron ser la parte menos exitosa, el 86% provenía de economías maduras.
El artículo hace otra contribución. Se creó una nueva base de datos, que (a) consta casi totalmente de datos derivados de micro datos de las encuestas de hogares, (b) mantiene constante el concepto (ingreso o consumo) de las encuestas de hogares en el tiempo para un país dado, (c) solo usa las tasas de cambio PPA más recientes y más robustas y (d) hace posible un análisis de panel balanceado entre los deciles-país. Este último aspecto es especialmente importante porque no se ha usado antes. En otras palabras, aunque sabíamos que las tasas de crecimiento de China eran altas y que el proceso era pro rico (los deciles más altos crecen más rápidamente), no podíamos comparar directamente el crecimiento del decil urbano chino superior con su decil rural 8 (p. ej.), y aún menos con el crecimiento de los deciles de Reino Unido, España o Kenia. Ahora todo esto es posible, y aquí solo explotamos algunos aspectos abiertos por la nueva base de datos. De hecho, encontramos que todos los deciles chinos, rurales y urbanos, mejoraron su posición relativa en la distribución global, a veces dramáticamente, saltando más de 10 percentiles. El decil urbano chino superior pasó así de estar en el percentil 68 del mundo al 83. Por otra parte, varios países africanos experimentaron una evolución exactamente opuesta: la posición de todos o casi todos sus deciles descendió globalmente. China contiene la mitad de los 20 deciles-país superiores más exitosos en el periodo 1988-2008. Entre los deciles-país menos exitosos es preponderante la participación de deciles del este europeo y más recientemente africanos.
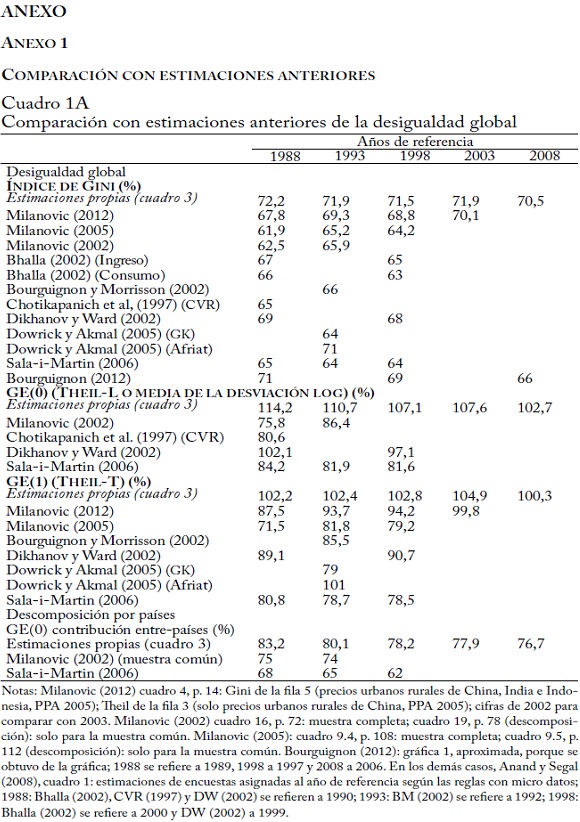
Anexo 2
Pruebas de robustez para la cola de pareto fuerte superior
Para determinar si nuestros resultados son razonables consideramos el tamaño del ajuste a cuentas nacionales y comparamos nuestros coeficientes de Pareto con los de la WTID (Alvaredo et al., 2013). Esto último es necesario para averiguar si nuestra combinación de la asignación de la brecha total al 10% superior y la aplicación de un ajuste de Pareto a las participaciones recién calculadas produce coeficientes de Pareto similares a los observados en los datos fiscales de la WTID (que se cree son razonablemente buenos para captar la participación de los ingresos más altos). Por supuesto, no esperaríamos una correspondencia exacta debido a las diferencias (p. ej., en la definición del ingreso o de la unidad de análisis) entre las dos fuentes de datos. Por último, probamos la robustez del índice global de Gini a un conjunto restringido de coeficientes de Pareto.
Para resumir la magnitud de nuestro ajuste a cuentas nacionales, el cuadro 2 del anexo presenta los valores mínimo y medio de la relación (promedio de las encuestas y promedio usado en el ajuste fuerte superior de Pareto) entre los cinco años de referencia y entre las diferentes regiones80. En los cinco años de referencia, la media de las encuesta está en promedio entre el 75,1% y el 81,4% del máximo (media de las encuesta, consumo de cuentas nacionales). El valor mínimo es 22,2% (Suazilandia en 2008).
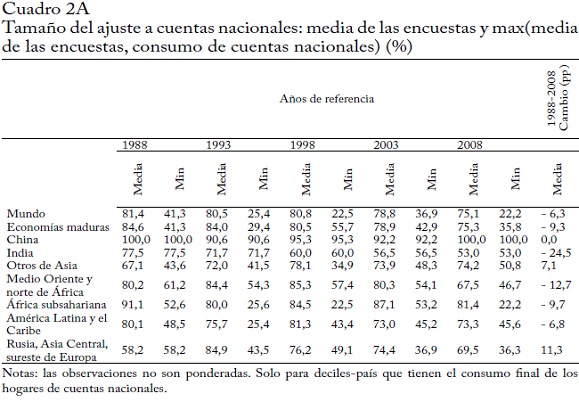
También comparamos las encuestas de nuestra base de datos con información de la WTID para el mismo año de las encuestas. Para los años-país que pudimos comparar, el coeficiente de Pareto de la WTID varía de 1,29 a 3,62 (en todos los años). Se piensa que la constante de Pareto del ingreso normalmente está entre 1,5 y 2,5 (Cowell, 2009). Como se explicó en la sección 4, tenemos dos imputaciones de Pareto: ajustes "proporcionales" y "fuertes superiores". El ajuste proporcional tiende a producir coeficientes de Pareto demasiados altos en comparación con los de la WTID, subestimando así la desigualdad (comparar el panel A del cuadro 3A con el panel C). Esto no es sorprendente dado que esperamos que las encuestas de hogares (de las que se toman las participaciones de los deciles en esta imputación) subreporten los ingresos superiores. Los coeficientes de Pareto obtenidos usando el ajuste "fuerte superior" parecen más cercanos a los valores de la WTID (comparar el panel B del cuadro 3A con el panel C). Pero los valores más bajos de este ajuste (justo por encima de 1) son increíblemente bajos, y quizás sobrestiman la desigualdad. Es decir, como ya se mencionó, el resultado de las grandes discrepancias de cuentas nacionales asignado totalmente al 10% superior. Además, solo cerca del 70% de las constantes de Pareto está en el rango observado en la WTID, frente al 90% en el ajuste proporcional.
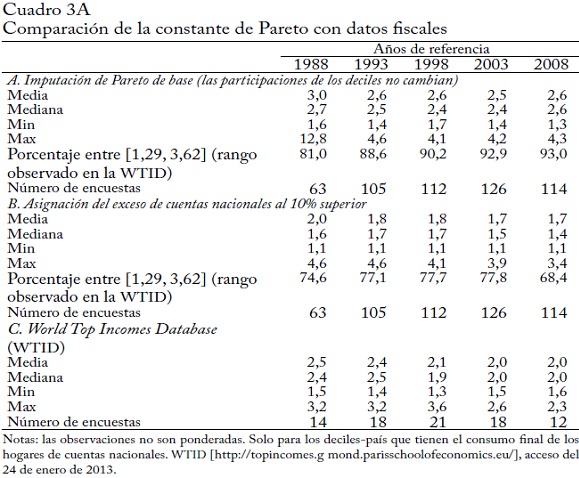
Estas comparaciones se deben tomar con cautela. Por supuesto, nos gustaría que las constantes de Pareto (y, por tanto, las participaciones del ingreso) después del ajuste sean similares a las estadísticas obtenidas de la WTID. Pero, por otra parte, se debe reconocer que las dos bases de datos se refieren a conceptos de ingreso diferentes (ingreso disponible vs. gravable) y a unidades diferentes (individuos vs. unidades gravables). Por tanto, la plena correspondencia entre las dos es muy improbable. El problema es que no tenemos un criterio para juzgar qué tan cercanas deberían ser idealmente las dos fuentes.
Para probar la sensibilidad del coeficiente global de Gini a estas constantes de Pareto increíblemente bajas, decidimos restringir los límites dentro de los cuales pueden estar estas constantes. Consideramos dos rangos: primero, el rango observado en la WTID, es decir, a = [1,29, 3,62]. Segundo, escogimos límites más estrechos (esencialmente arbitrarios) tales que a = [1,5, 3]. En ambos casos, las constantes de Pareto que están por debajo del límite inferior (por encima del superior) se cambian al límite inferior (superior). Usando estos valores revisados de a, calculamos hacia atrás el tamaño de la brecha de cuentas nacionales y en el paso final calculamos las participaciones revisadas y los ingresos promedio de los fractiles81. Puede parecer enredado ajustar las constantes de Pareto y después calcular la brecha de cuentas nacionales. La justificación para proceder así (y somos conscientes de que esta no es una razón muy sólida) es que tenemos una guía de cuál podría ser un rango razonable de las constantes de Pareto de la WTID.
Como muestra el cuadro 4A, el efecto de restringir las constantes de Pareto es que reduce el Gini global entre 0,2 y 0,8 puntos Gini en comparación con el ajuste "fuerte superior" del texto principal (comparar la filas 1 y 2 del cuadro 4A). Para límites de a más estrechos [1,5,3], las diferencias se encuentran entre 0,8 y 2,2 puntos Gini (compararlas filas 1 y 3). Por tanto, solo la fijación de límites más estrechos a las constantes de Pareto admisibles puede tener un impacto considerable sobre el Gini global. No obstante, en comparación con los resultados básicos usando el promedio de las encuestas, el índice global de Gini es aún mucho mayor.
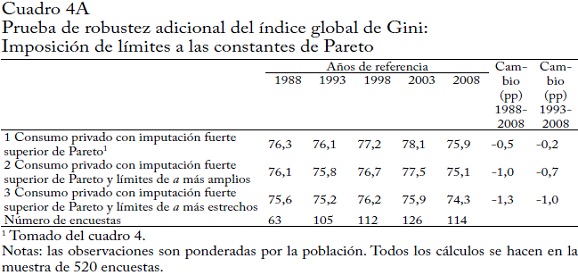
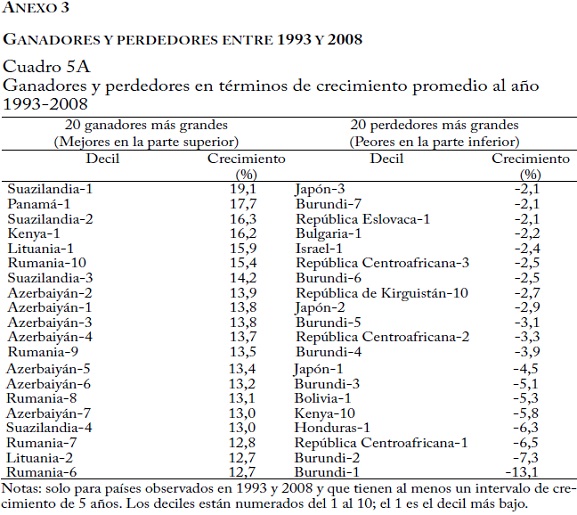
Pie de página
1 Cada decil se pondera por su población; por tanto, medimos la desigualdad interpersonal global del ingreso, donde a cada individuo se le asigna el ingreso de su decil de ingresos.
2 Los análisis de la desigualdad nacional del ingreso se suelen hacer en ingresos nominales, lo que supone un nivel de precios nacional común. Seguimos esos estudios nacionales ignorando las diferencias en el nivel de precios dentro de los países (excepto en los casos de China, India e Indonesia donde admitimos diferenciales de precios rural-urbanos).
3 Sin embargo, mejoramos los enfoques anteriores manteniendo constante el tipo de encuesta (ingreso o consumo) en el tiempo de cada país.
4 Pinkovskiy (2013) calcula límites no paramétricos del índice global de Atkinson permitiendo cualquier distribución del ingreso a nivel de países dadas las participaciones de los fractiles y un índice de Gini. Con una falta de respuesta del grupo superior suficientemente alta, la dirección del cambio del bienestar global entre 1970 y 2006 se vuelve ambigua. Él no presenta límites de las medidas de desigualdad global que permitan la falta de respuesta del grupo superior.
5 Podría parecer intuitivo que alargar la cola de la parte superior aumenta la desigualdad dentro de los países. Esto no es cierto en general y depende del patrón particular en el que ocurre el subregistro. Como muestra Deaton (2005), si la probabilidad de que el grupo superior responda disminuye siguiendo una distribución de Pareto y la distribución verdadera del ingreso es log-normal, la varianza "verdadera" no será diferente de la que se obtiene con una distribución truncada. El efecto en la desigualdad global depende del grado de subregistro de los ingresos más altos en los países, de dónde están los países y sus grupos de más altos ingresos en la distribución global del ingreso, de dónde empieza la falta de participación en la distribución nacional del ingreso (p. ej., en el 10% o en el 5% más altos), y de cuán populosos son los países y sus receptores de altos ingresos. Si el subregistro de los ingresos más altos es particularmente fuerte en países pobres, la desigualdad global podría caer realmente una vez permitimos el subregistro en la parte superior.
6 Queremos subrayar que el escalamiento de los ingresos de las encuestas a cuentas nacionales no es nuestra estrategia de estimación preferida. Simplemente replicamos el enfoque comúnmente adoptado en la literatura, que escala los ingresos de las encuestas al PIB de cuentas nacionales. El nuestro es el primer trabajo que escala al consumo de cuentas nacionales (y no al PIB), lo cual se debería preferir (Anand y Segal, 2008), como argumentamos más adelante.
7 Anand y Segal (2008) añaden un concepto cero: la desigualdad en el ingreso total (y no per cápita) entre países.
8 No todos comparten esta visión del mundo. Por ejemplo, Bhagwati califica de "locura" a la preocupación por la desigualdad interpersonal global, porque los habitantes del planeta "no pertenecen a una 'sociedad' en la que se comparen con los demás" (2004, 67). Usando un impuesto de renta mundial simulado, Kopczuket al. (2005) encuentran que los niveles actuales de ayuda externa son consistentes con preferencias que valoran mucho menos a los extranjeros (o con el supuesto de que la mayoría de las transferencias internacionales se pierden).
9 Además, nuestras metodologías son muy diferentes, pues él usa el PIB per cápita combinado con datos distributivos de PovcalNet y de la OCDE.
10 Alessandria y Kaboski (2011) explican la falla de la ley de un precio incluso para bienes transables mediante un modelo que supone que los consumidores de países pobres tienen una ventaja comparativa en la actividad de búsqueda.
11 El índice de Fisher es la media geométrica de los índices de Paasche y de Laspeyres. Por ello, sus pesos tienen en cuenta los países de referencia y de comparación. Cabe destacar que obedece a la propiedad de la reversión, es decir, que el nivel de precios del país 1 basado en el país 2 es la inversa del nivel de precios del país 2 basado en el país 1. En el caso especial de preferencias homotéticas idénticas entre dos países, el índice de Fisher es una aproximación de segundo orden a un índice de costo de vida "verdadero" (Deaton y Heston, 2010).
12 Supongamos que nos interesa estimar el nivel de precios de Ghana (con respecto al de Estados Unidos, el país base). Existe un índice de Fisher que va de Estados Unidos a Alemania y otro que va de Alemania a Ghana. El índice EKS es la media geométrica de todos estos índices indirectos de Fisher.
13 Por ejemplo, consideremos el alcohol en Bangladesh, donde tiene una baja participación y un precio relativamente alto (ver Deaton y Heston, 2010). El índice de Fisher logra un compromiso entre dos posiciones extremas: la participación en el presupuesto de Bangladesh subestimaría los precios de Bangladesh, mientras que las participaciones de la OCDE los sobrestimarían.
14 Este puede ser importante, por ejemplo, cuando se estudia la composición del PIB, debido a que los componentes convertidos a los factores de conversión GK son aditivos. Lo que no es el caso del índice EKS. Esta es una razón para que las Penn World Tables sigan usando el enfoque GK.
15 Reddy y Pogge (2010) argumentan que el consumo PPA no se debe usar para medir la pobreza global porque las canastas de consumo de los pobres son sistemáticamente diferentes de las del resto de la población. Por ejemplo, los pobres pueden enfrentar precios diferentes debido a dónde compran (Frankel y Gould, 2001) o cuánto compran (Rao, 2000). Sin embargo, Deaton y Dupriez(2009) encuentran que las canastas de bienes básicos ponderadas de nuevo para tener en cuenta las canastas de consumo de los pobres y los no pobres tienen muy poco efecto en las tasas de cambio PPA estimadas, lo que también es tranquilizador para nuestra estrategia de estimación.
16 En algunos países -en su mayoría africanos-, el consumo per cápita de cuentas nacionales es en realidad menor que el de las encuestas de hogares. Deaton (2005) argumenta que esto se podría explicar por la subestimación en cuentas nacionales, más que por problemas de las encuestas de hogares. Para una exposición anterior del problema, ver Milanovic (2002, pp. 65-66).
17 Se podría argumentar que el ingreso registrado en encuestas de hogares se debe aproximar con el PIB (y no con el consumo de cuentas nacionales). Pero Anand y Segal (2008) argumentan que, aun en este caso, es preferible el consumo de cuentas nacionales debido a los componentes no relacionados incluidos en el PIB antes mencionados.
18 Los problemas de medición en cuentas nacionales incluyen la medición de transacciones ilegales o de insumos intermedios. Además, debido a que el consumo se calcula como un residuo, los errores de medición se agravan (Anand y Segal, 2008).
19 En los datos de impuestos, la unidad de análisis es una unidad tributaria, que dependiendo de la jurisdicción puede ser una pareja casada o un individuo. Un hogar normalmente es más grande que una unidad tributaria. La literatura de datos de impuestos usa el ingreso gravable (usualmente antes de impuestos), mientras que la encuesta de hogares recoge el ingreso disponible. El ingreso gravable excluye algunos ingresos reales, como intereses exentos de impuestos sobre bonos del gobierno, y deducciones y exenciones, aunque muchos de los trabajos empíricos que usan datos de impuestos suman esos ingresos excluidos. Por otra parte, las encuestas de hogares suelen medir mal los ingresos y las ganancias del capital en comparación con los datos de impuestos, que cubren al menos los ingresos y las ganancias del capital gravables. Debido a que los datos de impuestos no suelen contener información suficiente para construir unidades e ingresos similares a los de una encuesta de hogares común, la única posibilidad es construir unidades tributarias e ingresos gravables en la encuesta de hogares, como en Alvaredo (2010). En el paso final de ese ejercicio se necesita suponer qué partes de la distribución verdadera son representadas por los datos de impuestos y qué partes son cubiertas por la encuesta de hogares. CBO (2012) ajusta los registros tributarios de Estados Unidos con registros de encuestas de hogares usando el ingreso. Esto añade el ingreso no gravable (p. ej., transferencias o ingresos en especie) de la encuesta. Armour et al. (2013) también ajustan los registros por el ingreso pero añaden los ingresos del capital a la encuesta de hogares porque estos ingresos tienden a ser mal medidos en este tipo de datos.
20 Esto también puede explicar por qué la discrepancia aumenta en países como China o India cuando se vuelven más ricos (Anand et al., 2010).
21 Incluir a los pobres puede ser insuficiente debido a la definición usada en las encuestas, que excluye las poblaciones sin hogar e institucionalizadas (ver Carr-H.,2013) o a problemas de muestreo (exclusión de regiones remotas y quizá más pobres). Así, la parte más baja de la distribución puede estar truncada. Además, el ingreso de los pobres incluidos en las encuestas puede estar mal medido debido a la producción doméstica o a beneficios recibidos en especie que no siempre se pueden incluir.
22 La imputación de Pareto no añade "nuevas" observaciones sino que "alarga" el decil superior. Esto implica que la imputación en sí misma no altera el promedio.
23 Según Deaton (2005), el consumo ESALSH representó el 3,9% del consumo total en el Reino Unido en 2001, frente al 2,1% en 1970. Además, argumenta que esta participación puede ser aún mayor en países pobres, aunque allí no existen datos.
24 Deaton (2001) argumenta que en India cerca de la mitad de la brecha entre el consumo de cuentas nacionales y el de las encuestas de hogares se debe a arriendos imputados.
25 PovcalNet es el instrumento en línea para medir la pobreza desarrollado por el Grupo de Investigación del Desarrollo del Banco Mundial, [http://iresearch.worldbank.org/PovcalNet]. Los datos se descargaron el 29 de julio de 2012, y corresponden a la última actualización de datos del 28 de febrero de 2012.
26 PovcalNet usa datos agrupados de encuestas de hogares para estimar estas participaciones de los deciles. Estas se estiman a partir de curvas de Lorenz ajustadas a la distribución del ingreso o consumo per cápita de los hogares ponderada por la población (considerando el tamaño de los hogares y la ponderación del muestreo). Se estimaron las curvas de Lorenz cuadrática generalizada y beta y se escogió la forma funcional con el mejor ajuste.
27 La inmensa mayoría de las observaciones año-país ya están en deciles o en cuantiles igualmente espaciados (p. ej., ventiles), y se pueden convertir fácilmente. En total se imputaron 13 años-país ajustando una curva de Lorenz log-normal usando el comando "ungroup" incluido en el Paquete DASP (Abdelkrim y Duclos,2007). Este procedimiento implementa el ajuste de Shorrocks y Wan (2008) y asegura así que la curva de Lorenz ajustada concuerda con los puntos originales. Escogemos una forma funcional log-normal y ajustamos la curva de Lorenz a las observaciones del año 2000, como sugieren Shorrocks y Wan (2008). Minoiu y Reddy (2012) demuestran que para estimar la distribución global del ingreso es mejor ajustar una curva de Lorenz paramétrica que estimar la densidad del núcleo.
28 Las fuentes para la base de datos final (años-país entre paréntesis) son: PovcalNet (379), WYD (173), LIS (8), SILC (2) y una encuesta de BHPS (Bardasi et al., 2012), de Statistics Finland y de Statistics Portugal.
29 Utilizando PovcalNet, Segal (2011) obtiene fractiles más detallados (limitados a representar a lo sumo 5 millones de personas) accediendo al código de estimación detallada de las curvas de Lorenz que PovcalNet ajusta a los datos agrupados. Esto es difícil y no nos fue factible dado el gran número de encuestas que consideramos, pero se puede abordar en futuros trabajos.
30 Por ejemplo, para el año de referencia 2008, el 7,4% de las encuestas se realizó en 2006. En el caso de PovcalNet, el año de encuesta no es a veces entero, lo que ocurre cuando una encuesta se hizo hace algo más de un año. En todos los casos tomamos el año de inicio de la encuesta, es decir, redondeamos por abajo los años no enteros.
31 La desigualdad tiende a ser menor en términos de consumo que en términos de ingreso (Deininger y Squire, 1996) y (al menos en Estados Unidos) ha aumentado al menos en términos de consumo (Fisher et al., 2013). En los datos completos de PovcalNet (no en la muestra que se usa aquí), el índice de Gini promedio de las encuestas de consumo (37,98%) es cerca de 10 puntos Gini menor que el de las encuestas de ingreso (48,44%). Una diferencia mayor que el ajuste propuesto por Li et al. (1998) de 6,6 puntos Gini.
32 Por ejemplo, los datos del ingreso se podrían escalar hacia abajo por los ahorros de cuentas nacionales (es decir, la brecha entre consumo nacional e ingreso nacional) (Deaton, 2001). No adoptamos ese enfoque debido a (1) los problemas de datos de cuentas nacionales discutido más atrás y (2) la evidencia de que la tasa de ahorro no es invariante al ingreso (Dynan et al., 2004). Cheny Ravallion incorporan ese ajuste en estimaciones anteriores de la pobreza global pero lo abandonan en un trabajo posterior (Chen y Ravallion, 2004).
33 La desigualdad del ingreso y del consumo se pueden mover en direcciones diferentes durante el mismo periodo (p. ej., Krueger y Perri, 2006).
34 Para Bulgaria, Botswana y Croacia el número de años de referencia con información de consumo y de ingreso fue igual. En todos los casos escogimos el tipo de encuesta que maximizara el número de encuestas tomadas de PovcalNet. Para Nicaragua, teníamos ambos tipos de encuestas en todos los años en PovcalNet. Escogimos las encuestas de ingreso porque este es el tipo prevaleciente en América Latina.
35 En China, India y Medio Oriente/norte de África, nuestra base de datos solo usa encuestas de consumo (excepto en toda China, donde se usan encuestas de ingreso). En África subsahariana el 98% de las encuestas son de consumo. En otros de Asia el 91% son encuestas de consumo. En las economías maduras y en América Latina el 97% y el 96%, respectivamente, son encuestas de ingreso.
36 En su estudio de los datos LIS, Atkinson et al. (1995) encuentran que la desigualdad del ingreso per cápita de los hogares es mayor que la desigualdad del ingreso de los hogares ajustado por una escala de equivalencia de raíz cuadrada. El efecto exacto en las comparaciones de la desigualdad entre países depende de la distribución conjunta del ingreso y el tamaño del hogar.
37 Para Suiza, en 2008, el decil más bajo tuvo un ingreso promedio nulo. Recodificamos esta omisión, porque de no hacerlo el 10% más bajo en Suiza sería la población más pobre del mundo. Por tanto, tenemos una observación perdida en 2008.
38 La conversión de monedas incluye cambios en la moneda que se está usando, como la formación de la zona del euro, y redenominaciones monetarias como las que se observan a menudo en entornos de alta inflación.
39 Como primer paso, usamos las cifras domésticas de los WDI. Donde no están disponibles, recurrimos directamente a las estadísticas del World Economic Outlook del FMI o de las oficinas de estadísticas de los países.
40 Los WDI no proporcionan PPA para Kosovo; así que usamos los factores de conversión PPA implícitos del PIB reportados en el World Economic Outlook del FMI.
41 Los datos de China e Indonesia, proporcionados por PovcalNet, ya incorporan ajustes por los costos diferenciales de residir en zonas rurales y urbanas. Para India, donde añadimos una encuesta de la WYD, usamos tasas de cambio PPA urbanas y rurales de 17,24 y 11,40 rupias respectivamente, las cuales se presentan en Ravallion (2008).
42 Estos países incluyen Argentina, Colombia, Ecuador, Honduras, Micronesia y Uruguay, y todos se toman de PovcalNet.
43 Es posible que esto subestime la desigualdad dentro del país en estos países, porque esperamos que las zonas rurales sean más pobres que las urbanas. Aunque la proporción de población rural en varios de ellos es mínima (Argentina, Uruguay).
44 Para ser precisos, las economías maduras incluyen los 27 países de la UE, Australia, Bermudas, Canadá, Hong Kong, Islandia, Israel, Japón, Corea, Nueva Zelanda, Noruega, Singapur, Suiza, Taiwán y Estados Unidos.
46 Definido como "el valor de mercado de todos los bienes y servicios [...]comprados por los hogares" [http://data.worldbank.org/indicator/NE.CON.PRVT.PP.KD]. Incluye bienes durables, arriendos imputados de propietarios-ocupantes, pagos para obtener permisos y licencias y gastos de las ESLSH.
47 Llenamos algunos vacíos de los WDI con datos de Estadísticas Financieras Internacionales (EFI) del FMI o de las oficinas estadísticas de los países. Complementamos la serie en dólares constantes PPA de 2005 con información de los WDI y las EFI en monedas corrientes y constantes locales así como en dólares corrientes. Convertimos los dólares corrientes usando tasas de cambio de mercado. En el resto de la conversión seguimos el mismo enfoque que con los micro datos usando el consumo PPA y el IPC.
48 Para el último año de referencia PovcalNet no tiene una encuesta de consumo, de modo que usamos una encuesta de ingreso de la WYD.
49 Atkinson (2007) usa las participaciones del 5% y el 10% superiores. Hlasny y Verme (2013) usan el 10% y el 1% superiores. La World Top Incomes Database (Alvaredo et al., 2013) usa el 0,1% y el 1% superiores en la mayoría de los casos.
50 Esto parece obedecer a la caída de Irán y Túnez en 2008, que representan el 26% del PIB y el 23% de la población de la región en 2008. La cobertura en esta región sigue siendo baja porque omitimos países grandes como Arabia Saudita o Emiratos Árabes Unidos que representan el 17% y el 10% de PIB regional respectivamente.
51 Por ejemplo, los índices de Gini a nivel de país reportados en PovcalNet (la muestra completa, no la muestra usada aquí) varían del 19,4% al 74,3%, con un promedio del 42,2%. Solo Jamaica (70,81%) y Namibia (74,33%) tienen índices de Gini mayores del 70%. Este conjunto de datos excluye los países ricos, que tienden a tener menor desigualdad; así, el Gini promedio puede estar sesgado hacia arriba.
52 El cuadro 1A del anexo se basa en Milanovic (2002, 2005, 2012), Bourguignon (2012) y Anand y Segal (2008). Anand y Segal se refieren erróneamente a Milanovic (2005) como GE(0), cuando de hecho es GE(1). Para Milanovic (2002,2005) usamos la muestra completa, porque es la más cercana a nuestro enfoque. La descomposición solo está disponible para la muestra de países que es común en todos los años.
53 El nivel de aversión a la desigualdad se puede interpretar como sigue (Atkinson, 1975). Consideremos dos personas que son idénticas, excepto que una tiene dos veces el ingreso de la otra. Consideremos una transferencia que quita 1 dólar a la persona rica y da una proporción x a la más pobre. Una aversión a la desigualdad de 2 significa que aceptaríamos una transferencia en la que apenas 25 centavos llegan a la persona más pobre para cada dólar quitado a la rica. Para e = 1 aceptaríamos 50 centavos y para e = 0,5 requeriríamos 71 centavos.
54 El índice de Atkinson es descomponible por subgrupos de población, mientras que el índice de Gini no lo es. Pero el índice de Atkinson no es descomponible aditivamente, en el sentido de que se pueda dividir en un promedio ponderado de las desigualdades dentro y entre grupos (Bourguignon, 1979).
55 En la descomposición GE(0) se usan proporciones de población y en la descomposición GE(1) participaciones del ingreso. La redistribución del ingreso entre países para igualar los ingresos promedio modificaría las participaciones del ingreso (pero no las de la población). En ese sentido, solo es consistente la interpretación de GE(0) porque la plena eliminación de una fuente de desigualdad (desigualdad entre o dentro) no afecta el nivel de la otra.
56 En un borrador anterior también descompusimos la desigualdad por regiones. La contribución entre regiones disminuyó más rápidamente que la contribución entre países. Esto sugiere que las regiones se han vuelto aún más similares entresí que los países.
57 La CIC original, como la definen Ravallion y Chen (2003), muestra la tasa de crecimiento de los ingresos para el mismo percentil (p. ej., el percentil 10de la distribución global) entre los periodos inicial y final. En cambio, nosotros comparamos el ingreso medio del mismo fractil (p. ej., del 10% inferior) en el tiempo. La justificación es importante cuando hay un cambio distributivo dentro de un fractil dado. Para ser más precisos: la CIC original evaluada en los 100 percentiles no muestra el crecimiento de los ingresos si todas o la mayoría de las ganancias de ingreso se concentran en el 1% superior. Como el grupo de ingreso más alto considerado es el percentil 99, la CIC de Ravallion-Chen mostrará un crecimiento nulo o casi nulo. No registraría la mayor parte del crecimiento.
58 Las CIC por región se evaluaron en grupos de deciles (promedio a promedio) y el decil superior se dividió en dos ventiles porque en China e India, que son regiones en sí mismas, tenemos a lo sumo 20 observaciones.
59 Por supuesto, estos no son necesariamente los mismos deciles-país (ni la misma población) que estaban en el 5% superior en 1988. Volvemos a este asunto en la quinta sección, donde discutimos las curvas de incidencia de crecimiento (cuasi) no anónimas.
60 Usamos un núcleo de Epanechnikov y el ancho de banda por defecto, seleccionados óptimamente por Stata.
61 Los números totales corresponden a la población mundial total y no solo a la población cubierta aquí por las encuestas.
62 Estas gráficas fueron creadas como densidades del núcleo superpuestas (acumulativas). Como la última densidad se muestra en la parte superior, procedemos en orden inverso: la primera densidad graficada es la densidad global incluyendo todas las regiones (igual que en la gráfica 2). Después graficamos la densidad de todas las regiones, excepto China. Procedemos eliminando una región a la vez. El área bajo la densidad global es 1. Las demás densidades incompletas se escalaron hacia abajo de acuerdo con la proporción de la población regional en un año particular. Por ejemplo, en 2008 la segunda densidad que graficamos se escaló hacia abajo a 0,7828 = 1 -x, donde x es la proporción de la población de China en 2008. Usamos un núcleo de Epanechnikov y el ancho de banda por defecto, seleccionados óptimamente por Stata. Se permite que el ancho debanda varíe en años diferentes, pero para cada año de referencia es igual entre las diferentes densidades acumulativas del núcleo.
63 Los ventiles corresponden a cantidades absolutas de dinero diferentes en 1988 y 2008.
64 La primera observación que tenemos para Rusia es la del año de referencia1993.
65 Esto significa que usamos el máximo consumo privado per cápita y el promedio de la encuesta. En otras palabras, cuando el promedio de la encuesta es mayor que el consumo privado mantenemos el promedio de la encuesta. Atkinson (2007) remplaza el promedio de la encuesta por agregados de cuentas nacionales en todos los casos. Adoptamos un enfoque diferente porque nos centramos en la subestimación de los ingresos más altos en las encuestas de hogares. Es decir, suponemos que las encuestas no pueden sobrestimar, sino solo subestimar el ingreso total de los hogares.
66 Nuestro enfoque difiere del de Atkinson en tres aspectos: primero, usamos el consumo privado, y Atkinson usa el PIB. Segundo, mantenemos el promedio de las encuestas cuando es mayor que el promedio de cuentas nacionales, y Atkinson no lo hace. Tercero, Atkinson supone la distribución de Pareto solo para el 5% superior.
67 El componente de traslapo no cambia si los promedios-país están muy alejados y la imputación de Pareto solo tiene un efecto pequeño. Por ejemplo, si solo tuviéramos a Suiza y Congo en la muestra, la elongación de Pareto de la parte superior de la distribución congoleña podría no llevar ningún fractil congoleño al rango de la distribución suiza (es decir, todos los fractiles suizos aún tendrían ingresos más altos).
68 Un valor más pequeño del coeficiente de Pareto implica una desigualdad mayor.
69 Por supuesto, esto ignora algunas diferencias de definición y otras razones por las que el promedio de cuentas nacionales y el de encuestas de hogares podrían diferir.
70 Pero para otras aplicaciones, como el número de personas de todo el mundo que están por encima de cierto nivel de ingresos, la imputación de Pareto podría hacer una diferencia sustancial (ver Atkinson, 2007).
71 Estas son brechas no ponderadas. En India, la brecha aumentó en casi 25puntos porcentuales (del consumo privado nacional). Pero la situación no es mucho mejor en otros lugares: las economías maduras, Medio Oriente y África subsahariana muestran brechas crecientes de cerca de 10 puntos porcentuales (ver el cuadro 2A del anexo).
72 Un tipo especial de CIC no anónima mostraría la tasa media de crecimiento medio ponderada adecuadamente de todos los individuos que pertenecían aun percentil dado en el año inicial (por supuesto, haciendo esto para los 100 percentiles). Tal CIC no anónima especial puede ser una comparación del ingreso medio ponderado de las mismas personas (pertenecientes a un percentil dado) en los años final e inicial.
73 Los rangos fraccionarios se derivan de un estimador de la distribución acumulativa suave que asegura que el rango promedio es 0,5, estimado con la rutina fracrank de Stata de Philippe van Kerm.
74 Hay dos razones para que las observaciones del diagrama de dispersión no estén igualmente distribuidas a lo largo del eje x, y parezcan estar concentradas en los rangos superiores. Primera, los rangos se calculan en la distribución de corte transversal, mientras que el diagrama de dispersión solo incluye los deciles-país observados en 1988 y 2008, muchos de los cuales son de países ricos. Segunda, los deciles-país se ponderan por el tamaño de la población al calcular los rangos, mientras que esta información no se muestra en los puntos de dispersión.
75 Los deciles-país están numerados del 1 al 10; el 1 es el decil más bajo.
76 Esto excluye algunos países que no tienen intervalos de 5 años. Chipre (para1988-2008) y Nigeria (para 1993-2008) se observaron en los años inicial y final, pero no tienen intervalos de crecimiento de 5 años en el intermedio.
77 En cambio, la gráfica 6 muestra el crecimiento (anualizado) de los deciles de ingreso entre 1988 y 2008 en el eje y, lo que nada dice de la permanencia de ese crecimiento. Por ejemplo, un decil puede mostrar una tasa de crecimiento muy alta entre 1988 y 2008 porque tuvo un ingreso excepcionalmente grande en 2008 (o porque no le fue bien en 1988). Por cierto, las dos ordenaciones son muy similares.
78 La ordenación por tasas de crecimiento de 20 años modifica ligeramente los resultados porque los deciles más bajos de Honduras y Paraguay están entre los veinte deciles menos exitosos. Esto también sucede para los deciles menos exitosos en términos de tasas de crecimiento de 15 años (cuadro 4A del anexo), según las cuales Kenia y Tanzania tuvieron muy mal desempeño.
79 El decil más bajo de Japón disminuyó en un 4,5% al año en promedio, una reducción que parece ser muy sustancial. En el mismo periodo, el ingreso promedio de Japón (en nuestros datos) se redujo en un 1,35% al año, mientras que el PIB per cápita (en dólares PPA de 2005) aumentó en un 0,88% al año. Solo pudimos obtener micro datos de LIS para Japón en el último año de referencia. Antes, los datos se basaban en tabulaciones, lo que quizá explique el fuerte descenso del decil más bajo entre 1988 y 2008.
80 En otras palabras, el cuadro 2A de este anexo muestra la relación promedio de las encuestas para max (promedio de las encuestas, consumo privado de cuentas nacionales), que por definición es menor o igual a 1.
81 El ajuste de cuentas nacionales (e) está dado por:
donde
son los ingresos promedio de los deciles 9 y 10 observados en la encuesta de hogares.
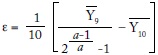
REFERENCIAS BIBLIOGRÁFICAS
1. Abdelkrim, A. y J.-Y. Duclos. "DASP: Distributive analysis Stata Package", Quebec, PEP, World Bank, UNDP y Universidad de Laval, 2007. [ Links ]
2. Ackland, R.; S. Dowrick y B. Freyens. "Measuring global poverty: Why PPP methods matter", Review of Economics and Statistics 95, 3, 2013, pp. 813-824. [ Links ]
3. Alessandria, G. y J. P. Kaboski. "Pricing-to-market and the failure of absolute PPP", American Economic Journal: Macroeconomics 3, 1, 2011, pp. 91-127. [ Links ]
4. Alvaredo, F. 2010, "The rich in Argentina over the Twentieth Century, 1932-2004", A. B. Atkinson y T. Piketty, eds., Top incomes: A global perspective, Oxford, N. Y., University Press, pp. 253-298. [ Links ]
5. Alvaredo, F.; A. B. Atkinson, T. Piketty y E. Saez. "The World Top Incomes Database", 2013, [http://topincomes.g-mond.parisschoolofeconomics.eu/], acceso del 24/01/2013. [ Links ]
6. Anand, S., P. Segal y J. E. Stiglitz. "Introduction", S. Anand, P. Segaly J. E. Stiglitz, eds., Debates on the measurement of global poverty, N. Y., Oxford University Press, 2010. [ Links ]
7. Anand, S. y P. Segal. "What do we know about global income inequality?", Journal of Economic Literature 46, 1, 2008, pp. 57-94. [ Links ]
8. Armour, P.; R. V. Burkhauser y J. Larrimore. "Deconstructing income and income inequality measures. A crosswalk from market income to comprehensive income", American Economic Review, Papers and Proceedings 103, 3, 2013, pp. 173-177. [ Links ]
9. Atkinson, A. B. "On the measurement of inequality", Journal of Economic Theory 2, 3, 1970, 244-263. [ Links ]
10. Atkinson, A. B. The economics of inequality, Londres, Clarendon Press, 1975. [ Links ]
11. Atkinson, A. B. "Measuring top incomes. Methodological issues", A.B. Atkinson y T. Piketty, eds., Top incomes over the Twentieth Century. A contrast between Continental European and English-speaking countries, Oxford, N. Y., Oxford University Press, 2007. [ Links ]
12. Atkinson, A. B. y A. Brandolini. "On analyzing the world distribution of income", The World Bank Economic Review 24, 1, 2010, pp. 1-37. [ Links ]
13. Atkinson, A. B. y T. Piketty. Top incomes over the Twentieth Century. A contrast between continental European and English-speaking countries, Oxford, N. Y., Oxford University Press, 2007. [ Links ]
14. Atkinson, A. B. y T. Piketty. Top incomes. A global perspective, Oxford, N. Y., Oxford University Press, 2010. [ Links ]
15. Atkinson, A. B.; L. Rainwater y T. M. Smeeding. Income distribution in OECD countries: Evidence from the Luxembourg Income Study, París, OECD Social Policy Studies, 1995. [ Links ]
16. Banerjee, A. y T. Piketty. "Top Indian incomes, 1922-2000", A. B. Atkinson y T. Piketty, eds., Top incomes. A global perspective, Oxford, N. Y., Oxford University Press, 2010. [ Links ]
17. Bardasi, E.; S. Jenkins, H. Sutherland, H. Levy y F. Zantomio. "British household panel survey derived current and annual net house hold income variables", Waves 1-18, 1991-2009, 2012. [ Links ]
18. Barro, R.J. y X. Salai Martin. "Convergence", Journal of Political Economy 100, 2, 1992, pp. 223-251. [ Links ]
19. Bhagwati, J. In defense of globalization, Nueva York, Oxford University Press, 2004. [ Links ]
20. Bourguignon, F. 1979, "Decomposable income inequality measures", Econometrica 47, 4, pp. 901-920. [ Links ]
21. Bourguignon, F. "Non-anonymous growth incidence curves, incomemobility and social welfare dominance", Journal of Economic Inequality 9, 4, 2011a, pp. 605-627. [ Links ]
22. Bourguignon, F. "A turning point in global inequality... and beyond", presentación en la Conferencia ABCDE, Washington, 2011b. [ Links ]
23. Bourguignon, F. La mondialisation de l'inégalité, París, Seuil y La République des Idées, 2012. [ Links ]
24. Bourguignon, F. y C. Morrisson. "Inequality among world citizens.1820-1992", The American Economic Review 92, 4, 2002, pp. 727-744. [ Links ]
25. Burkhauser, R. V.; S. Feng et al. "Recent trends in top income shares in the United States. Reconciling estimates from March CPS and IRS tax return data", Review of Economics and Statistics 94, 2, 2012, pp. 371-388. [ Links ]
26. Carr-H., R. "Missing millions and measuring development progress", World Development 46, 0, 2013, pp. 30-44. [ Links ]
27. CBO. "The distribution of household income and federal taxes, 2008 and 2009", Washington, Congressional Budget Office Report 4441, 2012. [ Links ]
28. Chen, S. y M. Ravallion. "How have the world's poorest fared since the early 1980s?", The World Bank Research Observer 19, 2, 2004, pp. 141-169. [ Links ]
29. Chen, S. y M. Ravallion. "China is poorer than we thought, but no less successful in the fight against poverty", S. Anand, P. Segal y J. Stiglitz, eds., Debates on the measurement of global poverty, Oxford, N. Y., Oxford University Press, 2010a. [ Links ]
30. Chen, S. y M. Ravallion. "The developing world is poorer than we thought, but no less successful in the fight against poverty", Quarterly Journal of Economics 125, 4, 2010b, pp. 1577-1625. [ Links ]
31. Cowell, F.A. Measuring inequality, Oxford, N. Y., Oxford University Press, 2009. [ Links ]
32. Cowell, F.A. y E. Flachaire. "Income distribution and inequality measurement. The problem of extreme values", Journal of Econometrics 141, 2, 2007, pp. 1044-1072. [ Links ]
33. Deaton, A. "Counting the world's poor. Problems and possible solutions", The World Bank Research Observer 16, 2, 2001, pp. 125-147. [ Links ]
34. Deaton, A. "Measuring poverty in a growing world (or measuring growth in a poor world)", Review of Economics and Statistics 87, 1, 2005, pp. 1-19. [ Links ]
35. Deaton, A. y O. Dupriez. "Purchasing power parity exchange ratesfor the global poor", American Economic Journal. Applied Economics 3, 2, 2011, pp. 137-166. [ Links ]
36. Deaton, A. y A. Heston. "Understanding PPPs and PPP-based National Accounts", American Economic Journal. Macroeconomics 2, 4, 2010, pp. 1-35. [ Links ]
37. Deininger, K. y L. Squire. "A new data set measuring income inequality", World Bank Economic Review 10, 3, 1996, pp. 565-591. [ Links ]
38. Dynan, K.E.; J. Skinner y S.P. Zeldes. "Do the rich save more?", Journal of Political Economy 112, 2, 2004, pp. 397-444. [ Links ]
39. Eltetö, D. y P. Koves. "On a problem of index number computation relating to international comparison", Statisztikai Szemle 42, 1964, pp. 507-518. [ Links ]
40. Fisher, J.D.; D.S. Johnson y T.M. Smeeding. "Measuring the trends in inequality of individuals and families. Income and consumption", American Economic Review. Papers and Proceedings 103, 3, 2013, pp. 184-188. [ Links ]
41. Frankel, D.M. y E.D. Gould. "The retail price of inequality", Journal of Urban Economics 49, 2, 2001, pp. 219-239. [ Links ]
42. Gerschenkron, A. "The Soviet indices of industrial production", Review of Economics and Statistics 29, 4, 1947, pp. 217-226. [ Links ]
43. Goldberg, P.K. y N. Pavcnik. "Distributional effects of globalization in developing countries", Journal of Economic Literature 45, 1, 2007, pp. 39-82. [ Links ]
44. Grimm, M. "Removing the anonymity axiom in assessing pro-poor growth", Journal of Economic Inequality 5, 2, 2007, pp. 179-197. [ Links ]
45. Groves, R.M. y M. Couper. Nonresponse in household interview surveys, Nueva York, Wiley, 1998. [ Links ]
46. Haskel, J.; R.Z. Lawrence, E.E. Leamer y M.J. Slaughter. "Globalization and U.S. wages. Modifying classic theory to explain recent facts", Journal of Economic Perspectives 26, 2, 2012, pp. 119-140. [ Links ]
47. Hlasny, V. y P. Verme. "Top incomes and the measurement of inequality in Egypt", World Bank Policy Research working paper 6557, 2013. [ Links ]
48. Khamis, S.H. "A new system of index numbers for national and international purposes", Journal of the Royal Statistical Society, Series A (General) 135, 1, 1972, pp. 96-121. [ Links ]
49. Kopczuk, W.; J. Slemrod y S. Yitzhaki. "The limitations of decentralized world redistribution. An optimal taxation approach", European Economic Review 49, 4, 2005, pp. 1051-1079. [ Links ]
50. Korinek, A.; J.A. Mistiaen y M. Ravallion. "Survey non response and the distribution of income", Journal of Economic Inequality 4, 1, 2006, pp. 33-55. [ Links ]
51. Krueger, D. y F. Perri. "Does income inequality lead to consumption inequality? Evidence and theory", Review of Economic Studies 73, 1, 2006, pp. 163-193. [ Links ]
52. Leigh, A. y P. van der Eng. "Inequality in Indonesia. What can we learn from top incomes?", Journal of Public Economics 93, 2009, pp. 209-212. [ Links ]
53. Li, H.; L. Squire y H.-f. Zou. "Explaining international and intertemporal variations in income inequality", Economic Journal 108, 446, 1998, pp. 26-43. [ Links ]
54. Milanovic, B. "True world income distribution, 1988 and 1993. First calculation based on household surveys alone", Economic Journal 112,476, 2002, pp. 51-92. [ Links ]
55. Milanovic, B. Worlds apart. Measuring international and global inequality, Princeton, N. J., Princeton University Press, 2005. [ Links ]
56. Milanovic, B. "Global inequality recalculated and updated: The effect of new PPP estimates on global inequality and 2005 estimates", Journal of Economic Inequality 10, 2012, pp. 1-18. [ Links ]
57. Minoiu, C. y S. Reddy. "Kernel density estimation on grouped data: The case of poverty assessment", Journal of Economic Inequality, 2012, pp. 1-27. [ Links ]
58. Mistiaen, J.A. y M. Ravallion. "Survey compliance and the distribution of income", World Bank Policy Research working paper, 2003. [ Links ]
59. Morival, E. "Top incomes and racial inequality in South Africa. Evidence from tax statistics and household surveys 1993-2008", tesis de maestría, Paris School of Economics, 2011. [ Links ]
60. Nuxoll, D.A. "Differences in relative prices and international differences in growth rates", American Economic Review 84, 5, 1994, pp. 1423-1436. [ Links ]
61. Pinkovskiy, M.L. "World welfare is rising. Estimation using nonparametric bounds on welfare measures", Journal of Public Economics 97, 0, 2013, pp. 176-195. [ Links ]
62. Pogge, T.W. World poverty and human rights. Cosmopolitan responsibilities and reforms, Cambridge, Polity Press, 2002. [ Links ]
63. Rao, V. "Price heterogeneity and 'real' inequality. A case study of prices and poverty in rural South India", Review of Income and Wealth 46, 2, 2000, pp. 201-211. [ Links ]
64. Ravallion, M. "A global perspective on poverty in India", Economic and Political Weekly 43, 43, 2008, pp. 31, 33-37. [ Links ]
65. Ravallion, M. "Understanding PPPs and PPP-based National Accounts. Comment", American Economic Journal. Macroeconomics 2, 4, 2010, pp. 46-52. [ Links ]
66. Ravallion, M. y S. Chen. "Measuring pro-poor growth", Economics Letters 78, 1, 2003, pp. 93-99. [ Links ]
67. Reddy, S.G. y T. Pogge. "How not to count the poor", S. Anand, P. Segal y J. E. Stiglitz, eds., Debates on the measurement of global poverty, Oxford, N. Y., Oxford University Press, 2010. [ Links ]
68. Sala-i-Martin, X. "The world distribution of income. Falling poverty and... convergence, period", Quarterly Journal of Economics 121, 2, 2006, pp. 351-397. [ Links ]
69. Segal, P. 2011, "Resource rents, redistribution, and halving global poverty. The resource dividend", World Development 39, pp. 475-489. [ Links ]
70. Shorrocks, A. y G. Wan. "Ungrouping income distributions", working paper UNUWIDER, 2008. [ Links ]
71. Singer, P. One world. The ethics of globalization, New Haven, Yale University Press, 2002. [ Links ]
72. Szekely, M. y M. Hilgert. "What's behind the inequality we measure: An investigation using Latin American data", Research Department working paper Inter-American Development Bank, 1999. [ Links ]
73. Szulc, B. "Indices for multiregional comparisons", Przeglad Statystyczny 3, 1964, pp. 239-254. [ Links ]
74. Van Kerm, P. "Income mobility profiles", Economics Letters 102, 2, 2009, pp. 93-95. [ Links ]
