











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkLos hallazgos de investigación publicados a veces son refutados por evidencia posterior, con la confusión y la decepción consiguientes. La refutación y la controversia se ven en la gama de diseños de investigación, desde los ensayos clínicos y los estudios epidemiológicos tradicionales (Ioannidis, Haidich y Lau, 2001; Lawlor, Smith et al., 2004; Vandenbroucke, 2004) hasta la investigación molecular más moderna (Michiels, Koscielny y Hill, 2005; Ioannidis, Ntzani, Trikali-nos et al., 2001). Es cada vez más preocupante que en la investigación moderna la mayoría de los reclamos de investigación publicados sean hallazgos falsos (Colhoun, McKeigue y Smith, 2003; Ioannidis, 2003 y 2005). Pero esto no debería ser sorprendente. Se puede probar que la mayoría de los hallazgos investigación reclamados son falsos. Aquí examino los factores clave que influyen en este problema y algunos corolarios relacionados.
MODELACION DEL MARCO DE RESULTADOS FALSOS POSITIVOS
Algunos metodólogos han señalado (Sterne y Smith, 2001; Wacholder, Chanock, Garcia-C. et al., 2004; Risch, 2000) que la alta tasa de no replicación (falta de confirmación) de los descubrimientos es consecuencia de la estrategia conveniente pero infundada de pretender resultados concluyentes solamente con base en un estudio único valorado por la significancia estadística formal, comúnmente para un valor p menor de 0,05. La investigación no es representada y sintetizada apropiadamente por los valores p, pero, infortunadamente, es generalizada la noción de que los artículos de investigación médica se deben interpretar únicamente con base en los valores p. Los resultados de investigación se definen aquí como una relación que alcance significación formal, por ejemplo, intervenciones efectivas, predictores informativos, factores de riesgo o asociaciones. La investigación "negativa" también es muy útil. "Negativa" es en realidad un nombre inapropiado, y la mala interpretación está muy extendida. Sin embargo, aquí me centraré en las relaciones que los investigadores pretenden que existen y no en los hallazgos nulos.
Como se ha demostrado, la probabilidad de que un resultado de investigación sea verdadero depende de la probabilidad previa de que sea verdadero (antes de hacer el estudio), del poder estadístico del estudio y del nivel de significancia estadística (Wacholder, Chanock, Garcia-C. et al., 2004; Risch, 2000). Consideremos una tabla 2 x 2 en la que los resultados de investigación se comparan con el patrón oro de las relaciones verdaderas en un campo científico. En un campo de investigación se pueden formular hipótesis verdaderas y falsas sobre la presencia de relaciones. Sea R la proporción entre el número de "relaciones verdaderas" y "no relaciones" de aquellas que se prueban en ese campo. R es característica del campo y puede variar mucho dependiendo de que el campo se centre en relaciones probables o busque solo una o algunas relaciones verdaderas entre miles y millones de hipótesis que se pueden formular. Consideremos también, por simplicidad de cálculo, campos circunscritos en los que solo existe una relación verdadera (entre las muchas hipótesis que se pueden formular) o hay un poder similar para encontrar alguna de las varias relaciones verdaderas existentes. La probabilidad previa al estudio de que una relación sea verdadera es R/(R + 1). La probabilidad de que un estudio encuentre que una relación verdadera refleja el poder 1-ß (uno menos la tasa de error Tipo II). La probabilidad de pretender una relación cuando realmente no existe ninguna refleja la tasa de error Tipo I, a. Suponiendo que en el campo se están probando c relaciones, los valores esperados de la tabla 2 x 2 se presentan en el cuadro 1. Después de que se pretende un resultado de investigación basado en el logro de significancia estadística formal, la probabilidad posterior al estudio de que sea verdadero es el valor predictivo positivo (VPP).
El VPP es también la probabilidad complementaria de lo que Wacholder et al. llaman probabilidad de informe falso positivo (Wacholder, Chanock, Garcia-C. et al., 2004). De acuerdo con la tabla 2 x 2, se obtiene VPP = (1 - ß)R/(R - ßR + α). Así, es más probable que un resultado de investigación sea más verdadero que falso si (1 - ß)R > α. Puesto que la gran mayoría de los investigadores suele depender de α = 0,05, esto significa que es más probable que un resultado de investigación sea más verdadero que falso si (1 - ß)R > 0,05.

Lo que es menos reconocido es que los sesgos y el grado de comprobación repetida independiente, por distintos equipos de investigadores del planeta, pueden distorsionar aún más esta imagen y pueden llevar a probabilidades aún más pequeñas que los resultados de investigación sean verdaderos. Intentaremos modelar estos dos factores en el contexto de tablas 2 x 2 similares.
SESGOS
Primero, definamos el sesgo como la combinación de diversos factores de diseño, datos, análisis y presentación que tienden a producir resultados de investigación que no se deberían producir. Sea u la proporción de análisis probados que no habrían sido "resultados de investigación", pero que terminan presentados y reportados como tales debido a sesgos. El sesgo no se debe confundir con la variabilidad al azar que ocasiona que algunos hallazgos sean falsos por casualidad aunque el diseño del estudio, los datos, el análisis y la presentación sean perfectos. El sesgo puede implicar manipulación en el análisis o en el reporte de hallazgos. El reporte selectivo o distorsionado es una forma típica de ese sesgo. Podemos suponer que u no depende de que exista o no una relación verdadera. Este no es un supuesto irrazonable, puesto que por lo común es imposible saber qué relaciones son verdaderas. En presencia de sesgo (cuadro 2), se tiene VPP = ([1 - β]R + uβR)/(R +α - βR) + u - uα + uβR), y VPP disminuye cuando aumenta u, salvo que 1 - ß < α, es decir, 1 - ß < 0,05 para la mayoría de las situaciones. Así, cuando aumenta el sesgo, las posibilidades de que un resultado de investigación sea verdadero disminuyen considerablemente. Esto se muestra en la gráfica 1 para diferentes niveles de poder y diferentes probabilidades pre-estudio.
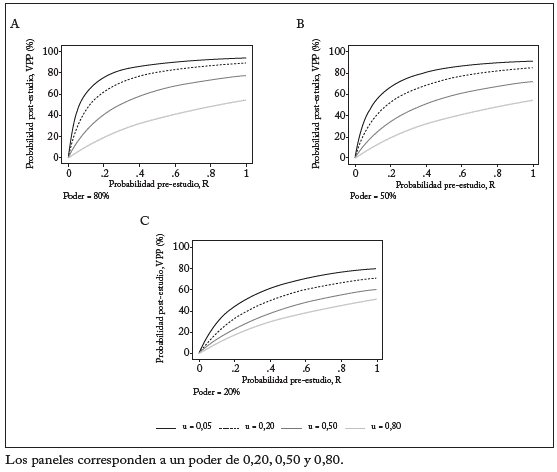
Gráfica 1 VPP (probabilidad de que un hallazgo de investigación sea verdadero) Como función de las probabilidades pre-estudio de diferentes niveles de sesgo, u
Cuadro 2 Hallazgos de investigacion y relaciones verdaderas en presencia de sesgo
DOI: 10.1371/journal.pmed.0020124.t002.
A la inversa, los hallazgos verdaderos de la investigación pueden ser anulados ocasionalmente debido al sesgo inverso. Por ejemplo, con grandes errores de medición las relaciones se pierden en el ruido (Kelsey, Whittemore et al., 1996), o los investigadores usan datos de modo ineficiente o no advierten relaciones estadísticamente significativas, o puede haber conflictos de interés que tienden a "enterrar" hallazgos significativos (Topol, 2004). No hay buena evidencia empírica a gran escala de la frecuencia con la que puede ocurrir ese sesgo inverso en los distintos campos de investigación. Pero quizá sea justo decir que el sesgo inverso no es tan común. Además, es probable que los errores de medición y de uso ineficiente de datos se estén convirtiendo en problemas menos frecuentes, porque el error de medición ha disminuido con los avances tecnológicos en la era molecular y los investigadores son cada vez más sofisticados acerca de sus datos. No obstante, el sesgo inverso se puede modelar de la misma manera que el sesgo anterior. Además, el sesgo inverso no se debe confundir con la variabilidad aleatoria que puede llevar a ignorar una relación verdadera por azar.
COMPROBACIÓN POR VARIOS EQUIPOS INDEPENDIENTES
Varios equipos independientes pueden abordar el mismo conjunto de preguntas de investigación. Cuando los esfuerzos de investigación se globalizan, la regla práctica es que varios equipos de investigación, a menudo decenas de ellos, puedan indagar las mismas preguntas o preguntas similares. Infortunadamente, en algunas áreas, la mentalidad predominante ha sido centrarse en descubrimientos aislados de equipos individuales e interpretar los experimentos aisladamente. En un número creciente de preguntas hay al menos un estudio que reivindica un hallazgo, y este recibe atención unilateral. La probabilidad de que al menos un estudio, entre varios sobre la misma pregunta, reivindique un hallazgo estadísticamente significativo es fácil de estimar. Para n estudios independientes de igual poder, la tabla 2 x 2 se muestra en el cuadro 3: VPP=R(1 - β n )/(R + 1 - [1 - α] n - Rβ n ) (sin considerar el sesgo). Con un creciente número de estudios independientes, VPP tiende a disminuir, salvo que 1 - ß < α, es decir, comúnmente 1 - ß < 0,05. Esto se muestra para diferentes niveles de poder y diferentes probabilidades pre-estudio en la gráfica 2. Para n estudios de poder diferente, el término ßn se remplaza por el producto de los términos ßi para i = 1, pero las inferencias son similares.
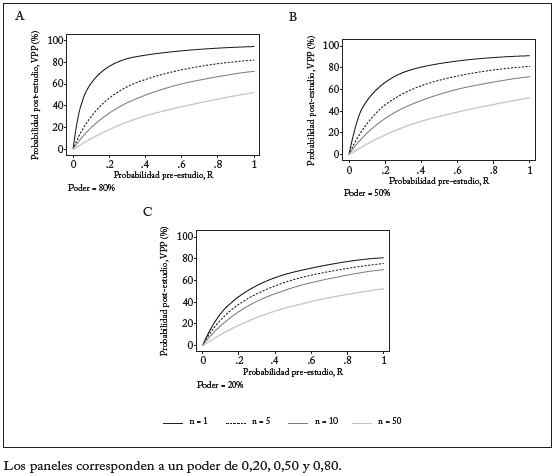
Gráfica 2 VPP (probabilidad de que un hallazgo de investigación sea verdadero) Como función de las probabilidades pre-estudio de diferentes estudios realizados, n

COROLARIOS
En el recuadro 1 se muestra un caso concreto. Con base en las consideraciones anteriores se pueden deducir varios corolarios interesantes sobre la probabilidad de que un hallazgo de investigación sea verdadero.

Corolario 1: Cuanto más pequeños son los estudios realizados en un campo científico, menor es la probabilidad de que los resultados de investigación sean verdaderos. Un tamaño de muestra pequeño significa menor poder y, para todas las funciones anteriores, el VPP de un hallazgo de investigación verdadero disminuye cuando el poder disminuye hacia 1 - ß=0,05. Por tanto, si los demás factores son iguales, es más probable que los resultados de investigación sean verdaderos en campos científicos que realizan grandes estudios, como las pruebas controladas aleatorias en cardiología (varios miles de sujetos escogidos al azar) (Yusuf, Collins y Peto, 1984), que en campos científicos con estudios pequeños, como la mayoría de la investigación de predictores moleculares (tamaños de muestra 100 veces más pequeños) (Altman y Royston, 2000).
Corolario 2: Cuanto más pequeño son los tamaños de efecto en un campo científico menor es la probabilidad de que los resultados de investigación sean verdaderos. El poder también está relacionado con el tamaño de efecto. Por tanto, es más probable que los resultados de investigación sean verdaderos en campos científicos con grandes efectos, como el impacto del tabaquismo en el cáncer o en enfermedades cardiovasculares (riesgos relativos de 3 a 20), que en campos científicos donde los efectos postulados son pequeños, como los factores genéticos de riesgo de enfermedades multigenéticas (riesgos relativos de 1,1 a 1,5) (Ioannidis, 2003). La epidemiología moderna está cada vez más obligada a elegir tamaños de efecto más pequeños (Taubes, 1995). En consecuencia, se espera que disminuya la proporción de resultados de investigación verdaderos. En la misma línea de pensamiento, si los tamaños de efecto verdaderos son muy pequeños en un campo científico, es probable que este campo esté plagado de pretensiones falsas positivas casi ubicuas. Por ejemplo, si la mayoría de los determinantes genéticos o nutricionales verdaderos de enfermedades complejas confieren riesgos relativos menores de 1,05, la epidemiología genética o nutricional sería en gran parte un esfuerzo utópico.
Corolario 3: Cuanto mayor es el número y menor la selección de relaciones comprobadas en un campo científico menor es la probabilidad de que los resultados de investigación sean verdaderos. Como se mostró antes, la probabilidad posterior al estudio de que un hallazgo sea verdadero (vpp) depende mucho de las probabilidades pre-estudio (r). Por tanto, es más probable que los resultados de investigación sean verdaderos en diseños confirmatorios, como las grandes pruebas aleatorias controladas fase III o sus meta-análisis, que en experimentos que generan hipótesis. Los campos que se consideran muy informativos y creativos dada la riqueza de la información recopilada y comprobada, como los micro arreglos y otras investigaciones orientadas al descubrimiento de alto rendimiento (Michiels, Koscielny y Hill, 2005; Ioannidis, 2005; Golub, Slonim et al., 1999), deberían tener VPP sumamente bajos.
Corolario 4: Cuanto mayor es la flexibilidad de los diseños, las definiciones, los resultados y los modos analíticos en un campo científico menor es la probabilidad de que los resultados de investigación sean verdaderos. La flexibilidad aumenta el potencial para transformar lo que serían resultados "negativos" en resultados "positivos", es decir, el sesgo u. En algunos diseños de investigación, por ejemplo, en pruebas aleatorias controladas (Moher, Schulz y Altman, 2001; Ioannidis, Evans et al., 2004; ICHE9, 1999) o meta-análisis (Moher, Cook, Eastwood et al., 1999; Stroup, Berlin, Morton et al., 2000), se han hecho esfuerzos para estandarizar su conducta y sus informes. Es probable que la adhesión a estándares comunes aumente la proporción de hallazgos verdaderos. Lo mismo se aplica a los resultados. Los hallazgos verdaderos pueden ser más comunes cuando los resultados son inequívocos y aceptados universalmente (p. ej., la muerte) que cuando se diseñan resultados muy diversos (p. ej., escalas de resultados de esquizofrenia) (Marshall, Lockwood, Bradley et al., 2000). De mamera similar, los campos que utilizan métodos analíticos estereotipados comúnmente acordados (p. ej., diagramas Kaplan-Meier y pruebas de comparación de sobrevivencia) (Altman y Goodman, 1994) pueden arrojar una mayor proporción de hallazgos verdaderos que campos donde los métodos analíticos aún están en experimentación (p. ej., métodos de inteligencia artificial) y solo se reportan los "mejores" resultados. No obstante, incluso en los diseños de investigación más estrictos, el sesgo parece ser un problema importante. Por ejemplo, hay fuerte evidencia de que el reporte selectivo de resultados, con la manipulación de los resultados y los análisis reportados, es un problema común incluso en pruebas aleatorias (Chan, Hrobjartsson, Haahr et al., 2004). La simple abolición de la publicación selectiva no haría desaparecer este problema.
Corolario 5: Cuanto mayores son los intereses y prejuicios financieros y de otro tipo en un campo científico menor es la probabilidad de que los resultados de la investigación sean verdaderos. Los conflictos de interés y los prejuicios pueden aumentar el sesgo u. Los conflictos de interés son muy comunes en la investigación biomédica (Krimsky, Rothenberg, Stott y Kyle, 1998), y suelen ser reportados en forma inadecuada y poco frecuente (ibid.; Papanikolaou, Baltogianni, Contopoulos-I. et al., 2001). Los prejuicios no necesariamente tienen orígenes financieros. Los científicos de un campo dado pueden tener prejuicios debido simplemente a su creencia en una teoría científica o al compromiso con sus propios resultados. Muchos estudios en apariencia independientes, realizados en las universidades, se pueden llevar a cabo únicamente para dar a los médicos e investigadores calificaciones para su promoción o su titularidad. Tales conflictos no financieros también pueden llevar a reportar resultados e interpretaciones distorsionados. Los investigadores prestigiosos pueden suprimir la aparición y la difusión de resultados que refuten sus hallazgos mediante el proceso de revisión por pares. Así perpetúan falsos en su campo de investigación. La evidencia empírica sobre la opinión de los expertos además, que es poco confiable (Antman, Lau et al., 1992).
Corolario 6: Cuanto más caliente es un campo científico (que involucra más equipos científicos) menor es la probabilidad de que los resultados de investigación sean verdaderos. Este corolario aparentemente paradójico se debe a que, como ya se indicó, el VPP de hallazgos aislados disminuye cuando muchos equipos de investigadores participan en el mismo campo. Esto puede explicar por qué a veces vemos gran excitación seguida de profundas desilusiones en campos que atraen mucha atención. Cuando numerosos equipos trabajan en el mismo campo y se producen datos experimentales masivos, la oportunidad es esencial para vencer a los competidores. Así, cada equipo puede dar prioridad a la búsqueda y difusión de sus resultados "positivos" más impresionantes. Puede ser atractivo difundir resultados "negativos" solo si o tro equipo h a encon trado una asociación "positiva" sobre la misma pregunta. En ese caso, puede ser atractivo refutar una pretensión publicada en una revista prestigiosa. Se acuñó la expresión "fenómeno Proteo" para describir pretensiones de investigación extremas rápidamente alternantes y refutaciones del todo opuestas (Ioannidis y Trikalinos, 2005). La evidencia empírica sugiere que esta secuencia de extremos opuestos es muy común en genética molecular (ibíd.).
Estos corolarios consideran cada factor por separado, pero a menudo se influyen entre sí. Por ejemplo, puede ser más probable que los investigadores que trabajan en campos donde los tamaños reales de efecto se consideran pequeños sean más propensos a realizar grandes estudios que los investigadores que trabajan en campos donde los tamaños reales de efecto se consideran grandes. O en un campo científico caliente pueden predominar perjuicios que socavan aún más el valor predictivo de sus resultados. Las partes interesadas muy prejuiciadas incluso pueden incluso crear barreras que aborten los esfuerzos para obtener y difundir resultados opuestos. A la inversa, el hecho de que un campo sea caliente o tenga fuertes intereses creados a veces puede promover estudios más grandes y mejores estándares de investigación, lo que mejora el valor predictivo de sus resultados de investigación. O las pruebas masivas orientadas al descubrimiento pueden dar como resultado tal cantidad de relaciones significativas que los investigadores tienen las suficientes para reportar e investigar más y así abstenerse del dragando y la manipulación de datos.
LA MAYORÍA DE LOS RESULTADOS DE INVESTIGACIÓN SON FALSOS EN LA MAYORÍA DE LOS DISEÑOS Y EN LA MAYORÍA DE LOS CAMPOS
En el marco descrito, un VPP superior al 50% es muy difícil de conseguir. El cuadro 4 presenta los resultados de las simulaciones que usan las fórmulas desarrolladas sobre la influencia del poder, la proporción relaciones verdaderas-no verdaderas y el sesgo, para varios tipos de situaciones que pueden ser características de diseños y campos de estudio específicos. Un hallazgo de una prueba aleatoria controlada, con un poder adecuadamente calibrado y bien realizada, que comienza con una posibilidad pre-estudio del 50% de que la intervención sea efectiva es eventualmente verdadero cerca del 85% de las veces. Se espera un desempeño muy similar en un meta-análisis confirmatorio de pruebas aleatorias de buena calidad: el sesgo potencial quizá aumente, pero el poder y las oportunidades antes de la prueba son más altos en comparación con una sola prueba aleatoria. A la inversa, un resultado meta-analítico de estudios no concluyentes, en los que el agrupamiento se usa para "corregir" el bajo poder de los estudios individuales, es probablemente falso si R < 1:3. Los resultados de investigación de ensayos clínicos de fase inicial con bajo poder serían verdaderos cerca de una a cuatro veces, o incluso menos frecuentes si el sesgo está presente. Los estudios epidemiológicos de naturaleza exploratoria se desempeñan aún peor, en especial cuando tienen poco poder, pero incluso los estudios epidemiológicos con buen poder pueden tener solo una probabilidad de uno a cinco de ser verdaderos, si R = 1:10. Por último, en la investigación orientada al descubrimiento con pruebas masivas, donde las relaciones probadas superan 1.000 veces a las verdaderas (p. ej., 30.000 genes probados, de los cuales 30 pueden ser los verdaderos culpables) (Ntzani y Ioannidis, 2003), el VPP de cada pretendida relación es sumamente bajo, aun con una considerable estandarización de los métodos estadísticos y de laboratorio, de los resultados y de los informes para minimizar el sesgo.
Cuadro 4 VPP de resultados de investigación para varias combinaciones de poder (1-ß), proporción de relaciones verdaderas-no verdaderas (R) y sesgo (u)
| 1-ß | R | u | Ejemplo práctico | VPP |
|---|---|---|---|---|
| 0,80 | 1:1 | 0,10 | PAC de poder adecuado con poco sesgo y 1:1 probabilidades pre-estudio | 0,8500 |
| 0,95 | 2:1 | 0,30 | Meta-análisis confirmatorio de PAC de buena calidad | 0,8500 |
| 0,80 | 1:3 | 0,40 | Meta-análisis de estudios pequeños no concluyentes | 0,4100 |
| 0,20 | 1:5 | 0,20 | PAC de poco poder, fase I/II bien realizada | 0,2300 |
| 0,20 | 1:5 | 0,80 | PAC de poco poder, fase I/II mal realizada | 0,1700 |
| 0,80 | 1:10 | 0,30 | Estudio epidemiológico exploratorio de poder adecuado | 0,2000 |
| 0,20 | 1:10 | 0,30 | Estudio epidemiológico exploratorio de poco poder | 0,1200 |
| 0,20 | 1:1.000 | 0,80 | Investigación exploratoria orientada al descubrimiento con pruebas masivas | 0,0010 |
| 0,20 | 1:1.000 | 0,20 | Como en el ejemplo anterior, pero con sesgo más limitado (más estandarizado) | 0,0015 |
Los VPP estimados (valores predictivos positivos) se calculan suponiendo a = 0,05 para un solo estudio.
PAC: prueba aleatoria controlada.
DOI: 10.1371/journal.pmed.0020124.t004
LOS RESULTADOS DE INVESTIGACIÓN REIVINDICADOS A MENUDO PUEDEN SER MEDIDAS PRECISAS DEL SESGO PREDOMINANTE
La mayor parte de la investigación biomédica moderna opera en áreas con muy baja probabilidad pre-estudio y post-estudio de hallazgos verdaderos. Supongamos que en un campo de investigación no hay hallazgos verdaderos por hacer. La historia de la ciencia nos enseña que, en el pasado, el empeño científico a menudo desperdició esfuerzos en campos que no producían ninguna información científica verdadera, al menos según nuestra comprensión actual. En ese "campo nulo", lo ideal sería esperar que todos los tamaños de efecto observados varíen al azar alrededor de 0 en ausencia de sesgo. El grado en que los resultados observados se desvían de lo que se espera solo por azar sería simplemente una medida pura del sesgo predominante.
Por ejemplo, supongamos que ningún nutriente o patrón dietético es realmente un determinante importante del riesgo de desarrollar un tumor específico. Supongamos también que la literatura científica ha examinado 60 nutrientes y afirma que todos ellos están relacionados con el riesgo de desarrollar este tumor con riesgos relativos de un rango de 1,2 a 1,4 para la comparación de los terciles superiores e inferiores de ingesta. Los tamaños de efecto pretendidos no miden entonces más que el sesgo neto involucrado en la elaboración de esta literatura científica. Los tamaños de efecto pretendidos son de hecho las estimaciones más precisas del sesgo neto. Se deduce incluso que entre "campos nulos", los campos que pretenden mayores efectos (a menudo con las pretensiones acompañantes de importancia médica o de salud pública) son simplemente aquellos que han sostenido los peores sesgos.
En campos con VPP muy bajo, las pocas relaciones verdaderas no distorsionarían mucho esta imagen general. Incluso si algunas relaciones son verdaderas, la forma de la distribución de los efectos observados aún arrojaría una medida clara de los sesgos involucrados en el campo. Este concepto invierte por completo la manera de ver los resultados científicos. Tradicionalmente, los investigadores han visto con excitación efectos grandes y altamente significativos como signos de descubrimientos importantes. En realidad, los efectos demasiado muy grandes y muy significativos pueden ser signos de grandes sesgos en la mayoría de los campos de la investigación moderna. Deberían llevar a los investigadores a una cuidadosa reflexión crítica sobre lo que puede haber salido mal con sus datos, análisis y resultados.
Por supuesto, es probable que los investigadores que trabajan en cualquier campo se resistan a aceptar que todo el campo al que han dedicado su carrera sea un "campo nulo". Sin embargo, otras líneas de prueba, o avances en la tecnología y la experimentación, pueden llevar eventualmente al desmantelamiento de un campo científico. La obtención de medidas del sesgo neto en un campo también puede ser útil para obtener información de cuál podría ser el rango del sesgo en otros campos donde pueden existir métodos analíticos, tecnologías y conflictos similares.
¿CÓMO PODEMOS MEJORAR LA SITUACIÓN?
¿Es inevitable que la mayoría de los resultados de investigación sean falsos, o podemos mejorar la situación? Un problema importante es que resulta imposible saber con el 100% de certeza cuál es la verdad en cualquier pregunta de investigación. A este respecto, el patrón "oro" puro es inalcanzable. Sin embargo, hay varios enfoques para mejorar la probabilidad post-estudio.
Por ejemplo, evidencia con mayor poder; los grandes estudios o los meta-análisis con menor sesgo pueden ayudar, pues se acercan más al patrón "oro" desconocido. Aunque los grandes estudios pueden tener sesgos y estos se deberían reconocer y evitar. Además, es imposible obtener evidencia a gran escala para todos los millones y trillones de preguntas de investigación planteadas en la investigación actual. La evidencia a gran escala se debería centrar en preguntas de investigación donde la probabilidad pre-estudio ya es muy alta, de modo que un hallazgo de investigación significativo lleve a una probabilidad postcomprobación que se considere bastante definitiva. La evidencia a gran escala también es particularmente indicada cuando pueda probar conceptos importantes en vez de preguntas estrechas y específicas. Un hallazgo negativo puede entonces refutar no solo una pretensión específica propuesta sino todo un campo o una parte considerable de ese campo. La selección del desempeño de estudios a gran escala con base en criterios estrechos, como la promoción comercial de un medicamento específico, es investigación desperdiciada. Además, se debe tener cuidado para que los estudios sumamente grandes tengan mayor probabilidad de encontrar una diferencia estadística formalmente significativa acerca de un efecto trivial que no sea significativamente diferente del efecto nulo (Lindley, 1957; Bartlett, 1957; Senn, 2001).
En segundo lugar, la mayoría de las preguntas de investigación son abordadas por muchos equipos, y es engañoso hacer énfasis en los hallazgos estadísticamente significativos de un equipo particular. Lo que importa es la totalidad de la evidencia. La disminución del sesgo mediante mejores estándares de investigación y la reducción de los prejuicios también pueden ayudar. Pero esto puede requerir un cambio de la mentalidad científica que puede ser difícil de lograr. En algunos diseños de investigación, los esfuerzos también pueden ser más exitosos con un registro anticipado de los estudios, por ejemplo, de los ensayos aleatorios (De Angelis, Drazen et al., 2004). El registro sería un reto para la investigación que genera hipótesis. Un tipo de registro o de interconexión de redes de bases de datos o de investigadores dentro de los campos puede ser más factible que registrar todos y cada uno de los experimentos que generan hipótesis. Pero aunque no veamos un gran avance en el registro de estudios en otros campos, podrían adoptarse más ampliamente los principios de desarrollo y adhesión a un protocolo de las pruebas aleatorias controladas.
Finalmente, en vez de perseguir la significancia estadística, deberíamos mejorar nuestra comprensión del rango de valores R -las probabilidades pre-estudio- donde operan los esfuerzos de investigación (Wacholder, Chanock, Garcia-C. et al., 2004). Antes de hacer un experimento, los investigadores deberían considerar la posibilidad de que crean estar probando una relación verdadera en vez de una no verdadera. A veces se pueden determinar unos altos valores conjeturados de R. Como se mostró más atrás, siempre que sean éticamente aceptables, se deben realizar grandes estudios con un sesgo mínimo sobre los hallazgos de investigación que se consideran relativamente establecidos, para ver con qué frecuencia se confirman. Sospecho que varios "clásicos" establecidos no pasarán la prueba (Ioannidis, 2005).
No obstante, la mayoría de los nuevos descubrimientos seguirán siendo resultado de la investigación que genera hipótesis con bajas o muy bajas probabilidades pre-estudio. Deberíamos reconocer entonces que las pruebas de significancia estadística en el reporte de un solo estudio dan una imagen apenas parcial, sin saber cuántas pruebas se han realizado fuera del informe y en el campo relevante. A pesar de la abundante literatura estadística sobre múltiples correcciones de pruebas (Hsueh, Chen y Kodell, 2003), suele ser imposible descifrar cuánto han dragado los datos los autores informantes u otros equipos de investigación que han precedido a un hallazgo de investigación reportado. Incluso si fuese factible determinarlo, esto no nos informaría sobre las probabilidades pre-estudio. De modo que es inevitable hacer suposiciones aproximadas sobre cuántas relaciones se espera que sean verdaderas entre las que se prueban en los campos de investigación y diseño de investigación relevantes. El campo más amplio puede ofrecer una guía para estimar esta probabilidad en un proyecto de investigación aislado. También sería útil aprovechar las experiencias de sesgos detectados en otros campos vecinos. Aunque estas suposiciones serían muy subjetivas, serían muy útiles para interpretar las pretensiones de investigación y ponerlas en contexto.

