










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkCiencia e Ingeniería Neogranadina
versão impressa ISSN 0124-8170versão On-line ISSN 1909-7735
Cienc. Ing. Neogranad. v.19 n.1 Bogotá jan./jun. 2009
Yolvy Amileth, Turizo Ascencio2
Diego Arturo, Sánchez Cárdenas3
1Ing. Sistemas, Esp. Ingeniería software, MsC. Ciencias Computacionales, Profesor Asistente Universidad Pedagógica y Tecnológica de Colombia, Tunja, Colombia, maurocallejas@yahoo.com
2Ing. de Sistemas y Computación. Universidad Pedagógica y Tecnológica de Colombia, Tunja, Colombia, yolvytu@yahoo.es
3Ing. de Sistemas y Computación. Universidad Pedagógica y Tecnológica de Colombia, Tunja, Colombia, dasc25@gmail.com
Fecha de recepción: 9 septiembre de 2008 Fecha de aprobación: 11 de junio de 2009
RESUMEN
En este documento se explica el desarrollo de una solución informática (Programa Forensys) para el Grupo de Caballería Mecanizado N°1 "Silva Plazas" (GMSIL) que facilita la identificación de los soldados ante y pos mortem utilizando la replicación de datos como servicio móvil para acceder a la información en tiempo real.
Palabras clave: soldado, replicación, tiempo real.
ABSTRACT
This document explains the development of a software for the Mechanized Cavalry Group No. 1 "Silva Plazas" (GMSIL) that facilitates the identification of soldiers ante and post mortem using data replication as a mobile service to have access to the information in a real time.
Key words: soldiers, replication, real time.
INTRODUCCIÓN
Los hombres vinculados a las Fuerzas Militares de Colombia son quienes mantienen el orden público en distintas zonas de la geografía nacional con el objetivo de brindar protección a la población civil y en virtud de su labor, los soldados se ven abocados a permanecer en constantes enfrentamientos con delincuentes o grupos al margen de la ley, que en ocasiones terminan con sus vidas. De esta manera se puede decir que es importante desarrollar un sistema que a través de los restos mortales hallados, establezca automáticamente su plena identificación.
Inicialmente se buscó a través de estudios científicos, identificar a las personas vivas. Hoy en día existen sistemas de información sofisticados, que por medio de la superposición radiofotográfica, la reconstrucción facial y el análisis de huellas dactilares consiguen identificar a un ser humano.
El principal objetivo de este proyecto radica en el desarrollo de una aplicación informática para el Grupo de Caballería Mecanizado N° 1 "Silva Plazas", que facilite la identificación ante y pos mortem de los soldados; aun a pesar de las limitaciones de infraestructura de telecomunicaciones que ciertos lugares geográficos pertenecientes a su jurisdicción puedan presentar.
Este adelanto tecnológico, es el punto inicial para idear nuevos proyectos en Colombia, enfocados en el procesamiento de imágenes digitalizadas como instrumento para la identificación humana.
1. MATERIALES Y MÉTODOS
En esta sección se describen algunas teorías utilizadas, luego se explica el método implementado y finalmente se describen las tecnologías y herramientas de software usadas.
1.1. BASES DE DATOS DISTRIBUIDAS
Consiste en un conjunto de localidades, cada una de las cuales mantiene un sistema de base de datos local. Cada localidad puede procesar transacciones locales, o bien transacciones globales entre varias localidades, requiriendo para ello comunicación entre sí [4].
1.2. ALMACENAMIENTO DISTRIBUIDO DE DATOS
Este apartado cubre dos tópicos fundamentales: la fragmentación y la replicación, que se definen enseguida.
1.2.1. Fragmentación
Dado que una relación se corresponde esencialmente con una tabla cualquiera dentro de una base de datos y la cuestión consiste en dividirla en fragmentos menores, para lo cual surgen dos alternativas lógicas en el proceso: la fragmentación horizontal y la fragmentación vertical.
Fragmentación Horizontal: Divide una relación R en subconjuntos de tuplas1, cada uno de ellos con un significado lógico.
Fragmentación Vertical: Divide la relación R en conjuntos de columnas. Cada fragmento mantiene ciertos atributos de la relación original. El objetivo de la fragmentación vertical consiste en dividir la relación en un conjunto de relaciones más pequeñas, tal que algunas de las aplicaciones de usuario sólo hagan uso de un fragmento.
1.2.2. Replicación
Es el proceso de copiar y de mantener los objetos de la base de datos en las múltiples bases de datos que incorporan un sistema distribuido. La replicación es útil para mejorar el funcionamiento y para proteger la disponibilidad de aplicaciones porque existen las opciones alternas del acceso de los datos.
Las aplicaciones transaccionales distribuidas de la base de datos, típicamente usan transacciones distribuidas para tener acceso a datos locales y remotos y modificar la base de datos global en tiempo real. [4]
-
Replicación de Instantáneas: En la replicación de instantáneas los datos se copian tal y como aparecen exactamente en un momento determinado. Por consiguiente, no requiere un control contínuo de los cambios. Se recomienda utilizarla cuando la mayoría de los datos no cambian periódicamente; se replican pequeñas cantidades de datos; los sitios con frecuencia están desconectados y es aceptable un periodo de latencia largo (la cantidad de tiempo que transcurre entre la actualización de los datos en un sitio y en otro). En ocasiones se hace necesario utilizarla cuando están involucrados algunos tipos de datos (text, ntext, e image) cuyas modificaciones no se almacenan en el registro de transacciones y por tanto no se pueden replicar utilizando la metodología de replicación transaccional.
-
Replicación Transaccional: En este caso se propaga una instantánea inicial de datos y después, cuando se efectúan las modificaciones, las transacciones individuales son propagadas. Suele utilizarse cuando se desea que las modificaciones de datos se propaguen normalmente pocos segundos después de producirse; se necesita que las transacciones sean atómicas, que se apliquen todas o ninguna; su aplicación no puede permitir un periodo de latencia largo para los cambios.
-
Replicación de Mezcla: Permite que varios sitios funcionen en línea o desconectados de manera autónoma y mezclar más adelante las modificaciones de datos realizadas en un resultado único y uniforme. Los datos se sincronizan entre los servidores a una hora programada o a petición. Las actualizaciones se realizan de manera independiente. Es útil en ambientes en los que cada sitio hace cambios solamente en sus datos pero que necesitan tener la información de los otros sitios [1].
Implementación de la replicación. Generalmente se clasifica la replicación según el sentido de los datos y según la oportunidad [9].
El sentido de viaje de los datos:
-
Unidireccional: cuando se tiene un nodo actualizable (copia principal) y otro nodo que contiene una copia del principal pero de sólo lectura.
-
Bidireccional: cuando se tiene que en todos los nodos se actualizan los datos y la replicación fluye en ambos sentidos.
La oportunidad de replicación:
-
Síncrona: cuando una tabla es actualizada en la copia principal, inmediatamente después las demás copias secundarias son actualizadas.
-
Asíncrona: consiste en actualizar las bases de datos secundarias en intervalos de tiempo.
1.3. NECROIDENTIFICACIÓN
La necroidentificación consiste en comparar, cotejar, poner en correlación, los datos obtenidos de un cadáver (datos "post mortem" = PM) con aquellos otros facilitados por familiares, conocidos, incluso por sistemas existentes, relativos a la persona que se sospecha fallecida y que se trata de identificar (datos "ante mortem" = AM). De la coincidencia entre datos AM y PM se obtiene el dictamen de identidad correspondiente, atendiendo a la calidad y cantidad de tales coincidencias.
El conjunto de técnicas de necroidentificación es variado; las circunstancias concretas de cada caso determinarán el empleo de las más adecuadas, pero sabiendo que no todas tienen el mismo grado de validez: la dactiloscopia y la odontología permiten, por sí solas, la identificación plena de un cadáver, mientras que en otros casos será el empleo conjunto de varias técnicas distintas las que puedan conducir al establecimiento de una identificación [2].
1.4. METODOLOGÍA DE DESARROLLO DE LA APLICACIÓN
La metodología aplicada para desarrollar el software que aquí se describe (FORENSYS), fue el Proceso Unificado [3]. Cada fase se llevó a cabo así:
Iniciación. Se desarrollaron entrevistas al personal de sanidad, operaciones, recurso humano y de inteligencia, para conocer sus necesidades, responsabilidades y funciones en cuanto al proceso actual de reconocimiento ante y pos mortem practicado a los soldados. Luego de comprender detalladamente el proceso, se definen los requisitos para la aplicación de acuerdo a las condiciones exigidas por el GMSIL, los usuarios finales y los desarrolladores; y finalmente se realiza la selección de la arquitectura de software sobre la cual se basa el diseño de la aplicación.
Elaboración. Se realizó la representación estática y dinámica del sistema con la asistencia de los usuarios finales. Los diagramas UML [7], que se elaboraron en esta fase, explican la interacción de los usuarios con el sistema, el diseño interno tanto de la aplicación como de la base de datos y la instalación de sus componentes dentro del GMSIL.
Construcción. Se realizó la codificación de cada módulo de la aplicación FORENSYS utilizando el lenguaje de programación Java [10] y el motor de base de datos Mysql [5]. Posteriormente se realizaron las pruebas de unidad e integración a la aplicación [6].
Transición. Terminó el proceso de codificación y se efectuaron pruebas con los usuarios finales y se dictaminaron cambios al aplicativo.
Producción. Se implantó FORENSYS en la red del GMSIL y se depuraron defectos.
1.5. TECNOLOGÍAS Y HERRAMIENTAS DE IMPLEMENTACIÓN
FORENSYS, se diseñó especialmente para lograr la identificación ante y pos mortem de los soldados en servicio incorporados al Grupo de Caballería Mecanizado N°1 Silva Plazas de la Ciudad de Duitama. Es un producto nuevo, independiente y totalmente autónomo. Cualquier operación o cambio que pueda ocurrir en éste no modifica ni altera ningún otro sistema informático que opera dentro del GMSIL.
Interfaces con el hardware. Los dispositivos con los que interactúa FORENSYS son los siguientes: a. Cinco equipos de escritorio con características de cliente. b. Un equipo portátil con características de cliente, para trasladar la información de reconocimiento al lugar de los hechos. c. Un equipo con características de servidor para el alojamiento de la base de datos. d. Un lector de huellas (captura de huellas dactilares) e. Y una cámara digital (captura de señales particulares).
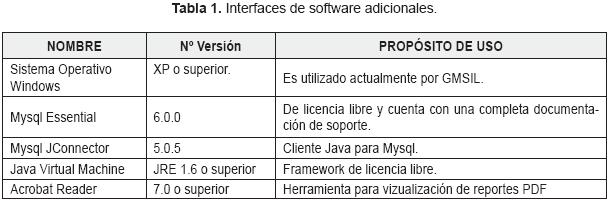
Interfaces con el software. FORENSYS usa los productos y/o paquetes de software que se presentan en la Tabla1.
Interfaces de comunicaciones. En cuanto a las interfaces de comunicación se usa una Red de Área Local - LAN y el protocolo TCP/IP que establece comunicación entre los equipos clientes y servidor.
Restricciones de memoria. La memoria RAM mínima que deben tener los equipos clientes debe ser de 256MB y para el servidor de 512MB. El espacio mínimo de memoria virtual para el servidor debe ser 1GB.
Arquitectura de software. El patrón empleado para el diseño de FORENSYS fue el Modelo Vista Controlador (MVC). Este patrón plantea la separación en tres capas: 1. Capa Modelo: representa la realidad. 2. Capa Controlador: conoce los métodos y atributos del modelo, recibe y realiza lo que el usuario quiere hacer. 3. Capa Vista: muestra un aspecto del modelo y es utilizada por la capa anterior para interaccionar con el usuario [8].
2. RESULTADOS Y ANÁLISIS
En cuanto a la identificación ante mortem que se realiza a un soldado en su proceso de incorporación, FORENSYS facilita su registro que corresponde a la Ficha Nacional de Identificación exigida por el Ejército Nacional de Colombia; esto se hace a través del módulo de identificación. De esta manera, cuando un soldado muere en circunstancias de difícil reconocimiento (incineración, a causa de explosivos, o en un estado de descomposición avanzado) el sistema permite ingresar parte de la información de dicho soldado, relacionada con su descripción morfológica, señales particulares y carta dental, para poder iniciar la búsqueda en el módulo antes mencionado y lograr determinar su identidad. Este reconocimiento se hace en el propio lugar de los hechos, aun a pesar de las limitaciones de infraestructura de comunicaciones que presentan algunos lugares geográficos, ya que toda la información es transportada en un equipo portátil.
Los módulos que componen FORENSYS están instalados dentro del GMSIL de acuerdo a la información que cada grupo de usuarios puede manipular. La función de cada módulo se explica a continuación:
2.1. MÓDULO DE USUARIOS
Permite crear y modificar los usuarios que tienen acceso a los diferentes apartes del aplicativo, como se observa en la figura 1.

2.2. MÓDULO DE IDENTIFICACIÓN
Registra la información de identificación de un soldado, señales particulares (figura 2), carta dental (figura 3), huellas dactilares (figura 4), y permite realizar búsquedas para cotejar la consistencia de los datos después de su fallecimiento.
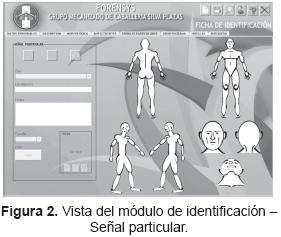


Este módulo se encuentra actualmente instalado en el consultorio médico y odontológico, en la dirección de recurso humano, en la oficina de inteligencia y en un equipo portátil, ya que estas dependencias ingresan a FORENSYS la información relacionada con su área, esto se hace en el momento de listar el personal a GMSIL. Por otro lado, a través de este módulo se mantiene actualizada y se consulta la situación del personal (aspectos de salud, carta dental, señales particulares, antecedentes entre otros).
2.3. MÓDULO DE GRUPOS
Permite ver los soldados activos clasificados por grupos y la zona en donde se encuentran operando. Además, desde este módulo es posible modificar el estado actual del soldado (vivo o fallecido), tal como se aprecia en la figura 5.

2.4. MÓDULO DE REPLICACIÓN
Permite realizar una copia de la información de identificación del grupo de soldados que se encuentra operando en una zona de tragedia, haciendo que la información para este evento se presente de manera veraz y oportuna simulando tiempo real (figura 6).

En este último módulo es implementada la fragmentación horizontal en conjunto con el proceso de replicación de instantáneas con el objetivo de realizar una copia parcial a un equipo portátil desde la base de datos central ubicada en el servidor. Este proceso se divide en las siguientes seis etapas:
-
Inicialmente se realiza una selección de los soldados (fragmentación horizontal) por zona de operación.
-
En seguida se ejecuta el proceso de fragmentación horizontal sobre las demás tablas de la base de datos que contienen información de los soldados obtenidos en la primera etapa de este proceso.
-
Se realiza una selección de los soldados por el grupo militar al que pertenecen.
-
El resultado de los pasos anteriores, se transfiriere en su totalidad a un equipo portátil mediante un proceso de replicación asíncrona unidireccional.
-
Se actualiza la información de identificación del soldado indicando su estado actual, vivo o fallecido directamente en el módulo de identificación.
-
Se transfiere a la base de datos central la información actualizada del grupo militar.
El proceso descrito anteriormente se realiza de manera transparente para el usuario final, ya que éste únicamente indica el parámetro según el cual se lleva a cabo la fragmentación en la primera etapa y las demás son realizadas internamente entre el servidor de la base de datos y el módulo de replicación.
3. CONCLUSIONES
Gracias a la información de identificación generada por FORENSYS, las entidades judiciales del país, pueden dar inicio a investigaciones para buscar a aquellos soldados que han sido retenidos o se encuentran desaparecidos por distintas causas.
La información de identificación que proporciona FORENSYS es de gran apoyo en el examen que realizan los médicos a los cuerpos para confirmar su identificación, determinar las causas de la muerte y finalmente hacer entrega de un dictamen forense.
FORENSYS permite realizar el reconocimiento de soldados que mueren en diversas circunstancias, especialmente cuando el cuerpo se encuentra completamente destruido o en un estado de descomposición avanzado, o porque ha sido víctima de incineración, ya que se debe recurrir a ciertas técnicas de identificación como la carta dental para lograr el éxito de su reconocimiento.
Cuando muere una cantidad significativa de soldados, el proceso de reconocimiento de víctimas se hace menos dispendioso y prolongado ya que FORENSYS permite registrar todos los hallazgos y buscar automáticamente a través de un equipo portátil el nombre de los soldados fallecidos en el lugar de los hechos.
Cuando un soldado asiste a una cita médica u odontológica, los antecedentes médicos, las señales particulares y la carta dental se actualizarán a través de FORENSYS, manteniendo así información confiable para el personal encargado de hacer su reconocimiento.
Los familiares tendrán conocimiento de la muerte del soldado en el instante de su reconocimiento, ya que los datos familiares contenidos en la base de datos estarán actualizados.
Pie de página
1Es la representación de una fila en una tabla dentro de cualquier base datos.REFERENCIAS BIBLIOGRÁFICAS
[1] AGUIRRE RIVERA Carlos Eduardo, 2007. Guía no. 4 bases de datos distribuidas. Página consultada el 20 diciembre de 2007. En: http://www.gratisweb.com/aguirre2007/guia4.htm. [ Links ]
[2] CARRERA CARBAJO I, 2008. Identificación de cadáveres y aspectos forenses de los desastres. Página consultada el 19 de junio de 2008. En: http://www.desastres.org/pdf/identificacioncadaveres.pdf. [ Links ]
[3] LARMAN Cray, (2003). UML y Patrones: Una introducción al análisis y diseño orientado a objetos y al proceso unificado. Madrid, Prentice Hall. 590 p. [ Links ]
[4] MONGE Raúl, 2008. Base de datos distribuidas: replicación. Página consultada el 19 junio 2008. En: www.itescam.edu.mx/principal/sylabus/fpdb/recursos/r11294.PDF. [ Links ]
[5] MySQL, (2008). Versiones de base de datos Mysql. Página consultada el 19 de junio de 2008. En: www.mysql.com. [ Links ]
[6] PRESSMAN Roger S., (2005). Ingeniería del Software: Un enfoque práctico, McGraw-Hill. 900 p. [ Links ]
[7] RUMBAUGH James, JACOBSON Ivar, BOOCH Grady, (2007). El Lenguaje Unificado de Modelado Manual de Referencia. Madrid, Addison Wesley. 667 p. [ Links ]
[8] TEDESCHI Nicolás, (2008). MVC (Model View Controler). Página consultada el 19 de junio de 2008. En: http://www.microsoft.com/spanish/msdn/comunidad/mtj.net/voices/MTJ_2828/default.aspx. [ Links ]
[9] UNIVERSIDAD NACIONAL DE TRUJILLO, 2007. Replicación de datos. Página consultada el 20 de diciembre de 2007. En: www.inf.unitru.edu.pe/~edsh/documentos/bd_replicacion.pdf. [ Links ]
[10] WEITZENFIELD Alfredo, (2004). Ingeniería de software orientada a objetos con Java e Internet. Thomson Learning Ibero. 698 p. [ Links ]

