










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkCiencia e Ingeniería Neogranadina
Print version ISSN 0124-8170On-line version ISSN 1909-7735
Cienc. Ing. Neogranad. vol.21 no.1 Bogotá Jan./June 2011
DISEÑO DE UN SISTEMA DE RECOMENDACIÓN EN REPOSITORIOS DE OBJETOS DE APRENDIZAJE BASADO EN LA PERCEPCIÓN DEL USUARIO: CASO RODAS
DESIGNING A LEARNING OBJECTS RECOMMENDATION SYSTEM FOR REPOSITORIES BASED ON USER'S PERCEPTION: THE RODAS CASE
Manuel Fernando Caro Piñeres1
Jaime Hernández2
Jovani Alberto Jiménez Builes3
1Docente Investigador. Grupo EdupMedia. Departamento de Informática, Universidad de Córdoba. Montería. Córdoba, Colombia.
loshigos@yahoo.es
2Docente Departamento de Informática, Universidad de Córdoba. Montería. Córdoba, Colombia.
jhernandez@gmail.com
3Profesor asociado. Grupo de investigación: Inteligencia Artificial en Educación, Universidad Nacional de Colombia, Medellín, Antioquia, Colombia.
jajimen1@unal.edu.co
Fecha de recepción: 23 de enero de 2011 Fecha de aprobación: 28 de mayo de 2011
RESUMEN
Este trabajo presenta un sistema de recomendación (SR), de objetos de aprendizaje (OA), en repositorios. Es un sistema que se basa en el filtrado colaborativo que utiliza una adaptación del algoritmo k-vecinos y con fundamento en la percepción de usabilidad y utilidad que el usuario tiene acerca de los OA que descarga del repositorio. También muestra la forma como el algoritmo k-vecinos se adaptó al concepto de percepción con la implementación de un sistema de votación de los OA por parte de los usuarios. Al final se muestra la validación del SR, utilizando el repositorio RODAS, con apartes del algoritmo y el modelado computacional.
Palabras clave: objetos de aprendizaje, sistemas de recomendación, repositorios de objetos de aprendizaje.
ABSTRACT
This paper describes a Learning Objects (LO) Recommendation System (RS) for repositories. The system is based on collaborative filtering using an adaptation of kneighboring algorithm which is supported on user's perception about usability and usefulness rather than downloading LO from repository. It also shows how the k-neighboring algorithm is adapted to user's perception by implementing a voting system of LO. Finally, the RS validation using RODAS repository is given describing some pieces of algorithm and the computational model.
Key words: learning objects, recommendation system, learning object repositories.
INTRODUCCIÓN
Día a día, crece el uso de Internet en diferentes áreas que traen consigo, ventajas y desventajas. En cuanto al uso con propósitos educativos, nos encontramos con un gran volumen de información representado en miles de links que no siempre tienen relevancia para nuestra consulta, lo cual genera pérdida de tiempo y dinero que podrían ser aprovechados en otras actividades.
Con la masificación del acceso a Internet y la expansión de los Objetos Virtuales de Aprendizaje (OA), elaborados por diversas instituciones y personas dedicadas o relacionadas con la docencia, en la actualidad existe una gran cantidad de Repositorios de OA (ROA), diseñados para organizarlos. También predominan los sistemas de búsqueda por etiquetas y por atributos de los metadatos incluidos en los OA. Estos sistemas arrojan consultas que poco o nada tienen en cuenta el perfil del usuario que las realiza y mucho menos, con sus preferencias respecto de la usabilidad y utilidad del objeto validado en el contexto. Por esta razón, que cuando es necesario recurrir a OA elaborados por terceros, los docentes utilizan Internet como principal fuente para su obtención, invirtiendo muchas veces, más de una hora para encontrar el objeto requerido. Por medio Google, hacen búsquedas directas de los objetos en los sitios de descarga. Las personas no acceden a repositorios ni a bibliotecas virtuales, porque desconocen su existencia.
En este sentido, el proceso de retroalimentación dado por los usuarios a través de las anotaciones y evaluaciones referidas al uso del OA en el ámbito educativo, resultan valioso para fcrear una memoria histórica acerca de la usabilidad del objeto. La recomendación de un OA en un ROA que haya sido bien valorado por los usuarios en diversas situaciones de aprendizaje, es un campo que viene tomando fuerza en la actualidad [1]. Los SR ahorran tiempo a los usuarios en la personalización de las búsquedas, sugiriendo objetos con una valoración alta, concedida por los mismos usuarios. En este marco, el trabajo que aquí se presenta, responde a la pregunta de investigación: ¿cómo diseñar un SR basado en la percepción de usabilidad y utilidad que los usuarios tengan acerca de los OA en un ROA?
Para lograrlo, se diseñó un SR de OA en ROA basado en el filtrado colaborativo, utilizando una adaptación del algoritmo k-vecinos fundamentado en la percepción de usabilidad y utilidad que el usuario tiene acerca de los OA que descarga del ROA. Su implementación y validación se hizo en RODAS, que es un ROA conformado por dos subsistemas, que se denominan rodasAdmin y rodas. El primero contiene las funcionalidades inherentes a la administración y configuración del sistema. Allí se registran los usuarios que podrán utilizar los servicios del repositorio. Éste subsistema es para uso exclusivo del webmaster. El segundo cuenta con las funciones de búsqueda y descarga, así como los módulos de upload (subir objetos al sistema), evaluaciones y otros servicios comunicativos, como foros y chat. Este subsistema es visible para la población académica en general, y se encuentra disponible en www.edupmedia.org/rodasv3
RODAS fue elaborado en primera instancia, para los profesores y estudiantes de la Facultad de Educación y Ciencias Humanas de la Universidad de Córdoba, con el propósito de reutilizar los OA elaborados en las actividades de docencia y extensión. Con el paso del tiempo, se abrió a los docentes de las instituciones de educación básica y primaria del Departamento de Córdoba [2]. En la actualidad, tiene acceso desde el sitio Web de la Secretaría de Educación del Municipio de Montería, disponible en www.semmonteria.gov.co
Este artículo ha sido estructurado de la siguiente manera: en el capítulo uno, se describe de marco teórico de referencia. En el capítulo dos, se presenta la metodología utilizada. En el capítulo tres, se exterioriza la implementación y validación del modelo de recomendación. Luego, en el capítulo cuatro, se presentan los resultados de la prueba de validación y la discusión sobre los mismos. Por último, se incluyen las conclusiones, las recomendaciones y la bibliografía.
1. MARCO CONCEPTUAL DE REFERENCIA
Hoy en día, existen varios recursos disponibles para organizar la información en la Internet para evitar molestias a los usuarios. Uno de ellos, son los ROA, que son una mezcla entre un buscador y un servidor de descargas. Poseen la ventaja de que el contenido es producido con fines educativos y tienen una serie de herramientas que permiten acceder a los materiales digitales que son requeridos por los docentes para orientar sus asignaturas. Estos materiales sí son elaborados con fines educativos y se les denomina Objetos Virtuales de Aprendizaje (OVA o en inglés: Virtual Learning Objects, VLO), o simplemente, Objetos de Aprendizaje (OA), que pueden consultarse de forma rápida y oportuna, gracias al repositorio.
1.1 OBJETOS DE APRENDIZAJE
Formalmente no hay una única definición para los OA. Sin embargo, es interesante conocer la definición propuesta por el Comité de Estándares de Tecnologías de Aprendizaje de la IEEE (LTSC: Learning Technology Standards Committee): un OA es cualquier entidad, digital o no digital, la cual puede ser usada, re-usada o referenciada durante el aprendizaje apoyado por tecnología" [3].
También existen otras definiciones para los OA, como la siguiente: es un recurso digital que puede ser reutilizado en diferentes ambientes educativos. Pueden ser cursos, animaciones, cuadros, fotografías, audios, películas, videos y documentos, que tengan objetivos educativos claros [4].
Los OA presentan una serie de características, a saber: Educabilidad: capacidad de generar aprendizaje a partir de su intencionalidad educativa. Usabilidad: facilidad y claridad con las cuales el usuario utiliza el objeto [5]. Interacción: el objeto debe motivar al usuario para generar inquietudes y retomar respuestas sustantivas al aprendizaje [6]. Reutilización: diseñados para ser usados en ambientes y repositorios diferentes al original, sin perder sus propiedades y objetivos [5]. A su vez, se puede crear nuevos objetos a partir de ellos, los cuales pueden ser utilizados en nuevas secuencias educativas.
1.2 REPOSITORIOS DE OBJETOS DE APRENDIZAJE (ROA)
Los ROA son sistemas de software que almacenan recursos educativos y sus metadatos. Dicho en otras palabras, son una gran colección de OA que se estructuran como bases de datos con metadatos asociados y que generalmente se pueden buscar en entornos Web [7]. Los ROA proporcionan algún tipo de interfaz de búsqueda que permite recuperar objetos [8].
Los metadatos son la documentación estandarizada de los detalles que posee un objeto [9]. Los propósitos de los metadatos son ofrecer funcionalidad e interoperatibilidad, además de adaptabilidad, compatibilidad, accesibilidad e interdependencia tecnológicas [10]. El uso de los metadatos facilita su indexación y búsqueda en Internet. Investigaciones recientes indican además, que los metadatos permiten que un OA llegue a un perfil específico de alumno, de acuerdo con su ritmo de aprendizaje, características y necesidades; para ello, se están utilizando técnicas de inteligencia artificial [11].
Algunos ejemplos de ROA comúnmente conocidos son: LoRluMET [12], MERLOT [5], CAREO [13], MyGfl [14], iLumina [15], SMETE [16], HEAL [17], ARIADNE [18], EdNA [19], Lydia [20], IDEA [21], BIOE [22] y CLOE [23], entre otros. Algunos autores consideran que los repositorios son intrínsecos a los OA. Sin embargo, no es posible pensar en OA, si no se los concibe almacenarlos en repositorios. Los objetos aislados no tienen algún significado real.
1.3 SISTEMAS DE RECOMENDACIÓN
Los SR tienen como finalidad, sugerir nuevos ítems o elementos a un usuario, utilizando técnicas de descubrimiento de conocimiento. Los SR se basan en el historial de selecciones anteriores o en selecciones de otros usuarios con similar historial de ratings o valoraciones sobre los mismos ítems o similares [24].
Existen dos procesos para recoger la información para las recomendaciones. El primero se denomina recomendación basada en el contenido. Allí, los algoritmos calculan la similitud de los OA recuperados con los OA indexados en la base de datos. Lo anterior se hace para saber, si éstos son similares en contenido y contexto con aquellos que el usuario ha utilizado últimamente. Este proceso se realiza mediante el análisis de los metadatos del OA, relacionado con el dominio de conocimiento [25]. El otro proceso utilizado es la recomendación basada en las preferencias del usuario, denominada también, como recomendación colaborativa [26]. Este proceso incluye aquellos sistemas que construyen la recomendación como una agregación estadística/probabilística de las preferencias de otros usuarios [27].
1.4 PERCEPCIÓN DEL USUARIO EN ROA
La percepción es un proceso de extracción y selección de información relevante que se encarga de generar un estado de lucidez que nos permite interactuar en forma coherente y racional con el mundo donde vivimos [28]. La percepción determina también, la entrada de información y garantiza que, con la información retomada del ambiente, se puede hacer abstracciones entre las cuales se encuentran los juicios, las categorías y los conceptos, entre otros.
En este caso en particular, para registrar la percepción del usuario se usa la tendencia que tienen los individuos de ver en el mundo, cualidades y totalidades. De esta forma, se maneja una serie de cualidades para cada objeto como lo son: usabilidad, robustez, pertinencia y accesibilidad sobre las cuales el usuario emitirá una serie de juicios valorativos de modo que "califiquen" el objeto evaluado [29]. Cuando el usuario ingresa en el sistema, el repositorio OA le recomienda que hayan sido evaluados por otras personas, de forma similar como el usuario actual evalúa los objetos de su interés.
1.5 TRABAJOS RELACIONADOS
A continuación, se describen algunos trabajos similares relacionados con el diseño planteado en este artículo.
1.5.1 Recomendación de objetos de aprendizaje almacenados en repositorios lor@server según las preferencias del usuario [30].
Este trabajo realizado en 2009 por Machado y Montoyo, trata acerca del desarrollo de un método para la gestión de OA basado en el procesamiento del lenguaje natural (PLN), en ontologías y aplicando un método híbrido de recomendación de OA en ROA. El objetivo es facilitar la gestión personalizada de OA.
Aunque las ontologías proporcionan significado formal y fácil de procesar por el computador, por lo general, los metadatos de los OA carecen de estructura semántica al referirse sólo a descripciones del mismo. Por lo tanto, este trabajo ameritó ajustes en los metadatos para darle significado, dado que las recomendaciones se hacen con base en las búsquedas sobre el dominio del conocimiento de la veterinaria; hecho que en ciertos casos, podría afectar la compatibilidad del sistema con otros similares.
1.5.2 Arquitectura para la recuperación de objetos de aprendizaje de calidad en repositorios distribuidos [31]
Este trabajo se enfoca en la búsqueda automática de OA, mediante el uso de agentes inteligentes (inteligencia artificial), que exploran ontologías realizadas con base en los metadatos [8]. La recuperación de OA se basa en el concepto de calidad que depende de un conjunto de evaluaciones realizadas sobre nueve categorías de metadatos del Learning Object Metadata (LOM), ellos son: título, palabras clave, ámbito, tipo interactividad, tipo de recurso de aprendizaje, nivel de interactividad, densidad semántica, contexto, dificultad y lenguaje.
De esta forma, la valoración de la calidad obtenida se traduce en un número que se adiciona como atributo a los metadatos y permite que los OA sean catalogados en un contexto. Este nuevo descriptor propuesto por los autores, permite incluir la calidad en la gestión de los OA con la definición de ontologías de dominio para su búsqueda y catalogación. De esta forma, la recomendación se basa en los atributos del objeto a modo de evaluación por expertos, pero sin tener en cuenta los gustos del usuario o su experiencia de los mismos de utilizar el OA.
1.5.3 Un sistema multiagente de recuperación de objetos de aprendizaje con atributos de contexto [32]
El propósito de este proyecto es diseñar una arquitectura basada en sistemas multiagente para identificar y recuperar OA relevantes, según la información de entrada suministrada por el usuario. El sistema se basa en seis agentes: interfaz, perfil del usuario, refinador semántico, buscadores, recomendador y mediador. En el sistema de recomendación utilizado, las sugerencias del ROA se realizan, atendiendo la similitud con otros OA que el usuario haya visitado en el pasado.
1.5.4 Sistema interactivo distribuido de repositorios de objetos de aprendizaje matemáticos, SÍNDROME [33].
El sistema SÍNDROME tiene una arquitectura basada en capas y organizada por componentes. Se fundamenta en WebServices de J2EE como mecanismo de acceso a los componentes distribuidos que conforman el sistema. Síndrome fue creado para administrar la búsqueda y recuperación de subconjuntos de OA, a partir de repositorios con colecciones extensas, con base en el estilo individual de aprendizaje del estudiante y en su comportamiento al usar los objetos presentados.
Este es un SR interesante, dado que tiene en cuenta para la recomendación, los estilos de aprendizaje de los usuarios del sistema, lo cual es de gran ayuda en contextos educativos para la gestión de tareas sobre aprendizaje autónomo.
2. METODOLOGÍA
Por sus particularidades el presente trabajo, es una investigación aplicada, dado que ha buscado solucionar un problema mediante la implementación y aplicación de soluciones tecnológicas. El SR se desarrolló para mejorar la búsqueda de OA que realizan los usuarios. Para su implementación, se optó por la tendencia predominante del filtrado colaborativo que se basa en la vecindad próxima (k-nearest neighbors). Inicia con una medida de preferencia de un usuario sobre un ítem. La medida se obtiene de las evaluaciones de preferencias de ítems y/o usuarios similares [34].
Se utilizaron técnicas estadísticas sobre el historial de los ratings o valoraciones que el usuario actual ha realizado sobre los ítems para luego comparar dicho historial con el historial de otros usuarios de similares preferencias y obtener los N ítems que serán recomendados al usuario actual [26].
La otra opción posible, concerniente a los algoritmos basados en modelos no fue tenida en cuenta, dado que este tipo de implementaciones consume demasiados recursos y poder de cómputo. Para finalizar, se validó el SR con minería de datos sobre un grupo de usuarios seleccionados al azar, para determinar la eficacia de las recomendaciones.
2.1 DISEÑO E IMPLEMENTACIÓN DEL SISTEMA DE RECOMENDACIÓN (SR)
El modelo de SR del ROA, utiliza una variación del algoritmo de filtrado colaborativo basado en el vecino más cercano, y se presentó el modelo de recomendación utilizado para este trabajo (figura 1).
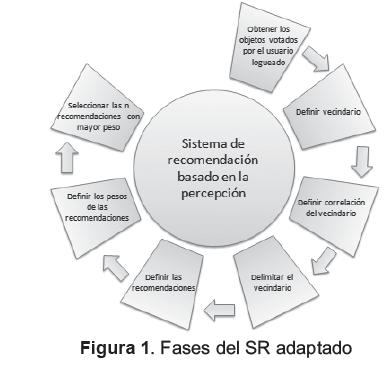
2.2. OBTENCIÓN DE OBJETOS VOTADOS
Inicialmente, se obtienen los votos realizados por el usuario actual (usuario logueado). El sistema cuenta con una base de datos cuyos componentes principales son las tablas de OA, usuarios y evaluaciones, tal y como se muestra en la figura 2.
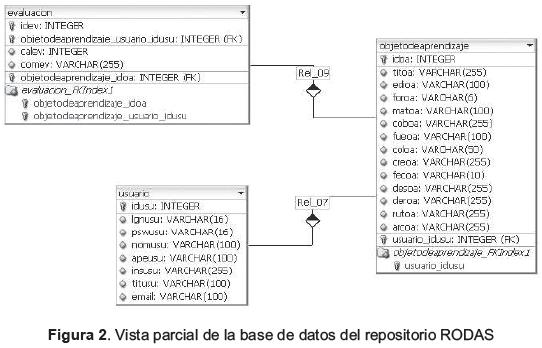
La apreciación de los usuarios sobre la funcionalidad de los objetos al ser usados, se mide con la escala de la tabla 1.

2.3. DEFINICIÓN DEL VECINDARIO
La definición del vecindario consiste en buscar todos los usuarios que votaron por los mismos objetos que el usuario logueado. Ya cargados los datos del usuario que ingresó en el banco, se inicializa el vecindario. El vecindario está constituido por todos los usuarios que tienen un nivel de correlación con el logueado. Se definen [35]:
- vecindario Total: que contiene todos los vecinos relacionados.
- Vecinos Cargados: indica el número de vecinos con los cuales se cuenta para realizar las recomendaciones.
Para una mayor ilustración, se presenta un fragmento de código que realiza el proceso descrito, en la figura 3:

2.4. DEFINICIÓN DE LA CORRELACIÓN DEL VECINDARIO
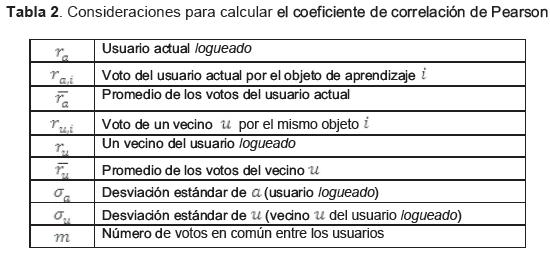
Se definen los pesos para cada usuario con base en el coeficiente de Correlación de Pearson [36]. El coeficiente es un índice que mide el grado de covariación entre distintas variables relacionadas linealmente. Sus valores absolutos oscilan entre 0 y 1 [37]. Dicho coeficiente se usa para determinar el nivel de cercanía o relación entre los usuarios, con respecto de la percepción que éstos tienen de los OA.
En la ecuación (1) el peso 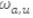 que se asigna al usuario
que se asigna al usuario 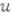 para predecir al usuario actual logueado a viene dado por: ra,i que corresponde a la votación del usuario a al elemento i.
para predecir al usuario actual logueado a viene dado por: ra,i que corresponde a la votación del usuario a al elemento i.
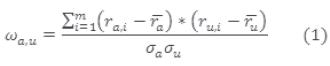
Para calcular el coeficiente de correlación de Pearson [38], se tiene en cuenta las siguientes consideraciones (tabla 2):
La desviación estándar especifica el grado de dispersión de un grupo de datos de su media aritmética. En este caso, determina qué tanto se alejan los votos del usuario sobre los objetos del promedio de votos.
La tendencia de votación del usuario logueado se da por desviación estándar 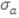 y la tendencia de votación del vecino actual se define por la desviación estándar σu [39]. Dado lo anterior, las respectivas fórmulas para el cálculo serían:
y la tendencia de votación del vecino actual se define por la desviación estándar σu [39]. Dado lo anterior, las respectivas fórmulas para el cálculo serían:
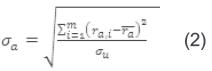
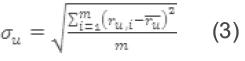
La fórmula anterior calcula la desviación estándar que es igual a la raíz2 de la varianza, si el usuario tiene más de un voto. Si sólo tiene un voto, la desviación es igual al valor votado, y si no ha realizado voto alguno, la desviación estándar es igual al valor máximo que puede tener un voto.
Si la desviación estándar de los votos del vecino por la desviación estándar de los votos del usuario logueado es diferente de cero, se calcula el peso, dividiendo la suma entre el producto de las desviaciones. De lo contrario, el peso del vecino con respecto del usuario logueado es cero.
2.5. DELIMITACIÓN DEL VECINDARIO
Si es muy grande el vecindario, aquellos usuarios que tienen mayor peso se ven opacados por quienes tienen poco peso. De no ocurrir así, se corre el riesgo de que los de menor peso dispersen la correlación con los vecinos de mayor peso [40].
Los pesos asignados a cada vecino del vecindario, se ordenan de forma descendiente según el peso de cada uno, mediante la utilización del método de ordenamiento de burbuja, para luego seleccionar los n primeros [41]. Delimitado el vecindario, se definen los objetos (sin duplicidad), que servirán como recomendaciones, lo cual se logra, sacando todos los objetos que han sido votados por los vecinos y que no hayan sido votados por el usuario logueado.
2.6 DEFINICIÓN DE LAS RECOMENDACIONES
Consiste en encontrar los objetos que hayan sido de interés para los vecinos del usuario logueado y por los cuales se haya realizado una valoración (votación); además, que el usuario logueado no haya valorado aún [42]. Cabe anotar que si dos o más vecinos han valorado el mismo objeto, este se escoge solo una vez.
Luego se obtienen los objetos por los cuales los demás usuarios hayan votado, pero que el usuario logueado no haya votado por ellos.
2.7. DEFINICIÓN DE LOS PESOS DE LAS RECOMENDACIONES
Las valoraciones realizadas a un objeto por los vecinos del usuario logueado y la cantidad de vecinos que hayan valorado dicho objeto, van a definir el peso del objeto o qué tan recomendable es para el usuario logueado. Estas valoraciones se asocian con su desviación estándar para no sesgarlas, según el nivel de optimismo de las valoraciones de los usuarios [34].
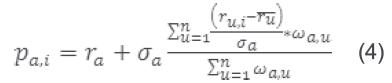
Para calcular el peso de las recomendaciones 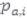 se tiene en cuenta las siguientes consideraciones:
se tiene en cuenta las siguientes consideraciones: 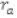 denota al usuario logueado, representa la tendencia de votación del usuario logueado,
denota al usuario logueado, representa la tendencia de votación del usuario logueado, 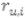 son los votos de un vecino por el mismo objeto i, mientras que
son los votos de un vecino por el mismo objeto i, mientras que 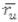 se refiere al promedio de los votos del vecino y el peso asignado al usuario logueado viene dado por
se refiere al promedio de los votos del vecino y el peso asignado al usuario logueado viene dado por
2.8. SELECCIÓN DE LAS RECOMENDACIONES
Las recomendaciones se ordenan por los pesos y se seleccionan los n primeros para sugerirle al usuario logueado (figura 4).
3. IMPLEMENTACIÓN Y VALIDACIÓN DEL MODELO DE RECOMENDACIÓN
3.1 PARADIGMA DE DESARROLLO
El paradigma seleccionado para este proyecto, ha sido el Orientado a Objetos (00), bajo el cual se puede construir sistemas complejos a partir de componentes individuales más sencillos que se denominan objetos. El paradigma 00 se basa en los siguientes conceptos:Objeto. Son representaciones digitales de las entidades de la vida real que poseen datos y operaciones sobre ellos, pero que interesan en la solución de un problema. Los datos se llaman atributos y las operaciones métodos. Los objetos se comunican entre sí, mediante el envío de mensajes.
Clase. Son estructuras de código que funcionan como fábricas de objetos y en ellas, se especifican los atributos y métodos de todos los objetos de la misma clase.
3.2 MODELADO DE CLASES
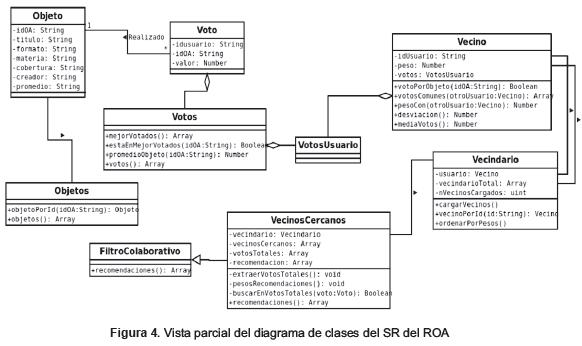
A continuación, se presenta el diagrama de clases que soporta el modelo de recomendación propuesto (figura 4).
En el modelo, existen dos clases básicas sobre las cuales se cimenta el proceso. La primera es la clase Objetos que carga toda la información desde la base de datos de todos los objetos registrados en el banco. Además, permite consultar la información de un objeto específico, utilizando la id del mismo, por medio del método objeto PorID (). A su vez, esta clase permite recuperar todos los objetos registrados, usando el método objetos ().
La otra clase básica es la clase Votos que carga toda la información desde la base de datos de todos los votos registrados sobre los objetos. Además, permite consultar el listado de los objetos mejor votados por medio del método mejor Votados (): Array. Esta clase también permite saber, si un objeto está dentro del listado de los mejor votados por medio del método está En Mejor Votados (idOA: String): Boolean y de igual forma, permite verificar el promedio de votos que ha recibido un objeto por medio del método promedio Objeto (idOA:Stríng):Number Adicional a las clases anteriores, también se usa:
La clase Vecino que define cada usuario que tiene algún grado de relación con el usuario logueado. Este grado de relación se obtiene por medio del método peso Con () que implementa la función 5:
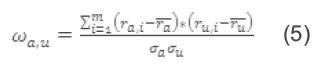
La clase Vecindario contiene un conjunto de vecinos relacionados con el usuario logueado. En esta clase, se hace un proceso de clasificación, en el cual se organizan los vecinos más cercanos al usuario logueado, teniendo en cuenta el peso de cada vecino.
La clase Vecinos Cercanos implementa el Filtro Colaborativo, buscando todas las posibles recomendaciones para el usuario logueado, teniendo en cuenta los votos que hayan recibido de todos los vecinos. También se encarga de definir los pesos de cada posible recomendación, usando la función 6 siguiente:
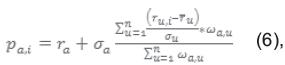 ordenarlas y filtrarlas según dicho peso.
ordenarlas y filtrarlas según dicho peso.
A continuación, se presenta uno de los métodos implementados para la recomendación. En este caso, se trata del cálculo del peso asignado a las recomendaciones para luego ordenarlas. Dichos pesos se guardan en un vector que después, será la base para seleccionar las mejores n para presentarlas al usuario logueado. El algoritmo sigue con fidelidad las ecuaciones descritas en los apartados anteriores.
3.3 SALIDA DE LAS RECOMENDACIONES
El sistema le presenta al usuario actual, las recomendaciones mediante un plug-in en la pestaña "destacados", mostrando al comienzo, cinco objetos. Este plug-in también presenta un pseudosistema de recomendación básico de propósito general como los más visitados y los más votados (figura 5).
El usuario puede ampliar el rango de la recomendación hasta diez objetos. De los anteriores, al lado derecho en el diagrama de barras, se muestra la valoración de dicho OA (figura 6).

Ya sobre la consulta, el usuario puede seleccionar cualquiera de los objetos y luego se presenta su perfil (figura 7).
4. RESULTADOS DE LA PRUEBA DE VALIDACIÓN
Para hacer verificable los objetivos del SR, se trabajó con un ROA que es muy utilizado por los docentes de educación básica primaria y básica secundaria adscritos a la Secretaría de Educación Municipal de Montería - Córdoba, denominado RODAS. De él, se genera un promedio sostenido de 15 descargas diarias de OA y cuenta con 230 usuarios registrados y activos a la fecha, hecho que permitió la verificación del sistema.
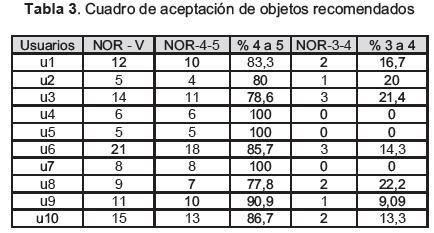
Para validar el SR, se tomaron datos de los diez usuarios con mayor actividad en RODAS, los cuales fueron etiquetados como U={u1,u2,..,u10}. Los datos para el proceso de validación se tomaron durante cinco días, teniendo en cuenta la percepción de usabilidad, accesibilidad y pertinencia que tienen los usuarios acerca de los OA que descargan del repositorio, y que se transforman en una valoración de 1 a 5 que le dan a los mismos.
Los datos agrupados en la tabla 3, en donde, la columna NOR-V representa el número de OA recomendado que fue descargado y valorado por el usuario, mientras que la columna NOR-4-5 representa el número de objetos recomendado y valorado por el usuario entre 4 y 5; Por su parte, NOR-3-4 representa el número de objetos recomendado y que fue valorado por el usuario entre 3 y 4.
En la tabla 3 y la figura 8, se puede observar que en promedio, el 88,3% de las votaciones dadas a los OA recomendados por parte de los usuarios, fue alta (superior a 4), lo cual indica que los objetos recomendados fueron bien valorados por los usuarios, hecho que nos permite decir que las recomendaciones estuvieron acordes con las necesidades del usuario y que el algoritmo propuesto genera una salida acertada para seleccionar la recomendación.
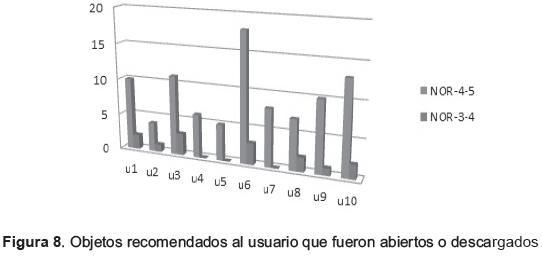
Las barras grises de la figura 8, muestran la cantidad de OA que fueron recomendados y que el usuario observó o descargó, dejando de manifiesto que las recomendaciones se tienen en cuenta por los usuarios en forma muy amplia, y que el algoritmo propuesto relaciona de manera adecuada, los criterios de búsqueda, perfil del usuario y los OA existentes.
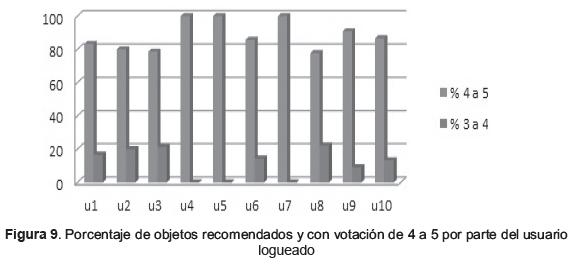
En cuanto a la valoración de los OA recomendados, la figura 9 refuerza la información presentada en la tabla 3. Queda de manifiesto por parte del comportamiento de los usuarios, que las recomendaciones les fueron de utilidad y les permitió explorar el uso de objetos que otros usuarios habían valorado en buena forma. Lo anterior representa un ahorro de tiempo en la búsqueda, puesto que los OA recomendados cuentan con la aceptación en calidad y funcionalidad por parte de quienes los han utilizado y valorado con anterioridad, además de generar cierta confianza por la percepción de calidad que implica el proceso para ser seleccionados como recomendados.
Una vez revisados los datos obtenidos en la validación, se puede considerar que el SR cumplió con las expectativas de recomendaciones de OA relacionadas con la usabilidad, accesibilidad y pertinencia. También, que el algoritmo propuesto es adecuado parar detectar las percepciones de los usuarios vecinos y ofrecerlas con eficacia a los nuevos usuarios, con un ahorro de tiempo y alto nivel de garantía de calidad y confiabilidad.
5. CONCLUSIONES Y RECOMENDACIONES
Luego de desarrollado y validado, se puede concluir que el SR implementado, facilita la aestión oersonalizada v la contextualización de OA a oartir de la Derceoción de usabilidad, accesibilidad y pertinencia que tienen los usuarios acerca de los productos que descargan del repositorio RODAS.
El SR propuesto permite formular recomendaciones de tipo top-N, en el cual los métodos basados en la vecindad, se pueden utilizar de acuerdo con los valores de similitud. El SR está basado en el filtrado colaborativo y ha demostrado que es fácil de implementar, hecho por el cual podría servir como referencia y modelo para otros repositorios cuyos fines sean similares a RODAS.
En la implementación del SR propuesto, la percepción del usuario con respecto de la usabilidad, accesibilidad y pertinencia de los OA, se tradujo en un sistema de valoración por votación de 1 a 5, siendo la base del algoritmo que se transformó en el factor principal para determinar la correlación entre las recomendaciones dadas a los usuarios. Lo anterior permitió mayor confiabilidad en la percepción del usuario final, a diferencia de los sistemas con valoración binaria o por dipolo con rango mínimo o limitado de calificación.
En cuanto a la validación del SR, que se desarrolló con usuarios reales del ROA RODAS, demostró que el 88,3% de los objetos recomendados tuvo una votación alta por parte de los usuarios registrados y que no hubo algún objeto con calificación inferior de tres puntos. Este alto nivel de puntuación nos indica que los objetos les fueron funcionales a los usuarios, y estuvieron acordes con sus necesidades de perfil y búsqueda, demostrando lo acertado del algoritmo propuesto a la hora de recomendar adecuados OA a los usuarios del sistema.
REFERENCIAS BIBLIOGRÁFICAS
[1] Cobos, R., and Pifarré, M. (2008). Collaborative knowledge construction in the web supported by the KnowCat system. In: Computers & Education, Vol. 50, Issue 3, pp. 962-978. [ Links ]
[2] Caro, M. (2007). Proyecto RODAS, repositorio de objetos virtuales de aprendizaje. Informe proyecto de investigación. lUP-España. [ Links ]
[3] IEEE, Learning Technology Standards Committee (LTSC). En: http://www.ieeeltsc.org ( Consulta: junio de 2011). [ Links ]
[4] Vargo J., Nesbit J., and Belfer K. Archambault, (2003). A learning object evaluation: computer mediated collaboration and inter rater reliability. In: International Journal of Computers and Applications Vol. 25 (3). [ Links ]
[5] Sicilia M. Sánchez, S. García, E. and Rodríguez D. (2009). Exploring structural prestige in learning object repositories: some insights from examining references in MERLOT. In: Intelligent Networking and Collaborative Systems, 2009. INCOS '09. International Conference, pp. 212-218. [ Links ]
[6] Polsani, P. (2003). Use and abuse of reusable learning objects. In: Journal of Digital Information, Vol. 3, No 4. [ Links ]
[7] Liu L, He G., Shi X., and Song H. (2007). Metadata extraction based on mutual information in digital libraries. Information Technologies and Applications in Education, 2007. ISITAE '07. In: First IEEE International Symposium, pp. 209-212. [ Links ]
[8] Morales E., Garcia F., and Barrón Á. (2007). Key issues for learning objects evaluation. In: 9th International Conference on Enterprise Information Systems Funchal, Portugal. [ Links ]
[9] Mize J., and Habermann R., (2010). Automating metadata for dynamic dataseis. OCEANS 2010, pp. 1-6, 20-23. [ Links ]
[10] Fillmann C, Gluz J. and Vicari (2011). An agent-based federated Learning object search service. Interdisciplinary Journal of E-learning and Learning Objects. Issue: 7, pp. 37-54. [ Links ]
[11] Gaviria J., Jiménez J., and Arevalo W. (2011). Building virtual learning objects that accomplish today CBR system requirements. In: Software Engineering: Methods, Modeling, and Teaching. Ed. Universidad de Medellín, pp. 125-141. [ Links ]
[12] Maarof M., and Yahya Y. (2008). Learning object repositories interoperability using metadata (LORIUMET). In: Information Technology, 2008. ITSim 2008. International Symposium, vol.3, pp. 1-5, 26-28 Aug. 2008. [ Links ]
[13] Campus Alberta Repository of Educational Objects (2011). (en línea) http://careo.netera.ca/cgibinAA/ebObjects/Repository. (mayo de 2011). [ Links ]
[14] Mygfl (2011). Grdi Pembelajaram Malaysia. En: http://www.mygfl.net.my (mayo de 2011). [ Links ]
[15] Ilumina (2011). Educational Resources for Science and Mathematics. En: http://www.ilumina-dlib.org (Consulta: mayo de 2001). [ Links ]
[16] Smete (2001). Smete Digital Library. En: http://www.smete.org/smete (Consulta: mayo de 2011). [ Links ]
[17] Heal (2011). Health Education Assets Library. En: http://www.healcentral.org/index.jsp (Consulta: mayo de 2011). [ Links ]
[18] Ariadne (2011). European Knowledge Pool System. En: http://www.ariadne-eu.org (Consulta: mayo de2011). [ Links ]
[19] Edna (2011). Educational Network Australia. En: http://www.edna.edu.au (Consulta: mayo de 2011). [ Links ]
[20] Lydia (2011). Lydia Global Repository. En: http://www.lydialearn.com (Consulta: mayo de 2011). [ Links ]
[21] Idea (2011). Interactive Dialogue with Educators froms Across the State. En: http://www.idea.wisconsin.edu (Consulta: mayo de 2011). [ Links ]
[22] Bioe (2011). Banco Internacional de Objetos Educacionais. En: http://objetoeducacionais2.mec.gov.br (Consulta: mayo de 2011). [ Links ]
[23] Cloe (2011). Cooperative Learning Object Exchange. En: http://cloe.on.ca/ (Consulta: abril de 2011). [ Links ]
[24] Ruiz F., Díaz A., Chang H., and Echeverría F., (2006). Sistema de predicción y recomendación personalizada basada en ranqueo de ítems homogéneos usando filtrado colaborativo. In: ACM Communication. [ Links ]
[25] Vallet D., Castells P., Fernández M., Mylonas P., and Avrithis Y. (2007). Personalised content retrieval in context using ontological knowledge. In: IEEE TCSVT, pág. 336-346. [ Links ]
[26] Hua Tsai K., Kai Chiu T., Che Lee M., and I Wang T. (2006). A learning objects recommendation model based on the preference and ontological approaches. ICALT '06 Proceedings of the Sixth IEEE International Conference on Advanced Learning Technologies. Taiwan, pp. 36-40. [ Links ]
[27] García, N., and Montoyo, A. (2008). Recomendación de objetos de aprendizaje almacenados en repositories lor@server según las preferencias del usuario. Departamento de Lenguajes y Sistemas, Universidad de Alicante, España. [ Links ]
[28] Oviedo, G. (2004). La definición del concepto de percepción en psicología con base en la teoría de Gestalt. En: Revista de estudios sociales. No. 18 , pp. 89-96. [ Links ] [ Links ]
[30] Machado N., and Montoyo A. (2008). Recomendación de objetos de aprendizaje almacenados en repositorios lor@server según las preferencias del usuario. Memorias Conferencia Ibero-Americana en Ingeniería e Innovación Tecnológica: CU IT 2009. Estados Unidos. [ Links ]
[31] Morales E., Gil A., and García F. (2007) Arquitectura para la recuperación de objetos de aprendizaje de calidad en repositorios distribuidos. SHCA: Taller en Sistemas Hipermedia Colaborativos y Adaptativos; Actas de los Talleres de JISBD, pp. 31-38, España. [ Links ]
[32] Gil A., and Garda F., (2007). Un sistema multiagente de recuperación de objetos de aprendizaje con atributos de contexto. Memorias Conferencia de la Asociación Española para la Inteligencia Artificial - CAEPIA2007, España. [ Links ]
[33] López G., Briseño J., and Guadalupe M., (2007). Sistema INteractivo Distribuido de Repositorios de Objetos de Aprendizaje Matemático -SÍNDROME. Memorias Quinto Taller sobre Tecnología de Objetos de Aprendizaje. México. [ Links ]
[34] Bell R., and Koren Y., (2007). Scalable collaborative filtering with jointly derived neighborhood interpolation weights. In Proc of. ICDM, 7th IEEE Int. Conf. on Data Mining, USA , pp. 43-52. [ Links ]
[35] Cheng R., and Chen L. (2009). Evaluating probability threshold k-Nearest-neighbor. In: IEEE TC on Data Engineering. USA. [ Links ]
[36] Shakhnarovish D., (2005). Nearest neighbor methods in learning and vision. MIT Press. USA. [ Links ]
[37] Rashid A., Karypis G., and Riedl J. (2006). Influence in ratings-based recommender systems: an algorithm-independent approach. In: Journal of the ACM. [ Links ]
[38] Bregón A., Arancha C, and Rodríguez J. (2005). Un sistema de razonamiento basado en casos para la clasificación de fallos en sistemas dinámicos. Actas del III Taller Nacional de Minería de Datos y Aprendizaje, TAMIDA, pp. 203-211, España. [ Links ]
[39] Ni K., and Nguyen Q. (2009). An adaptable -nearest neighbors algorithm for MMSE image interpolation. IEEE transactions on image processing, Vol. 18, No. 9. USA. [ Links ]
[40] Lathia N., Hailes S., and Capra L, (2009). Temporal recommendations with adaptive neighbourhoods. Computer Science Department - University College, London. [ Links ]
[41] Bela G., Beel J., and Hentschel C, (2009). A research paper recommender system. Proceedings of the International Conference on Emerging Trends in Computing (ICETiC'09), Kamaraj College of Engineering and Technology India, IEEE, pp. 309-315, USA. [ Links ]
[42] Lemire D., and Maclachlan A., (2005). One predictors for online rating based collaborative filtering. Secure Data Management - SDM05. Norway. [ Links ]

