










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkCiencia e Ingeniería Neogranadina
Print version ISSN 0124-8170
Cienc. Ing. Neogranad. vol.25 no.2 Bogotá July/Dec. 2015
https://doi.org/10.15665/re.v13i1.348
DOI: http://dx.doi.org/10.15665/re.v13i1.348
MODELO BASADO EN FACTORES Y REGLAS PARA CUANTIFICAR LA AFINIDAD ENTRE LOS INDIVIDUOS DE UN GRUPO HUMANO
A MODEL BASED ON FACTORS AND RULES TO QUANTIFY THE AFFINITY AMONG THE INDIVIDUALS OF A HUMAN GROUP
Juan Felipe Calvache1, Sergio Andrés Pérez2, Francisco Javier Moreno3
1 Ingeniero de Sistemas, Universidad Nacional de Colombia sede Medellín, Medellín, Colombia, jfcalvacheg@unal.edu.co
2 Ingeniero de Sistemas, Universidad Nacional de Colombia sede Medellín, Medellín, Colombia, seaperezpe@unal.edu.co
3 Ingeniero de Sistemas, Phd en Ingeniería, Profesor Asociado, Universidad Nacional de Colombia sede Medellín, Medellín, Colombia, fjmoreno@unal.edu.co
Fecha de recepción: 27 de Septiembre de 2014 Fecha de aprobación: 22 de Julio de 2015
Referencia: J.F. Calvache, S.A. Pérez, F.J. Moreno. (2015). Reglas para cuantificar la afinidad entre los individuos de un grupo humano. Ciencia e Ingeniería Neogranadina, 25 (2), pp. 117 - 136, DOI: http://dx.doi.org/10.18359/rcin.1435
RESUMEN
En este artículo se propone un modelo para cuantificar el grado de afinidad entre los individuos de un grupo humano. Para obtener el grado de afinidad se considera un conjunto de factores y de reglas (para cada factor) definidos por el analista. El modelo se puede aplicar prácticamente a cualquier grupo humano: estudiantes, trabajadores, miembros de una red social, etc. Para validar y mostrar la utilidad del modelo, se analizaron dos grupos de estudiantes de cursos universitarios. Los datos de los estudiantes, correspondientes a los factores definidos para los experimentos, se recopilaron mediante una encuesta que fue diseñada para tal efecto. Aunque se requieren experimentos más exhaustivos, los resultados evidenciaron posibles patrones; e.g., los grupos de estudiantes con mayor grado de afinidad fueron los de mayor calificación promedio grupal. También se observó que existen ciertos individuos que tienden a ser miembros de los grupos más afines y otros que tienden a ser miembros de los grupos menos afines.
Palabras clave: Afinidad, Comunidades, Grupos Humanos, Redes Sociales, Relaciones Sociales.
ABSTRACT
In this paper we propose a model to quantify the degree of affinity among the individuals of a human group. To obtain the degree of affinity, our model considers a set of factors and a set of rules (for each factor) which are defined by the analyst. Our model can be virtually applied to any human group: students, employees, members of a social network, etc. To validate and show the expediency of our model, we analyzed two groups of university courses. The students' data, corresponding to the factors identified for the experiments, were collected using a survey that was designed for this purpose. Although more extensive experiments are required, our results showed possible patterns, e.g., the groups of students with higher affinity were the groups with the highest average grades. It was also noted that there are certain individuals who tend to be members of the higher affinity groups and some who tend to be members of the lowest affinity groups.
Keywords: Affinity, Communities, Human Groups, Social Networks, Social Relationships.
INTRODUCCIÓN
En este artículo se propone un modelo para cuantificar el grado de afinidad entre los individuos de un grupo humano considerando sus preferencias personales y elementos en común de acuerdo con el contexto cultural, social y geográfico en el que se encuentren.
La noción de afinidad en grupos humanos ha tenido diversas aproximaciones. En [1] se propone un modelo para conformar equipos de trabajo. Los individuos se agrupan de acuerdo con un conjunto de criterios preestablecidos que incluyen el género, temas de interés, áreas de trabajo, tipos de proyectos en los que han participado, tipos de tareas que prefieren hacer, entre otros. Algunos de estos datos son extraídos de Facebook y Linkedln, y otros son capturados por medio de un aplicativo diseñado por los autores. Sin embargo, el modelo no considera ciertos aspectos que influyen en las relaciones humanas, como tipos de personalidad, ubicación geográfica, tendencias políticas y religiosas, entre otros.
Panigrahy [2] y Bapna [3] enfocan su trabajo a las redes sociales. Panigrahy propone una medida que considera el número de caminos disjuntos que existen entre un par de nodos para calcular la afinidad entre los usuarios de la red. Esta medida de afinidad representa la probabilidad de que un par dado de nodos permanezcan conectados cuando se elimina una parte de la red. Por su parte, Bapna propone un modelo basado en la confianza que tiene una persona en otra. Se proponen tres medidas: i) la intimidad, i.e., el número de amigos comunes entre dos personas, ii) la intensidad, i.e., el número de publicaciones en el muro (wall) intercambiados entre dos personas, y iii) el número de fotos etiquetadas (photos tagged), i.e., el número de fotos en las que se etiqueta el remitente en la foto del receptor o viceversa.
Por otro lado, en [4] se analizan las afinidades positivas y negativas en una red social. Cada individuo (denominado actor) tiene un conjunto de preferencias y de afinidades positivas y negativas con respecto a los otros actores. Con base en estos elementos, se propone un modelo probabilístico de relaciones entre los actores y se concluye que la probabilidad de una relación es mayor si se percibe reciprocidad entre los actores.
En [5] se analizan las afinidades implícitas y explícitas en una red de individuos. Las afinidades explícitas surgen de las conexiones explícitas de los individuos en la red, y las implícitas surgen naturalmente a partir del comportamiento y actitudes de los individuos. Los autores plantean una medida de afinidad de los individuos basados en el número de valores (y no en factores y reglas ponderadas, como se propone aquí) compartidos en sus atributos.
En [6] se presenta un modelo para distribuir y organizar a los trabajadores de una empresa considerando los factores de compatibilidad de los individuos. Estos factores incluyen la disposición y facilidad para trabajar en equipo, la seguridad, la responsabilidad, la autoestima y la sinceridad. Eaglea [7] propone un modelo para deducir relaciones de amistad a partir de un sistema de telefonía (celulares).
Según Zhang y Dantu [8] las relaciones sociales cambian con el tiempo. Los autores proponen medir un índice de reciprocidad, el cual se obtiene a partir del registro de llamadas telefónicas entre los usuarios y se aplica el modelo Arima (Autoregressive Integrated Moving Average, un modelo estadístico usado en estadística y econometría) [9] para analizar las relaciones sociales durante un periodo. Por otro lado, en [10] se propone un sistema recomendador de películas basado en una red social donde se analizan las relaciones entre los usuarios y se generan valores de afinidad grupales a partir de los perfiles de estos.
El modelo aquí propuesto soporta distintos factores que podrían influir en las relaciones de los individuos. Estos factores son definidos por el analista, i.e., no están predeterminados en el modelo a diferencia de los trabajos descritos. El modelo también permite tantas reglas (asociadas con cada factor) como el analista considere pertinentes para determinar el valor que tiene cada factor definido. Además, el modelo se puede aplicar a cualquier grupo humano, e.g., los estudiantes de un curso, los trabajadores de una empresa, los jugadores de un equipo, i.e., no solo a grupos enmarcados en el contexto de las redes sociales [11-12].
El artículo está organizado de la siguiente manera. En la primera sección se presenta el modelo para afinidad de dos individuos y su correspondiente extensión para grupos de más de dos individuos. En la segunda sección se presentan los experimentos y su análisis. En la tercera sección se presentan las conclusiones y se plantean trabajos futuros.
1. MODELO PROPUESTO
1.1 DEFINICIÓN DEL MODELO
El objetivo del modelo es cuantificar el grado de afinidad entre los individuos de un grupo humano de acuerdo con un conjunto de factores y reglas (asociadas con cada factor) definidas por el analista. Por ejemplo, el analista podría considerar factores como la música, la ubicación geográfica, el idioma, las tendencias políticas, religiosas y culturales [13-14]. Un ejemplo de una regla para el factor música puede ser: "si el género musical de dos individuos es el mismo, entonces el valor de su afinidad es 1, 0 de lo contrario".
Se define una matriz simétrica de afinidad A para n individuos de un grupo humano, como se muestra en la figura 1.

Donde aij representa el grado de afinidad entre los individuos i y j. Si i = j, entonces aij = 0. Para calcular el valor de cada aij se aplica la ecuación (1).
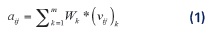
Donde Wk , 0 < Wk ≤1, es el peso asignado por el analista al factor k y (vij)k representa el valor de afinidad para los individuos i y j en el factor k. Por lo tanto, aij es el resultado de ponderar un conjunto de m factores definidos por el analista. Además, se debe cumplir la restricción de la ecuación (2).

A su vez, (vij)k es el resultado de ponderar un conjunto de z reglas y se calcula mediante la ecuación (3).

Donde pq, 0 < pq ≤1, es el peso asignado por el analista a la regla q y (rij)q es el valor de afinidad para los individuos i y j en la regla q. Además, se debe cumplir la restricción de la ecuación (4).

Por ejemplo, un analista podría definir los valores para una regla q así:

1.1.1 Ejemplo
A continuación se calculará la matriz de afinidad A para cuatro individuos (numerados del 1 al 4). Se consideran tres factores (m = 3): 1. Música, 2. Ubicación geográfica y 3. Tendencia política, véase la tabla 1.
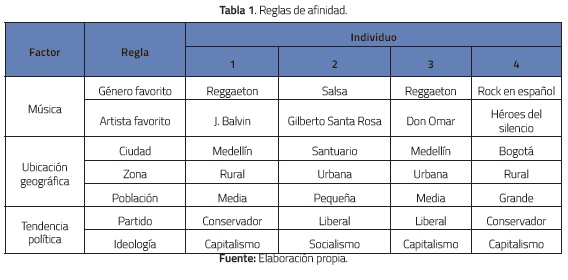
1.1.2 Reglas para el factor música
Se consideran dos reglas (z = 2) para este factor: 1. Género favorito y 2. Artista favorito:
- (rij)Género_favorito = 1 si el género favorito de la música es igual, 0 de lo contrario.
- (rij)Artista_favorito = 1 si el artista favorito es el mismo, 0.5 si los dos individuos tienen el mismo género musical y el artista favorito de cada individuo pertenece a ese género, 0.3 si los dos individuos tienen diferente género musical y el artista favorito de cada individuo ha interpretado al menos una canción de esos dos géneros, 0 de lo contrario.
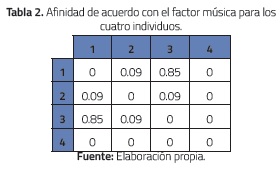
Los pesos son pGénero_favorito = 0.7 y pArtista_favorito = 0.3. Con estos valores se obtienen los valores de la tabla 2. Por ejemplo, (v12)Música= 0.7*0+0.3*0.3=0.09.
1.1.3 Reglas para el factor ubicación geográfica
Se consideran tres reglas (z = 3) para este factor: 1. Ciudad, 2. Zona y 3. Población:
- (rij)Ciudad = 1 si las dos personas viven en la misma ciudad, 0.7 si viven a una distancia menor a 30 km la una de la otra, 0.4 si viven a una distancia menor a 70 km la una de otra, 0 de lo contrario.
- (rij)Zona = 1 si las dos personas viven en zona urbana, 0.5 si viven en zona rural, 0 de lo contrario.
- (rij)Población = 1 si las dos personas viven en la misma ciudad y la población es pequeña (menos de 100 mil habitantes), 0.5 si viven en la misma ciudad y la población es media (entre 100 mil y un millón de habitantes), 0.2 si viven en la misma ciudad y la población es grande (más de un millón de habitantes), 0 de lo contrario.
Los pesos son PCiudad = 0.5, PZona = 0.3 y PPoblación = 0.2. Con estos valores se obtienen los valores de la tabla 3.

1.1.4 Reglas para el factor tendencia política
Se consideran dos reglas (z = 2) para este factor: 1. Partido y 2. Ideología:
- (rij)Partido = 1 si el partido político es el mismo, 0 de lo contrario.
- (rij)Ideología = 1 si la ideología es la misma, 0 de lo contrario.
Los pesos son PPartido = 0.8 y PIdeología = 0.2. Con estos valores se obtienen los valores de la tabla 4.

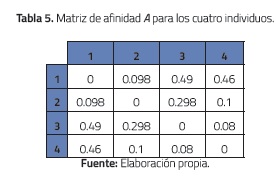
Finalmente, para calcular la matriz de afinidad A se consideran los siguientes pesos para cada factor: WMúsica = 0.2, WUbicación_gepgráfica = 0.4 y WTendencia_política = 0.4. Con estos valores se obtienen los valores de la Tabla 5. Por ejemplo, a12= 0.2*0.09+0.4*0.2+0.2+0.4*0=0.098.
Nótese que el modelo es flexible, ya que permite que el analista defina el número de factores, el número de reglas de cada factor y los valores de los pesos de cada factor y de cada regla.
1.2 EXTENSIÓN DEL MODELO PARA EL CÁLCULO DE AFINIDAD PARA MÁS DE DOS INDIVIDUOS
Para calcular la afinidad, e.g., de un conjunto de cuatro individuos G = {1,2,3,4}, se considera el nivel de afinidad de cada pareja (compuesta por individuos distintos) que se puede formar a partir del conjunto G. Se suman las afinidades de todas las parejas y se divide entre el número total de estas (seis en este ejemplo).
Sea P el conjunto de todas las parejas (i, j), i ? j, de individuos que se pueden formar a partir del conjunto G. La cardinalidad de P es Card (P) = Combinaciones (2, n), i.e., combinaciones de 2 en n, donde n = Card (G). Para el ejemplo, P = {(1,2), (1,3), (1,4), (2,3), (2,4), (3,4)}, Card(P) = Combinaciones(2, 4) = 6.
Sea Afinidad una función con signatura: P→[0;1], i.e., la función recibe una pareja (i, j) y devuelve su valor de afinidad (un número entre 0 y 1). El valor de afinidad de una pareja (i, j) se calcula de acuerdo con la ecuación (1). Entonces el valor de afinidad del conjunto G se calcula mediante la ecuación (5).
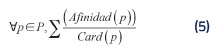
Con el fin de comparar el modelo propuesto con otras alternativas, se presenta a continuación una opción basada en clustering (agrupamiento). Considérese la matriz de afinidad A de la figura 1. Esta matriz se puede representar como un grafo no dirigido ponderado donde los vértices representan los individuos y αij(grado de afinidad) corresponde al peso asociado con la arista que conecta a los vértices i y j. Para n = 4 el grafo se muestra en la figura 2.
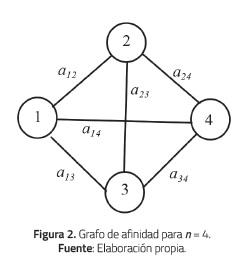
Con el fin de aplicar un método de clustering se presenta a continuación la forma general del algoritmo de clustering jerárquico [15].
Algoritmo de clustering jerárquico (forma general)
WHILE condición de fin de generación de clusters no se satisfaga DO
- Seleccionar los dos "mejores" clusters a juntar;
- Formar un nuevo cluster con los dos clusters seleccionados;
END WHILE;
Para cada problema particular se debe definir: a) la condición de fin de generación de clusters, y b) el método para seleccionar los dos "mejores" clusters a juntar. La condición de fin puede ser, e.g., terminar cuando se haya obtenido un número específico de clusters o cuando el próximo cluster a formarse es inadecuado (e.g., la distancia promedio entre sus miembros supera un umbral establecido por el analista). En cuanto al método para seleccionar los dos mejores clusters a juntar existen muchas variantes, e.g., seleccionar la pareja de clusters que tienen la menor distancia entre sus centroides o la pareja de clusters que genera el cluster con el menor radio (el radio de un cluster es la máxima distancia entre todos sus miembros y el centroide del cluster); si se presentan empates se decide arbitrariamente.
Para nuestro caso de estudio, el objetivo es agrupar los individuos según su grado de afinidad. Es decir, mientras el grado de afinidad entre dos individuos i y j sea mayor (tiende aija 1), se considera que los individuos son más cercanos. Por tanto, para el algoritmo de clustering se tomará (1-aij) como la distancia entre dos individuos. Por otro lado, el algoritmo terminará (condición de fin) cuando se haya obtenido un número específico de clusters; ya que para nuestro primer experimento (ver segunda sección) se solicitó a los estudiantes de los cursos examinados que conformaran grupos de entre dos y tres integrantes, lo cual determinará el número de clusters y con los cuales se comparará según los grupos (clusters) generados por el algoritmo de clustering.
El otro aspecto a definir es el método para seleccionar los dos "mejores" clusters a juntar. Inicialmente se tienen n clusters (cada individuo forma un cluster). Supongáse que los individuos i y j tienen la menor distancia (1-aij) entre todos los clusters. Por tanto, en la siguiente iteración habrá n-1 clusters con i y j conformando un nuevo cluster. El problema es definir el centroide del cluster conformado por i y j con el fin de establecer la distancia de este cluster hacia los demás en la siguiente iteración. Una solución es seleccionar el centroide como el miembro del cluster que minimiza la suma de las distancias a los otros puntos del cluster [15] (si el cluster solo tiene dos miembros la elección es arbitraria). Otras propuestas para seleccionar el centroide se exploran en dicha referencia: el problema en esencia es seleccionar un miembro del cluster como su miembro representativo (en general, denominado clustroid) y con base en él establecer las distancias a los demás clusters para seleccionar la próxima pareja de clusters que se deben juntar. En la figura 3 se bosqueja el proceso para un grafo de cuatro individuos.
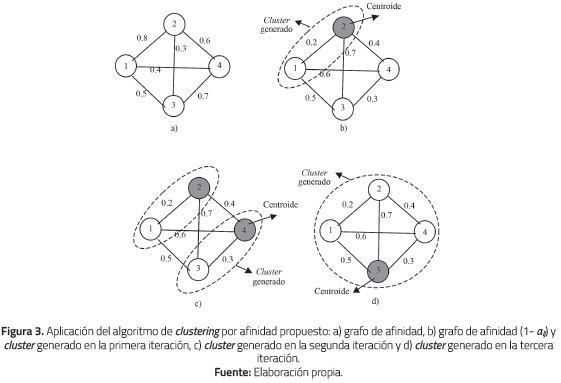
En la primera iteración, figura 1 b), los individuos que tienen la menor distancia (0.2) son el 1 y el 2; por tanto, se genera un cluster con estos dos nodos. Como la distancia de 1 a 2 es la misma que de 2 a 1, se elige arbitrariamente cualquiera de los dos nodos como el centroide del cluster (acá se eligió el nodo 2). En la segunda iteración, figura 1 c), los individuos que tienen la menor distancia (0.3) son el 3 y el 4; por tanto, se genera un cluster con estos dos nodos y se elige arbitrariamente como centroide el nodo 3. Si se continúa el algoritmo, en la tercera iteración, figura 1 d), la distancia entre los dos clusters es 0.4 (distancia entre los centroides de los dos clusters); se genera un cluster con todos los nodos del grafo. Nótese que el centroide de este cluster no es arbitrario: como el cluster tiene más de dos miembros, entonces se encuentra que el miembro que minimiza la suma de las distancias a los otros miembros del cluster es el 3 (0.5 + 0.7 + 0.3 = 1.5).
Nótese que al aplicar un algoritmo de clustering con base en el grado de afinidad, tal y cómo se ha propuesto, puede ocurrir lo siguiente. Supongáse que
-en la primera iteración los individuos i y j tienen la menor distancia (1-aij) entre todos los clusters. En la figura 3, los nodos 1 y 2.
-en la segunda iteración los individuos p y q tienen la menor distancia (1-apq) entre todos los clusters. En la figura 3, los nodos 3 y 4.
-en la tercera iteración los clusters conformados por (i, j) y (p, q) tienen la menor distancia entre todos los clusters. Es decir, se forma un cluster (i, j, p, q). En la figura 3, los nodos 1, 2, 3 y 4.
De esta forma, el cluster resultante está conformado por dos subclusters cada uno con alta afinidad; sin embargo, esto no garantiza que la afinidad del cluster resultante sea alta. Por ejemplo, i y j podrían ser altamente afines porque viven en zona urbana, mientras que p y q podrían ser altamente afines porque viven en zona rural. Por otro lado, estos cuatro individuos podrían ser afines en otras características y el alto nivel de afinidad de las parejas puede contribuir a un nivel de afinidad entre los cuatros individuos, i.e., afinidad entre los más afines así haya aspectos en los que puede haber posiciones opuestas entre los subclusters, lo que incluso puede llegar a ser beneficioso para el desempeño del grupo [16]. Aunque esto también se manifiesta en nuestro método, como se evidencia en la ecuación (5): allí se calcula la afinidad de un grupo con base en el promedio de las afinidades de todas las parejas que lo conforman.
Otra diferencia con nuestro método es que el algoritmo de clustering no garantiza la generación de clusters donde cada uno tiene un mínimo y un máximo número de miembros. De esta forma, si se requieren, e.g., 18 grupos cada uno con un mínimo de dos y un máximo de tres miembros, el algoritmo de clustering generará 18 clusters pero algunos podrían tener, e.g., uno, dos, tres, cuatro o más miembros.
2. EXPERIMENTOS
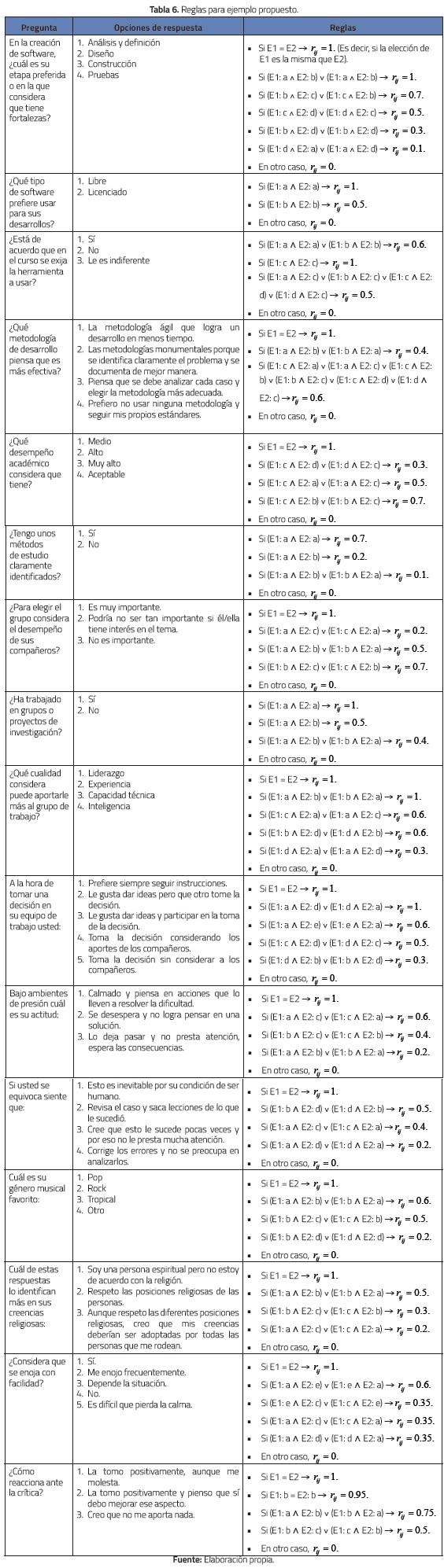
Para los experimentos se consideraron dos grupos de estudiantes correspondientes a dos cursos universitarios de ingeniería de sistemas de los últimos semestres. El primero de 60 estudiantes y el segundo de 50 estudiantes. Se consideraron 4 (m) factores para evaluar su afinidad: i) el aspecto técnico, ii) el aspecto académico, iii) las cualidades grupales, y iv) las cualidades individuales. Para los cuatros factores se usó el mismo peso (0.25). Para la obtención de los datos de los estudiantes se aplicó la encuesta que se muestra en la tabla 6; allí también se muestran las reglas que se consideraron (E1 y E2 representan estudiantes).
En un primer experimento se consideraron los dos cursos. En ambos cursos, al principio del semestre académico se solicitó a los estudiantes que conformaran grupos de entre dos y tres integrantes. Cada estudiante solo pertenece a un grupo, y cada uno elige libremente a sus compañeros de grupo (ningún estudiante está en ambos cursos, de hecho el primer curso es requisito del segundo). El total de grupos fue de 22 en el primer curso y 19 en el segundo. Al final del semestre se comparó la afinidad de cada grupo (calculada mediante la ecuación 5) con la calificación grupal promedio obtenida en el curso (calificación obtenida mediante evaluaciones grupales).
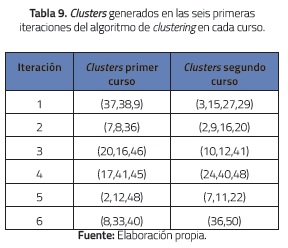
Con el fin de comparar la propuesta con la afinidad percibida por los integrantes de cada grupo, al final del semestre también se solicitó a cada integrante de cada grupo que calificase, según su experiencia vivida durante el curso, el grado de afinidad (entre 0 y 1) del grupo en cada uno de los 4 factores. Los resultados se promediaron y se obtuvo un nivel de afinidad percibido. En las tablas 7 y 8 se presentan los resultados obtenidos para 10 grupos de cada curso. Se presentan los 5 grupos con calificación más alta y los 5 con calificación más baja. Por otro lado, en la tabla 9 se presentan los resultados del algoritmo de clustering (los seis clusters con afinidad promedio más alta: la afinidad de cada cluster se calculó promediando las afinidades entre sus miembros). Con el fin de facilitar las comparaciones, la condición de fin de generación de clusters fue el número de grupos formado por los estudiantes en cada curso (22 en el primero y 19 en el segundo).
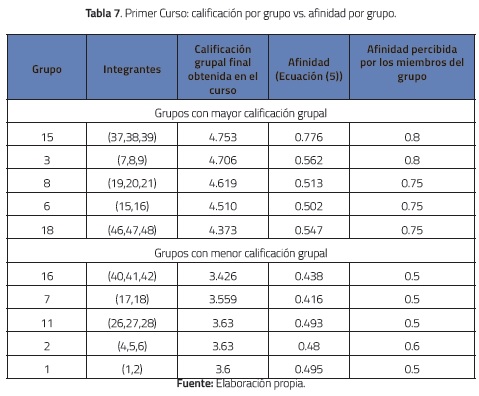

Aunque los resultados no son concluyentes, sí es al menos sugerente que los grupos con mayor afinidad (según la ecuación 5) son los que obtuvieron en general las mayores calificaciones grupales promedio. De hecho, en el primer curso los cinco grupos (y en el segundo curso los dos grupos) con mayor calificación grupal fueron precisamente los grupos con mayor afinidad. Esto sugiere que la afinidad de los individuos puede contribuir a un mejor desempeño grupal. En cuanto a la afinidad percibida, también es significativo que los grupos que se autocalificaron como los más afines, tendieron a obtener las calificaciones más altas mientras que los que se autocalificaron como los menos afines, efectivamente tendieron a obtener las calificaciones más bajas. Por otro lado, la afinidad percibida tiende a ser más alta que la afinidad calculada por el método propuesto. Esto se puede deber a que los individuos de cada grupo se conocían de otros cursos, i.e., ya habían establecido lazos de amistad lo que contribuyó a que tuviesen una apreciación alta con respecto a su afinidad grupal.
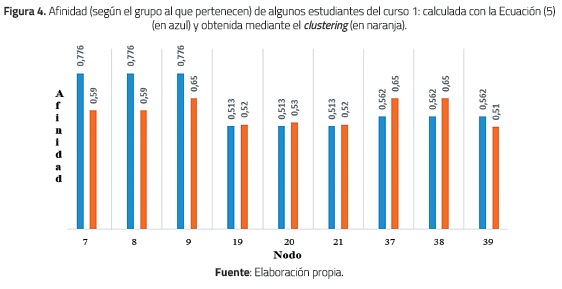
En cuanto a los resultados generados por el algoritmo de clustering e.g., para el primer curso en su cluster con afinidad promedio más alta (37, 38, 9) se observa que todos sus miembros se encuentran entre los cinco primeros grupos de mayor afinidad obtenidos con el método propuesto (ecuación 5). Esto sugiere al menos que los dos métodos identifican ciertos individuos que contribuyen en los grupos más afines. En la figura 4 se compara la afinidad (calculada con la ecuación 5) de los miembros de los tres grupos con mayor calificación grupal vs. la afinidad de estos miembros según la afinidad obtenida mediante el clustering. Por otro lado, en el segundo curso, en su cluster con mayor afinidad promedio (3, 15, 27, 29) se observa que ninguno de sus miembros se encuentra entre los cinco primeros grupos de mayor afinidad obtenidos con el método propuesto. Esto es sugerente y pone de manifiesto la diferencia de los dos métodos. Esto se explica porque la pareja (3, 27) es la de mayor afinidad en el segundo curso (véase la tabla 11), por ello el algoritmo de clustering la incluye en un cluster en la primera iteración y en posteriores iteraciones la une con los miembros 3 y 29. En conclusión, los métodos generan resultados distintos y no se garantiza que los individuos incluidos en los grupos más afines de uno también figuren como miembros de los grupos más afines del otro método.
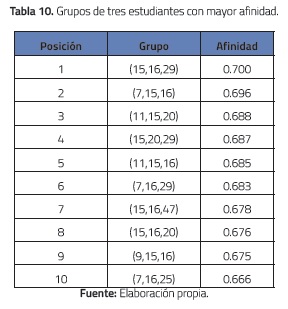
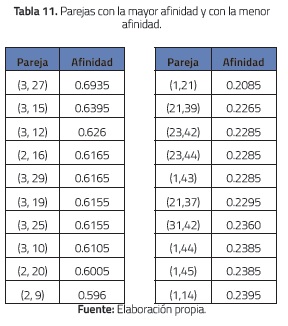
En un segundo experimento se calculó la afinidad para todos los grupos de tres estudiantes distintos que se pueden formar a partir del grupo de 50 estudiantes del segundo curso. En la tabla 10 se presentan los diez grupos con mayor afinidad. Nótese que los estudiantes con códigos 15 y 16 aparecen en ocho de estos diez grupos. Esto sugiere que son individuos con un alto nivel de afinidad (de hecho, el grupo con mayor afinidad incluye a estos dos estudiantes). Sin embargo, su afinidad como pareja no está entre las diez parejas con mayor afinidad (véase tabla 11). Por otro lado, la pareja conformada por los estudiantes 3 y 27 que posee la mayor afinidad (véase tabla 11), no aparece en ninguno de los diez grupos más afines de tres estudiantes de la tabla 10.
También se calculó la afinidad para todos los grupos de cuatro estudiantes distintos que se pueden formar a partir del grupo de 50 estudiantes. En la tabla 12 se presentan los diez grupos con mayor afinidad. Similarmente al caso anterior (grupos de tres estudiantes), se observó que los estudiantes 15 y 16 aparecen en la mayoría de estos grupos (de hecho, el estudiante 15 aparece en todos los grupos y el 16 en ocho de los diez grupos).
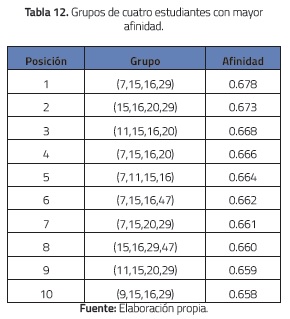
Para los grupos de cinco estudiantes, ver la tabla 13, los resultados mostraron el mismo comportamiento (de nuevo los estudiantes 15 y 16 aparecen en la mayoría de los grupos). Nótese, además, que los valores de afinidad de la tabla 13 son menores que los de las tablas 11 y 12; esto es razonable, ya que a medida que los grupos tienen más integrantes, existirán más diferencias entre ellos.
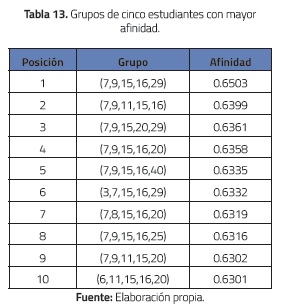
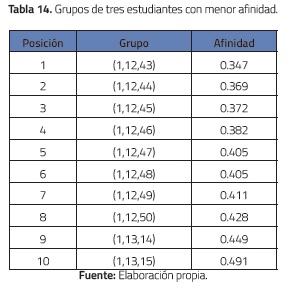
Con respecto a los diez grupos con menor afinidad, se puede observar un comportamiento análogo al de los grupos más afines, e.g., el individuo 1 aparece en todos los grupos de 3, 4 y 5 estudiantes, ver tablas 14, 15 y 16.
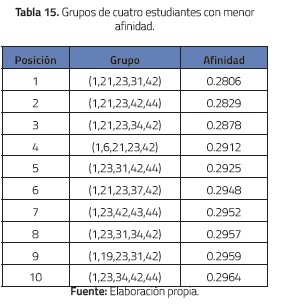
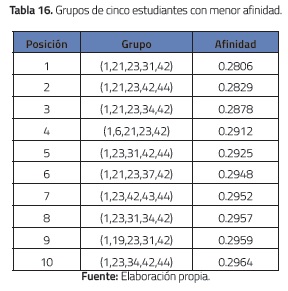
Estos mismos experimentos se hicieron con el grupo de estudiantes del primer curso y se obtuvieron resultados similares.
3. CONCLUSIONES Y TRABAJO FUTURO
En este artículo se propuso un modelo matemático para cuantificar el grado de afinidad entre los individuos de un grupo humano. Inicialmente, el modelo cuantifica el grado de afinidad entre dos individuos y luego se extiende para calcularlo para más de dos individuos. Para obtener el grado de afinidad, el modelo considera factores y reglas para cada factor. Una de las ventajas del modelo es que el analista puede especificar el número de factores y asociar con cada factor el número de reglas que desee. Además, puede especificar los pesos para cada factor y para cada regla de acuerdo con sus intereses. Esto hace que el modelo sea flexible y que se pueda aplicar prácticamente a cualquier grupo humano: estudiantes, trabajadores, miembros de una red social, etc.
Los experimentos se hicieron con dos cursos de estudiantes universitarios, uno de 60 estudiantes y el otro de 50. Los resultados indicaron que los grupos con mayor grado de afinidad fueron los de mayor calificación promedio grupal. En otro de los experimentos se analizó el grado de afinidad de todos los grupos que se pueden formar con 3, 4 y 5 estudiantes a partir del curso de 50 estudiantes. Se observó que existen ciertos individuos que regularmente conforman los grupos más afines. Los resultados también mostraron que a medida que los grupos tienen más individuos, el grado de afinidad tiende a bajar con respecto a los grupos con menos individuos. Esto es razonable, ya que mientras más grandes sean los grupos más diferencias se pueden encontrar entre los individuos.
Como trabajos futuros se tienen planeados los siguientes: i) automatizar la recolección de datos para los factores y reglas. En este trabajo se usó una encuesta (ver tabla 6); sin embargo, esta labor es tediosa para los usuarios y los analistas. La idea es desarrollar un aplicativo que recopile automáticamente los datos de los individuos correspondientes a los factores definidos por el analista. El aplicativo debería permitir que el analista especifique los factores, reglas y las fuentes de datos (e.g., una red social, una base de datos), ii) analizar cuáles son los rasgos que caracterizan a los individuos que suelen contribuir en mayor/menor medida con el grado de afinidad de los grupos y ver si es posible promover/aminorar estos rasgos en otros individuos, iii) determinar, con base en su grado de afinidad, cuál es el número apropiado de individuos para desarrollar una determinada tarea, iv) analizar aspectos de discriminación en grupos [17] y cómo maximizar la influencia de un grupo en una comunidad [18], v) automatizar la asignación de los valores para los rij, e.g., una asignación automática podría ser rij = 1 si los individuos comparten el mismo valor de una regla dada y rij = 0, de lo contrario. Sin embargo, estos valores se podrían refinar dependiendo de cada regla, de sus valores y de los objetivos de los analistas, y vi) extender medidas de similitud entre dos vertices, tales como las basadas en caminos aleatorios (random walks) [19] para obtener la afinidad de grupos y compararlo con el método aquí propuesto. Un trabajo análogo se puede hacer con grafos de afinidad y con otros algoritmos de clustering. Un punto de partida es el trabajo de Liu [20].
AGRADECIMIENTOS
Los autores desean expresar sus agradecimientos a los profesores Jesús Antonio Hernández y Jaime Guzmán Luna, de la Universidad Nacional, sede Medellín, por sus valiosos comentarios sobre el modelo propuesto. También al profesor Fernando Sánchez Lasheras, de la Universidad de Oviedo, por sus aportes en la parte de clustering.
BIBLIOGRAFÍA
[1] Molina, F., Loyola, P., Velásquez, J. D., (2010). Generación de equipos de trabajo mediante análisis de redes sociales e identificación de atributos personales. En: Revista Ingeniería de Sistemas, Vol. 14 (1), pp. 103-122. [ Links ]
[2] Panigrahy, R., Najork, M., Xie, Y. (2012). How User Behavior is Related to Social Affinity. En: 5th ACM International Conference on Web Search and Data Mining (WSDM). [ Links ]
[3] Bapna, R., Gupta, A., Rice, S., Sundararajan, A. (2011). Trust, Reciprocity and the Strength of Social Ties: An Online Social Network based Field Experiment. En: Conference on Information Systems and Technology (CIST). [ Links ]
[4] Chung-Chien, H., Medhin, N. (2006). Positive and Negative Affinities Model For Social Networks. En: Department of Mathematics, 3rd International Conference on Neural, Parallel and Scientific Computations. [ Links ]
[5] Smith, M., Giraud-Carrier, C., Purser, N. (2009). Implicit affinity networks and social capital. En: Journal Information Technology and Management, Vol. (2-3), pp. 123-134. [ Links ]
[6] Gil, J. (2007). La idónea agrupación de trabajadores según grados de compatibilidad psicológica. En: Asociación Española de Dirección y Economía de la Empresa (Aedem). [ Links ]
[7] Eaglea, N., Pentlandb, A., Lazerc, D. (2009). Inferring friendship network structure by using mobile phone data MIT Media Laboratory. En: Proceedings of the National Academy of Sciences of the United States of America PNAS, Vol. 106 (36), pp. 15274-15278. [ Links ]
[8] Zhang, H., Dantu, R. (2010). Predicting Social Ties in Mobile Phone Networks. En: IEEE International Conference on Intelligence and Security Informatics ISI. [ Links ]
[9] Bisgaard, S., Kulahci, M. (2011). Time Series Analysis and Forecasting by Example. New Jersey. Wiley. [ Links ]
[10] Kim, M., Park, S. O. (2013). Group affinity based social trust model for an intelligent movie recommender system. En: Multimedia Tools and Applications, Vol. 64, pp. 505-516. [ Links ]
[11] Wasserman, S., Faust, K. (1994). Social Network Analysis: Methods and Applications. Cambridge. Cambridge University Press. [ Links ]
[12] Kossinets, G., Kleinberg, J. M., Watts, D.J. (2001). The structure of information pathways in a social communication network. En: 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [ Links ]
[13] Aiken, L. (2003). Test psicológicos y evaluación. México. Prentice Hall. [ Links ]
[14] Morgeson, M., Reider, F., Campion, M. (2005). Selecting individuals in team settings: The importance of social skills, personality characteristics, and teamwork knowledge. En: Personnel Psychology, Vol. 58 (3), pp. 583-611. [ Links ]
[15] Leskovec, J., Rajaraman, A., Ullman, J.D. (2014). Mining of Massive datasets. Cambridge University Press. [ Links ]
[16] Gompers, P., Mukharlyamov, V. (2015). The Cost of Friendship. En: Journal of Financial Economics, aceptado para publicación. [ Links ]
[17] Fershtman, C., Gneezy, U. (2001). Discrimination in a Segmented Society: An Experimental Approach. En: Quarterly Journal of Economics, Vol. 115 (3), pp. 351-377. [ Links ]
[18] Kempe, D., Kleinberg, J. M., Tardos, E. (2003). Maximizing the spread of influence through a social network. En: 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [ Links ]
[19] Rao, D., Yarowsky, D., Callison-Burch, C.;(2008). Affinity measures based on the graph Laplacian. En: Proceedings of the 3rd TextGraphs Workshop on Graph-based Algorithms for NLP, pp. 41-48. [ Links ]
[20] Liu, H., Yang, X., Latecki, L. J., Yan, S. (2012). Dense neighborhoods on affinity graph. International Journal of Computer Vision, Vol. 98 (1), pp. 65-82. [ Links ]
