










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkCiencia e Ingeniería Neogranadina
Print version ISSN 0124-8170
Cienc. Ing. Neogranad. vol.26 no.1 Bogotá Jan./June 2016
https://doi.org/10.18359/rcin.1665
DOI: http://dx.doi.org/10.18359/rcin.1665
EL EFECTO DÍA EN LOS RETORNOS DEL ÍNDICE COLCAP ANALIZADO CON MAPAS AUTOORGANIZADOS
THE DAY-EFFECT ON THE RETURNS OF COLCAP INDEX ANALYSED WITH SELF-ORGANIZING MAPS
Juan David Ortiz Sandoval1, David René Pena Cuéllar2, Helbert Eduardo Espitia Cuchango3
1 Ing. Sistemas, grupo de investigación de Modelamiento en Ingeniería de Sistemas MIS, Universidad Distrital Francisco José de Caldas, Bogotá, Colombia, jdortizs@correo.udistrital.edu.co.
2 Ing. Sistemas, grupo de investigación de Modelamiento en Ingeniería de Sistemas MIS, Universidad Distrital Francisco José de Caldas, Bogotá, Colombia, drpenac@correo.udistrital.edu.co.
3 Ing. Electrónico, Doctor en Ingeniería de Sistemas y Computación, Profesor asociado, Facultad de Ingeniería, investigador grupo MIS, Universidad Distrital Francisco José de Caldas, Bogotá, Colombia, heespitiac@udistrital.edu.co.
Fecha de recepción: 9 de junio de 2015 Fecha de aprobación: 4 de octubre de 2015
Referencia: J. D. Ortiz Sandoval, D. R. Pena Cuéllar, H. E. Espitia Cuchango (2016). El efecto día en los retornos del índice colcap analizado con mapas autoorganizados. Ciencia e Ingeniería Neogranadina, 26 (1), pp. 97-108, DOI: http://dx.doi.org/10.18359/rcin.1665.
RESUMEN
En este artículo se analiza el valor histórico del índice Colcap (el cual corresponde al índice de referencia del mercado accionario colombiano), utilizando un modelo de mapa autoorganizado de Kohonen (SOM). Esto se realiza para encontrar una correlación del día semanal con el retorno diario del índice. En el desarrollo se presentan los datos empleados como también la configuración del SOM para el entrenamiento. El mapa autoorganizado entrenado es visualizado por cada componente del vector de entrada para revelar gráficamente las predominancias existentes en el valor del retorno del índice Colcap respecto al día semanal.
Palabras clave: Efecto día, hipótesis de mercados eficientes, mapas autoorganizados, mercado accionario colombiano, retorno diario.
ABSTRACT
In this article is analyzed the historic value of Colcap index (which is the reference index of colombian stock market), by using a model of Kohonen's Self-Organizing Map (SOM). This is done in order to find a correlation between weekday with the daily return of index. It is explained what data were used, as well as the configuration of SOM for training. The trained SOM was then visualized by each component of input vector to graphically reveal any existing predominancy in the value index return Colcap in regard of the weekday.
Keywords: Day effect, efficient market hypothesis, self-organizing maps, colombian stock market, daily return.
1. INTRODUCCIÓN
La información bursátil y financiera es una serial de alta sensibilidad a factores macroeconómicos que causan particularmente variaciones de precios accionarios. Las anomalías en el comportamiento de los precios debidas a factores exógenos son muestra de ineficiencia en un mercado bursátil. Si un mercado accionario presenta anomalías se declara como ineficiente, ya que, según la hipótesis de mercados eficientes [1], en un mercado eficiente es imposible predecir los movimientos de los precios a partir de un conjunto de información disponible. Una de las anomalías es la conocida como el efecto día, que indica que existe una correlación de los movimientos de precios accionarios con el día de la semana, siendo este el factor exógeno involucrado.
Explorar la presencia de anomalías como el efecto día [2], [3] es importante para conocer cómo el día de la semana puede afectar la manera como los inversionistas realizan sus operaciones de compra y venta. Según estudios previos acerca del anterior índice de referencia del mercado accionario colombiano, el IGBC, existen anomalías relacionadas con el día semanal presentes en el comportamiento de los precios [3-5]. Esto es muestra de ineficiencia, ya que la hipótesis de mercados eficientes afirma, esencialmente, que cualquier estrategia es inútil para predecir movimientos de precios en la medida en que se incorporan las expectativas e información de todos los participantes del mercado [6], lo que impide cualquier intento de obtener retornos excesivos al momento de la inversión.
La anomalía del efecto día aún no ha sido revelada en el índice Colcap, siendo necesario un análisis del valor de este para contrastar la dinámica que presenta con lo concluido en los estudios previos del IGBC. Muchos inversionistas están interesados en explorar y comprender la posibilidad de usar el comportamiento anómalo para diseñar estrategias de inversión rentables y evitar los riesgos subyacentes, ya que las anomalías podrían ayudar a predecir precios [4], [7].
En este trabajo se analizarán los valores históricos del índice Colcap para identificar la anomalía del efecto día utilizando los mapas autoorganizados de Kohonen (Self Organizing Maps SOM) [8-10], la cual es una arquitectura de red neuronal artificial de tipo no-supervisado usada comúnmente para cuantización vectorial, agrupamiento (clustering) y visualización de datos [11]. La ventaja de emplear SOM es su habilidad para encontrar relaciones subyacentes en los datos a través de una etapa de entrenamiento, aprovechando sus características conectivas y adaptativas con el fin de describir las predominancias de un conjunto de datos por medio de gráficas bidimensionales.
Este documento se encuentra organizado de la siguiente manera: en la Sección 2 se hace un resumen de los SOM; en la Sección 3, por otra parte, son explicados los datos de estudio y la implementación del SOM. La Sección 4 muestra los resultados del experimento; en la Sección 5 los análisis correspondientes. Finalmente, en la Sección 6 se presentan las conclusiones y posibles trabajos futuros a considerar.
2. MAPAS AUTOORGANIZADOS DE KOHONEN
Un mapa autoorganizado es una red neuronal feed-forward que usa un algoritmo de entrenamiento no-supervisado. Convierte relaciones estadísticas complejas y no-lineales entre datos de alta dimensión en relaciones geométricas simples en una visualización de menor dimensión [9]. Los SOM han mostrado ser útiles en problemas como: clasificación de patrones, cuantificación vectorial, reducción de dimensiones, extracción de rasgos, monitorización de procesos, análisis exploratorio, visualización y minería de datos [11], [12], además de prometedoras aplicaciones en bioinformática [10].
Este tipo de red neuronal de dos capas tiene la capacidad de representar información por medio de la autoorganización de sus neuronas, que responden a los datos de entrada (Figura 1). La primera capa se encarga de colectar la información y llevarla a la segunda capa de procesamiento y salida, que se conforma en una estructura rectangular de nx x ny neuronas. Cada neurona (i, j) tiene conexión con todos los elementos de entrada por medio de pesos sinápticos [13].
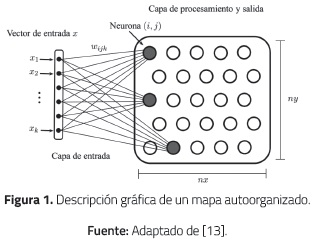
La capa de procesamiento es un espacio bidimensional o una cuadrícula (usualmente de forma plana) donde las neuronas son ubicadas cada una en un retículo rectangular, con máximo 4 neuronas vecinas, o hexagonal, con máximo 6 neuronas vecinas [13].
Las neuronas del SOM se activan colectivamente con cierta intensidad para patrones de entrada, dando como resultado zonas del mapa especializadas en reconocer patrones con características comunes y que describen relaciones subyacentes en la información utilizada para el análisis. Las neuronas de la capa de procesamiento compiten entre sí para activarse ante un patrón según sea la similitud de sus pesos [13].
El aprendizaje para modificar los pesos es no supervisado y competitivo. Se presenta un patrón entrada x de tamaño k, que es número de variables o componentes del patrón, a la neurona (i, j), la cual calcula la similitud entre su vector de pesos wij y el vector de entrada x por medio de una función de distancia (1), para cada componente k. Usualmente se usa la distancia euclidiana d como medida de cálculo para determinar la cercanía de las neuronas a las entradas.
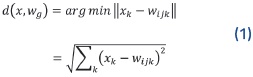
Cada neurona compite por activarse ante un patrón de entrada. La neurona cuyos pesos sean más parecidos a los datos de entrada se determina como neurona ganadora g (Best Matching Unit BMU), cuya distancia es la menor de todas (la distancia mínima entre w.. y x), con lo cual esta neurona será modificada en una wg iteración del aprendizaje para que sus pesos se parezcan más al vector de entrada, con ello la neurona responderá con mayor intensidad en el futuro.
La actualización de pesos se hace mediante (2), en la cual wjjk representa el peso k de la neurona Los pesos de las neuronas vecinas a la BMU también se modificarán si la neurona r pertenece al radio de vecindad de esta, y eso se determina por la función de vecindad hrg(3), que vale un número positivo cuando r se encuentra en la vecindad de BMU, o de lo contrario vale cero.
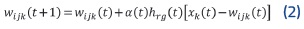
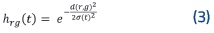
La fórmula de la función vecindad h rg es simétrica, decreciente y centrada en g, comúnmente de tipo gaussiano y determina qué tan cerca se ubican las neuronas vecinas a la ganadora a partir de un rango de vecindad variable σ(t) dado en (4).
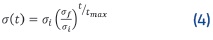
En el entrenamiento se parte de un radio grande o. que contiene varias neuronas y disminuye hasta alcanzar un valor σƒ siendo t la iteración actual del aprendizaje y t el número máximo de iteraciones para que se llegue al radio final of=l) que contiene a una sola neurona. Esto hace que las neuronas más cercanas a sufran mayores cambios en sus pesos que las más alejadas. La variable que completa el modelo de aprendizaje es α(t), que indica el ritmo en el cual las n neuronas son organizadas (5). El valor αi es menor a 1 y a medida que transcurren las épocas de entrenamiento se va acercando a un valor final αf de 0.01 en busca de que se produzcan al inicio cambios fuertes, y de forma progresiva más suaves y sutiles.
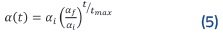
Normalmente el aprendizaje de un SOM está dividido en dos fases, una de ordenamiento y otra de convergencia. En la primera, los valores iniciales del radio de vecindad y del ritmo de aprendizaje (σi y αi) son grandes para que las neuronas se distribuyan rápidamente a través de los datos de entrada. Al terminar la primera fase se inicia una segunda, para ajustar una neurona por iteración, en la cual el radio de vecindad es igual a 1 y el ritmo de aprendizaje de 0.01. Ambos parámetros se mantienen constantes durante la convergencia, lo que produce una distribución más suave que en la primera fase. La etapa de convergencia tiene muchas más épocas de entrenamiento que la fase de ordenamiento [8].
La eficiencia de un SOM entrenado es medida por la distancia promedio entre los vectores de entrada y los pesos sinápticos de sus respectivas BMU; este valor es conocido como el error de cuantización promedio (Average Quantization Error). Un valor bajo indica un SOM mejor entrenado [14].
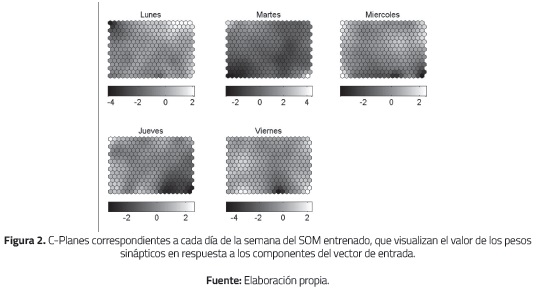
A pesar de que los SOM son considerados como una poderosa herramienta de mineria de datos, las personas desempeñan un papel importante en la interpretación de la información que se puede extraer de los mapas entrenados. El SOM por si solo no es de mucha utilidad sin técnicas de visualización que permitan destacar las propiedades de los datos [15]. Para esto se usan comúnmente visualizaciones bidimensionales mediante una escala de color, que pueden ser usadas para análisis exploratorio de los datos [16]. Una de estas es Component Planes (C-Planes) que representa los valores del vector de pesos mediante un color (colores claros y oscuros para pesos positivos y negativos, respectivamente). Cada C-Plane representa un componente del vector de entrada y visualiza la distribución que presentan los pesos para cada componente.
3. CASO DE ESTÚDIO
Los índices generales de la bolsa permiten representar el comportamiento que sigue un conjunto determinado de acciones en el mercado. En el caso colombiano, el comportamiento accionario en la Bolsa de Valores de Colombia es medido por el índice Colcap, que desde el año 2008 refleja las variaciones de los precios de las 20 acciones con mayor liquidez, contemplando un limitante de participación de cada acción a un máximo de 20% [17]. Progresivamente ha reemplazado en representatividad al Índice General de la Bolsa de Valores de Colombia, el IGBC, ya que este último no define límite alguno para la participación de una acción en la canasta y resulta muy dependiente de los movimientos del sector petrolero [18].
Para realizar la aplicación de los SOM al íindice Colcap, primero se realiza la recolección de los datos históricos, con los cuales se calcula el retorno simple diario [19, 20], esto para conformar patrones semanales los cuales son usados para el entrenamiento. El SOM se inicializa con los parámetros respectivos (número de neuronas y grilla, dimensiones de sus lados, épocas de entrenamiento, función de vecindad y radio, etc.). Luego se evalúa la eficiencia del mapa mediante el error promedio de cuantización (Average Quantization Error). Finalmente, se realizarán los respectivos análisis de los planos bidimensionales que resultan del proceso de entrenamiento para identificar las predominancias que se presentan según el día semanal.
3.1 Datos de estúdio
Los datos históricos del valor del íindice Colcap fueron tomados desde el 14/01/2008 hasta el 30/05/2014 (fecha de adquisición de los datos), siendo en total 1.560 valores históricos. Los datos se encuentran disponibles en el sitio web de la Bolsa de Valores de Colombia [21]. Es importante mencionar que no existe ningún tipo de restricción o condición legal para el aprovisionamiento de la información necesaria, y además se considera que las fuentes son confiables para la adquisición de los datos necesarios para la ejecución de este trabajo.
Seguidamente se calculó el retorno simple diario Rt (6), para obtener la variación porcentual entre el valor del íindice de un día accionario Pt y su valor precedente Pt-1.
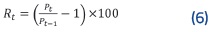
Se conformaron conjuntos de retornos diarios por semana, los cuales contienen 5 valores correspondientes para cada día hábil semanal. En el caso de no contar con cierto valor del retorno diario (debido días "no-bursátiles" como los días festivos), el valor se declara como vacio. En total se conformaron 333 conjuntos de retornos, de 5 columnas cada uno (k=5). Estos conjuntos se emplean como vectores de entrada para la fase de entrenamiento o aprendizaje del SOM.
3.2 Modelo de mapa autoorganizado SOM
El modelo fue implementado por medio del SOM desarrollado en el Laboratorio de Computación y Ciencia de la Información de la Universidad Tecnológica de Helsinki (de uso libre) [22].
La configuración del mapa se toma de tipo hexagonal, dado que es visualmente más ilustrativo y preciso [9, 10]. Además, se considera que la cantidad de neuronas del eje debe ser 30% mayor que el eje , ya que con una estructura rectangular se puede conseguir una ubicación de las neuronas más estable a través del espacio que describen vectores de entrada [14]. En este caso se utiliza un SOM rectangular de 1520 neuronas.
Para la vecindad se utiliza una función de tipo gaussiana con radio inicial de 7 y final de 1, correspondiente a la fase de ordenamiento, puesto que el radio debe ajustarse inicialmente con un valor amplio, cercano a la mitad del lado menor del mapa [8]. En la fase de convergencia se usó un radio fijo de 1, como se sugiere en [8] y [10]. Respecto a las épocas de entrenamiento, en la fase de ordenamiento debe utilizarse cerca de 100 épocas y una cifra entre 20.000 y 100.000 épocas asignadas a la convergencia considerando lo presentado en [12]. Como experimentación, se seleccionaron 100 y 80.000 épocas para cada fase de entrenamiento, y en estas el ritmo de aprendizaje a(t) está dado por una función inversa que inicia con un valor de 0.9 en la fase de ordenamiento, mientras que en la fase de convergencia inicia en 0.01. Este ritmo de aprendizaje inicialmente debe ser cercano a 1 para producir cambios grandes en los pesos de las neuronas involucradas en la vecindad, y a medida que transcurre el entrenamiento se reduce progresivamente a un valor cercano a 0 [8].
4. RESULTADOS
El SOM fue entrenado con los vectores de entrada, de esta forma, los pesos de cada neurona fueron ajustados a través del entrenamiento de acuerdo con los vectores de entrada presentados para encontrar predominancias en el retorno diario del Colcap. Fueron necesarios 56.98 minutos para alcanzar las épocas de entrenamiento fijadas en las fases de ordenamiento y convergencia, que permitieron obtener un SOM con 0.7773 de error promedio de cuantización. Para la ejecución de los experimentos fue empleado un computador personal Toshiba Satellite C660-2FE con un procesador Intel Core i5 de 2.4GHz y 6GB de memoria RAM, con sistema operativo Windows 7.
La Figura 2 muestra los C-Planes resultantes para el SOM entrenado, donde se pueden identificar los valores del vector de pesos respecto al día semanal, es decir, la manera en la que el SOM responde para los datos de cada día de la semana. La codificación de intensidad (escala de gris) permite señalar el valor que adquirieron los pesos a través del entrenamiento, denotando con tonos oscuros la presencia de valores negativos extremos; asimismo, tonos claros para los valores positivos extremos. Inicialmente se logra identificar una mayor existencia de pesos negativos para los días martes en comparación con los demás días de la semana, aunque resulta dificultosa la comparación debido a las diferentes escalas asociadas a cada dia.
La Figura 3 muestra por separado los resultados para cada día de la semana. En cada una de las visualizaciones se ajustó la escala para caracterizar dos tipos de retornos, los positivos (blanco) y negativos (negro).
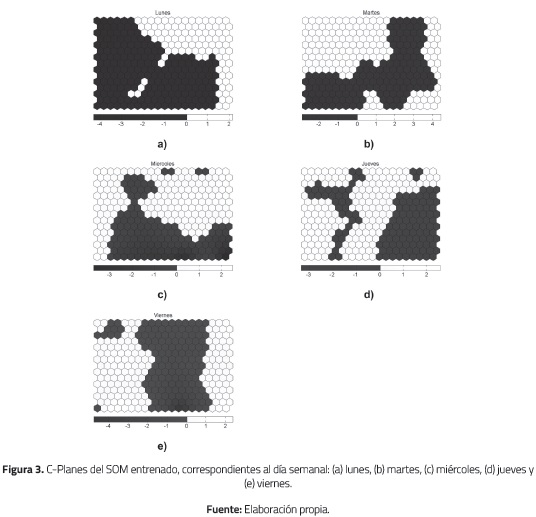
5. ANÁLISIS DE RESULTADOS
En la Figura 3, los C-Planes muestran claramente la predominancia de pesos negativos los días lunes; destacan también los valores más negativos para los pesos de las neuronas (superiores a -4%) en comparación con las demás visualizaciones. Por otro lado, es de notar una predominancia de retornos positivos en los días martes, donde se presenta el mayor valor de estos, superior a 4%, con una leve existencia de retornos negativos. En los miércoles y jueves se logra apreciar una predominancia positiva, aunque los valores no son tan altos, apenas superiores a 2%.
En el caso de los viernes no se distingue una clara predominancia, aunque los valores negativos son más extremos que los valores positivos, además que son los valores negativos más extremos de todos los días de la semana.
Se puede inferir que, históricamente, los días lunes resultan perjudiciales para los retornos del íindice Colcap. En los viernes se presenta la desvalorización más alta del íindice. Además, aunque similares en proporciones de valores positivos y negativos, los pesos para los días miércoles resultaron menores a los pesos para el día jueves. Para los días miércoles parece presentarse un retorno cercano a cero, aunque con mayor tendencia a ser negativo.
La Tabla 1 proporciona una forma de analizar los resultados cuantitativamente, donde se aprecia que en los días lunes predominan valores negativos para los pesos, reafirmando también la presencia el promedio más negativo en los días de la semana. En los días martes es cuando se presenta el valor máximo para los pesos y el promedio positivo de mayor magnitud, aunque no se describe una predominancia clara, ya que las neuronas están distribuidas en proporciones similares en valores positivos y negativos. Para los días miércoles se presenta una mayor cantidad de valores positivos, acompañado de un promedio positivo. La mayor predominancia de pesos positivos se presenta en los días jueves, aunque el promedio de los pesos es negativo. En los días viernes no existe una predominancia del signo de los valores, pero se presenta el valor más negativo de pesos junto con un promedio negativo.
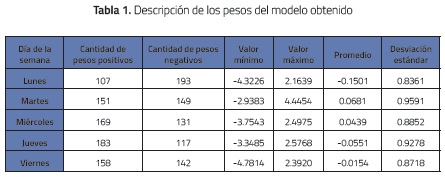
Respecto a la desviación estándar de los valores, es de notar que se presenta con mayor magnitud en los días martes, lo que indica que los datos de entrada en la variable de este día presentan mayor volatilidad y provocan que la visualización no entregue información de manera clara. Por el contrario, para los lunes, donde se presenta menor desviación estándar, se obtuvo una visualización en la que se puede identificar con mayor facilidad la predominancia negativa que allí existe.
Dado el carácter de este trabajo, orientado a describir los datos por medio de las visualizaciones bidimensionales, las predominancias vistas en estas son las que permiten inferir inicialmente una correlación de la variación del íindice con respecto al día semanal. Con ello, se rechaza la posibilidad de que el mercado accionario colombiano, representado por medio del Colcap, sea eficiente en información en el periodo analizado (enero de 2008 a mayo de 2014), por lo menos al nivel débil [1] (dado que se utilizó información histórica pública disponible), ya que en principio la presencia de arbitrajes en el comportamiento accionario podría ayudar en la predicción de precios.
Las razones para este comportamiento de los precios se pueden relacionar con la información que llega al mercado cada día y que puede influir en las decisiones de los inversionistas y analistas del mercado, como los estados financieros de las empresas, tasas de desempleo, inflación, entre otros. Esto implica que los inversionistas actúan colectivamente hacia una tendencia identificable [22], ya que pueden ser susceptibles a hechos recientes o notorios [4] teniendo también en cuenta que algunos inversionistas son más optimistas que otros respecto a la tendencia a futuro de los precios.
Los resultados y análisis se asemejan a lo expuesto en investigaciones previas sobre el efecto día en el mercado colombiano, como en [4] y [5], donde se afirma que los días iniciales de la semana impactan negativamente el movimiento de los precios accionarios en la Bolsa de Valores de Colombia, a diferencia de los días finales de la semana donde se pueden producir valorizaciones de los precios. En los trabajos mencionados se utilizaron modelos econométricos para analizar el valor histórico del IGBC.
6. CONCLUSIONES Y EXPECTATIVAS FUTURAS
En este trabajo se presentó la utilidad que tienen los SOM para manejar información financiera, específicamente en el estudio de retornos diarios. Es de considerar que el propósito del presente trabajo es la utilización de las propiedades de visualización propias del algoritmo de SOM y resaltar qué predomina por día semanal en el Colcap. Como resultados se obtuvieron una serie de patrones gráficos, los cuales son de importancia para resaltar las tendencias en los días de la semana en el comportamiento general del mercado accionario colombiano.
La identificación de una correlación entre el día semanal y la variación del Colcap fue lograda a través de visualizar el retorno diario para señalar el comportamiento que sobresale en cada dia, especialmente los lunes, en los cuales se caracteriza notoriamente como día desfavorable en términos del signo del retorno, mientras que sobre los días martes y viernes existe un efecto contrario. Es de interés la relación de las visualizaciones obtenidas con la desviación estándar de los datos de entrada, ya que cuanto menor fue la medida de esta última se obtuvieron mejores visualizaciones para apreciar las predominancias en el modelo SOM.
Los análisis realizados sobre los días favorables y desfavorables para la inversión en títulos transados en la Bolsa de Valores de Colombia se pueden tomar como referencia para identificar oportunidades de valorización de las inversiones que se realicen en un portafolio como el iColcap, el cual es un fondo que representa la inversión en las 20 acciones del íindice, o también en un portafolio de proporciones similares al íindice Colcap.
Sobre trabajos futuros se podría realizar el análisis individual de los retornos diarios históricos de las acciones que componen el íindice Colcap, teniendo en cuenta más variables como el efecto del final de mes o el periodo ex-dividendo, que es un lapso de 10 días anteriores al pago de un dividendo de una acción por parte de una empresa cotizante a sus inversionistas. Además, seria de interés explorar en qué días de la semana se publica información según el calendario económico para identificar patrones en la respuesta del mercado accionario a datos macroeconómicos de importancia que se divulgan cierto día de la semana.
BIBLIOGRAFÍA
[1] Fama, E. (1970). Efficient capital markets: A review of theory and empirical work. 777e Journal of Finance, 25(2), pp. 383-417. [ Links ]
[2] Kiymaz, H., Berument, H. (2003). The day of the week effect on stock market volatility and volume: International evidence. Review of Financial Economics, 13, pp. 363-380. [ Links ]
[3] Villalobos, J., Mendoza, J. (2010). Efecto día en el mercado accionario colombiano: una aproximación no paramétrica. Borradores de Economía, Banco de la República, 585, pp. 1-18. [ Links ]
[4] Montenegro, A. (2007). El efecto día en la Bolsa de Valores de Colombia. Documentos de Economia, Pontificia Universidad Javeriana, Facultad de Ciencias Económicas y Administrativas, 9. [ Links ]
[5] Rivera, D. (2009). Modelación del efecto del día de la semana para los íindices accionarios de Colombia mediante un modelo STAR GARCH. Revista de Economía del Rosario, 12(1), pp. 1-24. [ Links ]
[6] Bahi, C. (2007). Modelos de medición de la volatilidad en los mercados de valores: aplicación al mercado bursátil argentino, Universidad Nacional de Cuyo, Facultad de Ciencias Económicas. [ Links ]
[7] Sakalauskas, V. Kriksciuniene, D. (2012). Evaluation of the day-of-the-week effect using long range dependence measures. En 12th International Conference on Intelligent Systems Desing and Applications, pp. 143-148. [ Links ]
[8] Kohonen, T. (1990). The self-organizing map. En Proceedings of the IEEE, 78 (9), pp. 1464-1480. [ Links ]
[9] Kohonen, T. (1998). The self-organizing map. Neurocomputing, 21. [ Links ]
[10] Kohonen, T. (2013). Essentials of the self-organizing map. Neural Networks, 37, pp.52-65. [ Links ]
[11] Barreto, G. (2007). Time Series Prediction with the Self-Organizing Map: A Review. Perspectives on Neural-Symbolic Integration, 77, pp.135-158. [ Links ]
[12] Martin Del Brio, B., Sanz, A. (2007). Redes neuronales ysistemas borrosos, 3a edición. México, D.F., México: Alfaomega. [ Links ]
[13] Caicedo, E., López, J. (2009). Una aproximación práctica a las redes neuronales artificiales. Cali, Colombia: Programa editorial Universidad del Valle. [ Links ]
[14] Eklund, T., Back, B., Vanharanta, H., Visa, A. (2002). Assessing the feasibility of Self-Organizing Maps for data mining financial information. En Proceedings of the Xth European Conference on Information Systems, Gdansk, Polonia, pp. 528-537. [ Links ]
[15] Silva, B., Marques, N. (2010). Feature clustering with self-organizing maps and an application to financial time-series portfolio selection. En International Conference on Neural Computation, pp. 301-309. [ Links ]
[16] Engelbrecht, A. (2007). Computational Intelligence: An introduction, 2a edición. Chichester, Inglaterra: Wiley Publishing, pp. 71. [ Links ]
[17] Bolsa de Valores de Colombia. (2013). Metodologia para el cálculo del índice Colcap. [ Links ]
[18] Agudelo, D. (2013). El rebalanceo del Colcap y su efecto en las acciones. Diario La República, Bogotá, Colombia, pp. 13.(23 de febrero de 2013). [ Links ]
[19] Forero, G. (2011). Contrastación de paradigmas de las finanzas: normalidad e hipótesis del mercado eficiente. Aplicaciones en MATLAB. Observatorio de Economia y Operaciones Numéricas, 5, pp.167-227. [ Links ]
[20] De Lara, A. (2003). Medición y control de riesgos financieros, 3a edición. México, D.F., México: Limusa S.A., pp. 27. [ Links ]
[21] Bolsa de Valores de Colombia, Índices. En: http://www.bvc.com.co. [ Links ]
[22] Silva, B. Marques, N. (2011). Clustering stock markets values with a Self-Organized featured Map. En EPIA2011 - 15th Portuguese Conference on Artificial Intelligence, Lisboa, Portugal, pp. 520-534. [ Links ]
