











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Introducción
Cuando se analizan datos relacionados con el tiempo de ocurrencia de eventos de interés en el área de la ingeniería (tiempo de falla de un sistema, tiempo de vida útil de un producto, etc.), puede ocurrir que no se conozca el tiempo observado de manera exacta, obteniendo una información parcial para algunas observaciones. Esta información parcial, denominada censura, afecta la estimación y la cantidad de herramientas que se pueden utilizar para solucionar el problema. Para su interpretación, es indispensable estimar la función de confiabilidad [1], combinar estrategias como en [2] y calcular intervalos de confianza como los usados en [3].
En los últimos años, las herramientas computacionales han tomado fuerza para la estimación de la función de confiabilidad [4]. Siendo la técnica de remuestreo Jackknife [5] una alternativa que algunas veces mejora las estimaciones y, en situaciones extremas de muestras pequeñas y altos porcentajes de censura [6], ayuda a reducir el error de estimación de la función de confiabilidad. Autores como Rostron et al., recomiendan procedimientos como el bootstrapping para validar los intervalos de confianza para la función de confiabilidad [7].
Existen ventajas de usar transformaciones log y log(-log) en los IC para la función de confiabilidad. Pues, por sus propiedades asintóticas, se puede reducir la varianza y normalidad asintótica [8] para obtener IC más precisos. Lo que nos lleva a pensar que es importante combinar las estrategias de remuestreo Jackknife y las transformaciones logarítmicas para disminuir el error en la estimación de la función de confiabilidad. Este es un procedimiento diferente a la propuesta realizada por Johnson et al., donde se utilizó Jackknife K-repetido para mejorar las estimaciones [9]. De este procedimiento no se tienen antecedentes en la literatura sobre confiabilidad, por lo que su comparación con [9] resultaría ser un aporte original. Aunque, se debe tener en cuenta que recientes investigaciones que combinan enfoques bayesianos para estimar la confiabilidad han presentado afectaciones de aumento de error por el fenómeno de censura [10].
Este trabajo propone un nuevo intervalo de confianza que utiliza transformaciones logarítmicas y remuestreo Jackknife de grado (d), mayor al utilizado en la literatura de confiabilidad, con base en el estimador Kaplan-Meier y Nelson-Aalen, en situaciones de altos porcentajes de censura. Sobre el tema, algunas otras investigaciones han realizado la estimación intervalar para la función de confiabilidad usando la transformación log Por ejemplo, Barbiero et al. presentaron una comparación con diferentes escenarios, ilustrando la mejora en las estimaciones de la función de confiabilidad [11]. Mientras que Khalifeh et al. supusieron distribuciones paramétricas para los tiempos de falla [12], y en [13] se estimaron otras funciones como el riesgo acumulado.
El documento se encuentra organizado de la siguiente manera: primero, se describen los fundamentos teóricos que son utilizados para el desarrollo del trabajo; después se presenta la metodología para realizar el trabajo y se describe el estudio de simulación. Posteriormente, se presentan los resultados y la discusión; y, por último, se realizan las conclusiones y recomendaciones necesarias.
Estimador de Kaplan-Meier (KM)
Edward L. Kaplan y Paul Meier propusieron un método no paramétrico (no asume ninguna función de probabilidad para los tiempos de interés) y de máxima verosimilitud [14]. Es decir que este se basa en maximizar la función de verosimilitud de la muestra.
Una muestra aleatoria de tamaño n, extraída de una población, estará formada por k (k ≤ n) tiempos t1 < t2 <, ... ,< tn en los que se observan eventos. En cada tiempo t j existen n j individuos en riesgo y se observan d¡ eventos.
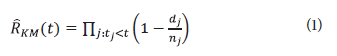
Donde d j es el número de eventos en el tiempo, y t j , y n es el número de personas expuestas en el tiempo t j . En otros contextos, dicho estimador es usado para predecir valores futuros [15].
Estimador de Nelson-Aalen (NA)
Wayne Nelson y Odd Aalen sugirieron una alternativa para estimar la función de confiabilidad basada en la función de riesgo acumulada
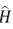 (t), dada por
(t), dada por
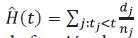 [16]. Entonces, el estimador para la función de confiabilidad es:
[16]. Entonces, el estimador para la función de confiabilidad es:

Se debe notar que
(t) acumula las contribuciones
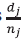 en los sucesivos instantes de fallo t
j
.
en los sucesivos instantes de fallo t
j
.
Remuestreo Jackknife delete-d
El método de remuestreo Jackknife delete-d (d=1,2,3,4), es una generalización del caso tradicional delete-I. En donde en lugar de suprimir d una observación a la vez, se suprime observaciones. Por lo tanto, el tamaño de delete-d muestras Jackkni-fe es (n-d) y se tienen (n d) muestras Jackknife. Los pseudovalores son dados por:
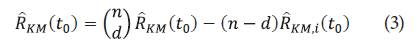
Así, el estimador mediante la estrategia Jackk-nife delete-d es:
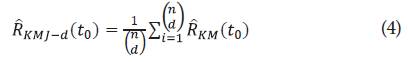
Con error estándar:
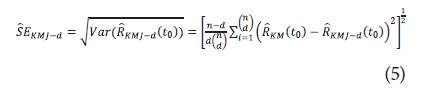
Por lo que bajo condiciones de regularidad se tiene que:
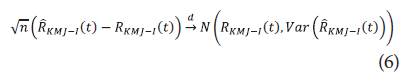
Donde
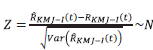 . Por lo tanto, para d = I,II,III y IV la expresión para los IC usando Jac-kknife es dada por:
. Por lo tanto, para d = I,II,III y IV la expresión para los IC usando Jac-kknife es dada por:
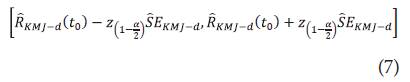
Donde
 es definido en (4). Ahora bien, ya definidos los intervalos de confianza para la función de confiabilidad mediante el remuestreo Jackknife en caso I, II, III y IV sin transformaciones, a continuación, se presenta la deducción de los intervalos teniendo en cuenta las transformaciones log y
log (-log).
es definido en (4). Ahora bien, ya definidos los intervalos de confianza para la función de confiabilidad mediante el remuestreo Jackknife en caso I, II, III y IV sin transformaciones, a continuación, se presenta la deducción de los intervalos teniendo en cuenta las transformaciones log y
log (-log).
Transformaciones para logy log (-log) para R(t)
La transformación log, sugerida inicialmente por [17], está basada en encontrar un intervalo de confianza para el logaritmo de la función de Hazard acumulada, H(t). Donde, para t
0
Є [0, T] se define Y
t
= log (
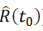 ) Siendo
el estimador para la función de confiabilidad seleccionado KM o NA. Se sigue por el método delta que:
) Siendo
el estimador para la función de confiabilidad seleccionado KM o NA. Se sigue por el método delta que:
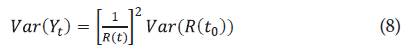
Luego, un intervalo de confianza para Y t , está dado por los límites:
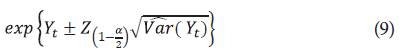
Con
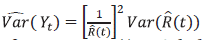 y así, un intervalo de confianza para R(t) está dado por:
y así, un intervalo de confianza para R(t) está dado por:
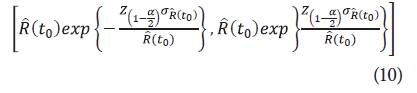
Donde
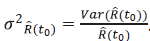 . Como la función logaritmo es asimétrica, se puede utilizar la transformación logarítmica para estabilizar la varianza. De igual forma, para encontrar un IC para la función de confiabilidad mediante la transformación log(-log). Se define W(t)= log (- log(R(t))), se sigue por el método delta que:
. Como la función logaritmo es asimétrica, se puede utilizar la transformación logarítmica para estabilizar la varianza. De igual forma, para encontrar un IC para la función de confiabilidad mediante la transformación log(-log). Se define W(t)= log (- log(R(t))), se sigue por el método delta que:
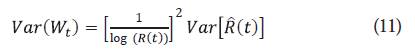
Luego, un intervalo de confianza para Wt, está dado por:

Con
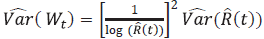 y así, un intervalo de confianza para R(t0) está dado por:
y así, un intervalo de confianza para R(t0) está dado por:

Donde exp
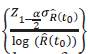 El intervalo de confianza para la función de confiabilidad, a partir de la transformación log (-log) se tiene con límites positivos y menores o iguales a uno, teniendo así un intervalo de confianza natural, puesto que la transformación está definida en todos los números reales.
El intervalo de confianza para la función de confiabilidad, a partir de la transformación log (-log) se tiene con límites positivos y menores o iguales a uno, teniendo así un intervalo de confianza natural, puesto que la transformación está definida en todos los números reales.
Metodología
Para el desarrollo del presente trabajo se inició con la deducción de las expresiones de los intervalos de confianza para la función de confiabilidad. Lo anterior, con base en cada estimador KM y NA mediante remuestreo Jackknife delete I, II, III, IV, y usando las transformaciones log y log (-log) de los intervalos de confianza para la función de confiabilidad. Posteriormente, se elaboró un algoritmo en el software estadístico R, versión 4.0.2 [18], para comparar los resultados vía simulación de Monte Carlo. Las muestras para los tiempos observados y censurados fueron generadas con la función rweibull de R, considerando la generación de los tiempos observados y censurados a derecha de forma independiente para modelos weibull(α, β), con parámetro de forma α= 0.5 y 2.5, y parámetro de escala β= 2.5 y 1.5. Con tamaño n = (10, 25, 50) y porcentajes de censura del 0%, 15%, 50%. A continuación, se determinaron las coberturas, tasas de errores definidas como la proporción de intervalos de confianza para la función de confiabilidad que no contienen el valor de referencia (función de confiabilidad Weibull evaluada en el tiempo de interés) y amplitud de los intervalos de confianza para la función de confiabilidad. En el estudio, no se consideraron estructuras de dependencia entre los tiempos observados y censurados.
Criterio de comparación
Para establecer la estrategia que presenta mejores resultados, se calcularon los intervalos de confianza para la función de confiabilidad en cada muestra simulada. Luego, se calcularon las tasas de error, teniendo en cuenta los valores de referencia según los modelos generadores de la simulación. Adicionalmente, se calculó el índice propuesto por [19], dado por:

Donde NS es el número de simulaciones (1000), NR es el nivel cobertura real (tasa de intervalos que contienen al valor de referencia), NN es el nivel nominal del intervalo (95%) y LPI es la longitud promedio de los intervalos, donde:
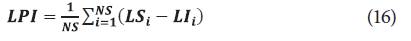
Resultados
Para deducir los nuevos intervalos se considera una muestra de n tiempos t 1 , t 2 ...t r ,t n con n ≥ r, siendo r el número de datos censurados en la muestra y (n - r) datos observados, definimos para la transformación log y log (-log):
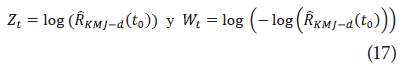
Respectivamente, obtenido de forma análoga usando el método delta. Cabe notar que:
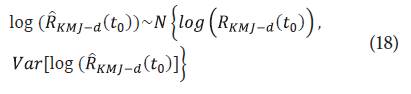
Adicionalmente:
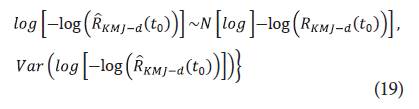
Adem ás, com
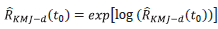 , obtenemos que:
, obtenemos que:
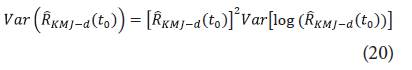
Así, un IC 100(1 - α) para log
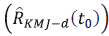 es dado por los límites:
es dado por los límites:
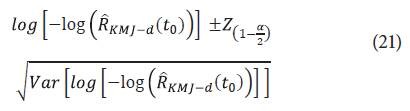
Por otra parte, 100 un IC 100(1-α) para log
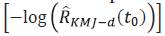 es dado por los límites:
es dado por los límites:
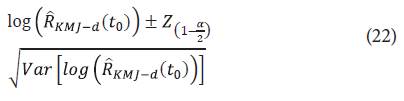
Siendo
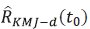 definido en la ecuación 4 con d=1,2,3,4. Por lo que:
definido en la ecuación 4 con d=1,2,3,4. Por lo que:
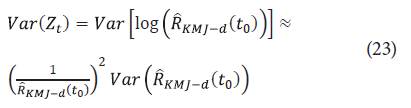
Además:
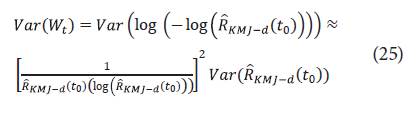
Donde
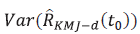 es definida en la ecuación 5. No obstante, los sesgos corregidos del estimador de Kaplan-Meier pueden ser utilizados [20]. Por lo que en el presente trabajo fue incluido el pseudovalor Jackknife.
es definida en la ecuación 5. No obstante, los sesgos corregidos del estimador de Kaplan-Meier pueden ser utilizados [20]. Por lo que en el presente trabajo fue incluido el pseudovalor Jackknife.
En la tabla 1 son presentados los resultados para cada escenario de simulación. Los valores dentro de la tabla corresponden a Tasas de Error/Índice, indicando en negrilla los valores con mejor comportamiento para los índices y tasas de error real de la estimación por intervalo. Las siglas de las tablas en el presente artículo (KM: estimador de Kaplan-Meier, log KM: transformación log usando KM, log(-log) KM: transformación log(-log) usando KM, n: tamaño de muestra, delete: grado de delete) se presentan de forma análoga con NA: estimador Nelson-Aalen.
Tabla 1 T.E/I con 0% de datos censurados a derecha.
| n | delete | KM | log KM | log(-log) KM | NA | log(NA) | log(-log) NA |
|---|---|---|---|---|---|---|---|
| 10 | I | 0.101/0.732 | 0.230/0.627 | 0.276/0.590 | 0.101/0.732 | 0.196/0.655 | 0.276/0.590 |
| II | 0.067/0.672 | 0.147/0.615 | 0.235/0.551 | 0.067/0.672 | 0.124/0.631 | 0.206/0.572 | |
| III | 0.063/0.599 | 0.104/0.573 | 0.204/0.509 | 0.063/0.599 | 0.090/0.582 | 0.151/0.543 | |
| IV | 0.064/0.531 | 0.075/0.525 | 0.146/0.484 | 0.064/0.531 | 0.068/0.528 | 0.108/0.506 | |
| 25 | I | 0.047/0.856 | 0.182/0.734 | 0.210/0.709 | 0.050/0.853 | 0.165/0.750 | 0.175/0.741 |
| II | 0.011/0.824 | 0.054/0.788 | 0.105/0.745 | 0.017/0.819 | 0.054/0.788 | 0.098/0.751 | |
| III | 0.003/0.776 | 0.027/0.757 | 0.061/0.731 | 0.003/0.776 | 0.027/0.757 | 0.047/0.742 | |
| IV | 0.000/0.732 | 0.000/0.732 | 0.000/0.712 | 0.000/0.726 | 0.000/0.735 | 0.000/0.733 | |
| 50 | I | 0.060/0.888 | 0.169/0.785 | 0.154/0.799 | 0.056/0.892 | 0.156/0.797 | 0.154/0.799 |
| II | 0.005/0.895 | 0.051/0.854 | 0.069/0.838 | 0.006/0.894 | 0.046/0.858 | 0.067/0.839 | |
| III | 0.001/0.896 | 0.010/0.872 | 0.003/0.775 | 0.001/0.896 | 0.030/0.862 | 0.010/0.775 | |
| IV | 0.000/0.897 | 0.001/0.882 | 0.001/0.845 | 0.000/0.897 | 0.001/0.881 | 0.001/0.846 |
Fuente: elaboración propia.
En la tabla 1 se observa la ausencia de datos censurados, situación ideal en la práctica y poco común para los estudios de ingeniería controlados. Además, se puede notar que los estimadores tradicionales (Kaplan-Meier y Nelson-Aalen), resultan ser la mejor opción, siendo, en general, aproximadamente iguales. Las estimaciones con tres dígitos decimales, muestran que los casos de menor tasa de error coinciden con mayores índices de calidad (valores en negrilla). Lo que coincide, a su vez, con la teoría de confiabilidad y las tendencias de similitud de resultados de los estimadores Kaplan-Meier y Nelson-Aalen en [6]. Los resultados obtenidos al aumentar el porcentaje de datos censurados son presentados en la tabla 2.
Tabla 2 T.E/I con 15% de datos censurados a derecha.
| n | delete | KM | log KM | log(-log) KM | NA | log(NA) | log(-log) NA |
|---|---|---|---|---|---|---|---|
| 10 | I | 0.090/0.732 | 0.160/0.676 | 0.212/0.634 | 0.090/0.732 | 0.145/0.688 | 0.191/0.651 |
| II | 0.059/0.658 | 0.090/0.636 | 0.109/0.623 | 0.059/0.658 | 0.082/0.642 | 0.111/0.621 | |
| III | 0.010/0.600 | 0.018/0.595 | 0.076/0.560 | 0.010/0.600 | 0.016/0.596 | 0.048/0.577 | |
| IV | 0.003/0.522 | 0.010/0.518 | 0.014/0.517 | 0.003/0.522 | 0.003/0.522 | 0.014/0.517 | |
| 25 | I | 0.070/0.835 | 0.120/0.790 | 0.100/0.809 | 0.070/0.835 | 0.130/0.781 | 0.070/0.835 |
| II | 0.050/0.790 | 0.060/0.782 | 0.020/0.815 | 0.060/0.782 | 0.070/0.774 | 0.020/0.815 | |
| III | 0.013/0.767 | 0.037/0.748 | 0.017/0.759 | 0.013/0.766 | 0.037/0.748 | 0.017/0.761 | |
| IV | 0.005/0.735 | 0.024/0.684 | 0.004/0.699 | 0.006/0.728 | 0.012/0.683 | 0.004/0.724 | |
| 50 | I | 0.080/0.870 | 0.210/0.747 | 0.110/0.841 | 0.100/0.851 | 0.200/0.756 | 0.100/0.851 |
| II | 0.010/0.861 | 0.060/0.726 | 0.030/0.837 | 0.010/0.818 | 0.060/0.746 | 0.020/0.828 | |
| III | 0.008/0.819 | 0.017/0.719 | 0.016/0.816 | 0.008/0.798 | 0.010/0.713 | 0.012/0.798 | |
| IV | 0.002/0.716 | 0.008/0.679 | 0.002/0.799 | 0.005/0.699 | 0.003/0.697 | 0.004/0.763 |
Fuente: elaboración propia.
Se puede observar que la estrategia de combinar Jackknife, aumentado el grado de delete, con las transformaciones empieza a mostrar algunas estimaciones con menores tasas de error y mayor índice de calidad. Esto coincide con lo reportado en [6], donde se vio la mejora de las estimaciones usando transformación log para los intervalos de confianza en la función de confiabilidad. Es de resaltar que se espera que el índice aumente cuando se disminuyen las tasas de error. No obstante, eso no siempre se cumple, ya que el resultado del índice puede estar influenciado por la amplitud y el sesgo de los IC. Pese a esto, los índices son adecuados para comparar las estimaciones mediante IC para la función de confiabilidad. En la tabla 3 son presentados los resultados en la situación más extrema del estudio; con mayores porcentajes de datos censurados.
Tabla 3 T.E/I con 50% de datos censurados a derecha.
| n | delete | KM | log KM | log(-log) KM | NA | log(NA) | log(-log) NA |
|---|---|---|---|---|---|---|---|
| 10 | I | 0.122/0.699 | 0.136/0.688 | 0.125/0.697 | 0.122/0.699 | 0.134/0.690 | 0.119/0.702 |
| II | 0.084/0.614 | 0.084/0.614 | 0.022/0.656 | 0.084/0.614 | 0.094/0.607 | 0.022/0.656 | |
| III | 0.012/0.562 | 0.028/0.553 | 0.004/0.567 | 0.024/0.555 | 0.030/0.552 | 0.002/0.568 | |
| IV | 0.009/0.441 | 0.012/0.438 | 0.001/0.401 | 0.011/0.440 | 0.018/0.438 | 0.001/0.443 | |
| 25 | I | 0.280/0.651 | 0.408/0.535 | 0.063/0.847 | 0.295/0.637 | 0.433/0.513 | 0.062/0.848 |
| II | 0.188/0.608 | 0.262/0.618 | 0.018/0.823 | 0.210/0.662 | 0.266/0.615 | 0.018/0.823 | |
| III | 0.180/0.653 | 0.220/0.621 | 0.040/0.764 | 0.180/0.653 | 0.220/0.621 | 0.040/0.764 | |
| IV | 0.300/0.535 | 0.300/0.535 | 0.100/0.688 | 0.300/0.535 | 0.300/0.535 | 0.100/0.688 | |
| 50 | I | 0.486/0.489 | 0.614/0.367 | 0.354/0.615 | 0.507/0.469 | 0.630/0.352 | 0.374/0.596 |
| II | 0.308/0.628 | 0.448/0.501 | 0.012/0.897 | 0.324/0.614 | 0.462/0.488 | 0.014/0.895 | |
| III | 0.260/0.647 | 0.280/0.630 | 0.000/0.875 | 0.260/0.647 | 0.280/0.630 | 0.000/0.875 | |
| IV | 0.229/0.775 | 0.229/0.786 | 0.000/0.898 | 0.229/0.757 | 0.255/0.709 | 0.000/0.889 |
Fuente: elaboración propia.
La tabla 3 indica que la estrategia de transformación log(-log) con remuestreo Jackknife funciona en situaciones de altos porcentaje de datos censurados (50%). Asimismo, muestra menores T.E y mayores I, confirmando la hipótesis de que combinar las dos estrategias (remuestreo y transformaciones) reduce un poco la variabilidad en las estimaciones.
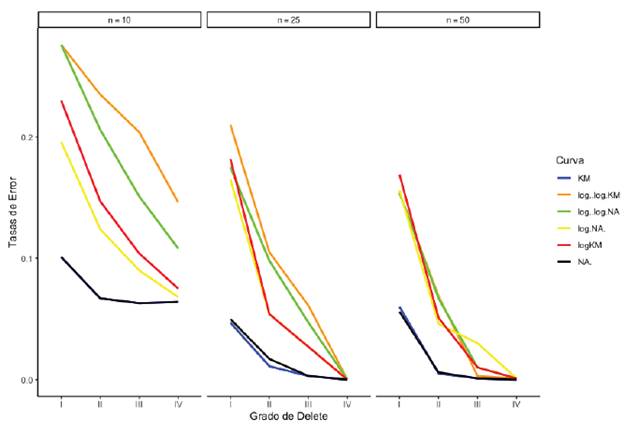
En la figura 1 se expone que en general la tendencia es decreciente, indicando que cuando todos los datos de muestra son observados, las tasas de error disminuyen conforme aumenta el grado de delete, independientemente del tamaño de la muestra. En el grupo de transformaciones (log(-log) KM: línea naranja, log(-log) NA: línea verde, log NA: línea amarilla, log KM: línea roja) y en el grupo de tradicionales sin transformación (KM: línea azul, NA: línea negra) se evidencian posibles agrupaciones de comportamientos cuando se aumenta el tamaño de muestra. Finalmente, se presentan las situaciones de 15% y 50% de datos censurados en las figuras 2 y 3, respectivamente.
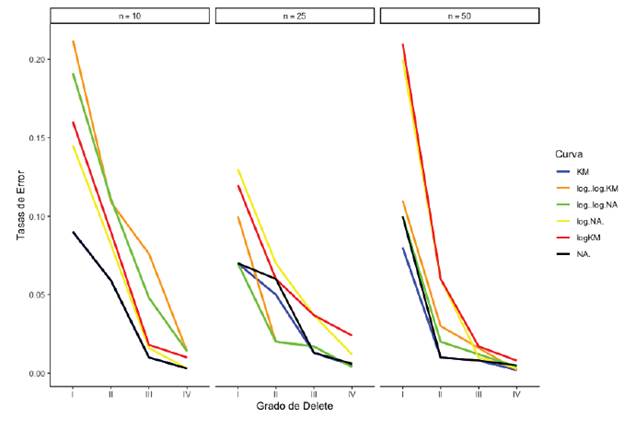
La figura 2 muestra el comportamiento similar de decrecimiento en las tasas de error cuando se aumenta el grado de delete. Igualmente, se puede ver que los estimadores sin las transformaciones log y log(-log) pueden ser equivalentemente buenas opciones cuando los porcentajes de censura son bajos (15%).
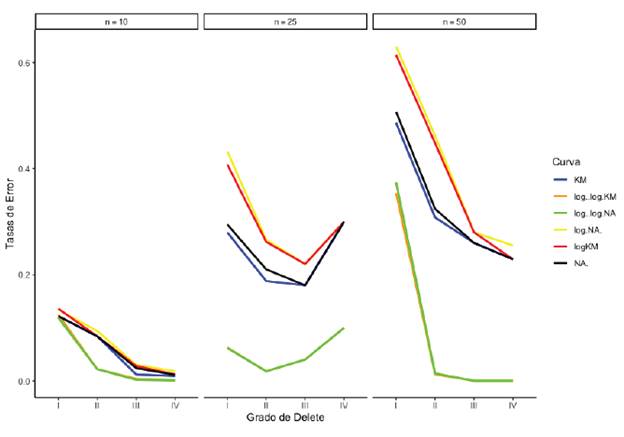
Por su parte, en la figura 3, se evidencia que cuando se aumenta el porcentaje de datos censurados en la muestra, la transformación log(-log) ayuda a disminuir las tasas de error, resultando muy similares los comportamientos al utilizar o Kaplan-Meier y Nelson-Aalen, independientemente del grado de delete.
La reducción de tasas de error al utilizar la estrategia combinada cuando los tamaños de muestra aumentan, confirma los resultados de [21] para el caso de la transformación log(-log), sin remues-treo Jackknife. Cabe mencionar que el tiempo de ejecución para obtener los resultados depende de forma sustancial del aumento del grado (d) de Jackknife y los tamaños de muestra (aproximadamente exponencial). Por otra parte, aunque para la deducción de los intervalos se requieran funciones que cambien la escala de medida, el intervalo final calculado preserva dicha característica de escala original de la unidad de tiempo.
Conclusiones y recomendaciones
La combinación de estrategias de remuestreo Jackknife delete-IV con la transformación en situaciones de altos porcentajes de censura (50%) funciona. Lo anterior ayuda a reducir las tasas de error en un promedio del 20% y aumentar el índice de calidad, independientemente del estimador no paramétrico Kaplan-Meier y Nelson-Aalen. Esto coincide con los resultados reportados por Ramirez-Montoya en la tendencia de mejora en la estimación usando sin remuestreo Jackknife [21].
Además, se puede afirmar que cuando la cantidad de datos censurados aumenta en la muestra, la afectación en la estimación del error es alta. Cambios de 0% a 50% de datos censurados aumentan el rango de error en promedio cinco veces más, disminuyendo levemente al aumentar el grado de delete en Jackknife [6]. Lo cual ocurre de manera similar en la investigación de Kumar-Mahto et al. [10]. En algunos otros estudios relacionados [21] también se reduce el error de estimación de la función de confiabilidad [22] con remuestreo Jackknife aumentando el grado de delete.
Después de concluido este trabajo, se recomienda tener un recurso computacional alto para estudiar la función de confiabilidad combinando remuestreo Jackknife y transformaciones con datos que contienen observaciones censuradas. Asimismo, se recomienda para estudios futuros proponer otro lenguaje de programación para acelerar la obtención de los resultados de horas a segundos.

