Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkINTRODUCCIÓN Y CONTEXTO
Desde antes del 2006, el gobierno colombiano, a través del Departamento Nacional de Planeación DNP, contrataba analistas privados -como Guillermo Rivas Mayorga, especialista en estadística- para analizar los datos recogidos por las encuestas del Departamento Administrativo Nacional de Estadística, DANE, entidad subordinada al DNP, y asesorar al gobierno. En el Sexto Reporte de este asesor a DNP, hallado a mediados de 2011, aparece el Cuadro 7 que contiene series completas de datos presentados en forma de deciles de distribución para los años 2002 a 2007 entregadas a él por DANE-DNP, donde están los dos años censurados que son objeto y eje de este estudio. Una copia del Cuadro 7 -que no hizo público el gobierno de Alvaro Uribe- se presenta más adelante en el momento de analizarlo. El documento menciona que entre las actividades del asesor figuraba la “Participación en reuniones interinstitucionales con DANE, CEPAL y Banco Mundial, para definir agendas de trabajo que permitan actualizar la metodología de medición de la pobreza que se utiliza en Colombia”. En su reporte, el asesor suele emplear como referencia de datos y cuadros la frase “Fuente: Cálculos propios con base en DANE ECH 2002-2006 y GEIH-2007 (Segundos bimestres) DNP-DDS”, donde ECH es la sigla de Encuesta Continua de Hogares y GEIH la de Gran Encuesta Integrada de Hogares. También acepta el asesor que entre 2002 y 2007 la población de pobres e indigentes no cambió porcentualmente y que “Como era de esperarse, el coeficiente de Gini tuvo un gran incremento entre el segundo trimestre de 2006 y 2007 al pasar de 0.54 a 0.59, gráfico 6, debido al considerable deterioro de la distribución del ingreso mostrado anteriormente” (Sexto Reporte: 2007, 2,3,11).
Otros datos aquí empleados sobre las líneas de pobreza provienen de publicaciones de Dane-DNP, de un reporte de la Universidad Nacional y de algunas declaraciones públicas de funcionarios y críticos tomadas de los debates surgidos sobre el tema.
Hasta el año 2005 el DANE estimaba la desigualdad de ingresos monetarios a partir de encuestas nacionales que abarcaban dos subconjuntos: 1) “Cabeceras” urbanas, C, y sus zonas próximas de 4 a 13 ciudades mayores y 2) El “Resto”, R, que abarcaba supuestamente las demás urbes menores y sus zonas rurales. Procesaban los datos para cada sector mediante el método antiguo usando solo dos variables: ingresos monetarios y poblaciones receptoras. Luego integraban C y R en el Total, T, y publicaban resultados semiprocesados en forma de series de deciles de distribución anual con sus respectivos ingresos promedios para las dos partes y para el conjunto total. Casi siempre omitían un dato clave: las fracciones de población de C y R en el total estudiado, T.
A su vez calculaban por aparte las cuatro “líneas de pobreza” que definían el ingreso monetario per cápita de pobreza moderada LPM y de pobreza extrema, LPE, para los dos sectores C y R. Estas líneas se emplean para delimitar y contar la población que vive en situación de pobreza moderada y extrema en los dos sectores, lo cual supone aplicarlas a la función de distribución acumulada, FDA, de cada sector para cada año estudiado. Tanto las LPM, como las LPE y las poblaciones resultantes en estado de pobreza, PM y PE, son distintas para los dos sectores encuestados de C, R y varían de año a año. Esas líneas de pobreza operan como las varas empleadas en el salto alto de atletismo: entre más altas se colocan, menos deportistas las superan y quedan más personas en condición de excluidos (en condiciones de pobreza moderada y extrema en nuestro caso). A la relación LPM/LPE de cada sector la llaman Coeficiente de Orshansky, CO, un parámetro de uso reciente en el análisis del método y sus premisas implícitas. Este CO requiere precaución y ética en su manejo porque puede ser usado para rebajar el número de pobres moderados y extremos disminuyendo al mismo tiempo la línea LPE y el parámetro CO. Las líneas de pobreza son de tipo normativo y es el gobierno el que define, justifica y postula su método de cálculo y sus valores para cada sector y cada tipo de pobreza, así como los métodos usados para ello.
En el año 2000 el gobierno de Colombia aprobó los Objetivos del Milenio, ODM, ante la ONU. Cinco años más tarde el gobierno aún no había realizado avances importantes en la ejecución de las metas convenidas en materia de pobreza y desigualdad ante la ONU. Un reporte académico del Centro para la Investigación del Desarrollo de la Universidad Nacional (CID-UNAL: 2006) planteó el debate basado en datos oficiales de ingreso del 2004. Dicho reporte cuestionaba las metodologías empleadas por DANE-DNP, el incumplimiento en los ODM, la existencia de cifras oficiales sesgadas por la influencia política, así como el silencio e indiferencia del gobierno frente al debate crítico propuesto por los autores del estudio, a pesar de que este fue hecho únicamente con datos oficiales (CID-UNAL, 2006: 43).
En septiembre de 2007 la Revista Semana publicó el artículo “¿Gobierno pretende manipular las cifras del Dane para mostrar puntos a su favor?” (Paredes, 2007) en el que dice:
“POLÉMICA La pregunta está en boca de todo el mundo. ¿Hay pruebas? Al menos los dos últimos directores del organismo más importante del país abandonaron su cargo con la afirmación de que se sentían presionados. ¿Qué pasa en el Dane? Un director del Dane renunció en el 2004, el siguiente director en el 2007”.
Según el mismo artículo, mientras el gobierno hablaba de crecimiento económico firme del 6% anual, se habían perdido 700.000 empleos. La entonces senadora Cecilia López es citada en el artículo argumentando que “Una de las razones con mayor peso fue que la Institución depende directamente del gobierno, lo que podría prestarse para la politización de los datos, en un contexto donde el presidente Uribe se vale constantemente de las cifras para argumentar a favor de los resultados de su gestión”.
Debido a que Alvaro Uribe fue reelecto en 2006, él mismo se vio en la necesidad de publicar y justificar los resultados de su primer período, situación que se repitió cuando emprendió la búsqueda de su segunda reelección para el año 2010, justo cuando los indicadores de distribución y pobreza no mostraban avances notables en la lucha contra la pobreza durante toda su gestión. Su gobierno manejó el asunto de manera muy reservada en esos años a través de un comité llamado MERPD, dependiente del DNP, dedicado al estudio del asunto. Poco después ese comité fue reemplazado por otro parecido, MESEP, una mesa de trabajo controlada por DANE-DNP donde participaban funcionarios, expertos internacionales del Banco Mundial y la Cepal, delegados del sector privado (Fedesarrollo) y un par de profesores universitarios, entre otros.
Sorpresivamente, en julio 20 de 2010 el ya saliente presidente Uribe destapó sus cartas cuando disertó sobre aspectos metodológicos y detalles técnicos del tema en su última rendición de cuentas ante el congreso de la nación, pocos días antes de entregar el gobierno a su sucesor Juan Manuel Santos. En dicho discurso dio algunas cifras dispersas, exaltó los avances sociales obtenidos en sus dos períodos de gobierno, invocó a los “expertos” y sus métodos nuevos basados en mediciones de Necesidades Básicas Insatisfechas, NBI; habló de otro concepto de pobreza, de los procedimientos desarrollados en la Universidad de Oxford-Inglaterra; del Indice de Pobreza Multidimensional, IPM-Oxford, basado en las NBI; y recomendó continuar esa política de su gobierno que nos llevaría a la prosperidad, si se financiaba de manera adecuada. Esta intervención es políticamente relevante porque en ella el expresidente Uribe asumió la autoría del cambio del método estadístico como logro y responsabilidad de su administración.
Durante el primer semestre del 2011 -cuando Santos ya ejercía su mandato- aparecieron en la prensa informes de serios problemas en las encuestas del DANE de los años 2006 y 2007. Casi al mismo tiempo, Santos anunció los nuevos proyectos de desarrollo nacional denominados “Locomotoras del Progreso” y “Prosperidad para Todos”. Al publicar las cifras oficiales empezó un debate público alrededor de las líneas de pobreza dictadas por el gobierno porque no eran coherentes con la experiencia cotidiana de la gente de las clases medias y populares. Santos y su equipo económico seguían la ruta trazada por Uribe, basada en evitar la medición antigua de las pobrezas monetarias, introducir el nuevo método Oxford, e invocar el reciente aval dado por la ONU a ese método en su Informe de Desarrollo Humano, UNHDR-2010, publicado a comienzos del año 2011, y prologado por Amartya Sen unos seis meses después del discurso de Uribe cuando el método IPM aún no tenía reconocimiento internacional.
Este estudio se centra en los datos monetarios completos entregados al asesor y censurados luego por DNP; los recupera, presenta y analiza; comprueba que las malas prácticas oficiales no surgieron de fallas de encuestas en el 2006: ya venían por lo menos desde el año 2002. Algunas de ellas provienen de errores teóricos inadvertidos por Dane-DNP, otras serían producto de una muy probable manipulación de los datos. Esas irregularidades pueden evidenciarse con matemáticas simples de promedios, teoría de conjuntos y probabilidades aplicadas al Cuadro 7 y a otros informes y tablas publicadas por Dane-Dnp. Ellas refuerzan otras observaciones críticas hechas por algunos analistas del tema. El objetivo es responder con estas evidencias y razonamientos a la pregunta clave de la revista Semana: ¿Hay pruebas?
El estudio concluye que sí hay indicios claros con potencial de constituirse en pruebas sólidas. Los presenta junto a algunas conclusiones y recomienda que sean contrastadas, verificadas y complementadas; que el debate continúe, que se mejoren los métodos oficiales de manejo y publicación de datos y resultados; y en especial, que se fomenten auditorías calificadas para controlar las estadísticas oficiales de pobreza y sus métodos por parte de la academia, instituciones científicas y ciudadanos capacitados para esa labor de control, tal como lo sugirió el estudio del CID-UNAL desde 2006.
Transcripción del Cuadro 7 del Sexto Reporte del asesor del DNP, 2011
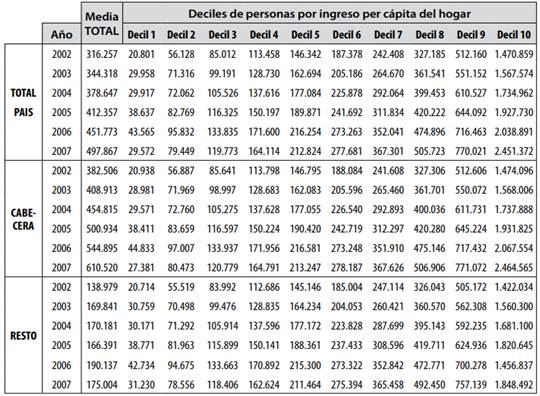
El hallazgo del Cuadro 7 en 2011 aportó información que no había sido publicada por el estado. Contiene los datos resumidos y completos para el período 2002-2007 tal como los entregó DNP al asesor en octubre de 2007 para uno de sus contratos. Se basa en deciles, o grupos de 10% de la población para los cuales se informa la fracción recibida del ingreso, o botín repartido en dinero per cápitames, para el sector C o R de cada año por aparte. Este tipo de datos semiprocesados son una manera resumida y conveniente de presentación para los analistas independientes porque las bases de datos recogidas en las encuestas son de gran tamaño y manejo muy laborioso. El Cuadro 7 aquí presentado es una transcripción personal tomada de la fotocopia original que aparece en el Sexto Reporte del asesor en formato pdf, la cual sale inclinada y algo borrosa, pero legible si no se compacta.
En su tercera columna del lado izquierdo, TOTAL, el Cuadro 7 presenta los promedios oficiales de ingresos para los diez deciles en unidades monetarias reales ($ corrientes por persona mensual) para cada año de C, R y T. Los diez deciles a promediar aparecen en el sector derecho del cuadro. La parte superior presenta una fila TOTAL que entrega los promedios oficiales de T, C y R para cada año reportado. En el reporte del asesor no figuran los porcentajes de población de C y R que componen el 100% de pobladores; esta es una omisión grave que le resta seriedad y transparencia a la información estatal entregada al contratista, y en general no suelen entregarla ni los reportes oficiales, ni los de Cepal, ni los de la ONU.
Es preciso aclarar que para 2002-2005 la Cabecera comprendía hasta 13 núcleos urbanos mayores del país -según DANE-DNP-, y para los años 2006-2007 el gobierno habla de 23 núcleos C y 23 del sector R (el Resto), debido a una ampliación de cobertura de sus encuestas realizada en esa época. Aparte de estos cambios, no se encontraron en la Tabla 7 elementos ni proporciones anormales que justifiquen declararlos incompatibles, ni motivos para suprimirlos. El país tenía derecho a conocer toda la Tabla 7 pero el gobierno de entonces no la hizo pública; tan solo fue manejada por ellos y sus mesas de expertos. La encontré por casualidad cuando el gobierno Santos creó el portal de contrataciones públicas en la red, luego de un proceso largo de búsqueda y lectura de documentos oficiales relacionados con el tema.
El método de análisis empleado
Hay dos elementos claves que deben tenerse en cuenta siempre y verificarse por separado para los sectores C, R y para T:
El valor monetario del ingreso promedio del país que suele ser afectado por el desempeño económico, la inflación, el empleo y el cambio de población.
La distribución estructural de ingreso -en forma de deciles o cuantiles adimensionales- que suelen ser presentados como tablas de deciles fraccionarios.
Ambos elementos inciden en el bienestar económico. El primero porque refleja el crecimiento real de la economía en precios de poder adquisitivo real; el segundo porque refleja la desigualdad estructural de la economía durante el año y el reparto estadístico entre diez capas sociales. El estudio se centra en el segundo aspecto, aceptando que el primero de ellos también influye en el bienestar comunitario.
En esencia el método empleado es así: a partir de los deciles adimensionales se calculan los componentes de la curva de Lorenz, CL, y se elabora su Función de Distribución Acumulativa, FDA, en medias, para aplicar sobre ésta las líneas de pobreza moderada y extrema, LPM y LPE en cada sector y año. Basta dividir LP/U -donde U es la media en valores reales- y se obtiene LP/U expresada en medias de la distribución. Esto debe hacerse para los valores de pobreza moderada y extrema dictados por el gobierno, para cada sector C y R en cada año. Luego se aplican estas líneas a la curva FDA del respectivo sector anual y se obtienen las poblaciones que superan esas líneas, así como las que no las superan y están en esa clase de pobreza. La bibliografía al final del texto presenta dos textos que explican el método con mayor detalle para los lectores interesados en su aplicación (Chaves, 2011) y (Chaves, 2009).
Para calcular la pobreza total es preciso ponderar las poblaciones en pobreza resultantes según las fracciones de población de C y R que deberían ser aportadas cuando se entreguen estos datos, pero no es frecuente que Dane-DNP incluyan estas fracciones junto a las tablas de deciles.
Controles básicos aplicados a datos de Cuadro 7.
A partir de los datos del Cuadro 7 del DANE-DNP se hicieron dos cálculos básicos para el control de su coherencia interna:
Se recalcularon los promedios de los diez deciles para cada sector C, R y su total T de cada año. Es de esperar que el resultado sea siempre igual al que aparece reportado en la columna Total del Cuadro 7 para C, R y el total de la nación. El objetivo es verificar la corrección y coherencia entre los promedios oficiales declarados y los estimados aquí.
Debido a que Dane-DNP no informan las fracciones de población respecto al país, se aplicó el método indirecto siguiente: Si llamamos X a la fracción de población de C, entonces 1-X es la fracción de población de R, y si C y R son los promedios de ingreso, entonces debe cumplirse para el ingreso promedio total T que:
CX + R(1-X) = T ….[1]…. para cada año reportado. De [1] se obtiene que …
X = ( T-R ) / ( C-R ) …[2] … para estimar X conocidos los promedios de ingreso de T, C y R.
El propósito es determinar las fracciones de población implícitas de Cabecera y Resto, que no fueron informadas por DANE-DNP, pero fueron usadas para ponderar el promedio total, T, en base a los promedios de C, R, tanto para los datos oficiales de la Tabla 7 como para los promedios calculados aquí. El resultado se compara luego con las fracciones del censo de población.
Resultados principales
La Tabla 1 (pág. 255), resume los valores estimados versus los valores oficiales reportados según el Cuadro 7.
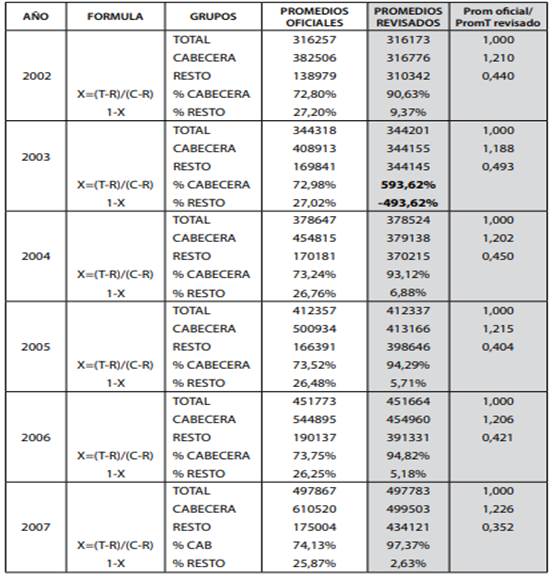
La columna del extremo derecho en la Tabla 1 muestra que la relación entre el valor oficial y el de la fila Total de Cabeceras ronda el valor 1.20, o sea que emplearon un valor cercano al 120% de la media de T para todos los años estudiados. De igual manera, la misma relación para R -el Resto- es cercano al 40% del promedio del Total, T, en todos los años entre 2002 y 2007. Esto debe ser explicado porque parece una premisa del modelo en el análisis de todos los años.
1. Los promedios estimados de las medias de C y R difieren completamente de los respectivos promedios oficiales publicados para todos los años. Esto es inaceptable porque deberían coincidir.
2. A pesar de lo anterior, el promedio calculado de T resultó virtualmente igual al promedio oficial de la columna Total. Se trata de un hecho sorprendente y repetido para seis años diferentes; esto solo puede ser producto de diseño intencional antes que del azar. Es muy extraño que al cambiar los promedios C y R se conserve el promedio de T. Para conservar el valor T a partir de promedios de C y R alterados es preciso cambiar las fracciones originales de población X de C, y 1-X de R con gran precisión.
Al calcular los valores Xc oficiales obtenemos que rondan el 73% de población total para C, y el saldo 27% corresponde a la población del Resto, cifras que son coherentes con los censos de población. Pero al hacer el mismo cálculo para los promedios corregidos reales, resulta que la fracción de población de C es superior al 90%, supera el 100% en 2003 y llega al 97% en 2007: parece que al alterar los promedios olvidaron que cambian internamente las fracciones de población de C y R si deciden conservar el promedio total T. Pero lo más sorprendente es que en el año 2003 la fracción de población Xc llega al 594% y la de Xr= - 494%: algo absurdo en la realidad pero posible en matemáticas porque los límites de un modelo matemático hecho con datos alterados pueden salirse de los límites de la lógica de conjuntos. Esto se debe a que los promedios de deciles de C,R y T del año 2003 son muy cercanos entre sí, además de que el promedio de T, que debería estar entre el de C y R, resultó superior al de C, la Cabecera en ese año.
En conclusión, los promedios de C,R oficiales son erróneos, aunque sus fracciones de población son correctas, e incluyen las proporciones de 120% y 40% ya señaladas, mientras que en el cálculo de control los promedios obtenidos son los correctos para C y R, pero sus fracciones implícitas de población necesariamente cambiaron internamente. Una posible razón es que las encuestas de R, Resto, quizás solo habrían sido hechas para las zonas rurales cercanas a las grandes urbes y no sobre el Resto real del país y que al presentarlas olvidaron conservar el 120% del Total nacional como media de las Cabeceras y el 40% del promedio Total como media del sector Resto.
4. ¿Cómo inciden esas alteraciones comentadas en los deciles oficiales de T, C y R? Ocurre que cada subconjunto C y R debe ser calculado por aparte -respecto a sí mismo- en una primera etapa “endógena” del análisis para cada año y sector.
Para el Cuadro 7 se aplica que el promedio en medias de la distribución de cada decil, Ki puede calcularse como: Ki = Di / Ui donde Di es el promedio monetario de cada decil, y Ui es el promedio monetario de los diez deciles que forman la fila -la media del sector-. Las unidades de Ki resultan así en medias adimensionales de ingreso.
A su vez la fracción elemental Yi que cada decil recibe del total repartido sectorial se expresa como Yi = 0.1 *Ki = 0.1* Di/Ui … (si se usaran quintiles se usaría 0.2 en lugar de 0.1)
Al hacer estos cálculos, la suma de los 10 deciles Yi elementales debe dar la unidad, lo cual permite calcular y graficar la CL e inferir luego la FDA. Pero si por algún motivo se usa un valor equivocado o alterado del promedio endógeno total Ui, inmediatamente se alteran todos los deciles y su suma ya no da la unidad: si se usa un valor de U más alto que el real la suma resulta inferior a 1; si se usa un valor de U más bajo la suma da un valor mayor de 1. En resumen, se deforma la tabla de deciles junto a la curva de Lorenz, CL, para los sectores Cabecera y Resto, lo cual impide a su vez hacer un modelo matemático satisfactorio de esas CL y distorsiona cualquier análisis y cálculo posterior. También colapsa la coherencia lógico-matemática del modelo de análisis de cada sector respecto a sí mismo, y más tarde la del total, T, que resulta de integrar los datos de C y R teniendo en cuenta sus participaciones en la población total y en el ingreso total.
Es obligatorio preguntar entonces: ¿Por qué distorsionaron los promedios para producir semejantes resultados en las poblaciones asignadas a los dos grupos C y R, sin alterar los promedios del Total, T? Además, si invocan que el cambio de método de encuestas del 2006-2007 hizo incompatibles y deficientes los resulta- dos de esos años, entonces ¿cómo explican que desde el año 2002 -y quizás desde antes- venían ocurriendo las alteraciones señaladas que no tienen nada que ver con los supuestos errores en la ejecución de las encuestas de los años 2006-2007?
La Tabla 2 muestra la deformación ocurrida para el año 2002, lo cual puede hacerse para los demás años con resultados similares. De este análisis queda claro que lo único que ha permanecido intacto son los datos deciles originales de la parte derecha del Cuadro 7 del asesor, tal como se los entregó DANE-DNP para hacer su trabajo aunque no estén multiplicados por 1.2 para Cabeceras y por 0.4 para el Resto, lo que igualaría los promedios de toda la tabla.
Tabla 2: INCOHERENCIAS ENTRE DECILES ESTIMADOS, OFICIALES Y DECILES A CEPAL
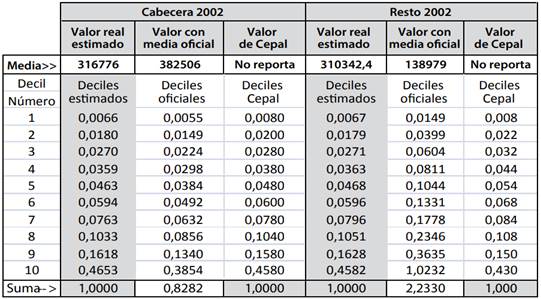
Fuentes: (Rivas, G; 2007) (Cepal) Cálculos propios.
Lo más posible es que la manipulación irregular ocurrió en la fase de interpretación final de los datos previamente recolectados y aprobados por DANE-DNP. Solo podemos evidenciar el hecho anómalo ocurrido y pedir las correspondientes explicaciones al gobierno de entonces.
En la Tabla 2 pueden observarse estas anomalías junto a otra adicional consistente en que la Cepal publicó en uno de sus reportes los deciles (en fracción) de los sectores Urbano, Rural y Total que producen índices de Gini inferiores con valores distintos a los estimados desde el Cuadro 7. En estos datos Cepal usa el término “sector Urbano” similar al de Cabeceras, y sector “Rural “ similar al sector Resto de DNP, sin entregar los ingresos promedios de sus sectores, ni de su total, ni sus fracciones de población. Esta ausencia de datos claves devalúa esas tablas y las hace casi inútiles. Debido a que la Cepal trabaja sobre datos entregados por cada gobierno miembro, se puede decir que la Cepal avaló los datos recibidos sin confrontarlos y que a la vez, unos son los datos transmitidos a la Cepal por el gobierno y otros son los entregados a sus asesores privados para asesorar sus mesas técnicas, datos que ni siquiera fueron informados a tiempo a los analistas independientes del país, ni a los medios de comunicación pública.
Una posible hipótesis explicativa es que el gobierno y la Cepal han creado un círculo de avales mutuos sobre datos duplicados y distintos para el mismo fenómeno, dando lugar a una especie de error a dúo; esta práctica quizás también se extiende a otras instituciones internacionales que procesan y publican esta clase de datos en sus reportes, además de asesorar los procedimientos y métodos econométricos que deben seguir los países del mundo para recibir su aprobación.
¿Para qué sirven los expertos de Cepal y BM que invita y paga el país para asesorar las mesas de trabajo y comités de expertos en desigualdad y pobrezas de DANE-DNP como la MERPD y MESEP? Parece que son los encargados de concertar los detalles para fortalecer la relación endogámica de “yo te avalo, tú me avalas, ambos nos fortalecemos” y explicar las modificaciones de método que luego publican en costosos eventos internacionales, reportes y libros construidos sobre cifras y cálculos que tan solo ellos controlan, sin vigilar de manera autocrítica su coherencia interna ni su grado de veracidad. Esa pregunta vale también para las mismas mesas técnicas como MERPD y MESEP coordinadas por Dane-DNP y los altos comités que orientan la política económica y social del gobierno.
OTROS ERRORES TEÓRICOS RELACIONADOS CON LAS LÍNEAS DE POBREZA
En los últimos tres años Dane-DNP, sus funcionarios y mesas de trabajo han publicado numerosos reportes, documentos y comunicados sobre el tema. También han divulgado tablas de Líneas de Pobreza en las que aparecen los valores del ingreso asignado a la pobreza moderada, LPM, a la pobreza extrema, LPE, y a la pobreza Total. Al aplicar el criterio de la fórmula x=(T-R)/(C-R) se encontraron numerosos casos en los que emplearon el mismo valor de X del año estudiado para estimar líneas nacionales de pobreza “total”, LPM y LPE, ponderando sus valores respecto a la población X de Cabeceras y (1-X) del sector Resto, R. Esta operación no tiene sentido porque las líneas de pobreza son propias de cada sector, son normativas y resultantes de análisis endógenos distintos que son elaborados bajo control del estado y luego publicados por este. Esto se explica a continuación con un ejemplo imaginario.
Supongamos que en una sociedad: 1) hay dos grupos distintos C y R que poseen respectivamente el 60% y el 40% de la población; 2) en el grupo C la ley autoriza a formar pareja a los mayores de 18 años y en el grupo R a los mayores de 16 años; 3) en el grupo C el 50% es mayor de 18 años y en el grupo R solo el 30% de población supera los 16 años. Surgen las siguientes preguntas que requieren un manejo claro de lógica de conjuntos, probabilidades y normas:
¿Qué porcentajes de la población de C, de R y del total T pueden formar pareja?
¿Es lícito aplicar el mismo cálculo para estimar una edad legal para el total, T, y calcular a partir de esta la población de T que puede formar pareja en el nivel nacional?
Las respuestas a esas dos preguntas son:
En el grupo C el % de población respecto al Total que puede formar pareja es 0.6*0.5=30% del total. En el grupo R ese % del total nacional es 0.4*0.3= 12% del total. Esto significa que en total el 42%=30%+12% son aptos para formar pareja en el universo que integra las dos poblaciones. Este es un cálculo ponderado de poblaciones aptas respecto a sus fracciones de población y es válido.
En este caso no es lícito intentar calcular una edad promedio normativa para el total, T, a partir de ponderar las normas grupales, porque son dos grupos distintos y disyuntos que no comparten las mismas normas. Aún más, sería peor intentar medir la población apta para formar pareja aplicando ese falso promedio normativo a la distribución FDA de T, la cual es estructuralmente distinta a las partes, aunque esas partes lo conformen. Hacerlo puede producir cualquier resultado erróneo sobre la población total apta para ser pareja. La explicación reside en que los criterios selectivos de tipo normativo solo son aplicables al sector para el cual se definen y aplican; no se pueden mezclar, de modo que solo aceptan cálculos estrictamente endógenos. Hechos estos, entonces se pueden sumar solo los valores de pobladores que clasifican para las dos normas regionales, pero esta cifra no debe emplearse para estimar una “normatividad promedio” supuestamente válida para el total general.
En el caso de las líneas de pobreza, eso equivale a desconocer la diversidad entre C y R asumida al hacer encuestas separadas y comprobadas por el hecho de que arrojan características propias distintas en las encuestas. No existen líneas de pobreza -moderadas o extremas- únicas aplicables a todo el universo muestral cuando se trabaja en base a dos sectores estructuralmente distintos.
Esto genera la pregunta sobre si cada región requiere líneas de pobreza monetarias propias. La respuesta es sí. Por simplicidad y dado el hecho de que los ingresos promedios y sus poblaciones varían de región a región, lo más práctico sería definir esas líneas en fracciones de la media de cada distribución regional. Por ejemplo si LPM=60$ y LPE=30$ en el sector C cuyo ingreso promedio fuese $100, se usaría el valor de LPM= 60% de la media y LPE 30% de la media, y cálculos similares se podrían hacer para el otro sector R, sin importar que posea menor ingreso promedio, culturas de consumo distintas y precios diferentes de mercado. Esto produce el concepto de pobrezas relativas y deben ser entendidas incorporando el ingreso promedio monetario de cada región también en medias.
Para cada sector hay así 4 datos básicos que deben ser informados junto a su tabla de deciles: 1) el ingreso real promedio en medias de T, 2) su fracción poblacional respecto al país Total, 3) Líneas de pobreza en fracción de la media de cada sector y tipo de pobreza, 4) las poblaciones pobres relativas halladas en las respectivas curvas FDA de distribución acumulativa regionales usando datos del anterior punto tres, 5) la población pobre del total que se obtendría ponderando los resultados del anterior punto cuatro con las fracciones de población del punto dos, para ambos sectores.
EL MANEJO DEL COEFICIENTE DE ORSHANSKY
Para disminuir artificialmente el porcentaje de pobres basta con rebajar las líneas de pobreza empleadas, tanto para la LPM como la LPE, conservando ciertas proporciones entre ellas. Hay una manera indirecta y a la vez truculenta de hacerlo que utiliza el llamado coeficiente de Orshansky, CO, o relación CO = LPM/LPE. Por ejemplo, en Colombia según el gobierno CO “total” era cercano a 2.8 antes del año 2000, y como LPE era un 25% del ingreso promedio, entonces la LPM= 2.8*0.25=70% del ingreso promedio en el pasado. Para reducirla en ambos sectores, el equipo económico del gobierno consideró que el valor 2.8 era muy alto en comparación con un promedio calculado por Cepal para 10 de17 países latinoamericanos que era de valor 2.4; y en base a este frágil argumento adoptaron un CO de Orshansky “total” de 2.4, a la vez que bajaban gradualmente la LPE. Como resultado, la cantidad de pobres en Colombia ha venido bajando desde el 2002 hasta la fecha. Este método ha sido cuestionado fuertemente en los debates académicos que surgieron en 2011, mientras que en el 2006 los académicos ya cuestionaban los bajos valores de las nuevas líneas de pobreza oficiales al contrastarlas desde otros métodos más exigentes. Más adelante se presentan varios pasajes de los debates adelantados al respecto.
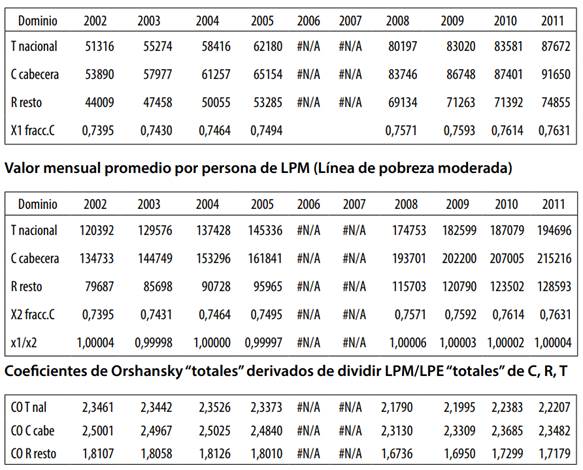
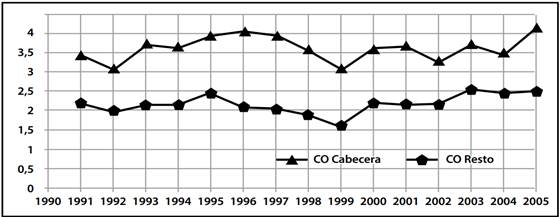
A partir del Cuadro 5 del reporte CID-Unal-2006 -que puede verse en el Anexo 2- se calcularon los respectivos coeficientes de Orshansky, CO, para los años 1991-2005 de los dos sectores C, R calculados en base a canastas de consumo. El siguiente Gráfico 1 muestra sus valores:
Puede observarse que desde 1991 el CO de C fluctuaba alrededor de 3.5 mientras que para R lo hacía alrededor de 2, según los datos recopilados por CID-UNAL. Pero al buscar datos similares elaborados por los mismos organismos del gobierno en 2012 encontramos que presentan valores para LPM “total” y LPE “total”. Al calcular para ellas los porcentajes de población implícita se encontró que las ponderaron usando las mismas fracciones de población tanto para C como para R. El siguiente Gráfico 2 muestra los CO derivados de esas líneas “totales” oficiales.
Ya explicamos que esas líneas “totales” carecen de validez; por lo tanto, emplearlas para calcular un CO “promedio” o “total” del país para C y R puede considerarse como un ejercicio inútil efectuado por los analistas oficiales. En el Anexo se presenta una transcripción de esas líneas de pobreza elaboradas por DNP donde aparecen las LPM Y LPE de C, de R y del “total T”. En base a estos valores calculamos los CO e igual hicimos para los datos del Cuadro 8 del asesor.
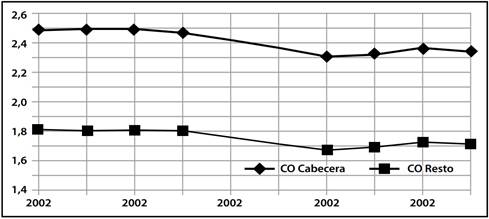
Fuente: (DNP; 2012). -Cálculos propios sobre datos-
Gráfico 2.- C. DE ORSHANSKY 2002-2011 SEGÚN DATOS DNP-2012
Aún si el CO “total” tuviera sentido lógico-matemático, era de esperar que su valor para C fuera cercano a 3,5; pero todos los valores se tornaron inferiores a 2.5 en el reporte del asesor, son inferiores a 2.35 en el reporte de DNP, y en ambos casos muestran una tendencia decreciente después de 2005. Como el estado tiene la potestad de establecer su valor para C y R, llama la atención que los nuevos valores del CO hayan sido drásticamente rebajados en relación a los del siglo pasado.
A partir de las cifras del Cuadro 8 mostrado en el Anexo 2, se pueden estimar los nuevos Coeficientes de Orshansky (CO) “totales” del asesor dividiendo la LP/ LI “totales”, para los años 2002-2007. El Cuadro 3B siguiente resume los cálculos.

Más adelante presentaremos las declaraciones empleadas por el estado para justificar estos cambios, así como algunas réplicas argumentadas durante los debates.
¿QUÉ ES EL NUEVO IPM, O INDICE DE POBREZA MULTIDIMENSIONAL DE LA U. DE OXFORD?
El IPM es un constructo matemático y metodológico elaborado por la U. de Oxford e inspirado en el Índice de Desarrollo Humano, IDH, de Amartya Sen. Fue publicado por la ONU al comenzar el año 2011, unos seis meses después de que Uribe lo mencionara como soporte de su discurso de despedida. El IPM es un indicador nuevo que mezcla y pondera de manera normativa numerosas variables no-monetarias para hacerlas cuantificables. En general miden el acceso a educación, salud, vías, agua potable, vivienda adecuada, empleo y otros servicios básicos que son precarios en las zonas rurales y en las periferias urbanas, mientras en las zonas urbanas abundan más y se pagan normalmente con impuestos recaudados del consumo y del ingreso monetario de los ciudadanos. Entienden la pobreza como el no-acceso a ciertas “oportunidades” sociales y a algunas libertades personales y políticas. Medir la pobreza desde ellas no solo requiere elegir decenas de variables -y descartar muchas otras posibles- sino además asignarles cifras y pesos específicos a cada una para mezclarlas y ponderarlas en un proceso que depende del criterio normativo, fines y preferencias de quienes manejen el modelo. Con ellos calculan numerosos porcentajes de poblaciones que no acceden a cada necesidad básica, las ponderan a su manera y luego elaboran numerosos índices de Gini para cada variable (o necesidad básica). Alkire-Foster, los ideólogos del IPM, citan un texto de Alkire y Amartya Sen donde claramente se aprecia la forma en que evaden el debate al respecto:
No es tanto una cuestión de hacer un referendum sobre los valores que se utilizarán, sino la necesidad de asegurarse de que los pesos específicos -o la escala de ponderaciones- utilizados permanezcan abiertos a la crítica y al escrutinio, y que aún así gocen de una aceptación pública razonable (Foster y Sen 1997, traducido del original) (Alkire, Foster: 2008, p. 28).
En otros términos, según Sen y Alkire, no hace falta debatir las premisas del método, basta con que tengan “aceptación pública razonable”. Pues bien, ese tipo de argumentos que trivializan y transfieren al público su responsabilidad subjetiva e indispensable para escoger las premisas faltantes -sin las cuales su modelo no funciona- son siempre cuestionables. Por un lado rompen el criterio de la cuchilla de Occam al introducir decenas de variables, pesos ponderados y líneas de corte -o de pobreza- que no someten a debate, por el otro miden cosas distintas a la pobreza monetaria, a la que cuestionan; y al final cierran el debate endosando su validez a algún mecanismo no especificado de “aceptación pública razonable”. El resultado es que introducen un modelo confuso con el que aspiran a sustituir otro modelo que si bien tiene sus puntos vulnerables, es mejorable, más claro, sencillo y preciso. Con ello le hacen un gran favor al sistema necesitado de suavizar y relativizar el tema de la distribución inequitativa del ingreso y del capital presente en los Objetivos del Milenio, que la ONU no sabía como manejar. Resulta muy cuestionable esta aplicación del aporte de Sen a la econometría de la justicia social mundial.
Es importante reconocer que las encuestas de NBI constituyen información valiosa y útil para programar y emprender acciones puntuales que lleven o mejoren los servicios faltantes a comunidades muy necesitadas de ellos, política que llaman “focalización del gasto público”. De realizarse ésta, mitigaría la dureza de vivir con poco ingreso monetario y ayudaría a reducir los desplazamientos forzados del campo a las grandes zonas urbanas, lo que bajaría el acaparamiento forzado de tierras y recursos por élites y empresas propias y externas que ha venido ocurriendo en estas décadas de políticas neoliberales.
El cambio de un método a otro nuevo requiere ser debatido y justificado en las instancias adecuadas. En el caso de Colombia el gobierno invocó supuestas fallas en las encuestas de 2006-2007, con lo cual ganaron tiempo para eludir el cumplimiento de los objetivos del milenio ODM, y para realizar convenios con la U. de Oxford para adaptar el nuevo método. Luego manipularon el manejo de los coeficientes de Orshansky y al final se cobijaron bajo el manto de la ONU cuando esta publicó su reporte UNDR-2010 a comienzos del 2011 en el que avala el nuevo método de pobrezas multidimensionales. Entonces publicaron el cambio de método y las primeras nuevas cifras favorables, argumentando que sostendrían los dos métodos por algunos años. Si a esto le sumamos la alteración comprobada de los promedios y fracciones de población que ya comentamos, más los datos deciles simultáneos pero distintos que fueron enviados a la Cepal, la confusión exige una pausa para repensar y corregir el camino a tomar.
RESUMEN DE ALGUNOS DE LOS DEBATES Y DISCURSOS SOBRE EL TEMA
1) El debate académico de la Universidad Nacional en 2006
El reporte de UNAL-CID de 2006 contiene más de 100 páginas y presenta un panorama general de la desigualdad social en Colombia-2004; sus autores hacen una clara invitación a abordar el tema y el debate con criterios académicos que controlen los métodos de procedimiento e impidan injerencias inaceptables por parte de personajes, sectores y entidades poderosas de la economía y de la política. Cito dos pasajes al respecto:
“2.2 EL DEBATE SOBRE LA POBREZA: CUANTA ES? Detrás de las cifras incluidas en los documentos del DNP y Presidencia de la República hay consideraciones sobre la medición de la pobreza que no son de conocimiento público y que, por tanto, es importante discutir. En nuestro informe anterior 27 hacíamos referencia al disgusto del gobierno nacional por la presentación de unas cifras que no coincidían con las oficiales y presentamos en un anexo la explicación del procedimiento metodológico y de la fuente de información. Desde entonces, el debate quedó silenciado y el gobierno solamente presenta como ciertas las cifras oficiales , desconociendo que hay otras alternativas. En esta ocasión, vamos a reiterar algunos aspectos de metodología y a contrastar los resultados gubernamentales con los CID ” (negrillas añadidas por autor) (CID-UNAL, 2006, p. 41).
“ El procedimiento de cálculo debería ser objeto de una norma ISO y acompañarse de veeduría ciudadana y académica. Por lo pronto, es un tema ligado a altos círculos donde intervienen unos pocos iniciados y las decisiones se toman con un doble criterio: técnico y político. El procedimiento es, en sí mismo, eminentemente técnico, sin embargo, la decisión de aceptar un número mayor o menor de pobres es política y depende de los funcionarios que aprueban o desaprueban el cálculo realizado. El gobierno nacional, de hecho, solamente acepta y revela como oficiales las cifras calculadas por el DNP, descartando cualquier otra alternativa, así ella provenga de la misma fuente de encuesta. Las diferencias entre las varias versiones de tamaños de pobreza se encuentran en alguna parte del procedimiento y, esencialmente, en la definición de la canasta de bienes y el valor de la misma ” (CID-UNAL, 2006, p. 43) (Negrillas añadidas por autor).
2) La academia y el debate sobre el coeficiente de Orshanskyen 2011
En el debate surgido a mediados del año 2011 hubo dos académicos de la U. Nacional que sostuvieron posiciones opuestas: Jorge Iván González -también miembro de la Mesep- asumió la defensa del nuevo método NBI escogido por DNP y Manuel Muñoz Conde quien lo criticó. Casualmente, el académico González fue uno de los dos coordinadores del reporte de CID-UNAL-06 que cuestionaba al DNP durante el primer período presidencial de Uribe y, al convertirse en miembro de la Mesep poco después, favoreció la posición en pro del nuevo método oficial tomado de Oxford. Esta es una cita de González tomada del debate de 2011:
Indigencia y pobreza. No existe ninguna definición absoluta de la pobreza. Una persona o una familia pueden sentirse “pobres” aunque su ingreso sea relativamente elevado, y viceversa, gentes de ingresos que otras personas consideran modestos no se ven a sí mismas como pobres. Por eso las definiciones de la pobreza son convencionales y no se pueden evaluar como “correctas” o “incorrectas” sino apenas como más o menos útiles para propósitos bien determinados (González, 2011).
El académico Muñoz Conde replicó a González con estas palabras, entre otras:
Pues bien: González en su artículo “clarificador” nos indica que a la Línea de Indigencia la multiplican por 2,4 para hallar la Línea de Pobreza. Ese valor del coeficiente de Orshansky es el promedio de los coeficientes de los países de América Latina … […] … ¿Acaso será muy populista preguntar por qué no se utilizó el coeficiente de Colombia, que es de 2,9? Con este simple cambio, la LP pasaría de 190.000 a 226.000 pesos, es decir aumenta un 20 por ciento ¿Qué pasaría entonces con la magnitud de la pobreza? (Muñoz, 2011).
3) El debate en el periódico The Guardian, Inglaterra, Agosto-Septiembrede2011
Al buscar aportes sobre el tema en la red, encontré que el diario inglés The Guardian publicó un artículo que suscitó un pequeño debate atendido por el autor Jonathan Glennie, especialista en temas latinoamericanos. La réplica más notable fue firmada por Sabina Alkire -Directora de OPHI (Oxford Poverty and Human Development Initiative) y diseñadora del método IPM en Inglaterrra- y por Yadira Díaz, exfuncionaria colombiana de Dane-DNP, asesora de diseño técnico del IPM adaptado para Colombia, y entonces estudiante de doctorado en la Universidad de Essex. A continuación cito algunas frases del artículo de Glennie cuya traducción es personal:
Colombia has become the first country in the world to announce a poverty reduction plan, with binding targets, based on a new “multidimensional” method of measuring poverty. The multidimensional poverty index (MPI) looks beyond income alone, and also assesses education, health and living standards (such as assets and housing).
(Colombia ha resultado el primer país del mundo que anuncia un plan de reducción de la pobreza, con objetivos vinculantes, basados en un nuevo método “multidimensional” de medición de la pobreza. El índice de pobreza multidimensional (IPM) mira más allá del simple ingreso, y también estima la educación, la salud y estándares de vida (como los servicios y la vivienda) -Traducción propia-.
The new Santos administration has made it clear that, after eight years of securitising the country under President Álvaro Uribe Vélez, it wants to bring prosperity and poverty reduction, a sincere and laudable aim.
(La nueva administración Santos ha dejado claro que, tras ocho años de la política de seguridad bajo el gobierno de Álvaro Uribe Vélez, quiere ahora traer prosperidad y reducción de la pobreza, una meta sincera y encomiable).
One initial concern with the MPI is that it appears to do Santos a huge political favour. According to the new measure, poverty levels are not at 64%, 28%, or even 16%. They are at 9%. What government could resist taking 3.1 million people out of poverty with a simple change in measurement methodology?
(Una reserva inicial sobre el método IPM es que parece hacerle a Santos un enorme favor político. Según la nueva medición, los niveles de pobreza no son del 64%, ni del 28%, ni siquiera del 16%. Ya están en el 9%. ¿Qué gobierno puede resistirse a sacar 3.1 millones de la pobreza mediante un simple cambio en la metodología de la medición?)
Since the MPI was launched in 2010, its proponents have emphasized that it seeks to complement rather than replace income measures.
(Desde que el Índice de Pobreza Multidimensional, IPM, fue lanzado en 2010, sus proponentes han enfatizado que buscan complementar antes que reemplazar las mediciones de ingreso.)
As well as counting poor people, researchers should apply the following ethics test to development strategies: if you displace 100 families from their land, is it possible that poverty indicators will actually improve? If the answer is yes, which it often is, there is something wrong or limited with the indicators. Perhaps some brilliant academic can devise a measure of poverty reduction that acknowledges this issue.
(Así como cuentan el número de pobres, los investigadores deberían aplicar el siguiente test ético a sus estrategias de desarrollo: ¿Si usted desplaza 100 familias de su tierra, es posible que los indicadores de pobreza mejoren realmente? Si la respuesta es que sí, lo que es frecuente, entonces hay algo erróneo o muy limitado con los indicadores. Quizás algún brillante académico pueda diseñar una medición de la reducción de pobreza que reconozca este aspecto) (Glennie, J. Agosto 30 de 2011, The Guardian, UK)
Este último comentario alude al fenómeno de los desplazamientos de población campesina de sus predios por causa de las violencias colombianas que produjeron gran despojo y transferencia de tierras a sectores latifundistas y provocaron a la vez importantes migraciones de campesinos a las zonas más pobres de las ciudades en busca de un entorno menos violento para subsistir. Puede argumentarse que dentro de sus NBI les faltó incluir como variable el derecho a no ser forzados a vender sus tierras, ni a ser desplazados a las urbes mediante amenazas y otros métodos violentos.
La diseñadora del método Oxford (Sabina Alkire) y la funcionaria Yadira Díaz replicaron pronto al analista Glennie con palabras como estos apartes entrecortados que cito ya traducidos:
1 September 2011 Jonathan … Tal como lo has explicado, el índice IPM del gobierno colombiano de hecho rebaja el porcentaje bajo la línea de pobreza (moderada) a 35% de la población (usando datos del 2008). Su meta es reducir la pobreza al 22% hacia el 2014 -una meta nada modesta-. Son cifras menores que las mostradas a partir de la línea de pobreza de ingresos, al menos para el 2006 cuando esta era de 45% de la población. ... Esas cifras vienen del IPM de Colombia, adaptadas nacionalmente y ya aceptadas, tal como fueron informadas por el Gobierno de Colombia a comienzos de este mes. Ellas mejoran otro índice multidimensional IPM entregado por el informe de Desarrollo Humano de las Naciones Unidas, UNDP de 2010, en el cual el IPM es de 9%. Este es próximo a las mediciones de pobreza de ingresos... y más ajustado a las políticas de la nación. ... el índice ha producido una imagen más nítida y más detallada de la pobreza y las privaciones del país. Este tapiz más completo es el que están usando para establecer sus metas de reducción de pobreza -en combinación con las medidas de pobreza de ingreso monetario-. El ejemplo de Colombia muestra a un gobierno innovando con una metodología de pobreza multidimensional flexible, apoyada por la Iniciativa de Oxford para el Desarrollo Humano (OPHI), para sacar el mayor partido de los datos disponibles y los problemas y necesidades específicos del país, y empleando el IPM nacional para informar las metas de reducción de la pobreza nacional. Esta es la clase de innovación nacional que el IPM internacional busca catalizar. (Negrillas añadidas).
Díaz-Alkire reconocen que “usando datos del 2008” bajó al 35% la pobreza que “era de 45% de la población” en el 2006. Esto es aún más extraño: mientras en Colombia, DANE-DNP anulan los datos del 2006-2007, en la Inglaterra del 2011 los calculan con el método IPM. Reconocen además que hacen cálculos con cifras de 2008 “ ya aceptadas, tal como fueron informadas por el Gobierno de Colombia a comienzos de este mes ” (entre agosto-septiembre de 2011). Y luego complican aún más el argumento: según ellas, su método IPM mejora el índice entregado por el informe de Desarrollo Humano de las Naciones Unidas, UNDP de 2010, en el cual el IPM ya es de 9%. No mencionan que se refieren a otro tipo y a otra medida de pobreza.
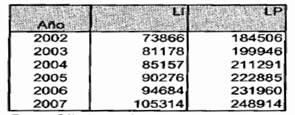
Casualmente, según el asesor la pobreza monetaria Total en 2006 fue de 46.9%, mientras en 2007 fue de 50.5%, tal como lo muestra la siguiente Tabla 4 elaborada en base a datos de (Rivas; 2007; p. 8).
Esta permite observar que las pobrezas no exhibieron avances importantes entre 2002 y 2007.
Tabla 4: LAS CONCLUSIONES DEL ASESOR SOBRE FRACCIONES DE POBREZA MODERADA Y EXTREMA POBLACIÓN EN INDIGENCIA O POBREZA EXTREMA MONETARIA EN REPORTE DE ASESOR
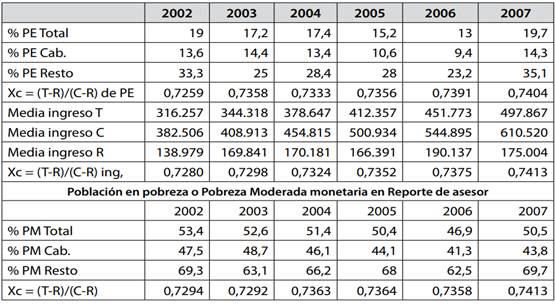
Fuente: Gráficos 2 y 3 de Reporte 6 de Asesor (p. 8) y promedios oficiales de Tabla 7. Observar: 1) los % hallados de poblaciones para ingresos, PM y PE son casi iguales en cada año como debe ser. 2) En 2007 los % de pobreza extrema fueron los más altos de 2002-2007. 3) La pobreza moderada superó siempre la mitad de la población total excepto en el año 2006. 4) Durante 2002-2007 más del 60% de pobladores rurales estaba por debajo de la pobreza moderada
Ocurre que el reporte UNDP de 2010 emplea la mitad de sus 300 páginas en tablas de NBI con múltiples variables de trabajo y múltiples índices de Gini, pero no presentan ni una sola tabla de deciles completa de distribución de ingreso monetario para país alguno aunque dicen complementarlo. Ese documento de las Naciones Unidas parece diseñado para anular la medición monetaria tradicional e imponerle al mundo la nueva metodología de Oxford, basada en Amartya Sen, quien contribuyó a resaltar los aspectos no cuantitativos de la pobreza, apelando paradójicamente a cuantificar lo no cuantitativo.
Parece que el dúo Colombia-Oxford usa el IPM como un “tapiz” para justificar el cambio de método: Colombia informa datos a Oxford y a Cepal, luego la ONU avala el método; Oxford produce y adapta nuevas cifras, informa a la ONU y avala a Colombia, esta a su vez entrega nuevas cifras ficticias del tema y las suplanta unas veces como metas de pobreza proyectadas para el futuro, otras como hechos cumplidos. A esto Díaz-Alkire lo llaman innovación, argumentando que conservan y complementan la medición del ingreso monetario -que no muestran pero alteran-, luego de devaluar su pertinencia. No muestran las tablas de distribución, ni los deciles basados en ingresos monetarios, ni los cálculos que pueden hacerse desde ellas de las pobrezas, pero dicen conservarlas mientras grafican metas y proyecciones futuras con otros valores. Estos argumentos son muy encomiables en las presentaciones de power-point pero no son de mucho fundamento y son de escaso valor en la práctica econométrica, porque no se someten a contrastación académica directa y escogen el dato más favorable de 2006, de 45%, cuando en 2007 fue de 50.5%.
4) Las explicaciones del Jefe Técnico de la Mesep-DNP-2011
En el portal razónpública punto org, dirigido por el intelectual liberal Fernando Gómez Buendía, se presentaron los artículos ya citados de los académicos. También aparecen las explicaciones del Jefe Técnico de la Mesep, Roberto Angulo, en representación de DNP, quien contestó algunas de las preguntas y comentarios en defensa del método Oxford. Algunas de la explicaciones que dio para justificar el uso exógeno de los coeficientes de Orshansky, ya cuestionadas por el académico Muñoz Conde, fueron:
“La decisión de usar coeficientes de Orshansky no basados en la encuesta de ingresos y gastos que sirvió para los cálculos obedeció a las siguientes razones: …[ …] … Para el caso de Colombia, el coeficiente de Orshansky es sustancialmente superior al promedio de América Latina (2,9 frente a 2,4). Tras estudiar la evidencia, la MESEP concluyó que emplear el valor 2,9 haría sobrestimar erróneamente la pobreza. Ú (sic) Aunque las diferencias de método entre los países dificultan la comparación, se adoptó el promedio para las zonas urbanas de América Latina que encontró la CEPAL (2,4) y para la zona rural se guardó la proporcionalidad que refleja la encuesta (1,74). …[ …] … Según la revisión que hizo la MESEP, en 7 países de América Latina se utiliza el coeficiente exógeno (por lo general se adopta el de CEPAL) y en 10 países el endógeno. Brasil por ejemplo, tiene un Orshanky de 3,5 pero utiliza un coeficiente exógeno de 2,0 (un “ajuste” bastante más drástico que el que hizo Colombia)”.
Afirma que “tras estudiar la evidencia, la Mesep concluyó que emplear el valor 2.9 haría sobreestimar erróneamente la pobreza”, lo cual indica que conocían los valores correctos calculados por otros medios y no los publicaron. Luego agrega que la Mesep “adoptó el promedio para las zonas urbanas de América Latina que encontró la CEPAL (2,4) y para la zona rural ..[…]… (1.74)” … porque … “en 7 países de América Latina se utiliza el coeficiente exógeno ..[…]… y en 10 países el endógeno”. Este recurso no es ético ni correcto desde la lógica de conjuntos. El hecho de que 7 países de 17 actúen mal no es justificación para imitarlos, cuando 10 de 17 países estudiados no lo hacen. Y usar para el Resto un CO=1.74 endógeno, indica que en este caso usaron una vara endógena que sería correcta si no la hubieran reducido algo más del 10% respecto al decenio anterior. La declaración confirma los indicios que sugieren que disminuyeron las varas para C y para R, empleando CO bajos y LPE igualmente rebajados.
El jefe técnico de la MESEP-DNP menciona a Brasil por haber bajado los CO suyos de 3.5 a 2, al que llama un ajuste bastante más drástico que el que hizo Colombia , frase donde acepta públicamente que ajustaron los resultados con un cambio de método del CO, no más ni menos drástico sino muy similar al brasilero, pasando el análisis del terreno endógeno colombiano a otro exógeno de promedios latinoamericanos, método que ya sometimos a crítica. Ni la Cepal ha explicado en detalle el método que usó para hallar su promedio latinoamericano ni ha justificado el uso que ha tenido.
5) El discurso de Alvaro Uribe Vélez sobre la metodología de Oxford, Julio 20 de 2010
Un año antes del debate en The Guardian, el saliente presidente Uribe pronunció su último discurso como jefe de estado. A continuación se muestran y comentan algunos apartes de su intervención ante el Congreso de Colombia, el 20 de julio de 2010, donde defendió y recomendó el cambio de método que implantó:
1) “Colombia ha reducido la pobreza durante estos años en cerca de 2 millones de personas, sin considerar el efecto de los apoyos de política social, y en cerca de 4 millones cuando se incluye el impacto del gasto social en el bienestar real de las familias”.
Dadas las manipulaciones ya señaladas de las medias de Cabeceras y Resto, las cifras del expresidente carecen de credibilidad, rigor y sustento real.
2) “Los expertos reconocen que la línea de ingreso que se exige en Colombia es bastante alta en la comparación internacional, lo cual incide en que por esta metodología la pobreza por ingreso todavía aparezca en el 45 por ciento”.
Aquí Uribe invoca a los “expertos” que afirman que la pobreza moderada no cambia mucho debido a que el país emplea líneas de ingresos de pobreza altas al compararlas con otros países. El expresidente sabía muy bien que el problema a resolver era el endógeno de su país que es distinto al de otros países de la región. Es una manera de ocultar que durante 10 años el país incumplió el compromiso relativo a la meta de pobreza de los ODM y hacernos creer que redujo en este primer paso al 45% lo que entonces superaba el 50%. Abona el terreno para promover el cambio de metodología de medición de pobrezas basado en bajar las varas que ya había ejecutado durante su gestión.
3)“- Los expertos consideran que el gasto social reduce la pobreza en 15 puntos y su focalización en los más pobres contribuye a construir equidad y a mejorar la distribución del ingreso;”...
Esta es una frase vaga que pide verificación. Por lo general el gasto social del estado alivia la pobreza porque genera empleo y suaviza la situación de los más pobres, pero su efecto depende de muchos factores que no menciona ni mide; cuantificar la reducción por causa de los subsidios a “15 puntos” es una frase sin sustento que buscaba impresionar al auditorio
4) “Teniendo en cuenta lo anterior, la política social reduce la pobreza medida por ingreso del 45 por ciento al 30 por ciento aproximadamente”.
No explica porqué la conclusión se sigue de lo anterior. Sin mayor explicación le resta al 45% de pobreza (cifra alterada) el 15% (cifra sin soporte) para decir que entrega un país con el 30% de pobreza moderada. Otra frase sin sustento, pero efectiva como recurso retórico.
5) “Pero la pobreza no es solo la ausencia de ingresos. El Índice Multidimensional de Pobreza que acaba de lanzar el Oxford Poverty and Human Development Initiative, y que examina 10 dimensiones de educación, salud y estándar de vida, señala en un reciente informe que la pobreza en Colombia es del 9 por ciento ”.
Aquí publicita el reciente método del IPM de Oxford y multiplica por diez las variables estudiadas, basado en la “corrección” de unos datos previamente aprobados por su gobierno y enviados a Oxford, para ser adaptados al método NBI, sin aclarar si se refiere a la pobreza moderada o la extrema, ni detallar el año estudiado. Uribe llega a afirmar que esa pobreza no definida es ya del 9%: en pocos párrafos bajó la pobreza del 50% al 9% mediante artificios retóricos. También omite decir que desde el inicio de su gobierno se emplearon otras metodologías por el dúo DANE-DNP, cuestionadas por académicos que denunciaron presiones indebidas del gobierno.
Es anormal que haya varias series simultáneas y distintas de datos deciles mencionados para los mismos años: los del Cuadro 7, los enviados inicialmente a Oxford, los enviados más tarde a la ONU y a Oxford para la última corrección con el nuevo método, y los que publicó la Cepal para los sectores Urbano y Rural. De todos ellos se han mostrado aquí solo los de la Cepal y los del Cuadro 7 del asesor. Los demás datos fueron los trabajados por la exfuncionaria Yadira Díaz junto a Sabina Alkire, donde llaman al resultado del 9% “meta” para el 2008 de pobreza -no se sabe si moderada o extrema- y al que Uribe convierte en hecho estadístico cumplido en su discurso. Esto refuerza la crítica mencionada que le hiciera la senadora Cecilia López en 2006 sobre la politización de los datos estadísticos por parte del expresidente Uribe.
En las palabras del expresidente Uribe queda claro que conocía las cifras y métodos que repetirían un año después Díaz-Alkire en 2011 desde la U. de Oxford. A su vez, Díaz-Alkire afirman que los datos habían sido aprobados por el gobierno colombiano dos meses antes de su comentario a The Guardian, de octubre 2011.
Esto indica que fueron recibidos del gobierno Santos, a pesar de que Uribe mencionó las mismas cifras y conclusiones de Oxford con un año de anticipación.
No había acceso a tablas oficiales completas de los deciles monetarios anteriores al 2010 que fueran publicadas durante el gobierno de Uribe, excepto las del 2004 citadas por el estudio CID-UNAL-2006. Quizás para eso sirvió anular los datos del 2006-2007: para crear un ambiente favorable que justificara la adopción de la nueva metodología de Oxford en Colombia. Cabe la pregunta: ¿Si anularon los datos de 2006 y 2007, porqué no publicaron los de 2002-2005 al país, pero sí se los entregaron completos al asesor para su trabajo, aparte de entregar otros datos distintos a la Cepal y a Oxford?
6) “Al aplicar la metodología de Oxford, el Departamento Nacional de Planeación concluye que entre 2003 y 2008 la pobreza disminuyó en 3.9 millones de personas”…
Ya lo comentó Glennie en The Guardian: ¿Qué gobierno puede negarse a sacar 3.1 millones de la pobreza mediante un simple cambio en la metodología de la medición? Avala el cambio de método y le atribuye la conclusión a su entidad subordinada, DNP.
7) “Entregamos un sistema de oportunidades sociales que, en la medida en que se amplíe y haya prosperidad económica para financiarlo, debe acelerar la superación de la pobreza.”
La cadena de avales y argumentos se cierra con el eslabón final del alto gobierno y la deja como herencia a seguir por el nuevo gobierno. Aquí transfiere el mensaje y la tarea al presidente Santos: la pobreza es un problema sistémico de oportunidades sociales, no de realidades sociales en la desigualdad del ingreso monetario; basta contar con financiación para ampliar las oportunidades y se genera un entorno de prosperidad y crecimiento para superar la pobreza y cumplir los Objetivos del Milenio. Es la misma receta de política social tomada de Amartya Sen, basada en dar oportunidades sociales sin tocar a fondo la distribución del ingreso y de la propiedad dentro de un entorno económico capitalista basado en el dinero y en la propiedad del capital.
Según su discurso al congreso, el entonces presidente Uribe estaba muy enterado del manejo de todos los detalles técnicos y del avance del proceso de cambio de método; no mencionó otras interpretaciones independientes que lo adversaban desde las universidades y medios; y eludió el debate público. Basado en las conclusiones de su oficina subordinada DNP, le informó por primera vez al país que había aplicado oficialmente el nuevo método de Oxford desde años antes, sin permitir otras opiniones. Colombia fue así el primer país del mundo en adoptar el método de Oxford.
Los datos que el artículo emplea son los mismos datos oficiales que el Dane- DNP elaboró y entregó a su asesor privado para hacer su trabajo. Ellos pueden ser consultados y bajados de los archivos del portal de contrataciones públicas del país, que en buena hora fuera creado por el actual presidente Santos al inicio de su gestión.
CONCLUSIONES Y RECOMENDACIONES
Aporta evidencias de que desde el 2002, por lo menos, el gobierno colombiano alteró las cifras reales de los promedios de los deciles de distribución de ingresos; estos promedios son cruciales; afectan las fracciones implícitas de población, las tablas de deciles, la calidad de los cálculos y los análisis posteriores sobre desigualdad y población de las dos pobrezas estimadas.
Hay evidencias de errores técnicos y metodológicos en la determinación de las líneas de pobreza y sus coeficientes de Orshansky. Algunos pueden ser resultado de ignorancia excusable por parte de los expertos, otros parecen ser resultado de un diseño y ejecución ocurridos dentro de las instituciones encargadas de recoger, analizar, aprobar y presentar los resultados oficiales al país.
Como resultado, hubo un cambio del método tradicional monetario -que era más informativo y claro- por el método de la U. de Oxford, IPM, con el aval de la Cepal y posteriormente de la ONU. El método IPM es más opaco, mide otras cosas y arroja menores cifras de pobres si se le aportan métodos y premisas numéricas convenientes o si son tomadas de contextos exógenos.
En 2010 el Presidente Uribe informó públicamente el cambio de método que ejecutó y lo recomendó al gobierno de Santos, quien lo emplea oficialmente desde entonces.
Se recomiendan estos cambios puntuales: a) Volver al método anterior de medición b) Emplear líneas de pobreza moderada y extrema en fracciones de la media de ingresos de cada sector; informar siempre la participación poblacional de cada sector y sus ingresos promedio en las tablas de deciles, mejorar algunos de sus procedimientos; c) Emplear la información derivada del conocimiento de NBI para llevar soluciones puntuales y concretas a las comunidades afectadas por su ausencia y/o calidad insuficiente, pero no para medir las pobrezas monetarias en base a esas NBI; d) Analizar por un lado el aporte del crecimiento del ingreso promedio real, y por el otro, el aporte generado por los cambios en la distribución estructural del ingreso de los sectores encuestados y hacer esto para cada año. Examinar luego su efecto combinado en la etapa final del análisis.
Es importante debatir el tema dentro de la academia y los organismos para el avance de la ciencia -dentro de un marco de diálogo abierto, autónomo y sin censuras- con el ánimo de aclararlo y hallar soluciones. La medición y erradicación de la pobreza es un tema social esencial de cualquier sistema económico que tenga al ser humano y su calidad de vida como eje de sus preocupaciones.
Ocultar realidades sociales mediante cambios metodológicos e informativos no es el camino correcto. Si un gobierno abusa del método, no merece presidir a la nación. Si la ONU, la Cepal, el BM y la OEA fomentan ese tipo de prácticas, no merecen representar a las comunidades de naciones.
El IPM de Oxford también debe someterse al principio de la cuchilla de Occam. Deben explicar de manera convincente y detallada cada una de sus premisas y procedimientos metodológicos asumidos para sus diez o más variables multidimensionales.
DNP publicó nuevos coeficientes de Orshansky inferiores a los usuales y aumentó su tendencia decreciente desde el 2002 hasta nuestros días; lo hizo para diversos sectores que empleó sin definir con claridad (Cabecera, Resto,13 Áreas Metropolitanas, Otras Cabeceras, Urbano y Rural). Persiste en errores como emplear valores exógenos, bajar las líneas de pobreza sin explicar el procedimiento empleado, y no definir con claridad qué significa cada uno de esos grupos, ni qué regiones o fracciones de población cubren.
Es importante que Dane-DNP publique una tabla corregida y similar a la del Cuadro 7, que cubra los datos de 2002 a 2012 basada solo en datos monetarios de ingreso.
Hay otras evidencias no mostradas de posibles anomalías que pueden comprobarse a partir de documentos oficiales emitidos por Dane-DNP y sus voceros. Pueden ser significativas para otro momento futuro.
El Cuadro 7 entregado por el gobierno al asesor es la mejor tabla de datos conocida para los años 2000 a 2007, a pesar de las incoherencias encontradas. Desde ella y con mejores datos de Líneas de Pobreza pueden estimarse con bastante aproximación las distribuciones y sus poblaciones en condición de pobreza monetaria para los años 2000-2007. Este trabajo extenso está en una etapa avanzada y queda pendiente para otro momento.
“Nos han dominado más por la ignorancia que por la fuerza”, dijo Simón Bolívar inspirado en su maestro Simón Rodríguez.