










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkRevista Facultad Nacional de Agronomía Medellín
Print version ISSN 0304-2847
Rev. Fac. Nac. Agron. Medellín vol.67 no.2 Medellín June/Dec. 2014
https://doi.org/10.15446/rfnam.v67n2.44179
http://dx.doi.org/10.15446/rfnam.v67n2.44179
SueMulador: Herramienta para la Simulación de Datos Faltantes en Series Climáticas Diarias de Zonas Ecuatoriales
SueMulador: A Tool For Missing Data Simulation of Climatic Series in Equatorial Zones
Héctor Alberto Chica Ramírez1; Andrés Javier Peña Quiñones2; José Fernando Giraldo Jiménez3; Diego Obando Bonilla4 y Néstor Miguel Riaño Herrera5
1 Ingeniero Agrónomo, Biometrista del Servicio de Análisis Económico y Estadístico (SAEE) - Centro de Investigación de la Caña de Azúcar de Colombia (Cenicaña). Vía Cali-Florida, km 26 San Antonio de los Caballeros, Valle del Cauca, Colombia.<hachica@cenicana.org>
2 Ingeniero Agrónomo, Investigador Científico II - Programa de Investigación en Variabilidad Climática y Caficultura - Centro Nacional de Investigaciones de Café (Cenicafé). km 4 vía antigua Chinchiná Manizales, Colombia. <andres.pena@cafedecolombia.com>
3 Ingeniero Agrónomo, Jefe de Investigación y Desarrollo Agronómico de Indupalma Ltda. km 5 Troncal del Magdalena Medio, San Alberto, Cesar, Colombia. <jfgiraldo@indupalma.com>
4 Ingeniero Forestal, Asociado de Investigación - Grupo de Decisión y Análisis de Políticas - Centro Internacional de Agricultura Tropical (CIAT). km 17 recta Cali-Palmira, Colombia. <d.obando@cgiar.org>
5 Ingeniero Agrónomo, Investigador Científico III. Coordinador - Programa de Investigación en Variabilidad Climática y Caficultura - Centro Nacional de Investigaciones de Café (Cenicafé). km 4 vía antigua Chinchiná-Manizales, Colombia. <Nestorm.Riano@cafedecolombia.com>
Recibido: Abril 23, 2013; aceptado: Noviembre 05, 2013.
Resumen. En la actualidad, los modelos de cultivo son una herramienta útil a la hora de tomar decisiones, no obstante, pese a su disponibilidad y facilidad de uso, la información necesaria para utilizarlos no existe o no tiene la calidad suficiente. Un ejemplo preciso del déficit de calidad en los datos lo constituyen las series meteorológicas diarias en las que predominan faltantes. Para hacer frente a esta situación y poder utilizar los modelos de cultivo se elaboró un software para llenar espacios vacíos en series climáticas diarias, basada en una cadena de Markov de orden dos y dos estados. La herramienta llamada SueMulador, se probó y validó con éxito en tres estaciones ubicadas en zonas contrastantes de la geografía colombiana.
Palabras clave: Series de tiempo, meteorologia, modelos de cultivo, variabilidad climática.
Abstract. Currently, crop models are an useful tool for decision making; however, even though they are available and are easy to use, the information needed to use does not exist or not have sufficient quality. A specific example of the lack of quality is the daily weather series, in which there is too much missing data. To address this situation and to use crop models, we developed a software to fill gaps in daily climate series based on a Markov chain of order two and two states. The new tool, called SueMulador, was successfully tested and validated in three contrasting regions of Colombia.
Key words: Time series, meteorology, crop models, climate variability.
Los modelos que utilizan información meteorológica, edáfica y económica para pronosticar producción de biomasa y rendimiento de especies vegetales cultivadas (modelos de cultivo), se han utilizado durante más de cuatro décadas (Gálvez et al., 2010). En el contexto mundial, en los últimos años su uso se ha masificado, debido a su utilidad como herramientas para la reducción de la incertidumbre en el momento de tomar decisiones asociadas con el manejo de sistemas de producción agrícola, pecuaria y forestal. No obstante, pese a su efectividad, en los países en vía de desarrollo su uso es restringido porque la información de entrada (clima, suelos, planta y socio-economía), necesaria para que los modelos brinden información precisa, no está disponible, o cuando lo está no tiene la calidad apropiada para que el modelo cumpla con su objetivo (Jones y Thornton, 2000).
En general, los modelos tienen como primer requerimiento, el ingreso de los datos de clima para el período durante el cual se simula el crecimiento y la producción. Sin embargo, la calidad de las series de tiempo climáticas no siempre es la mejor y es frecuente encontrar en ellas datos faltantes. Este problema suele resolverse de dos maneras, la primera corresponde a la estimación del valor faltante a partir de modelos de interpolación o de series temporales ajustados a los datos disponibles, cuyos parámetros son estimados mediante la minimización del error cuadrático medio (Schneider, 2001) y la segunda es la simulación de los valores faltantes ajustando la serie diaria de clima a un proceso estocástico markoviano (Moreno, 1993; Jones y Thornton, 1999), para así generar los estados futuros a partir de números aleatorios. En el caso de la interpolación, es necesario tener información adicional de covariables a partir de las cuales se estiman los valores faltantes (Schneider, 2001), por lo que es inadecuado para sitios en los que sólo se mide un elemento del clima, como es el caso de los puestos pluviométricos, que representan la mayor parte de las estaciones meteorológicas de los países ecuatoriales en desarrollo. En el caso de las series temporales es necesario que la serie de clima pueda ajustarse a un proceso autoregresivo de media móvil (ARIMA) (Wei, 1990), para después estimar los valores faltantes asumiendo que estos son atípicos aditivos (Maravall y Peña, 1992); no obstante, el uso de modelos ARIMA se dificulta porque la escala temporal en la cual se desean estimar los faltantes es diaria, no pudiéndose ajustar un modelo adecuado cuyo error de estimación permita una inferencia aceptable para los valores faltantes estimados.
Se presenta SueMulador, software que genera datos diarios de precipitación, brillo solar, humedad relativa y temperaturas (mínima y máxima) a través de un proceso estocástico markoviano, para suplir los datos faltantes de las series climáticas de las estaciones meteorológicas ubicadas en zonas ecuatoriales. La ventaja del SueMulador es que considera la variabilidad climática intra-anual asociada al movimiento de la Zona de Confluencia Intertropical (León et al., 2000), e interanual relacionada con los cambios en los patrones del clima como consecuencia de la variación de la temperatura superficial del Océano Pacífico Tropical Central (El Niño y La Niña) (Trenberth, 1997) para generar datos faltantes. Es de anotar que si bien en la literatura se encuentran reportes de herramientas similares, algunas de ellas, como MarkSim (Jones y Thornton, 2000), no tiene en cuenta la variación interanual natural del clima; el modelo desarrollado por Grondona et al. (2000) consideran esta variación pero fue desarrollado a escala muy local (Noreste de Argentina y Uruguay); mientras que el modelo elaborado por Fowler et al. (2005) tiene propósitos macro y su objetivo es simular datos a escala mensual para generar escenarios de cambio climático.
MATERIALES Y MÉTODOS
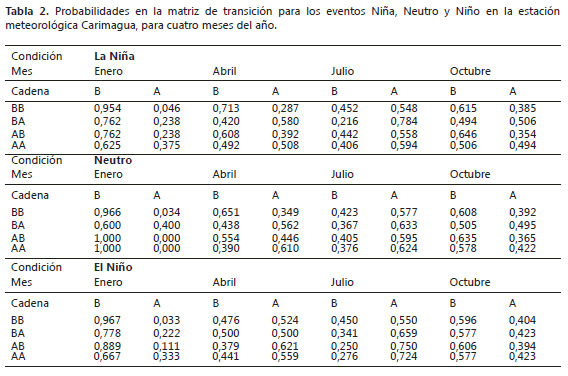
Descripción del algoritmo. El procedimiento de simulación tiene dos etapas. En la primera, se define una cadena de Markov de tiempo discreto (Moreno, 1993) para representar el comportamiento diario de las variables a partir de dos estados (alto, bajo) y de orden 2. El criterio para determinar el estado de un valor diario presente es mediante su comparación con el percentil 0,3 calculado con todos los datos de la serie. Si el valor diario es mayor al percentil 0,3 se considera alto, en caso contrario será bajo (Wilks, 1995). Para la precipitación el estado se considera alto si se tiene un valor superior a 1 mm de agua por considerar que desde el punto de vista agrícola son importantes los días con lluvia superior o igual a 1,0 mm (Peña, 2000), en los que los procesos de aporte de humedad a la parte foliar y al suelo empiezan a ser importantes. Después se calculan las probabilidades de transición como frecuencias relativas resultantes del cociente entre el número de eventos favorables y el número de eventos posibles (Tabla 1).
Tabla 1. Matriz de transición de la cadena de Markov de orden 2 y estados que representan las variables climáticas.
En términos de las variables climáticas, la probabilidad de transición P(x/wz) se interpreta como la posibilidad de que mañana suceda el estado "x", dado que ayer ocurrió el estado "z" y antes de ayer el estado "w" y para todo par de estados precedentes XY se da que:
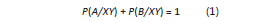
Para garantizar la estacionariedad (Moreno, 1993) de la cadena de Markov, es decir que las probabilidades de transición no cambien con el tiempo, la información de la variable de clima se clasifica por mes y tipo de evento ENOS (El Niño, La Niña, Neutro) resultando como máximo 36 matrices de transición por cada variable climática. Para determinar si un dato faltante corresponde a un estado E alto o bajo se observan sus dos estados precedentes (XY), se genera un número aleatorio U en el intervalo (0,1) bajo una distribución uniforme de probabilidad y con base en la ecuación (1) se concluye que:
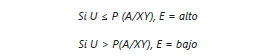
Según las probabilidades de transición para el mes y la condición ENOS al cual pertenece.
En la segunda etapa del procedimiento de simulación se calcula el valor numérico de la variable mediante la simulación de un número aleatorio proveniente de una distribución teórica de probabilidad a la que se ajustan los datos históricos. Para las variables temperatura (mínima y máxima), humedad relativa y brillo solar se utilizó la distribución del extremo más grande para los estados altos y cuya densidad es:
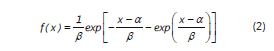
y con momentos:
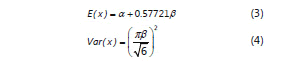
y la distribución del extremo más pequeño para los estados bajos.
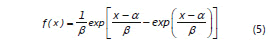
con momentos:
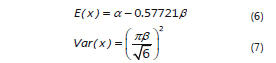
En la generación de valores de precipitación de estados altos se utilizó la distribución Birnbaum-Saunders (Espinosa et al., 2004) con densidad:
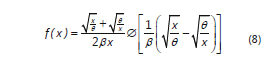
en donde F[·] es la distribución normal estándar y sus momentos son:
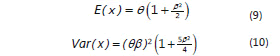
En todos los casos los parámetros de los modelos se estimaron por el método de momentos (Mood y Graybill, 1963), resolviendo el sistema de ecuaciones (3) y (4) para la distribución del extremo más grande, (6) y (7) para la distribución del extremo más pequeño y el sistema (9) y (10) para la distribución Birnbaum-Saunders.
Para generar un valor X de una distribución del extremo más grande se empleó la siguiente igualdad:
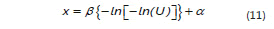
Análogamente, para generar un valor X de una distribución del extremo más pequeño se utiliza:
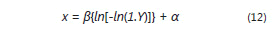
en donde U es un número aleatorio proveniente de la distribución uniforme en el intervalo (0,1).
Un valor aleatorio X de la distribución Birbaun Saunders surge con la siguiente igualdad:
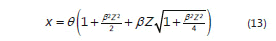
Con Z siendo un número aleatorio generado a partir de una distribución normal estándar con el método polar (Cao, 2002).
Descripción del software. La primera versión de SueMulador es una aplicación de escritorio para SO Windows 7 de 32 Bits construida con tecnología .NET, usando Net Framework 4 de Microsoft. SueMulador recibe como entrada principal un archivo plano tabulado de extensión .txt, en el cual se indica lugar, fecha y variables climáticas.
Como parámetros de ejecución, SueMulador requiere: 1) datos de la tabla que caracteriza los meses en función de los tres estados asociados al ENOS (El Niño, La Niña y Neutro). La tabla ENOS está contenida en el archivo ENOS.clm, el cual puede modificarse con un editor de archivos de texto. ENOS.clm debe estar en la misma carpeta de SueMulador.exe; 2) estados de cada variable, representado por una cadena de la forma E1/E2/…/En, en la cual Em es una cadena mono-carácter que representa un estado de la variable. E1 representa el estado más bajo y En el estado más alto. Por ejemplo, si la variable tiene 3 estados, uno bajo, uno medio y otro alto, sus estados se representan B/M/A; 3) tipo de límite de cada variable, que indica si se usará como valor crítico una constante o un percentil determinado. La constante se representa como un número cualquiera y el percentil como un número p tal que 0<=p<=1; 4) valores críticos para cada estado representados por una cadena de la forma V1/V2/…/Vn-1, en la cual n es el número de estados y Vm es el valor crítico que representa el límite superior del estado Em. El límite superior del estado más alto (En) no se incluye en esta cadena, puesto que su intervalo se ajusta por defecto como cualquier valor por encima del límite superior del estado En-1. Por ejemplo, si la variable tiene 3 estados, B/M/A, sus valores críticos se representan 3/5 si el límite es de tipo constante, o 0,2/ 0,4 si el límite es de tipo percentil. Los valores aquí usados solo se muestran como ejemplo. Cada variable, de acuerdo a su naturaleza o criterio del experto puede tener valores críticos distintos; 5) orden de la cadena, representado por un numero entero k>=2.
RESULTADOS Y DISCUSIÓN
Procedimiento de análisis y simulación en SueMulador. El procedimiento de análisis y simulación de las variables se ejecuta de la siguiente manera:
Para el registro de cada variable se asigna una condición Niña (-1), Neutro (0), Niño (1), según la fecha de registro de acuerdo a la tabla ENOS.
Se calculan los momentos de la serie de datos completa.
Para cada registro de cada variable se asigna un estado según los valores críticos asociados a la variable.
Se calculan los momentos agrupando los registros de cada variable según condición, mes y estado.
Se generan y agrupan por mes y condición tablas de transición para cada variable según la secuencia de la cadena markoviana.
Se simula un posible estado para los datos faltantes de la serie de acuerdo con las tablas de transición. En este punto se evalúa si el estado generado cumple con tener una probabilidad de ocurrencia definida y mayor que cero, y que al combinarse a orden k con sus estados precedentes y consecuentes, genera una cadena que tiene probabilidad de ocurrencia definida y mayor que cero. Si una de estas dos condiciones no se cumple, el estado se genera nuevamente hasta que se logre congruencia.
Se simulan los datos faltantes teniendo en cuenta la distribución teórica de la variable, el estado simulado, y los momentos de la variable según condición, mes y estado. Los valores simulados son evaluados y se consideran validos si se cumple que ymin=<ysim<=ymax, donde ymin y ymax definen el rango observado de la variable para el estado E. Si no se cumple la condición, el dato es simulado nuevamente hasta lograr ajuste al rango.
Finalmente, SueMulador entrega como salida una tabla con los datos observados y simulados, bien diferenciados, y un gráfico dinámico el cual contrasta los datos observados y simulados según la variable y periodo seleccionados. La tabla puede copiarse en el portapapeles en un formato compatible con Ms Excel y el gráfico puede guardarse en formato .bmp de alta calidad.
Validación del software. Se hizo utilizando información meteorológica de tres estaciones climáticas principales, ubicadas en regiones de Colombia que tienen características contrastantes dentro del país; Naranjal, ubicada en la región andina a 1.381 msnm, Carimagua, ubicada en la altillanura plana, en los llanos orientales a 200 msnm y Turipaná, ubicada en la región Caribe a 20 msnm (Figura 1).
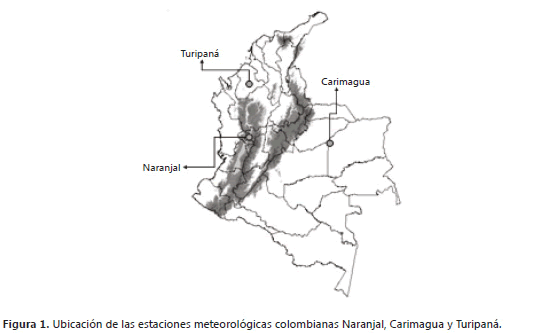
Con base en el análisis de las tres series originales (escala diaria), el cual se condensa en las cadenas de transición para cada estación-mes-condición (Tabla 2), se simularon tres series climáticas diarias (lluvia, brillo solar, temperatura máxima, temperatura mínima y humedad relativa) que tienen la misma longitud que las series originales.
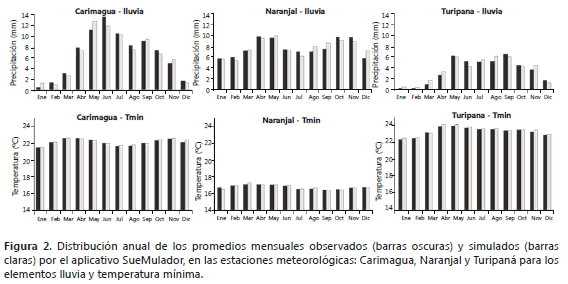
La comparación entre simulados y observados se hizo a escala mensual (promedios diarios mensuales), para lo cual se procedió a generar un promedio general en esa escala de tiempo tanto para los datos simulados como para los observados (Figura 2) y se utilizó la recta de pendiente 1 e intercepto 0 para evaluar la calidad de los datos simulados.
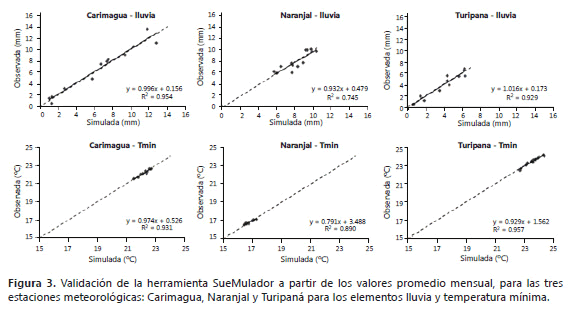
Los valores estimados y simulados de lluvia, agregados a nivel mensual, en las estaciones meteorológica Carimagua, Naranjal y Turipaná se ajustaron satisfactoriamente a la recta de pendiente uno e intercepto cero con valores de coeficiente de determinación de 95%, 75% y 93% respectivamente cuando se hizo la regresión respectiva. Los valores estimados y simulados de temperatura mínima, agregados a nivel mensual, en las estaciones meteorológica Carimagua y Turipaná se ajustaron satisfactoriamente a la recta de pendiente uno e intercepto cero con valores de coeficiente de determinación de 93%, y 96% respectivamente cuando se hizo la regresión respectiva.
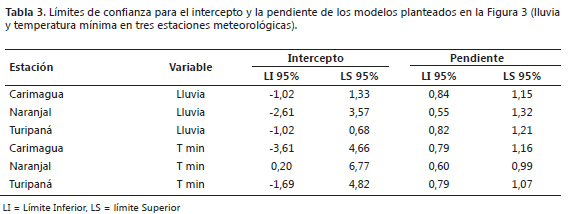
Se observa que cuando los datos simulados con SueMulador se promedian a escala mensual y se comparan con los datos mensuales observados, estas series tienen muy poca diferencia, mostrando que el software es capaz de estimar adecuadamente el comportamiento de la distribución intra e inter anual que caracteriza a cada elemento del clima en cada una de las regiones (Figura 3 y Tabla 3).
De la misma forma, al determinar la desviación estándar para los datos mensuales, se observa que los valores simulados conservan la distribución de la desviación estándar de los datos considerados; por ejemplo, para la serie Turipaná la desviación estándar de la precipitación (Figura 4) mantiene un comportamiento consistente entre valores simulados y reales.
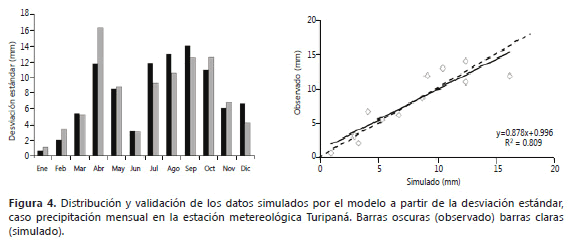
La capacidad de SueMulador para aproximarse con gran precisión a los datos observados se debe a que éste analiza las series en función del mes y del evento ENOS y las expresa como una probabilidad en la matriz de transición (Tabla 2), donde por ejemplo, se observa que en la estación metereológica Carimagua la probabilidad de que, estando en el mes de enero, llueva mañana como consecuencia de que llovió ayer y antes de ayer es del 37% durante un evento Niña, mientras que para el mismo periodo en evento Niño la probabilidad de ocurrencia de lluvia es del 33%.
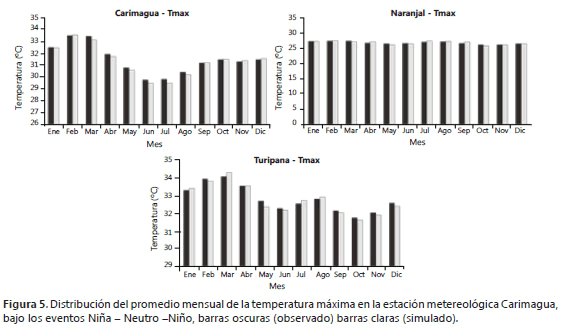
Al analizar los resultados de las simulaciones de acuerdo con la condición ENOS, se constata una consistencia en los cambios de magnitud de los valores promedio mensual observados en cada uno de los diferentes elementos climáticos durante los eventos Niña, Neutro o Niño (Figura 5).
CONCLUSIONES
Dada la naturaleza contrastante de las estaciones metereológicas Carimagua, Naranjal y Turipaná (muestra representativa de las condiciones ecuatoriales colombianas) se concluye que el SueMulador reconstruye adecuadamente series climáticas para las condiciones estipuladas. En todos los casos la aproximación de la desviación estándar mensual de las variables reflejó la realidad del comportamiento de cada una de las estaciones metereológicas.
La capacidad de SueMulador para aproximarse con gran precisión a los datos observados se debe a que éste analiza las series en función del mes y del evento ENOS y las expresa como una probabilidad en la matriz de transición; por ejemplo, en la estación metereológica Carimagua la probabilidad de que, estando en el mes de enero, llueva mañana como consecuencia de que llovió ayer y antes de ayer es del 37% durante un evento Niña, mientras que para el mismo periodo en evento Niño la probabilidad de ocurrencia de lluvia es del 33%.
AGRADECIMIENTOS
Los autores agradecen al Ministerio de Agricultura y Desarrollo Rural por la cofinanciación en el marco del proyecto: Ajuste, Validación y ampliación del modelo de crecimiento y captura de carbono para especies en el trópico CREFT, código 028-2007K5702-359-07. A las empresas e instituciones cofinanciadoras Smurfit Kappa Cartón de Colombia, Reforestadora El Guásimo, Reforestadora de la Costa REFOCOSTA, Reforestadora del Caribe, Pizano S.A., Universidad Nacional de Colombia Sede Medellín, Fundación Ecológica Cafetera, Federación Nacional de Cafeteros de Colombia Centro Nacional de Investigaciones de Café CENICAFÉ y en especial al Dr. Bernardo Chaves C., Investigador del la estación experimental Prosser de la Universidad del estado de Washington, USA; por su revisión y contribuciones.
BIBLIOGRAFÍA
Cao Abad, R. 2002 Introducción a la simulación y teoría de colas. Primera edición. NETBIBLO, S.L., Coruña. 217 p. [ Links ]
Charles, S., J. Hughes and P. Guttorp. 1997. Non homogeneous Hidden Markov model for Precipitation. NRCSE-TRS No. 004. [ Links ]
Espinosa, E., M. Cantú, M. y V. Leiva. 2004. Caracterización y aplicación de la distribución Birnbaum-Saunders como modelo de tiempos de vida. Revista Agraria -Nueva Época- 1(1): 19-27. [ Links ]
Fowler, H.J., C.G. Kilsby, P.E. O'Connell and A. Burton. 2005. A weather-type conditioned multi-site stochastic rainfall model for the generation of scenarios of climatic variability and change. Journal of Hydrology 308(1-4): 50-66. [ Links ]
Gálvez, G., A. Sigarroa, T. López, J. Fernández y J. Fernández. 2010. Modelación de cultivos agrícolas. Algunos ejemplos. Cultivos Tropicales 31(3): 60-65. [ Links ]
Grondona, M., G. Podestá, M. Bidegain, M. Marino and H. Hordij. 2000. A stochastic precipitation generator conditioned on ENSO phase: A case study in southeastern South America. Journal of Climate 13(16): 2973-2986. [ Links ]
Jones, P. and P. Thornton. 1999. Fitting a third-order Markov rainfall model to interpolated climate surfaces. Agricultural and Forest Meteorology 97(3): 213231. [ Links ]
Jones, P. and P. Thornton. 2000. MarkSim: Software to generate daily weather data for Latin America and Africa. Agronomy Journal 92(3): 445-453. [ Links ]
León. G., J. Zea y J. Eslava. 2000. Circulación general del trópico y la zona de confluencia intertropical en Colombia. Meteorología Colombiana 1:31-38. [ Links ]
Maravall, A. and D. Peña. 1992. Missing observations and additive outliers in time series models. Working papers statistics and econometric series 92-40 (28). Universidad Carlos III, Madrid. 53 p. [ Links ]
Mood, A. and F. Graybill. 1963. Introduction to the Theory of Statistics. Second edition. McGraw-Hill Book Company, Inc. New York. 443 p. [ Links ]
Moreno, L. 1993. Procesos Estocásticos. Primera edición. Universidad Nacional de Colombia, Bogotá, 151 p. [ Links ]
Peña, A. 2000. Incidencia de los fenómenos El Niño y La Niña sobre el clima del valle del río Cauca. Trabajo de Grado. Ingeniería Agronómica. Universidad Nacional de Colombia, Palmira 110 p. [ Links ]
Schneider, T. 2001. Analysis of incomplete climate data: estimation of mean values and covariance matrices and imputation of missing values. Journal of Climate 14(5): 853-871. [ Links ]
Trenberth, K. 1997. The definition of El Niño. Bulletin of American Meteorological Society 78(12): 2771-2777. [ Links ]
Wei, W. 1990. Time Series Analysis. Addison-Wesley Publishing Company, USA. 478 p. [ Links ]
Wilks, D. 1995. Statistical Methods in Atmospheric Sciences. Academic Press, USA. 467 p. [ Links ]
