











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. Introducción
Las actividades no reguladas o economía sumergida son un fenómeno generalizado en el sistema económico actual, presente más en países en desarrollo que en países desarrollados. Buehn y Schneider (2012), que cuantifican el peso de las actividades no reguladas para 162 países entre 1999 y 2007, encuentran que en promedio para todos los países analizados este tipo de actividades representa 33% del producto interno bruto (PIB). En los países desarrollados este porcentaje gira alrededor de 17%, mientras que en los países emergentes y en desarrollo la economía sumergida representa cerca de 36% del PIB. En América Latina y el Caribe las actividades no reguladas representan 35%, siendo Bolivia, Panamá, Perú y Haití los países con los niveles más altos: 66%, 63%, 58% y 56%, respectivamente.
La informalidad laboral es un importante componente de las actividades no reguladas y estas incluyen todas aquellas labores legales de producción de bienes y servicios que se ocultan voluntariamente de las autoridades para evitar el pago de seguridad social e impuestos y/o para no cumplir con las obligaciones y normas legales del mercado de trabajo4. Schneider y Williams (2013) estiman que en Latinoamérica, Brasil y Colombia tienen la mayor fuerza de trabajo en actividades informales, con 37,4 millones (49% de la fuerza laboral) y 9,7 millones (54% de la fuerza laboral) de trabajadores en este tipo de actividades, respectivamente.
Existe una gran cantidad de estudios que han analizado la informalidad laboral tanto a nivel de país como comparando entre estos (véase, por ejemplo, Perry et al., 2007; Jütting y De Laiglesia, 2009), y cada vez más existe un mayor interés de los investigadores y hacedores de política por los patrones regionales de este fenómeno, teniendo en cuenta su heterogeneidad espacial y la posibilidad de detectar aspectos locales y regionales que puedan mitigar su impacto en los mercados laborales (véase, por ejemplo, el número especial en International Labour Review, 2013). En el ámbito intraurbano existe una menor evidencia sobre el comportamiento de la informalidad laboral, sus determinantes y las implicaciones en la sociedad de su distribución espacial. La literatura de economía urbana ha resaltado que es cada vez más importante estudiar este tipo de fenómenos socioeconómicos al interior de una ciudad, dada la necesidad de tener ciudades equilibradas en términos de que estas deben ofrecer iguales oportunidades, tanto en cantidad como en calidad, a los individuos, independientemente de su localización geográfica dentro de la ciudad (Rasoolimanesh, Badarulzaman y Jaafar, 2012).
El principal objetivo de este documento es proveer dos contribuciones a la literatura existente sobre la dimensión intraurbana de la informalidad laboral. Primero, se lleva a cabo un análisis de la distribución espacial de la informalidad a nivel intra-urbano tomando como caso de estudio la ciudad de Medellín (Colombia). Esta ciudad es la segunda en importancia económica en Colombia, después de Bogotá; ha tenido importantes cambios urbanos en los últimos años dado su enfoque en la administración y el desarrollo de transporte urbano, focalizado principalmente en las zonas de menores ingresos, y aunque sus niveles de informalidad laboral son los más bajos de Colombia, resulta interesante estudiar cómo es la configuración espacial de este fenómeno en una ciudad que es modelo internacional de desarrollo urbano5.
Segundo, se hace un análisis empírico sobre los determinantes del tamaño del empleo informal a nivel de región analítica, la cual es una unidad espacial más grande que un barrio, pero más pequeña que una comuna. Este tipo de regiones cumplen ciertas condiciones que las hacen unidades espaciales adecuadas para estudiar fenómenos socioeconómicos en el espacio. La contribución en esta parte es evaluar qué factores afectan positiva o negativamente los niveles de informalidad en el espacio, teniendo en cuenta que este fenómeno tiene una importante dimensión geográfica, ya que es bastante sensible a la localización y el contexto social. La adopción de un análisis intraurbano de la informalidad ofrece nuevas perspectivas sobre la dimensión espacial de este tipo de fenómenos en el mercado laboral en países en desarrollo.
El documento se encuentra organizado como se describe a continuación. En la siguiente sección se hace una revisión de literatura tanto nacional como internacional sobre la informalidad regional y urbana. En la tercera sección se presentan los datos utilizados en análisis, así como algunas estadísticas descriptivas de las variables de interés. El análisis empírico se lleva a cabo en la sección cuatro donde se presenta el análisis de la distribución espacial de la informalidad en Medellín y la estimación de los modelos econométricos. En la sección cinco se hace un resumen de los resultados y se presentan las conclusiones del trabajo.
2. Literatura relacionada
La literatura que tiene en cuenta el análisis de causalidad entre variables económicas (como el efecto de la calidad del barrio sobre el empleo, el efecto de asistir a un tipo de colegio en el resultado final de los estudiantes, la localización de los hogares sobre el acceso al empleo, entre otros) ha reconocido la necesidad de tener en cuenta la ubicación geográfica de las unidades de observación para entender mejor el comportamiento de los fenómenos sociales y económicos (LaSage y Pace, 2009; Elhorst, 2010). Esta ubicación geográfica o factor espacial es fundamental para saber cómo es la distribución geográfica del fenómeno analizado y permite detectar patrones espaciales que pueden servir de insumo para el diseño de políticas más focalizadas en determinados territorios.
En esta sección se relacionan los documentos más actuales que relacionan la dimensión espacial con los mercados laborales, los cuales sirvieron de base para el análisis de este estudio. En general, en estos estudios se resalta la importancia de la distribución geográfica y patrones espaciales como factores determinantes de las dinámicas de los mercados laborales.
En el contexto internacional se tienen los trabajos de Jacquemond y Breau (2015), Di Caro y Nicotra (2016), y Green y Livanos (2015). Los primeros autores llevan a cabo un análisis espacial de diferentes formas de empleo precario en Francia, intentando determinar la distribución geográfica y los factores que determinan estas formas de empleo. A partir del censo de población de 2008 y haciendo un análisis a nivel de comuna y entre zonas urbanas y rurales, los autores definen cuatro diferentes indicadores de empleo precario: trabajadores con contrato a término fijo, trabajadores subsidiados (son un tipo especial de contratos que involucra estrategias de incentivos a los empleadores para contratar personas con dificultades para integrarse al mercado laboral o gente joven), trabajadores temporales y trabajadores de tiempo parcial.
Los resultados del análisis exploratorio de datos espaciales y de modelos econométricos espaciales para cada medida de empleo precario muestran que existen importantes patrones espaciales en la distribución geográfica de cada una de estas variables. Los mayores niveles de concentración regional se encuentran en los contratos a término fijo y parcial, en particular en las regiones del sur de Francia. Los resultados también muestran que los niveles de empleo precario tienden a ser mayores en áreas rurales que en áreas urbanas. En términos de los resultados de los modelos econométricos que tienen en cuenta la dependencia espacial, los autores muestran que el empleo precario, tanto urbano como rural, se encuentra estrechamente relacionado con los niveles de desempleo, la composición de la estructura industrial, el género y la estructura familiar de los hogares.
Di Caro y Nicotra (2016), para el caso de Italia, analizan los patrones regionales del trabajo irregular, lo que los autores llaman informalidad. Con información para 20 regiones de Italia en un período entre 2001 y 2012, los autores estudian los determinantes del tamaño del empleo informal. Adicionalmente, se estudia el comportamiento cíclico de la informalidad, intentando determinar si las actividades informales actúan como un complemento o un sustituto a las actividades formales. A partir de un modelo de regresión sin dependencia espacial y modelos VAR, los autores encuentran que el tamaño del sector informal incrementa ante una mayor carga fiscal, un mercado de crédito más rígido y mayor empleo público, mientras que mejores condiciones económicas y marcos regulatorios regionales más eficientes disminuyen el tamaño del sector informal.
En cuanto al rol de las actividades informales respecto a las formales, Di Caro y Nicotra (2016) encuentran que en las regiones localizadas en el centro-norte de Italia la informalidad actúa como un complemento a la formalidad, mientras que en el sur la informalidad es sustituta de la formalidad. Estas diferencias regionales son explicadas principalmente por las diferencias en la composición sectorial de las regiones. En las regiones del centro-norte existe una mayor relevancia de la industria manufacturera con lo cual las actividades formales e informales interactúan para reducir los costos laborales. En las regiones del sur, por su parte, los altos niveles de subempleo y mayor peso de los sectores agrícola y de construcción implican que la informalidad es una actividad de supervivencia que no se encuentra relacionada con el sector moderno de la economía.
Siguiendo una definición similar de trabajo precario utilizada en Jacquemond y Breau (2015), Green y Livanos (2015) estudian el crecimiento de los trabajos de tiempo parcial y temporales en los países de Europa como consecuencia de la crisis de 2008. A partir de la construcción de un indicador de empleo precario involuntario y la estimación de un modelo probit con selección muestral (Heck-probit), los autores encuentran que existen importantes diferencias regionales en la incidencia del indicador de empleo precario. En particular este indicador fue más alto en España, Portugal y Polonia, mientras que en los países anglosajones y nórdicos fue bajo. En relación con los factores que hacen más propenso a un individuo a estar en riesgo de empleo precario, los autores encuentran que los trabajadores más jóvenes y más viejos, las mujeres, los extranjeros, aquellos individuos menos educados y que tuvieron episodios de desempleo son más vulnerables a tener un empleo precario.
En los estudios para Colombia, resaltan los trabajos de García (2008; 2011) y Galvis (2012). El primer autor, logra identificar que hay patrones interesantes en el análisis de la informalidad en Colombia, vinculándola a su dimensión regional. El autor asocia la informalidad a las características económicas y sociales de cada región, encontrando que la informalidad tiene una relación inversa con el grado de desarrollo industrial de las ciudades y directa con factores institucionales locales. Adicionalmente, García (2008 y 2011) encuentra que hay un efecto local importante en la informalidad, el cual se encuentra relacionado con la estructura productiva e integración comercial que dependen de la ubicación geográfica de las ciudades.
Por su parte, Galvis (2012), a partir de la información de los mercados laborales de las 23 principales ciudades de Colombia, mide la incidencia de la informalidad de acuerdo con las variaciones en su definición. A partir de estas diferentes definiciones se estiman modelos probabilísticos para estudiar los determinantes de la informalidad a nivel micro y se hace un análisis a nivel regional. Como principales resultados el estudio muestra que, en aquellas ciudades con mayor dinámica económica, más grandes y centrales, existen menores niveles de informalidad, lo opuesto ocurre en aquellas ciudades menos prosperas y más periféricas, donde una alta proporción de los ocupados se encuentran laborando en el sector informal.
En Colombia en el ámbito intraurbano existen pocos estudios que analicen la distribución geográfica y su dependencia espacial de las variables del mercado laboral y en particular la calidad del empleo. Pérez y Mora (2014), y Mora, Pérez y González (2016) analizan los determinantes que inciden en la calidad de empleo en Cali, centrándose en la población afrodescendiente. En estos dos estudios se construye un indicador compuesto sobre la calidad del empleo utilizando componentes principales. Los autores llegan a conclusiones similares, mostrando que los individuos afrodescendientes que viven en la zona oriental de Cali tienen una mayor probabilidad de tener empleos de baja calidad, lo cual, de acuerdo con los autores, es evidencia de concentraciones espaciales en torno a la calidad del empleo en esta ciudad.
También a nivel intra-urbano para la ciudad de Cali se tiene el trabajo de Arroyo, Pinzón, Mora, Gómez y Cendales (2016). Los autores analizan cómo la raza y el lugar de residencia de las personas inciden en la calidad del empleo. Utilizando la Encuesta de Empleo y Calidad de Vida para Cali en el 2013 y estimando un modelo probit ordenado, los autores encuentran que los individuos afrodescendientes son más propensos a tener empleos de baja calidad y existen procesos de segregación espacial en los cuales los individuos localizados en el oriente de la ciudad tienen mayor probabilidad de tener empleos de baja calidad.
Para el caso de Medellín, se tiene el trabajo de Morales y Cardona (2016). Este trabajo se centra en analizar el impacto que genera en la oferta laboral femenina la calidad de los vecindarios. La calidad de los vecindarios es medida a través de cuatro indicadores: la densidad de servicios de guardería y cuidado infantil, la disponibilidad de medios de transporte eficientes, los niveles de criminalidad y la densidad de establecimientos generadores de empleo en el vecindario. Los autores utilizan información de la Encuesta de Calidad de Vida de Medellín para el 2012, así como información georreferenciada sobre sistemas de transporte masivo, plan de ordenamiento territorial (POT), equipamientos y otros. Entre los principales resultados los autores encuentran que en los vecindarios con mayor densidad de actividad económica las mujeres que allí habitan tienen mayor probabilidad de ingresar al mercado laboral. Asimismo, los resultados de las estimaciones indican que la participación laboral de las mujeres que viven en vecindarios de ingresos bajos y medios es más elevada en la medida en que haya más establecimientos comerciales cercanos.
La anterior revisión de literatura muestra, en términos generales, que existen pocos estudios a nivel intra-urbano que tengan en cuenta la dimensión geográfica de la informalidad laboral. En este sentido, este trabajo contribuye a la literatura ofreciendo un análisis detallado de la dimensión espacial de la informalidad al interior de una ciudad, examinando los patrones espaciales y los determinantes de este fenómeno.
3. Datos y estadísticas descriptivas
3.1. Datos
En este documento se trabaja con datos para la ciudad de Medellín, la cual se ubica en el noroccidente de Colombia; es la segunda ciudad con mayor dinamismo económico y densamente poblada del país6 Medellín se encuentra dividida administrativamente en 16 comunas, las cuales agrupan un total de 243 barrios. La distribución de las comunas gira en torno al río Medellín, el cual divide la ciudad en oriente y occidente (Gráfico 1).
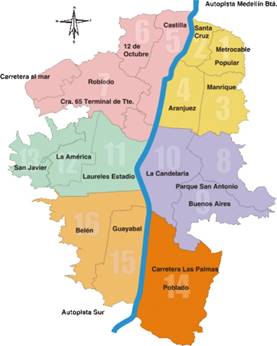
Gráfico 1 División administrativa de comunas de Medellín. Nota: Los números en cada región representan el número de la comuna. La zona azul representa el río Medellín.
Para el caso de estudio se usan los datos de la Encuesta de Calidad de Vida (ECV) para el año 2012. Esta encuesta es de sección cruzada y contiene información sobre las características de los hogares, aspectos demográficos, educación, seguridad social, mercado laboral e indicadores de pobreza y condiciones socioeconómicas. La muestra utilizada en este estudio incluye individuos entre 15 y 60 años de edad. Se tiene una muestra de 24.942 (63% de la muestra total) observaciones que en la muestra ampliada representan un total de 1.269.613 individuos.
Como se mencionó, la estructura urbana de Medellín tiene dos niveles administrativos: comunas y barrios. El proceso de muestreo en la ECV es representativo a nivel de comunas. Sin embargo, utilizar las comunas como unidad espacial de análisis para estudiar variables socioeconómicas, como el empleo informal, además de que son muy pocas unidades, presenta dos importantes desventajas (Duque, Patiño, Ruiz y Pardo-Pascual, 2015). En primer lugar, las comunas son muy grandes e internamente heterogéneas; tienen en promedio 16 barrios; las comunas más grandes tienen 23 barrios (El Poblado (comuna 14) y Belén (comuna 16)), y la más pequeña 10 barrios (Guayabal (comuna 15)). Esta heterogeneidad interna dificulta el análisis espacial de fenómenos socioeconómicos a nivel intra-urbano. En segundo lugar, como lo plantea Robinson (1950), Amrhein y Flowerdew (1992), Fotheringham y Wong (1991), y Paelinck (2000), se puede incurrir en problemas de agregación y sesgos de agregación, lo cual puede llevar a la falacia de ambigüedad por división, que implica una mala inferencia de los fenómenos analizados cuando se tiene información muy agregada. Estos problemas en nuestro caso con unidades espaciales tan heterogéneas implicarían que las características de las comunas no representarían las características de los barrios.
Alternativamente se podría trabajar con los barrios como unidades espaciales de análisis, sin embargo, esto podría implicar una falta de validez estadística de los resultados y potenciales problemas de dependencia espacial espuria (Weeks, Hill, Stow, Getis y Fugate, 2007). Con el fin de utilizar una unidad espacial de análisis más adecuada, solucionando los problemas anteriormente citados, se trabaja con lo que la literatura de ciencia regional llama regiones analíticas (véase Duque Royuela y Noreña, 2012, para una detallada descripción de estos métodos). Estas regiones analíticas cumplen una serie de criterios como el tamaño, la forma y ser homogéneas internamente, entre otras, que las hacen unidades espaciales adecuadas para estudiar fenómenos socioeconómicos en el espacio.
En particular, en el presente documento se utilizan las regiones analíticas construidas por Duque et al. (2012). Estas regiones analíticas fueron construidas en el contexto de un estudio de pobreza para la ciudad de Medellín utilizando información de la ECV para el 2007. El método utilizado por estos autores consiste en agregar unidades espaciales pequeñas en unidades espaciales más grandes teniendo en cuenta dos criterios. Primero, cada región es homogénea en términos de un conjunto de características socioeconómicas; segundo, cada una de estas regiones debe contener al menos cien hogares entrevistados, con el fin de asegurar la validez estadística. Para el cálculo de estas regiones analíticas los autores utilizaron el modelo Max-p regions (Duque, Dev, Betancourt y Franco, 2011) y consideraron diferentes variables socioeconómicas a nivel de barrio, como son las características de los materiales de la vivienda, grado de hacinamiento en las viviendas, desplazamiento por conflicto armado, pertenencia al Sistema de Identificación de Potenciales Beneficiarios de Programas Sociales (Sisben), grado de analfabetismo, ingresos del hogar, problemas de nutrición, medidas de educación sexual, entre otras.
Existen otros métodos de agregación espacial7, pero para nuestro caso específico que estamos utilizando información de encuestas de hogares, las agregaciones espaciales propuesta Duque et al. (2012) son bastante adecuadas. En particular, el procedimiento propuesto por los autores es bastante innovador al hacer uso de algoritmos de optimación que tienen las ventajas de crear unidades espaciales con formas diferentes a las regiones iniciales (barrios), permite a partir de una encuesta especificar el número de observaciones por regiones para obtener resultados estadísticamente significantes de los fenómenos socioeconómicos analizados (mínimo cien hogares por región), y hay una eficiencia en el uso de la información para crear agregaciones factibles.
El procedimiento de agregación espacial seguido por Duque et al. (2012) agrupó los 243 barrios en 139 regiones analíticas. En este trabajo se excluyeron cinco regiones analíticas, al no reportar individuos encuestados en la ECV 2012, lo que quiere decir que se cuenta con un total de 134 unidades espaciales; en el Gráfico 2 se muestran estas regiones analíticas. La ventaja de estas regiones analíticas sobre otras construidas con otras metodologías es que se parte de dos premisas: 1) la apariencia física urbana es un reflejo de la sociedad; 2) la gente que reside en áreas urbanas con características similares en términos de condiciones de vivienda, presenta características sociodemográficas similares. Esto permite inferir que la población que vive cerca presenta patrones socioeconómicos estándar y de esta manera facilita los análisis realizados a ciertos sectores de la ciudad.
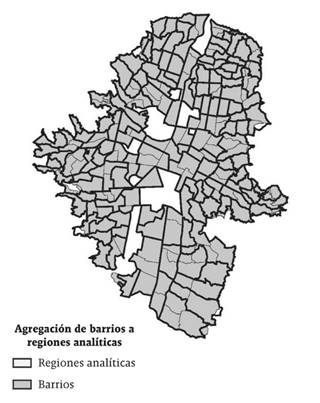
Nota: las áreas en color blanco corresponden a áreas institucionales como parques, el aeropuerto Olaya Herrera, unidades deportivas, universidades, las cuales no son incluidas en la investigación puesto que en estas no se encuentra vivienda alguna.
3.2. Estadísticas descriptivas
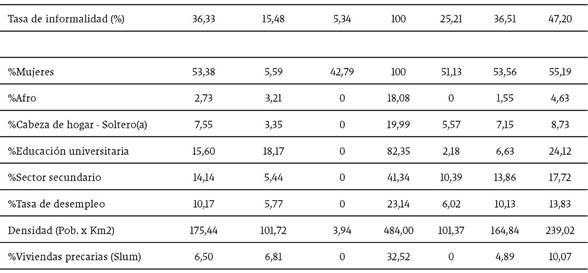
En la Tabla 1 se relacionan las variables utilizadas en el análisis y se muestran algunas estadísticas descriptivas, las cuales fueron calculadas utilizando los factores de expansión ofrecidos por la ECV para asegurar que las estimaciones fueran representativas. Como variable dependiente, se toma la tasa de informalidad que, para este caso, obedece a la definición bajo el enfoque institucional que se refiere a aquellos trabajadores que no tienen acceso a la seguridad social (salud y pensión)8.
De la Tabla 1 se observa que la tasa de informalidad promedio entre las 134 regiones analíticas es de 36,3% y varía entre 5,34% y 100%. El Gráfico 3 9 muestra espacialmente que las regiones con mayores tasas de informalidad se encuentran localizadas en la parte noroccidental de la ciudad, específicamente en las comunas 1, 2, 3 y 4 (Popular, Santa Cruz, Manrique y Aranjuez, respectivamente). También hay focos de informalidad en las partes periféricas de las comunas 8 y 13 (San Javier y Villa Hermosa), y en algunas zonas de la comuna 10 que es el centro administrativo y comercial de la ciudad.
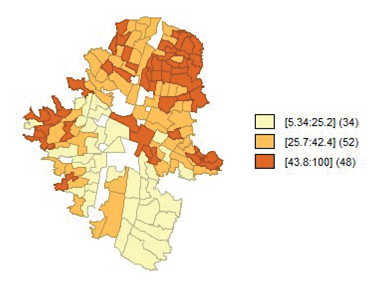
Los menores niveles de informalidad se presentan en el sur y centro-occidente de la ciudad, donde, como se verá más adelante, se encuentran las mejores condiciones socioeconómicas, como son las zonas de El Poblado (comuna 14) y Laureles-Estadio (comuna 11). Este patrón espacial es el claro reflejo de las condiciones socioeconómicas en las que se encuentra distribuida la ciudad. Las regiones del norte son las que presentan condiciones de vida más precarias de la ciudad, mientras que, del lado sur, oriente y centro-occidente, se encuentra el sector de la población con mejores condiciones de vida.
En cuanto a las variables que podrían explicar los niveles de informalidad se incluyen aquellas que caracterizan a cada una de las regiones analíticas en términos de: condiciones sociales (porcentaje de mujeres, porcentaje de afrodescendientes y porcentaje de cabezas de hogar-soltero(a), porcentaje de individuos con educación universitaria), condiciones económicas (porcentaje de individuos que laboran en el sector secundario y tasa de desempleo), y condiciones del entorno (porcentaje de viviendas precarias y densidad poblacional). Se intentó incorporar como variables explicativas la tasa de homicidios y el porcentaje de migrantes por factores de violencia. Tanto el nivel de crimen como una mayor población de migrantes por violencia pueden incidir positivamente sobre la informalidad laboral. Sin embargo, ninguna de estas variables resultó estadísticamente significativa.
En términos de características sociales, en la Tabla 1 se observa que las variables de porcentaje de mujeres, porcentaje de población afrodescendiente y porcentaje de cabezas de hogar-soltero(a) presentan tasas promedio de 53%, 3% y 8%, respectivamente. En el Gráfico 4, se muestra la distribución espacial de las anteriores variables. Para el caso del porcentaje de mujeres no existe un patrón de concentración claro. En el caso de la población afrodescendiente, se observa que la mayor concentración de esta población se localiza en las comunas 8 y 9, con mayores porcentajes en la zona periférica de la comuna 8. En cuanto a la población cabezas de hogar-soltero(a) se observa que en algunas zonas de El Poblado (comuna 14), Guayabal (comuna 15) y La Candelaria (comuna 10) existen las mayores tasas de personas que asumen la responsabilidad de sus hogares de manera individual.
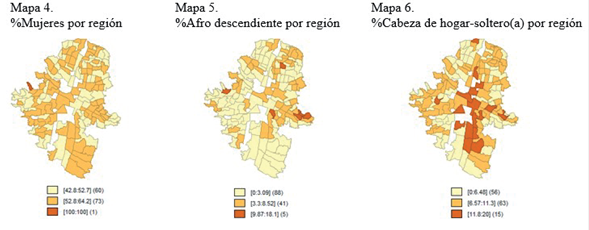
Gráfico 4 Distribución espacial del porcentaje de mujeres, afrodescendientes y cabezas de hogar-soltero(a)
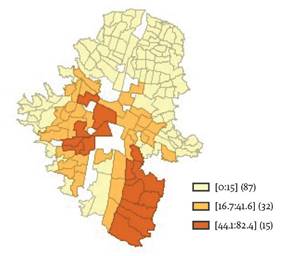
En términos de educación, se tomó como referencia la educación universitaria, que agrupa a todas aquellas personas que han aprobado niveles de educación universitaria y posgrados. Las estadísticas descriptivas de esta variable, reportadas en la Tabla 1, muestran que en promedio el 15% de la población de Medellín tiene educación superior. En términos de su distribución espacial, el Gráfico 5 muestra que, contrario a lo observado con la tasa de informalidad, las regiones con mayores niveles de población con educación universitaria se encuentran en las comunas El Poblado (14) y Laureles (11). Existe, por tanto, un patrón de desigualdad claro en términos de accesos a educación universitaria en la ciudad, puesto que es evidente que solo aquellas personas con condiciones de vida favorables logran acceder a niveles educativos altos y logran ubicarse en mejores puestos de trabajo, mientras que los individuos con peores condiciones socioeconómicas tienen menos probabilidad obtener mayores niveles educativos y son más propensos a ubicarse en la informalidad. Este patrón se refleja espacialmente y da indicios de procesos de segregación socio-espacial, en términos de que la ciudad se segmenta entre zonas con mejores condiciones socioeconómicas y zonas reprimidas en las que abundan individuos con bajo capital humano y peores condiciones económicas y sociales.
Para analizar las condiciones económicas de las regiones, se utilizan las variables de tasa de desempleo y porcentaje de individuos en el sector secundario de la economía. La tasa de desempleo (desempleados/PEA) permite determinar qué tan consolidado se encuentra el mercado laboral en las regiones y en qué estado se encuentra la fuerza laboral. El porcentaje de individuos trabajando en el sector secundario son aquellos individuos que trabajan en el sector de la industria, construcción y servicios públicos (gas, electricidad agua y alcantarillado). Esta variable de sector económico nos permite acercarnos al grado de modernidad de los trabajos de los individuos y cómo se distribuye este entre las regiones analizadas.
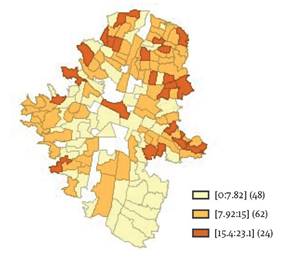
La tasa de desempleo en Medellín se encuentra en promedio en 10,16%, con regiones que pueden tener un máximo de desempleo de 23% ( Tabla 1). En términos de su distribución geográficas a través de las regiones analíticas, el Gráfico 6 muestra que las mayores tasas de desempleo se encuentran en regiones periféricas ubicadas en la parte norte de la ciudad, mientras que los menores niveles se localizan en la región sur-occidental de la ciudad específicamente en la comuna El Poblado. Aunque la zona centro-occidente también presenta menores niveles de desempleo, nuevamente se identifica que los mejores indicadores socioeconómicos los presentan regiones donde las condiciones de vida de los habitantes son las más favorables.
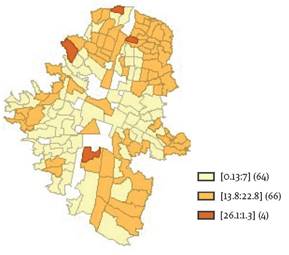
En términos de la proporción de trabajadores en el sector secundario, se tiene que en promedio el 14,14% de los trabajadores de la ciudad están empleados en este sector. La distribución espacial de esta variable (Gráfico 7) muestra que en 4 de las 134 regiones se presentan las tasas más altas de las cuales 2 se encuentran ubicadas en el norte donde las condiciones de vida son más vulnerables que en el resto de la ciudad. De igual forma, se observa que en regiones de la zona sur y norte existen comunas donde la proporción de personas que trabajan en el sector secundario se ubica en el mismo rango de 13% a 22% (comunas El Poblado, Manrique y Castilla), mientas que las tasas más bajas se localizan en las comunas San Javier y Buenos Aires.
Por último, y con respecto a características del entorno, las variables densidad y porcentaje de vivienda precaria permiten inferir cuales son las condiciones del hábitat donde residen los hogares en cada región. La variable densidad obedece al número de personas por kilómetro cuadrado en cada región. En este caso, la Tabla 1 presenta un promedio de 175 habitantes por kilómetro cuadrado. Se da la apariencia de que existen regiones donde se aglomeran personas en muy poco espacio versus regiones donde los habitantes gozan de mayor número de metros cuadrados. De acuerdo con el Gráfico 8, las regiones analíticas donde se presenta la mayor aglomeración de habitantes se ubica en la zona norte de la ciudad, específicamente en las comunas Castilla, Santa Cruz, Aranjuez y Popular. Esta última comuna agrupa varias características que determinan la situación de precariedad en la que viven sus habitantes.
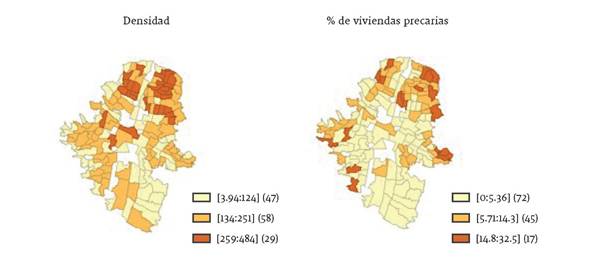
La variable porcentaje de viviendas precarias fue construida con base en la literatura relacionada con el indicador Slum, utilizado para estudios de pobreza y criminalidad (UN Habitat, 2003; 2006). Esta variable sirve para determinar si existe algún efecto de las condiciones en que viven los individuos sobre su calidad del empleo. Siguiendo la definición de UN Habitat (2006) una vivienda en el área urbana se considera precaria si cumple con alguna de las siguientes condiciones:
Material de la vivienda: las paredes no están hechas de material durable
Sobrepoblación: tres o más personas por habitación
Ausencia de acueducto
Ausencia de alcantarillado
Aunque la definición de UN Habitat (2006) también incluye la condición de no propiedad de la vivienda, para el caso de este estudio no se tomó esta característica, ya que en Colombia hay una alta proporción de individuos tanto de estratos socioeconómicos bajos como altos que no son propietarios de la vivienda donde habitan, por tanto, puede no ser una buena variable proxy para determinar la precariedad de la vivienda. Las estadísticas descriptivas de esta variable, reportadas en la Tabla 1, muestran que, en promedio, más de 6,5% de los individuos habitan en viviendas precarias y hay regiones con un máximo de este indicador de 32,5%. La distribución geográfica de las viviendas precarias reportadas en el Gráfico 8 muestra que existe una mayor proporción de estas viviendas en la periferia norte de Medellín, que como ya se ha comentado representa la zona más deprimida y con mayores niveles de pobreza de la ciudad (Duque et al., 2012, Duque et al., 2015).
En síntesis, el anterior análisis estadístico muestra que en aquellas regiones donde hay mayores tasas de informalidad, también se presentan los menores niveles educativos de la población, habitan en mayor proporción individuos desempleados y aquellos empleados se encuentran en sectores económicos menos modernos y existen altos niveles de precariedad de la vivienda. Específicamente estas regiones son aquellas ubicadas en el costado norte de la ciudad donde las personas se encuentran atrapadas en un entorno que imposibilita mejores oportunidades laborales que propendan por el desarrollo económico y perpetúan el escenario de segmentación espacial de la ciudad.
4. Resultados
4.1. Análisis de la distribución espacial de la informalidad
Para analizar la distribución espacial de los niveles de informalidad entre regiones analíticas se utilizan dos métodos. Primero, con el fin de resumir las propiedades espaciales de los datos y medir los niveles de autocorrelación espacial global, esto es, el nivel de agrupamiento espacial, se calcula el estadístico I de Moran. De acuerdo con Mitchell (1999) y LeGallo (2002) una I de Moran mayor que cero es indicio de dependencia espacial positiva e indica que niveles similares de empleo informal se encuentran agrupados. Segundo, si bien la I de Moran es útil como una medida resumen de la autocorrelación espacial global, este estadístico no permite identificar los patrones locales de asociación espacial, es decir, si existen o no clusters de informalidad concentrados en lugares particulares de la ciudad. En esta parte, entonces, se calculan indicadores locales de asociación espacial (LISA, por sus siglas en inglés) para cada región analítica (Anselin, 1995).
Es importante tener en cuenta que en el cálculo de la I de Moran y los LISA se debe calcular una matriz de pesos espaciales (W) para definir la interdependencia espacial entre las 134 regiones analíticas. En este trabajo, la contigüidad geográfica se aproxima a partir de una matriz de pesos espaciales tipo Queen de orden uno, la cual define regiones analíticas contiguas si estas comparten alguna frontera.
En el Gráfico 9 se muestra la dispersión entre el nivel de informalidad y su rezago espacial, así como el cálculo de la I de Moran y su nivel de significancia. Se observa que el estadístico de la I de Moran es alto, positivo y altamente significativo, lo cual indica que globalmente existen importantes patrones de dependencia espacial positiva en los niveles de informalidad en Medellín. En otras palabras, se corrobora que existen procesos de dependencia espacial en los niveles de informalidad en los que hay efectos de desbordamiento de este fenómeno entre regiones, con lo cual el fenómeno de informalidad de una región se encuentra asociado al nivel de informalidad en las regiones colindantes.
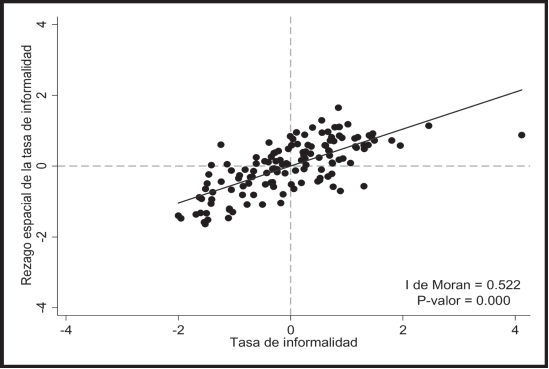
En el mapa LISA se puede identificar el tipo de autocorrelación espacial que existe y la formación de clusters asociados con los niveles de informalidad (Gráfico 10). El color rojo representa asociaciones high-high, es decir regiones con altos valores de informalidad se encuentran rodeadas de otras regiones también con altos valores de informalidad; y el color azul es para asociaciones low-low, que representan agrupaciones espaciales de similares bajos valores de informalidad. También existen otros dos tipos de dependencia espacial: high-low (rosado) y low-high (morado). La primeara asociación representa regiones con altos niveles de informalidad rodeados por regiones vecinas con bajos valores de este fenómeno, mientras que la segunda es lo contrario, regiones de baja informalidad rodeados de regiones de alta informalidad. Estas categorías corresponden a los cuatro cuadrantes en el gráfico de dispersión de la I de Moran (Gráfico 9) (Anselin, 1995; Ward y Gleditsch, 2008), siendo las dos últimas asociaciones (high-low y low-high) datos espaciales atípicos. Regiones analíticas que no muestren autocorrelación espacial estadísticamente significativa se dejan en color gris claro.
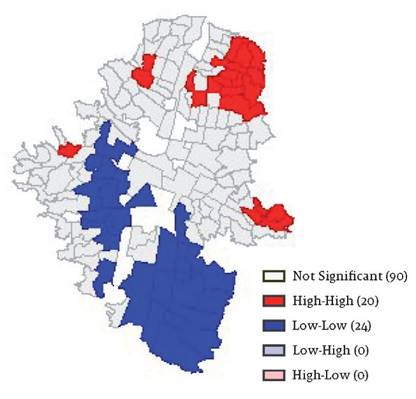
Los resultados del mapa LISA muestran que en la zona norte de la ciudad (comunas 1, 2, 3 y 4) existe un importante clúster de regiones con altos niveles de informalidad. Este mismo tipo de clúster de informalidad aparece en zonas periféricas de la comuna 8 y entre las comunas 6 y 7. En contraste, en la zona sur de la ciudad, que comprende la comuna El Poblado, existe un gran clúster de regiones con bajos niveles de informalidad. También se identifica un corredor con bajos niveles de informalidad que agrupa varias zonas entre las comunas 11, 12 y 16.
Se identifican, por tanto, interesantes patrones espaciales de la informalidad laboral, su importante dimensión geográfica y el papel que juega en la configuración socio-espacial de Medellín. La ciudad, a grandes rasgos, se encuentra segmentada entre norte (high-high) y sur (low-low) en términos de la calidad del empleo y otras condiciones socioeconómicas a las que se encuentra relacionada esta variable.
4.2. Análisis de regresión espacial
Con el fin de analizar qué variables determinan la tasa de informalidad en las regiones analíticas que componen la ciudad de Medellín, y teniendo en cuenta el aspecto espacial como determinante en la configuración de las dinámicas laborales de la ciudad, se presentan tres tipos de modelos econométricos. Un primer modelo econométrico clásico de mínimos cuadrados ordinarios (MCO) y dos modelos econométricos que toman en cuenta la dependencia espacial entre las unidades objeto de estudio llamados: modelo espacial autorregresivo (SAR o spatial lag) y modelo de error espacial (SEM o spatial error). Estos modelos parten de la correlación entre las unidades a través del espacio y cómo los datos espaciales pueden mostrar dependencia en las variables y en el término de error.
De acuerdo con Kalenkoski y Lacombe (2008), una familia de modelos de econometría espacial puede ser representada de la siguiente forma:
donde y representa la variable dependiente que en este caso corresponde a tasa de informalidad, ρ es el parámetro de dependencia espacial, W es la matriz de pesos espaciales, X denota el vector de variables independientes (% mujeres, % afrodescendientes, % cabeza de hogar, % educación universitaria, % sector secundario, densidad, tasa de desempleo y % vivienda precaria), y β es el vector asociado a los parámetros de la regresión. El error u es modelado por un proceso de autorregresión espacial con el parámetro de dependencia λ, y ε es un término de error aleatorio iid distribuido normal.
La ecuación (1) representa el modelo más general conocido como el modelo de autocorrelación espacial (SAC), e incluye dependencia espacial tanto en la variable dependiente y, como en el término de error u. Casos especiales de este modelo general pueden ser obtenidos restringiendo los parámetros de dependencia espacial. Por ejemplo, cuando el parámetro λ=0, se obtiene un modelo que exhibe dependencia espacial solo en la variable dependiente y, es decir el modelo espacial autorregresivo (SAR). El modelo de error espacial (SEM) aparece cuando ρ=0, generando como resultado dependencia espacial solo el término de error. Cuando se hace la doble restricción de λ=0 y ρ=0, que indica la falta de autocorrelación espacial, el resultado es la especificación del modelo por mínimos cuadrados ordinarios (MCO).
El termino W en la ecuación (1) representa la matriz de contigüidad espacial de primer orden, “que expresa para cada observación (fila) aquellas ubicaciones (columnas) que pertenecen a su vecindario establecidas como elementos no nulos” (Anselin y Bera, 1998). Es decir que es una matriz de 0 y 1, donde 0 significa que no existe región colindante y 1 significa que sí la hay. La matriz W de pesos espaciales proporciona una explicación de los términos Wy y Wu. El término Wy puede considerarse como un promedio ponderado de las observaciones circundantes sobre la variable dependiente y Wu puede considerarse como un promedio ponderado de los términos de error circundantes. Dependiendo del contexto del modelo de regresión, tanto ρ como λ miden el grado de autocorrelación espacial.
El uso de estos modelos es el siguiente. El modelo SAR se utiliza cuando se cree que la dependencia espacial es inherente a la variable dependiente. La dependencia espacial en la variable dependiente puede surgir debido a varios factores. Por ejemplo, pueden existir economías de aglomeración, que generan que las firmas y los individuos se localicen conjuntamente en un punto para ahorrar costos, tomar ventaja de las fuentes naturales o acceder más fácilmente a centros de empleos (Rosenthal y Strange, 2004).
El modelo SAR tiene la siguiente estructura:
La inclusión del término Wy como variable explicativa genera sesgos de simultaneidad, por lo que la estimación por MCO genera sesgo e inconsistencia en los parámetros estimados (Anselin, 1988). Por lo tanto, la estimación del modelo se lleva a cabo por el método de máxima verosimilitud.
Para el caso del modelo SEM, la dependencia espacial implica correlación espacial entre los términos de error. La intuición de este modelo es que es posible tener variables omitidas que son espacialmente correlacionadas entre ellas. La estimación por MCO del modelo SEM genera estimadores insesgados pero ineficientes, con lo cual las varianzas de los estimadores serán sesgadas y la inferencia estadística será inválida (Dubin, 1998). Este modelo al igual que el modelo SAR, se estima por máxima verosimilitud.
Este modelo SEM tiene la siguiente forma:
En este caso el término Wu define la relación de dependencia espacial entre los términos de error.
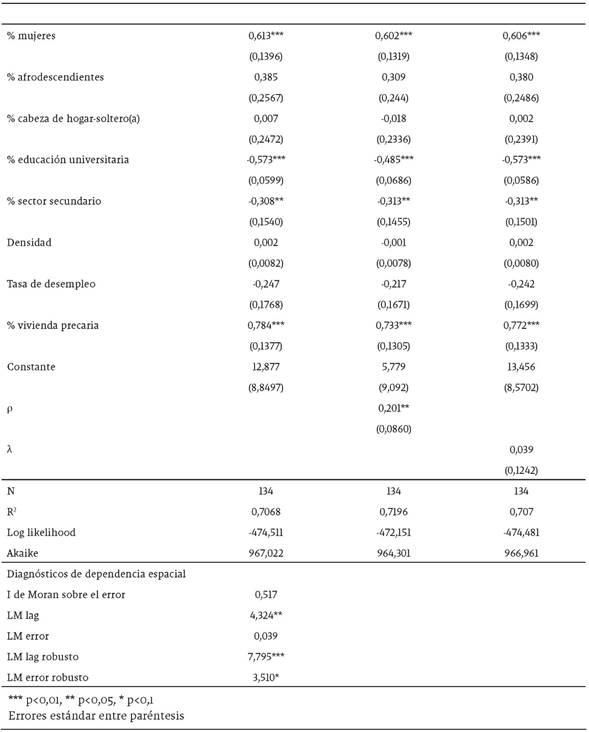
En la Tabla 2 se presentan los resultados de los tres modelos econométricos estimados. Las estimaciones son consistentes en términos de los valores de los coeficientes y la significancia estadística de estos. En los tres modelos se observa que un mayor porcentaje de mujeres y mayor porcentaje de viviendas precarias generan incrementos en los niveles de informalidad. Por su parte, las variables de proporción de individuos con estudios universitarios y proporción de trabajadores en el sector secundario tienen un efecto negativo sobre los niveles de informalidad.
Tabla 2 Resultados de los modelos econométricos (Var. dependiente: tasas de informalidad)
Fuente: cálculos propios a partir de la ECV 2012.
Con el fin de determinar qué modelo elegir entre el SAR y el SEM, y poder cuantificar los efectos, se sigue la estrategia empírica propuesta por Anselin, Bera, Florax y Yoon (1996) y Florax, Folmer y Rey (2003). Los primeros autores proveen tests de multiplicadores de Lagrange (LM) para elegir entre el modelo SAR y el modelo SEM. Existen dos tipos de test: no robustos y robustos. Los tests estadísticos no robustos se utilizan para probar sobre los residuales de la estimación por MCO la existencia de dependencia espacial en la variable dependiente (LM lag) o autocorrelación espacial en los errores (LM error). Ambos test siguen una distribución chi-cuadrado con un grado de libertad. La otra variedad de tests son los LM robustos. El estadístico LM lag robusto prueba sobre los residuales de los MCO, la existencia de dependencia espacial en la variable dependiente cuando la especificación potencialmente contiene un término de error espacialmente autocorrelacionado. Por su parte, el LM error robusto prueba sobre los residuales de los MCO la existencia de autocorrelación espacial en los errores ante la potencial existencia de dependencia espacial en la variable dependiente. Estos estadísticos robustos siguen igualmente una distribución chi-cuadrado con un grado de libertad.
Más adelante, Florax et al. (2003) definieron unas reglas que utilizan los estadísticos LM para elegir el modelo más apropiado. En la elección se siguen dos pasos. En un primer paso se calculan los estadísticos LM no robustos (LM lag y LM error). Si alguno de los dos estadísticos resulta no significativo, el modelo a elegir será aquel cuyo estadístico fue significativo. Si ambos estadísticos, por el contrario, son altamente significativos, el segundo paso implica calcular los LM robustos. Si estos estadísticos robustos son significativos, Florax et al. (2003) recomiendan escoger el estadístico con mayor valor.
Los estadísticos LM (no robustos y robustos) en nuestro caso, se muestran en la parte baja de la Tabla 2. Los resultados muestran que mientras el LM lag es significativo a un 5%, el LM error no resultó significativo a ningún nivel de significancia. Con estos resultados nos quedamos en la primera etapa del procedimiento propuesto por Florax et al. (2003) y elegimos el modelo SAR sobre el modelo SEM. Los resultados de este último modelo reportados en la columna 3 de la Cuadro 2, también muestran que el coeficiente λ del término de error espacial no es estadísticamente significativo, descartando, por tanto, dependencia espacial en el error. Este resultado es consistente con el hecho de que el estadístico I de Moran sobre el error estimado del modelo MCO (0,517), reportado en la parte baja de la Tabla 2, no es estadísticamente significativo.
Con el fin de obtener el efecto apropiado de un cambio en las variables explicatorias sobre la variable dependiente, los coeficientes estimados en el modelo SAR deben ser multiplicados por (1/(1-ρ)) (Kim, Phipps y Anselin, 2003). Se observa que la estimación de ρ es positiva y significativa al 5%, lo cual indica que el nivel de informalidad de una región analítica puede ser explicado por el nivel de informalidad experimentado en las regiones analíticas vecinas, ceteris paribus, los otros determinantes económicos y sociales. En términos de las variables explicativas, se observa que el coeficiente asociado al porcentaje de mujeres es positivo y altamente significativo, indicando que un incremento en la proporción de mujeres de 10% genera un incremento en los niveles de informalidad de 7,5%. Esto es consistente con la evidencia encontrada en otros estudios donde las mujeres son más propensas a ubicarse en la informalidad debido posiblemente a procesos de discriminación laboral (Uribe y Ortiz, 2006; García, 2017; García y Badillo, 2017), por lo que aquellas regiones con mayor proporción de mujeres presentan mayores niveles de informalidad.
Otra variable altamente significativa fue el nivel educativo, medido por la proporción de individuos con estudios universitarios. Se observa que esta variable presenta un efecto negativo importante sobre la informalidad. Puntualmente se tiene que un incremento en 10% de la proporción de población con estudios universitarios lleva a una reducción en los niveles de informalidad de 6,1%. Este resultado indica que el capital humano es un factor determinante en disminuir los niveles de informalidad, por lo que entornos con individuos más educados se reflejan en mejores indicadores laborales.
En relación con el efecto de la estructura sectorial de la producción de las regiones, se observa que una mayor proporción de individuos en el sector secundario disminuye los niveles de informalidad. En particular, se tiene que un incremento de 10% en la participación del sector secundario, disminuye la informalidad en 3,8%. Este efecto negativo puede estar relacionado con el hecho de que el sector secundario al representar el sector moderno de la economía es más productivo y, por tanto, ofrece mejores condiciones laborales.
Por último, otra variable que resultó estadísticamente significativa fue la medida de viviendas precarias, con un efecto positivo y bastante alto. La estimación del coeficiente asociado a esta variable muestra que un incremento en 10% en la proporción de viviendas precarias en las regiones, genera un incremento en los niveles de informalidad de 9,2%. Este resultado indica que aquellas regiones con mayores niveles de precariedad y pobreza generan condiciones más adversas para que los individuos localizados en estas áreas tengan buenos trabajos.
5. Conclusiones
En este trabajo se ha llevado a cabo un análisis de la dinámica espacial de la informalidad laboral a nivel intra-urbano tomando como caso de estudio la ciudad de Medellín. Utilizando los datos de la ECV 2012 y a partir de medidas estadísticas espaciales y modelos de regresión con dependencia espacial, se analiza la distribución espacial de la informalidad teniendo en cuenta su influencia en la configuración socio-espacial de la ciudad. También se estudian los factores determinantes de este fenómeno poniendo atención a variables asociadas con condiciones sociales, económicas y del entorno.
Entre los principales resultados de este estudio se encuentra que existen marcados patrones espaciales de la informalidad laboral a nivel intra-urbano en Medellín. Se observa que este fenómeno tiene una importante dimensión geográfica y desempeña un rol relevante en la configuración socio-espacial de la ciudad. En particular, se ha encontrado que Medellín está segmentada entre norte y sur en términos de la calidad del empleo y otras condiciones socioeconómicas relacionadas con esta variable. En el norte existe un clúster de regiones con altos de niveles de informalidad, regiones que igualmente se caracterizan por tener bajos niveles de educación de la población, mayores tasas de desempleo y alta precariedad de la vivienda. En contraste, en el sur existe un clusterclúster de regiones con bajos niveles de informalidad, en las cuales las condiciones socioeconómicas son mucho más favorables. Este patrón espacial permite entrever las condiciones de desigualdad tan marcadas de las que se compone la ciudad.
En términos de los determinantes de los niveles de informalidad laboral a nivel intra-urbano, se encuentra que las regiones con alta proporción de mujeres y mayor porcentaje de viviendas precarias están asociadas con regiones de niveles altos de informalidad. Por su parte, las variables asociadas a educación y empleo moderno tienen un efecto negativo sobre la informalidad laboral. Se resaltan los efectos del mayor nivel educativo y el de las viviendas precarias, los cuales tienen importantes impactos sobre el tamaño de la informalidad. En particular, se encuentra que un incremento en 10% de la proporción de población con estudios universitarios genera una reducción en la informalidad de 6,1%, mientras que el incremento en igual proporción de las viviendas precarias aumenta la informalidad en 9,2%.
De igual forma, la contigüidad de las regiones ayuda a determinar que el fenómeno de informalidad se replique casi de igual manera en la región vecina directamente, ya sea positiva para las regiones del sur y negativa para las del norte. Esto implica que la forma en que habitan los individuos y las condiciones socioeconómicas de las que gozan, forman la dinámica laboral de la que hacen parte las personas.

