Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Según Kuperman y Van Dyck (2013), el rol primario del vocabulario en la comprensión de la lectura, subraya la necesidad de métodos exactos de evaluar la familiaridad individual con palabras particulares. En las diferentes investigaciones psicolingüísticas relacionadas con los procesos de lectura y escritura, es necesario tener en cuenta una lista de estímulos para la aplicación de pruebas experimentales (Guzmán & Jiménez, 2001). En los estímulos, es fundamental el comportamiento de parámetros léxicos como la familiaridad de la palabra.
Sin embargo, este tipo de estudios es escaso en español y, específicamente en Colombia, inexistentes. No obstante, en el ámbito colombiano sí se han hecho estudios en los que se han usado estímulos en función de la familiaridad subjetiva, pero estos se han basado en los trabajos del español ibérico (Baquero, 2004; Martínez, 2004).
Familiaridad subjetiva
La familiaridad subjetiva (FS) se refiere al grado en que una persona ha usado, leído o escuchado una palabra (Delgado, 1988; Kondo, 2012). Este dato es relevante a la hora de hacer una investigación psicolingüística relacionada con la lectura o la escritura porque en la población infantil, la FS está correlacionada con la frecuencia de aparición de una palabra (Gómez-Veiga, Carriedo, Rucián & Vila, 2010; Guzmán & Jiménez, 2001).
Además, algunos autores consideran que es un buen predictor de la eficacia en el reconocimiento de palabras (Connine, Mullennix, Shernoff & Yelen, 1990; Guzmán, 1997), pues se ha encontrado que palabras con baja frecuencia de aparición y alta FS son reconocidas más rápidamente que las palabras de idéntica frecuencia, pero baja familiaridad (Gernsbacher, 1984). Lo anterior, permite comprender que la FS es una variable válida en las investigaciones sobre el reconocimiento de palabras implicado en los procesos de lectura y escritura.
Adicional a esto, la FS es uno de los principales factores que tienen efecto sobre la inteligibilidad de la palabra (Kondo, 2012). Una palabra familiar es una medida subjetiva de lo familiarizado que está el sujeto con la palabra. Lo que significa que la FS de la palabra es importante para la comprensión de esta.
Familiaridad subjetiva y frecuencia léxica
La frecuencia léxica, es una variable psicolingüística de gran interés por su influencia en el reconocimiento de la palabra (Gómez-Veiga et al., 2010). Uno de los datos más importantes que aportan las investigaciones sobre el reconocimiento de palabras frente a la enseñanza de lectoescritura, consiste en que cuando el niño se enfrenta a una palabra poco frecuente o desconocida, el acceso al léxico lo realizan a través de la ruta fonológica, debido a que esta ruta, requiere de la conversión: grafema-fonema (Cuetos, 1988). Como resultado de la práctica, los niños comienzan a reconocer palabras rápidamente, sin atender a los componentes de la palabra, es decir, registran las palabras a través de una ruta visual. De esta manera, esta ruta se irá perfeccionando a medida que el niño practique la lectura y las palabras se vayan repitiendo (Cuetos, 1988). Por lo tanto, se puede afirmar que las palabras familiares, se leen más rápidamente debido a su reconocimiento visual, lo cual repercute en una mayor accesibilidad al léxico.
Una dificultad a la que se enfrentan las investigaciones sobre lectoescritura, consiste en que la frecuencia léxica no siempre es el parámetro adecuado para realizar investigaciones en población infantil. En niños que están iniciando su aprendizaje lector, la frecuencia produce efectos opuestos a los encontrados en adultos (Jiménez, Guzmán, & Artiles, 1997). En términos generales, cuando la frecuencia y la FS no se corresponden, esta última es la que mejor predice el rendimiento en lectoescritura (Whalen & Zsiga, 1994).
Por lo tanto, las investigaciones dirigidas a una población infantil que utilicen estímulos basados en adultos, terminan por utilizar un tipo de construcción y un léxico poco representativo para dicha población. Algunos autores proponen el uso de la FS como variable predictora del reconocimiento de palabras (Guzmán & Jiménez, 2001), ya que esta puede ser una variable de más interés psicológico que la frecuencia léxica impresa, sobre todo, para realizar estudios dirigidos a poblaciones infantiles (Gómez-Veiga et al., 2010).
Parámetros psicolingüísticos
Los parámetros psicolingüísticos, son las variables lingüísticas que intervienen en el procesamiento cognitivo de producción y recepción del mensaje, permitiendo conocer los mecanismos psicológicos involucrados en el acceso ortográfico de la lectura y de la escritura (Jiménez & Muñetón, 2010). Este trabajo de FS se ha realizado bajo los parámetros psicolingüísticos de consistencia ortográfica, de longitud y estructura silábica.
El parámetro psicolingüístico de consistencia ortográfica, dispone que las palabras en las que hay una correspondencia fonema-grafema, de uno a uno, se denominan consistentes y en las palabras que no se da esta correspondencia, se denominan no-consistentes. Tomando como referente lo dicho por Jiménez y Muñetón (2002), la trascendencia de considerarlo un factor importante para la evaluación, radica en comprobar o derrocar el imaginario que advierte: en las palabras consistentes se cometerá menos errores que en las no-consistentes.
Algo similar sucede con el parámetro de longitud, el cual suele tener relación lineal con el tiempo de lectura de una palabra. Así, entre más larga sea, más tiempo se tarda en ser reconocida (Gough, 1972). Y en cuanto más larga sea una palabra, mayores probabilidades tiene el niño de incurrir en errores al escribirla (Treiman, 1993).
El parámetro de estructura silábica en posición inicial de palabra, se destaca porque algunos demuestran su influencia en las dificultades de escritura. Según los experimentos de Treiman (1992, 1993) hay mayor dificultad en la escritura de palabras que empiezan con estructura silábica mixta, es decir, con consonante + consonante + vocal (CCV) por ejemplo: blow, que en aquellas palabras que inician con una estructura silábica simple: consonante + vocal (CV) como: bowl. Esto se debe a que las palabras mixtas requieren un mayor desarrollo de la conciencia fonológica para su representación.
Con base en lo anterior, el objetivo de esta investigación consiste en evaluar la FS en un corpus de palabras del español colombiano en función de diferentes parámetros psicolingüísticos: longitud, estructura silábica y consistencia ortográfica en niños de segundo grado de educación primaria de la ciudad de Medellín. El propósito del estudio busca generar una lista de palabras de alta y baja familiaridad que sirvan como estímulos en posteriores pruebas de lectura y escritura para escolares de educación primaria.
Las palabras con FS alta serán las consistentes, las más cortas y las que conservan una estructura silábica inicial simple (CV). Mientras que las palabras con FS baja, serán aquellas no consistentes, las más largas y las que presentan una estructura silábica inicial mixta (CCV). Esto se plantea teniendo en cuenta que en las palabras que tienen solo una representación gráfica, se comenten menos errores y se memorizan más rápido que las palabras que no conservan una consistencia ortográfica (Jiménez & Muñetón, 2002), al igual que las palabras con estructura silábica simple (CV) se memorizan más temprano que las de estructura mixta (CCV), dado que estas requieren mayor desarrollo de la conciencia fonológica (Treiman, 1992, 1993). Adicional a esto, las palabras con una longitud mayor, tardan más tiempo en ser reconocidas (Gough, 1972) y según Alija y Cuetos (2006), las palabras más familiares son también las más frecuentes y las más cortas.
Método
Participantes
Los valores relativos a la FS, se obtuvieron de una muestra compuesta por 187 niños, 134 hombres (71%) y 53 mujeres (29%) de segundo grado de Educación Primaria de la ciudad de Medellín. La edad de los participantes estaba entre los 6 y 8 años. Todos los niños contaron con la autorización de sus acudientes para participar en la prueba. Inicialmente eran 230, sin embargo, fueron eliminados de la muestra aquellos niños que no estuvieron presentes en la totalidad de las pruebas. Los alumnos estaban escolarizados en tres colegios diferentes, dos privados y uno público. El número de estudiantes en la institución pública equivalía a la cantidad de alumnos de las dos privadas. Los tres colegios eran pertenecientes al estrato social 3, que corresponde al nivel socioeconómico medio de la ciudad, con esto se pretendía obtener homogeneidad entre los participantes y no analizar factores socioeconómicos.
Materiales
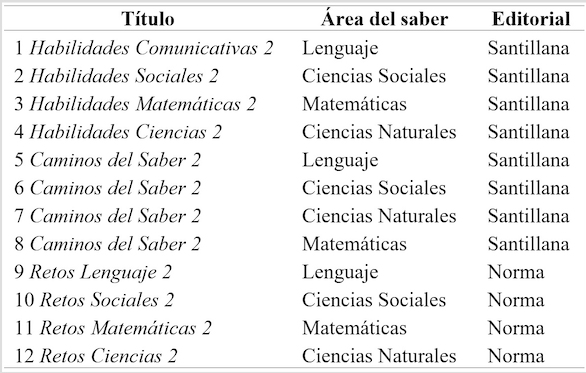
Se evaluó un total de 827 palabras que fueron extraídas de 12 libros (Ver Anexo A) de textos curriculares del segundo nivel escolar que son utilizados en las diferentes áreas del saber (i.e. lenguaje, sociales, ciencias naturales, matemáticas, etc.) y que son pertenecientes a diferentes Editoriales. Con ello se pretendía que las palabras extraídas fueran lo más variadas posible en cuanto a significados, sin estar limitadas a un área de contenido determinada. Las palabras se ajustaron a tres parámetros psicolingüísticos: consistencia ortográfica (consistentes C y no consistentes N); estructura silábica (iniciadas con consonante-vocal CV o consonante-consonante-vocal CCV) y longitud (bisílabas B y trisílabas T). Solamente se seleccionaron palabras enmarcadas dentro de las categorías gramaticales de sustantivos, verbos y adjetivos.
Procedimiento
Para conocer el grado de familiaridad que tenían los niños con la lista de palabras por presentar, se dividió cada salón de clase, por orden alfabético en dos grupos: A (primera mitad) y B (segunda mitad). A cada alumno, de acuerdo con la asignación de grupo, le correspondía leer y evaluar la familiaridad de la mitad de las palabras de la muestra. De esta manera, las 827 palabras fueron evaluadas en cada una de las clases, al ser leídas la mitad de ellas por cada alumno del grupo A, y la otra mitad por cada alumno del grupo B.
Para graduar los diferentes niveles de familiaridad de las palabras se diseñó un gráfico) que representado por un personaje, manifestaba diferentes actitudes emocionales frente a la palabra presentada (Ver Figura 1). Las actitudes del personaje fueron divididas en cuatro figuras, y debajo de cada una de las expresiones, se registró la palabra correspondiente al grado de familiaridad (nada, poco, mucho, muchísimo) para evitar confusiones por parte del niño.
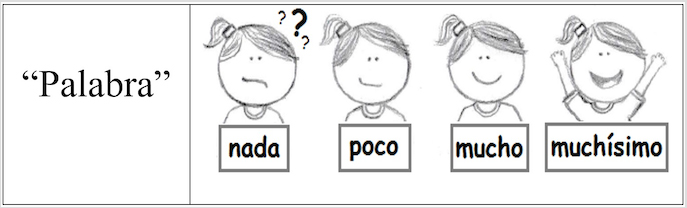
Para familiarizar a los alumnos con el personaje y sus actitudes, se realizó una sesión de entrenamiento en cada una de las clases en las que se daba a conocer el personaje y se explicaba la actividad con algunas palabras de ejemplo que no entraron en la muestra. Las instrucciones que se dieron a los alumnos al momento de realizar las pruebas, fueron las siguientes: ’en la hoja que tienen al frente aparecen unas palabras que deben leer en voz baja, frente a cada palabra aparece el personaje con diferentes expresiones en cuatro casillas. En la primera casilla se muestra algo confundido y con un signo de interrogante, debajo de esta expresión aparece la palabra nada que significa que no se conoce la palabra. En la segunda casilla el personaje aparece serio y debajo de esta aparece la palabra poco, indicando que la palabra se ha escuchado, pero no se sabe qué significa. En la tercera casilla, el personaje se muestra con una sonrisa en el rostro y debajo aparece la palabra mucho porque la palabra se ha escuchado y se conoce. Y en la cuarta y última casilla el personaje aparece muy feliz con las manos hacia arriba y debajo aparece la palabra muchísimo porque se conoce muy bien la palabra y se utiliza cotidianamente. La actividad comienza cuando se diga ¡YA! Se debe comenzar por la columna de la izquierda y frente a cada palabra deben marcar con una equis sobre el personaje si la palabra se conoce nada, poco, mucho o muchísimo. Cuando se termine la página se le da vuelta a la hoja para continuar. Quien vaya terminando puede entregar la hoja’.
Para comprobar que los niños entendían las instrucciones, los examinadores pasaron por el puesto de cada alumno fijándose en las palabras marcadas, posteriormente se les pedía que la leyeran y dieran un ejemplo de esta para ver si su respuesta coincidía con la expresión marcada.
Las sesiones fueron realizadas en la primera hora de la jornada escolar, pues se cree que en este momento es cuando los niños logran mayor grado de concentración. Se le presentó al niño una hoja con 50 palabras. El total de las palabras fueron valoradas por los alumnos en nueve sesiones, cada una fue de, aproximadamente 15 a 20 minutos de duración para todos los grupos, en un tiempo aproximado de dos meses (agosto y septiembre de 2014).
Resultados
Para los efectos de este trabajo se tuvieron en cuenta dos tipos de resultados. El primero, está relacionado con la obtención del corpus de palabras con FS alta y baja. Mientras el segundo, evidencia la relación entre la FS y los parámetros psicolingüísticos de consistencia ortográfica, longitud y estructura silábica.
Lista de palabras según la familiaridad subjetiva
A cada palabra de la muestra se le asignó un valor numérico de 1 a 4: 1 si los niños respondían nada y 4 si la conocían muchísimo. Se hizo un análisis estadístico de las respuestas en el que se halló la mediana (MD) de los valores asignados a cada palabra, ya que esta genera la tendencia central de los datos. Posteriormente, se obtuvieron los cuartiles para obtener un conjunto de datos ordenados en cuatro partes porcentualmente iguales, estas cuatro partes se tomaron en dos grandes grupos: FS alta y FS baja.
Se asumieron como palabras con FS alta, aquellas que quedaron entre los cuartiles 3 y 4. Las palabras que se situaron en el cuartil 4, lograron una mediana igual o superior a 3.74 y se llamaron Muy familiares, las palabras que se ubicaron en el cuartil 3, obtuvieron una mediana entre 3.73 y 3.63 y se llamaron Familiares.
Se tomaron como palabras con FS baja, aquellas que quedaron entre los cuartiles 1 y 2. Las palabras que resultaron en el cuartil 2, obtuvieron una mediana entre 3.62 y 3.26 y se llamaron Poco familiares, y las palabras que quedaron en el cuartil 1, obtuvieron una mediana igual o inferior a 3.25, estas se llamaron No familiares.
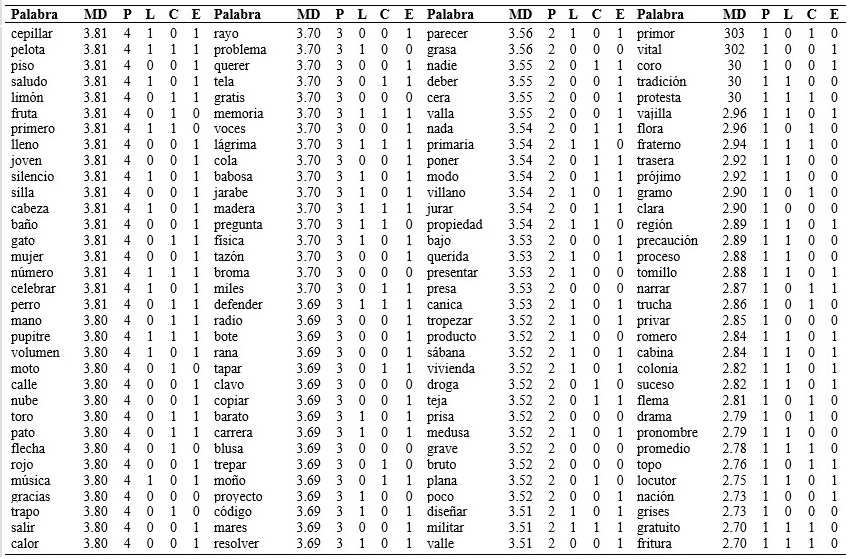
El análisis de los cuartiles permitió establecer una lista con 405 palabras con FS alta (211 muy familiares y 194 familiares) y 422 palabras con FS baja (215 poco familiares y 207 no familiares). En la Tabla 1 se recogen los resultados obtenidos en relación con la FS. Se presentan las 827 palabras seleccionadas siguiendo el criterio de ordenación por familiaridad. Además se presentan las características de la palabra según los parámetros psicolingüísticos de longitud (trisílaba=1, bisílaba=0), consistencia ortográfica (consistente=1, No consistente=0) y estructura silábica (CV=1, CCV=0).
Tabla 1 Listado de palabras ordenado por el grado de familiaridad subjetiva en función de los diferentes parámetros psicolingüísticos de longitud, consistencia ortográfica y estructura silábica.
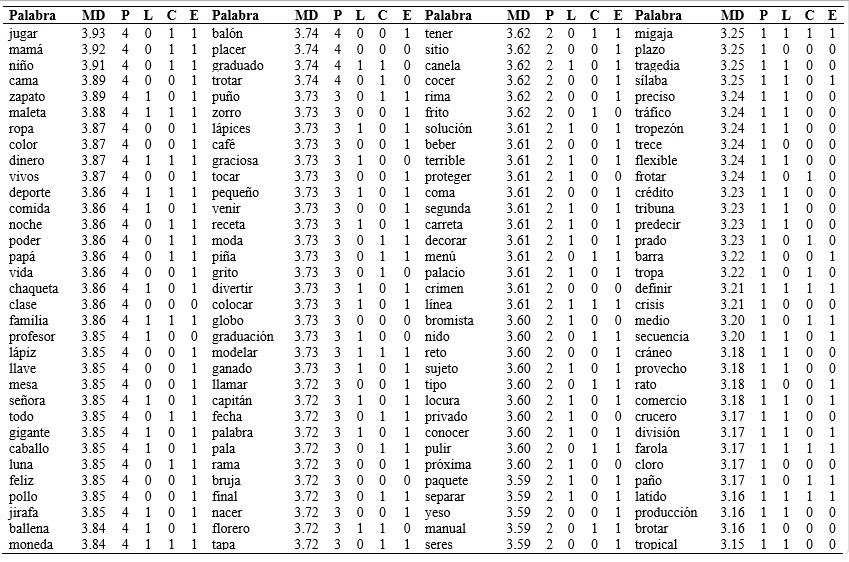
Nota:MD: mediana; P: percentil; L: longitud (1: trisílaba-0: bisílaba); C: consistencia (1: consistente – 0: no consistente); E: estructura (1: consonante vocal – 0 consonante consonante vocal).
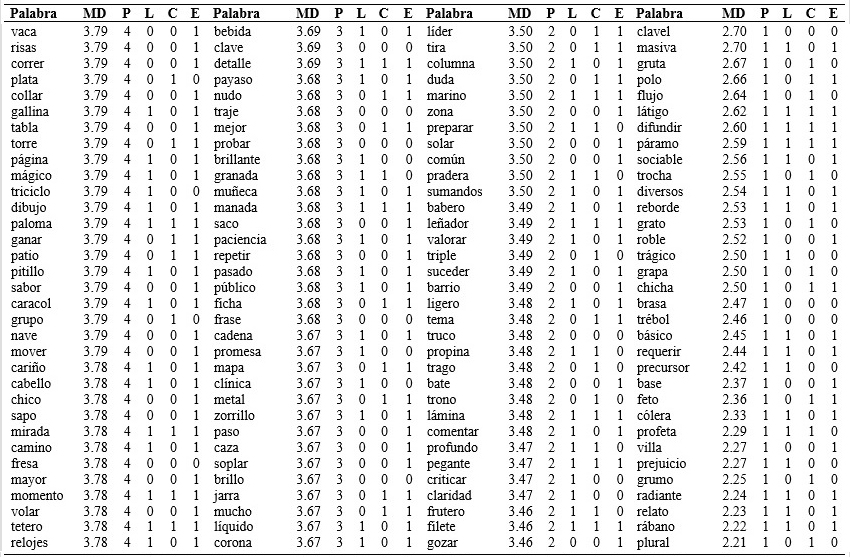
Tabla 1 (cont.) Listado de palabras ordenado por el grado de familiaridad subjetiva en función de los diferentes parámetros psicolingüísticos de longitud, consistencia ortográfica y estructura silábica.
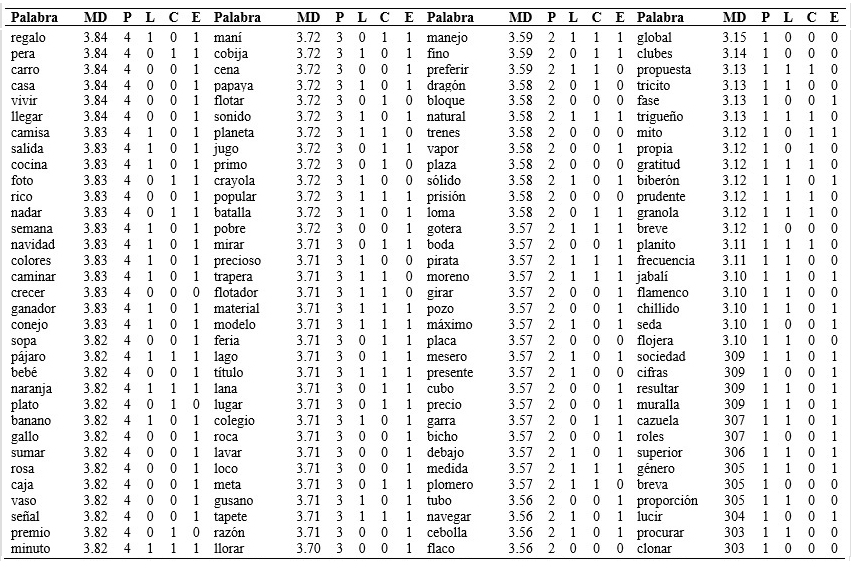
Nota:MD: mediana; P: percentil; L: longitud (1: trisílaba-0: bisílaba); C: consistencia (1: consistente – 0: no consistente); E: estructura (1: consonante vocal – 0 consonante consonante vocal).
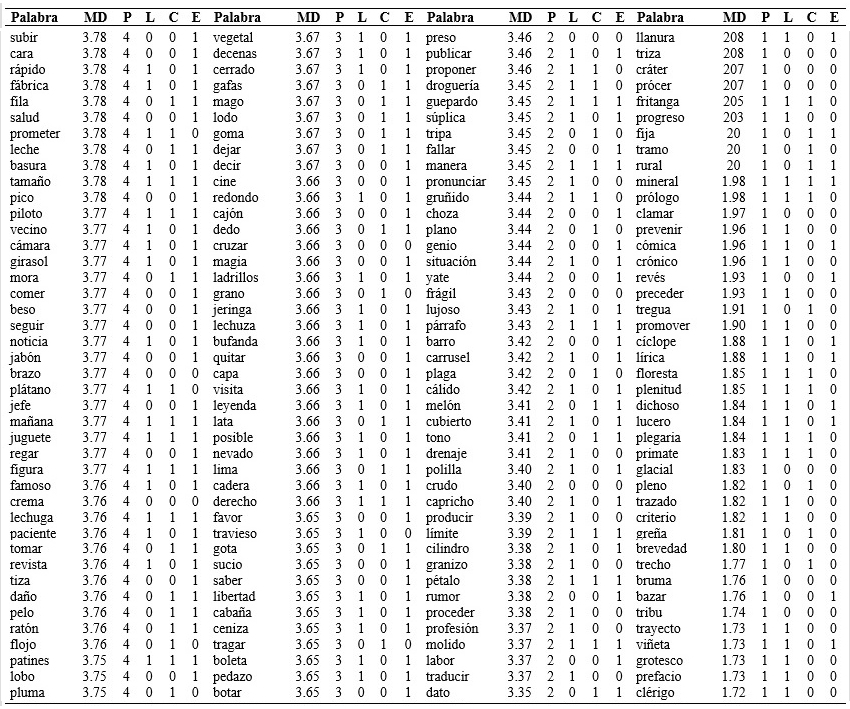
Tabla 1 (cont.) Listado de palabras ordenado por el grado de familiaridad subjetiva en función de los diferentes parámetros psicolingüísticos de longitud, consistencia ortográfica y estructura silábica.
Nota:MD: mediana; P: percentil; L: longitud (1: trisílaba-0: bisílaba); C: consistencia (1: consistente – 0: no consistente); E: estructura (1: consonante vocal – 0 consonante consonante vocal).
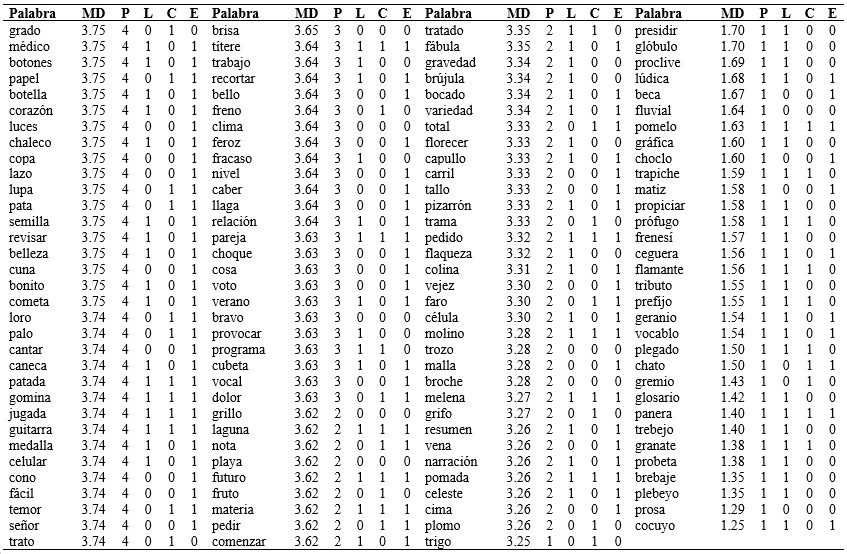
Tabla 1 (cont.) Listado de palabras ordenado por el grado de familiaridad subjetiva en función de los diferentes parámetros psicolingüísticos de longitud, consistencia ortográfica y estructura silábica.
Nota:MD: mediana; P: percentil; L: longitud (1: trisílaba-0: bisílaba); C: consistencia (1: consistente – 0: no consistente); E: estructura (1: consonante vocal – 0 consonante consonante vocal).
Tabla 1 (cont.) Listado de palabras ordenado por el grado de familiaridad subjetiva en función de los diferentes parámetros psicolingüísticos de longitud, consistencia ortográfica y estructura silábica.
Nota:MD: mediana; P: percentil; L: longitud (1: trisílaba-0: bisílaba); C: consistencia (1: consistente – 0: no consistente); E: estructura (1: consonante vocal – 0 consonante consonante vocal).
Tabla 1 (cont.) Listado de palabras ordenado por el grado de familiaridad subjetiva en función de los diferentes parámetros psicolingüísticos de longitud, consistencia ortográfica y estructura silábica.
Nota:MD: mediana; P: percentil; L: longitud (1: trisílaba-0: bisílaba); C: consistencia (1: consistente – 0: no consistente); E: estructura (1: consonante vocal – 0 consonante consonante vocal).
Relación entre la familiaridad subjetiva y los parámetros psicolingüísticos
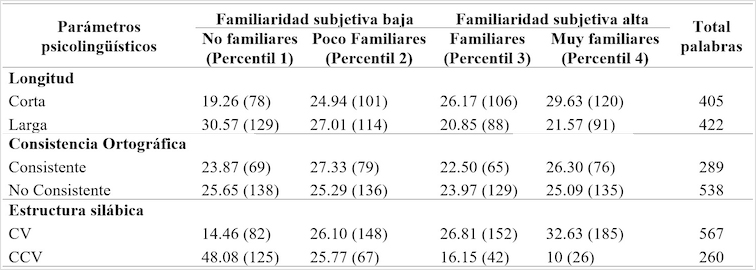
Después de obtener la lista de palabras, se observó la FS en función de la frecuencia con los diferentes parámetros psicolingüísticos (Ver Tabla 2).
Los resultados muestran un patrón entre estas dos variables. En los datos obtenidos para el parámetro psicolingüístico de longitud se puede observar que el mayor número de palabras cortas, se encuentran en las palabras denominadas Muy familiares y el número de estas va disminuyendo de manera proporcional según disminuye el nivel de familiaridad. Caso contrario se da con las palabras largas, pues la mayor frecuencia se ubica en las No familiares y van disminuyendo a medida que va aumentando la familiaridad, es decir que en las Muy familiares se encuentra el menor número de palabras largas.
Los datos hallados en el parámetro psicolingüístico de consistencia ortográfica, permanecen un poco más uniformes, sin embargo, también se pueden notar cambios en función de la familiaridad. En las palabras con ortografía consistente el mayor porcentaje se ubica en las palabras poco familiares, aunque, en los otros tipos de familiaridad se observa el mismo patrón mencionado para las palabras bisílabas, esto es, a mayor familiaridad mayor porcentaje de palabras consistentes. En las palabras no-consistentes, el mayor porcentaje se encuentra en las no familiares y este va decreciendo según aumenta la familiaridad, con la excepción de que hay un porcentaje menor de palabras no consistentes en las familiares que en las muy familiares.
En el parámetro psicolingüístico de estructura silábica, el patrón de relación entre ambas variables muestra una mayor solidez. Así, en las palabras con estructura silábica simple (CV) el mayor porcentaje se encuentra en las palabras muy familiares, disminuyendo paulatinamente hasta encontrar el menor porcentaje en las no familiares. En las palabras que inician con una estructura silábica mixta (CCV), se da el caso inverso, dado que el mayor porcentaje se ubica en las palabras no familiares y este va disminuyendo a medida que aumenta la familiaridad.
Al comparar los grados de familiaridad extremos, se puede observar que el patrón es inverso para cada parámetro psicolingüístico. En las palabras muy familiares el porcentaje de las palabras bisílabas, consistentes y con estructura CV es más alto que en las palabras no familiares.
Discusión
El propósito de esta investigación fue evaluar la familiaridad subjetiva en un corpus de palabras del español utilizado en la región colombiana, en función de diferentes parámetros psicolingüísticos como la longitud, la estructura silábica y la consistencia ortográfica en niños de segundo grado de educación primaria de la ciudad de Medellín. En primer lugar, se extrajeron palabras de diferentes textos escolares del respectivo grado educativo; luego, los niños valoraron estas palabras según el nivel de familiaridad que tenían con ellas y, a continuación, las palabras se clasificaron, en dos grandes grupos: alta y baja familiaridad. Finalmente, se observó la relación entre los parámetros psicolingüísticos de consistencia ortográfica, longitud y estructura silábica y los diferentes tipos de FS.
La hipótesis que se planteó al inicio de este estudio, sugería que las palabras con FS alta serían las consistentes, las más cortas y las palabras que conservaran una estructura silábica inicial simple (CV); mientras que las palabras con FS baja, serían aquellas no consistentes, las más largas y aquellas que tuvieran una estructura silábica inicial mixta (CCV). Esto se planteó debido a que desde un punto de vista teórico, se memorizan más rápido las palabras consistentes que las no consistentes y las palabras con estructura silábica CV, que aquellas con estructura CCV. Además, las palabras largas o trisílabas tardan más tiempo en ser reconocidas que las bisílabas.
El análisis de los datos obtenidos, evidencia una relación de la FS con cada uno de los parámetros psicolingüísticos propuestos. Lo que quiere decir que los resultados del presente experimento van en la misma línea con las predicciones realizadas al principio del estudio. Sin embargo, se puede destacar la escasa magnitud encontrada en el parámetro psicolingüístico de consistencia ortográfica en relación con la FS, no obstante, como se observa en la Tabla 2, los datos de las palabras muy familiares y no familiares muestran la misma línea de sentido, esto representa el mayor porcentaje de palabras no consistentes está en las palabras no familiares y el menor en las muy familiares; el mayor porcentaje de palabras consistentes están en las palabras muy familiares y el menor en las no familiares.
Es así como la hipótesis planteada al principio de la investigación, se corrobora con los resultados expuestos en este trabajo. Se puede decir entonces que las palabras más familiares para los niños, son también las palabras más cortas, consistentes y con una estructura silábica inicial simple (CV). En consecuencia, las palabras menos familiares son las palabras no consistentes, las más largas y las que comprenden una estructura silábica inicial mixta (CCV).
El corpus obtenido se presenta organizado según su FS (de alta a baja), se especifican la mediana (MD) y el percentil de cada palabra. Adicionalmente se enseñan las características de la palabra según los parámetros psicolingüísticos de longitud (trisílaba-bisílaba), consistencia ortográfica (Consistente - No consistente) y estructura silábica (CV-CCV).
Un corpus como el que se halló con esta investigación, es importante porque los datos obtenidos por medio de la FS facilitan posibles estímulos para ser usados en posteriores pruebas dirigidas a un público infantil hispanohablante, debido a que la mayoría de trabajos encontrados, basan sus datos en otras lenguas como el inglés y los trabajos elaborados en lengua española son construidos con léxico de adultos, estos no son representativos para usar en sujetos de corta edad (Jiménez et al., 1997). En este mismo sentido, las investigaciones encontradas realizadas con niños se basan, exclusivamente, en el español ibérico por lo que, actualmente, no se cuenta con un corpus de palabras representativo de la población infantil en Colombia.
Los datos obtenidos por medio de la FS, permiten hallar posibles estímulos a través de los cuales, en el futuro, se podrían examinar relaciones entre lectura, escritura y otros procesos cognitivos que intervienen en el procesamiento lingüístico. Además, como se explicó anteriormente, la FS puede afectar la inteligibilidad de las palabras, por lo tanto el hecho de utilizar palabras con alta familiaridad subjetiva en un experimento cognitivo, mitiga el sesgo de comprensión permitiendo obtener resultados más claros y concisos.
Con este trabajo, se ofrece una herramienta de utilidad para futuras investigaciones, especialmente en el campo de la psicolingüística, que trabaje con público infantil. Se proporciona, entonces, una base de datos con más de 800 palabras con FS alta y FS baja a la investigación psicolingüística interesada en realizar estudios evolutivos. Adicionalmente, la base de datos se divide en cuatro categorías que permiten observar dos extremos entre las palabras más familiares para los niños (muy familiares) y las palabras menos familiares (no familiares), permitiendo también evidenciar una parte más común para los niños que podría clasificarse como FS media (familiares y poco familiares).
Conclusión
Esta investigación presenta un corpus de FS en Colombia, específicamente en niños, ampliando el número de datos recogidos al respecto en lengua castellana. Dado que la mayoría de estos estudios se han realizado en inglés y otras lenguas con ortografía opaca. Esta investigación puede aportar elementos para la formulación de estrategias pedagógicas más adecuadas y eficaces que redunden en una mejor adquisición y consolidación de los procesos de lectoescritura en los niños en el contexto escolar.
Adicionalmente, se proponen otros parámetros psicolingüísticos, como la longitud, la estructura silábica y la consistencia ortográfica de la palabra que se relacionan con la FS y esta, a su vez, correlaciona con la frecuencia léxica, pues estudios recientes demuestran que las palabras frecuentes se leen más rápido y son las más familiares (Guzmán & Jiménez, 2001). Se corrobora que, como dijo Gómez-Veiga et al. (2010), la frecuencia léxica es importante para el reconocimiento de la palabra siendo así, la FS relevante para la comprensión (Kondo, 2012), ya que indica el grado de relación que tiene una persona con una palabra.
Se espera que estas palabras puedan ser usadas como estímulos con carácter pedagógico y puedan facilitar a otros profesionales el acceso ágil al léxico infantil. En el futuro, se puede pensar en una ampliación del corpus proporcionado y contar con un número de sujetos más alto para incrementar la muestra, ya que en el sistema educativo colombiano muchos estudiantes que inician el segundo grado de Primaria, no tienen un pleno dominio de la lectura, por lo que al final de la recolección de datos debían ser descartados, ya que no eran pruebas hechas a conciencia, lo cual redujo la muestra. Adicionalmente, se puede proyectar un estudio transversal que permita comparar el grado de FS en niños de otros grados escolares y así contribuir al robustecimiento de estos datos que siguen siendo escasos en la actualidad.