










Services on Demand
Journal
Article
 text in
text in  English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkColombia Médica
On-line version ISSN 1657-9534
Colomb. Med. vol.50 no.1 Cali Jan./Mar. 2019
https://doi.org/10.25100/cm.v50i1.4196
Carta al editor
Diferencias Clínicas entre niños con asma y rinitis en áreas urbanas y rurales
1Universidad del Valle, School of Public Health, Faculty of Health, CISALVA Institute, Cali, Colombia.
Estimados Editores:
En el artículo de Sánchez, et al.1, reportaron un interesante estudio sobre síntomas de asma y rinitis en niños en áreas urbanas y rurales de Colombia; identificando que el control de los síntomas es más difícil para los niños de las áreas urbanas. Ese artículo tiene la ventaja metodológica de haber realizado un seguimiento prospectivo de los pacientes pediátricos; sin embargo tengo varias preguntas sobre el mismo:
1) El cálculo del tamaño de la muestra no es claro. Los autores mencionaron las prevalencias de asma y rinitis en las áreas urbanas, con su error correspondiente, pero ellos no utilizaron esos parámetros para el cálculo del tamaño de la muestra. Por otro lado, los autores argumentaron que el desenlace (o variable resultado) principal del estudio fue comparar el tratamiento de asma y rinitis entre los niños de las áreas urbanas y rurales; entonces, los lectores pueden asumir que la medida de efecto utilizada fue la diferencia en el puntaje de la Prueba de Control del Asma (en inglés, Asthma Control Test - ACT) entre las dos áreas; pero los autores no explicaron este punto claramente. Adicionalmente, no es claro por qué el cociente entre los sujetos de las áreas urbanas/rurales es 1.57: ¿Es éste el cociente encontrado en las instituciones de salud del estudio? En consecuencia, parece que el cálculo para el tamaño de la muestra apropiado debe haber sido la diferencia de medias (o promedios) entre dos poblaciones independientes, aunque los autores no reportaron ningún tamaño de efecto de la prueba ACT basado en estudios previos. De esta forma, recalculé la diferencia de medias (como medida de efecto), utilizando el poder (80%) y el tamaño de muestra (urbano= 201 y rural= 128) reportado por los autores; usando Stata® 14.2 (comando power twomeans). De esta forma, el tamaño del efecto mínimamente detectable debería ser 3.5; el cual es mayor que la medida del efecto sobre el puntaje del ACT, estimada en eeste estudio 1 (es decir: 3.0); resultando así un estudio con bajo poder estadístico, al menos para las estimaciones transversales. Teniendo en cuenta estas consideraciones, ¿cuál fue el procedimiento de cálculo del tamaño de la muestra utilizado para planear este estudio?
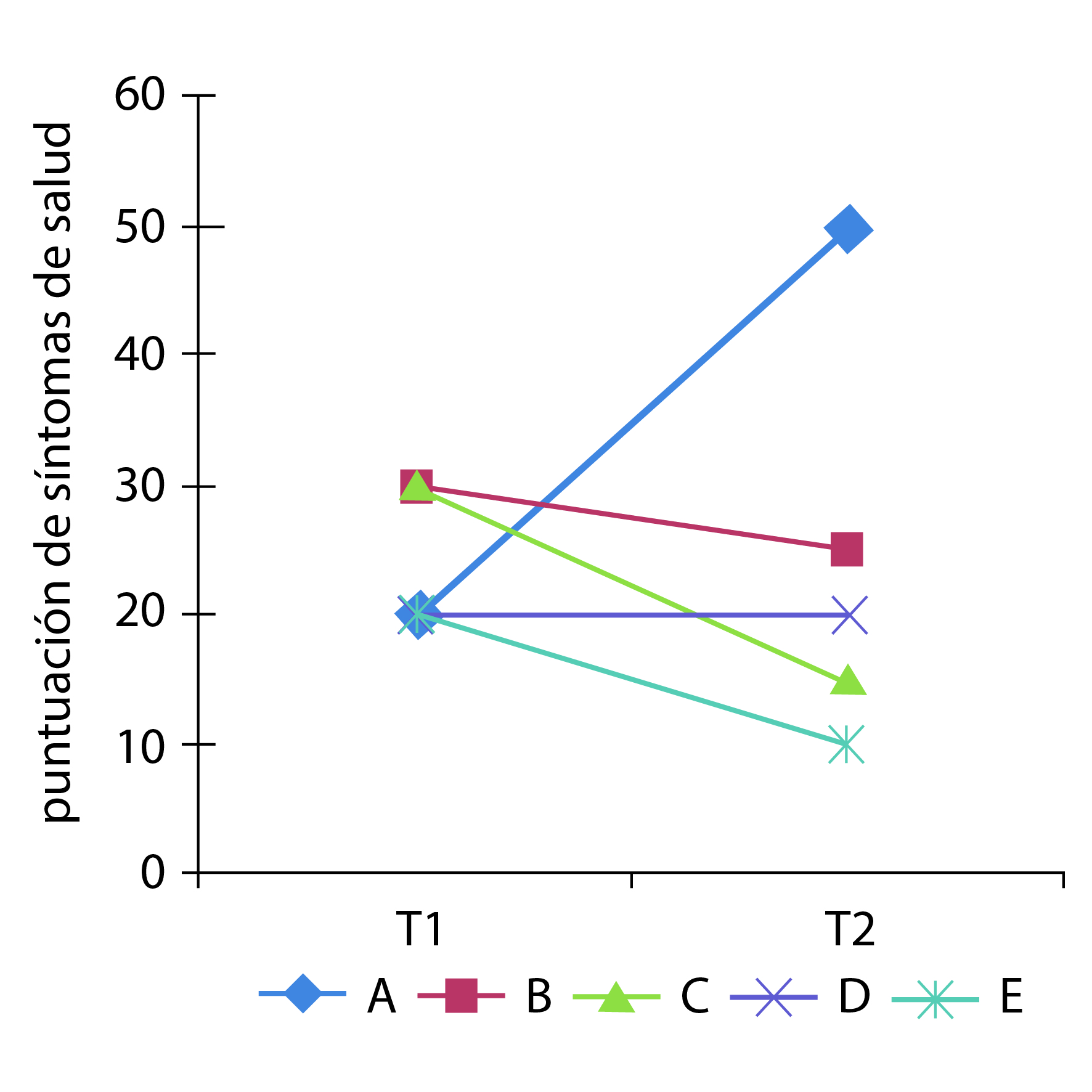
2) La investigación se diseñó como un estudio de seguimiento con cuatro mediciones (o valoraciones) después de transcurridos 3, 6, 9 y 12 meses; pero los análisis estadísticos fueron realizados siguiendo un abordaje transversal en el momento de cada medición, sin tener en cuenta la naturaleza longitudinal (o multinivel) de las medidas repetidas de cada paciente y sin ajustar tampoco por los puntajes de línea de base de cada paciente. Los análisis transversales no son apropiados para determinar los patrones longitudinales intra-sujetos; por ejemplo, la Figura 1 muestra el seguimiento hipotético de un puntaje de síntomas de salud para cinco sujetos, con dos mediciones a lo largo del tiempo (T=1 y T=2). Si se calcula la media de forma transversal para cada tiempo de medición, el valor es el mismo (24 puntos), pero las trayectorias individuales de cada persona (es decir, las líneas) muestran diferentes patrones de síntomas: algunos sujetos mejoran y otros empeoran con el paso del tiempo. De esta forma, es importante enfatizar que en el artículo de Sánchez et al.1, las medidas mensuales de cada paciente están anidadas (o aglomeradas) en cada individuo, lo cual constituye una estructura multinivel longitudinal 2. Hoy en día, existen diversos abordajes estadísticos (paramétricos y no paramétricos) para analizar apropiadamente este tipo de datos longitudinales, es decir, datos a partir del seguimiento de pacientes con mediciones repetidas de las variables desenlace a lo largo del tiempo 3,4. Las técnicas actuales para el análisis de datos longitudinales (o repetidos) tienen la ventaja de permitir realizar los análisis estadísticos cuando existen datos longitudinales incompletos o no balanceados, es decir, datos con valores perdidos (cumpliendo los supuestos MCAR o MAR de datos perdidos, por sus siglas en inglés), o con pérdidas a lo largo del seguimiento o datos con diferentes momentos de medición 5,6. Complementariamente, hoy en día las funciones para realizar los análisis de datos longitudinales, usando modelos de regresión mixtos (de efectos fijos y aleatorios) o de abordajes bayesianos, han sido implementadas en diferentes paquetes estadísticos informáticos 4. Estas técnicas permiten analizar no solo variables desenlace continuas con una distribución normal, sino también variables resultado del tipo continuas no-normales, dicotómicas y categóricas polinomiales 6. Por otro lado, en la Figura 3 de Sánchez et al.1, para las comparaciones de la farmacoterapia a los 12 meses, entre niños del área urbana vs. área rural, no se realizó ningún ajuste (o control) de los valores de línea de base de los puntajes de farmacoterapia correspondientes, cuyos valores eran diferentes entre los niños del área urbana vs. rural. Consecuentemente, las diferencias resultantes entre estas áreas a los 12 meses de seguimiento podrían explicarse, en su lugar, por las diferencias en los puntajes de línea de base entre las dos áreas y no por la residencia de los niños en un área específica. Finalmente, debido a que el diseño de la investigación es un estudio epidemiológico observacional, entonces es necesario realizar análisis estadísticos que ajusten por (o controlen) las variables confusoras que están relacionadas, teórica o conceptualmente, con las variables desenlace del estudio 7,8, porque el lugar de residencia de los niños (urbano o rural) no fue asignado al azar. Teniendo en cuenta la explicación anterior, ¿cuáles son los efectos del ambiente urbano sobre los puntajes de tratamiento farmacológico y de síntomas de asma y rinitis, a lo largo del tiempo, después de realizar los análisis estadísticos apropiados (es decir, modelos de regresión múltiple 7 y de medidas repetidas 3,4)?
3) Cuando el diseño de una investigación es un estudio longitudinal con medidas repetidas y los datos son analizados adecuadamente utilizando los métodos estadísticos actualizados, esta situación permite utilizar tamaños de muestra más pequeños, dada la eficiencia de los métodos de análisis de datos longitudinales. La eficiencia mejora cuando se agregan más mediciones para cada sujeto de investigación 4. Las guías para el cálculo del tamaño de muestra para estudios de medidas repetidas han sido abordadas por Guo, Logan, Glueck y Muller 9. De esta forma, ¿se tuvieron en cuenta estas guías para el cálculo del tamaño de muestra en este estudio?
4) En el artículo no se especifica ni la ubicación ni el nivel de atención de las instituciones de salud del estudio; ni tampoco se explican los criterios para haber elegido esas instituciones. Esta situación tiene varias implicaciones: Por ejemplo si los niños del área rural con los peores niveles de síntomas fueron referidos a centros de atención diferentes a los centros elegidos en esta investigación, entonces pudo haber ocurrido un sesgo de selección, el cual afecta la validez de los hallazgos del estudio 2,10. Teniendo en cuenta lo anterior, ¿cuál era el nivel de atención y la ubicación de las instituciones de salud del estudio y que sesgos potenciales se pudieron haber presentado dada la selección de esas instituciones?
References
1. Sánchez J, Sánchez A, Cardona R. Clinical differences between children with asthma and rhinitis in rural and urban areas. Colomb Med (Cali). 2018; 49(2): 169-174. [ Links ]
2. Snijders TAB, Bosker RJ. Multilevel analysis: an introduction to basic and advanced multilevel modeling. 2nd ed. Los Angeles: SAGE; 2012. [ Links ]
3. Fitzmaurice G, Davidian M, Verbeke G, Molenberghs G. Longitudinal data analysis. Boca Raton: CRC Press Taylor & Francis Group; 2009. [ Links ]
4. Brown H, Prescott R. Applied mixed models in medicine. 3rd ed. West Sussex: Wiley; 2015. [ Links ]
5. Cnaan A, Laird NM, Slasor P. Using the general linear mixed model to analyse unbalanced repeated measures and longitudinal data. Statist Med. 1997; 16(20): 2349-2380. [ Links ]
6. Gueorguieva R, Krystal JH. Move over ANOVA: progress in analyzing repeated- measures data and its reflection in papers published in the Archives of General Psychiatry. Arch Gen Psychiatry. 2004; 61(3): 310-317. [ Links ]
7. Szklo M, Nieto J. Epidemiology beyond the basics. 2nd ed. Sudbury, MA: Jones and Bartlett; 2007. [ Links ]
8. Hernán MA, Hernández-Díaz S, Werler MM, Mitchell AA. Causal knowledge as a prerequisite for confounding evaluation: an application to birth defects epidemiology. Am J Epidemiol. 2002; 155(2): 176-184. [ Links ]
9. Guo Y, Logan HL, Glueck DH, Muller KE. Selecting a sample size for studies with repeated measures. BMC Med Res Methodol. 2013; 13(1): 100. [ Links ]
10. Hernán MA, Hernández-Díaz S, Robins JM. A structural approach to selection bias. Epidemiology. 2004;15:615-625. [ Links ]
 This is an open-access article distributed under the terms of the Creative Commons Attribution License
This is an open-access article distributed under the terms of the Creative Commons Attribution License
