










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkIteckne
versão impressa ISSN 1692-1798
Iteckne vol.12 no.1 Bucaramanga jan./jun. 2015
Caracterización de un clúster y sus recursos en una red Ad Hoc a partir de la distribución geométrica truncada
Characterization of a cluster and its resources in an Ad-Hoc network starting from the truncated geometric distribution
Juan Pablo Ospina-López1, Jorge Eduardo Ortiz-Triviñio2
1 M. Sc. (c). Ingeniería de Sistemas y Computación. Universidad Nacional de Colombia. Bogotá, Colombia. jpospinalo@unal.edu.co.
2 Ph. D. Sistemas y Computación. Universidad Nacional de Colombia. Bogotá, Colombia. jeortiz@unal.edu.co.
RESUMEN
Una de las propiedades esperadas en las redes ad hoc es la capacidad de aumentar su tamaño recibiendo nuevos nodos y configurando nuevas aplicaciones sin afectar la calidad de los servicios ofrecidos. Esta propiedad, llamada escalabilidad se ve afectada por la naturaleza descentralizada de las redes ad hoc y hace necesario desarrollar mecanismos que le permitan a un gran número de nodos trabajar de manera conjunta sin afectar el rendimiento de la red. En este trabajo, proponemos un modelo estocástico basado en la distribución geométrica truncada, el cual permite caracterizar el nivel de recursos en una arquitectura jerárquica, para luego establecer una relación adecuada entre el nivel de recursos de dos capas sucesivas de la red.
PALABRAS CLAVE: Redes Ad Hoc, Escalabilidad, Modelo Estocástico, Distribución Geométrica, Arquitectura de red.
ABSTRACT
One of the expected properties of the ad hoc networks is the ability to increase its size to receive new nodes and configure new applications without affecting the quality of services. This property, called scalability is affected by the decentralized nature of ad hoc networks making it necessary to develop mechanisms that allow a large number of nodes work together without affecting network performance. In this paper, we propose a stochastic model based on the geometric distribution, which allows to characterize the level of resources in a hierarchical architecture and then establish an appropriate relationship between the level of resources of two successive layers of the network.
KEYWORDS: Ad hoc Networks, Scalability, Stochastic Model, Geometric Distribution, Network Architecture.
1. INTRODUCCIÓN
Las redes ad hoc son un paradigma totalmente distinto a las redes tradicionales, carecen por completo de una infraestructura fija, dan completa autonomía a los nodos para configurar su participación en la red. Esta naturaleza descentralizada trae consigo la aparición de propiedades emergentes y genera la necesidad de incorporar en los nodos ciertas características que les permitan configurarse e integrarse como parte de la red sin afectar su rendimiento.
Una de las propiedades esperadas en las redes ad hoc es la capacidad de aumentar de tamaño al recibir nuevos nodos y configurar nuevas aplicaciones sin afectar la calidad en los servicios ofrecidos. Esta propiedad denominada escalabilidad, es uno de los principales desafíos en el diseño de protocolos y una característica fundamental para lograr redes ad hoc con una alta capacidad de despliegue. En el siguiente artículo se propone un modelo basado en la distribución geométrica truncada, el cual permite caracterizar los recursos de una red bajo una arquitectura jerárquica y, posteriormente, establecer una función que permita obtener la relación adecuada entre el nivel de recursos de dos capas sucesivas de la red.
El artículo está organizado de la siguiente forma: primero, se hizo una breve revisión sobre las principales características de las redes ad hoc; luego se describen los factores que afectan de manera significativa la escalabilidad de la red, así como los resultados obtenidos para diferentes arquitecturas y, finalmente, se hará la descripción del modelo propuesto.
2. CARACTERÍSTICAS DE LAS REDES AD HOC
Las redes ad hoc son sistemas computacionales auto-organizados, formados por un conjunto de nodos que se comunican entre sí a través de enlaces inalámbricos y que no dependen de una infraestructura preexistente para funcionar. Cada nodo configura su participación en la red de forma autónoma, conociendo únicamente la información de los vecinos que se encuentran en su radio de transmisión. Entre sus principales características se encuentran [1], [2]:
Funcionamiento autónomo: las redes ad hoc son adaptativas y tienen la capacidad de configurarse así mismas sin ningún tipo de control externo.
Topología dinámica: la capacidad de los nodos para desplazarse de forma aleatoria puede generar cambios en la topología y causar fallas en las comunicaciones [3], [4].
Necesidad de cooperación: el objetivo de la cooperación entre nodos es buscar un equilibrio que permita operar de manera distribuida, compartir recursos y maximizar el rendimiento de la red [5], [6].
Administración de la energía: los dispositivos inalámbricos funcionan a través de baterías con capacidades limitadas. Un manejo eficiente de la energía garantiza el funcionamiento de los nodos por el mayor tiempo posible [7].
Nodos heterogéneos: los nodos generalmente presentan diferentes niveles de recursos (capacidad de almacenamiento, grado de movilidad, capacidad de procesamiento, energía disponible), haciendo posible clasificarlos según sus características individuales.
a. Arquitectura de red
La arquitectura de red describe las posibles configuraciones de los nodos especificando su diseño, su organización funcional así como el conjunto de protocolos necesarios para su funcionamiento. Generalmente las redes ad hoc presentan dos tipos de arquitecturas [8]:
Arquitecturas planas: en una arquitectura plana los nodos de la red realizan el enrutamiento y el envío de paquetes de forma independiente y sin ningún tipo de control externo. La falta de un enrutador por defecto hace necesario utilizar nodos intermedios para lograr las comunicaciones [9].
Arquitecturas jerárquicas: estas arquitecturas son generadas a partir de algoritmos de agrupamiento, creando grupos de nodos geográficamente adyacentes y conectados entre sí, llamados clúster, estos grupos se forman dinámicamente y pueden ser adaptados para mejorar el enrutamiento, disminuir el consumo de energía o mejorar la cooperación entre los nodos.
3. ESCALABILIDAD EN REDES AD HOC
El uso masivo de dispositivos inalámbricos hace necesario desarrollar en las redes ad hoc la capacidad de reaccionar adecuadamente al aumento en el número de nodos sin perder calidad en los servicios ofrecidos. Lograr escalabilidad es uno de los grandes retos en el diseño de protocolos y una de las propiedades necesarias para lograr redes ad hoc con una alta capacidad de despliegue. Entre los factores que afectan la escalabilidad en las redes ad hoc se encuentran:
Enrutamiento: la escalabilidad está directamente relacionada con los algoritmos de enrutamiento, pero incluso con un algoritmo de enrutamiento ideal, la limitación principal es la naturaleza multisalto de las comunicaciones. La necesidad de utilizar nodos intermedios hace que el tamaño de tablas de enrutamiento sea proporcional al número de nodos en la red [9].
Redes heterogéneas: la existencia de nodos heterogéneos, sumado a la necesidad de cooperación hace necesario garantizar que las tareas que se asignan a un nodo no estén por encima de su nivel de recursos (capacidad de memoria, procesador, disponibilidad), de lo contrario se pueden generar retrasos en las comunicaciones.
Competencia por los recursos: el aumento en la racionalidad de los nodos trae como consecuencia la aparición de comportamientos egoístas. Como una respuesta a esta nueva dinámica aparece la teoría de juegos al ser una herramienta para analizar formalmente los procesos de decisión que implican los modelos de cooperación, la competencia por recursos y el aumento en la racionalidad de los nodos [5], [6].
a. Escalabilidad en arquitecturas planas
Las arquitecturas planas presentan problemas de escalabilidad, debido a que el tamaño de las tablas de enrutamiento es proporcional al número de nodos en la red, sin embargo, funcionan adecuadamente en redes pequeñas, donde el enrutamiento y consumo de energía es bajo [9].
En los resultados obtenidos por Gupta y Kumar [12] es posible observar que una red con n nodos, la escalabilidad de la red disminuye en 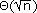 cuando el número de nodos aumenta. Estos resultados son independientes de los protocolos de enrutamiento del acceso al medio de transmisión y cualquier otro protocolo de control, al ser la principal limitación a la hora de diseñar redes de gran tamaño con arquitecturas planas.
cuando el número de nodos aumenta. Estos resultados son independientes de los protocolos de enrutamiento del acceso al medio de transmisión y cualquier otro protocolo de control, al ser la principal limitación a la hora de diseñar redes de gran tamaño con arquitecturas planas.
b. Escalabilidad en arquitecturas jerárquicas
La escalabilidad en una arquitectura jerárquica está relacionada con el nivel de recursos disponibles en una capa de la red y las tareas que los nodos deben realizar. Las capas superiores deben estar en la capacidad de soportar la carga de trabajo adicional que implica servir como intermediarios en las comunicaciones de la red [16], [17], [10].
Existen dos formas de lograr escalabilidad en una arquitectura jerárquica [18]:
Escalabilidad horizontal: la red escala horizontalmente si se agregan nuevos nodos a una capa de la red con el fin de ayudar a manejar el aumento en la carga de trabajo, esto mejora la estabilidad y el desempeño general del sistema.
Escalabilidad vertical: una red escala verticalmente cuando se añaden más recursos a un nodo en particular (procesador, memoria, energía disponible), este mejora el rendimiento de la red ayudando a centralizar la carga de trabajo sobre ese nodo.
Las arquitecturas jerárquicas surgen como respuesta a los problemas de escalabilidad presentados en arquitecturas planas, este tipo de organización aumenta la capacidad de la red al mejorar la calidad en las comunicaciones, el enrutamiento y el control de la topología, convirtiéndose en una buena alternativa para lograr escalabilidad en las redes ad hoc. [8], [19], [10].
c. Arquitecturas planas vs arquitecturas jerárquicas
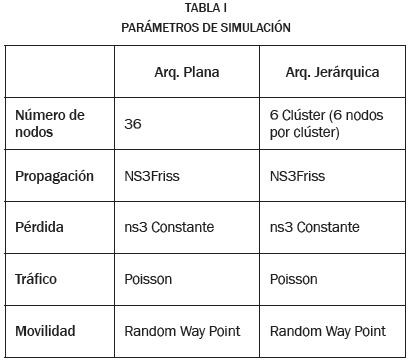
El escenario de simulación propuesto es desarrollado en el software para simulación de redes NS3 y busca comparar el rendimiento entre una arquitectura plana tradicional y una arquitectura jerárquica de dos capas compuesta por varios clúster conectados entre sí. El escenario de simulación consiste en un espacio geográfico de 1000m x 1000m, bajo un modelo de tráfico Poisson [20], el protocolo de enrutamiento OLSR (Optimized Link State Routing) y el modelo de movilidad random waypoint utilizando una velocidad uniformemente distribuida entre 0-1 m/s y donde los nodos nunca se detienen durante su recorrido. En la Tabla I es posible observar un resumen de los parámetros de configuración utilizados en la simulación.
Dos medidas de desempeño se evaluaron en ambos escenarios de simulación:
- Rendimiento del sistema (throughput): volumen de información entregada correctamente a su destino (en Mb).
- Paquetes perdidos: (lost packets): Número total de paquetes perdidos durante las comunicaciones.
Para evaluar el rendimiento de la red en ambos escenarios de simulación, se realizaron experimentos variando el tamaño de los paquetes desde 0.2 Mb hasta 2 Mb, para intentar conseguir resultados más claros sobre el comportamiento de una red bajo diferentes arquitecturas.
En los resultados de la simulación es posible verificar que una red bajo una arquitectura jerárquica presenta un mejor rendimiento en términos de los parámetros evaluados en comparación con una arquitectura plana. Al observar las Fig. 1 y 2, se evidencia una diferencia significativa en el rendimiento del sistema entre ambas arquitecturas, así como una menor pérdida de paquetes bajo una arquitectura jerárquica.
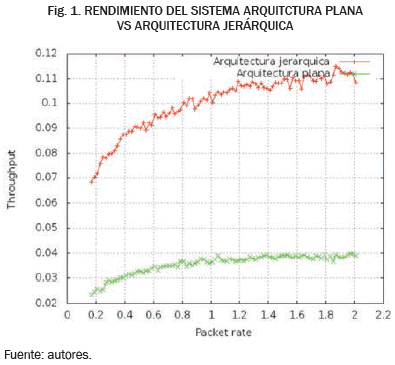
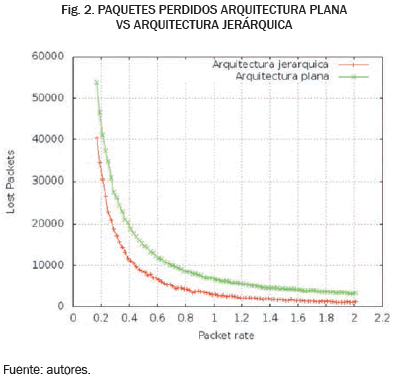
Teniendo en cuenta el mejor rendimiento presentando por las arquitecturas jerárquicas, así como el hecho de que los nodos en las capas superiores deben contar con los recursos necesarios para servir como intermendiarios en las comunicaicones de la red, se propone un modelo basado en la distribución geométrica truncada que permite caracterizar el nivel de recursos de un clúster.
4. MODELO ESTOCÁSTICO PARA LA CARACTERIZACIÓN DE UN CLÚSTER Y SUS RECURSOS
Cuando se genera una arquitectura jerárquica, el nivel de recursos en las capas superiores debe ser lo suficientemente grande para soportar la carga de trabajo adicional que implica administrar las comunicaciones de la red, y lo suficientemente pequeño para optimizar la utilización de los recursos. Encontrar la relación adecuada en el nivel de recursos de dos capas sucesivas de la red, hace necesario realizar una caracterización de los clústers que servirá para representar la distribución de recursos en los nodos. A continuación se presenta un modelo basado en la distribución geométrica truncada, que permite realizar una caracterización de un clúster a partir de sus niveles de recursos disponibles.
a. Familia geométrica
Sea X~G(p) una variable aleatoria con distribución geométrica y función de densidad de probabilidad determinada por la ecuación (1) con parámetro p (0,1) y dominio x
(0,1) y dominio x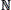 = {1,2,3,...}.
= {1,2,3,...}.
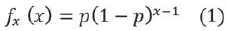
Vale la pena mencionar que esta distribución es al mundo discreto lo que la distribución exponencial es al mundo continuo, esto derivado del hecho de ser la única distribución discreta con la propiedad de pérdida de la memoria [20].
b. Familia geométrica truncada
Como se dijo anteriormente, el dominio de una variable aleatoria geométrica es el conjunto .
Sin embargo, para los propósitos de esta investigación es necesario restringir, por razones que se mencionarán más adelante, su dominio a un subconjunto A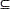 . En consecuencia, es necesario ajustar la estructura probabilística de la variable aleatoria a ese subconjunto.
. En consecuencia, es necesario ajustar la estructura probabilística de la variable aleatoria a ese subconjunto.
Si Y representa una variable aleatoria con una forma funcional geométrica, con parámetro p, pero truncada a un subconjunto A, entonces:
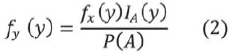
Donde IA se define como la función indicadora del conjunto A y donde P(A) puede calcularse de la siguiente forma:
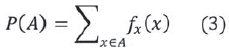
c. Caracterización de un clúster
Tradicionalmente la familia geométrica ha servido como un modelo para representar el número de ensayos de Bernoulli antes del primer éxito. Sin embargo, en este artículo se propone como modelo para describir el porcentaje de recursos con los que cuenta un nodo en relación con el total de los recursos del clúster. Por ejemplo, si el 100% de los recursos en un clúster X se supone bajo una forma funcional geométrica X~G(p), entonces, el porcentaje de recursos con los que cuenta el x-ésimo nodo estará determinado por la ecuación (1).
Debido a que una red ad hoc puede estar conformada por más de un clúster, es posible definir un conjunto de variables aleatorias que pertenecen a la familia geométrica para modelar el total de clústers en la red. Sea {Xi} con i un conjunto de variables aleatorias discretas con función de densidad determinada por la ecuación (4) con parámetro pi(0,1), y un dominio xi.
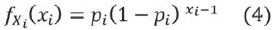
Debido a que un clúster cuenta con un número posiblemente grande, pero finito de nodos, es conveniente modelar el porcentaje de recursos de un nodo a través de un conjunto de variables aleatorias que pertenezcan a la familia geométrica truncada. Sea {Yi} con i un conjunto de variables aleatorias discretas con función de densidad determinada por la ecuación (5) con parámetro pi (0,1), y truncada a un subconjunto Ai que representa el total de nodos en el clúster. Donde Yi será la variable aleatoria asociada a un clúster i de tamaño Ni = ||Ai|| y donde representa el porcentaje de recursos del nodo yi en el clúster.
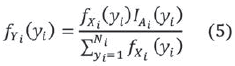
Se tendrán las siguientes consideraciones:
- Cada clúster Yi tendrá asociado un valor pi y una función de densidad
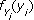 .
. - Los nodos en el clúster estarán representados por el valor yi en .
- El total de nodos en un clúster Yi es representado por un conjunto Ai donde ||Ai|| = Ni
El valor de probabilidad obtenido al evaluar para un nodo yi representa el porcentaje de recursos del nodo en comparación con el 100% de recursos en el clúster.
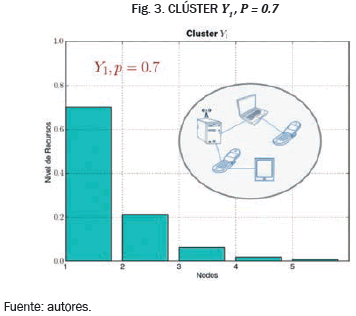
En las Fig. 3 y Fig. 4 se muestra la caracterización de los clúster Y1, Y2 a partir de la distribución geométrica truncada con N1 = 5, N2 = 3 y funciones de densidad asociadas 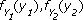 . En el clúster Y1 se observa una gran variación entre los recursos, disponibles por los nodos. Esta representación es adecuada para clústers heterogéneos donde se encuentra una diferencia significativa entre las características de cada nodo. En el clúster Y2 se observa una variación casi nula en los recursos. Esta representación es adecuada para clústers homogéneos donde los nodos tienen aproximadamente las mismas características.
. En el clúster Y1 se observa una gran variación entre los recursos, disponibles por los nodos. Esta representación es adecuada para clústers heterogéneos donde se encuentra una diferencia significativa entre las características de cada nodo. En el clúster Y2 se observa una variación casi nula en los recursos. Esta representación es adecuada para clústers homogéneos donde los nodos tienen aproximadamente las mismas características.

d. Cantidad de recursos esperada en un clúster
Debido a que los valores de yi representan los nodos en un clúster, es necesario utilizar una función h(·) que permita asociar un nodo yi con su nivel de recursos disponibles, de esta forma h(yi) servirá para representar la cantidad de recursos disponibles en el nodo yi. Teniendo en cuenta lo anterior, es posible calcular la cantidad esperada de recursos en un clúster Yi como:
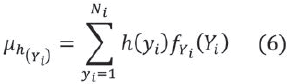
La función h(·) puede ser construida a partir de algoritmos de agrupamiento similares al WCA [11], o cualquier algoritmo que permita reunir los elementos más significativos en el funcionamiento de un nodo (ancho de banda, grado de movilidad, energía disponible, número de vecinos, capacidad de procesamiento).
Teniendo en cuenta la información anterior vale la pena mencionar lo siguiente:
- Cada clúster Yi tendrá asociado un valor constante pi que representa el grado de heterogeneidad en los nodos en el clúster. Valores de pi cercanos a 1 servirán para modelar clúster donde los nodos presentan una alta variación en su nivel de recursos, y valores de pi cercanos a 0 servirán para modelar clúster donde los nodos tienen aproximadamente los mismos recursos.
- La familia geométrica truncada permite modelar el nivel de recursos en un clúster y su grado de heterogeneidad con respecto a la red.
- El valor esperado
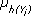 representa la cantidad esperada de recursos en el clúster Yi.
representa la cantidad esperada de recursos en el clúster Yi.
En una arquitectura jerárquica los nodos de las capas superiores deben contar con los recursos suficientes para servir como intermediarios en las comunicaciones de las capas inferiores, lo que genera el siguiente interrogante ¿Es posible establecer una función a partir de la cantidad de recursos de las capas inferiores que permita determinar el nivel de recursos necesarios en las capas superiores? A continuación se intenta dar respuesta a esa pregunta utilizando la familia geométrica truncada como una forma de caracterizar el nivel de recursos de un clúster.
e. Factor de crecimiento
Es razonable suponer que a medida que se agregan nuevas capas a la red, los recursos necesarios para mantener un nivel en la calidad de los servicios ofrecidos por el sistema deben aumentar, formalmente si µi representa el 100% de los recursos en la capa i de la red, entonces en la siguiente capa i+1 debe ocurrir que:
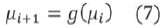
Donde g: 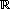 +→+ es una función creciente que permite estimar en qué medida deben aumentar los recursos en la capa i+1 para mantener un nivel mínimo en la calidad de los servicios. Varias posibilidades para g(·) pueden explorarse; sin embargo, en este artículo se supondrá un crecimiento proporcional. Ver ecuación (8).
+→+ es una función creciente que permite estimar en qué medida deben aumentar los recursos en la capa i+1 para mantener un nivel mínimo en la calidad de los servicios. Varias posibilidades para g(·) pueden explorarse; sin embargo, en este artículo se supondrá un crecimiento proporcional. Ver ecuación (8).
Existen dos escenarios límite en la relación que puede existir entre el nivel de recursos de dos capas sucesivas de la red:
Recursos ilimitados: si fuera posible tener una capa de la red con recursos ilimitados, la diferencia entre los recursos sería lo suficientemente grande para no tener problemas que afecten la calidad de los servicios. Este escenario es poco factible desde el punto de vista de diseño, ya que implica una asignación de recursos más allá de las necesidades de la red generando costos innecesarios.
Recursos iguales: si las capas de la red cuentan con aproximadamente los mismos recursos, es posible que la carga de trabajo adicional que deben realizar las capas superiores estén más allá de sus capacidades, en consecuencia es posible que exista una disminución en el desempeño de la red aumentando los retrasos y la pérdida de paquetes.
Teniendo en cuenta lo anterior, es posible observar que la relación adecuada entre los recursos disponibles por dos capas sucesivas de la red debe ser un valor intermedio a estos dos escenarios. Lograr que nodos ubicados en las capas i e i+1 de la red puedan mantener un nivel mínimo en la calidad del servicio, implica que el nivel de recursos esperado en la capa i+1 deba ser un valor que relaciona los recursos disponibles en la capa i con un factor de crecimiento que indicará en que medida los recursos en i+1 deben ser mayores en comparación con i. Para encontrar esta relación se propone (8), donde µi representa la cantidad esperada de recursos en la capa i de la red y donde k será un factor de crecimiento que representa la relación adecuada entre los recursos de las capas i e i+1.
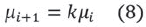
Teniendo en cuenta que puede existir más de un clúster en una capa de la red se utilizará la siguiente notación:
Sea Yi(j) el j-ésimo clúster en la capa i de la red. Cada clúster i tiene asociada una función de densidad 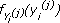 que pertenece a la familia geométrica truncada y que caracteriza la distribución de recursos disponibles en ese clúster.
que pertenece a la familia geométrica truncada y que caracteriza la distribución de recursos disponibles en ese clúster.
En la Fig. 5 se observa un ejemplo para una red con dos capas:
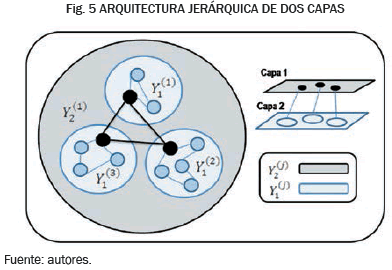
- La primera capa de la red, es decir, i = 1 está formada por los clústers Y1(j) con j{1,2,3}.
- La segunda capa de la red, es decir, i = 2 está formada por el clúster Y2(1)
Partiendo de la topología de red presentada en la Fig. 5 es razonable suponer que el nivel mínimo de recursos disponible en el clúster Y2(1) para servir como intermediario en las comunicaciones de Y1(1), Y1(2) y Y1(3) puede calcularse de la siguiente forma:
- Se debe calcular
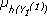 ,
, 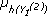 y
y 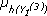 que representa el nivel esperado de recursos disponible en cada uno de los clústers de la primera capa.
que representa el nivel esperado de recursos disponible en cada uno de los clústers de la primera capa. - El total de recursos esperados en la primera capa puede calcularse como µ1 = + +
- Para estimar el nivel mínimo de recursos en la siguiente capa de la red µ2 puede utilizarse la ecuación (8). Luego, el valor µ2 = kµ1 representa en qué medida los recursos de la segunda capa de la red deben aumentar con respecto a la primera para mantener un mínimo en la calidad de los servicios ofrecidos.
5. CONCLUSIONES
Debido al uso masivo de dispositivos inalámbricos, es necesario generar en las redes de comunicaciones la capacidad de reaccionar adecuadamente al crecimiento de la red sin perder calidad en los servicios ofrecidos. Lograr escalabilidad en las redes ad hoc es uno de los grandes retos en el diseño de protocolos y una de las propiedades necesarias para lograr redes ad hoc con una alta capacidad de despliegue.
Las arquitecturas jerárquicas surgen como una respuesta vertical a los problemas de escalabilidad presentados en las arquitecturas planas. Siendo una buena alternativa para lograr escalabilidad en redes ad hoc.
En este artículo se ha explorado la familia geométrica como una forma de obtener una caracterización de los recursos de la red bajo una arquitectura jerárquica, suponiendo una relación proporcional entre el nivel de recursos de dos capas sucesivas de la red. En el trabajo futuro propuesto para esta investigación se espera encontrar un valor de k (factor de crecimiento) que permita determinar en escenarios específicos la cantidad de recursos necesarios en las capas superiores de la red para lograr escalabilidad.
La función h(·) debe ser construida teniendo en cuenta los elementos más significativos en el funcionamiento de un nodo (ancho de banda, grado de movilidad, energía disponible, capacidad de procesamiento), adicionalmente, debe contar con la flexibilidad para ajustar sus parámetros a las necesidades de la red, al ser este otro un elemento que se plantean como trabajo futuro en esta investigación.
REFERENCIAS
[1] I. Chlamtac, M. Conti, and J. J.-N. Liu, "Mobile ad hoc networking: imperatives and challenges," Ad Hoc Networks, vol. 1, no. 1, pp. 13-64, Jul. 2003. [ Links ]
[2] D. Raychaudhuri and N. B. Mandayam, "Frontiers of Wireless and Mobile Communications," Proceedings of the IEEE, vol. 100, no. 4, pp. 824-840, Apr. 2012. [ Links ]
[3] J. E. Ortiz, "Simulación y evaluación de redes ad hoc bajo diferentes modelos de movilidad," Ingeniería e Investigación, vol. 53, pp. 44-50, 2003. [ Links ]
[4] J. Spencer, The strange logic of random graphs. Springer, 2001, vol. 22. [ Links ]
[5] V. Srinivasan, P. Nuggehalli, C. F. Chiasserini, and R. R. Rao, "Cooperation in Wireless Ad Hoc Networks," vol. 00, no. C, 2003. [ Links ]
[6] M. I. D. B. D. P. Hoebeke J., "An overview of mobile ad hoc networks: Applications and challenges," Journal of the Communications Network, vol. 3, no. 3, pp. 60-66, 2004. [ Links ]
[7] L. M. Feeney and M. Nilsson, "Investigating the energy consumption of a wireless network interface in an ad hoc networking environment," in INFOCOM 2001. Twentieth Annual Joint Conference of the IEEE Computer and Communications Societies. Proceedings. IEEE, vol. 3. IEEE, 2001, pp. 1548-1557. [ Links ]
[8] S. Zhao and S. Jain, "Ad hoc and mesh network protocols and their integration with the internet," Emerging Wireless Technologies and the Future Mobile Internet, p. 54. [ Links ]
[9] M. G. D. Raychaudhuri, Emerging Wireless Technologies and the Future Mobile Internet. CAMBRIDGE University Press, 2011. [ Links ]
[10] J. Y. Yu and P. H. Chong, "A survey of clustering schemes for mobile ad hoc networks," IEEE Communications Surveys and Tutorials, vol. 7, no. 1, pp. 32-48, 2005. [ Links ]
[11] M. Chatterjee, S. K. Das, and D. Turgut, "Wca: A weighted clustering algorithm for mobile ad hoc networks," Cluster Computing, vol. 5, no. 2, pp. 193-204, 2002. [ Links ]
[12] P. Gupta and P. R. Kumar, "The capacity of wireless networks," Information Theory, IEEE Transactions on, vol. 46, no. 2, pp. 388-404, 2000. [ Links ]
[13] R. Ramanathan, R. Allan, P. Basu, J. Feinberg, G. Jakllari, V. Kawadia, S. Loos, J. Redi, C. Santivanez, and J. Freebersyser, "Scalability of mobile ad hoc networks: Theory vs practice," in Military Communications Conference, 2010-MILCOM 2010. IEEE, 2010, pp. 493-498. [ Links ]
[14] M. Grossglauser and D. Tse, "Mobility increases the capacity of ad-hoc wireless networks," in INFOCOM 2001. Twentieth Annual Joint Conference of the IEEE Computer and Communications Societies. Proceedings. IEEE, vol. 3. IEEE, 2001, pp. 1360-1369. [ Links ]
[15] M. Garetto, P. Giaccone, and E. Leonardi, "Capacity scaling in ad hoc networks with heterogeneous mobile nodes: The subcritical regime," IEEE/ACM Transactions on Networking (TON), vol. 17, no. 6, pp. 1888-1901, 2009. [ Links ]
[16] T. Ohta, S. Inoue, and Y. Kakuda, "An adaptive multihop clustering scheme for highly mobile ad hoc networks," in Autonomous Decentralized Systems, 2003. ISADS 2003. The Sixth International Symposium on, 2003, pp. 293-300. [ Links ]
[17] T. Ohta, N. Murakami, R. Oda, and Y. Kakuda, "An improved autono- mous clustering scheme for highly mobile large ad hoc networks," in Autonomous Decentralized Systems, 2005. ISADS 2005. Proceedings, 2005, pp. 655-660. [ Links ]
[18] M. Michael, J. Moreira, D. Shiloach, and R. Wisniewski, "Scale-up x scale-out: A case study using nutch/lucene," in Parallel and Distributed Processing Symposium, 2007. IPDPS 2007. IEEE International, 2007, pp. 1-8. [ Links ]
[19] Zhao, I. Seskar, and D. Raychaudhuri, "Performance and scalability of self-organizing hierarchical ad hoc wireless networks," in Wireless Communications and Networking Conference, 2004. WCNC. 2004 IEEE, vol. 1. IEEE, 2004, pp. 132-137. [ Links ]
[20] S. M. Ross, Introduction to probability models. Academic press, 2006. [ Links ]
[21] V. B. Iversen et al., "Teletraffic engineering handbook," ITU-D SG, vol. 2, p. 16, 2005. [ Links ]
