










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkIteckne
versão impressa ISSN 1692-1798
Iteckne vol.12 no.2 Bucaramanga jul./dez. 2015
Diseño de un sistema de comunicación entre personas sordas y personas oyentes
Design of a communication system between deaf people and hearing people
José Miguel Martínez-Aponte1, Sergio Stivenson-Pinto2
1 Ingeniero en Telecomunicaciones Universidad de Pamplona. Pamplona, Colombia. jmiguel_29ma@hotmail.com.
2 Ingeniero en Telecomunicaciones Universidad de Pamplona. Pamplona, Colombia. ing.sergio.elk@gmail.com.
RESUMEN
El siguiente artículo presenta el diseño de un software prototipo capaz de interpretar dos tipos de lenguaje, el lenguaje articulado y el lenguaje de señas. Se pretende mediante técnicas de procesamiento digital de señales y establecimiento de patrones encontrar la manera de decodificar los lenguajes, de tal forma que una persona sorda pueda entender lo que le comunica una oyente y viceversa.
PALABRAS CLAVE: Reconocimiento de señas, cuantificación, caracterización y modelos ocultos de Markov.
ABSTRACT
This article presents the design of a software prototype, able to allow the communication between two languages, the voice and the signs language. It is pretended to decode both languages by using digital signal processing techniques as well as the establishment of common patterns. The goal is that a deaf person be able to understand what a hearing person says and viceversa.
KEYWORDS: Signs recognizing, quantification, characterization, Hidden Markov Models.
1. INTRODUCCIÓN
El propósito de este proyecto es diseñar un sistema decodificador de lenguaje que logre el reconocimiento de voz y el de señas por medio de una computadora, usando como herramienta de desarrollo el software MatLab. Este sistema es un prototipo, el objetivo principal es el de lograr el reconocimiento de un número discreto de palabras y frases, pretendiendo la mayor robustez posible. Se utiliza el análisis cepstral en la escala mel y los modelos ocultos de Márkov para el reconocimiento de voz. En cuanto al reconocimiento de señas, la extracción de parámetros característicos se lleva a cabo gracias a la detección de color y a patrones de movimiento.
2. DESARROLLO DEL ARTÍCULO
2.1 Acerca de los lenguajes
Con el fin de ampliar la perspectiva que se tiene acerca de ambos lenguajes, se indagó sobre las características generales de cada uno de ellos.
2.1.1 Lenguaje articulado (voz)
La voz es el conjunto de sonidos que emplea el ser humano para comunicarse por medio de ondas mecánicas. Es producida por el aparato fonador, compuesto por las cuerdas vocales y el tracto vocal. Las cuerdas vocales son las encargadas de generar la frecuencia fundamental y sus armónicos, mientras el tracto vocal es el conjunto de cavidades resonantes, las cuales se acomodan de tal manera que amplifiquen o atenúen dichos armónicos, y puedan dar forma a los distintos sonidos de la voz [1].
2.1.2 Modelo source-filter de la voz
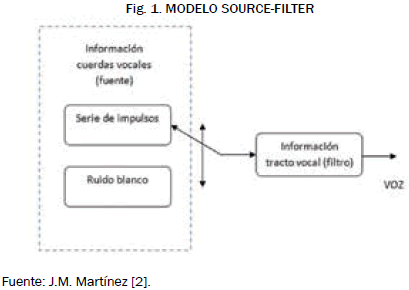
Se puede considerar la voz como una combinación aleatoria entre una señal periódica generada cuando las cuerdas vocales vibran y un ruido blanco (característico de los sonidos sordos como el de la ‘k’) cuando hay ausencia de esta vibración. Esta combinación es denominada fuente o source, es llamada así porque esta contiene la energía e información cruda de la voz y es la entrada a un filtro de características variables cuya función es terminar de darle forma a la señal de voz.
La Fig. 1 muestra un esquema del modelo source-filter, un modelo representativo del origen de la voz. De esta manera se puede incorporar al modelo la información de las cuerdas vocales más la información del tracto vocal, cuyas piezas móviles están consideradas como las características variables del filtro. La información del tracto vocal está contenida en la envolvente del espectro resultante [3].
2.1.3 Lenguaje de señas
Es un lenguaje basado en el movimiento corporal y gestual y se percibe de forma visual. El movimiento de las manos es el componente más influyente en las señas y es la base del establecimiento de patrones por reconocer.
2.1.4 Modelo de reconocimiento
En el reconocimiento automático de ambos lenguajes se establecen tres pasos importantes, la caracterización del lenguaje, el entrenamiento o aprendizaje del sistema y el proceso de reconocimiento.
2.2 Reconocimiento de voz
El reconocimiento de voz en este proyecto es aplicado a palabras aisladas, el discurso por parte del usuario debe ser pausado entre palabra y palabra. Se reconocen diez palabras, suficientes para establecer las frases de saludo mostradas en la Fig. 2.

La señal de voz es caracterizada matemáticamente por medio de los coeficientes Mel-cepstrum (MFCC por sus siglas en inglés). Estos coeficientes logran captar la información del tracto vocal, información que corresponde a las bajas frecuencias de la señal de voz en el dominio cepstral [4].
2.2.1 Análisis cepstral en la escala Mel
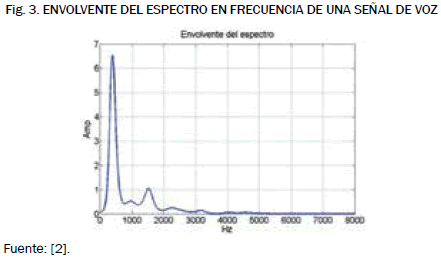
Considerando el modelo source-filter, enunciado anteriormente, la información del tracto vocal se encuentra en la envolvente del espectro en frecuencia de la señal de voz. En la Fig. 3 se puede ver la envolvente de una señal de voz en el dominio de la frecuencia.
Para poder captar las diferencias cepstrales entre un fonema y otro a medida que evoluciona una palabra en el tiempo, se analiza la señal de voz por ventanas de corta duración, estas ventanas están solapadas entre sí en un 50%. A cada una de estas ventanas se les calcula los MFCC como se muestra en la Fig. 4 [5], [6].
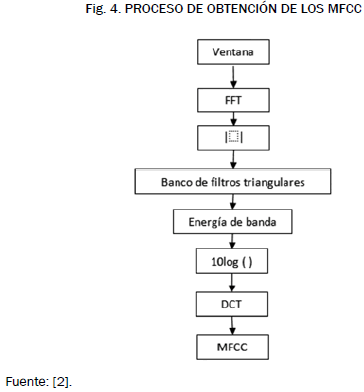
El espectro de amplitud de cada ventana, obtenido con la transformada discreta de Fourier, es multiplicado por un banco de N filtros triangulares equi-espaciados en la escala Mel. Luego a la salida de cada filtro se le calcula el logaritmo de la energía y, por último, la transformada discreta del coseno. En el proyecto se usó un banco de 20 filtros y los primeros 17 MFCCs para crear el vector característico. Con el fin de hacer más precisa la caracterización del vector, se le añaden también algunos coeficientes dinámicos, obtenidos de la primera y segunda derivada de los MFCCs (1) y (2) respectivamente [7].
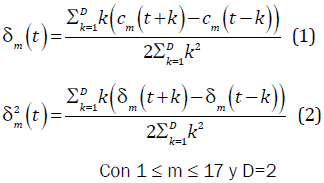
Donde cm es cada uno de los 17 MFCC, δm los coeficientes de la derivada y δ2m los de la aceleración (o segunda derivada), t es el parametro tiempo y D es la cantidad de vectores adyacentes sobre los cuales se calculan los coeficientes dinámicos. La Fig. 5 muestra la señal de voz dividida en ventanas, cada una con su vector característico, cada vector conformado por los MFCC, la derivada y la aceleración de los MFCC y tres valores de energía, uno por cada grupo de coeficientes.
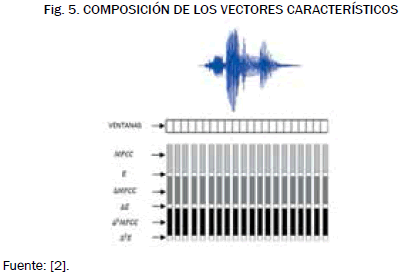
2.2.2 Proceso de cuantificación
Con este proceso se pretendió representar los vectores característicos con un índice, de tal forma que aquellos vectores cercanos entre sí pudieran ser cuantificados con un mismo valor y reducir la cantidad de información para utilizar y por ende el costo computacional. Para este propósito se tomaron suficientes muestras de voz y con los vectores característicos se empleó el algoritmo LGB para obtener un codebook, o libro de regiones representativas, con 1024 índices o codewords [3].
El proceso de cuantificación consiste entonces en asignar por medio de la distancia euclidiana, uno de los 1024 índices a cada uno de los vectores característicos de la señal de voz capturada, como resultado queda un vector de observación O = {O1,O2,O3 ...OT}. Donde On es la observación de la ventana . De esta manera datos por analizar se reducen de una matriz de MxT a un vector de observación de 1xT, siendo M la longitud del vector característico y T la cantidad de ventanas temporales de la señal de voz capturada.
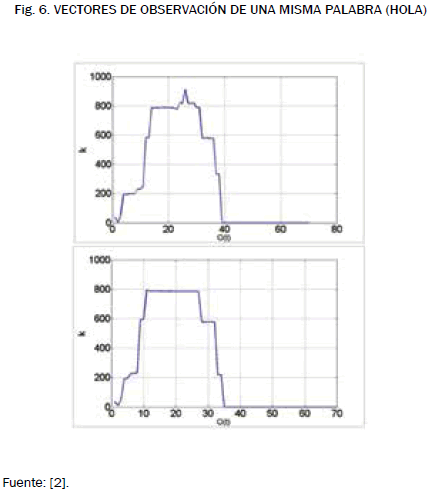
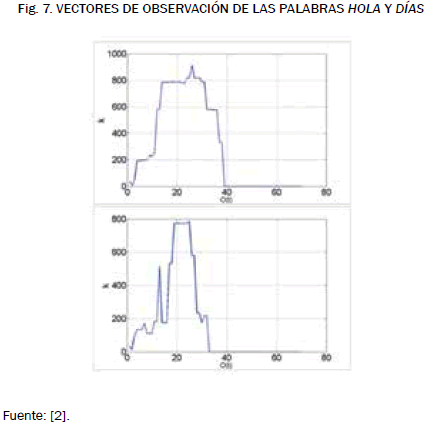
Como puede verse en las figs. 6 y 7, la cuantificación permite notar similitud y diferencias entre las distintas muestras de voz. El eje de abscisas corresponde al instante t, y las ordenadas al índice k o codeword correspondiente al vector en ese instante de tiempo. Una vez cuantificada la señal de voz se usan los modelos ocultos de Markov para determinar a qué palabra corresponde la secuencia de observación. Para esto se hizo necesario entrenar un modelo por cada palabra, de tal forma que se hiciera máxima la probabilidad condicional, P(O|λ) que es la probabilidad de que dado el modelo se dé la observación O.
2.2.3 Modelos ocultos de Márkov (HMM) t3
Son modelos probabilísticos que permiten representar un proceso doblemente estocástico, donde la probabilidad de estado asociado no es observable, de ahí la palabra oculto. Los HMM son útiles en el reconocimiento de patrones si estos cumplen con las características de un proceso aleatorio [8], [9].
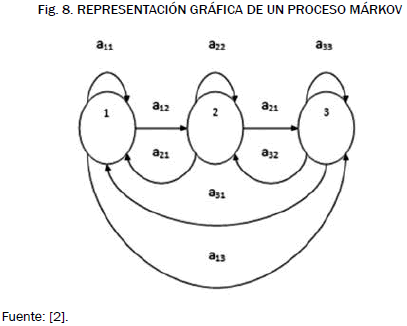
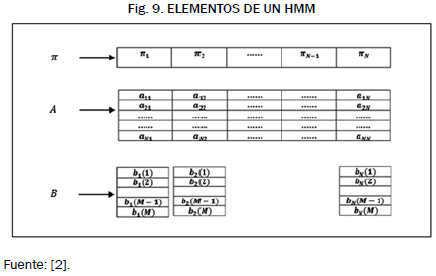
La Fig. 8 muestra un ejemplo de un modelo de tres estados, representados gráficamente por medio de círculos, las líneas que unen estos círculos corresponden a la probabilidad de transición de un estado a otro. Estas probabilidades de transición son acomodadas en la matriz de transición A de NxN posiciones, donde N es la cantidad de estados del modelo y junto con el vector de probabilidad inicial y la matriz de densidad de emisión B son los tres componentes de un HMM. La cantidad de estados de un modelo determina la robustez y complejidad al momento del entrenamiento, entre más estados tenga más complejo es [10].
La Fig. 9 muestra los elementos de un modelo oculto de Márkov de N estados y son definidos por (3), (4) y (5). Donde qt es el estado en el que el modelo se encuentra en el instante t.
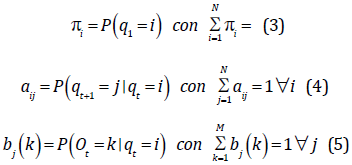
Lo que se hizo fue, a partir de cada observación de una palabra determinada, entrenar un HMM inicial de componentes λ = (A,B,π) con valores iniciales aleatorios hasta obtener un modelo más especifico para esa observación. A través de distintos algoritmos, que serán nombrados en la siguiente sección, se optimizó un modelo por cada una de las palabras por reconocer, teniendo así un diccionario de 10 HMMs.
2.2.4 Los tres problemas de un HMM y su solución
Existen tres problemas en un HMM [6]. El primero de ellos es hallar P(O/λ), la solución está en el algoritmo Forward o Backward:
- Algoritmo Forward
Inicio:
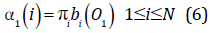
Iteracion:
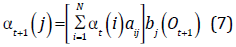
Fin:
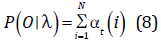
- Algoritmo Backward
Inicio:
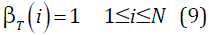
Iteración:
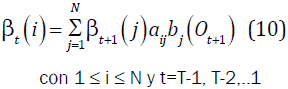
Fin:
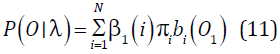
El segundo problema es encontrar la secuencia de estados óptima qt, para determinar los estados por los cuales transita un modelo al ser evaluado y en qué momento lo hacen. La secuencia de estados y la probabilidad P(O/λ) son los dos criterios usados para el correcto reconocimiento de palabras y para el entrenamiento. Con el algoritmo Viterbi se obtiene esa secuencia:
- Algoritmo Viterbi
Inicio:
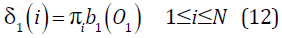
Iteración:
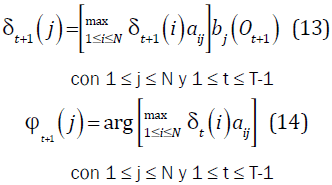
Fin:
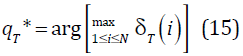
Secuencia de estados óptima:
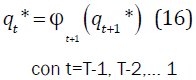
El tercer problema es el de entrenar un modelo a partir de una secuencia de observación dada. Para este propósito se utiliza el algoritmo Baumwelch y un algoritmo de re-estimación [11], [12].
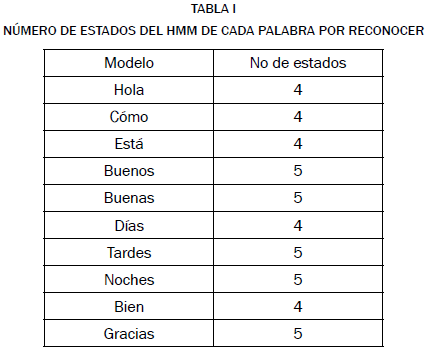
La tabla I muestra la cantidad de estados de cada uno de los modelos del sistema, entre más estados tenga un modelo mayor será el tiempo y la dificultad de su entrenamiento.
2.3 Reconocimiento de señas
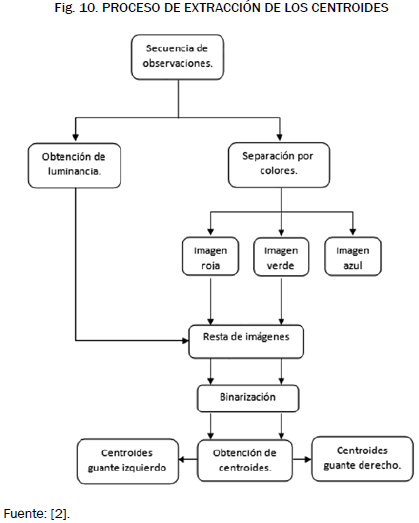
Se tomó como unidad de caracterización el centroide de las manos. Para ayudar a la ubicación de las manos en la imagen se usaron dos guantes de distinto color, uno para cada mano, y por medio de las técnicas mostradas en la Fig. 10 se llevó a cabo esta tarea [13], [14].
El sistema reconoce cuatro señas y al igual que con la voz se capturan de forma aislada. Las señas son los saludos: hola, buenos días, buenas tardes y buenas noches. Algunas señas varían dependiendo del país por lo que se establecen para este artículo las correspondientes al lenguaje de señas de Colombia [15].
2.3.1 Extracción de patrones representativos
Para la extracción de patrones, por cada muestra de una seña se toman 40 fotogramas en 3 segundos, velocidad suficiente para captar el movimiento de las manos y establecer el patrón de movimiento de los centroides de cada guante.
La Fig. 11 es una secuencia de imágenes RGB de resolución 640x480, las cuales contienen los movimientos correspondientes a la seña.

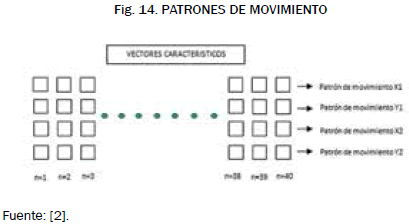
A cada una de estas 40 imágenes se les hace el filtro por color para detectar los guantes por separado y luego son binarizadas, se puede apreciar un ejemplo de esta binarización en la Fig. 12, a cada imagen binaria se le encuentran los centroides de cada guante y se almacenan en el vector de características de la Fig. 13. En la Fig. 14 se observa una matriz que contiene las 40 observaciones representadas por los vectores característicos.


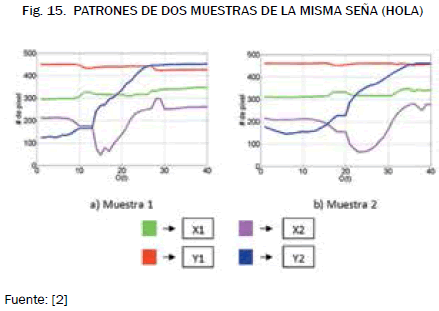
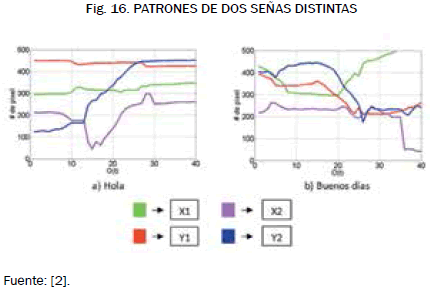
En las figs. 15 y 16 se puede ver el movimiento de los centroides en señas iguales y en señas distintas, respectivamente.
2.3.2 Reconocimiento por medio de la correlación
Se empleó la correlación, ya que es un método muy útil para medir la semejanza entre vectores de una misma longitud. La correlación mide la relación de cambio entre dos variables aleatorias y da como resultado un valor entre -1 y 1 siendo 1 el valor cuando las dos variables aleatorias varían en igual proporción. Se utilizó un umbral de acierto de 0.9 al momento de comparar y reconocer las señas.
2.3.3 Diccionario de señas
Al igual que con la voz es necesario que el sistema aprenda a reconocer señas o tenga una base de datos con la cual comparar y determinar la seña más parecida a la obtenida en una observación. Para esto se creó un diccionario con 10 muestras por cada una de las cuatro señas del sistema, así cuando se capture una nueva seña y se compare, se tendrá mayor probabilidad de acierto si se pregunta cuál fue la seña que más se repitió entre las del diccionario que dieron buena correlación.
3. RESULTADOS
El reconocimiento de voz fue realizado sobre una sola voz, la del autor, ya que es un prototipo el objetivo principal el de indagar y probar las técnicas mencionadas.
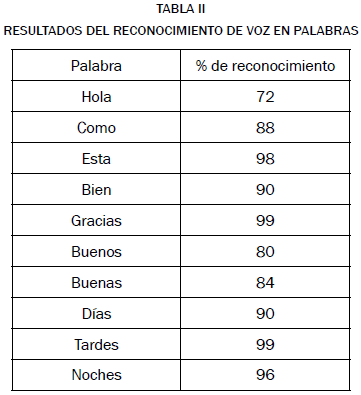
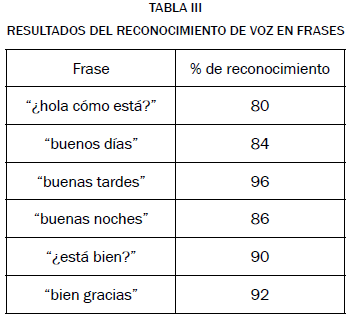
En las tablas II y III se ven los resultados luego de realizar las pruebas al sistema en un ambiente silencioso; se llevaron a cabo 100 pruebas por cada palabra y 50 por cada frase.
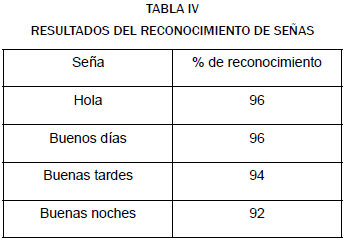
Para el reconocimiento de señas se hicieron 50 pruebas por cada seña en un ambiente de luminosidad normal, y los resultados en cuanto al acierto se pueden ver en la tabla IV.
Los tiempos de respuesta en el reconocimiento de voz fueron bastante buenos, al haber pocos modelos en el diccionario el reconocimiento fue casi inmediato (tiempo inferior al segundo). En cuanto al reconocimiento de imagen el procesamiento fue un poco más pesado, en consecuencia tuvo tiempos de respuesta más lentos, de 2 a 4 segundos aproximadamente en cada reconocimiento realizado.
4. CONCLUSIONES
Trabajar con modelos probabilísticos en el área de reconocimiento de voz permite al sistema una mayor flexibilidad, ante las posibles diferencias o errores existentes entre secuencias de observación de una misma palabra.
El uso de centroides como elementos característicos de las señas, y el establecimiento de patrones basados en la secuencia de movimiento dio muy buenos resultados en el reconocimiento de señas.
Las pruebas realizadas mostraron que los métodos utilizados para el reconocimiento de ambos lenguajes dieron un porcentaje de acierto alto y un tiempo de respuesta relativamente bueno.
AGRADECIMIENTOS
Dedicado a mis padres José A. Martinez y María R. Aponte, quienes han sido los pilares de mi formación y mi vida, a mis hermanos, a todos ellos les debo su apoyo, también agradecer a la Universidad de Pamplona por la formación y al director de mi proyecto de grado sobre el cual fue basado este artículo, ingeniero Sergio S. Pinto.
REFERENCIAS
[1] American Academy of Otolaryngology-head and neck surgery, "How the Voice Works", [online]. Disponible en http://www.entnet.org/content/how-voice-works. [ Links ]
[2] J. M. Martinez, "Diseño de un sistema de comunicación entre personas sordas y personas oyentes", tesis pregrado, Depto. de Ingenierías y Arquitectura, Universidad de Pamplona, Villa del Rosario, 2013. [ Links ]
[3] F. Martinez, G. Portale, H. Klein y O. Olmos, "Reconocimiento de voz, apuntes de cátedra para Introducción a la Inteligencia Artificial," [online] tutorial, Universidad Tecnológica Nacional, Argentina. Disponible: http://www.secyt.frba.utn.edu.ar/gia/IA1_IntroReconocimientoVoz.pdf. [ Links ]
[4] B. Logan, "Mel Frequency Cepstral Coefficients for Music Modeling," [online] artículo, Cambridge research laboratory and Compaq Computer Corporation, Disponible en: ftp://gatekeeper.dec.com/pub/Compaq/CRL/publications/logan/musicir_paper.pdf. [ Links ]
[5] K. Prahallad, "Speech Technology: A Practical Introduction," [online] laboratorio, Carnegie Mellon University & International Institute of Information Technology Hyderabad, Disponible en: http://www.speech.cs.cmu.edu/15-492/slides/03_mfcc.pdf. [ Links ]
[6] "Mel Frequency Cepstral Coefficient (MFCC)," [online] tutorial en internet, Disponible en: http://practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs/. [ Links ]
[7] L. Weisi, D. Tao, J. Kacprzyk, Z. Li, E Izquierdo and H. Wang, "A comprehensive study of sports video analysis," [online] in Multimedia analysis processing and communications, Springer 2011 edition, May 12, 2011. Disponible en https://books.google.es/. [ Links ]
[8] I. Villamil, "Aplicaciones en reconocimiento de voz utilizando HTK," [online] tesis de grado, Facultad de Ingeniería, Pontificia Universidad Javeriana, 2005, Disponible en: http://repository.javeriana.edu.co/bitstream/10554/7588/1/tesis95.pdf. [ Links ]
[9] P. Blunsom, "Hidden Markov Models," [online] tutorial, Utah State University, august 19, 2004. Disponible en http://digital.cs.usu.edu/~cyan/CS7960/hmmtutorial.pdf. [ Links ]
[10] F. Salcedo C. "Sistemas de reconocimiento basados en modelos ocultos de Márkov," [online] en Modelos ocultos de Márkov: del reconocimiento de voz a la música, Ed. Lulu Press, (2009). Disponible en https://books.google.es/. [ Links ]
[11] L. Bergasa, "Introducción a los modelos ocultos de Márkov", [online] tutorial, Depto. de Electrónica, Universidad de Alcalá, Argentina. Disponible en: http://www.bioingenieria.edu.ar/academica/catedras/metestad/Introduccion%20al%20Modelo%20oculto%20de%20Markov.pdf. [ Links ]
[12] L. Bahi, P. Brown, P. de Souza, and R. Mercer, "Maximum mutual information estimation of hidden Markov model parameters for speech recognition," Acoustics, Speech, and Signal Processing, IEEE International Conference on ICASSP 86, vol. 11. [ Links ]
[13] R. Buksh, S. Routh, P. Mitra, S. Banik, A. Mallik and S. Gupta, "MATLAB based image editing and color detection," International Journal of Scientific and Research Publications, vol. 4, Issue 1, January 2014 ISSN 2250. [ Links ]
[14] OTSU, Nobuyuki. "A Threshold selection method from Gray-level histograms," IEEE Transactions on systems, man, and cybernetics 9, nº 1 (1979), 62-66. [ Links ]
[15] Colombia Aprende, "Vocabulario por categorías," [online]. Disponible en: http://mail.colombiaaprende.edu.co:8080/recursos/lengua_senas/. [ Links ]
