











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. INTRODUCCIÓN
Las señales de voz han sido estudiadas con diversos propósitos de clasificación, detección o reconocimiento. Se han planteado e implementado sistemas de clasificación de género 1)-(6. En 4) y (5 se mencionan posibles aplicaciones y motivaciones de este objetivo.
Otros propósitos del uso de señales de voz es la formulación e implementación de sistemas para la distinción del habla 7)-(9, reconocimiento del habla 10, reconocimiento de lenguaje 11, reconocimiento de emociones basados en habla y en género 12), (13, diagnóstico de enfermedades patológicas como la disfonía y la laringitis 14, diagnóstico de nódulos, edemas y parálisis unilateral de las cuerdas vocales 15, reconocimiento de disartria en sistemas de reconocimiento automático de habla 16 y la detección temprana de Parkinson mediante voz 17.
Además de señales de voz, se han propuesto alternativas de clasificación que utilizan otras características de los individuos para clasificar el género. Algunos autores han propuesto la clasificación mediante el procesamiento de características fisionómicas humanas como la forma de la cara 18, las manos 19, las orejas 20 y los iris 21. Otros autores han utilizado estas características para la estimación de la edad y su clasificación por rangos 22)-(25.
La aparición y evolución de enfoques de clasificación que utilizan modelos de lógica difusa, redes neuronales artificiales, redes adaptativas de inferencia neurodifusa o aprendizaje automático en sistemas de control ha generado numerosos estudios e implementaciones en sistemas de detección, reconocimiento o clasificación. Se han propuesto modelos de redes neuronales 10), (13), (17, algoritmos genéticos 2, sistemas de inferencia neurodifusa (ANFIS) 3, y máquinas de soporte vectorial (SVM) 6 con el fin de clasificar con un margen de error bajo el género de una señal de voz humana. En este artículo, la clasificación se realiza mediante la aplicación de algoritmos de optimización a modelos difusos.
En este trabajo se presenta un esquema implementado en Matlab®, en el que se prueban 16 diferentes modelos de inferencia difusa (modelos difusos) de clasificación de género, los cuales se diferencian principalmente en la cantidad de entradas y los tipos de entrada especificados.
El objetivo principal del esquema propuesto es encontrar modelos de clasificación de género, basados en señales de voz humanas con un bajo margen de error; se hace la comparación de resultados entre modelos difusos, algoritmos de optimización bioinspirados y conjuntos de datos de entrada probados.
Para las entradas de los modelos difusos se definen cinco características por cada señal de voz. Cada modelo difuso propuesto utiliza tres, cuatro o cinco de estas características como entradas. Esto se realiza principalmente para determinar las entradas con mayor capacidad de clasificar géneros con un menor margen de error.
Los modelos son optimizados mediante cuatro algoritmos bioinspirados, y posteriormente optimizados, utilizando el método cuasi-Newton. Se implementan tres configuraciones diferentes para cada algoritmo bioinspirado por cada modelo en cada uno de los cuatro conjuntos de datos obtenidos del preprocesamiento de señales de voz.
El análisis de los resultados de desempeño de este trabajo permite encontrar el modelo difuso con la mayor capacidad para clasificar el género de una señal de voz humana. Adicionalmente, la interpretabilidad de este modelo hace posible la descripción de la voz perteneciente a un género determinado en función de las diferentes características de voz con las que se relaciona.
Por otra parte, la variedad de resultados obtenidos es analizada con el fin de establecer los modelos, conjuntos de datos, algoritmos bioinspirados y configuraciones de parámetros de mayor rendimiento.
La estructura de este documento es la siguiente. En la Sección 2 se definen las bases de lógica difusa. En la Sección 3, los algoritmos de optimización. En la Sección 4, las características de las señales de voz utilizadas. En la Sección 5 se presenta el esquema propuesto de clasificación. En la Sección 6 se hace el análisis cuantitativo y cualitativo de los resultados obtenidos. En la Sección 7 se listan las conclusiones obtenidas con base en la implementación y los resultados.
2. LÓGICA DIFUSA
La lógica difusa nace de la teoría de conjuntos difusos, base para el desarrollo del enfoque lingüístico 26, y sus valores de verdad pueden ser intermedios entre los valores verdadero y falso. De este modo, la lógica difusa, a diferencia de la lógica proposicional, no es dicotómica, cuantifica valores de verdad y tiene la capacidad de lidiar con la inferencia causal aproximada 27.
La lógica difusa es la base del funcionamiento de los sistemas de inferencia difusa basados en reglas 28. Estos están compuestos esencialmente de entradas, salidas, funciones de pertenencia y reglas de inferencia. A través de estos componentes y su configuración se obtienen los valores estimados de salida como valores aproximados de verdad para la clasificación, de acuerdo con los valores de entrada. El proceso de diseño de un modelo difuso involucra la definición del conjunto de entradas y salidas del sistema difuso, así como la posición, forma y dominio de sus funciones de pertenencia y las reglas de inferencia. La clasificación con bajo margen de error depende del diseño del sistema, lo que puede depender del criterio, pruebas y validación de expertos en el área particular de investigación 29.
A diferencia del enfoque de redes neuronales, los sistemas difusos pueden ser interpretables 28, lo que los hace útiles en problemas de control con alta interpretabilidad. Esto permite la descripción de las salidas en términos de las entradas, reglas de inferencia y funciones de pertenencia. La certeza en la descripción de las salidas dependerá del valor de desempeño del sistema de clasificación difuso. Sin embargo, la interpretación de un sistema difuso puede dificultarse si su estructura es de alta complejidad 30. La complejidad estructural de un sistema difuso depende proporcionalmente de la cantidad de reglas de inferencia y funciones de pertenencia en entradas y salidas. Los modelos difusos propuestos en este artículo tienen una estructura de complejidad moderada para evitar la obstrucción de su interpretabilidad.
En las últimas décadas, la aplicación de conjuntos difusos se ha visto ignorada en el campo del procesamiento del lenguaje natural y del habla, y se ha cuestionado la utilidad y contribución de la lógica difusa en las aplicaciones relacionadas con el procesamiento de señales de voz 31. No obstante, la evolución de la computación y contribuciones tecnológicas en los últimos años han favorecido al enfoque de lógica difusa para su utilización en diversos campos de estudio 32.
3. ALGORITMOS DE OPTIMIZACIÓN
En esta Sección se definen cuatro algoritmos bioinspirados y el método cuasi-Newton.
Los algoritmos bioinspirados tienen el objetivo de optimizar problemas que presentan múltiples soluciones locales, con el fin de converger a una solución óptima global. Simulan la forma en que la naturaleza se enfrenta a problemas de optimización mediante la evolución natural de especies 33. Por esta razón, estos algoritmos tienen naturaleza aleatoria y dependiente de múltiples parámetros. También existe la posibilidad de converger prematuramente a soluciones sobresalientes.
Atributos comunes en los algoritmos bioinspirados son una cantidad de iteraciones, una población o número de individuos, variables aleatorias y un criterio de finalización que se define principalmente con un número máximo de iteraciones o generaciones, con opciones adicionales, como detenerse al lograr un valor mínimo de desempeño, o una desviación estándar pequeña en los valores de desempeño de la población en una iteración.
Los algoritmos genéticos (GA), de búsqueda armónica (HS), de evolución diferencial (DE) y de optimización con enjambre de partículas (PSO) son los algoritmos bioinspirados que han sido utilizados para la optimización de los modelos difusos propuestos.
3.1 Algoritmos genéticos (Genetic Algorithms - GA)
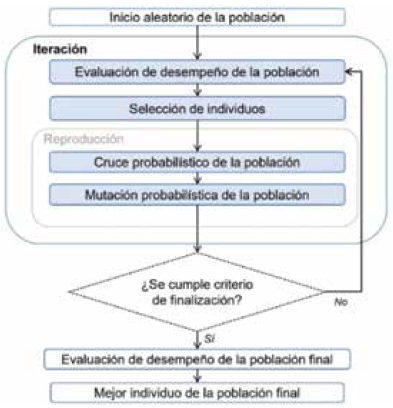
Un algoritmo genético es una forma de evolución que ocurre en un computador. Los algoritmos genéticos son un método de búsqueda útil para resolver problemas de optimización y modelar sistemas evolutivos 34.
La forma más simple de algoritmo genético involucra tres tipos de operadores: selección, cruce y mutación 35), (36. Estos operadores aplican iterativamente una cantidad de generaciones.
En primer lugar, los desempeños de cada individuo en la población son evaluados. Luego, el proceso de selección genera valores de expectativa por individuo para influenciar su probabilidad de reproducción.
La reproducción es simulada mediante los algoritmos de cruce y mutación que utilizan los individuos seleccionados como padres para generar individuos nuevos para la próxima generación.
El cruce, también llamado recombinación, consiste en combinar el genotipo de dos padres en un solo individuo. La mutación, en cambio, es la alteración genética aleatoria en el genotipo de un único padre en la población.
Los operadores de cruce y mutación pueden verse como maneras de mover a la población en el paisaje definido por la función de aptitud 35. Con estos operadores se busca la convergencia a un valor óptimo global y se logra una exploración mayor en el espacio de posibles soluciones.
Esta secuencia se repite por una cantidad de generaciones o hasta cumplir con el criterio de finalización. Tanto la mutación como la recombinación de individuos son procesos estocásticos, pues tienen un valor asociado de probabilidad.
El diagrama de flujo que describe el funcionamiento de los algoritmos genéticos se muestra en la Fig. 1.
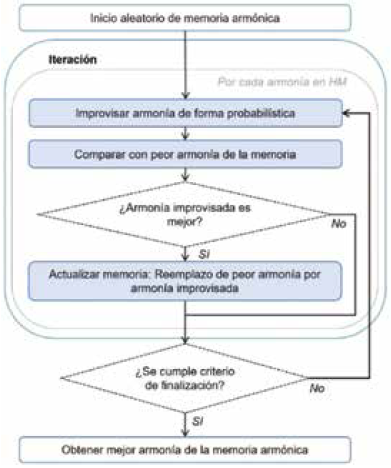
3.2 Algoritmo de búsqueda armónica (Harmony Search - HS)
La armonía musical es una combinación de sonidos considerada agradable desde un punto de vista estético. La armonía en la naturaleza es una relación especial entre varias ondas de sonido que tienen diferentes frecuencias 37.
El algoritmo de búsqueda armónica imita la improvisación musical en la que los músicos intentan encontrar mejores armonías basadas en la aleatoriedad o sus experiencias 38.
Se compone de una memoria armónica (HM) en la que se encuentran conjuntos de valores que representan las notas en una armonía. Esta memoria tiene un tamaño específico (HMS).
En el contexto de optimización, una nota es un valor de atributo de un individuo, y una armonía o conjunto de notas en la memoria armónica, es el individuo con todos sus atributos.
En cada iteración, las armonías existentes en la memoria armónica son improvisadas de acuerdo con una tasa de consideración de la memoria armónica (HMCR).
El proceso de improvisación de armonías puede utilizar una armonía de la memoria armónica (familiar) y alterar sus notas con un valor de probabilidad y una tasa de ajuste de tono (PAR), o generar una armonía completamente aleatoria dependiendo de un valor aleatorio que es comparado con el valor de HMCR como se define en la ecuación (1), dondeA i es una armonía yp i un valor de probabilidad.
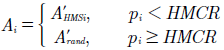 (1)
(1)
SiendoA i una armonía,p i un valor aleatorio entre 0 y 1,A’ HMSi una armonía en la memoria armónica con posibles modificaciones, yA rand un acorde aleatorio.
Si alguna de las armonías producidas en una iteración tiene mejor desempeño que al menos una armonía en la memoria armónica, esta ocupará el espacio de la peor armonía en la memoria.
La tasa de ajuste de tono (PAR) es un valor opcional del algoritmo que imita el ajuste de tono de cada instrumento para afinar el conjunto 37. El mecanismo de ajuste de tono se diseña como el desplazamiento de una nota a valores vecinos dentro de un rango de valores posibles. Esta tasa puede ser un valor constante, o un valor decreciente que inicia en un valor máximo y llega a un valor mínimo en la última iteración, con el fin de explorar en mayor profundidad la región del espacio de posibles soluciones donde se estima la ubicación del valor óptimo global.
El diagrama de flujo que describe el funcionamiento del algoritmo de búsqueda armónica se muestra en la Fig. 2.
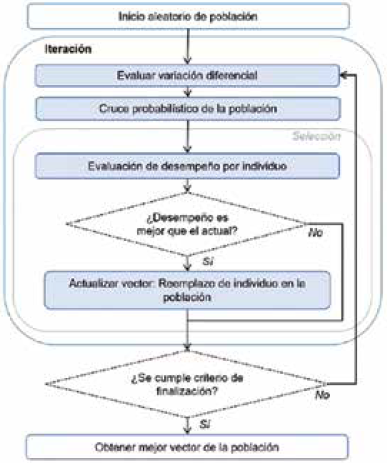
3.3 Algoritmo de evolución diferencial (Differential Evolution - DE)
La idea crucial detrás de este algoritmo es un esquema para generar vectores de parámetros de prueba 39. El algoritmo de evolución diferencial genera nuevos vectores de parámetros (individuos) al agregar un vector de diferencia ponderada entre dos miembros de la población a un tercer miembro. Si el vector resultante produce un valor de función objetivo más bajo que un miembro de población predeterminado, el vector recién generado reemplazará el vector con el que se comparó en la siguiente generación.
Para variar los parámetros en la población se define un operador de variación diferencial, que se realiza mediante el cambio en el valor de los parámetros de los vectores en una iteración, mediante la ecuación (2).
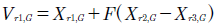 (2)
(2)
Siendo el pesoFun valor constante, yX r1, G , X r2, G , X r3, G vectores de la matriz de población en la generaciónG.
Luego se aplica un operador de cruce probabilístico, que funciona con una tasa de cruce y valores aleatorios por cada elemento de cada vector en la población. Esta es la primera estrategia definida para este algoritmo por Storn y Price 39.
Los elementos con un valor menor a la tasa de cruce (CR) toman el valor respectivo del vectorV.Los elementos restantes, con un valor aleatorio mayor o igual a la tasa de cruce, permanecen sin cambios. El valor de cada parámetrojen cada vectorise muestra en la ecuación (3).
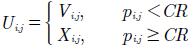 (3)
(3)
Siendop i,j un valor aleatorio entre 0 y 1.
Una vez finalizado el proceso de cruce, se realiza el proceso de selección vector por vector de la matriz de poblaciónU. En este proceso, cada vector es comparado con los demás en la población. Un vector será miembro de la población de la siguiente generación si y solo si su desempeño es mejor que el desempeño de otro vector en la población de la generación actual; de lo contrario, la población no se verá alterada.
El diagrama de flujo que describe el funcionamiento del algoritmo de evolución diferencial se muestra en la Fig. 3.
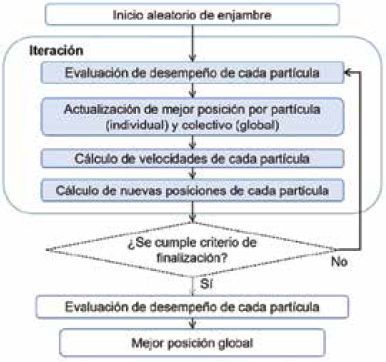
3.4 Algoritmo de optimización con enjambre de partículas (Particle Swarm Optimization - PSO)
El algoritmo de optimización con enjambre de partículas se inspira en el comportamiento social emergente que puede observarse en bandadas de aves y cardúmenes de peces de algunas especies 40.
La población está compuesta de partículas, siendo la posición de cada una de ellas un punto solución en el espacio de soluciones posibles de un número de dimensiones igual al número de parámetros del problema.
En cada iteración se actualiza la mejor posición de cada partícula (mejor posición individual), y la mejor posición del enjambre (mejor posición global). Con estos valores se calcula la velocidad de cada partícula mediante la ecuación (4).
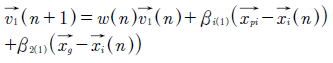 (4)
(4)
Donde:
ies el índice del individuo.
nes el índice de iteración.
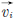 es la velocidad del i-ésimo individuo.
es la velocidad del i-ésimo individuo.
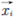 es la posición del i-ésimo individuo.
es la posición del i-ésimo individuo.
w(n) es la función de inercia.
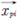 es la mejor posición del i-ésimo individuo.
es la mejor posición del i-ésimo individuo.
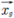 es la mejor posición del enjambre.
es la mejor posición del enjambre.
( son (valores aleatorios entre 0 y 1.
Una vez calculadas las velocidades se determina la posición de cada partícula para la siguiente iteración mediante la ecuación (5).
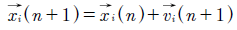 (5)
(5)
La inercia puede utilizarse como un valor constante o definirse con otros enfoques específicos 41. Uno de estos enfoques define a la inercia como un valor linealmente dependiente de las iteraciones como se define en la ecuación (6) 42.
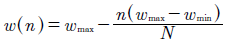 (6)
(6)
Dondew max yw min son los valores máximos y mínimos de inercia y N es el número total de iteraciones.
El diagrama de flujo que describe el funcionamiento del algoritmo de optimización con enjambre de partículas se muestra en la Fig. 4.
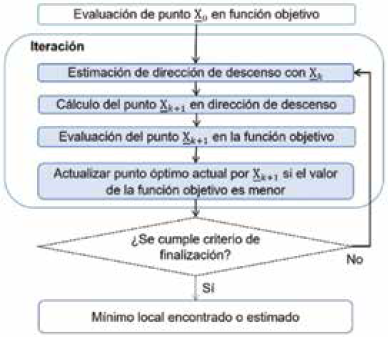
3.5 Método cuasi-Newton (Quasi-Newton method)
El método cuasi-Newton es un método de optimización basado en gradiente 43, útil en la optimización de problemas en los que se busca converger a una solución óptima local de una función objetivo a minimizar, partiendo de un punto inicial en el espacio de soluciones posibles.
Este se basa en el método de Newton, el cual establece que para un punto y una función objetivo , existe un punto dado por la ecuación (7) que se aproxima a un mínimo local en el espacio de soluciones.
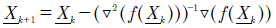 (7)
(7)
Donde
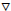 es el gradiente de la función objetivo,
2 es el Hessiano de la función objetivo, y
es el gradiente de la función objetivo,
2 es el Hessiano de la función objetivo, y
 es un punto mínimo estimado de la función.
es un punto mínimo estimado de la función.
El cálculo del Hessiano de una función objetivo puede tener un alto costo computacional, especialmente cuando las funciones no son lineales y se definen con múltiples variables 43.
El método cuasi-Newton calcula un valor aproximado del Hessiano. Se han desarrollado métodos de actualización del Hessiano como la fórmula de Davidon, Fletcher y Powell (DFP), y la fórmula de Broyden, Fletcher, Goldfarb y Shanno (BFGS). Esta última se considera la más efectiva para el uso en un método de propósito general 44), (45.
El esquema general del algoritmo se muestra en la Fig. 5.
4. CARACTERÍSTICAS DE LAS SEÑALES DE AUDIO
Esta Sección describe las cinco entradas utilizadas para los modelos difusos propuestos, abreviadas mediante las siglas EE, STE, ZCR, RMS y PSC.
Algunos artículos, con el propósito de clasificar el género utilizan las entradas EE, STE y ZCR como características fundamentales de las voces 1), (6. En 46 se ha planteado que las entradas STE y ZCR pueden clasificar sonidos que se asocian a entornos específicos.
En 1 se ha planteado que las características STE y ZCR tienen un valor bajo en voces masculinas, y un valor alto y continuo en voces femeninas.
Otros artículos han trabajado con los coeficientes MFCC (Mel Frequency Cepstral Coefficients) para la clasificación de género 47, reconocimiento de oradores 10, y detección de patologías por medio de señales de voz 7), (15), (48.
4.1 EE (Energy Entropy)
La entropía en la señal de voz se mide con los cambios repentinos en el nivel de energía de una señal de voz 1. Para calcularla, la señal de voz se divide inicialmente en k ventanas y luego se calcula la energía normalizada de la señal por cada ventana.
El valor de entropía es la suma de todos los valores calculados. La entropía de la señal está dada por la ecuación (8), donde es la energía de la señal normalizada.
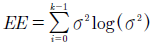 (8)
(8)
Esta característica se ha utilizado para otros propósitos relacionados, como la detección del habla 9.
4.2 STE (Short Time Energy)
La característica STE de una señal de voz busca ver la tendencia que esta tiene de aumentar repentinamente en lapsos cortos de tiempo. El valor STE de una ventana de la señal se calcula mediante la ecuación (9).
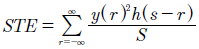 (9)
(9)
Dondeyes una señal,ses el tamaño de una ventana de la señal, yh(r)es la función de ventana definida en la ecuación (10).
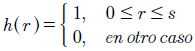 (10)
(10)
Normalmente, la energía es alta si hay una voz en la señal 2. Se ha planteado esta característica para la detección de frecuencia en el habla 49.
Esta entrada puede ser de utilidad para detectar los momentos en los que una señal tiene amplitud insuficiente facilitando la remoción de silencio de las señales de voz 50), (51. Es posible detectar el silencio de una señal al establecer un umbral mínimo de STE de modo que los valores menores a este umbral pueden catalogarse como silencios en una señal.
4.3 ZCR (Zero Crossing Rate)
Para una señal descrita por un vectorX, la tasa de cruces por cero (ZCR) se calcula por pares consecutivos deXcomo lo describe la ecuación (11).
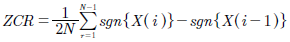 (11)
(11)
Siendosgnla función signo, definida en la ecuación (12).
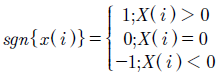 (12)
(12)
4.4 RMS (Root Mean Square)
Para una señal descrita por un vector, el valor cuadrático medio de una señal está definido por la ecuación (13).
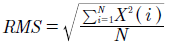 (13)
(13)
Se define como la raíz cuadrada del cuadrado medio, es decir, de la media aritmética de los cuadrados de un conjunto numérico. La diferencia entre esta entrada y STE es que esta característica no es calculada por ventanas, sino que resume el comportamiento de la señal total en un único valor. Además, como se trata de la raíz cuadrada tiene una sensibilidad menor que STE.
4.5 PSC (Perceptual Spectral Centroid)
El centroid espectral es una medida utilizada en el procesamiento digital de señales para caracterizar el espectro de frecuencia de una señal. Investigadores creen que la calidad del brillo del timbre se correlaciona con el aumento de la potencia en altas frecuencias 52. Esta medida de frecuencia indica la posición en la que se encuentra el baricentro del espectro.
Perceptualmente, tiene una conexión robusta con la impresión de brillo del sonido 53. Se calcula como la media ponderada de frecuencias, determinada mediante la transformada de Fourier, con sus magnitudes en el histograma de la señal. Se calcula mediante la ecuación (14).
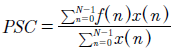 (14)
(14)
Siendox(n) el valor de frecuencia ponderada de una ubicaciónnen el histograma de la señal, yf(n) la frecuencia central de esa ubicación 54.
Se ha utilizado esta medida para estudiar el brillo en el sonido de instrumentos musicales y clasificar las emociones que son capaces de evocar los sonidos 55.
5. ESQUEMA DE CLASIFICACIÓN PROPUESTO
El esquema propuesto abarca 4 algoritmos bioinspirados, 4 conjuntos de datos, 3 configuraciones diferentes por algoritmo bioinspirado y 16 modelos difusos, dando lugar a 4x4x3x16=768 combinaciones posibles de clasificación probadas, es decir, 768 resultados de indicadores de desempeño.
Cada modelo difuso es optimizado por un algoritmo bioinspirado, y una vez el algoritmo bioinspirado termina, el modelo es optimizado localmente con el método cuasi-Newton.
5.1 Proceso de optimización
La evaluación de un individuo en el proceso de optimización con un algoritmo se hace mediante la construcción de un modelo difuso con los parámetros del individuo y la estructura definida en la función objetivo. Esta función es calculada con las respuestas de clasificación del modelo construido. La Fig. 6 muestra el esquema general que el algoritmo de optimización utiliza para la evaluación de los individuos, siendo el modelo de clasificación un modelo difuso de los 16 propuestos.
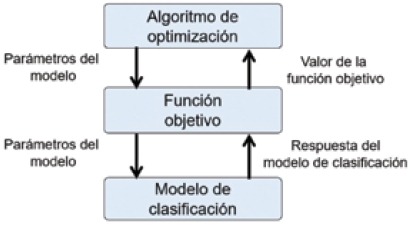
Fuente: Los autores.
Fig. 6. ESQUEMA DE EVALUACIÓN DE MODELOS DIFUSOS CON UN ALGORITMO DE OPTIMIZACIÓN
Un modelo difuso de clasificación es la representación funcional de un individuo en la población o un punto en el espacio de soluciones.
La función objetivo establecida es el error cuadrático medio (MSE). Con esta se evalúa el desempeño de todo modelo de clasificación difuso.
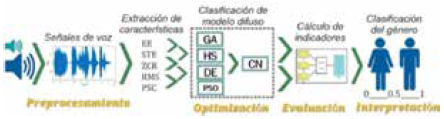
La Fig. 7 muestra los pasos que se realizan en un proceso de optimización con cualquier combinación posible probada de conjunto de datos, modelo y algoritmo bioinspirado.
Cada señal de voz se convierte en una serie de valores que se fija con un mecanismo de preprocesamiento de los cuatro definidos en la Subsección 5.3, y de cada serie se extraen las características definidas en la Sección 4; luego se realiza el proceso de optimización de un modelo difuso propuesto, el cual involucra evaluaciones iterativas del mismo. Si el modelo optimizado tiene resultados de desempeño altos, se hace un análisis de su interpretación.
5.2 Estructura de los modelos difusos propuestos
La estructura general de los modelos difusos propuestos se muestra en la Fig. 8.
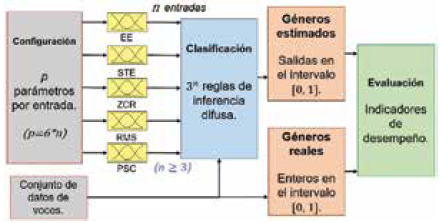
Los rangos de asignación factible de las funciones de pertenencia tienen en cuenta el valor mínimo y máximo por cada una de las entradas para el modelo difuso definidas en la Sección 4. Por ejemplo, para un modelo que utilice las primeras tres entradas, los rangos son los definidos en la ecuación (15).
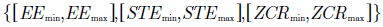 (15)
(15)
Con la normalización de cada uno de estos rangos entre los valores 0 (mínimo) y 1 (máximo), se establece un rango general para todas las entradas y se promueve la exploración factible en los algoritmos de optimización en un espacio fijo de soluciones de acuerdo con los datos procesados.
En este documento se trabaja con modelos difusos tipo Sugeno. Este tipo de modelo tiene ventaja sobre los modelos tipo Mamdani, dado que requiere menos memoria y posee mayor velocidad 56. Con este modelo se reduce la complejidad de evaluación por señal de voz, sin perjudicar el propósito de clasificación de género ni la utilidad de la información suministrada por las entradas.
Cada modelo de inferencia difusa produce una única salida compuesta de tres funciones de pertenencia de tipo constante entre 0 y 1. Esta indica el género estimado para una señal de voz, donde 0 representa al género femenino, 0.5 representa un género indefinido, y 1 representa al género masculino.
La forma gaussiana de las funciones de pertenencia es considerada más flexible que la forma triangular, y se aproxima más a los mecanismos de inferencia humanos 57), (58. A diferencia de las funciones de pertenencia triangulares, estas se definen con dos parámetros: media y varianza.
Se definen tres funciones de pertenencia gaussianas en cada entrada del modelo difuso. Tres se considera el número suficiente de funciones de pertenencia para inducir la interpretabilidad del modelo 28, mantener bajo control la complejidad de este y evitar la redundancia en las funciones de pertenencia.
El número de parámetros que configuran estas funciones de pertenencia es de dos parámetros por cada una de las tres funciones de pertenencia en cada entrada considerada. Así, el valor de parámetros de un sistema difuso, en función de sus entradas, está dado por la ecuación (16).
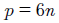 (16)
(16)
Estos parámetros se encuentran en el intervalo para definir la media, y en el intervalo para definir la varianza de cada función de pertenencia. Fuera de estos intervalos se aumenta la probabilidad de obtener funciones de pertenencia redundantes o de poca influencia para las salidas en el modelo optimizado.
El número de reglas de un modelo difuso en función del número de entradas está dado por la ecuación (17).
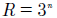 (17)
(17)
Siendo el número de entradas del modelo difuso a optimizar. Estas reglas utilizan el operador AND, para evaluar toda combinación posible de funciones de pertenencia por entrada para su ajuste en el proceso de optimización.
Los modelos difusos propuestos se diferencian principalmente en el conjunto de entradas y la cantidad de estas. La Tabla I muestra los modelos propuestos probados.
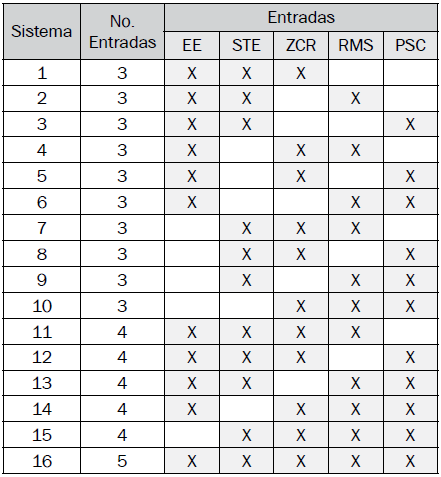
5.3 Conjuntos de datos propuestos
Se han implementado alteraciones sobre archivos de audio con el fin de atenuar 59, segmentar 60, detectar silencios 50), (51, y comprimir señales de voz mediante cuantización vectorial 61. En este artículo, los fragmentos de cada señal normalizada en los que el valor de STE es menor al 1% fueron removidos para evitar el procesamiento innecesario de silencios en el cálculo de sus características.
Para la obtención de los datos se ha establecido un conjunto de 50 archivos de audio con una señal de voz masculina o femenina. El 78% de los archivos de audio son obtenidos de una base de datos 62, y el 22% restante fue creado en un entorno arbitrario. Todos los archivos de audio pronuncian una palabra o frase legible. El 50% de los archivos pertenecen a voces masculinas, y el 50% restante a voces femeninas.
Se prueba la optimización con cuatro conjuntos de datos obtenidos de una base de datos de señales de voz, y cuatro mecanismos de preprocesamiento de las señales de audio, con el propósito de variar los valores de entrada sin alterar la base de datos de voces y determinar cuál de estos es clasificado con mayor exactitud. Los cuatro mecanismos de preprocesamiento de señales son:
Procesamiento puro de la señal (sin filtro promediador ni transformada rápida de Fourier).
Procesamiento de la señal aplicando transformada rápida de Fourier.
Procesamiento de la señal con filtro promediador de la señal en 10 períodos anteriores y sin transformada rápida de Fourier.
Procesamiento de la señal con filtro promediador de la señal en 10 períodos anteriores y transformada rápida de Fourier.
Por cada mecanismo se produce un conjunto de datos diferente. Los conjuntos producidos serán identificados como conjuntos 1, 2, 3 y 4, respectivamente.
5.4 Indicadores de desempeño
Los indicadores de desempeño son calculados en cada modelo difuso propuesto y género, y son el medio por el que se determinan los mejores resultados. Estos indicadores son la exactitud pura, la exactitud de acierto y el error cuadrático medio.
Para el cálculo de estos indicadores, toda señal de voz evaluada en un modelo difuso tiene tres valores: género real, género estimado y género definido.
Los valores de género real y género definido son enteros, donde 1 representa el género masculino, y 0 representa el género femenino. El valor de género estimado tiene un valor real que oscila entre estos valores.
El primer indicador, la exactitud pura (EP), es el valor que describe el éxito de clasificación del sistema sin un umbral definido. Mientras mayor sea la diferencia entre las salidas obtenidas (género estimado), y las esperadas (género real), la exactitud pura es menor. Se define mediante la ecuación (18).
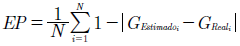 (18)
(18)
DondeNes el número de señales de voz procesadas y clasificadas por el modelo difuso.
El segundo indicador, la exactitud aproximada o de acierto (EA), a diferencia de la exactitud pura, utiliza el género definido que utiliza un umbral para clasificar la salida como masculina o femenina. El género definido se calcula mediante la ecuación (19).
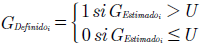 (19)
(19)
Donde el umbralUpara determinar el género es de 0,5. Si la salida final es mayor al umbral, el género será clasificado como masculino, y de otro modo, femenino. La exactitud de acierto se define mediante la ecuación (20).
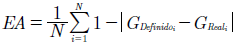 (20)
(20)
El propósito de la EA es concretar un género de acuerdo con la exactitud pura, siendo un indicador dicotómico de acierto o fallo por señal de voz.
El tercer indicador, el error cuadrático medio (MSE), es la media aritmética de la suma de las diferencias entre las salidas esperadas y las salidas obtenidas al cuadrado:
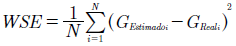 (21)
(21)
El MSE es el parámetro más usado en el propósito de prueba de modelos 63, y es usado en este artículo como indicador de desempeño (fitness) en los algoritmos de optimización.
Se busca que el MSE sea el mínimo posible. Si este valor es menor, los indicadores de exactitud tienden a ser mayores y los resultados obtenidos (géneros estimados) se aproximan a los deseados (géneros reales).
5.5 Configuración de los algoritmos de optimización
Para hacer la comparación de resultados entre algoritmos bioinspirados y sus configuraciones, se probó un número de iteraciones de 500, y una población de 20 individuos en todas las configuraciones.
La Tabla II muestra las tres diferentes configuraciones por cada algoritmo bioinspirado.
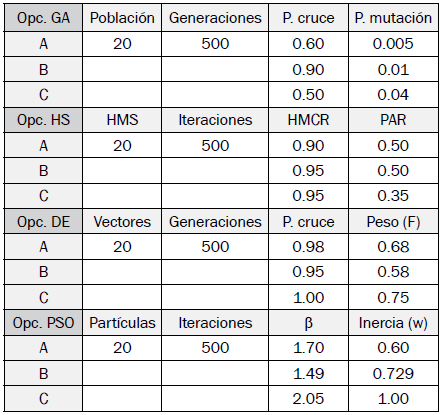
Para el método cuasi-Newton se establece una única configuración con un máximo de 100 iteraciones, y un máximo de 10.000 evaluaciones de la función objetivo.
6. ANÁLISIS DE RESULTADOS
En esta Sección se lista una serie de tablas y gráficas con los resultados de indicadores de desempeño, en las que se establecen los mejores conjuntos de datos y modelos por algoritmo bioinspirado.
6.1 Análisis cuantitativo
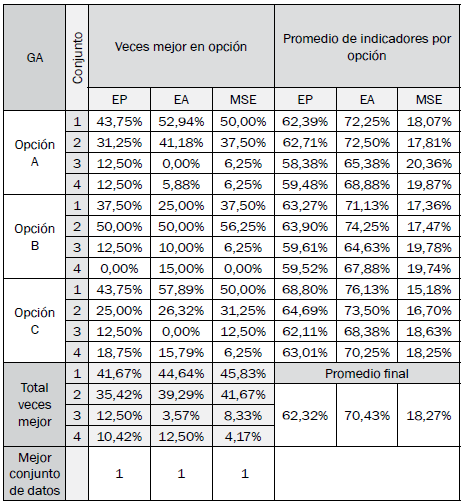
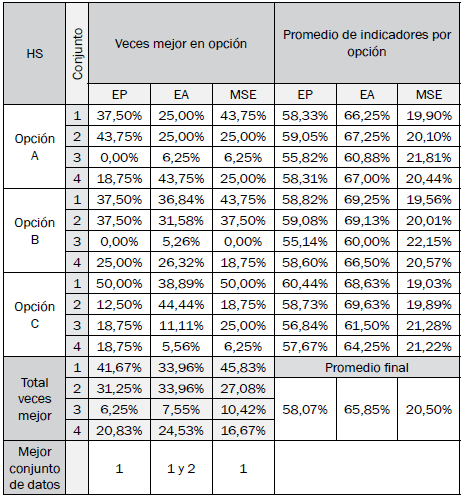
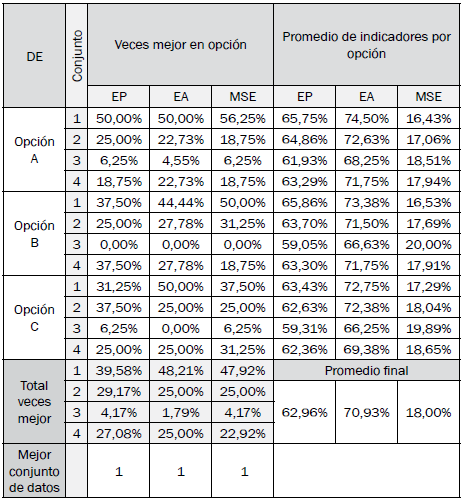
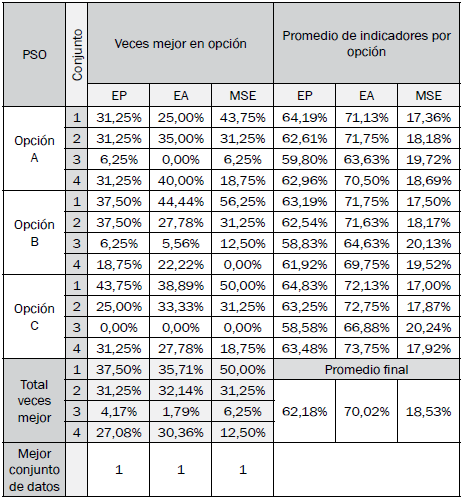
Las tablas III a VI resumen los resultados de desempeño en cada opción por cada algoritmo bioinspirado, independientemente del modelo difuso de clasificación.
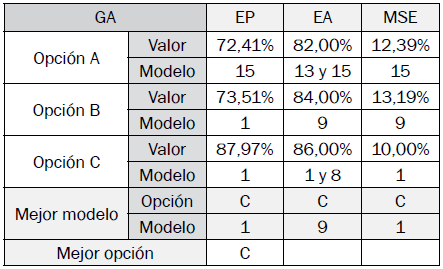
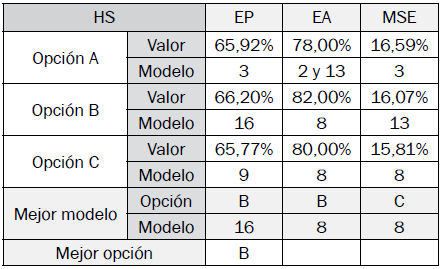
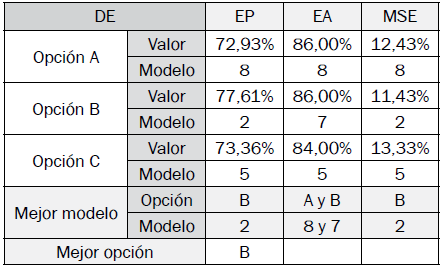
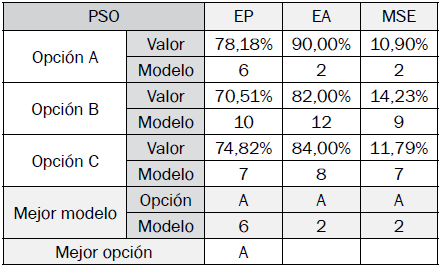
Los resultados de los mejores modelos difusos de clasificación optimizados encontrados por opción en cada algoritmo son especificados en las tablas VII a X, y se determina la mejor opción y modelo con base en sus indicadores de desempeño.
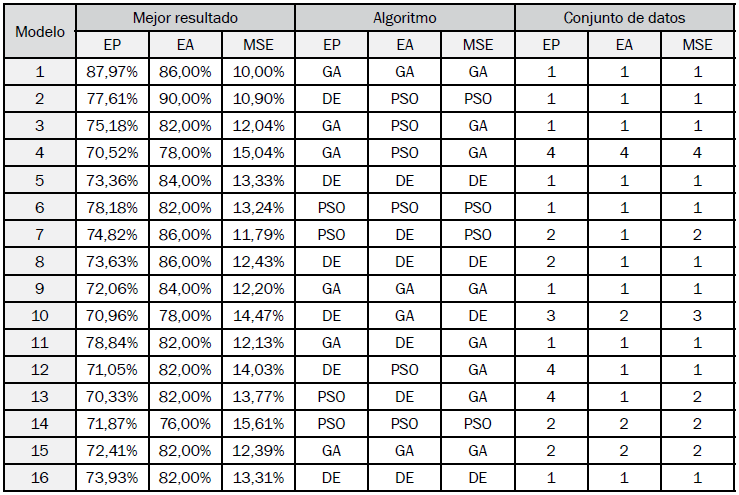
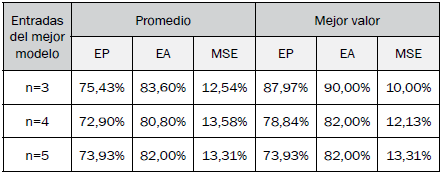
Los mejores resultados por modelo se muestran en la Tabla XI, con el algoritmo bioinspirado y conjunto de datos utilizado para lograr cada uno de sus indicadores. La Tabla XII muestra los resultados promedio por número de entradas y la Tabla XIII muestra los resultados promedio de los modelos con una entrada en común.
6.2 Análisis cualitativo
En esta Subsección se resumen gráficamente los resultados de la Subsección anterior.
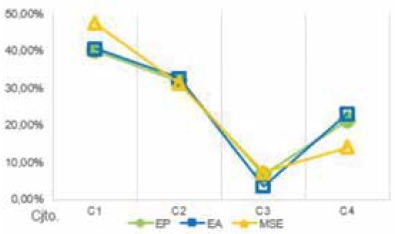
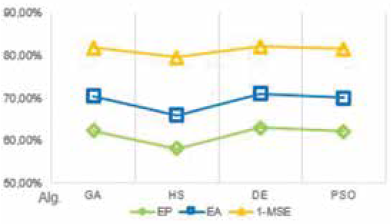
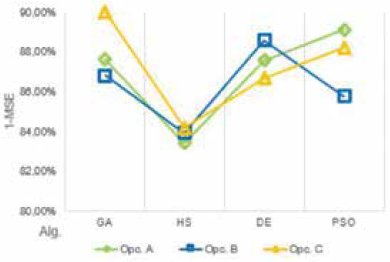
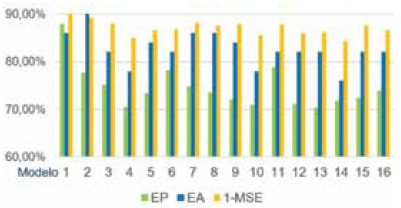
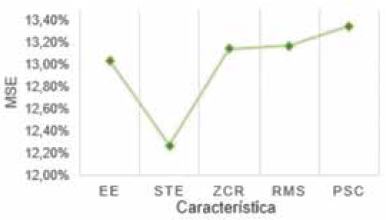
La Fig. 9 muestra el promedio de veces en que el resultado de desempeño de cada conjunto de datos fue mejor que los demás. La Fig. 10 muestra el desempeño por algoritmo bioinspirado. La Fig. 11 muestra el mejor desempeño por opción de cada algoritmo. La Fig. 12 compara los mejores resultados en cada modelo difuso. La Fig. 13 compara el promedio de estos resultados de acuerdo con el número de entradas de los modelos. La Fig. 14 compara el desempeño de las entradas de acuerdo con los mejores resultados de cada modelo difuso.
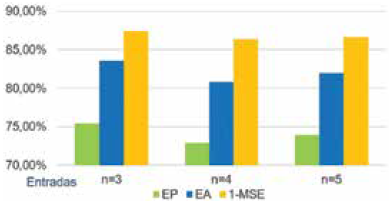
6.3 Análisis de modelos difusos de mayor desempeño
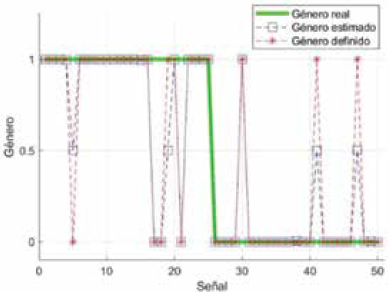
La Fig. 15 muestra los resultados de clasificación de género por voz del primer modelo difuso optimizado propuesto con el que se obtuvo el menor valor de MSE.
Se hace gráficamente evidente que el género estimado se aproxima con precisión al género real, con algunas excepciones en las que se aproxima al valor de umbral establecido (0,5) o al valor del género opuesto.
El criterio del género estimado no logró inferir el género del 8% de las señales de voz, y se equivocó de género en otro 8% de señales de voz. No obstante, el 84% restante de señales de voz fue clasificada con precisión, lo que puede interpretarse como la seguridad intrínseca del modelo difuso y su similitud con la inferencia de un ser humano para la clasificación de género.
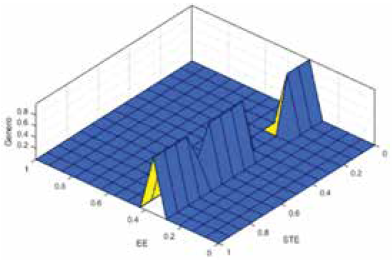
El primer modelo utiliza las tres primeras entradas definidas en la Sección 4. Las figuras 16, 17 y 18 muestran los valores que conforman la superficie de salida en función del valor de cada par posible de entradas.
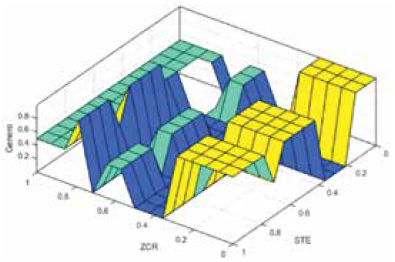
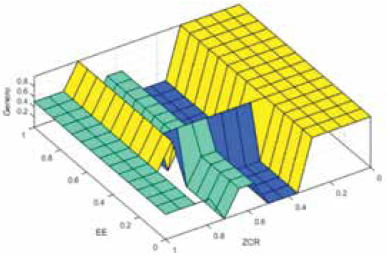
La Fig. 19 muestra los resultados de clasificación de género por voz del segundo mejor modelo difuso optimizado con el que se obtuvo un MSE del 10,9%.
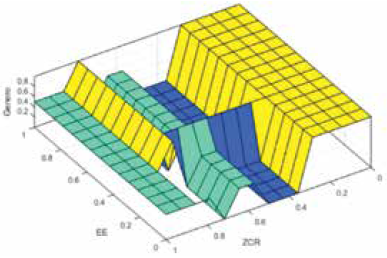
En este modelo la exactitud de acierto es del 90%, pero el criterio del género estimado tiene menor precisión, lo que lo hace menos confiable para la clasificación.
CONCLUSIONES
De acuerdo con los resultados se han obtenido las siguientes conclusiones:
Los conjuntos de datos de mayor a menor desempeño son 1, 2, 4 y 3. La Fig. 9 permite inferir que el procesamiento de la señal pura es sin duda la mejor opción, y que una señal promediada en 10 períodos anteriores no tiene la información que se requiere en el proceso de clasificación.
El modelo propuesto de mayor desempeño es el número 1, seguido de los modelos 2, 7 y 3. Todos estos usan tres entradas y los conjuntos de datos 1 y 2.
El modelo propuesto de menor desempeño es el número 14, seguido de los modelos 4, 10 y 12. Estos modelos tuvieron mejores resultados con los conjuntos de datos 3 y 4.
Los modelos de más de tres entradas no logran superar a los primeros cuatro mejores modelos. Esto puede atribuirse al tamaño del espacio de búsqueda, debido a que este es proporcional a la cantidad de entradas de un modelo difuso, a pesar de tener una cantidad de datos mayor para la clasificación.
El modelo obtenido de mejor desempeño se obtuvo con algoritmos genéticos en el modelo número 1, tuvo un MSE del 10% y logró una exactitud pura cercana al 88%. Las entradas de mayor influencia para el éxito de clasificación son EE, STE y ZCR.
La exactitud de acierto es un indicador de desempeño del que no se puede asegurar un modelo difuso optimizado con precisión; para este fin se utiliza la exactitud pura.
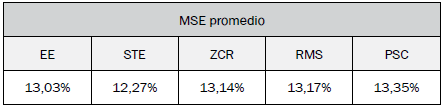
La entrada que más logra caracterizar el género de una señal de voz es STE. La entrada que menos logra caracterizar el género de una señal de voz es PSC.
Los algoritmos GA, DE y PSO tuvieron desempeños promedio cercanos. DE obtuvo el mejor promedio de indicadores de desempeño.
El algoritmo HS obtuvo el menor desempeño. Esto significa que el número de iteraciones que este requiere para lograr convergencia a mínimos globales debe ser mayor que la de los demás algoritmos.
Las mejores opciones para los algoritmos GA, HS, DE y PSO son las opciones C, C, B y A, respectivamente.
De acuerdo con la interpretación del mejor modelo optimizado, el valor de ZCR tiende a ser menor en voces masculinas.
De acuerdo con la interpretación del mejor modelo optimizado, un valor alto de ZCR junto a un valor bajo de STE describe mejor a las voces femeninas.
Este esquema puede ser utilizado para la clasificación de salidas diferentes al género y su descripción en función de las entradas de los modelos como ventaja de su interpretabilidad.

