











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
PermalinkINTRODUCTION
In Colombia, according to the National Plan for Science, Technology and Innovation; agroindustry is a traditional production sector in the country and it’s productivity can be significantly improved through the use and application of Information and Com munication Technologies (ict) 1. The objective of this sector is to obtain high quality products to meet global market requirements. To achieve this, the most frequent problem they face is the presence of diseases in crops that can cause large production losses. For this reason, several institutions of the agricultural sector have invested resources to implement ict solutions to their problems. Moreover, these institutions have experts that perform several researches to identify the causes of diseases that affect crops and to propose the best possible treatments.
Computer science proposals have been made to reduce the effects caused by different diseases and pests in crops. One of the solutions used for this purpose is expert system, a system that uses human knowledge stored in a computer to solve a problem that requires human expertise 2. For this purpose, different techniques of artificial intelligence are adressed, such as decision trees, bayesian networks, among others. Likewise, there is a trend in computer sciences to use graphs, which have a dynamic nature and consist of a set of nodes that are connected through edges, as data structure. Data structure in graphs can be exploited for storage and analysis in a crop environment, where there are different types of entities and variables related to ach other.
Various studies propose the development of expert systems to detect and recom mend a treatment for diseases in crops. Several of them make use of decision trees as prediction models, given a knowledge base, which categorizes a number of conditions to reach the solution of a problem. However, these approaches do not consider the representation of knowledge base and decision trees as graphs. Under this approach, graph data mining techniques could be exploited 3-6.
This article focuses on presenting an overview of graph pattern matching tech niques and expert systems used in agriculture for detection and treatment recommen dation of diseases in several crops. The review motivates us to present a proposal of an expert system for crop disease based on graph pattern matching. The remainder of this paper is organized as follows: Section II describes expert systems used in agricul ture and the graph pattern matching approach. Section III refers to the most relevant research found on these topics. Section IV reviews algorithms and techniques used, and describes our proposal. Section V presents a case study; and Section VI relates the conclusions.
1. BACKGROUND
There are three areas of importance to this proposal: expert systems, rules generation through decision trees, and graph pattern matching. First, an expert system is a branch of artificial intelligence composed of a number of tools that make use of human knowl edge stored in a computer in order to solve a problem 2. Indeed, the knowledge used in these systems comes from people who have a high degree of expertise in the area in which is necessary to make a decision or find a solution to a given problem. Under these conditions, expert systems have been implemented in many areas of knowledge.
Broadly, the structure of the expert systems is composed of: a knowledge acquisition subsystem, responsible for the accumulation, transfer and transformation of knowledge base, from expert information; a knowledge base, which contains the knowledge used to understand, formulate and solve a problem; inference engine, consisting of techniques and algorithms that have the ability to draw conclusions; a user interface, used for com munication between user and computer; and finally, an explanation subsystem used to justify the solution given by the system 7. Additionally, expert systems make use of one or more techniques of artificial intelligence (decision trees, bayesian networks, supervised learning, etc.) to improve their reasoning and thus inferring better results over knowledge base. Precisely, Decision Tree Induction (dti) is a technique that aims to generate models (classifiers) that relate the different variables and classes contained in a dataset, using symbolic and interpretable representations for understanding deci sion limits and implicit logic in existing data. Furthermore, it is possible to re-express complex decision trees as small sets of rules that outperform the original trees when classifying a new dataset is required 8.
On the other hand, we have the graph pattern matching problem. A graph consists of nodes that represent entities and edges that represent links or relationships between these entities 9, allowing the characterization of the distribution of large sources of information, strategic positions of its’ elements, and dynamics within a knowledge base 10. This representation generally cares about the syntax and not the semantics. The latter allows to enrich and generate additional information from stored data 11. A graph that considers semantic structures consists of ontology classes (nodes) and relations between them (connections) 3.
In turn, there is a technique in data mining in graphs called graph pattern match ing, which is defined: “given a data graph G, and a pattern of graph Q, find all matches of Q in G” 6. These types of search are usually aimed at finding entities with specific characteristics in their attributes and relationships with other nodes in the graph. In this sense, the searched pattern can be seen as a series of conditions within the attributes of the graph, similar to the assessment made by decision trees.
2. RELATED WORK
This studies are focused, on one hand, on the development of expert systems for crop diseases and, on the other hand, on graph pattern matching techniques and algorithms.
2.1 Expert Systems:
Expert systems aim to generate solutions to specific problems through the analysis of a series of facts and rules produced by people with a degree of expertise within an application area. In the first approach considered in this area, carried out by Mansingh et al. 12, an expert system to manage pests and diseases of coffee in a developing country is presented. This system considers a knowledge base, consisting of rules and facts created from the knowledge of experts in coffee pests and diseases, an inference engine and a module for explanation.
Similar to the previous work mentioned, in 13 an expert system to assist in the diagnosis of coffee diseases is built, based on the analysis of plants carried out by the farmer. The system structure is based on fuzzy logic techniques and decision trees, used to represent a number of present conditions given the existence of any disease, these conditions are defined by experts.
In 7, the proposed system makes use of condition-ending type rules (if-then) and builds from expert knowledge. Besides, the user may enter different crop parameters and these variables are used by the generated rules as a data source to perform the inference process. The evaluation process makes use of measures of satisfaction by users and experts, such as validation (which checks whether the recommendation given by the system is correct) user acceptance; and clearly, the gathering information pro cess. Added to this, there is an evaluation of some case studies conducted by samples containing controlled parameters that have been defined by the expert contributors of the project.
Lastly, in 14 and 15 expert and decision support systems are developed which consider climate information obtained from meteorological sensors and knowledge of people with experience in the domain where they are applied. First, in 14 the expert system works in parallel with a decision support system. On detection of a risk situ ation, the expert system is invoked to help the user take action against the problem. Second, in 15 the expert system becomes a guide for users according to the weather forecast obtained by monitoring different meteorological variables.
2.2 Decision Trees
There are several approaches that propose using decision trees in agricultural envi ronments. In the research carried out in 16, two algorithms, decision tree induction (dti), and a variant of dti combined with Rough Set are used. dti is based on finding a hypothesis or rules within a set of examples. The algorithms described are part of a set of techniques used to generate mango disease warnings in India. Research presented in 17 proposes the use of fuzzy decision trees to generate coffee rust warnings. These models represent thresholds for different variables involved in these problematic situ ations for both disease prevention and treatment. Meanwhile, in research conducted by Mahmoud Omid 18, the design of an expert system for sorting pistachio nuts through decision trees and a fuzzy logic-based classifier is presented. In this case, the discovery of relevant fuzzy rules was achieved using the decision tree algorithm. In the study presented by Millers et al. 19, the objective was to relate weather data with the severity percentage of wheat scab from decision tree induction.
2.3 Graph Pattern Matching
Within graph data mining, pattern matching is one of the techniques most explored by researchers. Below, various research papers that propose techniques and optimizations for matching patterns in graphs are described.
Firstly, in 20 a software called Graph Matching Toolkit (gmt) is presented. It allows to graphically construct graph patterns for their search. gmt uses an algorithm called TruST 21 to perform the pattern matching process, which generates a binary search tree to analyze graph nodes. The system proposed in 22, called G-Path, aims to find patterns on large graphs. In order to demonstrate the system’s operation , the authors construct a web application that allows searching for entities and relationships in large volume graphs. With a similar purpose, 23 addresses the problem of matching similar vertices of graph pairs in parallel, commonly found on large graphs databases. This approach makes use of a technique called Network Similarity Decomposition (nsd), submitted by the same author in 24.
Meanwhile, in 25 an algorithm for graph isomorphism at large scale is shown. This algorithm is an improvement of the VF algorithm 26, called VF2, where data structure used for the exploration of search space is enhanced. The proposed methodol ogy is implemented in a manner that significantly reduces memory requirements for execution. With this, the VF2 algorithm evaluation is presented and compared with Ullman’s algorithm 27, obtaining better performance measures in memory usage and execution time for VF2, especially in large graphs. These two algorithms (VF2 and Ullmann) are addressed in other studies, like in 28 where the most important theoretical foundations of graph matching and isomorphism between two graphs or sub-graphs are discussed, as well as its two approaches: exact and inexact. To carry out this research, the Ullman Algorithm was used as a starting point.
Besides, there are graphs with special features that require special analysis. Firstly, Moustafa et al., 29 try to deal with the problem of uncertain graphs with identity linkage uncertainty through the creation of a set of algorithms based on two ideas: context- aware path indexing and reduction by join-candidates. In second place, Ya masaki et al., 30 deal with a special kind of query graph where no vertex is totally surrounded by edges, called outerplanar graph pattern. Lastly, 31 presents a new approach for graph isomorphism in attributed graphs. For this purpose, query graphs are linearized into a walk with parameters. In addition, an algorithm called pmg is created to match the linearized walk by traversing the attribute graph.
The review conducted shows that there are many researchers that have interest in matching patterns in graphs. Due to this, graph as data structure becomes important within computer science.
3. DISCUSSION
In the previous section a revision of the state of the art about expert systems and graph pattern matching was presented. For expert systems, the search query was bounded to “crop disease expert systems” in order to find research that pointed to the development of these systems for prevention and treatment recommendation of diseases in differ ent crops. Most proposals presented in the papers mentioned make use of inference engines based on rules to analyze the problem’s characteristics and create a solution or suggestion. Thus, knowledge from experts is modeling through ‘‘if then...else’’ rules form. However, there are some research approaches that consider the use of artificial intelligence techniques, like decision trees to classify data involved in the problem addressed and to generate new knowledge that may be used by the expert system.
For the area of graph data mining, the search query was “graph pattern matching”. These approaches are based on proposing improvements to well known algorithms, generating new algorithms and more efficient techniques for problem matching in graphs, and to deal with graphs characteristics like attributes in nodes and edges, out erplanar graphs, among others. The most used algorithm is VF2 26, which represents the basis of new proposals seeking to improve their efficiency and performance over large graphs databases. This algorithm can be described by means of the state space representation (ssr). In each state, a partial mapping solution is maintained and only consistent states are kept. These states are generated using feasibility rules that remove pairs of nodes that cannot be isomorphic.
Based on the review of the state of the art mentioned, the gaps described in Table 1 were defined.
Table 1 Gaps found for the development of an expert system based on graph pattern matching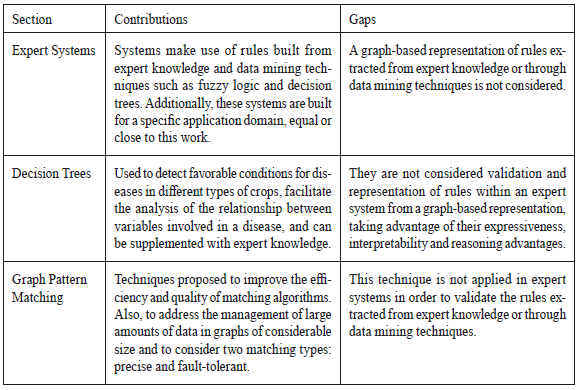 Source: authors
Source: authors
Using the review and gaps described above as a starting point, we considered some research about graph-based representation of knowledge and rules. Knowledge representation as graphs keeps essential properties of modeled objects, provides ad vantages for reasoning and enables greater expressiveness, establishing relationships between entities and specification of attributes in nodes and edges. Also, graphs are easily interpreted, and reasoning can be graphically represented in a natural manner using the graphs themselves 32.
On the other hand, expert systems are based mostly on rules that analyze the differ ent parameters involved in a problem and that may constitute a large ruleset. Precisely, there are some problems in large rulesets (integrity, conflicting rules, missing rules, duplication, subsumption) that can be addressed through their representation based on graphs 33. In 34 the author makes use of the Conceptual Graph (cg) formalism 35 with its reasoning operations for the comparison and integration of several conceptual graph rules corresponding to different experts viewpoints. The graph-oriented approach allows combining knowledge, user experience and semantic techniques into an expert system. Similarly, Buche et al., 36 use cg to build labelled graphs that represent rules,knowledge and facts. The knowledge base obtained can be further enriched through semantic concepts and ontologies. Furthermore, graph-based representation (directed acyclic graph) can improve the efficiency of rule execution, incorporating expert and statistical knowledge 37.
Considering the use of rulesets in expert systems, drawn from the knowledge produced by experts and extracted through data mining techniques, it is possible to represent each rule as a graph pattern. More specifically, the ruleset can be defined as a set of graph patterns R = (R1,,…, Rn). Thereby, we can define Graph Pattern Matching approach as follows: “given a data graph G, and a set of patterns R, find all matches of R in G”. This process finds the sub-graphs M (RG) that comply with the conditions established in each rule. Moreover, the graph pattern concept sup ports the interaction of the domain expert (being able to express his/her current level of knowledge) and can be used with data mining techniques to improve the pattern construction 38.
The foregoing considerations motivate the development of an expert system to detect diseases in crops, based on graph pattern matching as a validation technique of rules and knowledge produced by experts. Furthermore, graph patterns may represent the classification generated by artificial intelligence and data mining techniques, ap plied to a dataset obtained after crop monitoring.
4. PROPOSAL
Taking in account the previous considerations, our proposal is based on the modules exposed in Figure 1. These modules represent the analysis process of expert system and its components are described below:
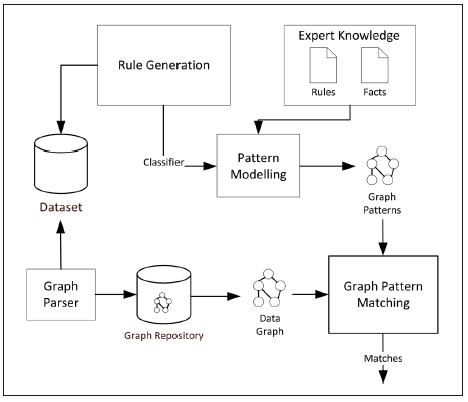
Expert knowledge: contains a set of rules and facts involved in the detection of crop diseases. From several researches, experts determine disease cycles and how external factors (such as climatic conditions and agronomic properties) affect each cycle stage, which allows characterizing the disease and generating predictive variables for rule extraction, making use of classifiers.
Rule generation: composed by a decision tree Induction technique, responsible for generating new classification rules based on analysis of data obtained from monitoring crops and their properties, where each ruleset is given as a classifier. Models generated from decision trees are of symbolic nature and easily interpretable.
Dataset: contains different parameters and monitoring data of crops.
Graph parser: is responsible for transforming the information contained in the dataset to a graph-based representation. In order to include the variety of semantics contained in crops environment, a data graph is defined as G (V,E,L) 6, where V denotes a finite set of nodes that represent entities within an environment, connected by direct links or vertices E, such that E
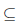 VxV _correspond to the relationships between nodes of the graph and L is a function defined in V so that for each v in V, L (v) is the label of v. Indeed, L (v) may indicate semantic variety mentioned as types of relationships, properties of nodes, etc. With this in mind, Graph parser is in charge of taking the information from the dataset to perform the transformation. The first step is to identify the different types of entities that exist in the dataset such as weather conditions, crop physical properties, crop management, among others. From this, a central node that represents the crop associated with an instance is determined, and a set of nodes that represent the data in this instance (which are labeled according to the corresponding entity type) are generated. As a next step, these nodes are interrelated and node labels describing values for the instance variables are added. As a result, a data graph that contains information about climatic conditions and agronomic properties of crops is obtained in a more expressive and interpretable representation.
VxV _correspond to the relationships between nodes of the graph and L is a function defined in V so that for each v in V, L (v) is the label of v. Indeed, L (v) may indicate semantic variety mentioned as types of relationships, properties of nodes, etc. With this in mind, Graph parser is in charge of taking the information from the dataset to perform the transformation. The first step is to identify the different types of entities that exist in the dataset such as weather conditions, crop physical properties, crop management, among others. From this, a central node that represents the crop associated with an instance is determined, and a set of nodes that represent the data in this instance (which are labeled according to the corresponding entity type) are generated. As a next step, these nodes are interrelated and node labels describing values for the instance variables are added. As a result, a data graph that contains information about climatic conditions and agronomic properties of crops is obtained in a more expressive and interpretable representation. Graph Repository: graph database containing information extracted from the dataset in a graph-based representation.
Pattern Modeling: is responsible for generating graph patterns to be evaluated, based on classifiers and rules created from expert knowledge. In this process, first, the generated classifiers must be expressed as “if ... then” type rules through the analysis of each decision tree leaf. From these rules and generated from expert’s knowledge, a ruleset for the disease to be identified is obtained. As a result, each rule can be represented as a graph pattern, based on 39 that defines a graph pattern as
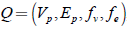 , where:
, where:Vp is a set of nodes and Ep is a set of directed edges, as they were defined for a data graph.
fv () is a function defined in Vp , so for each node u, fv (u) is a label of u.
fe () is a function defined in Ep, so for each edge (u,u') in Ep, fe (u,u') , is a label of the relationship between nodes (u,u').
Thereby, these functions can be used to specify semantic search conditions or variable ranges, defined by labels in terms of Boolean predicates. Thus, the patterns condition the search to instances where favorable conditions for a crop disease exist.
Graph Pattern Matching: composed of one or more graph pattern matching algorithms which validate the rules, expressed as a graph pattern, in order to find favorable conditions for the development of a crop disease. For this task, an adaptation of VF2 algorithm is considered. This adaptation performed an evaluation of labels values contained in nodes and relationships. In this way, the search conditions are more focused on the analysis of nodes and relationship labels, leaving the topological structure matching in background, which can improve the performance of the matching task. As a result, it is possible to find within a graph database, the subgraphs matching each pattern, which in this case correspond to crop registers where there is a risk of some disease ocurrence.
5. CASE STUDY
To illustrate the process carried out in the proposed system (Figure 1), a case study to detect favorable conditions for rust development in coffee is presented.
Coffee rust is still the main pathological problem in coffee cultivation. Research conducted by experts suggests that this disease is closely related to the physiological development of the crop, the production level of the plant and the distribution of some climatic variables such as temperature, humidity and rain. The knowledge produced by these experts is expressed through rules and facts that describe the relationship between different parameters involved in the development of coffee rust.
On the other hand, the Rule Generation module applies one or more data mining techniques to the crop information extracted from the dataset. Its purpose is to relate variables that characterize a crop in past episodes of the disease, taking into account the suggestions of the experts, in order to generate classifiers that can categorize new measurements and relate them to a favorable or unfavorable condition for an epidemic of coffee rust. In the case of applying a decision tree algorithm, each classifier would represent a branch of the decision tree, and therefore, this can result in a large ruleset.
The Pattern-Modeling module receives the rules and facts extracted from the expert knowledge and the classifiers given by the Rule Generation module. With such information, this module generates graph patterns, expressing the rules to be evalu ated. Graph patterns can represent existing conditions within the rules that evaluate monitoring data and crop properties, relationships that a crop unit may have with others, its’ flowering timing, fruit pending load and maintenance data (assuming that these are decisive factors for the appearance of rust in coffee). Figure 2 shows an example of the structure of a resulting graph pattern.
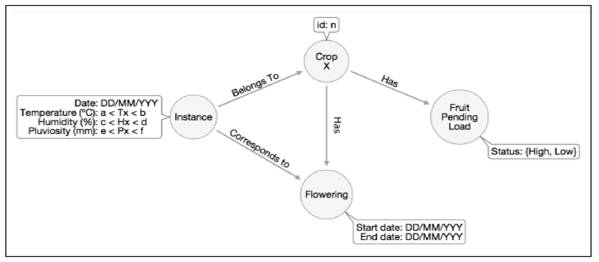
The graph pattern shown expresses the different conditions contained in one of the rules produced by experts and extracted by the Rule Generation module. Moreover, graph-based representation relates entities from different domains such as Instance, related to meteorological information taken at a specific date and containing ranges of climatic variables and including the Flowering entity, related to a property of the coffee crop. In a traditional representation of rules, a rule is required for each domain, resulting in a large ruleset where the maintenance operation may result in an incon sistency, as well as in unstructured rules 33.
The Graph parser module generates a graph-based representation of the dataset that contains the monitoring data and properties of coffee crops. The result of this process is a graph called data graph.
Finally, the graph pattern matching module takes the data graph and generated patterns to find subgraphs matching these patterns. Given that, graph patterns rep resent rules and classifiers obtained in previous steps and subgraphs that result from applying a graph pattern matching technique that represent instances in which condi tions favorable to the emergence of disease in the crop are met. Considering the graph pattern example mentioned above, resulting subgraphs obtained in this module met the conditions given for the Instance entity (values of climate variables were within the range set in the pattern), flowering dates coincided with the Flowering entity con tained in the pattern, and the status of fruit pending load was the same as such entity consulted through the pattern.
In this way, a ruleset could be expressed through graph patterns to get a better expressiveness, deal with the known problems on large rulesets, and support the inclu sion of other technologies related to graphs as ontologies, semantic inference engines and other Web 3.0 approaches.
6. CONCLUSIONS
This paper conducts a review of research carried out in recent years in the areas of expert systems for crop diseases and graph pattern matching techniques. In the first area, the systems developed make use mostly of rule-based reasoning. Additionally, some approaches propose the use of artificial intelligence techniques in expert systems as tools to generate inferences or new rules. However, there are some problems in large rulesets and its maintenance (integrity, conflicting rules, missing rules, duplication, subsumption). In the area of pattern matching, researches propose improvements and capabilities to be applied to graphs of different types and characteristics. Precisely, the expressiveness of graphs as data structure can be exploited to represent rulesets generated within an expert system, deal with problems on large rulesets and validate each rule making use of graph pattern matching techniques.
The above considerations motivated us to propose an expert system for crop dis ease based on graph pattern matching. As future work, we intend to implement the above proposal, in order to generate the mentioned expert system that implements an improved quality of analysis applied to different variables of Colombian crops and, thus, generate early warnings for several crop diseases.

