











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
PermalinkINTRODUCCIÓN
La medición del riesgo operacional es una de las áreas críticas de los procesos de ges tión de riesgo financiero. El riesgo operacional obedece a factores cuya cuantificación se hace muy compleja debido a la carencia de información de soporte. Desde hace algunos años, se ha desarrollado un conjunto significativo de instrumentos técnicos, útiles para medir distintos tipos de riesgo. Este avance se observa en mayor medida en el área financiera, en la cual diferentes técnicas estadísticas y econométricas han sido adoptadas para contribuir con los procesos de medición, y con la toma de deci siones óptimas bajo incertidumbre, por parte de las empresas 1. De esta forma, es posible encontrar técnicas econométricas útiles para medir diferentes tipos de riesgo financiero como mercado, liquidez, crédito, operacional o, incluso, el riesgo sistémico, que engloba aspectos de todos los anteriores 2.
Este documento plantea un avance en esta dirección, ya que estudia las fuentes de riesgo relevantes para empresas vinculadas en su operación con variables de tipo demográfico.
La estrategia se concentra: en la identificación de los factores de riesgo pertinentes para el negocio; la modelación estadística adecuada del riesgo marginal implícito en cada uno de estos factores; la modelación completa de las relaciones de codependencia que pueden existir entre ellos y, finalmente, el mapeo desde el dominio de los factores de riesgo hacia los indicadores financieros de las empresas.
La metodología se ilustra mediante su aplicación a la medición del riesgo de mortalidad, al que se encuentra expuesta una empresa de seguros funerarios, cuyos egresos futuros de operación están determinados por la materialización de eventos fúnebres dentro de la población afiliada. Se tiene información sobre esa población discriminada en rangos de edad y género, y se requiere analizar el comportamiento de la reserva técnica patrimonial asociada con la operación de la empresa. La propuesta metodológica involucra el uso de distintos modelos propios de la ciencia actuarial, tales como el modelo demográfico de Lee - Carter 3, así como de otros pertenecientes al ámbito de la econometría financiera, como el valor en riesgo (VaR), el valor en riesgo condicional (CoVaR) y la estimación de relaciones de dependencia mediante cópulas bivariadas.
En relación con la modelación de riesgos demográficos, la literatura es extensa. Incluso dentro del campo específico del pronóstico de las tasas de mortalidad existen abundantes vertientes. Aplicaciones del modelo de Lee-Carter en casos latinoameri canos se pueden encontrar por ejemplo en México 4 y en Chile 5.
1. METODOLOGÍA
La metodología propuesta consta de 4 pasos: identificación de factores de riesgo, mo delación de los comportamientos univariados, estimación de las relaciones de depen dencia y mapeo desde los factores de riesgo a los indicadores financieros de la empresa.
1.1. Identificación de los factores de riesgo
En el caso ilustrativo, considerado en el presente artículo, se tiene que los principales egresos futuros de la empresa dependen del número de fallecimientos registrados en la población afiliada. Entre mayor sea el número de fallecimientos, mayor será el desem bolso en términos de auxilios funerarios. Por lo tanto, no existen variables de control propiamente dichas. Por una parte, se tiene que la pérdida esperada depende de las tasas de mortalidad específicas, por rangos de edad y sexo, de los grupos de personas afiliados a la entidad. Por otro lado, se sabe que tal pérdida depende de la población afiliada al fondo, discriminada en las mismas categorías de las tasas de mortalidad. Para facilitar el cálculo, esta población se supone constante a lo largo del año. De esta forma, la pérdida esperada está dada por
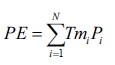 ()1
()1
En donde, la pérdida esperada, PE, depende linealmente de las tasas de mortali dad específicas, Tmi, en cada grupo etario por sexo. Depende también de la población afiliada, discriminada una vez más por rango de edad y sexo, Pi . En total se identifican 34 factores de riesgo: tasas de mortalidad para hombres y mujeres en grupos de edades: menores a 1 año, entre 1-4 años,…, 70-74 años y de 75 años en adelante.
1.2. Modelación de los comportamientos univariados
Cada uno de los 34 factores de riesgo debe ser pronosticado, para poder así estimar su participación dentro de la pérdida esperada de la compañía. Para tal fin, se exploran, en este paso, dos metodologías alternativas: una de ellas el modelo de Lee & Carter 3, y otra los modelos de series de tiempo univariados tradicionales, ARIMA (auto rregresivos integrados de medias móviles).
El modelo de Lee-Carter es un modelo estadístico ampliamente utilizado en la lite ratura sobre demografía y actuaría, para la estimación y pronóstico de tasas específicas de mortalidad y tablas de vida 7)-(10. Se ha convertido en una herramienta indispensable dentro de la formulación de políticas públicas relacionadas con la expectativa de vida de una población específica y el pronóstico de sus tasas de mortalidad.
Formalmente, sea log mxt el logaritmo natural de la tasa de mortalidad específica del grupo x en el período t. Se tiene que el modelo puede ser estructurado en términos de a y b en la dimensión etaria, y un vector k a lo largo de la dimensión temporal, de forma tal que:
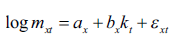 ()2
()2
Adicionalmente deben cumplirse las restricciones de que 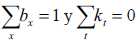 de manera que las ax son promedios temporales simples de los logaritmos de las tasas de mortalidad específicas, y los parámetros del sistema están plenamente identificados.
de manera que las ax son promedios temporales simples de los logaritmos de las tasas de mortalidad específicas, y los parámetros del sistema están plenamente identificados.
La estrategia de estimación consiste en utilizar una descomposición de valor singular (SVD), puesto que el método de mínimos cuadrados ordinarios no puede ser aplicado directamente en la ecuación (2), ya que el índice kt debe ser también estima do en el proceso. De esta forma, kt es un índice del nivel de mortalidad en el tiempo, mientras que axindica la forma general de esta mortalidad a lo largo del espectro de los distintos rangos de edad. bx, por su parte, mide la sensibilidad de la tasa de mortalidad específica ante cambios en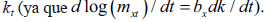
La popularidad del modelo con respecto a modelos tradicionales de series de tiempo ARIMA se debe a la inclusión del término kt que es común a todas las tasas. Este solo varía en el tiempo y no tranversalmente. De esta forma, se reduce la cantidad de parámetros a ser estimados, a la vez que impone un comportamiento acompasado entre las tasas, impidiendo pronósticos en intervalos largos de tiempo dispersos.
Dado que en el ejercicio presente no es de interés la construcción de tablas de vida a lo largo de dominios prolongados de tiempo, es posible utilizar modelos ARIMA tradicionales para el pronóstico de las tasas de mortalidad individuales, a manera de comparación, para dar robustez a los hallazgos.
En este caso se aplicó un modelo ARIMA a los logaritmos de la serie de tiempo de cada una de las tasas específicas de mortalidad de forma tal que
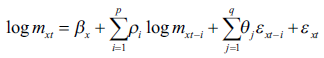 ()3
()3
Se utilizan logaritmos para garantizar la no-negatividad del pronóstico. La ecuación (3) se estima para cada grupo poblacional. βx el intercepto de cada regresión. Por su parte, ρiy son los coeficientes autorregresivos y de medias móviles del sistema, res pectivamente. Los números i y j son determinados a través de comparación de mode los, proceso en el cual se selecciona el modelo con un menor criterio de informaciónbayesiano (BIC). εxt es un término de perturbación ruido blanco. Cuando se detecta la presencia de raíces unitarias se procede a la diferenciación de la variable, para lograr la estacionariedad.
1.3. Modelación de las relaciones de dependencia
Hasta aquí solo se han considerado los comportamientos univariados de los factores de riesgo. Si bien el método de Lee-Carter impone una dependencia lineal en la parte de baja frecuencia de los espectros de las series, aún en este caso las relaciones de de pendencia no lineales se dejan por fuera del análisis, y también así las que se presentan en el resto del espectro. Estas relaciones son de gran importancia en el análisis, puesto que un incremento abrupto y conjunto en las tasas de mortalidad podría configurar un escenario de operación de gran estrés financiero, y podría llevar a la quiebra.
Una forma particularmente conveniente y completa de modelar las relaciones de dependencia entre las tasas de mortalidad en este tipo de problemas la constituye la estimación de tales relaciones mediante cópulas. Formalmente, una cópula es una función de distribución multivariada tal que
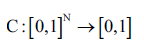 ()4
()4
Donde N son el número de factores de riesgo descritos antes y C denota la cópula.
En términos generales el teorema de Sklar (1959) plantea que si F es una función de distribución multivariada con marginales F1, …, FN (no necesariamente continua), entonces, existe una cópula C n: (,) (,) 0101_tal que, para todo z1, …, zN en R = (-∞, ∞):
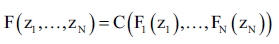 ()5
()5
Si las marginales son continuas, C es única.
Cabe anotar que la cópula no se encuentra definida sobre las tasas de mortalidad directamente, ni sobre las series filtradas a través del modelo ARIMA o el Modelo de Lee-Carter. Primero es necesario construir una pseudo-muestra a saber:
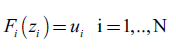 ()6
()6
Donde zi son los residuales de la regresión en las ecuaciones 2 o 3. Para construir μ, que es el vector con componentes del tipo μi, en este estudio se hace uso de las distribuciones empíricas acumuladas de probabilidad, asociadas con cada factor deriesgo. Una consideración adicional que se debe tener en cuenta es que al trabajar con muchos factores de riesgo la estimación de una cópula multivariada no es recomenda ble; de hecho, construir modelos de este tipo es un problema de reconocida dificultad 13. Una alternativa de amplio uso en la literatura reciente es el uso de pair-copulas (una estructura jerárquica de cópulas bivariadas).
Siguiendo este esquema como en 13, se muestra que al mismo tiempo que se mantiene la lógica de elaborar relaciones complejas a través de bloques individuales simples, se minimiza la cantidad de supuestos de independencia condicional, que mu chas veces deben ser impuestos, al utilizar otros caminos en el proceso de estimación.
Formalmente, la función de densidad, asociada con la función de distribución acumulada en (5), puede ser factorizada así:
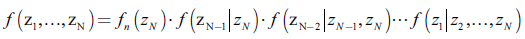 ()7
()7
A su vez, cada término en 7 puede ser descompuesto en una cópula bivariada, multiplicada por una densidad marginal condicional. Usando la fórmula general se tiene que:
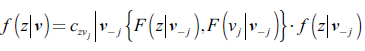 ()8
()8
para un vector N-dimensional υ. Aquí υ j es un componente escogido arbitraria mente de υ. υ-j denota el vector-υ, excluyendo ese componente. Por su parte, czvj es una cópula bivariada (cópula-par) entre z y υj. En conclusión, tal y como se señala en 13, bajo condiciones de regularidad apropiadas, una densidad multivariada puede ser expresada como el producto entre cópulas-par, actuando sobre diferentes distribuciones de probabilidad condicionales. También es claro que la construcción es, por naturaleza, iterativa, y que, dada una factorización específica, existen muchas re-parametrizaciones con las cuales se puede lograr este objetivo.
Estas diferentes construcciones de cópulas-par disponibles pueden ser descritas a partir de 14 en un modelo gráfico denominado vine regular. La clase de vine regular es amplia. En este estudio se sigue una de las posibilidades de mayor uso, conocida como D-vine15. Cada modelo señala una forma específica de descomponer la densidad.
La figura 1 describe una descomposición D-vine de cinco dimensiones. Consta de cuatro árboles Tj , j = 1,…,4. El árbol Tj tiene 6 - j nodos y 5 - j ejes. Cada eje co rresponde a una densidad de cópula-par, y el rótulo del eje corresponde al subíndice de la densidad bivariada, e.g. el eje 25|34 corresponde a la cópula c 25|34(·).
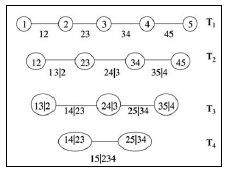
En 14 se proporciona la densidad de una distribución N-dimensional en términos de un vine-regular. De esta forma la densidad de f(z 1 ,…,zN) puede ser escrita como:
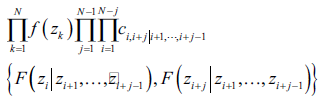 ()9
()9
Donde los índices j identifican los árboles, mientras que los índices i denotan los ejes en cada árbol. En los D-vine, ningún nodo en ningún árbol conecta con más de dos ejes. En 13 se proveen los pasos necesarios para realizar simulaciones usando las cópulas estimadas en el constructo D-vine. Este método es necesario para prede cir el número de fallecimientos que se puede presentar en escenarios de estrés en la operación de la empresa.
1.4. Mapeo desde factores de riesgo hacia indicadores financieros
Una vez modelados los factores de riesgo, es posible obtener por simulación diferentes escenarios de operación de la empresa en términos del número de eventos que se pue den registrar en el siguiente año de operación. En particular se utilizan, además de la pérdida esperada, dos indicadores de amplio uso en la ingeniería financiera, como lo son el valor en riesgo (VaR) y el valor en riesgo condicional (CoVaR) 2), (6), (16.
1.4.1. Resumen del algoritmo
Se simulan M escenarios de operación de la empresa (1.000 por ejemplo), en términos de las tasas de mortalidad que pudieren observarse.
Se toma el escenario medio (que corresponde al pronóstico de la pérdida, pérdida esperada),
Se calcula un escenario extremo, al (1 - α) % de confianza (VaR 1-α) y
Se construye un escenario de pérdida sistémica, asociado con el promedio de todos los escenarios por encima del (VaR 1-α), denominado CoVaR 1-α.
En cada caso se multiplican las tasas correspondientes por la población afiliada por sexo y rango de edad, de la empresa, la cual se supone fija durante el año de operación.
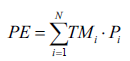 ()10
()10
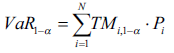 ()11
()11
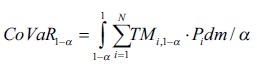 ()12
()12
Donde Pi es la población perteneciente a cada rango de edad y sexo. TMi es la tasa específica de mortalidad por rango de edad y sexo.
2. ANÁLISIS DE RESULTADOS
Para estimar la dinámica de las tasas de mortalidad es necesaria una serie de tiempo de cada tasa con una longitud considerable. Las tasas de mortalidad observadas en la población afiliada de las empresas son generalmente muy pocas, por lo que es mejor recurrir a las tasas de mortalidad de la zona geográfica de operación de la empresa, en este caso, la ciudad de Santiago de Cali. En esta ciudad se desarrolla la gran mayoría de las operaciones de la empresa y en donde se emplaza más del 80 % de su población de clientes.
2.1. Datos
Los datos de las tasas de mortalidad por géneros y según los rangos de edad especi ficados se obtuvieron directamente de la Secretaría de Salud Municipal de Cali, con una frecuencia anual desde 1985 hasta 2012.
La empresa, por su parte, proporcionó información sobre la población afiliada, según género, fecha de nacimiento y defunción. Con esta información fue posible caracterizar la población, tarea para la cual se hizo uso de 74.644 registros. La Figura 2 describe en términos generales a la población afiliada, y la Figura 3, las defunciones registradas al año 2013 dentro de la población afiliada de la empresa en el mismo año.
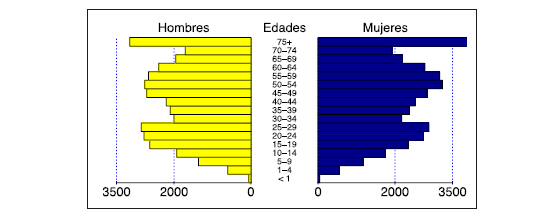
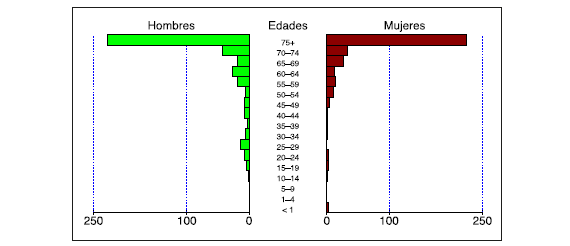
Como se puede observar, debido al tipo de negocio de la empresa, tanto la población general afiliada, como el número de defunciones registrado se encuentran concentrados en los rangos de edad más altos (entre 70 y 74 años, y más de 75 años). El número de hombres y mujeres es, por su parte, equiparable. Esta mayor concentración se tiene en cuenta en el cálculo de la pérdida esperada, el VaR y el CoVaR, en las fórmulas (10) a (12), ya que, a pesar de que la tasa de mortalidad pronosticada debe hacer uso de la información para la ciudad, el cálculo de los indicadores se realiza multiplicando por las poblaciones específicas de la empresa.
Las tasas de mortalidad por sexo y rango de edad para Cali, desde 1985 a 2012, que constituyen la muestra de estudio, se presentan en la Figura 4.
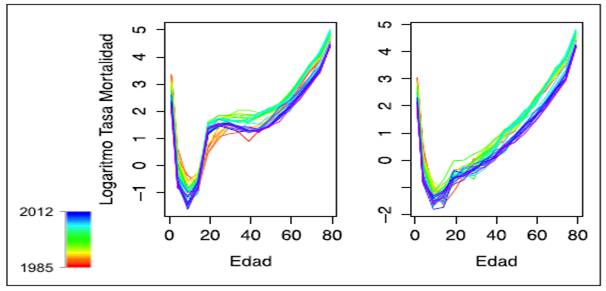
2.2. Resultados Modelo ARIMA
Los modelos ARIMA univariados, ajustados sobre el logaritmo de las tasas de mortalidad, se hicieron con el paquete de R, auto.arima. Se escogió el mejor modelo siguiendo el criterio bayesiano (BIC), es decir, se escogió el modelo que minimizara tal estadístico en cada caso. Este criterio permite tener en cuenta, no solo el ajuste del modelo dentro de la muestra, sino que incorpora cierta penalización por el número de grados de libertad consumidos en la estimación (para minimizar la probabilidad de sobreajuste en muestra).
Los modelos escogidos de esta forma tienden a ser más parsimoniosos que los especificados siguiendo criterios alternativos.
Los estadísticos asociados con estas estimaciones no se reportan en este docu mento, pero están disponibles a petición del interesado. En la Tabla 1 se presentan las tasas de mortalidad pronosticadas a un año por grupo de edad.
Tabla 1 Pronósticos por rango de edad y sexo ARIMA. Tasas de mortalidad 0/00
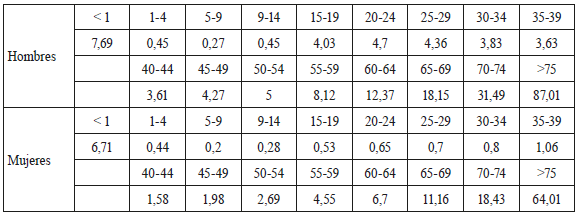
Fuente: elaboración propia
Con los residuales de los modelos ARIMA se construyó la pseudo-muestra. Se contrastó la hipótesis de que tal pseudo-muestra descrita en la ecuación (6) estaba bien construida, mediante un estadístico de Kolmogorov-Smirnov. En ningún caso se rechaza la hipótesis nula de que la pseudo-muestra se distribuye uniforme entre 0 y 1.
El procedimiento de ajuste de la cópula en la pseudo-muestra implica la elección de la estructura que más se acople a los datos en cada paso de la iteración. Esto se hizo, una vez más, automáticamente, con la ayuda del paquete de R, CD Vine. Se consideraron 40 categorías disponibles.
Finalmente, se simularon 1 000 escenarios, de los cuales se extrajeron el VaR y el CoVaR al 90 % de confianza, construidos después de multiplicar cada uno de los escenarios simulados por la población expuesta. La síntesis de los escenarios se presenta en la Figura 5.
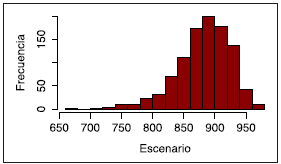
Para el caso del modelo ARIMA la pérdida esperada, en términos de número de fallecimientos, a un año, ascendió a 882. El VaR, con un 90 % de confianza, se ubicó en 930, y el CoVaR, en 944.
2.3. Resultados modelo Lee- Carter
El modelo de Lee-Carter se ajustó con ayuda del paquete en R Demography. En la Tabla 2 se presentan las tasas de mortalidad pronosticadas a un año por grupo de edad.
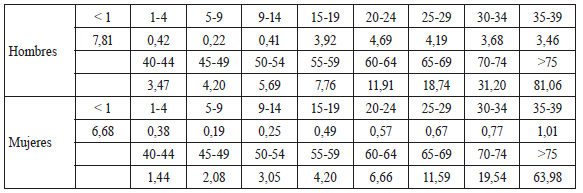
La síntesis de los escenarios simulados con este modelo se presenta en la Figura 6.
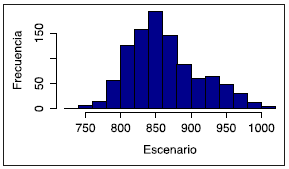
Para el caso del modelo de Lee-Carter la pérdida esperada, en términos de número de fallecimientos, a un año, ascendió a 863. El VaR con un 90 % de confianza se ubicó en 938, y el CoVaR, en 962.
2.4. Análisis de la reserva técnica de operación
Para la valoración de la reserva técnica de operación, que se desprende de la anterior metodología, se procedió al análisis de los estados financieros de la entidad a diciembre 31 de 2013. Con esta información se estimó el indicador de utilidad para cobertura de servicio (UCS). Este se obtiene como la diferencia entre los ingresos operacionales y los gastos de funcionamiento de la entidad: UCS = Ingresos operacionales - Gastos de personal - Gastos Generales. El indicador de utilidad para cobertura de servicio permite estimar la capacidad de atender los auxilios y servicios funerarios comprometidos a partir de su ejercicio anual. El resultado deseable en términos de este indicador es que la utilidad para cobertura de servicio de un determinado período haya sido suficiente para cubrir los costos y auxilios funerarios del mismo período, sin necesidad de re currir a reserva alguna.
Al observar el período 2008-2013, (Figura 7) se puede observar que la cobertura de los servicios y auxilios funerarios se ha realizado básicamente con los recursos provistos por el propio negocio después de descontar los gastos de funcionamiento del mismo. Esta situación ha permitido que la entidad pueda fortalecer su reserva técnica a lo largo de los años.
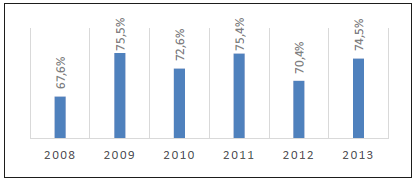
Posteriormente se simularon escenarios de operación de la empresa, mediante los pronósticos del modelo de Lee-Carter (CoVaR), y se evaluaron costos promedio de eventos entre $1 400 000 y $2 000 000 de pesos. Para los escenarios de riesgo extremo propuestos, el costo del servicio funerario podría oscilar entre $1.3 millones y $1.9 millones de pesos, lo cual implicaría que aún, en escenarios extremos, se puede cubrir el servicio funerario con la utilidad para cobertura de servicio.
Un análisis aún más extremo se puede llevar a cabo utilizando el CoVaR esti mado, en varios años de forma consecutiva. Para este escenario se considera un costo medio de servicio de $1.810.750. Con este valor se estima el costo total anual de auxilio funerario, el cual se compara contra la utilidad de cobertura de servicio del mismo año. Los desfases son cubiertos por la reserva de la entidad que a diciembre de 2013 ascendía a $2.307 millones de pesos. Con estas situaciones extremas recurrentes, el fondo de imprevistos de la empresa se estaría agotando entre el año 2018 y el 2019, sin considerar ningún tipo de realimentación financiera.
3. CONCLUSIONES
Se propone una metodología para estimar el riesgo financiero de una empresa expuesta ante factores de tipo demográfico. Se identifica en las tasas de mortalidad por sexo y rangos de edad como el principal factor de riesgo del negocio y para su modelación se recurre a modelos por factores como el de Lee-Carter y a cópulas bivariadas. Se simulan varios escenarios de operación y financieros de una empresa a manera de ejemplo, con datos reales y, de esta forma, se hace posible estimar la reserva técnica óptima de operación de la entidad y el tiempo en que se agotaría tal reserva.
Esta estrategia de modelación tiene en cuenta diferentes hechos estilizados de las tasas de mortalidad, como el hecho de que no son estacionarias en media, y los patrones de dependencia temporal y transversal en el conjunto de tasas de mortalidad. Los patrones de dependencia transversal son capturados mediante cópulas bivariadas, mientras que los de dependencia temporal, mediante modelos tradicionales de series de tiempo univariadas. Estos últimos son aplicados sobre las diferencias logarítmicas de las tasas de mortalidad. La presente metodología tiene aplicaciones tanto para el pronóstico directo de diferentes escenarios de operación de empresas expuestas a riesgos de mortalidad y longevidad, como a la construcción de intervalos de confianza para el pronóstico de tasas de mortalidad en demografía y actuaría.
Los resultados señalan que las estrategias adoptadas históricamente por la empresa para la constitución de la reserva técnica han sido efectivas en la medida en que se ha logrado contar con un mecanismo de cobertura eficiente ante los siniestros normales que se han presentado.

